
📍 let, const : let, const와 블록 레벨 스코프
ES5까지 변수를 선언할 수 있는 유일한 방법은 [var 키워드]를 사용하는 것이었다. var 키워드로 선언된 변수는 아래와 같은 특징이 있다. 이는 다른 언어와는 다른 특징으로 주의를 기울이지 않으면 심각한 문제를 일으킨다.
- [함수 레벨 스코프(Function-level scope)]
- 함수의 코드 블록만을 스코프로 인정한다. 따라서 전역 함수 외부에서 생성한 변수는 모두 전역 변수이다. 이는 전역 변수를 남발할 가능성을 높인다.
- for 문의 변수 선언문에서 선언한 변수를 for 문의 코드 블록 외부에서 참조할 수 있다.
- var 키워드 생략 허용
- 암묵적 전역 변수를 양산할 가능성이 크다.
- 변수 중복 선언 허용
- 의도하지 않은 변수값의 변경이 일어날 가능성이 크다.
- [변수 호이스팅]
- 변수를 선언하기 이전에 참조할 수 있다.
대부분의 문제는 전역 변수로 인해 발생한다. 전역 변수는 간단한 애플리케이션의 경우, 사용이 편리하다는 장점이 있지만 불가피한 상황을 제외하고 사용을 억제해야 한다. 전역 변수는 유효 범위(scope)가 넓어서 어디에서 어떻게 사용될 것인지 파악하기 힘들며, 비순수 함수(Impure function)에 의해 의도하지 않게 변경될 수도 있어서 복잡성을 증가시키는 원인이 된다. 따라서 변수의 스코프는 좁을수록 좋다.
ES6는 이러한 var 키워드의 단점을 보완하기 위해 let과 const 키워드를 도입하였다.
#1. let
#1.1 블록 레벨 스코프
대부분의 프로그래밍 언어는 블록 레벨 스코프(Block-level scope)를 따르지만 자바스크립트는 함수 레벨 스코프(Function-level scope)를 따른다.
함수 레벨 스코프(Function-level scope)함수 내에서 선언된 변수는 함수 내에서만 유효하며 함수 외부에서는 참조할 수 없다. 즉, 함수 내부에서 선언한 변수는 지역 변수이며 함수 외부에서 선언한 변수는 모두 전역 변수이다.블록 레벨 스코프(Block-level scope)모든 코드 블록(함수, if 문, for 문, while 문, try/catch 문 등) 내에서 선언된 변수는 코드 블록 내에서만 유효하며 코드 블록 외부에서는 참조할 수 없다. 즉, 코드 블록 내부에서 선언한 변수는 지역 변수이다.
var foo = 123; // 전역 변수
console.log(foo); // 123
{
var foo = 456; // 전역 변수
}
console.log(foo); // 456
블록 레벨 스코프를 따르지 않는 var 키워드의 특성 상, 코드 블록 내의 변수 foo는 전역 변수이다. 그런데 이미 전역 변수 foo가 선언되어 있다. var 키워드를 사용하여 선언한 변수는 중복 선언이 허용되므로 위의 코드는 문법적으로 아무런 문제가 없다. 단, 코드 블록 내의 변수 foo는 전역 변수이기 때문에 전역에서 선언된 전역 변수 foo의 값 123을 새로운 값 456으로 재할당하여 덮어쓴다.
ES6는 블록 레벨 스코프를 따르는 변수를 선언하기 위해 let 키워드를 제공한다.
let foo = 123; // 전역 변수
{
let foo = 456; // 지역 변수
let bar = 456; // 지역 변수
}
console.log(foo); // 123
console.log(bar); // ReferenceError: bar is not defined
let 키워드로 선언된 변수는 블록 레벨 스코프를 따른다. 위 예제에서 코드 블록 내에 선언된 변수 foo는 블록 레벨 스코프를 갖는 지역 변수이다. 전역에서 선언된 변수 foo와는 다른 별개의 변수이다. 또한 변수 bar도 블록 레벨 스코프를 갖는 지역 변수이다. 따라서 전역에서는 변수 bar를 참조할 수 없다.
#1.2 변수 중복 선언 금지
var 키워드로는 동일한 이름을 갖는 변수를 중복해서 선언할 수 있었다. 하지만, let 키워드로는 동일한 이름을 갖는 변수를 중복해서 선언할 수 없다. 변수를 중복 선언하면 문법 에러(SyntaxError)가 발생한다.
var foo = 123;
var foo = 456; // 중복 선언 허용
let bar = 123;
let bar = 456; // Uncaught SyntaxError: Identifier 'bar' has already been declared
#1.3 호이스팅
자바스크립트는 ES6에서 도입된 let, const를 포함하여 모든 선언(var, let, const, function, [function*], class)을 호이스팅한다. 호이스팅(Hoisting)이란, var 선언문이나 function 선언문 등을 해당 스코프의 선두로 옮긴 것처럼 동작하는 특성을 말한다.
하지만 var 키워드로 선언된 변수와는 달리 let 키워드로 선언된 변수를 선언문 이전에 참조하면 참조 에러(ReferenceError)가 발생한다. 이는 let 키워드로 선언된 변수는 스코프의 시작에서 변수의 선언까지 일시적 사각지대(Temporal Dead Zone; TDZ)에 빠지기 때문이다.
console.log(foo); // undefined
var foo;
console.log(bar); // Error: Uncaught ReferenceError: bar is not defined
let bar;
변수가 어떻게 생성되며 호이스팅은 어떻게 이루어지는지 좀 더 자세히 살펴보자. 변수는 3단계에 걸쳐 생성된다.
선언 단계(Declaration phase)변수를 실행 컨텍스트의 변수 객체(Variable Object)에 등록한다. 이 변수 객체는 스코프가 참조하는 대상이 된다.초기화 단계(Initialization phase)변수 객체(Variable Object)에 등록된 변수를 위한 공간을 메모리에 확보한다. 이 단계에서 변수는 undefined로 초기화된다.할당 단계(Assignment phase)undefined로 초기화된 변수에 실제 값을 할당한다.
var 키워드로 선언된 변수는 선언 단계와 초기화 단계가 한번에 이루어진다. 즉, 스코프에 변수를 등록(선언 단계)하고 메모리에 변수를 위한 공간을 확보한 후, undefined로 초기화(초기화 단계)한다. 따라서 변수 선언문 이전에 변수에 접근하여도 스코프에 변수가 존재하기 때문에 에러가 발생하지 않는다. 다만 undefined를 반환한다. 이후 변수 할당문에 도달하면 비로소 값이 할당된다. 이러한 현상을 [변수 호이스팅(Variable Hoisting)]이라 한다.
// 스코프의 선두에서 선언 단계와 초기화 단계가 실행된다.
// 따라서 변수 선언문 이전에 변수를 참조할 수 있다.
console.log(foo); // undefined
var foo;
console.log(foo); // undefined
foo = 1; // 할당문에서 할당 단계가 실행된다.
console.log(foo); // 1

let 키워드로 선언된 변수는 선언 단계와 초기화 단계가 분리되어 진행된다. 즉, 스코프에 변수를 등록(선언단계)하지만 초기화 단계는 변수 선언문에 도달했을 때 이루어진다. 초기화 이전에 변수에 접근하려고 하면 참조 에러(ReferenceError)가 발생한다. 이는 변수가 아직 초기화되지 않았기 때문이다. 다시 말하면 변수를 위한 메모리 공간이 아직 확보되지 않았기 때문이다. 따라서 스코프의 시작 지점부터 초기화 시작 지점까지는 변수를 참조할 수 없다. 스코프의 시작 지점부터 초기화 시작 지점까지의 구간을 ‘일시적 사각지대(Temporal Dead Zone; TDZ)’라고 부른다.
// 스코프의 선두에서 선언 단계가 실행된다.
// 아직 변수가 초기화(메모리 공간 확보와 undefined로 초기화)되지 않았다.
// 따라서 변수 선언문 이전에 변수를 참조할 수 없다.
console.log(foo); // ReferenceError: foo is not defined
let foo; // 변수 선언문에서 초기화 단계가 실행된다.
console.log(foo); // undefined
foo = 1; // 할당문에서 할당 단계가 실행된다.
console.log(foo); // 1

결국 ES6에서는 호이스팅이 발생하지 않는 것과 차이가 없어 보인다. 하지만 그렇지 않다.
let foo = 1; // 전역 변수
{
console.log(foo); // ReferenceError: foo is not defined
let foo = 2; // 지역 변수
}
위 예제의 경우, 전역 변수 foo의 값이 출력될 것처럼 보인다. 하지만 ES6의 선언문도 여전히 호이스팅이 발생하기 때문에 참조 에러(ReferenceError)가 발생한다.
ES6의 let으로 선언된 변수는 블록 레벨 스코프를 가지므로 코드 블록 내에서 선언된 변수 foo는 지역 변수이다. 따라서 지역 변수 foo도 해당 스코프에서 호이스팅되고 코드 블록의 선두부터 초기화가 이루어지는 지점까지 일시적 사각지대(TDZ)에 빠진다. 따라서 전역 변수 foo의 값이 출력되지 않고 참조 에러(ReferenceError)가 발생한다.
#1.4 클로저
블록 레벨 스코프를 지원하는 let은 var보다 직관적이다.
var funcs = [];
// 함수의 배열을 생성하는 for 루프의 i는 전역 변수다.
for (var i = 0; i < 3; i++) {
funcs.push(function () { console.log(i); });
}
// 배열에서 함수를 꺼내어 호출한다.
for (var j = 0; j < 3; j++) {
funcs[j]();
}
위 코드의 실행 결과로 0, 1, 2를 기대할 수도 있지만 결과는 3이 세 번 출력된다. 그 이유는 for 루프의 var i가 전역 변수이기 때문이다. 0, 1, 2를 출력하려면 아래와 같은 코드가 필요하다.
var funcs = [];
// 함수의 배열을 생성하는 for 루프의 i는 전역 변수다.
for (var i = 0; i < 3; i++) {
(function (index) { // index는 자유변수다.
funcs.push(function () { console.log(index); });
}(i));
}
// 배열에서 함수를 꺼내어 호출한다
for (var j = 0; j < 3; j++) {
funcs[j]();
}
자바스크립트의 함수 레벨 스코프로 인하여 for 루프의 초기화 식에 사용된 변수가 전역 스코프를 갖게 되어 발생하는 문제를 회피하기 위해 [클로저]를 활용한 방법이다.
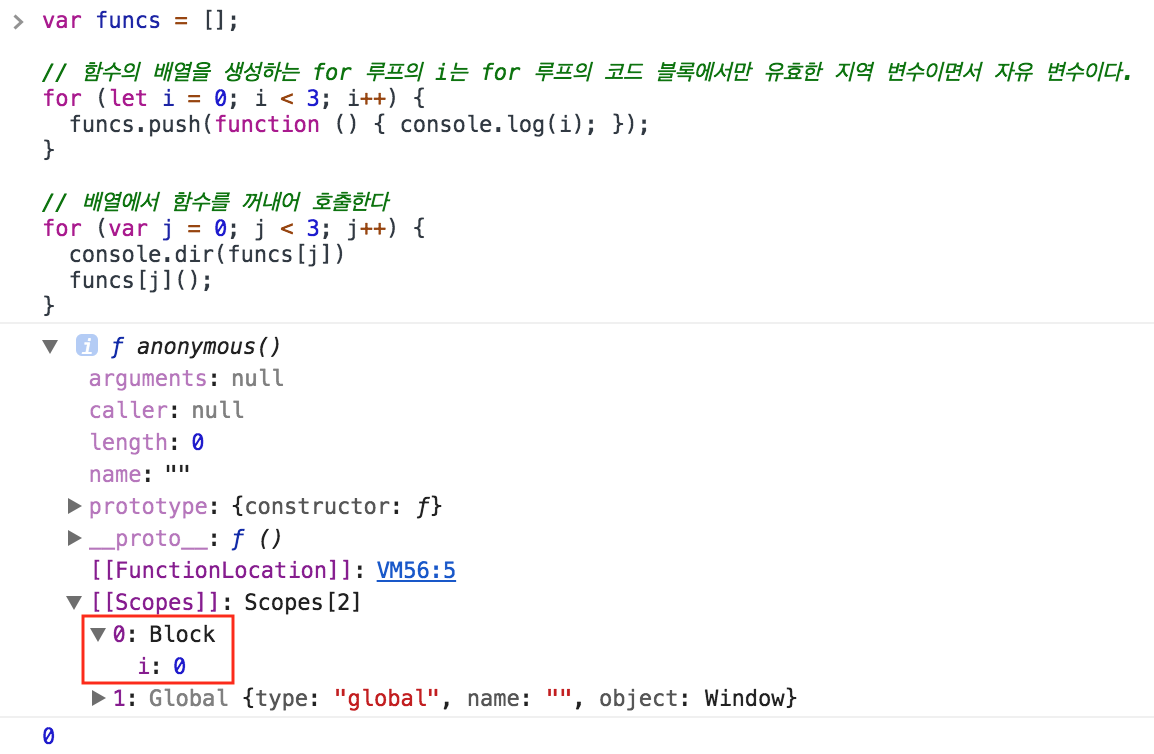
ES6의 let 키워드를 for 루프의 초기화 식에 사용하면 클로저를 사용하지 않아도 위 코드와 동일한 동작을 한다.
var funcs = [];
// 함수의 배열을 생성하는 for 루프의 i는 for 루프의 코드 블록에서만 유효한 지역 변수이면서 자유 변수이다.
for (let i = 0; i < 3; i++) {
funcs.push(function () { console.log(i); });
}
// 배열에서 함수를 꺼내어 호출한다
for (var j = 0; j < 3; j++) {
console.dir(funcs[j]);
funcs[j]();
}
for 루프의 let i는 for loop에서만 유효한 지역 변수이다. 또한, i는 자유 변수로서 for 루프의 생명주기가 종료되어도 변수 i를 참조하는 함수가 존재하는 한 계속 유지된다.
#1.5 전역 객체와 let
전역 객체(Global Object)는 모든 객체의 유일한 최상위 객체를 의미하며 일반적으로 Browser-side에서는 window 객체, Server-side(Node.js)에서는 global 객체를 의미한다. var 키워드로 선언된 변수를 전역 변수로 사용하면 전역 객체의 프로퍼티가 된다.
var foo = 123; // 전역변수
console.log(window.foo); // 123
let 키워드로 선언된 변수를 전역 변수로 사용하는 경우, let 전역 변수는 전역 객체의 프로퍼티가 아니다. 즉, window.foo와 같이 접근할 수 없다. let 전역 변수는 보이지 않는 개념적인 블록 내에 존재하게 된다.
let foo = 123; // 전역변수
console.log(window.foo); // undefined
#2. const
const는 상수(변하지 않는 값)를 위해 사용한다. 하지만 반드시 상수만을 위해 사용하지는 않는다.
#2.1 선언과 초기화
let은 재할당이 자유로우나 const는 재할당이 금지된다.
const FOO = 123;
FOO = 456; // TypeError: Assignment to constant variable.
주의할 점은 const는 반드시 선언과 동시에 할당이 이루어져야 한다는 것이다. 그렇지 않으면 다음처럼 문법 에러(SyntaxError)가 발생한다.
const FOO; // SyntaxError: Missing initializer in const declaration
또한, const는 let과 마찬가지로 블록 레벨 스코프를 갖는다.
{
const FOO = 10;
console.log(FOO); //10
}
console.log(FOO); // ReferenceError: FOO is not defined
#2.2 상수
상수는 가독성과 유지보수의 편의를 위해 적극적으로 사용해야 한다.
// 10의 의미를 알기 어렵기 때문에 가독성이 좋지 않다.
if (rows > 10) {
}
// 값의 의미를 명확히 기술하여 가독성이 향상되었다.
const MAXROWS = 10;
if (rows > MAXROWS) {
}
조건문 내의 10은 어떤 의미로 사용하였는지 파악하기가 곤란하다. 하지만 네이밍이 적절한 상수로 선언하면 가독성과 유지보수성이 대폭 향상된다.
const는 객체에도 사용할 수 있다. 물론 이때도 재할당은 금지된다.
const obj = { foo: 123 };
obj = { bar: 456 }; // TypeError: Assignment to constant variable.
#2.3 const와 객체
const는 재할당이 금지된다. 이는 const 변수의 타입이 객체인 경우, 객체에 대한 참조를 변경하지 못한다는 것을 의미한다. 하지만 이때 객체의 프로퍼티는 보호되지 않는다. 다시 말하자면 재할당은 불가능하지만 할당된 객체의 내용(프로퍼티의 추가, 삭제, 프로퍼티 값의 변경)은 변경할 수 있다.
const user = { name: 'Lee' };
// const 변수는 재할당이 금지된다.
// user = {}; // TypeError: Assignment to constant variable.
// 객체의 내용은 변경할 수 있다.
user.name = 'Kim';
console.log(user); // { name: 'Kim' }
객체의 내용이 변경되더라도 객체 타입 변수에 할당된 주소값은 변경되지 않는다. 따라서 객체 타입 변수 선언에는 const를 사용하는 것이 좋다. 만약에 명시적으로 객체 타입 변수의 주소값을 변경(재할당)하여야 한다면 let을 사용한다.
#3. var vs. let vs. const
변수 선언에는 기본적으로 const를 사용하고 let은 재할당이 필요한 경우에 한정해 사용하는 것이 좋다. 원시 값의 경우, 가급적 상수를 사용하는 편이 좋다. 그리고 객체를 재할당하는 경우는 생각보다 흔하지 않다. const 키워드를 사용하면 의도치 않은 재할당을 방지해 주기 때문에 보다 안전하다.
var와 let, 그리고 const는 다음처럼 사용하는 것을 추천한다.
- ES6를 사용한다면 var 키워드는 사용하지 않는다.
- 재할당이 필요한 경우에 한정해 let 키워드를 사용한다. 이때 변수의 스코프는 최대한 좁게 만든다.
- 변경이 발생하지 않는(재할당이 필요 없는 상수) 원시 값과 객체에는 const 키워드를 사용한다. const 키워드는 재할당을 금지하므로 var, let 보다 안전하다.
변수를 선언하는 시점에는 재할당이 필요할지 잘 모르는 경우가 많다. 그리고 객체는 의외로 재할당을 하는 경우가 드물다. 따라서 변수를 선언할 때에는 일단 const 키워드를 사용하도록 한다. 반드시 재할당이 필요하다면(반드시 재할당이 필요한지 한번 생각해 볼 일이다.) 그때 const를 let 키워드로 변경해도 결코 늦지 않는다.
ㅤㅤ
📍 Template Literals : 템플릿 리터럴
ES6는 템플릿 리터럴(Template literal)이라고 불리는 새로운 문자열 표기법을 도입하였다. 템플릿 리터럴은 일반 문자열과 비슷해 보이지만, ‘ 또는 “ 같은 통상적인 따옴표 문자 대신 백틱(backtick) 문자 ```를 사용한다.
const template = `템플릿 리터럴은 '작은따옴표(single quotes)'과 "큰따옴표(double quotes)"를 혼용할 수 있다.`;
console.log(template);
일반적인 문자열에서 줄바꿈은 허용되지 않으며 공백(white-space)를 표현하기 위해서는 백슬래시()로 시작하는 이스케이프 시퀀스(Escape Sequence)를 사용하여야 한다. ES6 템플릿 리터럴은 일반적인 문자열과 달리 여러 줄에 걸쳐 문자열을 작성할 수 있으며 템플릿 리터럴 내의 모든 white-space는 있는 그대로 적용된다.
const template = `<ul class="nav-items">
<li><a href="#home">Home</a></li>
<li><a href="#news">News</a></li>
<li><a href="#contact">Contact</a></li>
<li><a href="#about">About</a></li>
</ul>`;
console.log(template);
템플릿 리터럴은 + 연산자를 사용하지 않아도 간단한 방법으로 새로운 문자열을 삽입할 수 있는 기능을 제공한다. 이를 문자열 인터폴레이션(String Interpolation)이라 한다.
const first = 'Ung-mo';
const last = 'Lee';
// ES5: 문자열 연결
console.log('My name is ' + first + ' ' + last + '.');
// "My name is Ung-mo Lee."
// ES6: String Interpolation
console.log(`My name is ${first} ${last}.`);
// "My name is Ung-mo Lee."
문자열 인터폴레이션은 ${ … }으로 표현식을 감싼다. 문자열 인터폴레이션 내의 표현식은 문자열로 강제 타입 변환된다.
console.log(`1 + 1 = ${1 + 1}`); // "1 + 1 = 2"ㅤㅤ
📍 Arrow function : 화살표 함수
1. 화살표 함수의 선언
화살표 함수(Arrow function)는 function 키워드 대신 화살표(=>)를 사용하여 보다 간략한 방법으로 함수를 선언할 수 있다. 하지만 모든 경우 화살표 함수를 사용할 수 있는 것은 아니다. 화살표 함수의 기본 문법은 아래와 같다.
// 매개변수 지정 방법
() => { ... } // 매개변수가 없을 경우
x => { ... } // 매개변수가 한 개인 경우, 소괄호를 생략할 수 있다.
(x, y) => { ... } // 매개변수가 여러 개인 경우, 소괄호를 생략할 수 없다.
// 함수 몸체 지정 방법
x => { return x * x } // single line block
x => x * x // 함수 몸체가 한줄의 구문이라면 중괄호를 생략할 수 있으며 암묵적으로 return된다. 위 표현과 동일하다.
() => { return { a: 1 }; }
() => ({ a: 1 }) // 위 표현과 동일하다. 객체 반환시 소괄호를 사용한다.
() => { // multi line block.
const x = 10;
return x * x;
};
#2. 화살표 함수의 호출
화살표 함수는 익명 함수로만 사용할 수 있다. 따라서 화살표 함수를 호출하기 위해서는 함수 표현식을 사용한다.
// ES5
var pow = function (x) { return x * x; };
console.log(pow(10)); // 100
// ES6
const pow = x => x * x;
console.log(pow(10)); // 100
또는 콜백 함수로 사용할 수 있다. 이 경우 일반적인 함수 표현식보다 표현이 간결하다.
// ES5
var arr = [1, 2, 3];
var pow = arr.map(function (x) { // x는 요소값
return x * x;
});
console.log(pow); // [ 1, 4, 9 ]
// ES6
const arr = [1, 2, 3];
const pow = arr.map(x => x * x);
console.log(pow); // [ 1, 4, 9 ]
#3. this
function 키워드로 생성한 일반 함수와 화살표 함수의 가장 큰 차이점은 this이다.
