
📍 Closure : 클로저
#1. 클로저(closure)의 개념
클로저(closure)는 자바스크립트에서 중요한 개념 중 하나다. 클로저는 자바스크립트 고유의 개념이 아니라 함수를 일급 객체로 취급하는 함수형 프로그래밍 언어(Functional Programming language: 얼랭(Erlnag), 스칼라(Scala), 하스켈(Haskell), 리스프(Lisp)…)에서 사용되는 중요한 특성이다.
클로저는 자바스크립트 고유의 개념이 아니므로 ECMAScript 명세에 클로저의 정의가 등장하지 않는다. 클로저에 대해 MDN은 아래와 같이 정의하고 있다.
“A closure is the combination of a function and the lexical environment within which that function was declared.”
클로저는 함수와 그 함수가 선언됐을 때의 렉시컬 환경(Lexical environment)과의 조합이다.
function outerFunc() {
var x = 10;
var innerFunc = function () {
console.log(x);
};
innerFunc();
}
outerFunc(); // 10함수 outerFunc 내에서 내부함수 innerFunc가 선언되고 호출되었다. 이때 내부함수 innerFunc는 자신을 포함하고 있는 외부함수 outerFunc의 변수 x에 접근할 수 있다. 이는 함수 innerFunc가 함수 outerFunc의 내부에 선언되었기 때문이다.
스코프는 함수를 호출할 때가 아니라 함수를 어디에 선언하였는지에 따라 결정된다. 이를 렉시컬 스코핑(Lexical scoping) 이라 한다. 함수 innerFunc는 함수 outerFunc의 내부에서 선언 되었기 때문에 함수 innerFunc의 상위 스코프 는 함수 outerFunc이다. 함수 innerFunc가 전역에 선언되었다면 함수 innerFunc의 상위 스코프는 전역 스코프 가 된다.
따라서, 함수 innerFunc가 함수 outerFunc의 내부에 선언된 내부함수이므로 함수 innerFunc는 자신이 속한 렉시컬 스코프(전역, 함수 outerFunc, 자신의 스코프)를 참조할 수 있다.
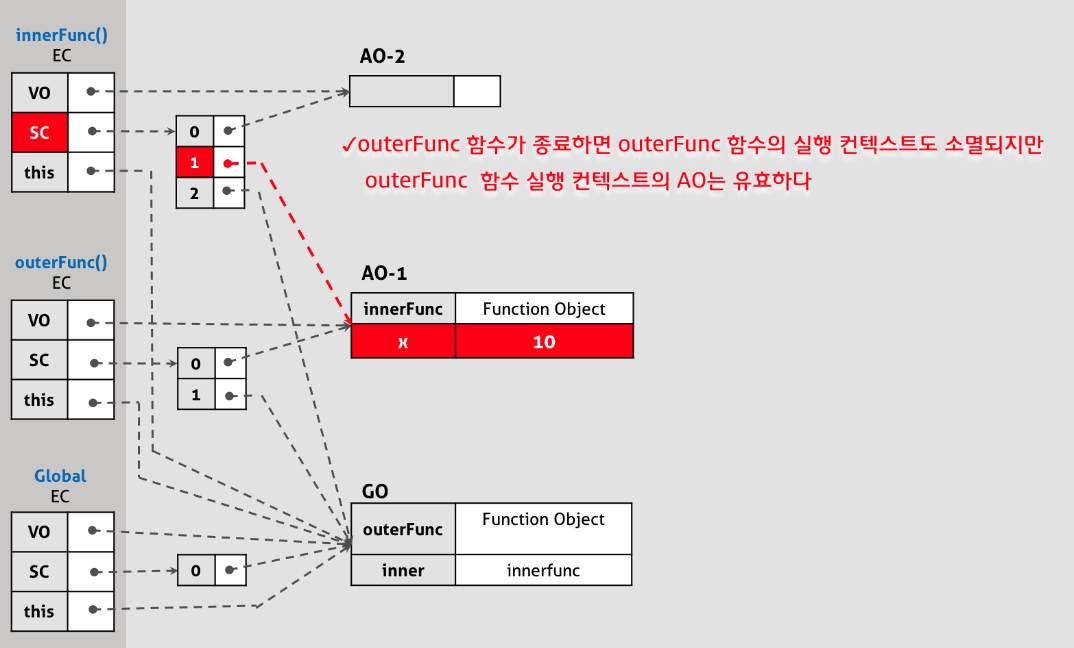
내부함수 innerFunc가 호출되면 자신의 실행 컨텍스트가 실행 컨텍스트 스택에 쌓이고 변수 객체(Variable Object)와 스코프 체인(Scope chain) 그리고 this에 바인딩할 객체가 결정된다.
이때 스코프 체인은 전역 스코프를 가리키는 전역 객체와 함수 outerFunc의 스코프를 가리키는 함수 outerFunc의 활성 객체(Activation object) 그리고 함수 자신의 스코프를 가리키는 활성 객체를 순차적으로 바인딩한다. 스코프 체인이 바인딩한 객체가 바로 렉시컬 스코프의 실체이다.
내부함수 innerFunc가 자신을 포함하고 있는 외부함수 outerFunc의 변수 x에 접근할 수 있는 것, 다시 말해 상위 스코프에 접근할 수 있는 것은 렉시컬 스코프의 레퍼런스를 차례대로 저장하고 있는 실행 컨텍스트의 스코프 체인 을 자바스크립트 엔진이 검색하였기에 가능한 것이다.
- innerFunc 함수 스코프(함수 자신의 스코프를 가리키는 활성 객체) 내에서 변수 x를 검색한다. 검색이 실패하였다.
- innerFunc 함수를 포함하는 외부 함수 outerFunc의 스코프(함수 outerFunc의 스코프를 가리키는 함수 outerFunc의 활성 객체)에서 변수 x를 검색한다. 검색이 성공하였다.
이번에는 내부함수 innerFunc를 함수 outerFunc 내에서 호출하는 것이 아니라 반환하도록 변경한다.
function outerFunc() {
var x = 10;
var innerFunc = function () {
console.log(x);
};
return innerFunc;
}
/**
* 함수 outerFunc를 호출하면 내부 함수 innerFunc가 반환된다.
* 그리고 함수 outerFunc의 실행 컨텍스트는 소멸한다.
*/
var inner = outerFunc();
inner(); // 10함수 outerFunc는 내부함수 innerFunc를 반환하고 생을 마감했다. 즉, 함수 outerFunc는 실행된 이후 콜스택(실행 컨텍스트 스택)에서 제거되었으므로 함수 outerFunc의 변수 x 또한 더이상 유효하지 않게 되어 변수 x에 접근할 수 있는 방법은 달리 없어 보인다. 그러나 위 코드의 실행 결과는 변수 x의 값인 10이다. 이미 life-cycle이 종료되어 실행 컨텍스트 스택에서 제거된 함수 outerFunc의 지역변수 x가 다시 부활이라도 한 듯이 동작하고 있다.
이처럼 자신을 포함하고 있는 외부함수보다 내부함수가 더 오래 유지되는 경우, 외부 함수 밖에서 내부함수가 호출되더라도 외부함수의 지역 변수에 접근할 수 있는데 이러한 함수를
클로저(Closure)라고 부른다.
MDN 정의
“A closure is the combination of a function and the lexical environment within which that function was declared.”
클로저는 함수와 그 함수가 선언됐을 때의 렉시컬 환경(Lexical environment)과의 조합이다.
위 정의에서 말하는 “함수” 란 반환된 내부함수 를 의미 하고 “그 함수가 선언될 때의 렉시컬 환경” 이란 내부 함수가 선언됐을 때의 스코프를 의미한다. 즉, 클로저 는 반환된 내부함수가 자신이 선언됐을 때의 환경인 스코프를 기억하여 자신이 선언됐을 때의 환경(스코프) 밖에서 호출되어도 그 환경(스코프)에 접근할 수 있는 함수를 말한다. 조금 더 간단히 말하면 클로저는 자신이 생성될 때의 환경을 기억하는 함수 다.
클로저에 의해 참조되는 외부함수의 변수 즉 outerFunc 함수의 변수 x를 자유변수(Free variable) 라고 부른다. 클로저라는 이름은 자유변수에 함수가 닫혀있다(closed)라는 의미로 의역하면 자유변수에 엮여있는 함수 라는 뜻이다.
실행 컨텍스트 의 관점에 설명하면, 내부함수가 유효한 상태에서 외부함수가 종료하여 외부함수의 실행 컨텍스트가 반환되어도, 외부함수 실행 컨텍스트 내의 활성 객체(Activation object) 는 내부함수에 의해 참조되는 한 유효하여 내부함수가 스코프 체인 을 통해 참조할 수 있는 것을 의미한다.
즉 외부함수가 이미 반환 되었어도 외부함수 내의 변수 는 이를 필요로 하는 내부함수가 하나 이상 존재 하는 경우 계속 유지된다. 이때 내부함수가 외부함수에 있는 변수의 복사본이 아니라 실제 변수에 접근 한다는 것에 주의하여야 한다.
#2. 클로저의 활용
클로저 는 자신이 생성될 때의 환경을 기억해야 하므로 메모리 차원에서 손해 를 볼 수 있다. 하지만 클로저는 자바스크립트의 강력한 기능으로 이를 적극적으로 사용해야 한다. 아래는 클로저가 유용하게 사용되는 상황이다.
#2.1 상태 유지
클로저가 가장 유용하게 사용되는 상황은
현재 상태를 기억하고변경된 최신 상태를 유지하는 것이다.
<!DOCTYPE html>
<html>
<body>
<button class="toggle">toggle</button>
<div class="box" style="width: 100px; height: 100px; background: red;"></div>
<script>
var box = document.querySelector('.box');
var toggleBtn = document.querySelector('.toggle');
var toggle = (function () {
var isShow = false;
// ① 클로저를 반환
return function () {
box.style.display = isShow ? 'block' : 'none';
// ③ 상태 변경
isShow = !isShow;
};
})();
// ② 이벤트 프로퍼티에 클로저를 할당
toggleBtn.onclick = toggle;
</script>
</body>
</html>① 즉시실행함수는 함수를 반환하고 즉시 소멸한다. 즉시실행함수가 반환한 함수는 자신이 생성됐을 때의 렉시컬 환경(Lexical environment)에 속한 변수 isShow를 기억하는 클로저다. 클로저가 기억하는 변수 isShow는 box 요소의 표시 상태를 나타낸다.
② 클로저를 이벤트 핸들러로서 이벤트 프로퍼티에 할당했다. 이벤트 프로퍼티에서 이벤트 핸들러인 클로저를 제거하지 않는 한 클로저가 기억하는 렉시컬 환경의 변수 isShow는 소멸하지 않는다. 다시 말해 현재 상태를 기억한다.
③ 버튼을 클릭하면 이벤트 프로퍼티에 할당한 이벤트 핸들러인 클로저가 호출된다. 이때 .box 요소의 표시 상태를 나타내는 변수 isShow의 값이 변경된다. 변수 isShow는 클로저에 의해 참조되고 있기 때문에 유효하며 자신의 변경된 최신 상태를 게속해서 유지한다.
이처럼 클로저는 현재 상태를 기억 하고 이 상태가 변경되어도 최신 상태를 유지 해야 하는 상황에 매우 유용하다. 만약 자바스크립트에 클로저라는 기능이 없다면 상태를 유지하기 위해 전역 변수 를 사용할 수 밖에 없다. 전역 변수는 언제든지 누구나 접근할 수 있고 변경 할 수 있기 때문에 많은 부작용을 유발 해 오류의 원인이 되므로 사용을 억제해야 한다.
#2.2 전역 변수의 사용 억제
<!DOCTYPE html>
<html>
<body>
<p>전역 변수를 사용한 Counting</p>
<button id="inclease">+</button>
<p id="count">0</p>
<script>
var incleaseBtn = document.getElementById('inclease');
var count = document.getElementById('count');
// 카운트 상태를 유지하기 위한 전역 변수
var counter = 0;
function increase() {
return ++counter;
}
incleaseBtn.onclick = function () {
count.innerHTML = increase();
};
</script>
</body>
</html>위 코드는 잘 동작하지만 오류를 발생시킬 가능성을 내포하고 있는 좋지 않은 코드다. increase 함수는 호출되기 직전에 전역변수 counter의 값이 반드시 0 이여야 제대로 동작한다. 하지만 변수 counter는 전역 변수 이기 때문에 언제든지 누구나 접근할 수 있고 변경 할 수 있다. 이는 의도치 않게 값이 변경될 수 있다 는 것을 의미한다. 만약 누군가에 의해 의도치 않게 전역 변수 counter의 값이 변경됐다면 이는 오류로 이어진다. 변수 counter는 카운터를 관리하는 increase 함수가 관리하는 것이 바람직하다.
<!DOCTYPE html>
<html>
<body>
<p>지역 변수를 사용한 Counting</p>
<button id="inclease">+</button>
<p id="count">0</p>
<script>
var incleaseBtn = document.getElementById('inclease');
var count = document.getElementById('count');
function increase() {
// 카운트 상태를 유지하기 위한 지역 변수
var counter = 0;
return ++counter;
}
incleaseBtn.onclick = function () {
count.innerHTML = increase();
};
</script>
</body>
</html>전역변수를 지역변수로 변경하여 의도치 않은 상태 변경은 방지했다. 하지만 increase 함수가 호출될 때마다 지역변수 counter를 0으로 초기화하기 때문에 언제나 1이 표시된다. 다시 말해 변경된 이전 상태를 기억하지 못한다. 이전 상태를 기억하도록 클로저를 사용하여 이 문제를 해결 할 수 있다.
<!DOCTYPE html>
<html>
<body>
<p>클로저를 사용한 Counting</p>
<button id="inclease">+</button>
<p id="count">0</p>
<script>
var incleaseBtn = document.getElementById('inclease');
var count = document.getElementById('count');
var increase = (function () {
// 카운트 상태를 유지하기 위한 자유 변수
var counter = 0;
// 클로저를 반환
return function () {
return ++counter;
};
})();
incleaseBtn.onclick = function () {
count.innerHTML = increase();
};
</script>
</body>
</html>스크립트가 실행되면 즉시실행함수가 호출되고 변수 increase에는 함수 function () { return ++counter; } 가 할당된다. 이 함수는 자신이 생성됐을 때의 렉시컬 환경을 기억하는 클로저 다.
즉시실행함수는 호출된 이후 소멸되지만 즉시실행함수가 반환한 함수는 변수 increase에 할당되어 increase 버튼을 클릭하면 클릭 이벤트 핸들러 내부에서 호출된다. 이때 클로저인 이 함수는 자신이 선언됐을 때의 렉시컬 환경인 즉시실행함수의 스코프에 속한 지역변수 counter를 기억한다. 따라서 즉시실행함수의 변수 counter에 접근할 수 있고 변수 counter는 자신을 참조하는 함수가 소멸될 때까지 유지된다.
즉시실행함수는 한번만 실행되므로 increase가 호출될 때마다 변수 counter가 재차 초기화될 일은 없을 것이다. 변수 counter는 외부에서 직접 접근할 수 없는 private 변수이므로 전역 변수를 사용했을 때와 같이 의도되지 않은 변경 을 걱정할 필요도 없기 때문이 보다 안정적인 프로그래밍이 가능하다.
변수의 값은 누군가에 의해 언제든지 변경될 수 있어 오류 발생의 근본적 원인이 될 수 있다. 상태 변경 이나 가변 데이터를 피하고 불변성 을 지향하는 함수형 프로그래밍에서 부수 효과를 최대한 억제 하여 오류를 피하고 프로그램의 안정성을 높이기 위해 클로저는 적극적으로 사용된다.
// 함수를 인자로 전달받고 함수를 반환하는 고차 함수
// 이 함수가 반환하는 함수는 클로저로서 카운트 상태를 유지하기 위한 자유 변수 counter을 기억한다.
function makeCounter(predicate) {
// 카운트 상태를 유지하기 위한 자유 변수
var counter = 0;
// 클로저를 반환
return function () {
counter = predicate(counter);
return counter;
};
}
// 보조 함수
function increase(n) {
return ++n;
}
// 보조 함수
function decrease(n) {
return --n;
}
// 함수로 함수를 생성한다.
// makeCounter 함수는 보조 함수를 인자로 전달받아 함수를 반환한다
const increaser = makeCounter(increase);
console.log(increaser()); // 1
console.log(increaser()); // 2
// increaser 함수와는 별개의 독립된 렉시컬 환경을 갖기 때문에 카운터 상태가 연동하지 않는다.
const decreaser = makeCounter(decrease);
console.log(decreaser()); // -1
console.log(decreaser()); // -2함수 makeCounter는 보조 함수를 인자 로 전달받고 함수를 반환 하는 고차 함수이다. 함수 makeCounter가 반환하는 함수는 자신이 생성됐을 때의 렉시컬 환경인 함수 makeCounter의 스코프에 속한 변수 counter을 기억하는 클로저다. 함수 makeCounter는 인자로 전달받은 보조 함수를 합성하여 자신이 반환하는 함수의 동작을 변경할 수 있다.
이때 주의해야 할 것은 함수 makeCounter를 호출해 함수를 반환할 때 반환된 함수는 자신만의 독립된 렉시컬 환경을 갖는다 는 것이다. 이는 함수를 호출하면 그때마다 새로운 렉시컬 환경이 생성 되기 때문이다. 위 예제에서 변수 increaser와 변수 decreaser에 할당된 함수는 각각 자신만의 독립된 렉시컬 환경을 갖기 때문에 카운트를 유지하기 위한 자유 변수 counter를 공유하지 않아 카운터의 증감이 연동하지 않는다. 따라서 독립된 카운터가 아니라 연동하여 증감이 가능한 카운터를 만들려면 렉시컬 환경을 공유하는 클로저 를 만들어야 한다.
#2.3 정보의 은닉
이번에는 생성자 함수 Counter를 생성하고 이를 통해 counter 객체를 만든다.
function Counter() {
// 카운트를 유지하기 위한 자유 변수
var counter = 0;
// 클로저
this.increase = function () {
return ++counter;
};
// 클로저
this.decrease = function () {
return --counter;
};
}
const counter = new Counter();
console.log(counter.increase()); // 1
console.log(counter.decrease()); // 0생성자 함수 Counter는 increase, decrease 메소드를 갖는 인스턴스를 생성한다. 이 메소드들은 모두 자신이 생성됐을 때의 렉시컬 환경인 생성자 함수 Counter의 스코프에 속한 변수 counter를 기억하는 클로저이며 렉시컬 환경을 공유 한다. 생성자 함수가 함수가 생성한 객체의 메소드는 객체의 프로퍼티에만 접근할 수 있는 것이 아니며 자신이 기억하는 렉시컬 환경의 변수에도 접근할 수 있다.
이때 생성자 함수 Counter의 변수 counter는 this에 바인딩된 프로퍼티가 아니라 변수다. counter가 this에 바인딩된 프로퍼티라면 생성자 함수 Counter가 생성한 인스턴스를 통해 외부에서 접근이 가능한 public 프로퍼티가 되지만 생성자 함수 Counter 내에서 선언된 변수 counter는 생성자 함수 Counter 외부에서 접근할 수 없다. 하지만 생성자 함수 Counter가 생성한 인스턴스의 메소드인 increase, decrease는 클로저이기 때문에 자신이 생성됐을 때의 렉시컬 환경인 생성자 함수 Counter의 변수 counter에 접근할 수 있다. 이러한 클로저의 특징을 사용해 클래스 기반 언어의 private 키워드를 흉내낼 수 있다.
#2.4 자주 발생하는 실수
var arr = [];
for (var i = 0; i < 5; i++) {
arr[i] = function () {
return i;
};
}
for (var j = 0; j < arr.length; j++) {
console.log(arr[j]());
}배열 arr에 5개의 함수가 할당되고 각각의 함수는 순차적으로 0 1 2 3 4 를 반환할 것으로 기대하겠지만 결과는 그렇지않다. for문 에서 사용한 변수 i 는 전역 변수 이기 때문이다.
var arr = [];
for (var i = 0; i < 5; i++) {
arr[i] = (function (id) {
// ②
return function () {
return id; // ③
};
})(i); // ①
}
for (var j = 0; j < arr.length; j++) {
console.log(arr[j]());
}① 배열 arr에는 즉시실행함수에 의해 함수가 반환된다.
② 이때 즉시실행함수는 i를 인자로 전달받고 매개변수 id에 할당한 후 내부 함수를 반환하고 life-cycle이 종료된다. 매개변수 id는 자유변수가 된다.
③ 배열 arr에 할당된 함수는 id를 반환한다. 이때 id는 상위 스코프의 자유변수이므로 그 값이 유지된다.
위 예제는 자바스크립트의 함수 레벨 스코프 특성으로 인해 for 루프의 초기문에서 사용된 변수의 스코프가 전역이 되기 때문에 발생하는 현상이다. ES6의 let 키워드 사용하면 이와 같은 문제는 해결된다.
let arr = [];
for (let i = 0; i < 5; i++) {
arr[i] = function () {
return i;
};
}
for (let i = 0; i < arr.length; i++) {
console.log(arr[i]());
}또는 함수형 프로그래밍 기법인 고차 함수 를 사용하는 방법이 있다. 이 방법은 변수와 반복문의 사용을 억제할 수 있기 때문에 에플리케이션의 오류를 줄이고 가독성을 좋게 만든다.
const arr = new Array(5).fill();
arr.forEach((v, i, array) => (array[i] = () => i));
arr.forEach((f) => console.log(f()));ㅤㅤ
📍 Object-Oriented Programming : 자바스크립트 객체지향 프로그래밍
#1. 객체지향 프로그래밍 (Object-Oriented Programming) 개요
오늘날 많은 유명한 프로그래밍 언어(Java, C++, C#, Python, PHP, Ruby, Object-C)는 객체지향 프로그래밍 을 지원한다. 객체지향 이라는 개념은 불행히도 명확한 정의가 없는 것이 특징이다.
객체지향 프로그래밍은 실세계에 존재하고 인지하고 있는 객체(Object) 를 소프트웨어의 세계에서 표현하기 위해 객체의 핵심적인 개념 또는 기능만을 추출하는 추상화(abstraction)를 통해 모델링하려는 프로그래밍 패러다임을 말한다. 다시 말해, 우리가 주변의 실세계에서 사물을 인지하는 방식을 프로그래밍에 접목하려는 사상을 의미한다.
객체지향 프로그래밍은 함수들의 집합 혹은 단순한 컴퓨터의 명령어들의 목록이라는 전통적인 절차지향 프로그래밍과는 다른, 관계성있는 객체들의 집합이라는 관점으로 접근하는 소프트웨어 디자인으로 볼 수 있다. 각 객체는 메시지를 받을 수도 있고, 데이터를 처리할 수도 있으며, 또다른 객체에게 메시지를 전달할 수도 있다. 각 객체는 별도의 역할이나 책임을 갖는 작은 독립적인 기계 또는 부품으로 볼 수 있다.
객체지향 프로그래밍은 보다 유연하고 유지보수하기 쉬우며 확장성 측면에서서도 유리한 프로그래밍을 하도록 의도되었고, 대규모 소프트웨어 개발에 널리 사용되고 있다.
#2. 클래스 기반 vs. 프로토타입 기반
#2.1 클래스 기반 언어
클래스 기반 언어(Java, C++, C#, Python, PHP, Ruby, Object-C)는 클래스 로 객체의 자료구조와 기능을 정의하고 생성자를 통해 인스턴스를 생성한다.
클래스란 같은 종류의 집단에 속하는 속성(attribute) 과 행위(behavior) 를 정의한 것으로 객체지향 프로그램의 기본적인 사용자 정의 데이터형(user define data type)이라고 할 수 있다. 결국 클래스는 객체 생성에 사용되는 패턴 혹은 청사진(blueprint)일 뿐이며 new 연산자 를 통한 인스턴스화 과정이 필요하다.
모든 인스턴스는 오직 클래스에서 정의된 범위 내에서만 작동하며 런타임에 그 구조를 변경할 수 없다. 이러한 특성은 정확성 안정성 예측성 측면에서 클래스 기반 언어가 프로토타입 기반 언어보다 좀 더 나은 결과를 보장한다.
아래의 예제는 Java로 구현된 클래스이다. Java는 class 키워드를 제공하고 이것으로 클래스를 정의한다. 생성자는 클래스명과 동일하며 메소드로 구현된다.
class Person {
private String name;
public Person(String name) {
this.name = name;
}
public void setName(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
public static void main(String[] args) {
Person me = new Person("Lee");
String name= me.getName();
System.out.println(name); // Lee
}
}
#2.2 프로토타입 기반 언어
자바스크립트는 멀티-패러다임 언어로 명령형(imperative) 함수형(functional) 프로토타입 기반(prototype-based) 객체지향 언어다. 비록 다른 객체지향 언어들과의 차이점에 대한 논쟁들이 있긴 하지만, 자바스크립트는 강력한 객체지향 프로그래밍 능력들을 지니고 있다. 간혹 클래스가 없어서 객체지향이 아니라고 생각하는 사람들도 있으나 프로토타입 기반의 객체지향 언어다.
자바스크립트는 클래스 개념이 없고 별도의 객체 생성 방법이 존재한다.
- 객체 리터럴
- Object() 생성자 함수
- 생성자 함수
// 객체 리터럴
var obj1 = {};
obj1.name = 'Lee';
// Object() 생성자 함수
var obj2 = new Object();
obj2.name = 'Lee';
// 생성자 함수
function F() {}
var obj3 = new F();
obj3.name = 'Lee';자바스크립트는 이미 생성된 인스턴스의 자료구조와 기능을 동적으로 변경할 수 있다는 특징이 있다. 객체 지향의 상속, 캡슐화(정보 은닉) 등의 개념은 프로토타입 체인과 클로저 등으로 구현할 수 있다.
클래스 기반 언어에 익숙한 프로그래머들은 이러한 프로토타입 기반의 특성으로 인해 혼란을 느낀다. 자바스크립트에서는 함수 객체로 많은 것을 할 수 있는데 클래스 생성자 메소드도 모두 함수로 구현이 가능하다.
ES6에서 새롭게
Class가 도입되었다. ES6의 Class는 기존 prototype 기반 객체지향 프로그래밍보다 Class 기반 언어에 익숙한 프로그래머가 보다 빠르게 학습할 수 있는 단순하고 깨끗한 새로운 문법을 제시하고 있다. ES6의 Class가 새로운 객체지향 모델을 제공하는 것이 아니며 Class도 사실 함수이고 기존 prototype 기반 패턴의 Syntactic sugar이다.
#3. 생성자 함수와 인스턴스의 생성
자바스크립트는
생성자 함수와new 연산자를 통해 인스턴스를 생성할 수 있다. 이때 생성자 함수는 클래스이자 생성자의 역할을 한다.
// 생성자 함수(Constructor)
function Person(name) {
// 프로퍼티
this.name = name;
// 메소드
this.setName = function (name) {
this.name = name;
};
// 메소드
this.getName = function () {
return this.name;
};
}
// 인스턴스의 생성
var me = new Person('Lee');
console.log(me.getName()); // Lee
// 메소드 호출
me.setName('Kim');
console.log(me.getName()); // Kim위 코드는 잘 동작 하지만 문제가 많다.
var me = new Person('Lee');
var you = new Person('Kim');
var him = new Person('Choi');
console.log(me); // Person { name: 'Lee', setName: [Function], getName: [Function] }
console.log(you); // Person { name: 'Kim', setName: [Function], getName: [Function] }
console.log(him); // Person { name: 'Choi', setName: [Function], getName: [Function] }위와 같이 Person 생성자 함수로 여러개의 인스턴스를 생성하면 각각의 인스턴스에 메소드 setName, getName이 중복되어 생성된다. 즉, 각 인스턴스가 내용이 동일한 메소드를 각자 소유한다. 이는 메모리 낭비인데 생성되는 인스턴스가 많아지거나 메소드가 크거나 많다면 무시할 수 없는 문제이다. 이 같은 문제를 해결하려면 다른 접근 방식이 필요한데 그 해답은 프로토타입이다.
#4. 프로토타입 체인과 메소드의 정의
모든 객체는 프로토타입 이라는 다른 객체를 가리키는 내부 링크를 가지고 있다. 즉, 프로토타입을 통해 직접 객체를 연결할 수 있는데 이를 프로토타입 체인이라 한다.
프로토타입을 이용하여 생성자 함수 내부의 메소드 를 생성자 함수의 prototype 프로퍼티가 가리키는 프로토타입 객체 로 이동시키면 생성자 함수에 의해 생성된 모든 인스턴스는 프로토타입 체인을 통해 프로토타입 객체의 메소드를 참조할 수 있다.
function Person(name) {
this.name = name;
}
// 프로토타입 객체에 메소드 정의
Person.prototype.setName = function (name) {
this.name = name;
};
// 프로토타입 객체에 메소드 정의
Person.prototype.getName = function () {
return this.name;
};
var me = new Person('Lee');
var you = new Person('Kim');
var him = new Person('choi');
console.log(Person.prototype);
// Person { setName: [Function], getName: [Function] }
console.log(me); // Person { name: 'Lee' }
console.log(you); // Person { name: 'Kim' }
console.log(him); // Person { name: 'choi' }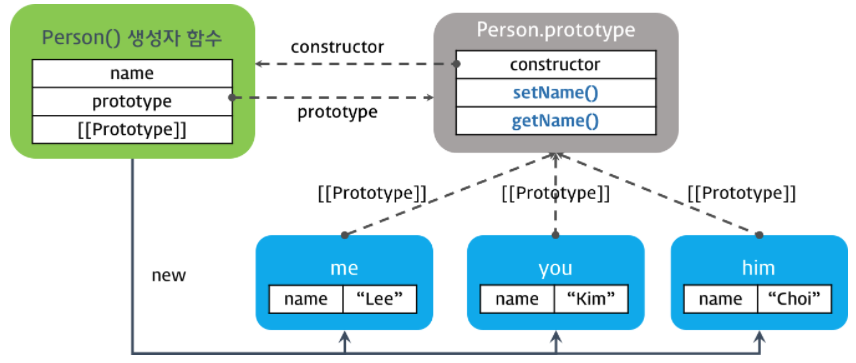
Person 생성자 함수의 prototype 프로퍼티가 가리키는 프로토타입 객체로 이동시킨 setName. getName 메소드는 프로토타입 체인에 의해 모든 인스턴스가 참조할 수 있다. 프로토타입 객체는 상속할 것들이 저장되는 장소이다.
/**
* 모든 생성자 함수의 프로토타입은 Function.prototype이다. 따라서 모든 생성자 함수는 Function.prototype.method()에 접근할 수 있다.
* @method Function.prototype.method
* @param ({string}) (name) - (메소드 이름)
* @param ({function}) (func) - (추가할 메소드 본체)
*/
Function.prototype.method = function (name, func) {
// 생성자함수의 프로토타입에 동일한 이름의 메소드가 없으면 생성자함수의 프로토타입에 메소드를 추가
// this: 생성자함수
if (!this.prototype[name]) {
this.prototype[name] = func;
}
};
/**
* 생성자 함수
*/
function Person(name) {
this.name = name;
}
/**
* 생성자함수 Person의 프로토타입에 메소드 setName을 추가
*/
Person.method('setName', function (name) {
this.name = name;
});
/**
* 생성자함수 Person의 프로토타입에 메소드 getName을 추가
*/
Person.method('getName', function () {
return this.name;
});
var me = new Person('Lee');
var you = new Person('Kim');
var him = new Person('choi');
console.log(Person.prototype);
// Person { setName: [Function], getName: [Function] }
console.log(me); // Person { name: 'Lee' }
console.log(you); // Person { name: 'Kim' }
console.log(him); // Person { name: 'choi' }#5. 상속 (Inheritance)
Java같은 클래스 기반 언어에서 상속(또는 확장)은 코드 재사용 의 관점에서 매우 유용하다. 새롭게 정의할 클래스가 기존에 있는 클래스와 매우 유사하다면, 상속을 통해 다른 점만 구현하면 된다. 코드 재사용은 개발 비용을 현저히 줄일 수 있는 잠재력이 있기 때문에 매우 중요하다.
클래스 기반 언어에서 객체는 클래스의 인스턴스이며 클래스는 다른 클래스로 상속될 수 있다. 자바스크립트는 기본적으로 프로토타입을 통해 상속을 구현한다. 이것은 프로토타입을 통해 객체가 다른 객체로 직접 상속 된다는 의미이다. 이러한 점이 자바스크립트의 약점으로 여겨지기도 하지만 프로토타입 상속 모델은 사실 클래스 기반보다 강력한 방법이다.
자바스크립트의 상속 구현 방식은 크게 두 가지로 구분할 수 있다. 하나는 클래스 기반 언어의 상속 방식을 흉내 내는 것(의사 클래스 패턴 상속. Pseudo-classical Inheritance)이고, 두번째는 프로토타입으로 상속을 구현하는 것(프로토타입 패턴 상속. Prototypal Inheritance)이다.
#5.1 의사 클래스 패턴 상속 (Pseudo-classical Inheritance)
의사 클래스 패턴은 자식 생성자 함수의 prototype 프로퍼티 를 부모 생성자 함수의 인스턴스 로 교체하여 상속을 구현하는 방법이다. 부모와 자식 모두 생성자 함수를 정의하여야 한다.
// 부모 생성자 함수
var Parent = (function () {
// Constructor
function Parent(name) {
this.name = name;
}
// method
Parent.prototype.sayHi = function () {
console.log('Hi! ' + this.name);
};
// return constructor
return Parent;
})();
// 자식 생성자 함수
var Child = (function () {
// Constructor
function Child(name) {
this.name = name;
}
// 자식 생성자 함수의 프로토타입 객체를 부모 생성자 함수의 인스턴스로 교체.
Child.prototype = new Parent(); // ②
// 메소드 오버라이드
Child.prototype.sayHi = function () {
console.log('안녕하세요! ' + this.name);
};
// sayBye 메소드는 Parent 생성자함수의 인스턴스에 위치된다
Child.prototype.sayBye = function () {
console.log('안녕히가세요! ' + this.name);
};
// return constructor
return Child;
})();
var child = new Child('child'); // ①
console.log(child); // Parent { name: 'child' }
console.log(Child.prototype); // Parent { name: undefined, sayHi: [Function], sayBye: [Function] }
child.sayHi(); // 안녕하세요! child
child.sayBye(); // 안녕히가세요! child
console.log(child instanceof Parent); // true
console.log(child instanceof Child); // trueChild 생성자 함수가 생성한 인스턴스 child(①)의 프로토타입 객체는 Parent 생성자 함수가 생성한 인스턴스(②)이다. 그리고 Parent 생성자 함수가 생성한 인스턴스의 프로토타입 객체는 Parent.prototype이다.
이로써 child는 프로토타입 체인에 의해 Parent 생성자 함수가 생성한 인스턴스 와 Parent.prototype의 모든 프로퍼티 에 접근할 수 있게 되었다. 이름은 의사 클래스 패턴 상속이지만 내부에서는 프로토타입을 사용하는 것은 변함이 없다.
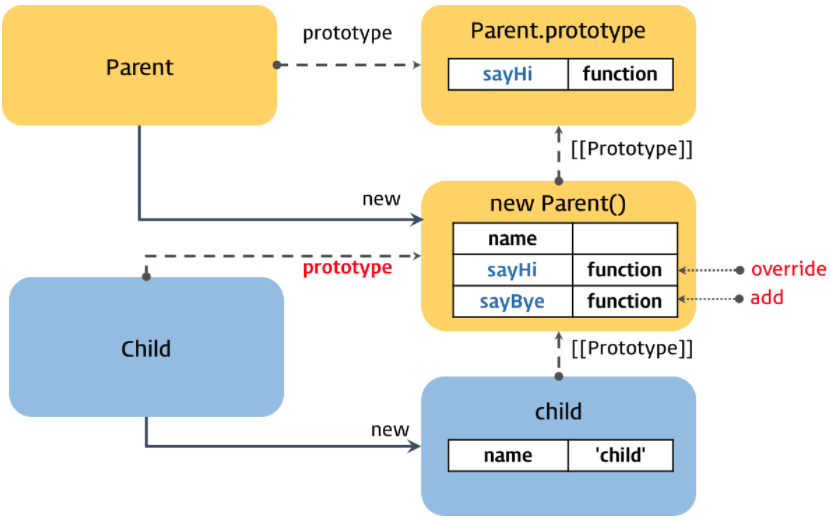
의사 클래스 패턴은 클래스 기반 언어의 상속을 흉내내어 상속을 구현하였다. 구동 상에 문제는 없지만 의사 클래스 패턴은 아래와 같은 문제를 가지고 있다.