#3.1 일반 함수의 this
자바스크립트의 경우 함수 호출 방식에 의해 [this]에 바인딩할 어떤 객체가 동적으로 결정된다. 다시 말해, 함수를 선언할 때 this에 바인딩할 객체가 정적으로 결정되는 것이 아니고, 함수를 호출할 때 함수가 어떻게 호출되었는지에 따라 this에 바인딩할 객체가 동적으로 결정된다.
콜백 함수 내부의 this는 전역 객체 window를 가리킨다.
function Prefixer(prefix) {
this.prefix = prefix;
}
Prefixer.prototype.prefixArray = function (arr) {
// (A)
return arr.map(function (x) {
return this.prefix + ' ' + x; // (B)
});
};
var pre = new Prefixer('Hi');
console.log(pre.prefixArray(['Lee', 'Kim']));
(A) 지점에서의 this는 생성자 함수 Prefixer가 생성한 객체, 즉 생성자 함수의 인스턴스(위 예제의 경우 pre)이다.
(B) 지점에서 사용한 this는 아마도 생성자 함수 Prefixer가 생성한 객체(위 예제의 경우 pre)일 것으로 기대하였겠지만, 이곳에서 this는 전역 객체 window를 가리킨다. 이는 생성자 함수와 객체의 메소드를 제외한 모든 함수(내부 함수, 콜백 함수 포함) 내부의 this는 전역 객체를 가리키기 때문이다.
콜백 함수 내부의 this가 메소드를 호출한 객체(생성자 함수의 인스턴스)를 가리키게 하려면 아래의 3가지 방법이 있다.
// Solution 1: that = this
function Prefixer(prefix) {
this.prefix = prefix;
}
Prefixer.prototype.prefixArray = function (arr) {
var that = this; // this: Prefixer 생성자 함수의 인스턴스
return arr.map(function (x) {
return that.prefix + ' ' + x;
});
};
var pre = new Prefixer('Hi');
console.log(pre.prefixArray(['Lee', 'Kim']));
// Solution 2: map(func, this)
function Prefixer(prefix) {
this.prefix = prefix;
}
Prefixer.prototype.prefixArray = function (arr) {
return arr.map(function (x) {
return this.prefix + ' ' + x;
}, this); // this: Prefixer 생성자 함수의 인스턴스
};
var pre = new Prefixer('Hi');
console.log(pre.prefixArray(['Lee', 'Kim']));
ES5에 추가된 Function.prototype.bind()로 this를 바인딩한다.
// Solution 3: bind(this)
function Prefixer(prefix) {
this.prefix = prefix;
}
Prefixer.prototype.prefixArray = function (arr) {
return arr.map(function (x) {
return this.prefix + ' ' + x;
}.bind(this)); // this: Prefixer 생성자 함수의 인스턴스
};
var pre = new Prefixer('Hi');
console.log(pre.prefixArray(['Lee', 'Kim']));
#3.2 화살표 함수의 this
일반 함수는 함수를 선언할 때 this에 바인딩할 객체가 정적으로 결정되는 것이 아니고, 함수를 호출할 때 함수가 어떻게 호출되었는지에 따라 this에 바인딩할 객체가 동적으로 결정된다고 하였다.
화살표 함수는 함수를 선언할 때 this에 바인딩할 객체가 정적으로 결정된다. 동적으로 결정되는 일반 함수와는 달리 화살표 함수의 this 언제나 상위 스코프의 this를 가리킨다. 이를 Lexical this라 한다. 화살표 함수는 앞서 살펴본 Solution 3의 Syntactic sugar이다.
화살표 함수의 this 바인딩 객체 결정 방식은 함수의 상위 스코프를 결정하는 방식인 [렉시컬 스코프]와 유사하다.
function Prefixer(prefix) {
this.prefix = prefix;
}
Prefixer.prototype.prefixArray = function (arr) {
// this는 상위 스코프인 prefixArray 메소드 내의 this를 가리킨다.
return arr.map(x => `${this.prefix} ${x}`);
};
const pre = new Prefixer('Hi');
console.log(pre.prefixArray(['Lee', 'Kim']));
화살표 함수는 call, apply, bind 메소드를 사용하여 this를 변경할 수 없다.
window.x = 1;
const normal = function () { return this.x; };
const arrow = () => this.x;
console.log(normal.call({ x: 10 })); // 10
console.log(arrow.call({ x: 10 })); // 1
#4. 화살표 함수를 사용해서는 안되는 경우
화살표 함수는 Lexical this를 지원하므로 콜백 함수로 사용하기 편리하다. 하지만 화살표 함수를 사용하는 것이 오히려 혼란을 불러오는 경우도 있으므로 주의하여야 한다.
#4.1 메소드
화살표 함수로 메소드를 정의하는 것은 피해야 한다.
// Bad
const person = {
name: 'Lee',
sayHi: () => console.log(`Hi ${this.name}`)
};
person.sayHi(); // Hi undefined
위 예제의 경우, 메소드로 정의한 화살표 함수 내부의 this는 메소드를 소유한 객체, 즉 메소드를 호출한 객체를 가리키지 않고 상위 컨택스트인 전역 객체 window를 가리킨다. 따라서 화살표 함수로 메소드를 정의하는 것은 바람직하지 않다.
이와 같은 경우는 메소드를 위한 단축 표기법인 [ES6의 축약 메소드 표현]을 사용하는 것이 좋다.
// Good
const person = {
name: 'Lee',
sayHi() { // === sayHi: function() {
console.log(`Hi ${this.name}`);
}
};
person.sayHi(); // Hi Lee
#4.2 prototype
화살표 함수로 정의된 메소드를 prototype에 할당하는 경우도 동일한 문제가 발생한다. 화살표 함수로 정의된 메소드를 prototype에 할당하여 보자.
// Bad
const person = {
name: 'Lee',
};
Object.prototype.sayHi = () => console.log(`Hi ${this.name}`);
person.sayHi(); // Hi undefined
화살표 함수로 객체의 메소드를 정의하였을 때와 같은 문제가 발생한다. 따라서 prototype에 메소드를 할당하는 경우, 일반 함수를 할당한다.
// Good
const person = {
name: 'Lee',
};
Object.prototype.sayHi = function() {
console.log(`Hi ${this.name}`);
};
person.sayHi(); // Hi Lee
#4.3 생성자 함수
화살표 함수는 생성자 함수로 사용할 수 없다. 생성자 함수는 prototype 프로퍼티를 가지며 prototype 프로퍼티가 가리키는 프로토타입 객체의 constructor를 사용한다. 하지만 화살표 함수는 prototype 프로퍼티를 가지고 있지 않다.
const Foo = () => {};
// 화살표 함수는 prototype 프로퍼티가 없다
console.log(Foo.hasOwnProperty('prototype')); // false
const foo = new Foo(); // TypeError: Foo is not a constructor
#4.4 addEventListener 함수의 콜백 함수
addEventListener 함수의 콜백 함수를 화살표 함수로 정의하면 this가 상위 컨택스트인 전역 객체 window를 가리킨다.
// Bad
var button = document.getElementById('myButton');
button.addEventListener('click', () => {
console.log(this === window); // => true
this.innerHTML = 'Clicked button';
});
따라서 addEventListener 함수의 콜백 함수 내에서 this를 사용하는 경우, function 키워드로 정의한 일반 함수를 사용하여야 한다. 일반 함수로 정의된 addEventListener 함수의 콜백 함수 내부의 [this]는 이벤트 리스너에 바인딩된 요소(currentTarget)를 가리킨다.
// Good
var button = document.getElementById('myButton');
button.addEventListener('click', function() {
console.log(this === button); // => true
this.innerHTML = 'Clicked button';
});ㅤㅤ
📍 Extended Parameter Handling : 매개변수 기본값, Rest 파라미터, Spread 문법, Rest/Spread 프로퍼티
1. 매개변수 기본값 (Default Parameter value)
함수를 호출할 때 매개변수의 개수만큼 인수를 전달하는 것이 일반적이지만 그렇지 않은 경우에도 에러가 발생하지는 않는다. 함수는 매개변수의 개수와 인수의 개수를 체크하지 않는다. 인수가 부족한 경우, 매개변수의 값은 undefined이다.
function sum(x, y) {
return x + y;
}
console.log(sum(1)); // NaN
따라서 매개변수에 적절한 인수가 전달되었는지 함수 내부에서 확인할 필요가 있다.
function sum(x, y) {
// 매개변수의 값이 falsy value인 경우, 기본값을 할당한다.
x = x || 0;
y = y || 0;
return x + y;
}
console.log(sum(1)); // 1
console.log(sum(1, 2)); // 3
ES6에서는 매개변수 기본값을 사용하여 함수 내에서 수행하던 인수 체크 및 초기화를 간소화할 수 있다. 매개변수 기본값은 매개변수에 인수를 전달하지 않았을 경우에만 유효하다.
function sum(x = 0, y = 0) {
return x + y;
}
console.log(sum(1)); // 1
console.log(sum(1, 2)); // 3
매개변수 기본값은 함수 정의 시 선언한 매개변수 개수를 나타내는 함수 객체의 length 프로퍼티와 arguments 객체에 영향을 주지 않는다.
function foo(x, y = 0) {
console.log(arguments);
}
console.log(foo.length); // 1
sum(1); // Arguments { '0': 1 }
sum(1, 2); // Arguments { '0': 1, '1': 2 }
#2. Rest 파라미터
#2.1 기본 문법
Rest 파라미터(Rest Parameter, 나머지 매개변수)는 매개변수 이름 앞에 세개의 점 ...을 붙여서 정의한 매개변수를 의미한다. Rest 파라미터는 함수에 전달된 인수들의 목록을 배열로 전달받는다.
function foo(...rest) {
console.log(Array.isArray(rest)); // true
console.log(rest); // [ 1, 2, 3, 4, 5 ]
}
foo(1, 2, 3, 4, 5);
함수에 전달된 인수들은 순차적으로 파라미터와 Rest 파라미터에 할당된다.
function foo(param, ...rest) {
console.log(param); // 1
console.log(rest); // [ 2, 3, 4, 5 ]
}
foo(1, 2, 3, 4, 5);
function bar(param1, param2, ...rest) {
console.log(param1); // 1
console.log(param2); // 2
console.log(rest); // [ 3, 4, 5 ]
}
bar(1, 2, 3, 4, 5);
Rest 파라미터는 이름 그대로 먼저 선언된 파라미터에 할당된 인수를 제외한 나머지 인수들이 모두 배열에 담겨 할당된다. 따라서 Rest 파라미터는 반드시 마지막 파라미터이어야 한다.
function foo( ...rest, param1, param2) { }
foo(1, 2, 3, 4, 5);
// SyntaxError: Rest parameter must be last formal parameter
Rest 파라미터는 함수 정의 시 선언한 매개변수 개수를 나타내는 함수 객체의 length 프로퍼티에 영향을 주지 않는다.
function foo(...rest) {}
console.log(foo.length); // 0
function bar(x, ...rest) {}
console.log(bar.length); // 1
function baz(x, y, ...rest) {}
console.log(baz.length); // 2
#2.2 arguments와 rest 파라미터
ES5에서는 인자의 개수를 사전에 알 수 없는 가변 인자 함수의 경우, [arguments 객체]를 통해 인수를 확인한다. arguments 객체는 함수 호출 시 전달된 인수(argument)들의 정보를 담고 있는 순회가능한(iterable) 유사 배열 객체(array-like object)이며 함수 내부에서 지역 변수처럼 사용할 수 있다.
arguments 프로퍼티는 현재 일부 브라우저에서 지원하고 있지만 ES3부터 표준에서 deprecated 되었다. Function.arguments와 같은 사용 방법은 권장되지 않으며 함수 내부에서 지역변수처럼 사용할 수 있는 arguments 객체를 참조하도록 한다.
// ES5
var foo = function () {
console.log(arguments);
};
foo(1, 2); // { '0': 1, '1': 2 }
가변 인자 함수는 파라미터를 통해 인수를 전달받는 것이 불가능하므로 arguments 객체를 활용하여 인수를 전달받는다. 하지만 arguments 객체는 유사 배열 객체이므로 배열 메소드를 사용하려면 Function.prototype.call을 사용해야 하는 번거로움이 있다.
// ES5
function sum() {
/*
가변 인자 함수는 arguments 객체를 통해 인수를 전달받는다.
유사 배열 객체인 arguments 객체를 배열로 변환한다.
*/
var array = Array.prototype.slice.call(arguments);
return array.reduce(function (pre, cur) {
return pre + cur;
});
}
console.log(sum(1, 2, 3, 4, 5)); // 15
ES6에서는 [rest 파라미터]를 사용하여 가변 인자의 목록을 배열로 전달받을 수 있다. 이를 통해 유사 배열인 arguments 객체를 배열로 변환하는 번거로움을 피할 수 있다.
// ES6
function sum(...args) {
console.log(arguments); // Arguments(5) [1, 2, 3, 4, 5, callee: (...), Symbol(Symbol.iterator): ƒ]
console.log(Array.isArray(args)); // true
return args.reduce((pre, cur) => pre + cur);
}
console.log(sum(1, 2, 3, 4, 5)); // 15
하지만 ES6의 [화살표 함수]에는 함수 객체의 arguments 프로퍼티가 없다. 따라서 화살표 함수로 가변 인자 함수를 구현해야 할 때는 반드시 rest 파라미터를 사용해야 한다.
var normalFunc = function () {};
console.log(normalFunc.hasOwnProperty('arguments')); // true
const arrowFunc = () => {};
console.log(arrowFunc.hasOwnProperty('arguments')); // false
#3. Spread 문법
Spread 문법(Spread Syntax, ...)는 대상을 개별 요소로 분리한다. Spread 문법의 대상은 [이터러블]이어야 한다.
// ...[1, 2, 3]는 [1, 2, 3]을 개별 요소로 분리한다(→ 1, 2, 3)
console.log(...[1, 2, 3]) // 1, 2, 3
// 문자열은 이터러블이다.
console.log(...'Hello'); // H e l l o
// Map과 Set은 이터러블이다.
console.log(...new Map([['a', '1'], ['b', '2']])); // [ 'a', '1' ] [ 'b', '2' ]
console.log(...new Set([1, 2, 3])); // 1 2 3
// 이터러블이 아닌 일반 객체는 Spread 문법의 대상이 될 수 없다.
console.log(...{ a: 1, b: 2 });
// TypeError: Found non-callable @@iterator
#3.1 함수의 인수로 사용하는 경우
배열을 분해하여 배열의 각 요소를 파라미터에 전달하고 싶은 경우, Function.prototype.apply를 사용하는 것이 일반적이다.
// ES5
function foo(x, y, z) {
console.log(x); // 1
console.log(y); // 2
console.log(z); // 3
}
// 배열을 분해하여 배열의 각 요소를 파라미터에 전달하려고 한다.
const arr = [1, 2, 3];
// apply 함수의 2번째 인수(배열)는 분해되어 함수 foo의 파라이터에 전달된다.
foo.apply(null, arr);
// foo.call(null, 1, 2, 3);
ES6의 Spread 문법(…)을 사용한 배열을 인수로 함수에 전달하면 배열의 요소를 분해하여 순차적으로 파라미터에 할당한다.
// ES6
function foo(x, y, z) {
console.log(x); // 1
console.log(y); // 2
console.log(z); // 3
}
// 배열을 foo 함수의 인자로 전달하려고 한다.
const arr = [1, 2, 3];
/* ...[1, 2, 3]는 [1, 2, 3]을 개별 요소로 분리한다(→ 1, 2, 3)
spread 문법에 의해 분리된 배열의 요소는 개별적인 인자로서 각각의 매개변수에 전달된다. */
foo(...arr);
앞에서 살펴본 Rest 파라미터는 Spread 문법을 사용하여 파라미터를 정의한 것을 의미한다. 형태가 동일하여 혼동할 수 있으므로 주의가 필요하다.
/* Spread 문법을 사용한 매개변수 정의 (= Rest 파라미터)
...rest는 분리된 요소들을 함수 내부에 배열로 전달한다. */
function foo(param, ...rest) {
console.log(param); // 1
console.log(rest); // [ 2, 3 ]
}
foo(1, 2, 3);
/* Spread 문법을 사용한 인수
배열 인수는 분리되어 순차적으로 매개변수에 할당 */
function bar(x, y, z) {
console.log(x); // 1
console.log(y); // 2
console.log(z); // 3
}
// ...[1, 2, 3]는 [1, 2, 3]을 개별 요소로 분리한다(-> 1, 2, 3)
// spread 문법에 의해 분리된 배열의 요소는 개별적인 인자로서 각각의 매개변수에 전달된다.
bar(...[1, 2, 3]);
Rest 파라미터는 반드시 마지막 파라미터이어야 하지만 Spread 문법을 사용한 인수는 자유롭게 사용할 수 있다.
// ES6
function foo(v, w, x, y, z) {
console.log(v); // 1
console.log(w); // 2
console.log(x); // 3
console.log(y); // 4
console.log(z); // 5
}
// ...[2, 3]는 [2, 3]을 개별 요소로 분리한다(→ 2, 3)
// spread 문법에 의해 분리된 배열의 요소는 개별적인 인자로서 각각의 매개변수에 전달된다.
foo(1, ...[2, 3], 4, ...[5]);
#3.2 배열에서 사용하는 경우
Spread 문법을 배열에서 사용하면 보다 간결하고 가독성 좋게 표현할 수 있다.
#3.2.1 concat
ES5에서 기존 배열의 요소를 새로운 배열 요소의 일부로 만들고 싶은 경우, 배열 리터럴 만으로 해결할 수 없고 [concat 메소드]를 사용해야 한다.
// ES5
var arr = [1, 2, 3];
console.log(arr.concat([4, 5, 6])); // [ 1, 2, 3, 4, 5, 6 ]
Spread 문법을 사용하면 배열 리터럴 만으로 기존 배열의 요소를 새로운 배열 요소의 일부로 만들 수 있다.
// ES6
const arr = [1, 2, 3];
// ...arr은 [1, 2, 3]을 개별 요소로 분리한다
console.log([...arr, 4, 5, 6]); // [ 1, 2, 3, 4, 5, 6 ]
#3.2.2 push
ES5에서 기존 배열에 다른 배열의 개별 요소를 각각 push하려면 아래와 같은 방법을 사용한다.
// ES5
var arr1 = [1, 2, 3];
var arr2 = [4, 5, 6];
// apply 메소드의 2번째 인자는 배열. 이것은 개별 인자로 push 메소드에 전달된다.
Array.prototype.push.apply(arr1, arr2);
console.log(arr1); // [ 1, 2, 3, 4, 5, 6 ]
Spread 문법을 사용하면 아래와 같이 보다 간편하게 표현할 수 있다.
// ES6
const arr1 = [1, 2, 3];
const arr2 = [4, 5, 6];
// ...arr2는 [4, 5, 6]을 개별 요소로 분리한다
arr1.push(...arr2); // == arr1.push(4, 5, 6);
console.log(arr1); // [ 1, 2, 3, 4, 5, 6 ]
#3.2.3 splice
ES5에서 기존 배열에 다른 배열의 개별 요소를 삽입하려면 아래와 같은 방법을 사용한다.
// ES5
var arr1 = [1, 2, 3, 6];
var arr2 = [4, 5];
/*
apply 메소드의 2번째 인자는 배열. 이것은 개별 인자로 splice 메소드에 전달된다.
[3, 0].concat(arr2) → [3, 0, 4, 5]
arr1.splice(3, 0, 4, 5) → arr1[3]부터 0개의 요소를 제거하고 그자리(arr1[3])에 새로운 요소(4, 5)를 추가한다.
*/
Array.prototype.splice.apply(arr1, [3, 0].concat(arr2));
console.log(arr1); // [ 1, 2, 3, 4, 5, 6 ]
Spread 문법을 사용하면 아래와 같이 보다 간편하게 표현할 수 있다.
// ES6
const arr1 = [1, 2, 3, 6];
const arr2 = [4, 5];
// ...arr2는 [4, 5]을 개별 요소로 분리한다
arr1.splice(3, 0, ...arr2); // == arr1.splice(3, 0, 4, 5);
console.log(arr1); // [ 1, 2, 3, 4, 5, 6 ]
#3.2.4 copy
ES5에서 기존 배열을 복사하기 위해서는 slice 메소드를 사용한다.
// ES5
var arr = [1, 2, 3];
var copy = arr.slice();
console.log(copy); // [ 1, 2, 3 ]
// copy를 변경한다.
copy.push(4);
console.log(copy); // [ 1, 2, 3, 4 ]
// arr은 변경되지 않는다.
console.log(arr); // [ 1, 2, 3 ]
Spread 문법을 사용하면 보다 간편하게 배열을 복사할 수 있다.
// ES6
const arr = [1, 2, 3];
// ...arr은 [1, 2, 3]을 개별 요소로 분리한다
const copy = [...arr];
console.log(copy); // [ 1, 2, 3 ]
// copy를 변경한다.
copy.push(4);
console.log(copy); // [ 1, 2, 3, 4 ]
// arr은 변경되지 않는다.
console.log(arr); // [ 1, 2, 3 ]
이때 원본 배열의 각 요소를 얕은 복사(shallow copy)하여 새로운 복사본을 생성한다. 이는 Array#slice 메소드도 마찬가지다.
const todos = [
{ id: 1, content: 'HTML', completed: false },
{ id: 2, content: 'CSS', completed: true },
{ id: 3, content: 'Javascript', completed: false }
];
// shallow copy
// const _todos = todos.slice();
const _todos = [...todos];
console.log(_todos === todos); // false
// 배열의 요소는 같다. 즉, 얕은 복사되었다.
console.log(_todos[0] === todos[0]); // true
Spread 문법과 Object.assign는 원본을 shallow copy한다. Deep copy를 위해서는 lodash의 deepClone을 사용하는 것을 추천한다.
Spread 문법을 사용하면 유사 배열 객체(Array-like Object)를 배열로 손쉽게 변환할 수 있다.
const htmlCollection = document.getElementsByTagName('li');
// 유사 배열인 HTMLCollection을 배열로 변환한다.
const newArray = [...htmlCollection]; // Spread 문법
// ES6의 Array.from 메소드를 사용할 수도 있다.
// const newArray = Array.from(htmlCollection);
#4. Rest/Spread 프로퍼티
ECMAScript 언어 표준에 제안(proposal)된 Rest/Spread 프로퍼티(Object Rest/Spread Properties)는 객체 리터럴을 분해하고 병합하는 편리한 기능을 제공한다.