1. new 연산자를 통해 인스턴스를 생성한다.
이는 자바스크립트의 프로토타입 본질에 모순되는 것이다. 프로토타입 본성에 맞게 객체에서 다른 객체로 직접 상속하는 방법을 갖는 대신 생성자 함수 와 new 연산자 를 통해 객체를 생성하는 불필요한 간접적인 단계가 있다. 클래스와 비슷하게 보이는 일부 복잡한 구문은 프로토타입 메커니즘을 명확히 나타내지 못하게 한다.
게다가 생성자 함수의 사용에는 심각한 위험이 존재한다. 만약 생성자 함수를 호출할 때 new 연산자를 포함하는 것을 잊게 되면 this 는 새로운 객체 와 바인딩되지 않고 전역객체 에 바인딩된다. (new 연산자와 함께 호출된 생성자 함수 내부의 this는 새로 생성된 객체를 참조한다.)
이런 문제점을 경감시키기 위해
파스칼 표시법(첫글자를 대문자 표기)으로 생성자 함수 이름을 표기하는 방법을 사용하지만, 더 나은 대안은 new 연산자의 사용을 피하는 것이다.
2. 생성자 링크의 파괴
위 그림을 보면 child 객체의 프로토타입 객체는 Parent 생성자 함수가 생성한 new Parent() 객체이다. 프로토타입 객체는 내부 프로퍼티로 constructor 를 가지며 이는 생성자 함수 를 가리킨다. 하지만 의사 클래스 패턴 상속은 프로토타입 객체를 인스턴스로 교체 하는 과정에서 constructor의 연결 이 깨지게 된다. 즉, child 객체를 생성한 것은 Child 생성자 함수이지만 child.constructor 의 출력 결과는 Child 생성자 함수가 아닌 Parent 생성자 함수 를 나타낸다. 이는 child 객체의 프로토타입 객체인 new Parent() 객체는 constructor가 없기 때문에 프로토타입 체인에 의해 Parent.prototype의 constructor 를 참조했기 때문이다.
console.log(child.constructor); // [Function: Parent]3. 객체리터럴
의사 클래스 패턴 상속은 기본적으로 생성자 함수를 사용하기 때문에 객체리터럴 패턴으로 생성한 객체의 상속에는 적합하지 않다. 이는 객체리터럴 패턴으로 생성한 객체의 생성자 함수는 Object() 이고 이를 변경할 방법이 없기 때문이다.
var o = {};
console.log(o.__proto__ === Object.prototype); // true#5.2 프로토타입 패턴 상속 (Prototypal Inheritance)
프로토타입 패턴 상속은 Object.create 함수를 사용하여 객체에서 다른 객체로 직접 상속을 구현하는 방식이다. 프로토타입 패턴 상속은 개념적으로 의사 클래스 패턴 상속보다 더 간단하다. 또한 의사 클래스 패턴의 단점인 new 연산자 가 필요없으며, 생성자 링크 도 파괴되지 않으며, 객체리터럴 에도 사용할 수 있다.
// 부모 생성자 함수
var Parent = (function () {
// Constructor
function Parent(name) {
this.name = name;
}
// method
Parent.prototype.sayHi = function () {
console.log('Hi! ' + this.name);
};
// return constructor
return Parent;
})();
// create 함수의 인수는 프로토타입이다.
var child = Object.create(Parent.prototype);
child.name = 'child';
child.sayHi(); // Hi! child
console.log(child instanceof Parent); // true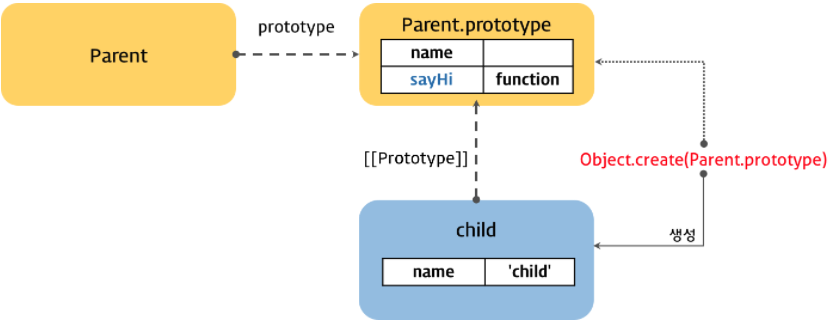
객체리터럴 패턴으로 생성한 객체에도 프로토타입 패턴 상속을 사용할 수 있다.
var parent = {
name: 'parent',
sayHi: function () {
console.log('Hi! ' + this.name);
},
};
// create 함수의 인자는 객체이다.
var child = Object.create(parent);
child.name = 'child';
// var child = Object.create(parent, {name: {value: 'child'}});
parent.sayHi(); // Hi! parent
child.sayHi(); // Hi! child
console.log(parent.isPrototypeOf(child)); // true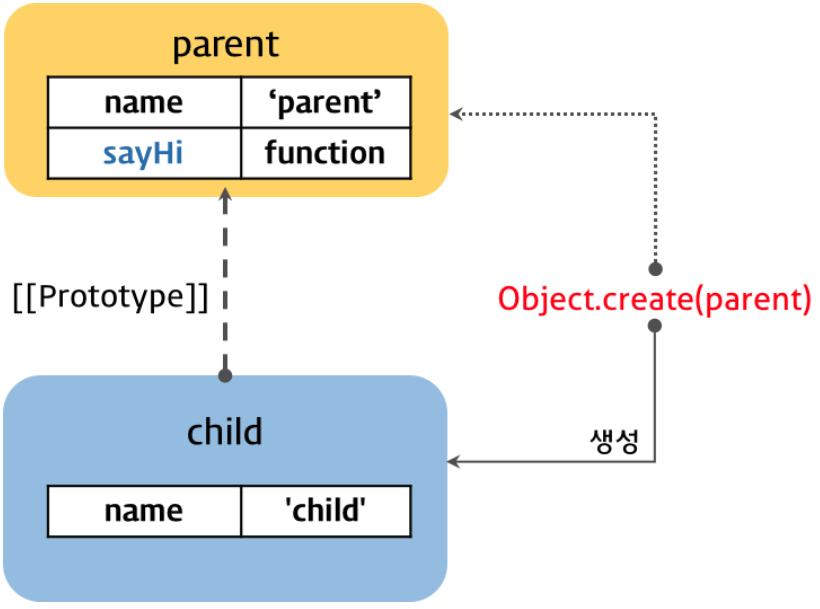
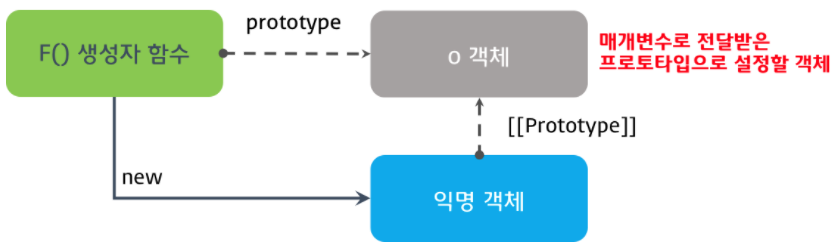
Object.create 함수 는 매개변수에 프로토타입으로 설정할 객체 또는 인스턴스를 전달 하고 이를 상속하는 새로운 객체를 생성 한다. Object.create 함수의 폴리필(Polyfill: 특정 기능이 지원되지 않는 브라우저를 위해 사용할 수 있는 코드 조각이나 플러그인)을 살펴보면 상속의 핵심을 이해할 수 있다.
// Object.create 함수의 폴리필
if (!Object.create) {
Object.create = function (o) {
function F() {} // 1
F.prototype = o; // 2
return new F(); // 3
};
}위 폴리필은 프로토타입 패턴 상속의 핵심을 담고 있다.
- 비어있는 생성자 함수 F를 생성한다.
- 생성자 함수 F의 prototype 프로퍼티에 매개변수로 전달받은 객체를 할당한다.
- 생성자 함수 F를 생성자로 하여 새로운 객채를 생성하고 반환한다.
#6. 캡슐화(Encapsulation)와 모듈 패턴(Module Pattern)
캡슐화는 관련있는 멤버 변수와 메소드를 클래스와 같은 하나의 틀 안에 담고 외부에 공개될 필요가 없는 정보는 숨기는 것을 말하며 다른 말로 정보 은닉(information hiding) 이라고 한다.
Java의 경우, 클래스를 정의하고 그 클래스를 구성하는 멤버에 대하여 public 또는 private 등으로 한정할 수 있다. public 으로 선언된 메소드 또는 데이터는 외부에서 사용이 가능하며, private 으로 선언된 경우는 외부에서 참조할 수 없고 내부에서만 사용된다.
이것은 클래스 외부에는 제한된 접근 권한을 제공하며 원하지 않는 외부의 접근에 대해 내부를 보호하는 작용을 한다. 이렇게 함으로써 이들 부분이 프로그램의 다른 부분들에 영향을 미치지 않고 변경될 수 있다. 하지만 자바스크립트는 public 또는 private 등의 키워드를 제공하지 않는다. 하지만 정보 은닉이 불가능한 것은 아니다.
var Person = function (arg) {
var name = arg ? arg : ''; // ①
this.getName = function () {
return name;
};
this.setName = function (arg) {
name = arg;
};
};
var me = new Person('Lee');
var name = me.getName();
console.log(name);
me.setName('Kim');
name = me.getName();
console.log(name);①의 name 변수는 private 변수가 된다. 자바스크립트는 function-level scope 를 제공하므로 함수 내의 변수는 외부에서 참조할 수 없다. 만약에 var 대신 this 를 사용하면 public 멤버가 된다. 단 new 키워드로 객체를 생성하지 않으면 this 는 생성된 객체에 바인딩되지 않고 전역객체에 연결 된다.
그리고 public 메소드 getName, setName은 클로저 로서 private 변수(자유 변수)에 접근할 수 있다. 이것이 기본적인 정보 은닉 방법이다.
var person = function (arg) {
var name = arg ? arg : '';
return {
getName: function () {
return name;
},
setName: function (arg) {
name = arg;
},
};
};
var me = person('Lee'); /* or var me = new person('Lee'); */
var name = me.getName();
console.log(name);
me.setName('Kim');
name = me.getName();
console.log(name);person 함수는 객체를 반환한다. 이 객체 내의 메소드 getName, setName은 클로저 로서 private 변수 name에 접근할 수 있다. 이러한 방식을 모듈 패턴 이라 하며 캡슐화와 정보 은닉를 제공한다. 많은 라이브러리에서 사용되는 유용한 패턴이다.
이 모듈 패턴은 다음과 같은 주의할 점이 있다.
private 멤버가 객체나 배열일 경우, 반환된 해당 멤버의 변경이 가능하다.
var person = function (personInfo) {
var o = personInfo;
return {
getPersonInfo: function () {
return o;
},
};
};
var me = person({ name: 'Lee', gender: 'male' });
var myInfo = me.getPersonInfo();
console.log('myInfo: ', myInfo);
// myInfo: { name: 'Lee', gender: 'male' }
myInfo.name = 'Kim';
myInfo = me.getPersonInfo();
console.log('myInfo: ', myInfo);
// myInfo: { name: 'Kim', gender: 'male' }객체를 반환하는 경우 반환값은 얕은 복사(shallow copy)로 private 멤버의 참조값 을 반환하게 된다. 따라서 외부 에서도 private 멤버의 값을 변경할 수 있다. 이를 회피하기 위해서는 객체를 그대로 반환하지 않고 반환해야 할 객체의 정보를새로운 객체 에 담아 반환해야 한다. 반드시 객체 전체 가 그대로 반환되어야 하는 경우에는 깊은 복사(deep copy)로 복사본을 만들어 반환한다.
person 함수가 반환한 객체는 person 함수 객체의 프로토타입에 접근할 수 없다. 이는 상속을 구현할 수 없음을 의미한다. 앞에서 살펴본 모듈 패턴은 생성자 함수가 아니며 단순히 메소드를 담은 객체를 반환한다. 반환된 객체는 객체 리터럴 방식으로 생성된 객체로 함수 person의 프로토타입에 접근할 수 없다.
var person = function (arg) {
var name = arg ? arg : '';
return {
getName: function () {
return name;
},
setName: function (arg) {
name = arg;
},
};
};
var me = person('Lee');
console.log(person.prototype === me.__proto__); // false
console.log(me.__proto__ === Object.prototype); // true: 객체 리터럴 방식으로 생성된 객체와 동일하다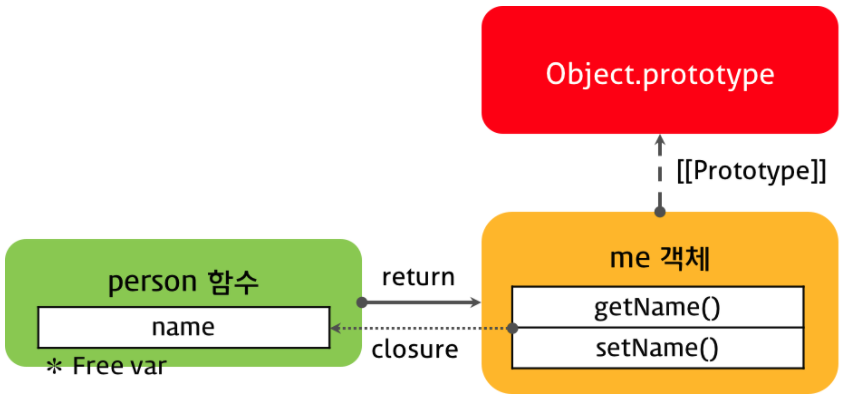
반환된 객체가 함수 person의 프로토타입에 접근할 수 없다는 것은 person을 부모 객체로 상속할 수 없다는 것을 의미한다.
함수 person을 부모 객체로 상속할 수 없다는 것은 함수 person이 반환하는 객체에 모든 메소드를 포함시켜야한다는 것을 의미한다.
이 문제를 해결하기 위해서는 객체를 반환 하는 것이 아닌 함수를 반환 해야 한다.
var Person = (function () {
var name;
var F = function (arg) {
name = arg ? arg : '';
};
F.prototype = {
getName: function () {
return name;
},
setName: function (arg) {
name = arg;
},
};
return F;
})();
var me = new Person('Lee');
console.log(Person.prototype === me.__proto__);
console.log(me.getName());
me.setName('Kim');
console.log(me.getName());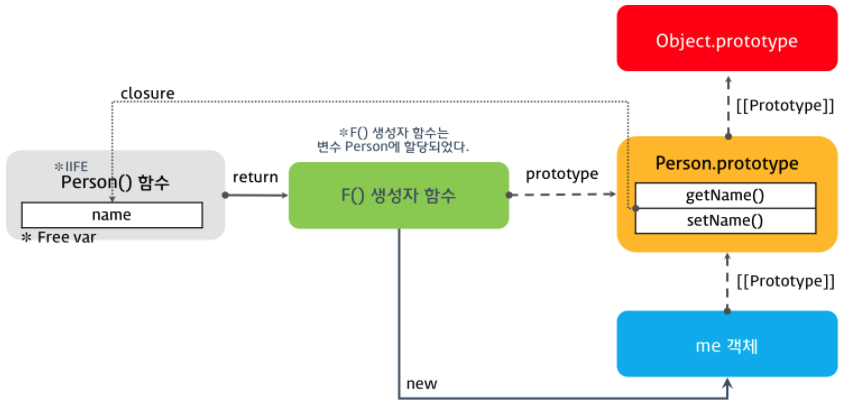
캡슐화를 구현하는 패턴은 다양하며 각각의 패턴에는 장단점이 있다. 다양한 패턴의 장단점을 분석하고 파악하는 것이 보다 효율적인 코드를 작성하는데 중요하다.
사실 자바스크립트는 클래스 기반 언어가 아니므로 기존의 전통적 방식으로 구현하려는 시도는 바른 판단은 아니다. 다만 객체지향 프로그래밍이 추구하는 재사용성, 유지보수의 용이성 등을 극대화하기 위한 노력의 일환으로 보아야 한다. 자바스크립트만의 방식을 잘 활용하여 기존의 방식에 얽매이지 않는다면 보다 효율적인 프로그래밍이 가능할 것이다.
ㅤㅤ
📍 Built-in Object : 빌트인 객체
자바스크립트의 객체는 아래와 같이 크게 3개의 객체로 분류할 수 있다.

#1. 네이티브 객체
네이티브 객체(Native objects or Built-in objects or Global Objects)는 ECMAScript 명세에 정의된 객체를 말하며 애플리케이션 전역의 공통 기능을 제공한다. 네이티브 객체는 애플리케이션의 환경과 관계없이 언제나 사용할 수 있다.
Object, String, Number, Function, Array, RegExp, Date, Math와 같은 객체 생성에 관계가 있는 함수 객체와 메소드로 구성된다.
네이티브 객체를 Global Objects라고 부르기도 하는데 이것은 전역 객체(Global Object)와 다른 의미로 사용되므로 혼동에 주의하여야 한다.
전역 객체(Global Object)는 모든 객체의 최상위 객체를 의미하며 일반적으로 Browser-side에서는 window, Server-side(Node.js)에서는 global 객체를 의미한다.
#1.1 Object
[Object() 생성자 함수]는 객체를 생성한다. 만약 생성자 인수값이 null이거나 undefined이면 빈 객체를 반환한다.
// 변수 o에 빈 객체를 저장한다
var o = new Object();
console.log(typeof o + ': ', o);
o = new Object(undefined);
console.log(typeof o + ': ', o);
o = new Object(null);
console.log(typeof o + ': ', o);그 이외의 경우 생성자 함수의 인수값에 따라 강제 형변환된 객체가 반환된다. 이때 반환된 객체의 [[Prototype]] 프로퍼티에 바인딩된 객체는 Object.prototype이 아니다.