- 2019년 5월 현재 Rest/Spread 프로퍼티는 TC39 프로세스의 stage 4(Finished) 단계이다.
- stage 4에 도달한 제안은 finished-proposals를 참고하면 된다.
- 지원 현황
- 2019년 1월 현재 객체 리터럴 Rest/Spread 프로퍼티를 Babel로 트랜스파일링하려면 @babel/plugin-proposal-object-rest-spread 플러그인을 사용해야 한다.
// 객체 리터럴 Rest/Spread 프로퍼티
// Spread 프로퍼티
const n = { x: 1, y: 2, ...{ a: 3, b: 4 } };
console.log(n); // { x: 1, y: 2, a: 3, b: 4 }
// Rest 프로퍼티
const { x, y, ...z } = n;
console.log(x, y, z); // 1 2 { a: 3, b: 4 }
Spread 문법의 대상은 이터러블이어야 한다. Rest/Spread 프로퍼티는 일반 객체에 Spread 문법의 사용을 허용한다.
Rest/Spread 프로퍼티를 사용하면 객체를 손쉽게 병합 또는 변경할 수 있다. 이는 Object.assign을 대체할 수 있는 간편한 문법이다.
// 객체의 병합
const merged = { ...{ x: 1, y: 2 }, ...{ y: 10, z: 3 } };
console.log(merged); // { x: 1, y: 10, z: 3 }
// 특정 프로퍼티 변경
const changed = { ...{ x: 1, y: 2 }, y: 100 };
// changed = { ...{ x: 1, y: 2 }, ...{ y: 100 } }
console.log(changed); // { x: 1, y: 100 }
// 프로퍼티 추가
const added = { ...{ x: 1, y: 2 }, z: 0 };
// added = { ...{ x: 1, y: 2 }, ...{ z: 0 } }
console.log(added); // { x: 1, y: 2, z: 0 }
Object.assign 메소드를 사용해도 동일한 작업을 할 수 있다.
// 객체의 병합
const merged = Object.assign({}, { x: 1, y: 2 }, { y: 10, z: 3 });
console.log(merged); // { x: 1, y: 10, z: 3 }
// 특정 프로퍼티 변경
const changed = Object.assign({}, { x: 1, y: 2 }, { y: 100 });
console.log(changed); // { x: 1, y: 100 }
// 프로퍼티 추가
const added = Object.assign({}, { x: 1, y: 2 }, { z: 0 });
console.log(added); // { x: 1, y: 2, z: 0 }ㅤㅤ
📍 Enhanced Object property : 객체 리터럴 프로퍼티 기능 확장
1. 프로퍼티 축약 표현
ES5에서 객체 리터럴의 프로퍼티는 프로퍼티 이름과 프로퍼티 값으로 구성된다. 프로퍼티의 값은 변수에 할당된 값일 수도 있다.
// ES5
var x = 1, y = 2;
var obj = {
x: x,
y: y
};
console.log(obj); // { x: 1, y: 2 }
ES6에서는 프로퍼티 값으로 변수를 사용하는 경우, 프로퍼티 이름을 생략(Property shorthand)할 수 있다. 이때 프로퍼티 이름은 변수의 이름으로 자동 생성된다.
// ES6
let x = 1, y = 2;
const obj = { x, y };
console.log(obj); // { x: 1, y: 2 }
#2. 프로퍼티 키 동적 생성
문자열 또는 문자열로 변환 가능한 값을 반환하는 표현식을 사용해 프로퍼티 키를 동적으로 생성할 수 있다. 단, 프로퍼티 키로 사용할 표현식을 대괄호([…])로 묶어야 한다. 이를 계산된 프로퍼티 이름(Computed property name)이라 한다.
ES5에서 프로퍼티 키를 동적으로 생성하려면 객체 리터럴 외부에서 대괄호([…]) 표기법을 사용해야 한다.
// ES5
var prefix = 'prop';
var i = 0;
var obj = {};
obj[prefix + '-' + ++i] = i;
obj[prefix + '-' + ++i] = i;
obj[prefix + '-' + ++i] = i;
console.log(obj); // {prop-1: 1, prop-2: 2, prop-3: 3}
ES6에서는 객체 리터럴 내부에서도 프로퍼티 키를 동적으로 생성할 수 있다.
// ES6
const prefix = 'prop';
let i = 0;
const obj = {
[`${prefix}-${++i}`]: i,
[`${prefix}-${++i}`]: i,
[`${prefix}-${++i}`]: i
};
console.log(obj); // {prop-1: 1, prop-2: 2, prop-3: 3}
#3. 메소드 축약 표현
ES5에서 메소드를 선언하려면 프로퍼티 값으로 함수 선언식을 할당한다.
// ES5
var obj = {
name: 'Lee',
sayHi: function() {
console.log('Hi! ' + this.name);
}
};
obj.sayHi(); // Hi! Lee
ES6에서는 메소드를 선언할 때, function 키워드를 생략한 축약 표현을 사용할 수 있다.
// ES6
const obj = {
name: 'Lee',
// 메소드 축약 표현
sayHi() {
console.log('Hi! ' + this.name);
}
};
obj.sayHi(); // Hi! Lee
#4. proto 프로퍼티에 의한 상속
ES5에서 객체 리터럴을 상속하기 위해서는 Object.create() 함수를 사용한다. 이를 [프로토타입 패턴 상속]이라 한다.
// ES5
var parent = {
name: 'parent',
sayHi: function() {
console.log('Hi! ' + this.name);
}
};
// 프로토타입 패턴 상속
var child = Object.create(parent);
child.name = 'child';
parent.sayHi(); // Hi! parent
child.sayHi(); // Hi! child
ES6에서는 객체 리터럴 내부에서 [proto] 프로퍼티를 직접 설정할 수 있다. 이것은 객체 리터럴에 의해 생성된 객체의 proto 프로퍼티에 다른 객체를 직접 바인딩하여 상속을 표현할 수 있음을 의미한다.
// ES6
const parent = {
name: 'parent',
sayHi() {
console.log('Hi! ' + this.name);
}
};
const child = {
// child 객체의 프로토타입 객체에 parent 객체를 바인딩하여 상속을 구현한다.
__proto__: parent,
name: 'child'
};
parent.sayHi(); // Hi! parent
child.sayHi(); // Hi! childㅤㅤ
📍 Destructuring : 디스트럭처링
디스트럭처링(Destructuring)은 구조화된 배열 또는 객체를 Destructuring(비구조화, 파괴)하여 개별적인 변수에 할당하는 것이다. 배열 또는 객체 리터럴에서 필요한 값만을 추출하여 변수에 할당하거나 반환할 때 유용하다.
#1. 배열 디스트럭처링 (Array destructuring)
ES5에서 배열의 각 요소를 배열로부터 디스트럭처링하여 변수에 할당하기 위한 방법은 아래와 같다.
// ES5
var arr = [1, 2, 3];
var one = arr[0];
var two = arr[1];
var three = arr[2];
console.log(one, two, three); // 1 2 3
ES6의 배열 디스트럭처링은 배열의 각 요소를 배열로부터 추출하여 변수 리스트에 할당한다. 이때 추출/할당 기준은 배열의 인덱스이다.
// ES6 Destructuring
const arr = [1, 2, 3];
// 배열의 인덱스를 기준으로 배열로부터 요소를 추출하여 변수에 할당
// 변수 one, two, three가 선언되고 arr(initializer(초기화자))가 Destructuring(비구조화, 파괴)되어 할당된다.
const [one, two, three] = arr;
// 디스트럭처링을 사용할 때는 반드시 initializer(초기화자)를 할당해야 한다.
// const [one, two, three]; // SyntaxError: Missing initializer in destructuring declaration
console.log(one, two, three); // 1 2 3
배열 디스트럭처링을 위해서는 할당 연산자 왼쪽에 배열 형태의 변수 리스트가 필요하다.
let x, y, z;
[x, y, z] = [1, 2, 3];
// 위의 구문과 동치이다.
let [x, y, z] = [1, 2, 3];
왼쪽의 변수 리스트와 오른쪽의 배열은 배열의 인덱스를 기준으로 할당된다.
let x, y, z;
[x, y] = [1, 2];
console.log(x, y); // 1 2
[x, y] = [1];
console.log(x, y); // 1 undefined
[x, y] = [1, 2, 3];
console.log(x, y); // 1 2
[x, , z] = [1, 2, 3];
console.log(x, z); // 1 3
// 기본값
[x, y, z = 3] = [1, 2];
console.log(x, y, z); // 1 2 3
[x, y = 10, z = 3] = [1, 2];
console.log(x, y, z); // 1 2 3
// spread 문법
[x, ...y] = [1, 2, 3];
console.log(x, y); // 1 [ 2, 3 ]
ES6의 배열 디스트럭처링은 배열에서 필요한 요소만 추출하여 변수에 할당하고 싶은 경우에 유용하다. 아래의 코드는 Date 객체에서 년도, 월, 일을 추출하는 예제이다.
const today = new Date(); // Tue May 21 2019 22:19:42 GMT+0900 (한국 표준시)
const formattedDate = today.toISOString().substring(0, 10); // "2019-05-21"
const [year, month, day] = formattedDate.split('-');
console.log([year, month, day]); // [ '2019', '05', '21' ]
#2. 객체 디스트럭처링 (Object destructuring)
ES5에서 객체의 각 프로퍼티를 객체로부터 디스트럭처링하여 변수에 할당하기 위해서는 프로퍼티 이름(키)을 사용해야 한다.
// ES5
var obj = { firstName: 'Ungmo', lastName: 'Lee' };
var firstName = obj.firstName;
var lastName = obj.lastName;
console.log(firstName, lastName); // Ungmo Lee
ES6의 객체 디스트럭처링은 객체의 각 프로퍼티를 객체로부터 추출하여 변수 리스트에 할당한다. 이때 할당 기준은 프로퍼티 이름(키)이다.
// ES6 Destructuring
const obj = { firstName: 'Ungmo', lastName: 'Lee' };
// 프로퍼티 키를 기준으로 디스트럭처링 할당이 이루어진다. 순서는 의미가 없다.
// 변수 lastName, firstName가 선언되고 obj(initializer(초기화자))가 Destructuring(비구조화, 파괴)되어 할당된다.
const { lastName, firstName } = obj;
console.log(firstName, lastName); // Ungmo Lee
객체 디스트럭처링을 위해서는 할당 연산자 왼쪽에 객체 형태의 변수 리스트가 필요하다.
// 프로퍼티 키가 prop1인 프로퍼티의 값을 변수 p1에 할당
// 프로퍼티 키가 prop2인 프로퍼티의 값을 변수 p2에 할당
const { prop1: p1, prop2: p2 } = { prop1: 'a', prop2: 'b' };
console.log(p1, p2); // 'a' 'b'
console.log({ prop1: p1, prop2: p2 }); // { prop1: 'a', prop2: 'b' }
// 아래는 위의 축약형이다
const { prop1, prop2 } = { prop1: 'a', prop2: 'b' };
console.log({ prop1, prop2 }); // { prop1: 'a', prop2: 'b' }
// default value
const { prop1, prop2, prop3 = 'c' } = { prop1: 'a', prop2: 'b' };
console.log({ prop1, prop2, prop3 }); // { prop1: 'a', prop2: 'b', prop3: 'c' }
객체 디스트럭처링은 객체에서 프로퍼티 이름(키)으로 필요한 프로퍼티 값만을 추출할 수 있다.
const todos = [
{ id: 1, content: 'HTML', completed: true },
{ id: 2, content: 'CSS', completed: false },
{ id: 3, content: 'JS', completed: false }
];
// todos 배열의 요소인 객체로부터 completed 프로퍼티만을 추출한다.
const completedTodos = todos.filter(({ completed }) => completed);
console.log(completedTodos); // [ { id: 1, content: 'HTML', completed: true } ]
Array.prototype.filter 메소드의 콜백 함수는 대상 배열(todos)을 순회하며 첫 번째 인자로 대상 배열의 요소를 받는다. 이때 필요한 프로퍼티(completed 프로퍼티)만을 추출할 수 있다.
중첩 객체의 경우는 아래와 같이 사용한다.
const person = {
name: 'Lee',
address: {
zipCode: '03068',
city: 'Seoul'
}
};
const { address: { city } } = person;
console.log(city); // 'Seoul'ㅤㅤ
📍 Class : 클래스
자바스크립트는 프로토타입 기반(prototype-based) 객체지향 언어다. 비록 다른 객체지향 언어들과의 차이점에 대한 논쟁이 있긴 하지만, 자바스크립트는 강력한 객체지향 프로그래밍 능력을 지니고 있다.
프로토타입 기반 프로그래밍은 클래스가 필요없는(class-free) 객체지향 프로그래밍 스타일로 프로토타입 체인과 클로저 등으로 객체 지향 언어의 상속, 캡슐화(정보 은닉) 등의 개념을 구현할 수 있다.
- [Javascript Object-Oriented Programming]
ES5에서는 생성자 함수와 프로토타입, 클로저를 사용하여 객체 지향 프로그래밍을 구현하였다.
// ES5
var Person = (function () {
// Constructor
function Person(name) {
this._name = name;
}
// public method
Person.prototype.sayHi = function () {
console.log('Hi! ' + this._name);
};
// return constructor
return Person;
}());
var me = new Person('Lee');
me.sayHi(); // Hi! Lee.
console.log(me instanceof Person); // true
위 예제를 프로토타입 관점에서 표현해 보면 아래와 같다.
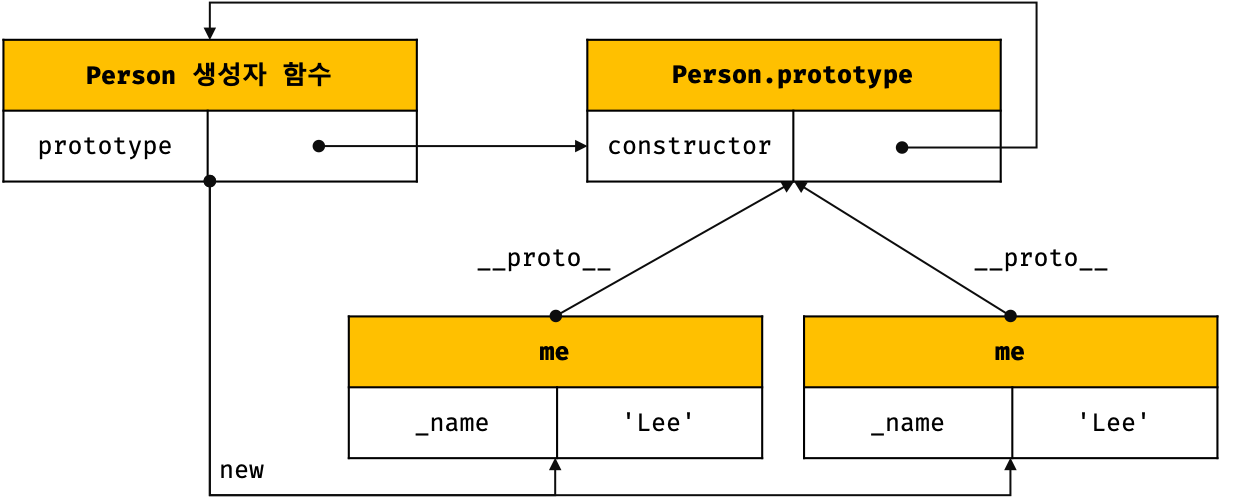
하지만 클래스 기반 언어에 익숙한 프로그래머들은 프로토타입 기반 프로그래밍 방식이 혼란스러울 수 있으며 자바스크립트를 어렵게 느끼게하는 하나의 장벽처럼 인식되었다.
ES6의 클래스는 기존 프로토타입 기반 객체지향 프로그래밍보다 클래스 기반 언어에 익숙한 프로그래머가 보다 빠르게 학습할 수 있는 단순명료한 새로운 문법을 제시하고 있다. 그렇다고 ES6의 클래스가 기존의 프로토타입 기반 객체지향 모델을 폐지하고 새로운 객체지향 모델을 제공하는 것은 아니다. 사실 클래스도 함수이며 기존 프로토타입 기반 패턴의 문법적 설탕(Syntactic sugar)이라고 볼 수 있다. 다만, 클래스와 생성자 함수가 정확히 동일하게 동작하지는 않는다. 클래스가 보다 엄격하다. 따라서 클래스를 프로토타입 기반 패턴의 문법적 설탕이라고 인정하지 않는 견해도 일리가 있다.
#1. 클래스 정의 (Class Definition)
ES6 클래스는 class 키워드를 사용하여 정의한다.
클래스 이름은 성성자 함수와 마찬가지로 파스칼 케이스를 사용하는 것이 일반적이다. 파스칼 케이스를 사용하지 않아도 에러가 발생하지는 않는다.
// 클래스 선언문
class Person {
// constructor(생성자)
constructor(name) {
this._name = name;
}
sayHi() {
console.log(`Hi! ${this._name}`);
}
}
// 인스턴스 생성
const me = new Person('Lee');
me.sayHi(); // Hi! Lee
console.log(me instanceof Person); // true
클래스는 클래스 선언문 이전에 참조할 수 없다.
console.log(Foo);
// ReferenceError: Cannot access 'Foo' before initialization
class Foo {}
하지만 호이스팅이 발생하지 않는 것은 아니다. 클래스는 var 키워드로 선언한 변수처럼 호이스팅되지 않고 let, const 키워드로 선언한 변수처럼 호이스팅된다. 따라서 클래스 선언문 이전에 일시적 사각지대(Temporal Dead Zone; TDZ)에 빠지기 때문에 호이스팅이 발생하지 않는 것처럼 동작한다.
const Foo = '';
{
// 호이스팅이 발생하지 않는다면 ''가 출력되어야 한다.
console.log(Foo);
// ReferenceError: Cannot access 'Foo' before initialization
class Foo {}
}
클래스 선언문도 변수 선언, 함수 정의와 마찬가지로 호이스팅이 발생한다. 호이스팅은 var, let, const, function, function*, class 키워드를 사용한 모든 선언문에 적용된다. 다시 말해, 선언문을 통해 모든 식별자(변수, 함수, 클래스 등)는 호이스팅된다. 모든 선언문은 런타임 이전에 먼저 실행되기 때문이다.
일반적이지는 않지만, 표현식으로도 클래스를 정의할 수 있다. 함수와 마찬가지로 클래스는 이름을 가질 수도 갖지 않을 수도 있다. 이때 클래스가 할당된 변수를 사용해 클래스를 생성하지 않고 기명 클래스의 클래스 이름을 사용해 클래스를 생성하면 에러가 발생한다. 이는 함수와 마찬가지로 클래스 표현식에서 사용한 클래스 이름은 외부 코드에서 접근 불가능하기 때문이다. 자세한 내용은 [함수표현식(Function expression)]을 참조하기 바란다.
// 클래스명 MyClass는 함수 표현식과 동일하게 클래스 몸체 내부에서만 유효한 식별자이다.
const Foo = class MyClass {};
const foo = new Foo();
console.log(foo); // MyClass {}
new MyClass(); // ReferenceError: MyClass is not defined
#2. 인스턴스 생성
마치 생성자 함수와 같이 new 연산자와 함께 클래스 이름을 호출하면 클래스의 인스턴스가 생성된다.
class Foo {}
const foo = new Foo();
위 코드에서 new 연산자와 함께 호출한 Foo는 클래스의 이름이 아니라 constructor(생성자)이다. 표현식이 아닌 선언식으로 정의한 클래스의 이름은 constructor와 동일하다.
// Foo는 사실 생성자 함수(constructor)이다.
console.log(Object.getPrototypeOf(foo).constructor === Foo); // true
new 연산자를 사용하지 않고 constructor를 호출하면 타입 에러(TypeError)가 발생한다. constructor는 new 연산자 없이 호출할 수 없다.
class Foo {}
const foo = Foo(); // TypeError: Class constructor Foo cannot be invoked without 'new'
#3. constructor
constructor는 인스턴스를 생성하고 클래스 필드를 초기화하기 위한 특수한 메소드이다.
클래스 필드(class field)
클래스 내부의 캡슐화된 변수를 말한다. 데이터 멤버 또는 멤버 변수라고도 부른다. 클래스 필드는 인스턴스의 프로퍼티 또는 정적 프로퍼티가 될 수 있다. 쉽게 말해, 자바스크립트의 생성자 함수에서 this에 추가한 프로퍼티를 클래스 기반 객체지향 언어에서는 클래스 필드라고 부른다.
// 클래스 선언문
class Person {
// constructor(생성자). 이름을 바꿀 수 없다.
constructor(name) {
// this는 클래스가 생성할 인스턴스를 가리킨다.
// _name은 클래스 필드이다.
this._name = name;
}
}
// 인스턴스 생성
const me = new Person('Lee');
console.log(me); // Person {_name: "Lee"}
constructor는 클래스 내에 한 개만 존재할 수 있으며 만약 클래스가 2개 이상의 constructor를 포함하면 문법 에러(SyntaxError)가 발생한다. 인스턴스를 생성할 때 new 연산자와 함께 호출한 것이 바로 constructor이며 constructor의 파라미터에 전달한 값은 클래스 필드에 할당한다.
constructor는 생략할 수 있다. constructor를 생략하면 클래스에 constructor() {}를 포함한 것과 동일하게 동작한다. 즉, 빈 객체를 생성한다. 따라서 인스턴스에 프로퍼티를 추가하려면 인스턴스를 생성한 이후, 프로퍼티를 동적으로 추가해야 한다.
class Foo { }
const foo = new Foo();
console.log(foo); // Foo {}
// 프로퍼티 동적 할당 및 초기화
foo.num = 1;
console.log(foo); // Foo { num: 1 }
constructor는 인스턴스의 생성과 동시에 클래스 필드의 생성과 초기화를 실행한다. 따라서 클래스 필드를 초기화해야 한다면 constructor를 생략해서는 안된다.
class Foo {
// constructor는 인스턴스의 생성과 동시에 클래스 필드의 생성과 초기화를 실행한다.
constructor(num) {
this.num = num;
}
}
const foo = new Foo(1);
console.log(foo); // Foo { num: 1 }
#4. 클래스 필드
클래스 몸체(class body)에는 메소드만 선언할 수 있다. 클래스 바디에 클래스 필드(멤버 변수)를 선언하면 문법 에러(SyntaxError)가 발생한다.
class Foo {
name = ''; // SyntaxError
constructor() {}
}
위 예제를 최신 브라우저(Chrome 72 이상) 또는 최신 Node.js(버전 12 이상)에서 실행하면 정상 동작한다. 이는 2019년 5월 현재 TC39 프로세스의 stage 3(candidate) 단계에 있는 클래스 몸체에서 직접 인스턴스 필드를 선언하고 private 인스턴스 필드를 선언할 수 있는 프로포절 Class field declarations proposal의 Field declarations을 최신 브라우저와 최신 Node.js가 구현했기 때문이다.
클래스 필드의 선언과 초기화는 반드시 constructor 내부에서 실시한다.
class Foo {
constructor(name = '') {
this.name = name; // 클래스 필드의 선언과 초기화
}
}
const foo = new Foo('Lee');
console.log(foo); // Foo { name: 'Lee' }
constructor 내부에서 선언한 클래스 필드는 클래스가 생성할 인스턴스를 가리키는 this에 바인딩한다. 이로써 클래스 필드는 클래스가 생성할 인스턴스의 프로퍼티가 되며, 클래스의 인스턴스를 통해 클래스 외부에서 언제나 참조할 수 있다. 즉, 언제나 public이다.
ES6의 클래스는 다른 객체지향 언어처럼 private, public, protected 키워드와 같은 접근 제한자(access modifier)를 지원하지 않는다.
class Foo {
constructor(name = '') {
this.name = name; // public 클래스 필드
}
}
const foo = new Foo('Lee');
console.log(foo.name); // 클래스 외부에서 참조할 수 있다.
#5. Class field declarations proposal
class Foo {
x = 1; // Field declaration
#p = 0; // Private field
static y = 20; // Static public field
static #sp = 30; // Static private field
// 2019/5 : Chrome 미구현
// static #sm() { // Static private method
// console.log('static private method');
// }
bar() {
this.#p = 10; // private 필드 참조
// this.p = 10; // 새로운 public p 필드를 동적 추가한다.
return this.#p;
}
}
const foo = new Foo();
console.log(foo); // Foo {#p: 10, x: 1}
console.log(foo.x); // 1
// console.log(foo.#p); // SyntaxError: Undefined private field #p: must be declared in an enclosing class
console.log(Foo.y); // 20
// console.log(Foo.#sp); // SyntaxError: Undefined private field #sp: must be declared in an enclosing class
console.log(foo.bar()); // 10
위 예제는 최신 브라우저(Chrome 72 이상) 또는 최신 Node.js(버전 12 이상)에서 정상 동작한다
Technical Committee 39(TC39)
Ecma 인터내셔널에는 기술 위원회(Technial Committee)가 여럿 존재한다. 이 중 ECMA-262 명세(ECMAScript)의 관리를 담당하는 위원회가 바로 TC39이다. TC39는 Google, Apple, Microsoft, Mozilla 등 브라우저 벤더와 Facebook, Twitter와 같이 ECMA-262 명세(ECMAScript)를 제대로 준수해야 하는 기업으로 구성되어 있다.
TC39 프로세스
TC39 프로세스는 ECMA-262 명세(ECMAScript)에 새로운 표준 사양(제안. Proposal)을 추가하기 위해 공식적으로 명문화해 놓은 과정을 말한다. TC39 프로세스는 0 단계부터 4 단계까지 총 5개의 단계로 구성되어 있고 상위 단계로 승급하기 위한 명시적인 조건들이 존재한다. 승급 조건을 충족시킨 제안(Proposal)은 TC39의 동의를 통해 다음 단계(Stage)로 승급된다. TC39 프로세스는 아래의 단계를 거쳐 최종적으로 ECMA-262 명세(ECMAScript)의 새로운 표준 사양이 된다.stage 0: strawman => stage 1: proposal => stage 2: draft => stage 3: candidate => stage 4: finishedstage 3 상태의 제안은 심각한 문제가 없는 이상 변경되지 않고 대부분 stage 4로 승급된다. stage 4까지 승급한 제안은 큰 이변이 없는 한 새로운 ECMAScript 버전에 포함된다.
#6. getter, setter
#6.1 getter
getter는 클래스 필드에 접근할 때마다 클래스 필드의 값을 조작하는 행위가 필요할 때 사용한다. getter는 메소드 이름 앞에 get 키워드를 사용해 정의한다. 이때 메소드 이름은 클래스 필드 이름처럼 사용된다. 다시 말해 getter는 호출하는 것이 아니라 프로퍼티처럼 참조하는 형식으로 사용하며 참조 시에 메소드가 호출된다. getter는 이름 그대로 무언가를 취득할 때 사용하므로 반드시 무언가를 반환해야 한다. 사용 방법은 아래와 같다.
class Foo {
constructor(arr = []) {
this._arr = arr;
}
// getter: get 키워드 뒤에 오는 메소드 이름 firstElem은 클래스 필드 이름처럼 사용된다.
get firstElem() {
// getter는 반드시 무언가를 반환해야 한다.
return this._arr.length ? this._arr[0] : null;
}
}
const foo = new Foo([1, 2]);
// 필드 firstElem에 접근하면 getter가 호출된다.
console.log(foo.firstElem); // 1
#6.2 setter
setter는 클래스 필드에 값을 할당할 때마다 클래스 필드의 값을 조작하는 행위가 필요할 때 사용한다. setter는 메소드 이름 앞에 set 키워드를 사용해 정의한다. 이때 메소드 이름은 클래스 필드 이름처럼 사용된다. 다시 말해 setter는 호출하는 것이 아니라 프로퍼티처럼 값을 할당하는 형식으로 사용하며 할당 시에 메소드가 호출된다. 사용 방법은 아래와 같다.
class Foo {
constructor(arr = []) {
this._arr = arr;
}
// getter: get 키워드 뒤에 오는 메소드 이름 firstElem은 클래스 필드 이름처럼 사용된다.
get firstElem() {
// getter는 반드시 무언가를 반환하여야 한다.
return this._arr.length ? this._arr[0] : null;
}
// setter: set 키워드 뒤에 오는 메소드 이름 firstElem은 클래스 필드 이름처럼 사용된다.
set firstElem(elem) {
// ...this._arr은 this._arr를 개별 요소로 분리한다
this._arr = [elem, ...this._arr];
}
}
const foo = new Foo([1, 2]);
// 클래스 필드 lastElem에 값을 할당하면 setter가 호출된다.
foo.firstElem = 100;
console.log(foo.firstElem); // 100
getter와 setter는 클래스에서 새롭게 도입된 기능이 아니다. getter와 setter는 접근자 프로퍼티(accessor property)이다.
// _arr은 데이터 프로퍼티이다.
console.log(Object.getOwnPropertyDescriptor(foo, '_arr'));
// {value: Array(2), writable: true, enumerable: true, configurable: true}
// firstElem은 접근자 프로퍼티이다. 접근자 프로퍼티는 프로토타입의 프로퍼티이다.
console.log(Object.getOwnPropertyDescriptor(Foo.prototype, 'firstElem'));
// {get: ƒ, set: ƒ, enumerable: false, configurable: true}
#7. 정적 메소드
클래스의 정적(static) 메소드를 정의할 때 static 키워드를 사용한다. 정적 메소드는 클래스의 인스턴스가 아닌 클래스 이름으로 호출한다. 따라서 클래스의 인스턴스를 생성하지 않아도 호출할 수 있다.
class Foo {
constructor(prop) {
this.prop = prop;
}
static staticMethod() {
/*
정적 메소드는 this를 사용할 수 없다.
정적 메소드 내부에서 this는 클래스의 인스턴스가 아닌 클래스 자신을 가리킨다.
*/
return 'staticMethod';
}
prototypeMethod() {
return this.prop;
}
}
// 정적 메소드는 클래스 이름으로 호출한다.
console.log(Foo.staticMethod());
const foo = new Foo(123);
// 정적 메소드는 인스턴스로 호출할 수 없다.
console.log(foo.staticMethod()); // Uncaught TypeError: foo.staticMethod is not a function
클래스의 정적 메소드는 인스턴스로 호출할 수 없다. 이것은 정적 메소드는 this를 사용할 수 없다는 것을 의미한다. 일반 메소드 내부에서 this는 클래스의 인스턴스를 가리키며, 메소드 내부에서 this를 사용한다는 것은 클래스의 인스턴스의 생성을 전제로 하는 것이다.
정적 메소드는 클래스 이름으로 호출하기 때문에 클래스의 인스턴스를 생성하지 않아도 사용할 수 있다. 단, 정적 메소드는 this를 사용할 수 없다. 달리 말하면 메소드 내부에서 this를 사용할 필요가 없는 메소드는 정적 메소드로 만들 수 있다. 정적 메소드는 [Math] 객체의 메소드처럼 애플리케이션 전역에서 사용할 유틸리티(utility) 함수를 생성할 때 주로 사용한다.
정적 메소드는 클래스의 인스턴스 생성없이 클래스의 이름으로 호출하며 클래스의 인스턴스로 호출할 수 없다고 하였다.
위에서도 언급했지만 사실 클래스도 함수이고 기존 prototype 기반 패턴의 Syntactic sugar일 뿐이다.
class Foo {}
console.log(typeof Foo); // function
위 예제를 ES5로 표현해보면 아래와 같다. ES5로 표현한 아래의 코드는 ES6의 클래스로 표현한 코드와 정확히 동일하게 동작한다.
var Foo = (function () {
// 생성자 함수
function Foo(prop) {
this.prop = prop;
}
Foo.staticMethod = function () {
return 'staticMethod';
};
Foo.prototype.prototypeMethod = function () {
return this.prop;
};
return Foo;
}());
var foo = new Foo(123);
console.log(foo.prototypeMethod()); // 123
console.log(Foo.staticMethod()); // staticMethod
console.log(foo.staticMethod()); // Uncaught TypeError: foo.staticMethod is not a function
함수 객체(자바스크립트의 함수는 객체이다. 객체로서의 함수를 강조하고자 함수 객체라 표현하였다.)는 prototype 프로퍼티를 갖는데 일반 객체의 과는 다른 것이며 일반 객체는 prototype 프로퍼티를 가지지 않는다.
함수 객체만이 가지고 있는 prototype 프로퍼티는 함수 객체가 생성자로 사용될 때, 이 함수를 통해 생성된 객체의 부모 역할을 하는 프로토타입 객체를 가리킨다. 위 코드에서 Foo는 생성자 함수로 사용되므로 생성자 함수 Foo의 prototype 프로퍼티가 가리키는 프로토타입 객체는 생성자 함수 Foo를 통해 생성되는 인스턴스 foo의 부모 역할을 한다.
console.log(Foo.prototype === foo.__proto__); // true
그리고 생성자 함수 Foo의 prototype 프로퍼티가 가리키는 프로토타입 객체가 가지고 있는 constructor 프로퍼티는 생성자 함수 Foo를 가리킨다.
console.log(Foo.prototype.constructor === Foo); // true
정적 메소드인 staticMethod는 생성자 함수 Foo의 메소드(함수는 객체이므로 메소드를 가질 수 있다.)이고, 일반 메소드인 prototypeMethod는 프로토타입 객체 Foo.prototype의 메소드이다. 따라서 staticMethod는 foo에서 호출할 수 없다.
지금까지 설명한 내용을 프로토타입 체인 관점에서 표현하면 아래와 같다.
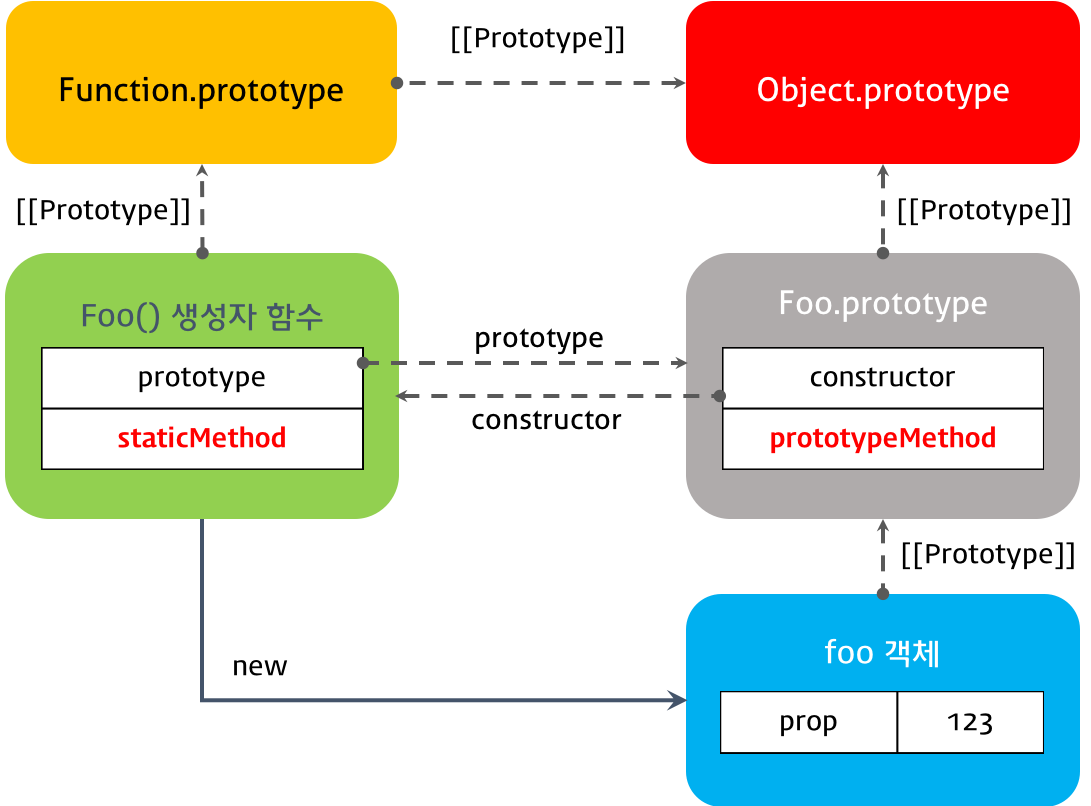
#8. 클래스 상속
클래스 상속(Class Inheritance)은 코드 재사용 관점에서 매우 유용하다. 새롭게 정의할 클래스가 기존에 있는 클래스와 매우 유사하다면, 상속을 통해 그대로 사용하되 다른 점만 구현하면 된다. 코드 재사용은 개발 비용을 현저히 줄일 수 있는 잠재력이 있으므로 매우 중요하다.
#8.1 extends 키워드
extends 키워드는 부모 클래스(base class)를 상속받는 자식 클래스(sub class)를 정의할 때 사용한다.
// 부모 클래스
class Circle {
constructor(radius) {
this.radius = radius; // 반지름
}
// 원의 지름
getDiameter() {
return 2 * this.radius;
}
// 원의 둘레
getPerimeter() {
return 2 * Math.PI * this.radius;
}
// 원의 넓이
getArea() {
return Math.PI * Math.pow(this.radius, 2);
}
}
// 자식 클래스
class Cylinder extends Circle {
constructor(radius, height) {
super(radius);
this.height = height;
}
// 원통의 넓이: 부모 클래스의 getArea 메소드를 오버라이딩하였다.
getArea() {
// (원통의 높이 * 원의 둘레) + (2 * 원의 넓이)
return (this.height * super.getPerimeter()) + (2 * super.getArea());
}
// 원통의 부피
getVolume() {
return super.getArea() * this.height;
}
}
// 반지름이 2, 높이가 10인 원통
const cylinder = new Cylinder(2, 10);
// 원의 지름
console.log(cylinder.getDiameter()); // 4
// 원의 둘레
console.log(cylinder.getPerimeter()); // 12.566370614359172
// 원통의 넓이
console.log(cylinder.getArea()); // 150.79644737231007
// 원통의 부피
console.log(cylinder.getVolume()); // 125.66370614359172
// cylinder는 Cylinder 클래스의 인스턴스이다.
console.log(cylinder instanceof Cylinder); // true
// cylinder는 Circle 클래스의 인스턴스이다.
console.log(cylinder instanceof Circle); // true
오버라이딩(Overriding)
상위 클래스가 가지고 있는 메소드를 하위 클래스가 재정의하여 사용하는 방식이다.
오버로딩(Overloading)
매개변수의 타입 또는 갯수가 다른, 같은 이름의 메소드를 구현하고 매개변수에 의해 메소드를 구별하여 호출하는 방식이다. 자바스크립트는 오버로딩을 지원하지 않지만 arguments 객체를 사용하여 구현할 수는 있다.
위 코드를 프로토타입 관점으로 표현하면 아래와 같다. 인스턴스 cylinder는 [프로토타입 체인]에 의해 부모 클래스 Circle의 메소드를 사용할 수 있다.
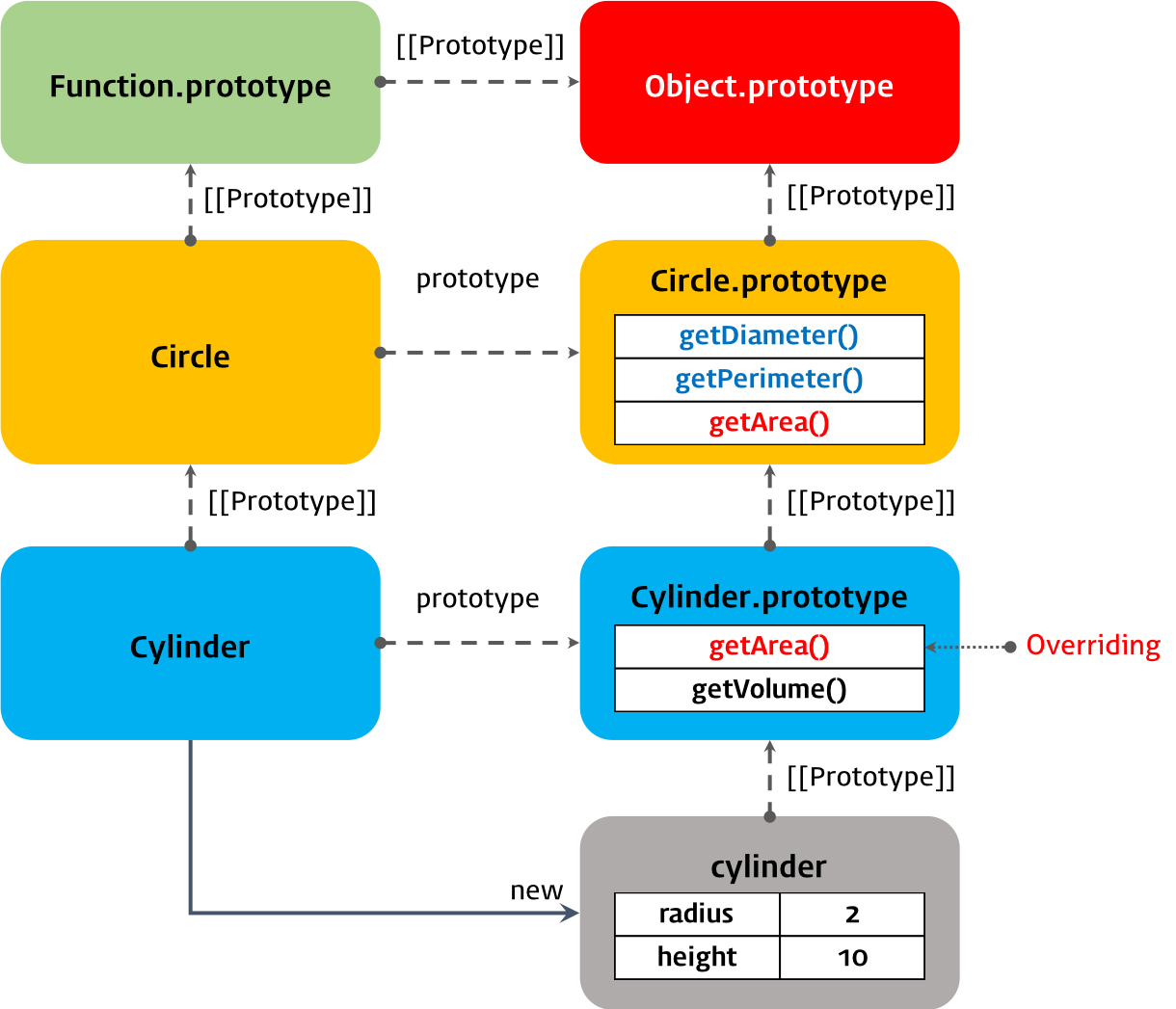
console.log(cylinder.__proto__ === Cylinder.prototype); // true
console.log(Cylinder.prototype.__proto__ === Circle.prototype); // true
console.log(Circle.prototype.__proto__ === Object.prototype); // true
console.log(Object.prototype.__proto__ === null); // true
프로토타입 체인은 특정 객체의 프로퍼티나 메소드에 접근하려고 할 때 프로퍼티 또는 메소드가 없다면 [[Prototype]] 내부 슬롯이 가리키는 링크를 따라 자신의 부모 역할을 하는 프로토타입 객체의 프로퍼티나 메소드를 차례대로 검색한다. 그리고 검색에 성공하면 그 프로퍼티나 메소드를 사용한다.
#8.2 super 키워드
super 키워드는 부모 클래스를 참조(Reference)할 때 또는 부모 클래스의 constructor를 호출할 때 사용한다.
위 “extends 키워드”의 예제를 보면 super가 메소드로 사용될 때, 그리고 객체로 사용될 때 다르게 동작하는 것을 알 수 있다.
// 부모 클래스
class Circle {
...
}
class Cylinder extends Circle {
constructor(radius, height) {
// ① super 메소드는 부모 클래스의 constructor를 호출하면서 인수를 전달한다.
super(radius);
this.height = height;
}
// 원통의 넓이: 부모 클래스의 getArea 메소드를 오버라이딩하였다.
getArea() {
// (원통의 높이 * 원의 둘레) + (2 * 원의 넓이)
// ② super 키워드는 부모 클래스(Base Class)에 대한 참조
return (this.height * super.getPerimeter()) + (2 * super.getArea());
}
// 원통의 부피
getVolume() {
// ② super 키워드는 부모 클래스(Base Class)에 대한 참조
return super.getArea() * this.height;
}
}
// 반지름이 2, 높이가 10인 원통
const cylinder = new Cylinder(2, 10);
① super 메소드는 자식 class의 constructor 내부에서 부모 클래스의 constructor(super-constructor)를 호출한다. 즉, 부모 클래스의 인스턴스를 생성한다. 자식 클래스의 constructor에서 super()를 호출하지 않으면 this에 대한 참조 에러(ReferenceError)가 발생한다.
class Parent {}
class Child extends Parent {
// ReferenceError: Must call super constructor in derived class before accessing 'this' or returning from derived constructor
constructor() {}
}
const child = new Child();
이것은 super 메소드를 호출하기 이전에는 this를 참조할 수 없음을 의미한다.