// String 객체를 반환한다
// var obj = new String('String');과 동치이다
var obj = new Object('String');
console.log(typeof obj + ': ', obj);
console.dir(obj);
var strObj = new String('String');
console.log(typeof strObj + ': ', strObj);
// Number 객체를 반환한다
// var obj = new Number(123);과 동치이다
var obj = new Object(123);
console.log(typeof obj + ': ', obj);
var numObj = new Number(123);
console.log(typeof numObj + ': ', numObj);
// Boolean 객체를 반환한다.
// var obj = new Boolean(true);과 동치이다
var obj = new Object(true);
console.log(typeof obj + ': ', obj);
var boolObj = new Boolean(123);
console.log(typeof boolObj + ': ', boolObj);객체를 생성할 경우 특수한 상황이 아니라면 객체리터럴 방식을 사용하는 것이 일반적이다.
// 객체리터럴을 사용하는 것이 바람직하다.
var o = {};#1.2 Function
자바스크립트의 모든 함수는 Function 객체이다. 다른 모든 객체들처럼 Function 객체는 new 연산자을 사용해 생성할 수 있다.
var adder = new Function('a', 'b', 'return a + b');
adder(2, 6); // 8#1.3 Boolean
Boolean 객체는 원시 타입 boolean을 위한 레퍼(wrapper) 객체이다. Boolean 생성자 함수로 Boolean 객체를 생성할 수 있다.
var foo = new Boolean(true); // true
var foo = new Boolean('false'); // true
var foo = new Boolean(false); // false
var foo = new Boolean(); // false
var foo = new Boolean(''); // false
var foo = new Boolean(0); // false
var foo = new Boolean(null); // falseBoolean 객체와 원시 타입 boolean을 혼동하기 쉽다. Boolean 객체는 true/false를 포함하고 있는 객체이다.
var x = new Boolean(false);
if (x) {
// x는 객체로서 존재한다. 따라서 참으로 간주된다.
// . . . 이 코드는 실행된다.
}#1.4 Number
- [Number]
#1.5 Math
- [Math]
#1.6 Date
- [Date]
#1.7 String
- [Date]
#1.8 RegExp
- [RegExp]
#1.9 Array
- [Array]
#1.10 Error
Error 생성자는 error 객체를 생성한다. error 객체의 인스턴스는 런타임 에러가 발생하였을 때 throw된다.
try {
// foo();
throw new Error('Whoops!');
} catch (e) {
console.log(e.name + ': ' + e.message);
}Error 이외에 Error에 관련한 객체는 아래와 같다.
- EvalError
- InternalError
- RangeError
- ReferenceError
- SyntaxError
- TypeError
- URIError
#1.11 Symbol
Symbol은 ECMAScript 6(Javascript 2015) 에서 추가된 유일하고 변경 불가능한(immutable) 원시 타입으로 Symbol 객체는 원시 타입 Symbol 값을 생성한다.
#1.12 원시 타입과 래퍼객체(Wrapper Object)
앞서 살펴본 바와 같이 각 네이티브 객체는 각자의 프로퍼티와 메소드를 가진다. 정적(static) 프로퍼티, 메소드는 해당 인스턴스를 생성하지 않아도 사용할 수 있고 prototype에 속해있는 메소드는 해당 prototype을 상속받은 인스턴스가 있어야만 사용할 수 있다.
그런데 원시 타입 값에 대해 표준 빌트인 객체의 메소드를 호출하면 정상적으로 작동한다.
var str = 'Hello world!';
var res = str.toUpperCase();
console.log(res); // 'HELLO WORLD!'
var num = 1.5;
console.log(num.toFixed()); // 2이는 원시 타입 값에 대해 표준 빌트인 객체의 메소드를 호출할 때, 원시 타입 값은 연관된 객체(Wrapper 객체)로 일시 변환 되기 때문에 가능한 것이다. 그리고 메소드 호출이 종료되면 객체로 변환된 원시 타입 값은 다시 원시 타입 값으로 복귀한다.
Wrapper 객체는 String, Number, Boolean이 있다.
#2. 호스트 객체
호스트 객체(Host object)는 브라우저 환경에서 제공하는 window, XmlHttpRequest, HTMLElement 등의 DOM 노드 객체와 같이 호스트 환경에 정의된 객체를 말한다. 예를 들어 브라우저에서 동작하는 환경과 브라우저 외부에서 동작하는 환경의 자바스크립트(Node.js)는 다른 호스트 객체를 사용할 수 있다.
브라우저에서 동작하는 환경의 호스트 객체는 전역 객체인 window, BOM(Browser Object Model)과 DOM(Document Object Model) 및 XMLHttpRequest 객체 등을 제공한다.
#2.1 전역 객체(Global Object)
- [전역 객체]는 모든 객체의 유일한 최상위 객체를 의미하며 일반적으로 Browser-side에서는
window, Server-side(Node.js)에서는global객체를 의미한다.
#2.2 BOM (Browser Object Model)
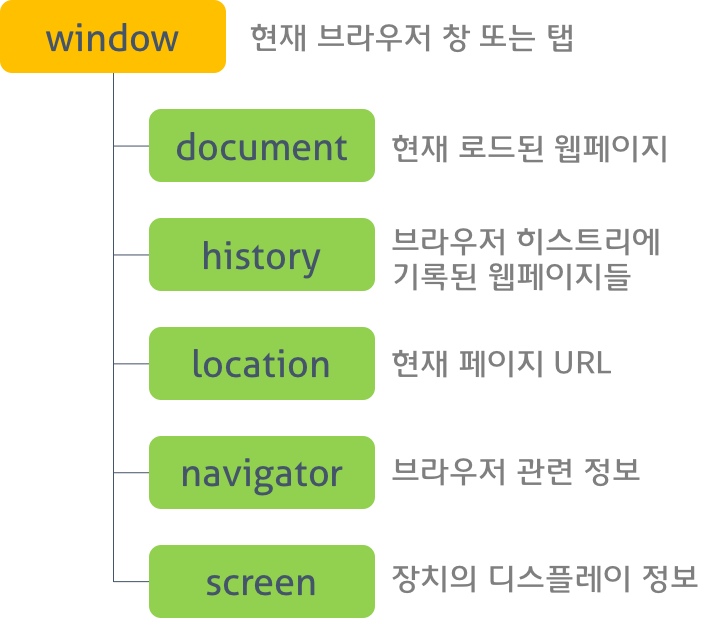
브라우저 객체 모델은 브라우저 탭 또는 브라우저 창의 모델을 생성한다. 최상위 객체는 window 객체로 현재 브라우저 창 또는 탭을 표현하는 객체이다. 또한 이 객체의 자식 객체 들은 브라우저의 다른 기능들을 표현한다. 이 객체들은 Standard Built-in Objects가 구성된 후에 구성된다.
#2.2 DOM (Document Object Model)
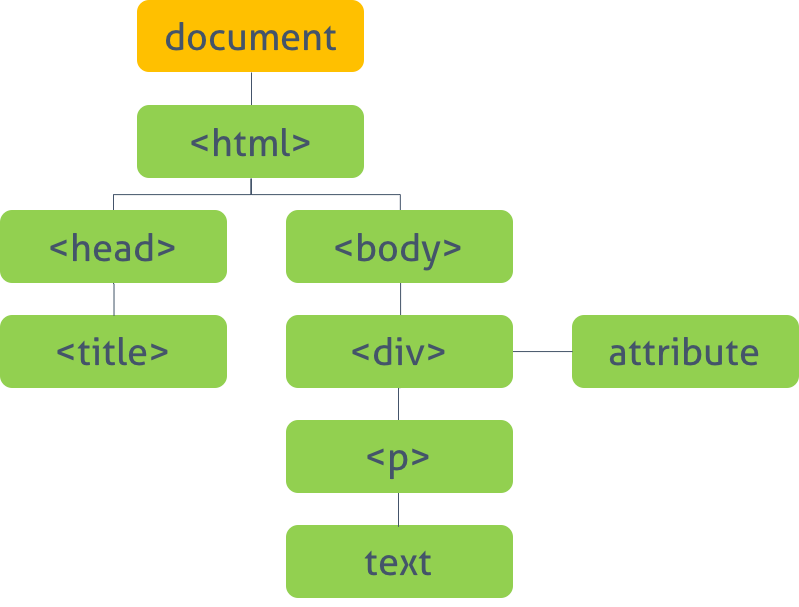
문서 객체 모델은 현재 웹페이지의 모델을 생성한다. 최상위 객체는 document 객체로 전체 문서를 표현한다. 또한 이 객체의 자식 객체들은 문서의 다른 요소들을 표현한다. 이 객체들은 Standard Built-in Objects가 구성된 후에 구성된다.
ㅤㅤ
📍 Global Object : 전역 객체
전역 객체(Global Object)는 모든 객체의 유일한 최상위 객체를 의미하며 일반적으로 Browser-side에서는 window, Server-side(Node.js)에서는 global 객체를 의미한다.
// in browser console
this === window; // true
// in Terminal
node;
this === global; // true- 전역 객체는 [실행 컨텍스트]에 컨트롤이 들어가기 이전에 생성이 되며 constructor가 없기 때문에 new 연산자를 이용하여 새롭게 생성할 수 없다. 즉, 개발자가 전역 객체를 생성하는 것은 불가능하다.
- 전역 객체는 전역 스코프(Global Scope)를 갖게 된다.
- 전역 객체의 자식 객체를 사용할 때 전역 객체의 기술은 생략할 수 있다. 예를 들어 document 객체는 전역 객체 window의 자식 객체로서 window.document…와 같이 기술할 수 있으나 일반적으로 전역 객체의 기술은 생략한다.
document.getElementById('foo').style.display = 'none';
// window.document.getElementById('foo').style.display = 'none';- 그러나 사용자가 정의한 변수와 전역 객체의 자식 객체 이름이 충돌하는 경우, 명확히 전역 객체를 기술하여 혼동을 방지할 수 있다.
function moveTo(url) {
var location = { href: 'move to ' };
alert(location.href + url);
// location.href = url;
window.location.href = url;
}
moveTo('http://www.google.com');- 전역 객체는 전역 변수(Global variable)를 프로퍼티로 가지게 된다. 다시 말해 전역 변수는 전역 객체의 프로퍼티이다.
var ga = 'Global variable';
console.log(ga);
console.log(window.ga);- 글로벌 영역에 선언한 함수도 전역 객체의 프로퍼티로 접근할 수 있다. 다시 말해 전역 함수는 전역 객체의 메소드이다.
function foo() {
console.log('invoked!');
}
window.foo();- Standard Built-in Objects(표준 빌트인 객체)도 역시 전역 객체의 자식 객체이다. 전역 객체의 자식 객체를 사용할 때 전역 객체의 기술은 생략할 수 있으므로 표준 빌트인 객체도 전역 객체의 기술을 생략할 수 있다.
// window.alert('Hello world!');
alert('Hello world!');#1. 전역 프로퍼티(Global property)
전역 프로퍼티는 전역 객체의 프로퍼티를 의미한다. 애플리케이션 전역에서 사용하는 값들을 나타내기 위해 사용한다. 전역 프로퍼티는 간단한 값이 대부분이며 다른 프로퍼티나 메소드를 가지고 있지 않다.
#1.1. Infinity
Infinity 프로퍼티는 양/음의 무한대를 나타내는 숫자값 Infinity를 갖는다.
console.log(window.Infinity); // Infinity
console.log(3 / 0); // Infinity
console.log(-3 / 0); // -Infinity
console.log(Number.MAX_VALUE * 2); // 1.7976931348623157e+308 * 2
console.log(typeof Infinity); // number#1.2. NaN
NaN 프로퍼티는 숫자가 아님(Not-a-Number)을 나타내는 숫자값 NaN을 갖는다. NaN 프로퍼티는 Number.NaN 프로퍼티와 같다.
console.log(window.NaN); // NaN
console.log(Number('xyz')); // NaN
console.log(1 * 'string'); // NaN
console.log(typeof NaN); // number#1.3. undefined
undefined 프로퍼티는 원시 타입 undefined를 값으로 갖는다.
console.log(window.undefined); // undefined
var foo;
console.log(foo); // undefined
console.log(typeof undefined); // undefined#2. 전역 함수(Global function)
전역 함수는 애플리케이션 전역에서 호출할 수 있는 함수로서 전역 객체의 메소드이다.
#2.1. eval()
매개변수에 전달된 문자열 구문 또는 표현식을 평가 또는 실행한다. 사용자로 부터 입력받은 콘텐츠(untrusted data)를 eval()로 실행하는 것은 보안에 매우 취약하다. eval()의 사용은 가급적으로 금지되어야 한다.
eval(string);
// string: code 또는 표현식을 나타내는 문자열. 표현식은 존재하는 객체들의 프로퍼티들과 변수들을 포함할 수 있다.var foo = eval('2 + 2');
console.log(foo); // 4
var x = 5;
var y = 4;
console.log(eval('x * y')); // 20#2.2. isFinite()
매개변수에 전달된 값이 정상적인 유한수인지 검사하여 그 결과를 Boolean으로 반환한다. 매개변수에 전달된 값이 숫자가 아닌 경우, 숫자로 변환한 후 검사를 수행한다.
isFinite(testValue); // testValue: 검사 대상 값console.log(isFinite(Infinity)); // false
console.log(isFinite(NaN)); // false
console.log(isFinite('Hello')); // false
console.log(isFinite('2005/12/12')); // false
console.log(isFinite(0)); // true
console.log(isFinite(2e64)); // true
console.log(isFinite('10')); // true: '10' → 10
console.log(isFinite(null)); // true: null → 0isFinite(null)은 true를 반환하는데 이것은 null을 숫자로 변환하여 검사를 수행하였기 때문이다.
// null이 숫자로 암묵적 강제 형변환이 일어난 경우
Number(null); // 0
// null이 불리언로 암묵적 강제 형변환이 일어난 경우
Boolean(null); // false#2.3. isNaN()
매개변수에 전달된 값이 NaN인지 검사하여 그 결과를 Boolean으로 반환한다. 매개변수에 전달된 값이 숫자가 아닌 경우, 숫자로 변환한 후 검사를 수행한다.
isNaN(testValue); // testValue: 검사 대상 값isNaN(NaN); // true
isNaN(undefined); // true: undefined → NaN
isNaN({}); // true: {} → NaN
isNaN('blabla'); // true: 'blabla' → NaN
isNaN(true); // false: true → 1
isNaN(null); // false: null → 0
isNaN(37); // false
// strings
isNaN('37'); // false: '37' → 37
isNaN('37.37'); // false: '37.37' → 37.37
isNaN(''); // false: '' → 0
isNaN(' '); // false: ' ' → 0
// dates
isNaN(new Date()); // false: new Date() → Number
isNaN(new Date().toString()); // true: String → NaN#2.4. parseFloat()
매개변수에 전달된 문자열을 부동소수점 숫자(floating point number)로 변환하여 반환한다.
parseFloat(string);
// string: 변환 대상 문자열문자열의 첫 숫자만 반환되며 전후 공백은 무시된다. 그리고 첫문자를 숫자로 변환할 수 없다면 NaN을 반환한다.
parseFloat('3.14'); // 3.14
parseFloat('10.00'); // 10
parseFloat('34 45 66'); // 34
parseFloat(' 60 '); // 60
parseFloat('40 years'); // 40
parseFloat('He was 40'); // NaN#2.5. parseInt()
매개변수에 전달된 문자열을 정수형 숫자(Integer)로 해석(parsing)하여 반환한다. 반환값은 언제나 10진수이다.
parseInt(string, radix);
// string: 파싱 대상 문자열
// radix: 진법을 나타내는 기수(2 ~ 36, 기본값 10)첫번째 매개변수에 전달된 값이 문자열이 아니면 문자열로 변환한 후 숫자로 해석하여 반환한다.
parseInt(10); // 10
parseInt(10.123); // 102번째 매개변수에는 진법을 나타내는 기수(2 ~ 36)를 지정할 수 있다. 기수를 생략하면 첫번째 매개변수에 전달된 문자열을 10진수로 해석하여 반환한다.
parseInt('10'); // 10
parseInt('10.123'); // 10두번째 매개변수에 진법을 나타내는 기수를 지정하면 첫번째 매개변수에 전달된 문자열을 해당 기수의 숫자로 해석하여 반환한다. 이때 반환값은 언제나 10진수이다.
parseInt('10', 2); // 2진수 10 → 10진수 2
parseInt('10', 8); // 8진수 10 → 10진수 8
parseInt('10', 16); // 16진수 10 → 10진수 16기수를 지정하여 10진수 숫자를 해당 기수의 문자열로 변환하여 반환하고 싶을 때는 [Number.prototype.toString] 메소드를 사용한다.
두번째 매개변수에 진법을 나타내는 기수를 지정하지 않더라도 첫번째 매개변수에 전달된 문자열이 “0x” 또는 “0X”로 시작한다면 16진수로 해석하여 반환한다.
parseInt('0x10'); // 16진수 10 → 10진수 16두번째 매개변수에 진법을 나타내는 기수를 지정하지 않더라도 첫번째 매개변수에 전달된 문자열이 “0”로 시작한다면 8진수로 해석하지 않고 10진수로 해석한다.
ES5 이전까지는 비록 사용을 금지하고는 있었지만 “0”로 시작하는 숫자를 8진수로 해석하였다. ES6부터는 “0”로 시작하는 숫자를 8진수로 해석하지 않고 10진수로 해석한다.