② super 키워드는 부모 클래스(Base Class)에 대한 참조이다. 부모 클래스의 필드 또는 메소드를 참조하기 위해 사용한다.
#8.3 static 메소드와 prototype 메소드의 상속
프로토타입 관점에서 바라보면 자식 클래스의 [[Prototype]] 내부 슬롯이 가리키는 프로토타입 객체는 부모 클래스이다.
class Parent {}
class Child extends Parent {}
console.log(Child.__proto__ === Parent); // true
console.log(Child.prototype.__proto__ === Parent.prototype); // true
자식 클래스 Child의 프로토타입 객체는 부모 클래스 Parent이다. 이것을 그림으로 표현해보면 아래와 같다.
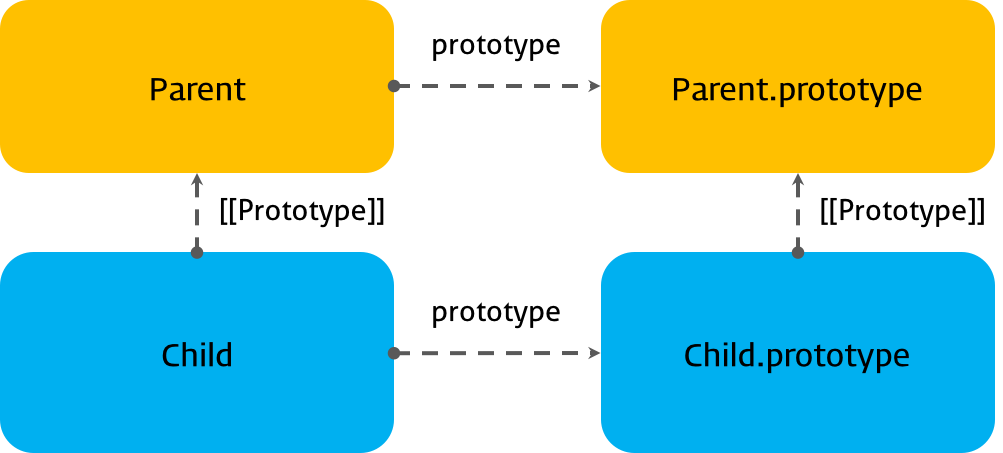
자식 클래스의 프로토타입 객체는 부모 클래스이다
이것은 [Prototype chain]에 의해 부모 클래스의 정적 메소드도 상속됨을 의미한다.
class Parent {
static staticMethod() {
return 'staticMethod';
}
}
class Child extends Parent {}
console.log(Parent.staticMethod()); // 'staticMethod'
console.log(Child.staticMethod()); // 'staticMethod'
자식 클래스의 정적 메소드 내부에서도 super 키워드를 사용하여 부모 클래스의 정적 메소드를 호출할 수 있다. 이는 자식 클래스는 프로토타입 체인에 의해 부모 클래스의 정적 메소드를 참조할 수 있기 때문이다.
하지만 자식 클래스의 일반 메소드(프로토타입 메소드) 내부에서는 super 키워드를 사용하여 부모 클래스의 정적 메소드를 호출할 수 없다. 이는 자식 클래스의 인스턴스는 프로토타입 체인에 의해 부모 클래스의 정적 메소드를 참조할 수 없기 때문이다.
class Parent {
static staticMethod() {
return 'Hello';
}
}
class Child extends Parent {
static staticMethod() {
return `${super.staticMethod()} wolrd`;
}
prototypeMethod() {
return `${super.staticMethod()} wolrd`;
}
}
console.log(Parent.staticMethod()); // 'Hello'
console.log(Child.staticMethod()); // 'Hello wolrd'
console.log(new Child().prototypeMethod());
// TypeError: (intermediate value).staticMethod is not a function
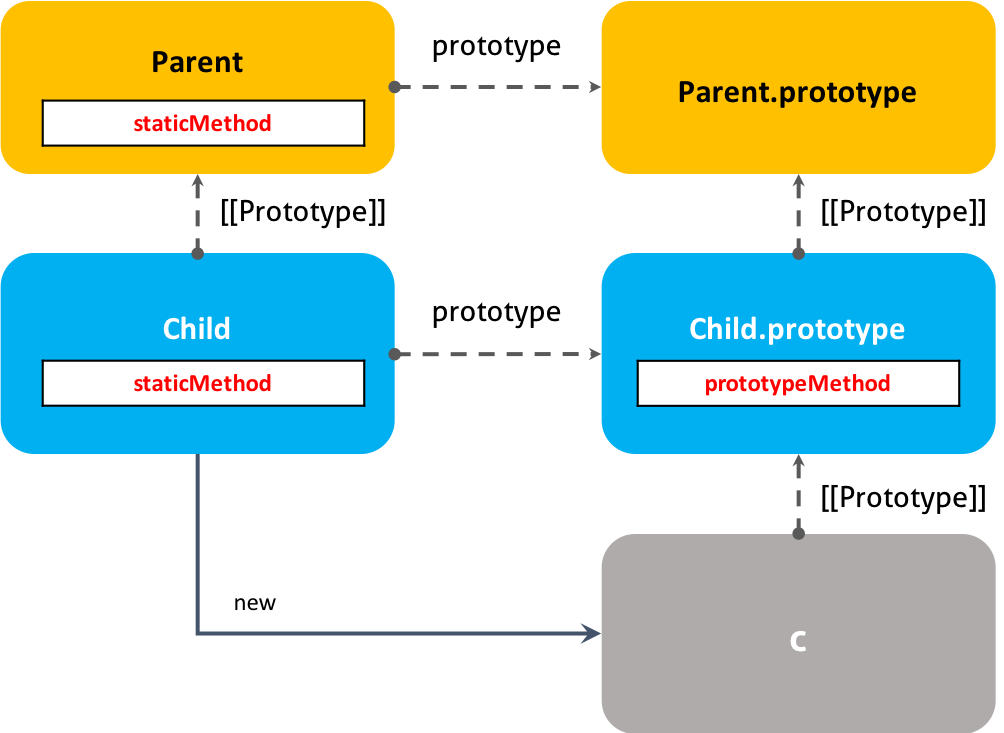
ㅤㅤ
📍 Module : 모듈
모듈이란 애플리케이션을 구성하는 개별적 요소로서 재사용 가능한 코드 조각을 말한다. 모듈은 세부 사항을 캡슐화하고 공개가 필요한 API만을 외부에 노출한다.
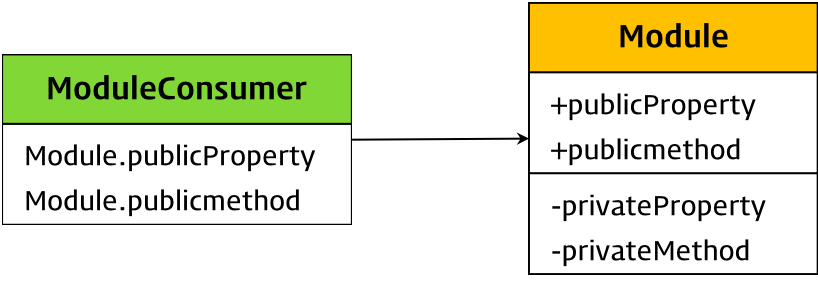
일반적으로 모듈은 파일 단위로 분리되어 있으며 애플리케이션은 필요에 따라 명시적으로 모듈을 로드하여 재사용한다. 즉, 모듈은 애플리케이션에 분리되어 개별적으로 존재하다가 애플리케이션의 로드에 의해 비로소 애플리케이션의 일원이 된다. 모듈은 기능별로 분리되어 작성되므로 코드의 단위를 명확히 분리하여 애플리케이션을 구성할 수 있으며 재사용성이 좋아서 개발 효율성과 유지보수성을 높일 수 있다.
자바스크립트는 웹페이지의 보조적인 기능을 수행하기 위해 한정적인 용도로 만들어진 태생적 한계로 다른 언어에 비해 부족한(나쁜) 부분이 있는 것이 사실이다. 그 대표적인 것이 모듈 기능이 없는 것이다.
C 언어는 #include, Java는 import 등 대부분의 프로그래밍 언어는 모듈 기능을 가지고 있다. 하지만 클라이언트 사이드 자바스크립트는 script 태그를 사용하여 외부의 스크립트 파일을 가져올 수는 있지만, 파일마다 독립적인 파일 스코프를 갖지 않고 하나의 전역 객체(Global Object)를 공유한다. 즉, 자바스크립트 파일을 여러 개의 파일로 분리하여 script 태그로 로드하여도 분리된 자바스크립트 파일들이 결국 하나의 자바스크립트 파일 내에 있는 것처럼 하나의 전역 객체를 공유한다. 따라서 분리된 자바스크립트 파일들이 하나의 전역을 갖게 되어 전역 변수가 중복되는 등의 문제가 발생할 수 있다. 이것으로는 모듈화를 구현할 수 없다.
자바스크립트를 클라이언트 사이드에 국한하지 않고 범용적으로 사용하고자 하는 움직임이 생기면서 모듈 기능은 반드시 해결해야 하는 핵심 과제가 되었다. 이런 상황에서 제안된 것이 CommonJS와 AMD(Asynchronous Module Definition)이다.
결국, 자바스크립트의 모듈화는 크게 CommonJS와 AMD 진영으로 나뉘게 되었고 브라우저에서 모듈을 사용하기 위해서는 CommonJS 또는 AMD를 구현한 모듈 로더 라이브러리를 사용해야 하는 상황이 되었다.
서버 사이드 자바스크립트 런타임 환경인 Node.js는 모듈 시스템의 사실상 표준(de facto standard)인 CommonJS를 채택하였고 독자적인 진화를 거쳐 현재는 CommonJS 사양과 100% 동일하지는 않지만 기본적으로 CommonJS 방식을 따르고 있다. 즉, Node.js에서는 표준은 아니지만 모듈이 지원된다. 따라서 Node.js 환경에서는 모듈 별로 독립적인 스코프, 즉 모듈 스코프를 갖는다.
이러한 상황에서 ES6에서는 클라이언트 사이드 자바스크립트에서도 동작하는 모듈 기능을 추가하였다. 2019년 11월 현재, 모던 브라우저(Chrome 61, FF 60, SF 10.1, Edge 16 이상)에서 ES6 모듈을 사용할 수 있다.
script 태그에 type="module" 어트리뷰트를 추가하면 로드된 자바스크립트 파일은 모듈로서 동작한다. ES6 모듈의 파일 확장자는 모듈임을 명확히 하기 위해 mjs를 사용하도록 권장한다.
<script type="module" src="lib.mjs"></script>
<script type="module" src="app.mjs"></script>
단, 아래와 같은 이유로 아직까지는 브라우저가 지원하는 ES6 모듈 기능보다는 Webpack 등의 모듈 번들러를 사용하는 것이 일반적이다.
- 브라우저의 ES6 모듈 기능을 사용하더라도 트랜스파일링이나 번들링이 필요하다.
- 아직 지원하지 않는 기능(Bare import 등)이 있다. (ECMAScript modules in browsers 참고)
- 점차 해결되고는 있지만 아직 몇가지 이슈가 있다. (ECMAScript modules in browsers 참고)
ES6를 사용하여 프로젝트를 진행하려면 ES6로 작성된 코드를 IE를 포함한 모든 브라우저에서 문제 없이 동작시키기 위한 개발환경을 구축하는 것이 필요하다.
#1. 모듈 스코프
ES6 모듈 기능을 사용하지 않으면 분리된 자바스크립트 파일에 독자적인 스코프를 갖지 않고 하나의 전역을 공유한다.
// foo.js
var x = 'foo';
// 변수 x는 전역 변수이다.
console.log(window.x); // foo
// bar.js
// foo.js에서 선언한 전역 변수 x와 중복된 선언이다.
var x = 'bar';
// 변수 x는 전역 변수이다.
// foo.js에서 선언한 전역 변수 x의 값이 재할당되었다.
console.log(window.x); // bar
<!DOCTYPE html>
<html>
<body>
<script src="foo.js"></script>
<script src="bar.js"></script>
</body>
</html>
HTML에서 2개의 자바스크립트 파일을 로드하면 로드된 자바스크립트는 하나의 전역을 공유한다. 위 예제에서 로드된 2개의 자바스크립트 파일은 하나의 전역 객체를 공유하며 하나의 전역 스코프를 갖는다. 따라서 foo.js에서 선언한 변수 x와 bar.js에서 선언한 변수 x는 중복 선언되며 의도치 않게 변수 x의 값이 덮어 써진다.
ES6 모듈은 파일 자체의 스코프를 제공한다. 즉, ES6 모듈은 독자적인 모듈 스코프를 갖는다. 따라서, 모듈 내에서 var 키워드로 선언한 변수는 더 이상 전역 변수가 아니며 window 객체의 프로퍼티도 아니다.
// foo.mjs
var x = 'foo';
console.log(x); // foo
// 변수 x는 전역 변수가 아니며 window 객체의 프로퍼티도 아니다.
console.log(window.x); // undefined
// bar.mjs
// 변수 x는 foo.mjs에서 선언한 변수 x와 스코프가 다른 변수이다.
var x = 'bar';
console.log(x); // bar
// 변수 x는 전역 변수가 아니며 window 객체의 프로퍼티도 아니다.
console.log(window.x); // undefined
<!DOCTYPE html>
<html>
<body>
<script type="module" src="foo.mjs"></script>
<script type="module" src="bar.mjs"></script>
</body>
</html>
모듈 내에서 선언한 변수는 모듈 외부에서 참조할 수 없다. 스코프가 다르기 때문이다.
// foo.js
const x = 'foo';
console.log(x); // foo
// bar.js
// 다른 모듈에서 선언한 변수는 모듈 외부에서 참조할 수 없다. 스코프가 다르기 때문이다.
console.log(x); // ReferenceError: x is not defined
<!DOCTYPE html>
<html>
<body>
<script type="module" src="foo.js"></script>
<script type="module" src="bar.js"></script>
</body>
</html>
#2. export 키워드
모듈은 독자적인 모듈 스코프를 갖기 때문에 모듈 안에 선언한 모든 식별자는 기본적으로 해당 모듈 내부에서만 참조할 수 있다. 만약 모듈 안에 선언한 식별자를 외부에 공개하여 다른 모듈들이 참조할 수 있게 하고 싶다면 export 키워드를 사용한다. 선언된 변수, 함수, 클래스 모두 export할 수 있다.
모듈을 공개하려면 선언문 앞에 export 키워드를 사용한다. 여러 개를 export할 수 있는데 이때 각각의 export는 이름으로 구별할 수 있다.
// lib.mjs
// 변수의 공개
export const pi = Math.PI;
// 함수의 공개
export function square(x) {
return x * x;
}
// 클래스의 공개
export class Person {
constructor(name) {
this.name = name;
}
}
선언문 앞에 매번 export 키워드를 붙이는 것이 싫다면 export 대상을 모아 하나의 객체로 구성하여 한번에 export할 수도 있다.
// lib.mjs
const pi = Math.PI;
function square(x) {
return x * x;
}
class Person {
constructor(name) {
this.name = name;
}
}
// 변수, 함수 클래스를 하나의 객체로 구성하여 공개
export { pi, square, Person };
#3. import 키워드
모듈에서 공개(export)한 대상을 로드하려면 import 키워드를 사용한다.
모듈이 export한 식별자로 import하며 ES6 모듈의 파일 확장자를 생략할 수 없다.
// app.mjs
// 같은 폴더 내의 lib.mjs 모듈을 로드.
// lib.mjs 모듈이 export한 식별자로 import한다.
// ES6 모듈의 파일 확장자를 생략할 수 없다.
import { pi, square, Person } from './lib.mjs';
console.log(pi); // 3.141592653589793
console.log(square(10)); // 100
console.log(new Person('Lee')); // Person { name: 'Lee' }
모듈이 export한 식별자를 각각 지정하지 않고 하나의 이름으로 한꺼번에 import할 수도 있다. 이때 import되는 식별자는 as 뒤에 지정한 이름의 객체에 프로퍼티로 할당된다.
// app.mjs
import * as lib from './lib.mjs';
console.log(lib.pi); // 3.141592653589793
console.log(lib.square(10)); // 100
console.log(new lib.Person('Lee')); // Person { name: 'Lee' }
이름을 변경하여 import할 수도 있다.
// app.mjs
import { pi as PI, square as sq, Person as P } from './lib.mjs';
console.log(PI); // 3.141592653589793
console.log(sq(2)); // 4
console.log(new P('Kim')); // Person { name: 'Kim' }
모듈에서 하나만을 export할 때는 default 키워드를 사용할 수 있다.
// lib.mjs
export default function (x) {
return x * x;
}
다만, default를 사용하는 경우, var, let, const는 사용할 수 없다.
// lib.mjs
export default () => {};
// => OK
export default const foo = () => {};
// => SyntaxError: Unexpected token 'const'
default 키워드와 함께 export한 모듈은 {} 없이 임의의 이름으로 import한다.
// app.mjs
import square from './lib.mjs';
console.log(square(3)); // 9
브라우저가 지원하는 ES6 모듈 기능을 이용하여 import와 export가 동작하는지 확인해보자.
// lib.mjs
export default x => x * x;
// app.mjs
// 브라우저 환경에서는 모듈의 파일 확장자를 생략할 수 없다.
// 모듈의 파일 확장자는 .mjs를 권장한다.
import square from './lib.mjs';
console.log(square(10)); // 100
<!DOCTYPE html>
<html>
<body>
<script type="module" src="./lib.js"></script>
<script type="module" src="./app.js"></script>
</body>
</html>
위 HTML을 실행보면 콘솔에 100이 출력되는 것을 확인할 수 있다.
ㅤㅤ
📍 Promise : 프로미스
1. 프로미스란?
자바스크립트는 비동기 처리를 위한 하나의 패턴으로 콜백 함수를 사용한다. 하지만 전통적인 콜백 패턴은 콜백 헬로 인해 가독성이 나쁘고 비동기 처리 중 발생한 에러의 처리가 곤란하며 여러 개의 비동기 처리를 한번에 처리하는 데도 한계가 있다.
ES6에서는 비동기 처리를 위한 또 다른 패턴으로 프로미스(Promise)를 도입했다. 프로미스는 전통적인 콜백 패턴이 가진 단점을 보완하며 비동기 처리 시점을 명확하게 표현할 수 있다는 장점이 있다.
#2. 콜백 패턴의 단점
#2.1 콜백 헬
동기식 처리 모델(Synchronous processing model)은 직렬적으로 태스크(task)를 수행한다. 즉, 태스크는 순차적으로 실행되며 어떤 작업이 수행 중이면 다음 태스크는 대기하게 된다. 예를 들어 서버에서 데이터를 가져와서 화면에 표시하는 태스크를 수행할 때, 서버에 데이터를 요청하고 데이터가 응답될 때까지 이후의 태스크들은 블로킹된다.
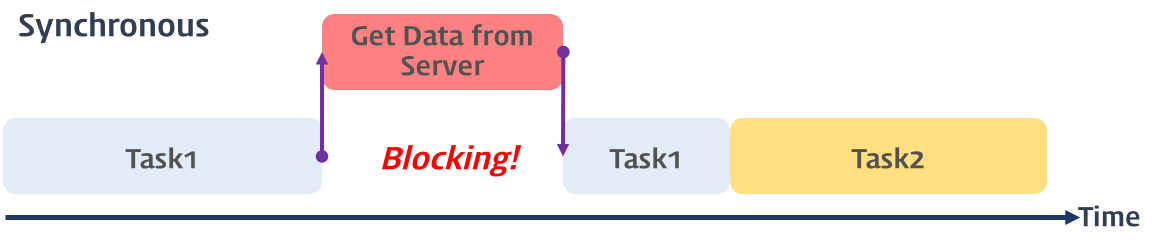
비동기식 처리 모델(Asynchronous processing model 또는 Non-Blocking processing model)은 병렬적으로 태스크를 수행한다. 즉, 태스크가 종료되지 않은 상태라 하더라도 대기하지 않고 즉시 다음 태스크를 실행한다. 예를 들어 서버에서 데이터를 가져와서 화면에 표시하는 태스크를 수행할 때, 서버에 데이터를 요청한 이후 서버로부터 데이터가 응답될 때까지 대기하지 않고(Non-Blocking) 즉시 다음 태스크를 수행한다. 이후 서버로부터 데이터가 응답되면 이벤트가 발생하고 이벤트 핸들러가 데이터를 가지고 수행할 태스크를 계속해 수행한다. 자바스크립트의 대부분의 DOM 이벤트와 Timer 함수(setTimeout, setInterval), Ajax 요청은 비동기식 처리 모델로 동작한다.
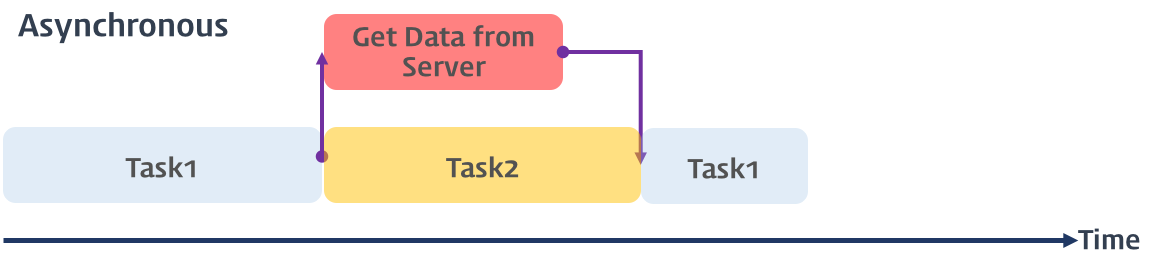
자바스크립트에서 빈번하게 사용되는 [비동기식 처리 모델]은 요청을 병렬로 처리하여 다른 요청이 블로킹(blocking, 작업 중단)되지 않는 장점이 있다.
하지만 비동기 처리를 위해 콜백 패턴을 사용하면 처리 순서를 보장하기 위해 여러 개의 콜백 함수가 네스팅(nesting, 중첩)되어 복잡도가 높아지는 콜백 헬(Callback Hell)이 발생하는 단점이 있다. 콜백 헬은 가독성을 나쁘게 하며 실수를 유발하는 원인이 된다. 아래는 콜백 헬이 발생하는 전형적인 사례이다.
step1(function(value1) {
step2(value1, function(value2) {
step3(value2, function(value3) {
step4(value3, function(value4) {
step5(value4, function(value5) {
// value5를 사용하는 처리
});
});
});
});
});

콜백 헬이 발생하는 이유에 대해 살펴보자. 비동기 처리 모델은 실행 완료를 기다리지 않고 즉시 다음 태스크를 실행한다. 따라서 비동기 함수(비동기를 처리하는 함수) 내에서 처리 결과를 반환(또는 전역 변수에의 할당)하면 기대한 대로 동작하지 않는다.
<!DOCTYPE html>
<html>
<body>
<script>
// 비동기 함수
function get(url) {
// XMLHttpRequest 객체 생성
const xhr = new XMLHttpRequest();
// 서버 응답 시 호출될 이벤트 핸들러
xhr.onreadystatechange = function () {
// 서버 응답 완료가 아니면 무시
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status === 200) { // 정상 응답
console.log(xhr.response);
// 비동기 함수의 결과에 대한 처리는 반환할 수 없다.
return xhr.response; // ①
} else { // 비정상 응답
console.log('Error: ' + xhr.status);
}
};
// 비동기 방식으로 Request 오픈
xhr.open('GET', url);
// Request 전송
xhr.send();
}
// 비동기 함수 내의 readystatechange 이벤트 핸들러에서 처리 결과를 반환(①)하면 순서가 보장되지 않는다.
const res = get('http://jsonplaceholder.typicode.com/posts/1');
console.log(res); // ② undefined
</script>
</body>
</html>
비동기 함수 내의 readystatechange 이벤트 핸들러에서 처리 결과를 반환(①)하면 순서가 보장되지 않는다. 즉, ②에서 get 함수가 반환한 값을 참조할 수 없다.
get 함수가 호출되면 get 함수의 실행 컨텍스트가 생성되고 호출 스택(실행 컨텍스트 스택)에서 실행된다. get 함수가 반환하는 xhr.response는 readystatechange 이벤트 핸들러가 반환한다. readystatechange 이벤트는 발생하는 시점을 명확히 알 수 없지만 반드시 get 함수가 종료한 이후 발생한다. get 함수의 마지막 문인 xhr.send();가 실행되어야 request를 전송하고 request를 전송해야 readystatechange 이벤트가 발생할 수 있기 때문이다.
get 함수가 종료하면 곧바로 console.log(②)가 호출되어 호출 스택에 들어가 실행된다. console.log가 호출되기 직전에 readystatechange 이벤트가 이미 발생했다하더라도 이벤트 핸들러는 console.log보다 먼저 실행되지 않는다.
readystatechange 이벤트의 이벤트 핸들러는 이벤트가 발생하면 즉시 실행되는 것이 아니다. 이벤트가 발생하면 일단 태스크 큐로 들어가고 호출 스택이 비면 그때 이벤트 루프에 의해 호출 스택으로 들어가 실행된다. console.log 호출 시점 이전에 readystatechange 이벤트가 이미 발생했다하더라도 get 함수가 종료하면 곧바로 console.log가 호출되어 호출 스택에 들어가기 때문에 readystatechange 이벤트의 이벤트 핸들러는 console.log가 종료되어 호출 스택에서 빠진 이후 실행된다. 만약 get 함수 이후에 console.log가 100번 호출된다면 readystatechange 이벤트의 이벤트 핸들러는 모든 console.log가 종료한 이후에나 실행된다.
때문에 get 함수의 반환 결과를 가지고 후속 처리를 할 수 없다. 즉, 비동기 함수의 처리 결과를 반환하는 경우, 순서가 보장되지 않기 때문에 그 반환 결과를 가지고 후속 처리를 할 수 없다. 즉, 비동기 함수의 처리 결과에 대한 처리는 비동기 함수의 콜백 함수 내에서 처리해야 한다. 이로 인해 콜백 헬이 발생한다.
만일 비동기 함수의 처리 결과를 가지고 다른 비동기 함수를 호출해야 하는 경우, 함수의 호출이 중첩(nesting)이 되어 복잡도가 높아지는 현상이 발생하는데 이를 Callback Hell이라 한다.
Callback Hell은 코드의 가독성을 나쁘게 하고 복잡도를 증가시켜 실수를 유발하는 원인이 되며 에러 처리가 곤란하다.
#2.2 에러 처리의 한계
콜백 방식의 비동기 처리가 갖는 문제점 중에서 가장 심각한 것은 에러 처리가 곤란하다는 것이다.
try {
setTimeout(() => { throw new Error('Error!'); }, 1000);
} catch (e) {
console.log('에러를 캐치하지 못한다..');
console.log(e);
}
try 블록 내에서 setTimeout 함수가 실행되면 1초 후에 콜백 함수가 실행되고 이 콜백 함수는 예외를 발생시킨다. 하지만 이 예외는 catch 블록에서 캐치되지 않는다.
비동기 처리 함수의 콜백 함수는 해당 이벤트(timer 함수의 tick 이벤트, XMLHttpRequest의 readystatechange 이벤트 등)가 발생하면 태스트 큐(Task queue)로 이동한 후 호출 스택이 비어졌을 때, 호출 스택으로 이동되어 실행된다. setTimeout 함수는 비동기 함수이므로 콜백 함수가 실행될 때까지 기다리지 않고 즉시 종료되어 호출 스택에서 제거된다. 이후 tick 이벤트가 발생하면 setTimeout 함수의 콜백 함수는 태스트 큐로 이동한 후 호출 스택이 비어졌을 때 호출 스택으로 이동되어 실행된다. 이때 setTimeout 함수는 이미 호출 스택에서 제거된 상태이다. 이것은 setTimeout 함수의 콜백 함수를 호출한 것은 setTimeout 함수가 아니다라는 것을 의미한다. setTimeout 함수의 콜백 함수의 호출자(caller)가 setTimeout 함수라면 호출 스택에 setTimeout 함수가 존재해야 하기 때문이다.
예외(exception)는 호출자(caller) 방향으로 전파된다. 하지만 위에서 살펴본 바와 같이 setTimeout 함수의 콜백 함수를 호출한 것은 setTimeout 함수가 아니다. 따라서 setTimeout 함수의 콜백 함수 내에서 발생시킨 에러는 catch 블록에서 캐치되지 않아 프로세스는 종료된다.
이러한 문제를 극복하기 위해 Promise가 제안되었다. Promise는 ES6에 정식 채택되어 IE를 제외한 대부분의 브라우저가 지원하고 있다.
#3. 프로미스의 생성
프로미스는 Promise 생성자 함수를 통해 인스턴스화한다. Promise 생성자 함수는 비동기 작업을 수행할 콜백 함수를 인자로 전달받는데 이 콜백 함수는 resolve와 reject 함수를 인자로 전달받는다.
// Promise 객체의 생성
const promise = new Promise((resolve, reject) => {
// 비동기 작업을 수행한다.
if (/* 비동기 작업 수행 성공 */) {
resolve('result');
}
else { /* 비동기 작업 수행 실패 */
reject('failure reason');
}
});
Promise는 비동기 처리가 성공(fulfilled)하였는지 또는 실패(rejected)하였는지 등의 상태(state) 정보를 갖는다.
| 상태 | 의미 | 구현 |
|---|---|---|
| pending | 비동기 처리가 아직 수행되지 않은 상태 | resolve 또는 reject 함수가 아직 호출되지 않은 상태 |
| fulfilled | 비동기 처리가 수행된 상태 (성공) | resolve 함수가 호출된 상태 |
| rejected | 비동기 처리가 수행된 상태 (실패) | reject 함수가 호출된 상태 |
| settled | 비동기 처리가 수행된 상태 (성공 또는 실패) | resolve 또는 reject 함수가 호출된 상태 |
Promise 생성자 함수가 인자로 전달받은 콜백 함수는 내부에서 비동기 처리 작업을 수행한다. 이때 비동기 처리가 성공하면 콜백 함수의 인자로 전달받은 resolve 함수를 호출한다. 이때 프로미스는 ‘fulfilled’ 상태가 된다. 비동기 처리가 실패하면 reject 함수를 호출한다. 이때 프로미스는 ‘rejected’ 상태가 된다.
const promiseAjax = (method, url, payload) => {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.open(method, url);
xhr.setRequestHeader('Content-type', 'application/json');
xhr.send(JSON.stringify(payload));
xhr.onreadystatechange = function () {
// 서버 응답 완료가 아니면 무시
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status >= 200 && xhr.status < 400) {
// resolve 메소드를 호출하면서 처리 결과를 전달
resolve(xhr.response); // Success!
} else {
// reject 메소드를 호출하면서 에러 메시지를 전달
reject(new Error(xhr.status)); // Failed...
}
};
});
};
위 예제처럼 비동기 함수 내에서 Promise 객체를 생성하고 그 내부에서 비동기 처리를 구현한다. 이때 비동기 처리에 성공하면 resolve 메소드를 호출한다. 이때 resolve 메소드의 인자로 비동기 처리 결과를 전달한다. 이 처리 결과는 Promise 객체의 후속 처리 메소드로 전달된다. 만약 비동기 처리에 실패하면 reject 메소드를 호출한다. 이때 reject 메소드의 인자로 에러 메시지를 전달한다. 이 에러 메시지는 Promise 객체의 후속 처리 메소드로 전달된다.
#4. 프로미스의 후속 처리 메소드
Promise로 구현된 비동기 함수는 Promise 객체를 반환하여야 한다. Promise로 구현된 비동기 함수를 호출하는 측(promise consumer)에서는 Promise 객체의 후속 처리 메소드(then, catch)를 통해 비동기 처리 결과 또는 에러 메시지를 전달받아 처리한다. Promise 객체는 상태를 갖는다고 하였다. 이 상태에 따라 후속 처리 메소드를 체이닝 방식으로 호출한다. Promise의 후속 처리 메소드는 아래와 같다.
then
then 메소드는 두 개의 콜백 함수를 인자로 전달 받는다. 첫 번째 콜백 함수는 성공(fulfilled, resolve 함수가 호출된 상태) 시 호출되고 두 번째 함수는 실패(rejected, reject 함수가 호출된 상태) 시 호출된다.then 메소드는 Promise를 반환한다.
catch
예외(비동기 처리에서 발생한 에러와 then 메소드에서 발생한 에러)가 발생하면 호출된다. catch 메소드는 Promise를 반환한다.
앞에서 프로미스로 정의한 비동기 함수 get을 사용해 보자. get 함수는 XMLHttpRequest 객체를 통해 Ajax 요청을 수행하므로 브라우저에서 실행하여야 한다.
<!DOCTYPE html>
<html>
<body>
<!DOCTYPE html>
<html>
<body>
<pre class="result"></pre>
<script>
const $result = document.querySelector('.result');
const render = content => { $result.textContent = JSON.stringify(content, null, 2); };
const promiseAjax = (method, url, payload) => {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.open(method, url);
xhr.setRequestHeader('Content-type', 'application/json');
xhr.send(JSON.stringify(payload));
xhr.onreadystatechange = function () {
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status >= 200 && xhr.status < 400) {
resolve(xhr.response); // Success!
} else {
reject(new Error(xhr.status)); // Failed...
}
};
});
};
/*
비동기 함수 promiseAjax은 Promise 객체를 반환한다.
Promise 객체의 후속 메소드를 사용하여 비동기 처리 결과에 대한 후속 처리를 수행한다.
*/
promiseAjax('GET', 'http://jsonplaceholder.typicode.com/posts/1')
.then(JSON.parse)
.then(
// 첫 번째 콜백 함수는 성공(fulfilled, resolve 함수가 호출된 상태) 시 호출된다.
render,
// 두 번째 함수는 실패(rejected, reject 함수가 호출된 상태) 시 호출된다.
console.error
);
</script>
</body>
</html>
#5. 프로미스의 에러 처리
위 예제의 비동기 함수 get은 Promise 객체를 반환한다. 비동기 처리 결과에 대한 후속 처리는 Promise 객체가 제공하는 후속 처리 메서드 then, catch, finally를 사용하여 수행한다. 비동기 처리 시에 발생한 에러는 then 메서드의 두 번째 콜백 함수로 처리할 수 있다.
const wrongUrl = 'https://jsonplaceholder.typicode.com/XXX/1';
// 부적절한 URL이 지정되었기 때문에 에러가 발생한다.
promiseAjax(wrongUrl)
.then(res => console.log(res), err => console.error(err)); // Error: 404
비동기 처리에서 발생한 에러는 Promise 객체의 후속 처리 메서드 catch를 사용해서 처리할 수도 있다.
const wrongUrl = 'https://jsonplaceholder.typicode.com/XXX/1';
// 부적절한 URL이 지정되었기 때문에 에러가 발생한다.
promiseAjax(wrongUrl)
.then(res => console.log(res))
.catch(err => console.error(err)); // Error: 404
catch 메서드를 호출하면 내부적으로 then(undefined, onRejected)을 호출한다. 위 예제는 내부적으로 다음과 같이 처리된다.
const wrongUrl = 'https://jsonplaceholder.typicode.com/XXX/1';
// 부적절한 URL이 지정되었기 때문에 에러가 발생한다.
promiseAjax(wrongUrl)
.then(res => console.log(res))
.then(undefined, err => console.error(err)); // Error: 404
단, then 메서드의 두 번째 콜백 함수는 첫 번째 콜백 함수에서 발생한 에러를 캐치하지 못하고 코드가 복잡해져서 가독성이 좋지 않다.
promiseAjax('https://jsonplaceholder.typicode.com/todos/1')
.then(res => console.xxx(res), err => console.error(err));
// 두 번째 콜백 함수는 첫 번째 콜백 함수에서 발생한 에러를 캐치하지 못한다.
catch 메서드를 모든 then 메서드를 호출한 이후에 호출하면 비동기 처리에서 발생한 에러(reject 함수가 호출된 상태)뿐만 아니라 then 메서드 내부에서 발생한 에러까지 모두 캐치할 수 있다.
promiseAjax('https://jsonplaceholder.typicode.com/todos/1')
.then(res => console.xxx(res))
.catch(err => console.error(err)); // TypeError: console.xxx is not a function
또한 then 메서드에 두 번째 콜백 함수를 전달하는 것보다 catch 메서드를 사용하는 것이 가독성이 좋고 명확하다. 따라서 에러 처리는 then 메서드에서 하지 말고 catch 메서드를 사용하는 것을 권장한다.
#6. 프로미스 체이닝
비동기 함수의 처리 결과를 가지고 다른 비동기 함수를 호출해야 하는 경우, 함수의 호출이 중첩(nesting)이 되어 복잡도가 높아지는 콜백 헬이 발생한다. 프로미스는 후속 처리 메소드를 체이닝(chainning)하여 여러 개의 프로미스를 연결하여 사용할 수 있다. 이로써 콜백 헬을 해결한다.
Promise 객체를 반환한 비동기 함수는 프로미스 후속 처리 메소드인 then이나 catch 메소드를 사용할 수 있다. 따라서 then 메소드가 Promise 객체를 반환하도록 하면(then 메소드는 기본적으로 Promise를 반환한다.) 여러 개의 프로미스를 연결하여 사용할 수 있다.
아래는 서버로 부터 특정 포스트를 취득한 후, 그 포스트를 작성한 사용자의 아이디로 작성된 모든 포스트를 검색하는 예제이다.
<!DOCTYPE html>
<html>
<body>
<pre class="result"></pre>
<script>
const $result = document.querySelector('.result');
const render = content => { $result.textContent = JSON.stringify(content, null, 2); };
const promiseAjax = (method, url, payload) => {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.open(method, url);
xhr.setRequestHeader('Content-type', 'application/json');
xhr.send(JSON.stringify(payload));
xhr.onreadystatechange = function () {
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status >= 200 && xhr.status < 400) {
resolve(xhr.response); // Success!
} else {
reject(new Error(xhr.status)); // Failed...
}
};
});
};
const url = 'http://jsonplaceholder.typicode.com/posts';
// 포스트 id가 1인 포스트를 검색하고 프로미스를 반환한다.
promiseAjax('GET', `${url}/1`)
// 포스트 id가 1인 포스트를 작성한 사용자의 아이디로 작성된 모든 포스트를 검색하고 프로미스를 반환한다.
.then(res => promiseAjax('GET', `${url}?userId=${JSON.parse(res).userId}`))
.then(JSON.parse)
.then(render)
.catch(console.error);
</script>
</body>
</html>
#7. 프로미스의 정적 메소드
Promise는 주로 생성자 함수로 사용되지만 함수도 객체이므로 메소드를 갖을 수 있다. Promise 객체는 4가지 정적 메소드를 제공한다.
#7.1 Promise.resolve/Promise.reject
Promise.resolve와 Promise.reject 메소드는 존재하는 값을 Promise로 래핑하기 위해 사용한다.
정적 메소드 Promise.resolve 메소드는 인자로 전달된 값을 resolve하는 Promise를 생성한다.
const resolvedPromise = Promise.resolve([1, 2, 3]);
resolvedPromise.then(console.log); // [ 1, 2, 3 ]
위 예제는 아래 예제와 동일하게 동작한다.
const resolvedPromise = new Promise(resolve => resolve([1, 2, 3]));
resolvedPromise.then(console.log); // [ 1, 2, 3 ]
Promise.reject 메소드는 인자로 전달된 값을 reject하는 프로미스를 생성한다.
const rejectedPromise = Promise.reject(new Error('Error!'));
rejectedPromise.catch(console.log); // Error: Error!
위 예제는 아래 예제와 동일하게 동작한다.
const rejectedPromise = new Promise((resolve, reject) => reject(new Error('Error!')));
rejectedPromise.catch(console.log); // Error: Error!
#7.2 Promise.all
Promise.all 메소드는 프로미스가 담겨 있는 배열 등의 [이터러블]을 인자로 전달 받는다. 그리고 전달받은 모든 프로미스를 병렬로 처리하고 그 처리 결과를 resolve하는 새로운 프로미스를 반환한다.
Promise.all([
new Promise(resolve => setTimeout(() => resolve(1), 3000)), // 1
new Promise(resolve => setTimeout(() => resolve(2), 2000)), // 2
new Promise(resolve => setTimeout(() => resolve(3), 1000)) // 3
]).then(console.log) // [ 1, 2, 3 ]
.catch(console.log);
Promise.all 메소드는 3개의 프로미스를 담은 배열을 전달받았다. 각각의 프로미스는 아래와 같이 동작한다.
- 첫번째 프로미스는 3초 후에 1을 resolve하여 처리 결과를 반환한다.
- 두번째 프로미스는 2초 후에 2을 resolve하여 처리 결과를 반환한다.
- 세번째 프로미스는 1초 후에 3을 resolve하여 처리 결과를 반환한다.
Promise.all 메소드는 전달받은 모든 프로미스를 병렬로 처리한다. 이때 모든 프로미스의 처리가 종료될 때까지 기다린 후 아래와 모든 처리 결과를 resolve 또는 reject한다.
- 모든 프로미스의 처리가 성공하면 각각의 프로미스가 resolve한 처리 결과를 배열에 담아 resolve하는 새로운 프로미스를 반환한다. 이때 첫번째 프로미스가 가장 나중에 처리되어도 Promise.all 메소드가 반환하는 프로미스는 첫번째 프로미스가 resolve한 처리 결과부터 차례대로 배열에 담아 그 배열을 resolve하는 새로운 프로미스를 반환한다. 즉, 처리 순서가 보장된다.
- 프로미스의 처리가 하나라도 실패하면 가장 먼저 실패한 프로미스가 reject한 에러를 reject하는 새로운 프로미스를 즉시 반환한다.
Promise.all([
new Promise((resolve, reject) => setTimeout(() => reject(new Error('Error 1!')), 3000)),
new Promise((resolve, reject) => setTimeout(() => reject(new Error('Error 2!')), 2000)),
new Promise((resolve, reject) => setTimeout(() => reject(new Error('Error 3!')), 1000))
]).then(console.log)
.catch(console.log); // Error: Error 3!
위 예제의 경우, 세번째 프로미스가 가장 먼저 실패하므로 세번째 프로미스가 reject한 에러가 catch 메소드로 전달된다.
Promise.all 메소드는 전달 받은 이터러블의 요소가 프로미스가 아닌 경우, Promise.resolve 메소드를 통해 프로미스로 래핑된다.
Promise.all([
1, // => Promise.resolve(1)
2, // => Promise.resolve(2)
3 // => Promise.resolve(3)
]).then(console.log) // [1, 2, 3]
.catch(console.log);
아래는 github id로 github 사용자 이름을 취득하는 예제이다.
const githubIds = ['jeresig', 'ahejlsberg', 'ungmo2'];
Promise.all(githubIds.map(id => fetch(`https://api.github.com/users/${id}`)))
// [Response, Response, Response] => Promise
.then(responses => Promise.all(responses.map(res => res.json())))
// [user, user, user] => Promise
.then(users => users.map(user => user.name))
// [ 'John Resig', 'Anders Hejlsberg', 'Ungmo Lee' ]
.then(console.log)
.catch(console.log);
위 예제의 Promise.all 메소드는 fetch 함수가 반환한 3개의 프로미스의 배열을 인수로 전달받고 이 프로미스들을 병렬 처리한다. 모든 프로미스의 처리가 성공하면 Promise.all 메소드는 각각의 프로미스가 resolve한 3개의 Response 객체가 담긴 배열을 resolve하는 새로운 프로미스를 반환하고 후속 처리 메소드 then에는 3개의 Response 객체가 담긴 배열이 전달된다. 이때 json 메소드는 프로미스를 반환하므로 한번 더 Promise.all 메소드를 호출해야 하는 것에 주의하자. 두번째 호출한 Promise.all 메소드는 github로 부터 취득한 3개의 사용자 정보 객체가 담긴 배열을 resolve하는 프로미스를 반환하고 후속 처리 메소드 then에는 3개의 사용자 정보 객체가 담긴 배열이 전달된다.
#7.3 Promise.race
Promise.race 메소드는 Promise.all 메소드와 동일하게 프로미스가 담겨 있는 배열 등의 [이터러블]을 인자로 전달 받는다. 그리고 Promise.race 메소드는 Promise.all 메소드처럼 모든 프로미스를 병렬 처리하는 것이 아니라 가장 먼저 처리된 프로미스가 resolve한 처리 결과를 resolve하는 새로운 프로미스를 반환한다.