따라서 문자열을 8진수로 해석하려면 지수를 반드시 지정하여야 한다.
parseInt('010'); // 8진수 10으로 인식하지 않는다.
parseInt('010', 8); // 8진수 10 → 10진수 8
parseInt('10', 8); // 8진수 10 → 10진수 8parseInt는 첫번째 매개변수에 전달된 문자열의 첫번째 문자가 해당 지수의 숫자로 변환될 수 없다면 NaN을 반환한다.
parseInt('A0')); // NaN
parseInt('20', 2); // NaN
하지만 첫번째 매개변수에 전달된 문자열의 두번째 문자부터 해당 진수를 나타내는 숫자가 아닌 문자(예를 들어 2진수의 경우, 2)와 마주치면 이 문자와 계속되는 문자들은 전부 무시되며 해석된 정수값만을 반환한다.
parseInt('1A0')); // 1
parseInt('102', 2)); // 2
parseInt('58', 8); // 5
parseInt('FG', 16); // 15
첫번째 매개변수에 전달된 문자열에 공백이 있다면 첫번째 문자열만 해석하여 반환하며 전후 공백은 무시된다. 만일 첫번째 문자열을 숫자로 파싱할 수 없는 경우, NaN을 반환한다.
parseInt('34 45 66'); // 34
parseInt(' 60 '); // 60
parseInt('40 years'); // 40
parseInt('He was 40'); // NaN#2.6. encodeURI() / decodeURI()
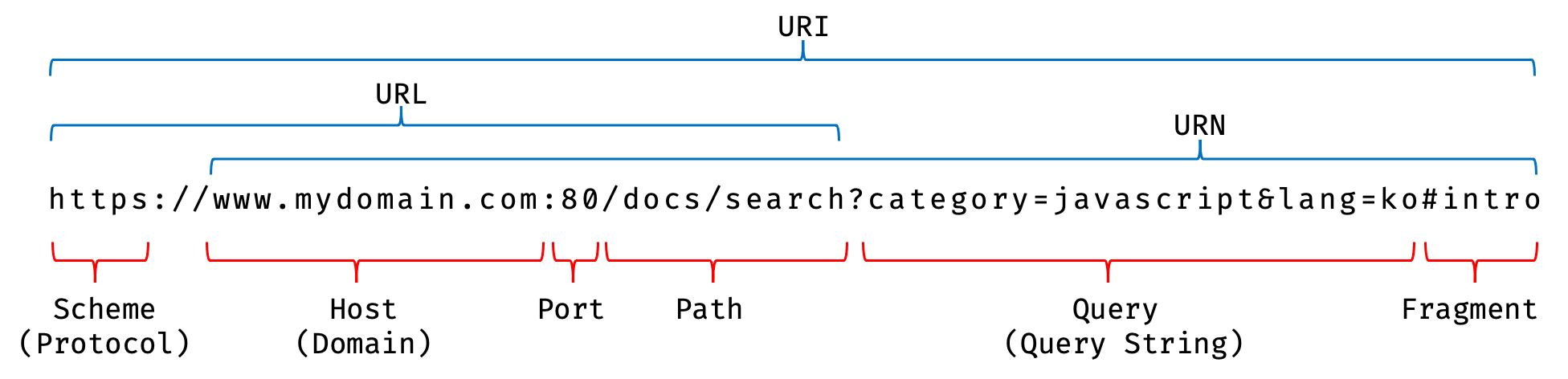
encodeURI()은 매개변수로 전달된 URI(Uniform Resource Identifier)를 인코딩한다.
여기서 인코딩이란 URI의 문자들을 이스케이프 처리하는 것을 의미한다.
이스케이프 처리네트워크를 통해 정보를 공유할 때 어떤 시스템에서도 읽을 수 있는 ASCII Character-set로 변환하는 것이다. UTF-8 특수문자의 경우, 1문자당 1~3byte, UTF-8 한글 표현의 경우, 1문자당 3btye이다. 예를 들어 특수문자 공백(space)은 %20, 한글 ‘가’는 %EC%9E%90으로 인코딩된다.이스케이프 처리 이유URI 문법 형식 표준 RFC3986에 따르면 URL은 ASCII Character-set으로만 구성되어야 하며 한글을 포함한 대부분의 외국어나 ASCII에 정의되지 않은 특수문자의 경우 URL에 포함될 수 없다. 따라서 URL 내에서 의미를 갖고 있는 문자(%, ?, #)나 URL에 올 수 없는 문자(한글, 공백 등) 또는 시스템에 의해 해석될 수 있는 문자(<, >)를 이스케이프 처리하여 야기될 수 있는 문제를 예방하기 위함이다.
단 아래의 문자는 이스케이프 처리에서 제외된다.
- 알파벳, 0~9의 숫자, - _ . ! ~ * ‘ ( )
decodeURI()은 매개변수로 전달된 URI을 디코딩한다.
encodeURI(URI);
// URI: 완전한 URI
decodeURI(encodedURI);
// encodedURI: 인코딩된 완전한 URIvar uri = 'http://example.com?name=이웅모&job=programmer&teacher';
var enc = encodeURI(uri);
var dec = decodeURI(enc);
console.log(enc);
// http://example.com?name=%EC%9D%B4%EC%9B%85%EB%AA%A8&job=programmer&teacher
console.log(dec);
// http://example.com?name=이웅모&job=programmer&teacher#2.7. encodeURIComponent() / decodeURIComponent()
encodeURIComponent()은 매개변수로 전달된 URI(Uniform Resource Identifier) component(구성 요소)를 인코딩한다. 여기서 인코딩이란 URI의 문자들을 이스케이프 처리하는 것을 의미한다. 단 아래의 문자는 이스케이프 처리에서 제외된다.
- 알파벳, 0~9의 숫자, - _ . ! ~ * ‘ ( )
decodeURIComponent()은 매개변수로 전달된 URI component(구성 요소)를 디코딩한다.
encodeURIComponent()는 인수를 쿼리스트링의 일부라고 간주한다. 따라서 =, ?, &를 인코딩한다. 반면 encodeURI()는 인수를 URI 전체라고 간주하며 파라미터 구분자인 =, ?, &를 인코딩하지 않는다.
encodeURIComponent(URI);
// URI: URI component(구성 요소)
decodeURIComponent(encodedURI);
// encodedURI: 인코딩된 URI component(구성 요소)var uriComp = '이웅모&job=programmer&teacher';
// encodeURI / decodeURI
var enc = encodeURI(uriComp);
var dec = decodeURI(enc);
console.log(enc);
// %EC%9D%B4%EC%9B%85%EB%AA%A8&job=programmer&teacher
console.log(dec);
// 이웅모&job=programmer&teacher
// encodeURIComponent / decodeURIComponent
enc = encodeURIComponent(uriComp);
dec = decodeURIComponent(enc);
console.log(enc);
// %EC%9D%B4%EC%9B%85%EB%AA%A8%26job%3Dprogrammer%26teacher
console.log(dec);
// 이웅모&job=programmer&teacherㅤㅤ
📍 Number : Number 레퍼 객체
Number 객체는 원시 타입 number를 다룰 때 유용한 프로퍼티와 메소드를 제공하는 레퍼(wrapper) 객체이다. 변수 또는 객체의 프로퍼티가 숫자를 값으로 가지고 있다면 Number 객체의 별도 생성없이 Number 객체의 프로퍼티와 메소드를 사용할 수 있다.
원시 타입이 wrapper 객체의 메소드를 사용할 수 있는 이유는 원시 타입으로 프로퍼티나 메소드를 호출할 때 원시 타입과 연관된 wrapper 객체로 일시적으로 변환되어 프로토타입 객체를 공유하게 되기 때문이다.
var num = 1.5;
console.log(num.toFixed()); // 2위에서 원시 타입을 담고 있는 변수 num이 Number.prototype.toFixed() 메소드를 호출할 수 있는 것은 변수 num의 값이 일시적으로 wrapper객체로 변환되었기 때문이다.
#1. Number Constructor
Number 객체는 Number() 생성자 함수를 통해 생성할 수 있다.
new Number(value);만일 인자가 숫자로 변환될 수 없다면 NaN을 반환한다.
var x = new Number(123);
var y = new Number('123');
var z = new Number('str');
console.log(x); // 123
console.log(y); // 123
console.log(z); // NaNNumber() 생성자 함수를 new 연산자를 붙이지 않아 생성자로 사용하지 않으면 Number 객체를 반환하지 않고 원시 타입 숫자를 반환한다. 이때 형 변환이 발생할 수 있다.
var x = Number('123');
console.log(typeof x, x); // number 123일반적으로 숫자를 사용할 때는 원시 타입 숫자를 사용한다.
var x = 123;
var y = new Number(123);
console.log(x == y); // true
console.log(x === y); // false
console.log(typeof x); // number
console.log(typeof y); // object#2. Number Property
정적(static) 프로퍼티로 Number 객체를 생성할 필요없이 Number.propertyName의 형태로 사용한다.
#2.1 Number.EPSILON
Number.EPSILON은 JavaScript에서 표현할 수 있는 가장 작은 수이다. 이는 임의의 수와 그 수보다 큰 수 중 가장 작은 수와의 차이와 같다. Number.EPSILON은 약 2.2204460492503130808472633361816E-16 또는 2-52이다.
부동소수점 산술 연산 비교는 정확한 값을 기대하기 어렵다. 정수는 2진법으로 오차없이 저장이 가능하지만 부동소수점을 표현하는 가장 널리 쓰이는 표준인 IEEE 754은 2진법으로 변환시 무한소수가 되어 미세한 오차가 발생할 수밖에 없는 구조적 한계를 갖는다.
따라서 부동소수점의 비교는 Number.EPSILON을 사용하여 비교 기능을 갖는 함수를 작성하여야 한다.
console.log(0.1 + 0.2); // 0.30000000000000004
console.log(0.1 + 0.2 == 0.3); // false!!!
function isEqual(a, b) {
// Math.abs는 절댓값을 반환한다.
// 즉 a와 b의 차이가 JavaScript에서 표현할 수 있는 가장 작은 수인 Number.EPSILON보다 작으면 같은 수로 인정할 수 있다.
return Math.abs(a - b) < Number.EPSILON;
}
console.log(isEqual(0.1 + 0.2, 0.3));#2.2 Number.MAX_VALUE
자바스크립트에서 사용 가능한 가장 큰 숫자(1.7976931348623157e+308)를 반환한다. MAX_VALUE보다 큰 숫자는 Infinity이다.
Number.MAX_VALUE; // 1.7976931348623157e+308
var num = 10;
num.MAX_VALUE; // undefined
console.log(Infinity > Number.MAX_VALUE); // true#2.3 Number.MIN_VALUE
자바스크립트에서 사용 가능한 가장 작은 숫자(5e-324)를 반환한다. MIN_VALUE는 0에 가장 가까운 양수 값이다. MIN_VALUE보다 작은 숫자는 0으로 변환된다.
Number.MIN_VALUE; // 5e-324
var num = 10;
num.MIN_VALUE; // undefined
console.log(Number.MIN_VALUE > 0); // true#2.4 Number.POSITIVE_INFINITY
양의 무한대 Infinity를 반환한다.
Number.POSITIVE_INFINITY; // Infinity
var num = 10;
num.POSITIVE_INFINITY; // undefined#2.5 Number.NEGATIVE_INFINITY
음의 무한대 -Infinity를 반환한다.
Number.NEGATIVE_INFINITY; // -Infinity
var num = 10;
num.NEGATIVE_INFINITY; // undefined#2.6 Number.NaN
숫자가 아님(Not-a-Number)을 나타내는 숫자값이다. Number.NaN 프로퍼티는 window.NaN 프로퍼티와 같다.
console.log(Number('xyz')); // NaN
console.log(1 * 'string'); // NaN
console.log(typeof NaN); // number#3. Number Method
#3.1 Number.isFinite(testValue: number): boolean
매개변수에 전달된 값이 정상적인 유한수인지를 검사하여 그 결과를 Boolean으로 반환한다.
/**
* @param {any} testValue - 검사 대상 값. 암묵적 형변환되지 않는다.
* @return {boolean}
*/
Number.isFinite(testValue);Number.isFinite()는 전역 함수 isFinite()와 차이가 있다. 전역 함수 isFinite()는 인수를 숫자로 변환하여 검사를 수행하지만 Number.isFinite()는 인수를 변환하지 않는다. 따라서 숫자가 아닌 인수가 주어졌을 때 반환값은 언제나 false가 된다.
Number.isFinite(Infinity); // false
Number.isFinite(NaN); // false
Number.isFinite('Hello'); // false
Number.isFinite('2005/12/12'); // false
Number.isFinite(0); // true
Number.isFinite(2e64); // true
Number.isFinite(null); // false. isFinite(null) => true#3.2 Number.isInteger(testValue: number): boolean
매개변수에 전달된 값이 정수(Integer)인지 검사하여 그 결과를 Boolean으로 반환한다. 검사전에 인수를 숫자로 변환하지 않는다.
/**
* @param {any} testValue - 검사 대상 값. 암묵적 형변환되지 않는다.
* @return {boolean}
*/
Number.isInteger(testValue);Number.isInteger(123); //true
Number.isInteger(-123); //true
Number.isInteger(5 - 2); //true
Number.isInteger(0); //true
Number.isInteger(0.5); //false
Number.isInteger('123'); //false
Number.isInteger(false); //false
Number.isInteger(Infinity); //false
Number.isInteger(-Infinity); //false
Number.isInteger(0 / 0); //false#3.3 Number.isNaN(testValue: number): boolean
매개변수에 전달된 값이 NaN인지를 검사하여 그 결과를 Boolean으로 반환한다.
/**
* @param {any} testValue - 검사 대상 값. 암묵적 형변환되지 않는다.
* @return {boolean}
*/
Number.isNaN(testValue);Number.isNaN()는 전역 함수 isNaN()와 차이가 있다. 전역 함수 isNaN()는 인수를 숫자로 변환하여 검사를 수행하지만 Number.isNaN()는 인수를 변환하지 않는다. 따라서 숫자가 아닌 인수가 주어졌을 때 반환값은 언제나 false가 된다.
Number.isNaN(NaN); // true
Number.isNaN(undefined); // false. undefined → NaN. isNaN(undefined) → true.
Number.isNaN({}); // false. {} → NaN. isNaN({}) → true.
Number.isNaN('blabla'); // false. 'blabla' → NaN. isNaN('blabla') → true.
Number.isNaN(true); // false
Number.isNaN(null); // false
Number.isNaN(37); // false
Number.isNaN('37'); // false
Number.isNaN('37.37'); // false
Number.isNaN(''); // false
Number.isNaN(' '); // false
Number.isNaN(new Date()); // false
Number.isNaN(new Date().toString()); // false. String → NaN. isNaN(String) → true.#3.4 Number.isSafeInteger(testValue: number): boolean
매개변수에 전달된 값이 안전한(safe) 정수값인지 검사하여 그 결과를 Boolean으로 반환한다. 안전한 정수값은 -(253 - 1)와 253 - 1 사이의 정수값이다. 검사전에 인수를 숫자로 변환하지 않는다.
/**
* @param {any} testValue - 검사 대상 값. 암묵적 형변환되지 않는다.
* @return {boolean}
*/
Number.isSafeInteger(testValue);Number.isSafeInteger(123); //true
Number.isSafeInteger(-123); //true
Number.isSafeInteger(5 - 2); //true
Number.isSafeInteger(0); //true
Number.isSafeInteger(1000000000000000); // true
Number.isSafeInteger(10000000000000001); // false
Number.isSafeInteger(0.5); //false
Number.isSafeInteger('123'); //false
Number.isSafeInteger(false); //false
Number.isSafeInteger(Infinity); //false
Number.isSafeInteger(-Infinity); //false
Number.isSafeInteger(0 / 0); //false#3.5 Number.prototype.toExponential(fractionDigits?: number): string
대상을 지수 표기법으로 변환하여 문자열로 반환한다. 지수 표기법이란 매우 큰 숫자를 표기할 때 주로 사용하며 e(Exponent) 앞에 있는 숫자에 10의 n승이 곱하는 형식으로 수를 나타내는 방식이다.
1234 = 1.234e+3
/**
* @param {number} [fractionDigits] - 0~20 사이의 정수값으로 소숫점 이하의 자릿수를 나타낸다. 옵션으로 생략 가능하다.
* @return {string}
*/
numObj.toExponential([fractionDigits]);var numObj = 77.1234;
console.log(numObj.toExponential()); // logs 7.71234e+1
console.log(numObj.toExponential(4)); // logs 7.7123e+1
console.log(numObj.toExponential(2)); // logs 7.71e+1
console.log(77.1234.toExponential()); // logs 7.71234e+1
console.log(77.toExponential()); // SyntaxError: Invalid or unexpected token
console.log(77 .toExponential()); // logs 7.7e+1
정수 리터럴과 함께 메소드를 사용할 경우
아래의 예제를 실행하면 에러가 발생한다.
77.toString(); // SyntaxError: Invalid or unexpected token
숫자 뒤의 .은 의미가 모호하다. 소수 구분 기호일 수도 있고 객체 프로퍼티에 접근하기 위한 마침표 표기법(Dot notation)일 수도 있다. 따라서 자바스크립트 엔진은 숫자 뒤의 .을 부동 소수점 숫자의 일부로 해석한다. 그러나 77.toString()은 숫자로 해석할 수 없으므로 에러(SyntaxError: Invalid or unexpected token)가 발생한다.
(1.23).toString(); // '1.23'위 예제의 경우, 숫자 뒤의 첫 번째 . 뒤에는 숫자가 이어지므로 .은 명백하게 부동 소수점 숫자의 일부이다. 숫자에 소수점은 하나만 존재하므로 두 번째 .은 마침표 표기법(Dot notation)으로 해석된다.
따라서 정수 리터럴과 함께 메소드를 사용할 경우, 아래의 방법을 권장한다.
(77).toString(); // '77'또한 아래 방법도 허용되기는 한다. 자바스크립트 숫자는 정수 부분과 소수 부분 사이에 공백을 포함할 수 없다. 따라서 숫자 뒤의 . 뒤에 공백이 오면 .을 마침표 표기법(Dot notation)으로 해석하기 때문이다.
(77).toString(); // '77'#3.6 Number.prototype.toFixed(fractionDigits?: number): string
매개변수로 지정된 소숫점자리를 반올림하여 문자열로 반환한다.
/**
* @param {number} [fractionDigits] - 0~20 사이의 정수값으로 소숫점 이하 자릿수를 나타낸다. 기본값은 0이며 옵션으로 생략 가능하다.