Promise.race([
new Promise(resolve => setTimeout(() => resolve(1), 3000)), // 1
new Promise(resolve => setTimeout(() => resolve(2), 2000)), // 2
new Promise(resolve => setTimeout(() => resolve(3), 1000)) // 3
]).then(console.log) // 3
.catch(console.log);
에러가 발생한 경우는 Promise.all 메소드와 동일하게 처리된다. 즉, Promise.race 메소드에 전달된 프로미스 처리가 하나라도 실패하면 가장 먼저 실패한 프로미스가 reject한 에러를 reject하는 새로운 프로미스를 즉시 반환한다.
Promise.race([
new Promise((resolve, reject) => setTimeout(() => reject(new Error('Error 1!')), 3000)),
new Promise((resolve, reject) => setTimeout(() => reject(new Error('Error 2!')), 2000)),
new Promise((resolve, reject) => setTimeout(() => reject(new Error('Error 3!')), 1000))
]).then(console.log)
.catch(console.log); // Error: Error 3!ㅤㅤ
📍 Symbol : 심볼
1. Symbol이란?
1997년 자바스크립트가 ECMAScript로 처음 표준화된 이래로 자바스크립트는 6개의 타입을 가지고 있었다.
- 원시 타입 (primitive data type)
- Boolean
- null
- undefined
- Number
- String
- 객체 타입 (Object type)
- Object
심볼(symbol)은 ES6에서 새롭게 추가된 7번째 타입으로 변경 불가능한 원시 타입의 값이다. 심볼은 주로 이름의 충돌 위험이 없는 유일한 객체의 프로퍼티 키(property key)를 만들기 위해 사용한다.
#2. Symbol의 생성
Symbol은 Symbol() 함수로 생성한다. Symbol() 함수는 호출될 때마다 Symbol 값을 생성한다. 이때 생성된 Symbol은 객체가 아니라 변경 불가능한 원시 타입의 값이다.
// 심볼 mySymbol은 이름의 충돌 위험이 없는 유일한 프로퍼티 키
let mySymbol = Symbol();
console.log(mySymbol); // Symbol()
console.log(typeof mySymbol); // symbol
Symbol() 함수는 [String], [Number], [Boolean]과 같이 래퍼 객체를 생성하는 생성자 함수와는 달리 new 연산자를 사용하지 않는다.
new Symbol(); // TypeError: Symbol is not a constructor
Symbol() 함수에는 문자열을 인자로 전달할 수 있다. 이 문자열은 Symbol 생성에 어떠한 영향을 주지 않으며 다만 생성된 Symbol에 대한 설명(description)으로 디버깅 용도로만 사용된다.
let symbolWithDesc = Symbol('ungmo2');
console.log(symbolWithDesc); // Symbol(ungmo2)
console.log(symbolWithDesc === Symbol('ungmo2')); // false
#3. Symbol의 사용
객체의 프로퍼티 키는 빈 문자열을 포함하는 모든 문자열로 만들 수 있다.
const obj = {};
obj.prop = 'myProp';
obj[123] = 123; // 123은 문자열로 변환된다.
// obj.123 = 123; // SyntaxError: Unexpected number
obj['prop' + 123] = false;
console.log(obj); // { '123': 123, prop: 'myProp', prop123: false }
Symbol 값도 객체의 프로퍼티 키로 사용할 수 있다. Symbol 값은 유일한 값이므로 Symbol 값을 키로 갖는 프로퍼티는 다른 어떠한 프로퍼티와도 충돌하지 않는다.
const obj = {};
const mySymbol = Symbol('mySymbol');
obj[mySymbol] = 123;
console.log(obj); // { [Symbol(mySymbol)]: 123 }
console.log(obj[mySymbol]); // 123
#4. Symbol 객체
Symbol() 함수로 Symbol 값을 생성할 수 있었다. 이것은 Symbol이 함수 객체라는 의미이다.
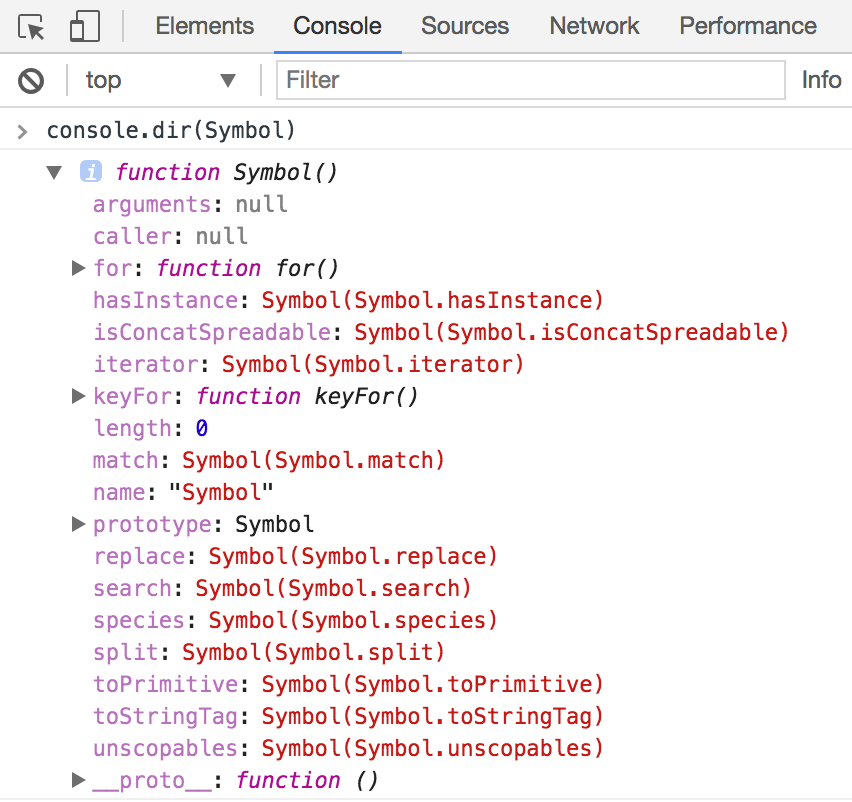
위 참조 결과에서 알 수 있듯이 Symbol 객체는 프로퍼티와 메소드를 가지고 있다. Symbol 객체의 프로퍼티 중에 length와 prototype을 제외한 프로퍼티를 Well-Known Symbol이라 부른다.
#4.1 Symbol.iterator
Well-Known Symbol은 자바스크립트 엔진에 상수로 존재하며 자바스크립트 엔진은 Well-Known Symbol을 참조하여 일정한 처리를 한다. 예를 들어 어떤 객체가 Symbol.iterator를 프로퍼티 key로 사용한 메소드 가지고 있으면 자바스크립트 엔진은 이 객체가 [이터레이션 프로토콜]을 따르는 것으로 간주하고 이터레이터로 동작하도록 한다.
Symbol.iterator를 프로퍼티 key로 사용하여 메소드를 구현하고 있는 빌트인 객체(빌트인 이터러블)는 아래와 같다. 아래의 객체들은 이터레이션 프로토콜을 준수하고 있으며 이터러이터를 반환한다.
Array
Array.prototype[Symbol.iterator]
String
String.prototype[Symbol.iterator]
Map
Map.prototype[Symbol.iterator]
Set
Set.prototype[Symbol.iterator]
DOM data structures
NodeList.prototype[Symbol.iterator] HTMLCollection.prototype[Symbol.iterator]
arguments
arguments[Symbol.iterator]
// 이터러블
// Symbol.iterator를 프로퍼티 key로 사용한 메소드를 구현하여야 한다.
// 배열에는 Array.prototype[Symbol.iterator] 메소드가 구현되어 있다.
const iterable = ['a', 'b', 'c'];
// 이터레이터
// 이터러블의 Symbol.iterator를 프로퍼티 key로 사용한 메소드는 이터레이터를 반환한다.
const iterator = iterable[Symbol.iterator]();
// 이터레이터는 순회 가능한 자료 구조인 이터러블의 요소를 탐색하기 위한 포인터로서 value, done 프로퍼티를 갖는 객체를 반환하는 next() 함수를 메소드로 갖는 객체이다. 이터레이터의 next() 메소드를 통해 이터러블 객체를 순회할 수 있다.
console.log(iterator.next()); // { value: 'a', done: false }
console.log(iterator.next()); // { value: 'b', done: false }
console.log(iterator.next()); // { value: 'c', done: false }
console.log(iterator.next()); // { value: undefined, done: true }
#4.2 Symbol.for
Symbol.for 메소드는 인자로 전달받은 문자열을 키로 사용하여 Symbol 값들이 저장되어 있는 전역 Symbol 레지스트리에서 해당 키와 일치하는 저장된 Symbol 값을 검색한다. 이때 검색에 성공하면 검색된 Symbol 값을 반환하고, 검색에 실패하면 새로운 Symbol 값을 생성하여 해당 키로 전역 Symbol 레지스트리에 저장한 후, Symbol 값을 반환한다.
// 전역 Symbol 레지스트리에 foo라는 키로 저장된 Symbol이 없으면 새로운 Symbol 생성
const s1 = Symbol.for('foo');
// 전역 Symbol 레지스트리에 foo라는 키로 저장된 Symbol이 있으면 해당 Symbol을 반환
const s2 = Symbol.for('foo');
console.log(s1 === s2); // true
Symbol 함수는 매번 다른 Symbol 값을 생성하는 것에 반해, Symbol.for 메소드는 하나의 Symbol을 생성하여 여러 모듈이 키를 통해 같은 Symbol을 공유할 수 있다.
Symbol.for 메소드를 통해 생성된 Symbol 값은 반드시 키를 갖는다. 이에 반해 Symbol 함수를 통해 생성된 Symbol 값은 키가 없다.
const shareSymbol = Symbol.for('myKey');
const key1 = Symbol.keyFor(shareSymbol);
console.log(key1); // myKey
const unsharedSymbol = Symbol('myKey');
const key2 = Symbol.keyFor(unsharedSymbol);
console.log(key2); // undefinedㅤㅤ
📍 Iteration & for of : 이터레이션과 for of 문
1. 이터레이션 프로토콜
ES6에서 도입된 이터레이션 프로토콜(iteration protocol)은 데이터 컬렉션을 순회하기 위한 프로토콜(미리 약속된 규칙)이다. 이터레이션 프로토콜을 준수한 객체는 for…of 문으로 순회할 수 있고 [Spread 문법]의 피연산자가 될 수 있다.
이터레이션 프로토콜에는 이터러블 프로토콜(iterable protocol)과 이터레이터 프로토콜(iterator protocol)이 있다.
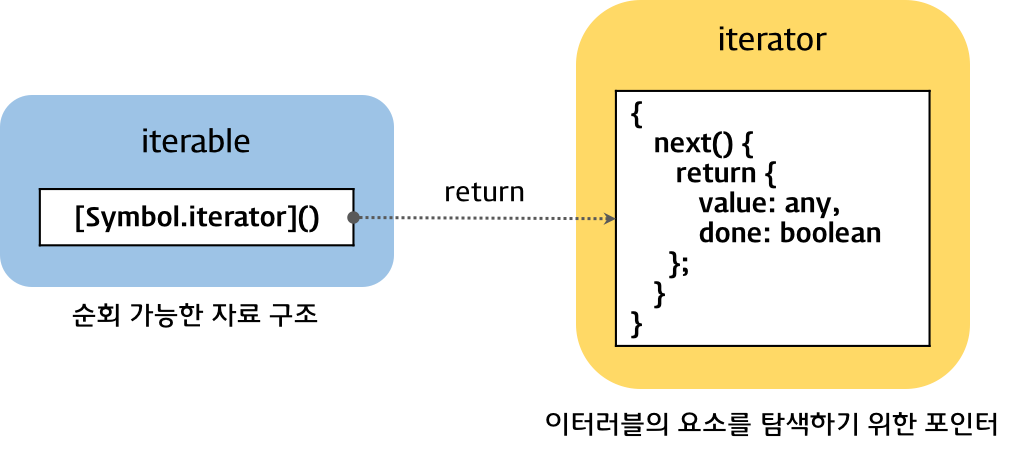
#1.1 이터러블
이터러블 프로토콜을 준수한 객체를 이터러블이라 한다. 이터러블은 Symbol.iterator 메소드를 구현하거나 프로토타입 체인에 의해 상속한 객체를 말한다. Symbol.iterator 메소드는 이터레이터를 반환한다. 이터러블은 for…of 문에서 순회할 수 있으며 Spread 문법의 대상으로 사용할 수 있다.
배열은 Symbol.iterator 메소드를 소유한다. 따라서 배열은 이터러블 프로토콜을 준수한 이터러블이다.
const array = [1, 2, 3];
// 배열은 Symbol.iterator 메소드를 소유한다.
// 따라서 배열은 이터러블 프로토콜을 준수한 이터러블이다.
console.log(Symbol.iterator in array); // true
// 이터러블 프로토콜을 준수한 배열은 for...of 문에서 순회 가능하다.
for (const item of array) {
console.log(item);
}
일반 객체는 Symbol.iterator 메소드를 소유하지 않는다. 따라서 일반 객체는 이터러블 프로토콜을 준수한 이터러블이 아니다.
const obj = { a: 1, b: 2 };
// 일반 객체는 Symbol.iterator 메소드를 소유하지 않는다.
// 따라서 일반 객체는 이터러블 프로토콜을 준수한 이터러블이 아니다.
console.log(Symbol.iterator in obj); // false
// 이터러블이 아닌 일반 객체는 for...of 문에서 순회할 수 없다.
// TypeError: obj is not iterable
for (const p of obj) {
console.log(p);
}
일반 객체는 이터레이션 프로토콜을 준수(Symbol.iterator 메소드를 소유)하지 않기 때문에 이터러블이 아니다. 따라서 일반 객체는 for…of 문에서 순회할 수 없으며 Spread 문법의 대상으로 사용할 수도 없다. 하지만 일반 객체도 이터러블 프로토콜을 준수하도록 구현하면 이터러블이 된다.
#1.2 이터레이터
이터레이터 프로토콜은 next 메소드를 소유하며 next 메소드를 호출하면 이터러블을 순회하며 value, done 프로퍼티를 갖는 이터레이터 리절트 객체를 반환하는 것이다. 이 규약을 준수한 객체가 이터레이터이다.
이터러블 프로토콜을 준수한 이터러블은 Symbol.iterator 메소드를 소유한다. 이 메소드를 호출하면 이터레이터를 반환한다. 이터레이터 프로토콜을 준수한 이터레이터는 next 메소드를 갖는다.
// 배열은 이터러블 프로토콜을 준수한 이터러블이다.
const array = [1, 2, 3];
// Symbol.iterator 메소드는 이터레이터를 반환한다.
const iterator = array[Symbol.iterator]();
// 이터레이터 프로토콜을 준수한 이터레이터는 next 메소드를 갖는다.
console.log('next' in iterator); // true
이터레이터의 next 메소드를 호출하면 value, done 프로퍼티를 갖는 이터레이터 리절트(iterator result) 객체를 반환한다.
// 배열은 이터러블 프로토콜을 준수한 이터러블이다.
const array = [1, 2, 3];
// Symbol.iterator 메소드는 이터레이터를 반환한다.
const iterator = array[Symbol.iterator]();
// 이터레이터 프로토콜을 준수한 이터레이터는 next 메소드를 갖는다.
console.log('next' in iterator); // true
// 이터레이터의 next 메소드를 호출하면 value, done 프로퍼티를 갖는 이터레이터 리절트 객체를 반환한다.
let iteratorResult = iterator.next();
console.log(iteratorResult); // {value: 1, done: false}
이터레이터의 next 메소드는 이터러블의 각 요소를 순회하기 위한 포인터의 역할한다. next 메소드를 호출하면 이터러블을 순차적으로 한 단계씩 순회하며 이터레이터 리절트 객체를 반환한다.
// 배열은 이터러블 프로토콜을 준수한 이터러블이다.
const array = [1, 2, 3];
// Symbol.iterator 메소드는 이터레이터를 반환한다.
const iterator = array[Symbol.iterator]();
// 이터레이터 프로토콜을 준수한 이터레이터는 next 메소드를 갖는다.
console.log('next' in iterator); // true
// 이터레이터의 next 메소드를 호출하면 value, done 프로퍼티를 갖는 이터레이터 리절트 객체를 반환한다.
// next 메소드를 호출할 때 마다 이터러블을 순회하며 이터레이터 리절트 객체를 반환한다.
console.log(iterator.next()); // {value: 1, done: false}
console.log(iterator.next()); // {value: 2, done: false}
console.log(iterator.next()); // {value: 3, done: false}
console.log(iterator.next()); // {value: undefined, done: true}
이터레이터의 next 메소드가 반환하는 이터레이터 리절트 객체의 value 프로퍼티는 현재 순회 중인 이터러블의 값을 반환하고 done 프로퍼티는 이터러블의 순회 완료 여부를 반환한다.
#1.3 빌트인 이터러블
ES6에서 제공하는 빌트인 이터러블은 아래와 같다.
Array, String, Map, Set, TypedArray(Int8Array, Uint8Array, Uint8ClampedArray, Int16Array, Uint16Array, Int32Array, Uint32Array, Float32Array, Float64Array), DOM data structure(NodeList, HTMLCollection), Arguments
// 배열은 이터러블이다.
const array = [1, 2, 3];
// 이터러블은 Symbol.iterator 메소드를 소유한다.
// Symbol.iterator 메소드는 이터레이터를 반환한다.
let iter = array[Symbol.iterator]();
// 이터레이터는 next 메소드를 소유한다.
// next 메소드는 이터레이터 리절트 객체를 반환한다.
console.log(iter.next()); // {value: 1, done: false}
console.log(iter.next()); // {value: 2, done: false}
console.log(iter.next()); // {value: 3, done: false}
console.log(iter.next()); // {value: undefined, done: true}
// 이터러블은 for...of 문으로 순회 가능하다.
for (const item of array) {
console.log(item);
}
// 문자열은 이터러블이다.
const string = 'hi';
// 이터러블은 Symbol.iterator 메소드를 소유한다.
// Symbol.iterator 메소드는 이터레이터를 반환한다.
iter = string[Symbol.iterator]();
// 이터레이터는 next 메소드를 소유한다.
// next 메소드는 이터레이터 리절트 객체를 반환한다.
console.log(iter.next()); // {value: "h", done: false}
console.log(iter.next()); // {value: "i", done: false}
console.log(iter.next()); // {value: undefined, done: true}
// 이터러블은 for...of 문으로 순회 가능하다.
for (const letter of string) {
console.log(letter);
}
// arguments 객체는 이터러블이다.
(function () {
// 이터러블은 Symbol.iterator 메소드를 소유한다.
// Symbol.iterator 메소드는 이터레이터를 반환한다.
iter = arguments[Symbol.iterator]();
// 이터레이터는 next 메소드를 소유한다.
// next 메소드는 이터레이터 리절트 객체를 반환한다.
console.log(iter.next()); // {value: 1, done: false}
console.log(iter.next()); // {value: 2, done: false}
console.log(iter.next()); // {value: undefined, done: true}
// 이터러블은 for...of 문으로 순회 가능하다.
for (const arg of arguments) {
console.log(arg);
}
}(1, 2));
#4. 이터레이션 프로토콜의 필요성
데이터 소비자(Data consumer)인 for…of 문, spread 문법 등은 아래와 같이 다양한 데이터 소스를 사용한다.
Array, String, Map, Set, TypedArray(Int8Array, Uint8Array, Uint8ClampedArray, Int16Array, Uint16Array, Int32Array, Uint32Array, Float32Array, Float64Array), DOM data structure(NodeList, HTMLCollection), Arguments
위 데이터 소스는 모두 이터레이션 프로토콜을 준수하는 이터러블이다. 즉, 이터러블은 데이터 공급자(Data provider)의 역할을 한다.
만약 이처럼 다양한 데이터 소스가 각자의 순회 방식을 갖는다면 데이터 소비자는 다양한 데이터 소스의 순회 방식을 모두 지원해야 한다. 이는 효율적이지 않다. 하지만 다양한 데이터 소스가 이터레이션 프로토콜을 준수하도록 규정하면 데이터 소비자는 이터레이션 프로토콜만을 지원하도록 구현하면 된다.
즉, 이터레이션 프로토콜은 다양한 데이터 소스가 하나의 순회 방식을 갖도록 규정하여 데이터 소비자가 효율적으로 다양한 데이터 소스를 사용할 수 있도록 데이터 소비자와 데이터 소스를 연결하는 인터페이스의 역할을 한다.
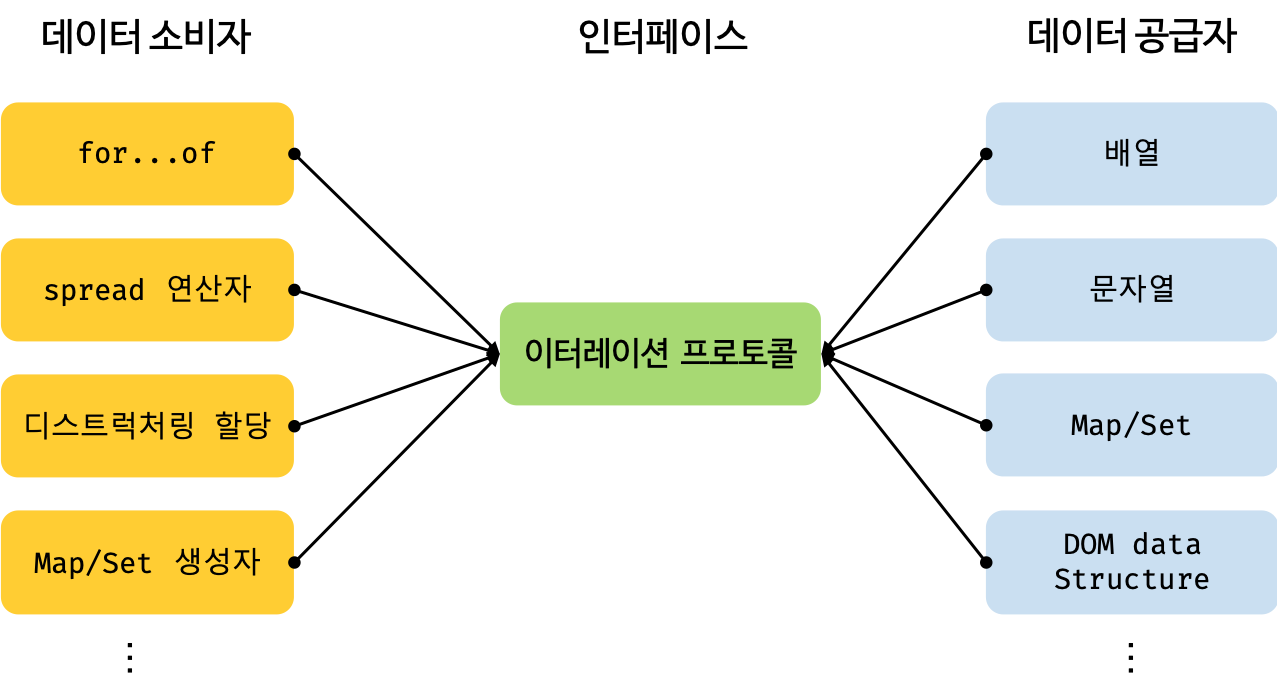
이터러블을 지원하는 데이터 소비자는 내부에서 Symbol.iterator 메소드를 호출해 이터레이터를 생성하고 이터레리터의 next 메소드를 호출하여 이터러블을 순회한다. 그리고 next 메소드가 반환한 이터레이터 리절트 객체의 value 프로퍼티 값을 취득한다.
#2. for…of 문
for…of 문은 내부적으로 이터레이터의 next 메소드를 호출하여 이터러블을 순회하며 next 메소드가 반환한 이터레이터 리절트 객체의 value 프로퍼티 값을 for…of 문의 변수에 할당한다. 그리고 이터레이터 리절트 객체의 done 프로퍼티 값이 false이면 이터러블의 순회를 계속하고 true이면 이터러블의 순회를 중단한다.
// 배열
for (const item of ['a', 'b', 'c']) {
console.log(item);
}
// 문자열
for (const letter of 'abc') {
console.log(letter);
}
// Map
for (const [key, value] of new Map([['a', '1'], ['b', '2'], ['c', '3']])) {
console.log(`key : ${key} value : ${value}`); // key : a value : 1 ...
}
// Set
for (const val of new Set([1, 2, 3])) {
console.log(val);
}
for…of 문이 내부적으로 동작하는 것을 for 문으로 표현하면 아래와 같다.
// 이터러블
const iterable = [1, 2, 3];
// 이터레이터
const iterator = iterable[Symbol.iterator]();
for (;;) {
// 이터레이터의 next 메소드를 호출하여 이터러블을 순회한다.
const res = iterator.next();
// next 메소드가 반환하는 이터레이터 리절트 객체의 done 프로퍼티가 true가 될 때까지 반복한다.
if (res.done) break;
console.log(res);
}
#3. 커스텀 이터러블
#3.1 커스텀 이터러블 구현
일반 객체는 이터러블이 아니다. 일반 객체는 Symbol.iterator 메소드를 소유하지 않는다. 즉, 일반 객체는 이터러블 프로토콜을 준수하지 않으므로 for…of 문으로 순회할 수 없다.
// 일반 객체는 이터러블이 아니다.
const obj = { a: 1, b: 2 };
// 일반 객체는 Symbol.iterator 메소드를 소유하지 않는다.
// 따라서 일반 객체는 이터러블 프로토콜을 준수한 이터러블이 아니다.
console.log(Symbol.iterator in obj); // false
// 이터러블이 아닌 일반 객체는 for...of 문에서 순회할 수 없다.
// TypeError: obj is not iterable
for (const p of obj) {
console.log(p);
}
하지만 일반 객체가 이터레이션 프로토콜을 준수하도록 구현하면 이터러블이 된다. 피보나치 수열(1, 2, 3, 5…)을 구현한 간단한 이터러블을 만들어 보자.
const fibonacci = {
// Symbol.iterator 메소드를 구현하여 이터러블 프로토콜을 준수
[Symbol.iterator]() {
let [pre, cur] = [0, 1];
// 최대값
const max = 10;
// Symbol.iterator 메소드는 next 메소드를 소유한 이터레이터를 반환해야 한다.
// next 메소드는 이터레이터 리절트 객체를 반환
return {
// fibonacci 객체를 순회할 때마다 next 메소드가 호출된다.
next() {
[pre, cur] = [cur, pre + cur];
return {
value: cur,
done: cur >= max
};
}
};
}
};
// 이터러블의 최대값을 외부에서 전달할 수 없다.
for (const num of fibonacci) {
// for...of 내부에서 break는 가능하다.
// if (num >= 10) break;
console.log(num); // 1 2 3 5 8
}
Symbol.iterator 메소드는 next 메소드를 갖는 이터레이터를 반환하여야 한다. 그리고 next 메소드는 done과 value 프로퍼티를 가지는 이터레이터 리절트 객체를 반환한다. for…of 문은 done 프로퍼티가 true가 될 때까지 반복하며 done 프로퍼티가 true가 되면 반복을 중지한다.
이터러블은 for…of 문뿐만 아니라 spread 문법, 디스트럭쳐링 할당, Map과 Set의 생성자에도 사용된다.
// spread 문법과 디스트럭처링을 사용하면 이터러블을 손쉽게 배열로 변환할 수 있다.
// spread 문법
const arr = [...fibonacci];
console.log(arr); // [ 1, 2, 3, 5, 8 ]
// 디스트럭처링
const [first, second, ...rest] = fibonacci;
console.log(first, second, rest); // 1 2 [ 3, 5, 8 ]
#3.2 이터러블을 생성하는 함수
위 fibonacci 이터러블에는 외부에서 값을 전달할 방법이 없다는 아쉬운 점이 있다. fibonacci 이터러블의 최대값을 외부에서 전달할 수 있도록 수정해 보자. 이터러블의 최대 순회수를 전달받아 이터러블을 반환하는 함수를 만들면 된다.
// 이터러블을 반환하는 함수
const fibonacciFunc = function (max) {
let [pre, cur] = [0, 1];
return {
// Symbol.iterator 메소드를 구현하여 이터러블 프로토콜을 준수
[Symbol.iterator]() {
// Symbol.iterator 메소드는 next 메소드를 소유한 이터레이터를 반환해야 한다.
// next 메소드는 이터레이터 리절트 객체를 반환
return {
// fibonacci 객체를 순회할 때마다 next 메소드가 호출된다.
next() {
[pre, cur] = [cur, pre + cur];
return {
value: cur,
done: cur >= max
};
}
};
}
};
};
// 이터러블을 반환하는 함수에 이터러블의 최대값을 전달한다.
for (const num of fibonacciFunc(10)) {
console.log(num); // 1 2 3 5 8
}
#3.3 이터러블이면서 이터레이터인 객체를 생성하는 함수
이터레이터를 생성하려면 이터러블의 Symbol.iterator 메소드를 호출해야 한다. 이터러블이면서 이터레이터인 객체를 생성하면 Symbol.iterator 메소드를 호출하지 않아도 된다.
// 이터러블이면서 이터레이터인 객체를 반환하는 함수
const fibonacciFunc = function (max) {
let [pre, cur] = [0, 1];
// Symbol.iterator 메소드와 next 메소드를 소유한
// 이터러블이면서 이터레이터인 객체를 반환
return {
// Symbol.iterator 메소드
[Symbol.iterator]() {
return this;
},
// next 메소드는 이터레이터 리절트 객체를 반환
next() {
[pre, cur] = [cur, pre + cur];
return {
value: cur,
done: cur >= max
};
}
};
};
// iter는 이터러블이면서 이터레이터이다.
let iter = fibonacciFunc(10);
// iter는 이터레이터이다.
console.log(iter.next()); // {value: 1, done: false}
console.log(iter.next()); // {value: 2, done: false}
console.log(iter.next()); // {value: 3, done: false}
console.log(iter.next()); // {value: 5, done: false}
console.log(iter.next()); // {value: 8, done: false}
console.log(iter.next()); // {value: 13, done: true}
iter = fibonacciFunc(10);
// iter는 이터러블이다.
for (const num of iter) {
console.log(num); // 1 2 3 5 8
}
아래의 객체는 Symbol.iterator 메소드와 next 메소드를 소유한 이터러블이면서 이터레이터이다. Symbol.iterator 메소드는 this를 반환하므로 next 메소드를 갖는 이터레이터를 반환한다.
{
[Symbol.iterator]() {
return this;
},
next() { /***/ }
}
#3.4 무한 이터러블과 Lazy evaluation(지연 평가)
무한 이터러블(infinite sequence)을 생성하는 함수를 정의해보자. 이를 통해 무한 수열(infinite sequence)을 간단히 표현할 수 있다.
// 무한 이터러블을 생성하는 함수
const fibonacciFunc = function () {
let [pre, cur] = [0, 1];
return {
[Symbol.iterator]() {
return this;
},
next() {
[pre, cur] = [cur, pre + cur];
// done 프로퍼티를 생략한다.
return { value: cur };
}
};
};
// fibonacciFunc 함수는 무한 이터러블을 생성한다.
for (const num of fibonacciFunc()) {
if (num > 10000) break;
console.log(num); // 1 2 3 5 8...
}
// 무한 이터러블에서 3개만을 취득한다.
const [f1, f2, f3] = fibonacciFunc();
console.log(f1, f2, f3); // 1 2 3
“[이터레이션 프로토콜의 필요성]“에서 살펴보았듯이 이터러블은 데이터 공급자(Data provider)의 역할을 한다. 배열, 문자열, Map, Set 등의 빌트인 이터러블은 데이터를 모두 메모리에 확보한 다음 동작한다. 하지만 이터러블은 Lazy evaluation(지연 평가)를 통해 값을 생성한다. Lazy evaluation은 평가 결과가 필요할 때까지 평가를 늦추는 기법이다.
위 예제의 fibonacciFunc 함수는 무한 이터러블을 생성한다. 하지만 fibonacciFunc 함수가 생성한 무한 이터러블은 데이터를 공급하는 메커니즘을 구현한 것으로 데이터 소비자인 for…of 문이나 디스트럭처링 할당이 실행되기 이전까지 데이터를 생성하지는 않는다. for…of 문의 경우, 이터러블을 순회할 때 내부에서 이터레이터의 next 메소드를 호출하는데 바로 이때 데이터가 생성된다. next 메소드가 호출되기 이전까지는 데이터를 생성하지 않는다. 즉, 데이터가 필요할 때까지 데이터의 생성을 지연하다가 데이터가 필요한 순간 데이터를 생성한다.
ㅤㅤ
📍 Generator : 제너레이터와 async/await
1. 제너레이터란?
ES6에서 도입된 제너레이터(Generator) 함수는 이터러블을 생성하는 함수이다. 제너레이터 함수를 사용하면 [이터레이션 프로토콜]을 준수해 이터러블을 생성하는 방식보다 간편하게 이터러블을 구현할 수 있다. 또한 제너레이터 함수는 비동기 처리에 유용하게 사용된다.
// 이터레이션 프로토콜을 구현하여 무한 이터러블을 생성하는 함수
const createInfinityByIteration = function () {
let i = 0; // 자유 변수
return {
[Symbol.iterator]() { return this; },
next() {
return { value: ++i };
}
};
};
for (const n of createInfinityByIteration()) {
if (n > 5) break;
console.log(n); // 1 2 3 4 5
}
// 무한 이터러블을 생성하는 제너레이터 함수
function* createInfinityByGenerator() {
let i = 0;
while (true) { yield ++i; }
}
for (const n of createInfinityByGenerator()) {
if (n > 5) break;
console.log(n); // 1 2 3 4 5
}
제너레이터 함수는 일반 함수와는 다른 독특한 동작을 한다. 제너레이터 함수는 일반 함수와 같이 함수의 코드 블록을 한 번에 실행하지 않고 함수 코드 블록의 실행을 일시 중지했다가 필요한 시점에 재시작할 수 있는 특수한 함수이다.
function* counter() {
console.log('첫번째 호출');
yield 1; // 첫번째 호출 시에 이 지점까지 실행된다.
console.log('두번째 호출');
yield 2; // 두번째 호출 시에 이 지점까지 실행된다.
console.log('세번째 호출'); // 세번째 호출 시에 이 지점까지 실행된다.
}
const generatorObj = counter();
console.log(generatorObj.next()); // 첫번째 호출 {value: 1, done: false}
console.log(generatorObj.next()); // 두번째 호출 {value: 2, done: false}
console.log(generatorObj.next()); // 세번째 호출 {value: undefined, done: true}
일반 함수를 호출하면 return 문으로 반환값을 리턴하지만 제너레이터 함수를 호출하면 제너레이터를 반환한다. 이 제너레이터는 이터러블(iterable)이면서 동시에 이터레이터(iterator)인 객체이다. 다시 말해 제너레이터 함수가 생성한 제너레이터는 Symbol.iterator 메소드를 소유한 이터러블이다. 그리고 제너레이터는 next 메소드를 소유하며 next 메소드를 호출하면 value, done 프로퍼티를 갖는 이터레이터 리절트 객체를 반환하는 이터레이터이다.
// 제너레이터 함수 정의
function* counter() {
for (const v of [1, 2, 3]) yield v;
// => yield* [1, 2, 3];
}
// 제너레이터 함수를 호출하면 제너레이터를 반환한다.
let generatorObj = counter();
// 제너레이터는 이터러블이다.
console.log(Symbol.iterator in generatorObj); // true
for (const i of generatorObj) {
console.log(i); // 1 2 3
}
generatorObj = counter();
// 제너레이터는 이터레이터이다.
console.log('next' in generatorObj); // true
console.log(generatorObj.next()); // {value: 1, done: false}
console.log(generatorObj.next()); // {value: 2, done: false}
console.log(generatorObj.next()); // {value: 3, done: false}
console.log(generatorObj.next()); // {value: undefined, done: true}
#2. 제너레이터 함수의 정의
제너레이터 함수는 function* 키워드로 선언한다. 그리고 하나 이상의 yield 문을 포함한다.
// 제너레이터 함수 선언문
function* genDecFunc() {
yield 1;
}
let generatorObj = genDecFunc();
// 제너레이터 함수 표현식
const genExpFunc = function* () {
yield 1;
};
generatorObj = genExpFunc();
// 제너레이터 메소드
const obj = {
* generatorObjMethod() {
yield 1;
}
};
generatorObj = obj.generatorObjMethod();
// 제너레이터 클래스 메소드
class MyClass {
* generatorClsMethod() {
yield 1;
}
}
const myClass = new MyClass();
generatorObj = myClass.generatorClsMethod();
#3. 제너레이터 함수의 호출과 제너레이터 객체
제너레이터 함수를 호출하면 제너레이터 함수의 코드 블록이 실행되는 것이 아니라 제너레이터 객체를 반환한다. 앞에서 살펴본 바와 같이 제너레이터 객체는 이터러블이며 동시에 이터레이터이다. 따라서 next 메소드를 호출하기 위해 Symbol.iterator 메소드로 이터레이터를 별도 생성할 필요가 없다.
// 제너레이터 함수 정의
function* counter() {
console.log('Point 1');
yield 1; // 첫번째 next 메소드 호출 시 여기까지 실행된다.
console.log('Point 2');
yield 2; // 두번째 next 메소드 호출 시 여기까지 실행된다.
console.log('Point 3');
yield 3; // 세번째 next 메소드 호출 시 여기까지 실행된다.
console.log('Point 4'); // 네번째 next 메소드 호출 시 여기까지 실행된다.
}
// 제너레이터 함수를 호출하면 제너레이터 객체를 반환한다.
// 제너레이터 객체는 이터러블이며 동시에 이터레이터이다.
// 따라서 Symbol.iterator 메소드로 이터레이터를 별도 생성할 필요가 없다
const generatorObj = counter();
// 첫번째 next 메소드 호출: 첫번째 yield 문까지 실행되고 일시 중단된다.
console.log(generatorObj.next());
// Point 1
// {value: 1, done: false}
// 두번째 next 메소드 호출: 두번째 yield 문까지 실행되고 일시 중단된다.
console.log(generatorObj.next());
// Point 2
// {value: 2, done: false}
// 세번째 next 메소드 호출: 세번째 yield 문까지 실행되고 일시 중단된다.
console.log(generatorObj.next());
// Point 3
// {value: 3, done: false}
// 네번째 next 메소드 호출: 제너레이터 함수 내의 모든 yield 문이 실행되면 done 프로퍼티 값은 true가 된다.
console.log(generatorObj.next());
// Point 4
// {value: undefined, done: true}
제너레이터 함수가 생성한 제너레이터 객체의 next 메소드를 호출하면 처음 만나는 yield 문까지 실행되고 일시 중단(suspend)된다. 또 다시 next 메소드를 호출하면 중단된 위치에서 다시 실행(resume)이 시작하여 다음 만나는 yield 문까지 실행되고 또 다시 일시 중단된다.
start -> generatorObj.next() -> yield 1 -> generatorObj.next() -> yield 2 -> ... -> end
next 메소드는 이터레이터 리절트 객체와 같이 value, done 프로퍼티를 갖는 객체를 반환한다. value 프로퍼티는 yield 문이 반환한 값이고 done 프로퍼티는 제너레이터 함수 내의 모든 yield 문이 실행되었는지를 나타내는 boolean 타입의 값이다. 마지막 yield 문까지 실행된 상태에서 next 메소드를 호출하면 done 프로퍼티 값은 true가 된다.
#4. 제너레이터의 활용
#4.1 이터러블의 구현
제너레이터 함수를 사용하면 [이터레이션 프로토콜]을 준수해 이터러블을 생성하는 방식보다 간편하게 이터러블을 구현할 수 있다. 이터레이션 프로토콜을 준수하여 무한 피보나치 수열을 생성하는 함수를 구현해 보자.
// 무한 이터러블을 생성하는 함수
const infiniteFibonacci = (function () {
let [pre, cur] = [0, 1];
return {
[Symbol.iterator]() { return this; },
next() {
[pre, cur] = [cur, pre + cur];
// done 프로퍼티를 생략한다.
return { value: cur };
}
};
}());
// infiniteFibonacci는 무한 이터러블이다.
for (const num of infiniteFibonacci) {
if (num > 10000) break;
console.log(num); // 1 2 3 5 8...
}
이터레이션 프로토콜을 보다 간단하게 처리하기 위해 제너레이터를 활용할 수 있다. 제너레이터를 활용하여 무한 피보나치 수열을 구현한 이터러블을 만들어 보자.
// 무한 이터러블을 생성하는 제너레이터 함수
const infiniteFibonacci = (function* () {
let [pre, cur] = [0, 1];
while (true) {
[pre, cur] = [cur, pre + cur];
yield cur;
}
}());
// infiniteFibonacci는 무한 이터러블이다.
for (const num of infiniteFibonacci) {
if (num > 10000) break;
console.log(num);
}
제너레이터 함수에 최대값을 인수를 전달해보자.
// 무한 이터러블을 생성하는 제너레이터 함수
const createInfiniteFibByGen = function* (max) {
let [prev, curr] = [0, 1];
while (true) {
[prev, curr] = [curr, prev + curr];
if (curr >= max) return; // 제너레이터 함수 종료
yield curr;
}
};
for (const num of createInfiniteFibByGen(10000)) {
console.log(num);
}
이터레이터의 next 메소드와 다르게 제너레이터 객체의 next 메소드에는 인수를 전달할 수도 있다. 이를 통해 제너레이터 객체에 데이터를 전달할 수 있다.
function* gen(n) {
let res;
res = yield n; // n: 0 ⟸ gen 함수에 전달한 인수
console.log(res); // res: 1 ⟸ 두번째 next 호출 시 전달한 데이터
res = yield res;
console.log(res); // res: 2 ⟸ 세번째 next 호출 시 전달한 데이터
res = yield res;
console.log(res); // res: 3 ⟸ 네번째 next 호출 시 전달한 데이터
return res;
}
const generatorObj = gen(0);
console.log(generatorObj.next()); // 제너레이터 함수 시작
console.log(generatorObj.next(1)); // 제너레이터 객체에 1 전달
console.log(generatorObj.next(2)); // 제너레이터 객체에 2 전달
console.log(generatorObj.next(3)); // 제너레이터 객체에 3 전달
/*
{ value: 0, done: false }
{ value: 1, done: false }
{ value: 2, done: false }
{ value: 3, done: true }
*/
이터레이터의 next 메소드는 이터러블의 데이터를 꺼내 온다. 이에 반해 제너레이터의 next 메소드에 인수를 전달하면 제너레이터 객체에 데이터를 밀어 넣는다. 제너레이터의 이런 특성은 동시성 프로그래밍을 가능하게 한다.
#4.2 비동기 처리
제너레이터를 사용해 비동기 처리를 동기 처리처럼 구현할 수 있다. 다시 말해 비동기 처리 함수가 처리 결과를 반환하도록 구현할 수 있다.
const fetch = require('node-fetch');
function getUser(genObj, username) {
fetch(`https://api.github.com/users/${username}`)
.then(res => res.json())
// ① 제너레이터 객체에 비동기 처리 결과를 전달한다.
.then(user => genObj.next(user.name));
}
// 제너레이터 객체 생성
const g = (function* () {
let user;
// ② 비동기 처리 함수가 결과를 반환한다.
// 비동기 처리의 순서가 보장된다.
user = yield getUser(g, 'jeresig');
console.log(user); // John Resig
user = yield getUser(g, 'ahejlsberg');
console.log(user); // Anders Hejlsberg
user = yield getUser(g, 'ungmo2');
console.log(user); // Ungmo Lee
}());
// 제너레이터 함수 시작
g.next();
① 비동기 처리가 완료되면 next 메소드를 통해 제너레이터 객체에 비동기 처리 결과를 전달한다.
② 제너레이터 객체에 전달된 비동기 처리 결과는 user 변수에 할당된다.
제너레이터을 통해 비동기 처리를 동기 처리처럼 구현할 수 있으나 코드는 장황해졌다. 따라서 좀 더 간편하게 비동기 처리를 구현할 수 있는 async/await가 ES7에서 도입되었다.
const fetch = require('node-fetch');
// Promise를 반환하는 함수 정의
function getUser(username) {
return fetch(`https://api.github.com/users/${username}`)
.then(res => res.json())
.then(user => user.name);
}
async function getUserAll() {
let user;
user = await getUser('jeresig');
console.log(user);
user = await getUser('ahejlsberg');
console.log(user);
user = await getUser('ungmo2');
console.log(user);
}
getUserAll();본 포스트는 [웹 프로그래밍 튜토리얼 PoiemaWeb의 ECMAScript6] 를 정독하며 정리한 글입니다.