* @return {string}
*/
numObj.toFixed([fractionDigits]);var numObj = 12345.6789;
// 소숫점 이하 반올림
console.log(numObj.toFixed()); // '12346'
// 소숫점 이하 1자리수 유효, 나머지 반올림
console.log(numObj.toFixed(1)); // '12345.7'
// 소숫점 이하 2자리수 유효, 나머지 반올림
console.log(numObj.toFixed(2)); // '12345.68'
// 소숫점 이하 3자리수 유효, 나머지 반올림
console.log(numObj.toFixed(3)); // '12345.679'
// 소숫점 이하 6자리수 유효, 나머지 반올림
console.log(numObj.toFixed(6)); // '12345.678900'#3.7 Number.prototype.toPrecision(precision?: number): string
매개변수로 지정된 전체 자릿수까지 유효하도록 나머지 자릿수를 반올림하여 문자열로 반환한다. 지정된 전체 자릿수로 표현할 수 없는 경우 지수 표기법으로 결과를 반환한다.
/**
* @param {number} [precision] - 1~21 사이의 정수값으로 전체 자릿수를 나타낸다. 옵션으로 생략 가능하다.
* @return {string}
*/
numObj.toPrecision([precision]);var numObj = 15345.6789;
// 전체자리수 유효
console.log(numObj.toPrecision()); // '12345.6789'
// 전체 1자리수 유효, 나머지 반올림
console.log(numObj.toPrecision(1)); // '2e+4'
// 전체 2자리수 유효, 나머지 반올림
console.log(numObj.toPrecision(2)); // '1.5e+4'
// 전체 3자리수 유효, 나머지 반올림
console.log(numObj.toPrecision(3)); // '1.53e+4'
// 전체 6자리수 유효, 나머지 반올림
console.log(numObj.toPrecision(6)); // '12345.7'#3.8 Number.prototype.toString(radix?: number): string
숫자를 문자열로 변환하여 반환한다.
/**
* @param {number} [radix] - 2~36 사이의 정수값으로 진법을 나타낸다. 옵션으로 생략 가능하다.
* @return {string}
*/
numObj.toString([radix]);var count = 10;
console.log(count.toString()); // '10'
console.log((17).toString()); // '17'
console.log((17).toString()); // '17'
console.log((17.2).toString()); // '17.2'
var x = 16;
console.log(x.toString(2)); // '10000'
console.log(x.toString(8)); // '20'
console.log(x.toString(16)); // '10'
console.log((254).toString(16)); // 'fe'
console.log((-10).toString(2)); // '-1010'
console.log((-0xff).toString(2)); // '-11111111'#3.9 Number.prototype.valueOf(): number
Number 객체의 원시 타입 값(primitive value)을 반환한다.
var numObj = new Number(10);
console.log(typeof numObj); // object
var num = numObj.valueOf();
console.log(num); // 10
console.log(typeof num); // numberㅤㅤ
📍 Math : 수학 상수와 함수를 위한 Math 객체
Math 객체는 수학 상수와 함수를 위한 프로퍼티와 메소드를 제공하는 빌트인 객체이다. Math 객체는 생성자 함수가 아니다. 따라서 Math 객체는 정적(static) 프로퍼티와 메소드만을 제공한다.
사용 빈도가 높은 프로퍼티와 메소드만을 설명한다.
#1. Math Property
#1.1 Math.PI
PI 값(π ≈ 3.141592653589793)을 반환한다.
Math.PI; // 3.141592653589793#2. Math Method
#2.1 Math.abs(x: number): number
인수의 절댓값(absolute value)을 반환한다. 절댓값은 반드시 0 또는 양수이어야 한다.
Math.abs(-1); // 1
Math.abs('-1'); // 1
Math.abs(''); // 0
Math.abs([]); // 0
Math.abs(null); // 0
Math.abs(undefined); // NaN
Math.abs({}); // NaN
Math.abs('string'); // NaN
Math.abs(); // NaN#2.2 Math.round(x: number): number
인수의 소수점 이하를 반올림한 정수를 반환한다.
Math.round(1.4); // 1
Math.round(1.6); // 2
Math.round(-1.4); // -1
Math.round(-1.6); // -2
Math.round(1); // 1
Math.round(); // NaN#2.3 Math.ceil(x: number): number
인수의 소수점 이하를 올림한 정수를 반환한다.
Math.ceil(1.4); // 2
Math.ceil(1.6); // 2
Math.ceil(-1.4); // -1
Math.ceil(-1.6); // -1
Math.ceil(1); // 1
Math.ceil(); // NaN#2.4 Math.floor(x: number): number
인수의 소수점 이하를 내림한 정수를 반환한다. Math.ceil의 반대 개념이다.
- 양수인 경우, 소수점 이하를 떼어 버린 다음 정수를 반환한다.
- 음수인 경우, 소수점 이하를 떼어 버린 다음 -1을 한 정수를 반환한다.
Math.floor(1.9); // 1
Math.floor(9.1); // 9
Math.floor(-1.9); // -2
Math.floor(-9.1); // -10
Math.floor(1); // 1
Math.floor(); // NaN#2.5 Math.sqrt(x: number): number
인수의 제곱근을 반환한다.
Math.sqrt(9); // 3
Math.sqrt(-9); // NaN
Math.sqrt(2); // 1.414213562373095
Math.sqrt(1); // 1
Math.sqrt(0); // 0
Math.sqrt(); // NaN#2.6 Math.random(): number
임의의 부동 소수점을 반환한다. 반환된 부동 소수점은 0부터 1 미만이다. 즉, 0은 포함되지만 1은 포함되지 않는다.
Math.random(); // 0 ~ 1 미만의 부동 소수점 (0.8208720231391746)
// 1 ~ 10의 랜덤 정수 취득
// 1) Math.random로 0 ~ 1 미만의 부동 소수점을 구한 다음, 10을 곱해 0 ~ 10 미만의 부동 소수점을 구한다.
// 2) 0 ~ 10 미만의 부동 소수점에 1을 더해 1 ~ 10까지의 부동 소수점을 구한다.
// 3) Math.floor으로 1 ~ 10까지의 부동 소수점의 소수점 이하를 떼어 버린 다음 정수를 반환한다.
const random = Math.floor(Math.random() * 10 + 1);
console.log(random); // 1 ~ 10까지의 정수#2.7 Math.pow(x: number, y: number): number
첫번째 인수를 밑(base), 두번째 인수를 지수(exponent)로하여 거듭제곱을 반환한다.
Math.pow(2, 8); // 256
Math.pow(2, -1); // 0.5
Math.pow(2); // NaN
// ES7(ECMAScript 2016) Exponentiation operator(거듭 제곱 연산자)
2 ** 8; // 256#2.8 Math.max(…values: number[]): number
인수 중에서 가장 큰 수를 반환한다.
Math.max(1, 2, 3); // 3
// 배열 요소 중에서 최대값 취득
const arr = [1, 2, 3];
const max = Math.max.apply(null, arr); // 3
// ES6 Spread operator
Math.max(...arr); // 3#2.9 Math.min(…values: number[]): number
인수 중에서 가장 작은 수를 반환한다.
Math.min(1, 2, 3); // 1
// 배열 요소 중에서 최소값 취득
const arr = [1, 2, 3];
const min = Math.min.apply(null, arr); // 1
// ES6 Spread operator
Math.min(...arr); // 1ㅤㅤ
📍 Date : 날짜와 시간을 위한 Date 객체
Date 객체는 날짜와 시간(년, 월, 일, 시, 분, 초, 밀리초(천분의 1초(millisecond, ms)))을 위한 메소드를 제공하는 빌트인 객체이면서 생성자 함수이다.
Date 생성자 함수로 생성한 Date 객체는 내부적으로 숫자값을 갖는다. 이 값은 1970년 1월 1일 00:00(UTC)을 기점으로 현재 시간까지의 밀리초를 나타낸다.
UTC(협정 세계시: Coordinated Universal Time)는 GMT(그리니치 평균시: Greenwich Mean Time)로 불리기도 하는데 UTC와 GMT는 초의 소숫점 단위에서만 차이가 나기 때문에 일상에서는 혼용되어 사용된다. 기술적인 표기에서는 UTC가 사용된다.
KST(Korea Standard Time)는 UTC/GMT에 9시간을 더한 시간이다. 즉, KST는 UTC/GMT보다 9시간이 빠르다. 예를 들어, UTC 00:00 AM은 KST 09:00 AM이다.
현재의 날짜와 시간은 자바스크립트 코드가 동작한 시스템의 시계에 의해 결정된다. 시스템 시계의 설정(timezone, 시간)에 따라 서로 다른 값을 가질 수 있다.
#1. Date Constructor
Date 객체는 생성자 함수이다. Date 생성자 함수는 날짜와 시간을 가지는 인스턴스를 생성한다. 생성된 인스턴스는 기본적으로 현재 날짜와 시간을 나타내는 값을 가진다. 현재 날짜와 시간이 아닌 다른 날짜와 시간을 다루고 싶은 경우, Date 생성자 함수에 명시적으로 해당 날짜와 시간 정보를 인수로 지정한다. Date 생성자 함수로 객체를 생성하는 방법은 4가지가 있다.
#1.1 new Date()
인수를 전달하지 않으면 현재 날짜와 시간을 가지는 인스턴스를 반환한다.
const date = new Date();
console.log(date); // Thu May 16 2019 17:16:13 GMT+0900 (한국 표준시)#1.2 new Date(milliseconds)
인수로 숫자 타입의 밀리초를 전달하면 1970년 1월 1일 00:00(UTC)을 기점으로 인수로 전달된 밀리초만큼 경과한 날짜와 시간을 가지는 인스턴스를 반환한다.
// KST(Korea Standard Time)는 GMT(그리니치 평균시: Greenwich Mean Time)에 9시간을 더한 시간이다.
let date = new Date(0);
console.log(date); // Thu Jan 01 1970 09:00:00 GMT+0900 (한국 표준시)
// 86400000ms는 1day를 의미한다.
// 1s = 1,000ms
// 1m = 60s * 1,000ms = 60,000ms
// 1h = 60m * 60,000ms = 3,600,000ms
// 1d = 24h * 3,600,000ms = 86,400,000ms
date = new Date(86400000);
console.log(date); // FFri Jan 02 1970 09:00:00 GMT+0900 (한국 표준시)#1.3 new Date(dateString)
인수로 날짜와 시간을 나타내는 문자열을 전달하면 지정된 날짜와 시간을 가지는 인스턴스를 반환한다. 이때 인수로 전달한 문자열은 Date.parse 메소드에 의해 해석 가능한 형식이어야 한다.
let date = new Date('May 16, 2019 17:22:10');
console.log(date); // Thu May 16 2019 17:22:10 GMT+0900 (한국 표준시)
date = new Date('2019/05/16/17:22:10');
console.log(date); // Thu May 16 2019 17:22:10 GMT+0900 (한국 표준시)#1.4 new Date(year, month[, day, hour, minute, second, millisecond])
인수로 년, 월, 일, 시, 분, 초, 밀리초를 의미하는 숫자를 전달하면 지정된 날짜와 시간을 가지는 인스턴스를 반환한다. 이때 년, 월은 반드시 지정하여야 한다. 지정하지 않은 옵션 정보는 0 또는 1으로 초기화된다.
인수는 다음과 같다.
| 인수 | 내용 |
|---|---|
| year | 1900년 이후의 년 |
| month | 월을 나타내는 0 ~ 11까지의 정수 (주의: 0부터 시작, 0 = 1월) |
| day | 일을 나타내는 1 ~ 31까지의 정수 |
| hour | 시를 나타내는 0 ~ 23까지의 정수 |
| minute | 분을 나타내는 0 ~ 59까지의 정수 |
| second | 초를 나타내는 0 ~ 59까지의 정수 |
| millisecond | 밀리초를 나타내는 0 ~ 999까지의 정수 |
년, 월을 지정하지 않은 경우 1970년 1월 1일 00:00(UTC)을 가지는 인스턴스를 반환한다.
// 월을 나타내는 4는 5월을 의미한다.
// 2019/5/1/00:00:00:00
let date = new Date(2019, 4);
console.log(date); // Wed May 01 2019 00:00:00 GMT+0900 (한국 표준시)
// 월을 나타내는 4는 5월을 의미한다.
// 2019/5/16/17:24:30:00
date = new Date(2019, 4, 16, 17, 24, 30, 0);
console.log(date); // Thu May 16 2019 17:24:30 GMT+0900 (한국 표준시)
// 가독성이 훨씬 좋다.
date = new Date('2019/5/16/17:24:30:10');
console.log(date); // Thu May 16 2019 17:24:30 GMT+0900 (한국 표준시)#1.5 Date 생성자 함수를 new 연산자없이 호출
Date 생성자 함수를 new 연산자없이 호출하면 인스턴스를 반환하지 않고 결과값을 문자열로 반환한다.
let date = Date();
console.log(typeof date, date); // string Thu May 16 2019 17:33:03 GMT+0900 (한국 표준시)#2. Date 메소드
#2.1 Date.now
1970년 1월 1일 00:00:00(UTC)을 기점으로 현재 시간까지 경과한 밀리초를 숫자로 반환한다.
const now = Date.now();
console.log(now);#2.2 Date.parse
1970년 1월 1일 00:00:00(UTC)을 기점으로 인수로 전달된 지정 시간(new Date(dateString)의 인수와 동일한 형식)까지의 밀리초를 숫자로 반환한다.
let d = Date.parse('Jan 2, 1970 00:00:00 UTC'); // UTC
console.log(d); // 86400000
d = Date.parse('Jan 2, 1970 09:00:00'); // KST
console.log(d); // 86400000
d = Date.parse('1970/01/02/09:00:00'); // KST
console.log(d); // 86400000#2.3 Date.UTC
1970년 1월 1일 00:00:00(UTC)을 기점으로 인수로 전달된 지정 시간까지의 밀리초를 숫자로 반환한다.
Date.UTC 메소드는 new Date(year, month[, day, hour, minute, second, millisecond])와 같은 형식의 인수를 사용해야 한다. Date.UTC 메소드의 인수는 local time(KST)가 아닌 UTC로 인식된다.
let d = Date.UTC(1970, 0, 2);
console.log(d); // 86400000
d = Date.UTC('1970/1/2');
console.log(d); // NaNmonth는 월을 의미하는 0~11까지의 정수이다. 0부터 시작하므로 주의가 필요하다.
#2.4 Date.prototype.getFullYear
년도를 나타내는 4자리 숫자를 반환한다.
const today = new Date();
const year = today.getFullYear();
console.log(today); // Thu May 16 2019 17:39:30 GMT+0900 (한국 표준시)
console.log(year); // 2019#2.5 Date.prototype.setFullYear
년도를 나타내는 4자리 숫자를 설정한다. 년도 이외 월, 일도 설정할 수 있다.
dateObj.setFullYear(year[, month[, day]])
const today = new Date();
// 년도 지정
today.setFullYear(2000);
let year = today.getFullYear();
console.log(today); // Tue May 16 2000 17:42:40 GMT+0900 (한국 표준시)
console.log(year); // 2000
// 년도 지정
today.setFullYear(1900, 0, 1);
year = today.getFullYear();
console.log(today); // Mon Jan 01 1900 17:42:40 GMT+0827 (한국 표준시)
console.log(year); // 1900#2.6 Date.prototype.getMonth
월을 나타내는 0 ~ 11의 정수를 반환한다. 1월은 0, 12월은 11이다.
const today = new Date();
const month = today.getMonth();
console.log(today); // Thu May 16 2019 17:44:03 GMT+0900 (한국 표준시)
console.log(month); // 4#2.7 Date.prototype.setMonth
월을 나타내는 0 ~ 11의 정수를 설정한다. 1월은 0, 12월은 11이다. 월 이외 일도 설정할 수 있다.
dateObj.setMonth(month[, day])
const today = new Date();
// 월을 지정
today.setMonth(0); // 1월
let month = today.getMonth();
console.log(today); // Wed Jan 16 2019 17:45:20 GMT+0900 (한국 표준시)
console.log(month); // 0
// 월/일을 지정
today.setMonth(11, 1); // 12월 1일
month = today.getMonth();
console.log(today); // Sun Dec 01 2019 17:45:20 GMT+0900 (한국 표준시)
console.log(month); // 11#2.8 Date.prototype.getDate
날짜(1 ~ 31)를 나타내는 정수를 반환한다.
const today = new Date();
const date = today.getDate();
console.log(today); // Thu May 16 2019 17:46:42 GMT+0900 (한국 표준시)
console.log(date); // 16#2.9 Date.prototype.setDate
날짜(1 ~ 31)를 나타내는 정수를 설정한다.
const today = new Date();
// 날짜 지정
today.setDate(1);
const date = today.getDate();
console.log(today); // Wed May 01 2019 17:47:01 GMT+0900 (한국 표준시)
console.log(date); // 1#2.10 Date.prototype.getDay
요일(0 ~ 6)를 나타내는 정수를 반환한다. 반환값은 아래와 같다.
| 요일 | 반환값 |
|---|---|
| 일요일 | 0 |
| 월요일 | 1 |
| 화요일 | 2 |
| 수요일 | 3 |
| 목요일 | 4 |
| 금요일 | 5 |
| 토요일 | 6 |
const today = new Date();
const day = today.getDay();
console.log(today); // Thu May 16 2019 17:47:31 GMT+0900 (한국 표준시)
console.log(day); // 4#2.11 Date.prototype.getHours
시간(0 ~ 23)를 나타내는 정수를 반환한다.
const today = new Date();
const hours = today.getHours();
console.log(today); // Thu May 16 2019 17:48:03 GMT+0900 (한국 표준시)
console.log(hours); // 17#2.12 Date.prototype.setHours
시간(0 ~ 23)를 나타내는 정수를 설정한다. 시간 이외 분, 초, 밀리초도 설정할 수 있다.
dateObj.setHours(hour[, minute[, second[, ms]]])
const today = new Date();
// 시간 지정
today.setHours(7);
let hours = today.getHours();
console.log(today); // Thu May 16 2019 07:49:06 GMT+0900 (한국 표준시)
console.log(hours); // 7
// 시간/분/초/밀리초 지정
today.setHours(0, 0, 0, 0); // 00:00:00:00
hours = today.getHours();
console.log(today); // Thu May 16 2019 00:00:00 GMT+0900 (한국 표준시)
console.log(hours); // 0#2.13 Date.prototype.getMinutes
분(0 ~ 59)를 나타내는 정수를 반환한다.
const today = new Date();
const minutes = today.getMinutes();
console.log(today); // Thu May 16 2019 17:50:29 GMT+0900 (한국 표준시)
console.log(minutes); // 50#2.14 Date.prototype.setMinutes
분(0 ~ 59)를 나타내는 정수를 설정한다. 분 이외 초, 밀리초도 설정할 수 있다.
dateObj.setMinutes(minute[, second[, ms]])
const today = new Date();
// 분 지정
today.setMinutes(50);
let minutes = today.getMinutes();
console.log(today); // Thu May 16 2019 17:50:30 GMT+0900 (한국 표준시)
console.log(minutes); // 50
// 분/초/밀리초 지정
today.setMinutes(5, 10, 999); // HH:05:10:999
minutes = today.getMinutes();
console.log(today); // Thu May 16 2019 17:05:10 GMT+0900 (한국 표준시)
console.log(minutes); // 5#2.15 Date.prototype.getSeconds
초(0 ~ 59)를 나타내는 정수를 반환한다.
const today = new Date();
const seconds = today.getSeconds();
console.log(today); // Thu May 16 2019 17:53:17 GMT+0900 (한국 표준시)
console.log(seconds); // 17#2.16 Date.prototype.setSeconds
초(0 ~ 59)를 나타내는 정수를 설정한다. 초 이외 밀리초도 설정할 수 있다.
dateObj.setSeconds(second[, ms])
const today = new Date();
// 초 지정
today.setSeconds(30);
let seconds = today.getSeconds();
console.log(today); // Thu May 16 2019 17:54:30 GMT+0900 (한국 표준시)
console.log(seconds); // 30
// 초/밀리초 지정
today.setSeconds(10, 0); // HH:MM:10:000
seconds = today.getSeconds();
console.log(today); // Thu May 16 2019 17:54:10 GMT+0900 (한국 표준시)
console.log(seconds); // 10#2.17 Date.prototype.getMilliseconds
밀리초(0 ~ 999)를 나타내는 정수를 반환한다.
const today = new Date();
const ms = today.getMilliseconds();
console.log(today); // Thu May 16 2019 17:55:02 GMT+0900 (한국 표준시)
console.log(ms); // 905#2.18 Date.prototype.setMilliseconds
밀리초(0 ~ 999)를 나타내는 정수를 설정한다.
const today = new Date();
// 밀리초 지정
today.setMilliseconds(123);
const ms = today.getMilliseconds();
console.log(today); // Thu May 16 2019 17:55:45 GMT+0900 (한국 표준시)
console.log(ms); // 123#2.19 Date.prototype.getTime
1970년 1월 1일 00:00:00(UTC)를 기점으로 현재 시간까지 경과된 밀리초를 반환한다.
const today = new Date();
const time = today.getTime();
console.log(today); // Thu May 16 2019 17:56:08 GMT+0900 (한국 표준시)
console.log(time); // 1557996968335#2.20 Date.prototype.setTime
1970년 1월 1일 00:00:00(UTC)를 기점으로 현재 시간까지 경과된 밀리초를 설정한다.
dateObj.setTime(time);const today = new Date();
// 1970년 1월 1일 00:00:00(UTC)를 기점으로 현재 시간까지 경과된 밀리초 지정
today.setTime(86400000); // 86400000 === 1day
const time = today.getTime();
console.log(today); // Fri Jan 02 1970 09:00:00 GMT+0900 (한국 표준시)
console.log(time); // 86400000#2.21 Date.prototype.getTimezoneOffset
UTC와 지정 로케일(Locale) 시간과의 차이를 분단위로 반환한다.
const today = new Date();
const x = today.getTimezoneOffset() / 60; // -9
console.log(today); // Thu May 16 2019 17:58:13 GMT+0900 (한국 표준시)
console.log(x); // -9KST(Korea Standard Time)는 UTC에 9시간을 더한 시간이다. 즉, UTC = KST - 9h이다.
#2.22 Date.prototype.toDateString
사람이 읽을 수 있는 형식의 문자열로 날짜를 반환한다.
const d = new Date('2019/5/16/18:30');
console.log(d.toString()); // Thu May 16 2019 18:30:00 GMT+0900 (한국 표준시)
console.log(d.toDateString()); // Thu May 16 2019#2.23 Date.prototype.toTimeString
사람이 읽을 수 있는 형식의 문자열로 시간을 반환한다.
const d = new Date('2019/5/16/18:30');
console.log(d.toString()); // Thu May 16 2019 18:30:00 GMT+0900 (한국 표준시)
console.log(d.toTimeString()); // 18:30:00 GMT+0900 (한국 표준시)#3. Date Example
현재 날짜와 시간을 초단위로 반복 출력하는 예제이다.
(function printNow() {
const today = new Date();
const dayNames = [
'(일요일)',
'(월요일)',
'(화요일)',
'(수요일)',
'(목요일)',
'(금요일)',
'(토요일)',
];
// getDay: 해당 요일(0 ~ 6)를 나타내는 정수를 반환한다.
const day = dayNames[today.getDay()];
const year = today.getFullYear();
const month = today.getMonth() + 1;
const date = today.getDate();
let hour = today.getHours();
let minute = today.getMinutes();
let second = today.getSeconds();
const ampm = hour >= 12 ? 'PM' : 'AM';
// 12시간제로 변경
hour %= 12;
hour = hour || 12; // 0 => 12
// 10미만인 분과 초를 2자리로 변경
minute = minute < 10 ? '0' + minute : minute;
second = second < 10 ? '0' + second : second;
const now = `${year}년 ${month}월 ${date}일 ${day} ${hour}:${minute}:${second} ${ampm}`;
console.log(now);
setTimeout(printNow, 1000);
})();ㅤㅤ
📍 RegExp : 정규표현식
1. 정규표현식(Regular Expression)
정규표현식(Regular Expression)은 문자열에서 특정 내용을 찾거나 대체 또는 발췌하는데 사용한다.
예를 들어 회원가입 화면에서 사용자로 부터 입력 받는 전화번호가 유효한지 체크할 필요가 있다. 이때 정규표현식을 사용하면 간단히 처리할 수 있다.
const tel = '0101234567팔';
// 정규 표현식 리터럴
const myRegExp = /^[0-9]+$/;
console.log(myRegExp.test(tel)); // false반복문과 조건문을 사용한 복잡한 코드도 정규표현식을 이용하면 매우 간단하게 표현할 수 있다. 하지만 정규표현식은 주석이나 공백을 허용하지 않고 여러가지 기호를 혼합하여 사용하기 때문에 가독성이 좋지 않다는 문제가 있다.
정규표현식은 리터럴 표기법으로 생성할 수 있다. 정규 표현식 리터럴은 아래와 같이 표현한다.

정규표현식을 사용하는 자바스크립트 메소드는 RegExp.prototype.exec, RegExp.prototype.test, String.prototype.match, String.prototype.replace, String.prototype.search, String.prototype.split 등이 있다.
const targetStr = 'This is a pen.';
const regexr = /is/gi;
// RegExp 객체의 메소드
console.log(regexr.exec(targetStr)); // [ 'is', index: 2, input: 'This is a pen.' ]
console.log(regexr.test(targetStr)); // true
// String 객체의 메소드
console.log(targetStr.match(regexr)); // [ 'is', 'is' ]
console.log(targetStr.replace(regexr, 'IS')); // ThIS IS a pen.
// String.prototype.search는 검색된 문자열의 첫번째 인덱스를 반환한다.
console.log(targetStr.search(regexr)); // 2 ← index
console.log(targetStr.split(regexr)); // [ 'Th', ' ', ' a pen.' ]#1.2 플래그
플래그는 아래와 같은 종류가 있다.
| Flag | Meaning | Description |
|---|---|---|
| i | Ignore Case | 대소문자를 구별하지 않고 검색한다. |
| g | Global | 문자열 내의 모든 패턴을 검색한다. |
| m | Multi Line | 문자열의 행이 바뀌더라도 검색을 계속한다. |
플래그는 옵션이므로 선택적으로 사용한다. 플래그를 사용하지 않은 경우 문자열 내 검색 매칭 대상이 1개 이상이더라도 첫번째 매칭한 대상만을 검색하고 종료한다.
const targetStr = 'Is this all there is?';
// 문자열 is를 대소문자를 구별하여 한번만 검색한다.
let regexr = /is/;
console.log(targetStr.match(regexr)); // [ 'is', index: 5, input: 'Is this all there is?' ]
// 문자열 is를 대소문자를 구별하지 않고 대상 문자열 끝까지 검색한다.
regexr = /is/gi;
console.log(targetStr.match(regexr)); // [ 'Is', 'is', 'is' ]
console.log(targetStr.match(regexr).length); // 3#1.2 패턴
패턴에는 검색하고 싶은 문자열을 지정한다. 이때 문자열의 따옴표는 생략한다. 따옴표를 포함하면 따옴표까지도 검색한다. 또한 패턴은 특별한 의미를 가지는 메타문자(Metacharacter) 또는 기호로 표현할 수 있다. 몇가지 패턴 표현 방법을 소개한다.
const targetStr = 'AA BB Aa Bb';
// 임의의 문자 3개
const regexr = /.../;.은 임의의 문자 한 개를 의미한다. 문자의 내용은 무엇이든지 상관없다. 위 예제의 경우 .를 3개 연속하여 패턴을 생성하였으므로 3자리 문자를 추출한다.
console.log(targetStr.match(regexr)); // [ 'AA ', index: 0, input: 'AA BB Aa Bb' ]이때 추출을 반복하지 않는다. 반복하기 위해서는 플래그 g를 사용한다.
const targetStr = 'AA BB Aa Bb';
// 임의의 문자 3개를 반복하여 검색
const regexr = /.../g;
console.log(targetStr.match(regexr)); // [ 'AA ', 'BB ', 'Aa ' ]모든 문자를 선택하려면 .와 g를 동시에 지정한다.
const targetStr = 'AA BB Aa Bb';
// 임의의 한문자를 반복 검색
const regexr = /./g;
console.log(targetStr.match(regexr));
// [ 'A', 'A', ' ', 'B', 'B', ' ', 'A', 'a', ' ', 'B', 'b' ]패턴에 문자 또는 문자열을 지정하면 일치하는 문자 또는 문자열을 추출한다.
const targetStr = 'AA BB Aa Bb';
// 'A'를 검색
const regexr = /A/;
console.log(targetStr.match(regexr)); // 'A'이때 대소문자를 구별하며 패턴과 일치한 첫번째 결과만 반환된다. 대소문자를 구별하지 않게 하려면 플래그 i를 사용한다.
const targetStr = 'AA BB Aa Bb';
// 'A'를 대소문자 구분없이 반복 검색
const regexr = /A/gi;
console.log(targetStr.match(regexr)); // [ 'A', 'A', 'A', 'a' ]앞선 패턴을 최소 한번 반복하려면 앞선 패턴 뒤에 +를 붙인다. 아래 예제의 경우, 앞선 패턴은 A이므로 A+는 A만으로 이루어진 문자열(‘A’, ‘AA’, ‘AAA’, …)를 의미한다.
const targetStr = 'AA AAA BB Aa Bb';
// 'A'가 한번이상 반복되는 문자열('A', 'AA', 'AAA', ...)을 반복 검색
const regexr = /A+/g;
console.log(targetStr.match(regexr)); // [ 'AA', 'AAA', 'A' ]|를 사용하면 or의 의미를 가지게 된다.
const targetStr = 'AA BB Aa Bb';
// 'A' 또는 'B'를 반복 검색
const regexr = /A|B/g;
console.log(targetStr.match(regexr)); // [ 'A', 'A', 'B', 'B', 'A', 'B' ]분해되지 않은 단어 레벨로 추출하기 위해서는 +를 같이 사용하면 된다.
const targetStr = 'AA AAA BB Aa Bb';
// 'A' 또는 'B'가 한번 이상 반복되는 문자열을 반복 검색
// 'A', 'AA', 'AAA', ... 또는 'B', 'BB', 'BBB', ...
const regexr = /A+|B+/g;
console.log(targetStr.match(regexr)); // [ 'AA', 'AAA', 'BB', 'A', 'B' ]위 예제는 패턴을 or로 한번 이상 반복하는 것인데 간단히 표현하면 아래와 같다. []내의 문자는 or로 동작한다. 그 뒤에 +를 사용하여 앞선 패턴을 한번 이상 반복하게 한다.
const targetStr = 'AA BB Aa Bb';
// 'A' 또는 'B'가 한번 이상 반복되는 문자열을 반복 검색
// 'A', 'AA', 'AAA', ... 또는 'B', 'BB', 'BBB', ...
const regexr = /[AB]+/g;
console.log(targetStr.match(regexr)); // [ 'AA', 'BB', 'A', 'B' ]범위를 지정하려면 []내에 -를 사용한다. 아래의 경우 대문자 알파벳을 추출한다.
const targetStr = 'AA BB ZZ Aa Bb';
// 'A' ~ 'Z'가 한번 이상 반복되는 문자열을 반복 검색
// 'A', 'AA', 'AAA', ... 또는 'B', 'BB', 'BBB', ... ~ 또는 'Z', 'ZZ', 'ZZZ', ...
const regexr = /[A-Z]+/g;
console.log(targetStr.match(regexr)); // [ 'AA', 'BB', 'ZZ', 'A', 'B' ]대소문자를 구별하지 않고 알파벳을 추출하려면 아래와 같이 한다.
const targetStr = 'AA BB Aa Bb';
// 'A' ~ 'Z' 또는 'a' ~ 'z'가 한번 이상 반복되는 문자열을 반복 검색
const regexr = /[A-Za-z]+/g;
// 아래와 동일하다.
// const regexr = /[A-Z]+/gi;
console.log(targetStr.match(regexr)); // [ 'AA', 'BB', 'Aa', 'Bb' ]숫자를 추출하는 방법이다.
const targetStr = 'AA BB Aa Bb 24,000';
// '0' ~ '9'가 한번 이상 반복되는 문자열을 반복 검색
const regexr = /[0-9]+/g;
console.log(targetStr.match(regexr)); // [ '24', '000' ]컴마 때문에 결과가 분리되므로 패턴에 포함시킨다.
const targetStr = 'AA BB Aa Bb 24,000';
// '0' ~ '9' 또는 ','가 한번 이상 반복되는 문자열을 반복 검색
const regexr = /[0-9,]+/g;
console.log(targetStr.match(regexr)); // [ '24,000' ]이것을 간단히 표현하면 아래와 같다. \d는 숫자를 의미한다. \D는 \d와 반대로 동작한다.
const targetStr = 'AA BB Aa Bb 24,000';
// '0' ~ '9' 또는 ','가 한번 이상 반복되는 문자열을 반복 검색
let regexr = /[\d,]+/g;
console.log(targetStr.match(regexr)); // [ '24,000' ]
// '0' ~ '9'가 아닌 문자(숫자가 아닌 문자) 또는 ','가 한번 이상 반복되는 문자열을 반복 검색
regexr = /[\D,]+/g;
console.log(targetStr.match(regexr)); // [ 'AA BB Aa Bb ', ',' ]\w는 알파벳과 숫자를 의미한다. \W는 \w와 반대로 동작한다.
const targetStr = 'AA BB Aa Bb 24,000';
// 알파벳과 숫자 또는 ','가 한번 이상 반복되는 문자열을 반복 검색
let regexr = /[\w,]+/g;
console.log(targetStr.match(regexr)); // [ 'AA', 'BB', 'Aa', 'Bb', '24,000' ]
// 알파벳과 숫자가 아닌 문자 또는 ','가 한번 이상 반복되는 문자열을 반복 검색
regexr = /[\W,]+/g;
console.log(targetStr.match(regexr)); // [ ' ', ' ', ' ', ' ', ',' ]#1.3 자주 사용하는 정규표현식
특정 단어로 시작하는지 검사한다.
const url = 'http://example.com';
// 'http'로 시작하는지 검사
// ^ : 문자열의 처음을 의미한다.
const regexr = /^http/;
console.log(regexr.test(url)); // true특정 단어로 끝나는지 검사한다.
const fileName = 'index.html';
// 'html'로 끝나는지 검사
// $ : 문자열의 끝을 의미한다.
const regexr = /html$/;
console.log(regexr.test(fileName)); // true숫자인지 검사한다.
const targetStr = '12345';
// 모두 숫자인지 검사
// [^]: 부정(not)을 의미한다. 얘를 들어 [^a-z]는 알파벳 소문자로 시작하지 않는 모든 문자를 의미한다.
// [] 바깥의 ^는 문자열의 처음을 의미한다.
const regexr = /^\d+$/;
console.log(regexr.test(targetStr)); // true하나 이상의 공백으로 시작하는지 검사한다.
const targetStr = ' Hi!';
// 1개 이상의 공백으로 시작하는지 검사
// \s : 여러 가지 공백 문자 (스페이스, 탭 등) => [\t\r\n\v\f]
const regexr = /^[\s]+/;
console.log(regexr.test(targetStr)); // true아이디로 사용 가능한지 검사한다. (영문자, 숫자만 허용, 4~10자리)
const id = 'abc123';
// 알파벳 대소문자 또는 숫자로 시작하고 끝나며 4 ~10자리인지 검사
// {4,10}: 4 ~ 10자리
const regexr = /^[A-Za-z0-9]{4,10}$/;
console.log(regexr.test(id)); // true메일 주소 형식에 맞는지 검사한다.
const email = 'ungmo2@gmail.com';
const regexr = /^[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*\.[a-zA-Z]{2,3}$/;
console.log(regexr.test(email)); // true핸드폰 번호 형식에 맞는지 검사한다.
const cellphone = '010-1234-5678';
const regexr = /^\d{3}-\d{3,4}-\d{4}$/;
console.log(regexr.test(cellphone)); // true특수 문자 포함 여부를 검사한다.
const targetStr = 'abc#123';
// A-Za-z0-9 이외의 문자가 있는지 검사
let regexr = /[^A-Za-z0-9]/gi;
console.log(regexr.test(targetStr)); // true
// 아래 방식도 동작한다. 이 방식의 장점은 특수 문자를 선택적으로 검사할 수 있다.
regexr = /[\{\}\[\]\/?.,;:|\)*~`!^\-_+<>@\#$%&\\\=\(\'\"]/gi;
console.log(regexr.test(targetStr)); // true
// 특수 문자 제거
console.log(targetStr.replace(regexr, '')); // abc123#2. Javascript Regular Expression
#2.1 RegExp Constructor
자바스크립트은 정규표현식을 위해 RegExp 객체를 지원한다. RegExp 객체를 생성하기 위해서는 리터럴 방식과 RegExp 생성자 함수를 사용할 수 있다. 일반적인 방법은 리터럴 방식이다.
new RegExp(pattern[, flags])
- pattern 정규표현식의 텍스트
- flags 정규표현식의 플래그 (g, i, m, u, y)
// 정규식 리터럴
/ab+c/i;
new RegExp('ab+c', 'i');
new RegExp(/ab+c/, 'i');
new RegExp(/ab+c/i); // ES6정규표현식을 사용하는 메소드는 RegExp.prototype.exec, RegExp.prototype.test, String.prototype.match, String.prototype.replace, String.prototype.search, String.prototype.split 등이 있다.
#2.2 RegExp Method
#2.2.1 RegExp.prototype.exec(target: string): RegExpExecArray | null
문자열을 검색하여 매칭 결과를 반환한다. 반환값은 배열 또는 null이다.
const target = 'Is this all there is?';
const regExp = /is/;
const res = regExp.exec(target);
console.log(res); // [ 'is', index: 5, input: 'Is this all there is?' ]exec 메소드는 g 플래그를 지정하여도 첫번째 메칭 결과만을 반환한다.
const target = 'Is this all there is?';
const regExp = /is/g;
const res = regExp.exec(target);
console.log(res); // [ 'is', index: 5, input: 'Is this all there is?' ]#2.2.2 RegExp.prototype.test(target: string): boolean
문자열을 검색하여 매칭 결과를 반환한다. 반환값은 true 또는 false이다.
const target = 'Is this all there is?';
const regExp = /is/;
const res = regExp.test(target);
console.log(res); // trueㅤㅤ
📍 String : String 레퍼 객체
String 객체는 원시 타입인 문자열을 다룰 때 유용한 프로퍼티와 메소드를 제공하는 레퍼(wrapper) 객체이다. 변수 또는 객체 프로퍼티가 문자열을 값으로 가지고 있다면 String 객체의 별도 생성없이 String 객체의 프로퍼티와 메소드를 사용할 수 있다.
원시 타입이 wrapper 객체의 메소드를 사용할 수 있는 이유는 원시 타입으로 프로퍼티나 메소드를 호출할 때 원시 타입과 연관된 wrapper 객체로 일시적으로 변환되어 프로토타입 객체를 공유하게 되기 때문이다.
const str = 'Hello world!';
console.log(str.toUpperCase()); // 'HELLO WORLD!'위에서 원시 타입 문자열을 담고 있는 변수 str이 String.prototype.toUpperCase() 메소드를 호출할 수 있는 것은 변수 str의 값이 일시적으로 wrapper객체로 변환되었기 때문이다.
사용 빈도가 높은 String 객체의 프로퍼티와 메소드에 대해 살펴보도록 한다.
#1. String Constructor
String 객체는 String 생성자 함수를 통해 생성할 수 있다. 이때 전달된 인자는 모두 문자열로 변환된다.
new String(value);let strObj = new String('Lee');
console.log(strObj); // String {0: 'L', 1: 'e', 2: 'e', length: 3, [[PrimitiveValue]]: 'Lee'}
strObj = new String(1);
console.log(strObj); // String {0: '1', length: 1, [[PrimitiveValue]]: '1'}
strObj = new String(undefined);
console.log(strObj); // String {0: 'u', 1: 'n', 2: 'd', 3: 'e', 4: 'f', 5: 'i', 6: 'n', 7: 'e', 8: 'd', length: 9, [[PrimitiveValue]]: 'undefined'}new 연산자를 사용하지 않고 String 생성자 함수를 호출하면 String 객체가 아닌 문자열 리터럴을 반환한다. 이때 형 변환이 발생할 수 있다.
var x = String('Lee');
console.log(typeof x, x); // string Lee일반적으로 문자열을 사용할 때는 원시 타입 문자열을 사용한다.
const str = 'Lee';
const strObj = new String('Lee');
console.log(str == strObj); // true
console.log(str === strObj); // false
console.log(typeof str); // string
console.log(typeof strObj); // object#2. String Property
#2.1 String.length
문자열 내의 문자 갯수를 반환한다. String 객체는 length 프로퍼티를 소유하고 있으므로 유사 배열 객체이다.
const str1 = 'Hello';
console.log(str1.length); // 5
const str2 = '안녕하세요!';
console.log(str2.length); // 6#3. String Method
String 객체의 모든 메소드는 언제나 새로운 문자열을 반환한다. 문자열은 변경 불가능(immutable)한 원시 값이기 때문이다.
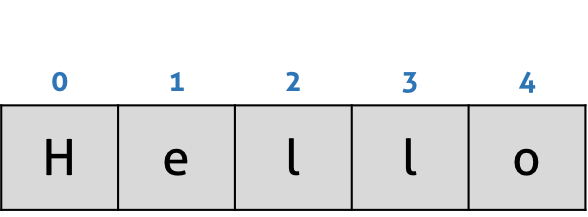
#3.1 String.prototype.charAt(pos: number): string
인수로 전달한 index를 사용하여 index에 해당하는 위치의 문자를 반환한다. index는 0 ~ (문자열 길이 - 1) 사이의 정수이다. 지정한 index가 문자열의 범위(0 ~ (문자열 길이 - 1))를 벗어난 경우 빈문자열을 반환한다.
const str = 'Hello';
console.log(str.charAt(0)); // H
console.log(str.charAt(1)); // e
console.log(str.charAt(2)); // l
console.log(str.charAt(3)); // l
console.log(str.charAt(4)); // o
// 지정한 index가 범위(0 ~ str.length-1)를 벗어난 경우 빈문자열을 반환한다.
console.log(str.charAt(5)); // ''
// 문자열 순회. 문자열은 length 프로퍼티를 갖는다.
for (let i = 0; i < str.length; i++) {
console.log(str.charAt(i));
}
// String 객체는 유사 배열 객체이므로 배열과 유사하게 접근할 수 있다.
for (let i = 0; i < str.length; i++) {
console.log(str[i]); // str['0']
}#3.2 String.prototype.concat(…strings: string[]): string
인수로 전달한 1개 이상의 문자열과 연결하여 새로운 문자열을 반환한다.
concat 메소드를 사용하는 것보다는 +, += 할당 연산자를 사용하는 것이 성능상 유리하다.
/**
* @param {...string} str - 연결할 문자열
* @return {string}
*/
str.concat(str1[,str2,...,strN])
console.log('Hello '.concat('Lee')); // Hello Lee
#3.3 String.prototype.indexOf(searchString: string, fromIndex=0): number
인수로 전달한 문자 또는 문자열을 대상 문자열에서 검색하여 처음 발견된 곳의 index를 반환한다. 발견하지 못한 경우 -1을 반환한다.
/**
* @param {string} searchString - 검색할 문자 또는 문자열
* @param {string} [fromIndex=0] - 검색 시작 index (생략할 경우, 0)
* @return {number}
*/
str.indexOf(searchString[, fromIndex])
const str = 'Hello World';
console.log(str.indexOf('l')); // 2
console.log(str.indexOf('or')); // 7
console.log(str.indexOf('or', 8)); // -1
if (str.indexOf('Hello') !== -1) {
// 문자열 str에 'hello'가 포함되어 있는 경우에 처리할 내용
}
// ES6: String.prototype.includes
if (str.includes('Hello')) {
// 문자열 str에 'hello'가 포함되어 있는 경우에 처리할 내용
}#3.4 String.prototype.lastIndexOf(searchString: string, fromIndex=this.length-1): number
인수로 전달한 문자 또는 문자열을 대상 문자열에서 검색하여 마지막으로 발견된 곳의 index를 반환한다. 발견하지 못한 경우 -1을 반환한다.
2번째 인수(fromIndex)가 전달되면 검색 시작 위치를 fromIndex으로 이동하여 역방향으로 검색을 시작한다. 이때 검색 범위는 0 ~ fromIndex이며 반환값은 indexOf 메소드와 동일하게 발견된 곳의 index이다.
/**
* @param {string} searchString - 검색할 문자 또는 문자열
* @param {number} [fromIndex=this.length-1] - 검색 시작 index (생략할 경우, 문자열 길이 - 1)
* @return {number}
*/
str.lastIndexOf(searchString[, fromIndex])
const str = 'Hello World';
console.log(str.lastIndexOf('World')); // 6
console.log(str.lastIndexOf('l')); // 9
console.log(str.lastIndexOf('o', 5)); // 4
console.log(str.lastIndexOf('o', 8)); // 7
console.log(str.lastIndexOf('l', 10)); // 9
console.log(str.lastIndexOf('H', 0)); // 0
console.log(str.lastIndexOf('W', 5)); // -1
console.log(str.lastIndexOf('x', 8)); // -1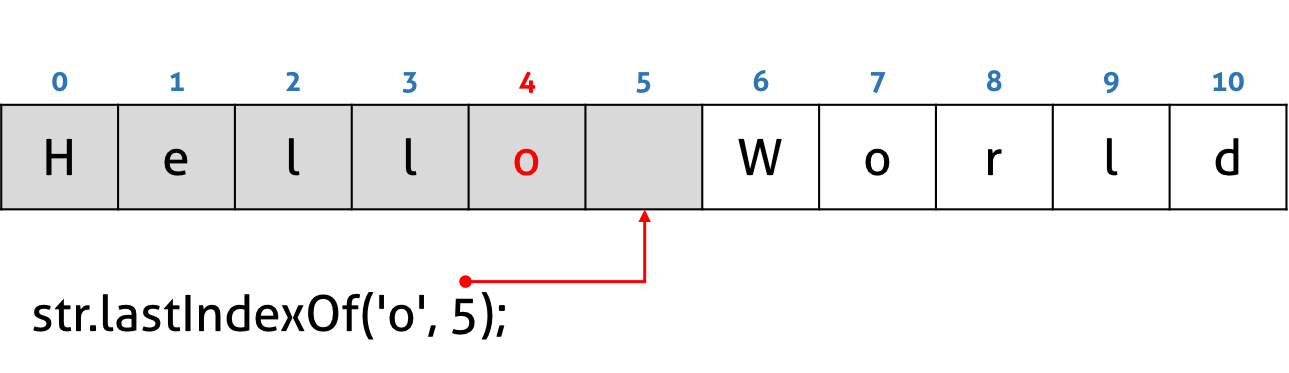
#3.5 String.prototype.replace(searchValue: string | RegExp, replaceValue: string | replacer: (substring: string, …args: any[]) => string): string): string
첫번째 인수로 전달한 문자열 또는 정규표현식을 대상 문자열에서 검색하여 두번째 인수로 전달한 문자열로 대체한다. 원본 문자열은 변경되지 않고 결과가 반영된 새로운 문자열을 반환한다.
검색된 문자열이 여럿 존재할 경우 첫번째로 검색된 문자열만 대체된다.
/**
* @param {string | RegExp} searchValue - 검색 대상 문자열 또는 정규표현식
* @param {string | Function} replacer - 치환 문자열 또는 치환 함수
* @return {string}
*/
str.replace(searchValue, replacer);const str = 'Hello world';
// 첫번째로 검색된 문자열만 대체하여 새로운 문자열을 반환한다.
console.log(str.replace('world', 'Lee')); // Hello Lee
// 특수한 교체 패턴을 사용할 수 있다. ($& => 검색된 문자열)
console.log(str.replace('world', '<strong>$&</strong>')); // Hello <strong>world</strong>
/* 정규표현식
g(Global): 문자열 내의 모든 패턴을 검색한다.
i(Ignore case): 대소문자를 구별하지 않고 검색한다.
*/
console.log(str.replace(/hello/gi, 'Lee')); // Lee Lee
// 두번째 인수로 치환 함수를 전달할 수 있다.
// camelCase => snake_case
const camelCase = 'helloWorld';
// /.[A-Z]/g => 1문자와 대문자의 조합을 문자열 전체에서 검색한다.
console.log(
camelCase.replace(/.[A-Z]/g, function (match) {
// match : oW => match[0] : o, match[1] : W
return match[0] + '_' + match[1].toLowerCase();
}),
); // hello_world
// /(.)([A-Z])/g => 1문자와 대문자의 조합
// $1 => (.)
// $2 => ([A-Z])
console.log(camelCase.replace(/(.)([A-Z])/g, '$1_$2').toLowerCase()); // hello_world
// snake_case => camelCase
const snakeCase = 'hello_world';
// /_./g => _와 1문자의 조합을 문자열 전체에서 검색한다.
console.log(
snakeCase.replace(/_./g, function (match) {
// match : _w => match[1] : w
return match[1].toUpperCase();
}),
); // helloWorld첫번째 인자에는 문자열 또는 정규표현식이 전달된다. 문자열의 경우 첫번째 검색 결과만이 대체되지만 정규표현식을 사용하면 다양한 방식으로 검색할 수 있다.
위 예제에서 /hello/는 패턴이라하며 검색할 문자열을 의미한다. gi는 flag라 하는데 g(global)는 문자열 내에 패턴과 일치하는 모든 문자열을 검색하라는 의미이고 i(ignore)는 대소문자를 구분하지 않는다는 의미이다.
#3.6 String.prototype.split(separator: string | RegExp, limit?: number): string[]
첫번째 인수로 전달한 문자열 또는 정규표현식을 대상 문자열에서 검색하여 문자열을 구분한 후 분리된 각 문자열로 이루어진 배열을 반환한다. 원본 문자열은 변경되지 않는다.
인수가 없는 경우, 대상 문자열 전체를 단일 요소로 하는 배열을 반환한다.
/**
* @param {string | RegExp} [separator] - 구분 대상 문자열 또는 정규표현식
* @param {number} [limit] - 구분 대상수의 한계를 나타내는 정수
* @return {string[]}
*/
str.split([separator[, limit]])
const str = 'How are you doing?';
// 공백으로 구분(단어로 구분)하여 배열로 반환한다
console.log(str.split(' ')); // [ 'How', 'are', 'you', 'doing?' ]
// 정규 표현식
console.log(str.split(/\s/)); // [ 'How', 'are', 'you', 'doing?' ]
// 인수가 없는 경우, 대상 문자열 전체를 단일 요소로 하는 배열을 반환한다.
console.log(str.split()); // [ 'How are you doing?' ]
// 각 문자를 모두 분리한다
console.log(str.split('')); // [ 'H','o','w',' ','a','r','e',' ','y','o','u',' ','d','o','i','n','g','?' ]
// 공백으로 구분하여 배열로 반환한다. 단 요소수는 3개까지만 허용한다
console.log(str.split(' ', 3)); // [ 'How', 'are', 'you' ]
// 'o'으로 구분하여 배열로 반환한다.
console.log(str.split('o')); // [ 'H', 'w are y', 'u d', 'ing?' ]#3.7 String.prototype.substring(start: number, end=this.length): string
첫번째 인수로 전달한 start 인덱스에 해당하는 문자부터 두번째 인자에 전달된 end 인덱스에 해당하는 문자의 바로 이전 문자까지를 모두 반환한다. 이때 첫번째 인수 < 두번째 인수의 관계가 성립된다.
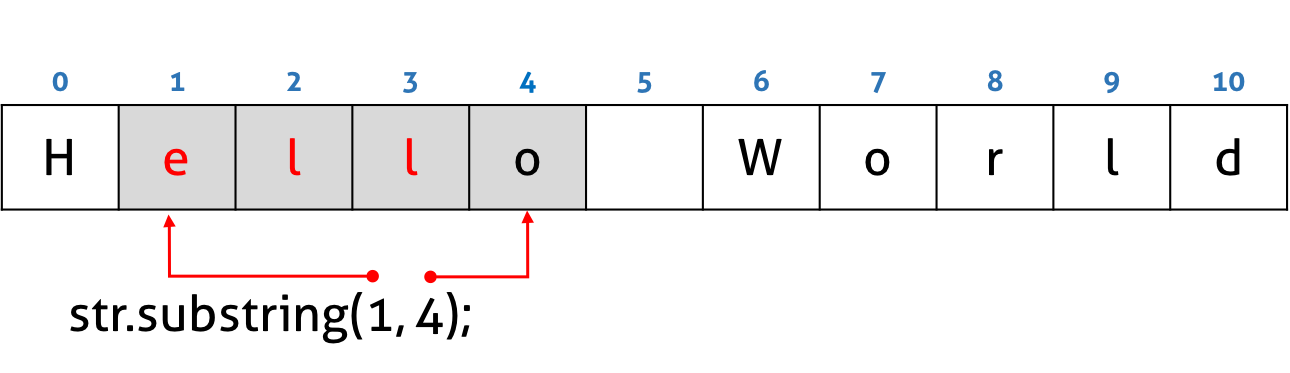
- 첫번째 인수 > 두번째 인수 : 두 인수는 교환된다.
- 두번째 인수가 생략된 경우 : 해당 문자열의 끝까지 반환한다.
- 인수 < 0 또는 NaN인 경우 : 0으로 취급된다.
- 인수 > 문자열의 길이(str.length) : 인수는 문자열의 길이(str.length)으로 취급된다.
/**
* @param {number} start - 0 ~ 해당문자열 길이 -1 까지의 정수
* @param {number} [end=this.length] - 0 ~ 해당문자열 길이까지의 정수
* @return {string}
*/
str.substring(start[, end])
const str = 'Hello World'; // str.length == 11
console.log(str.substring(1, 4)); // ell
// 첫번째 인수 > 두번째 인수 : 두 인수는 교환된다.
console.log(str.substring(4, 1)); // ell
// 두번째 인수가 생략된 경우 : 해당 문자열의 끝까지 반환한다.
console.log(str.substring(4)); // o World
// 인수 < 0 또는 NaN인 경우 : 0으로 취급된다.
console.log(str.substring(-2)); // Hello World
// 인수 > 문자열의 길이(str.length) : 인수는 문자열의 길이(str.length)으로 취급된다.
console.log(str.substring(1, 12)); // ello World
console.log(str.substring(11)); // ''
console.log(str.substring(20)); // ''
console.log(str.substring(0, str.indexOf(' '))); // 'Hello'
console.log(str.substring(str.indexOf(' ') + 1, str.length)); // 'World'#3.8 String.prototype.slice(start?: number, end?: number): string
String.prototype.substring과 동일하다. 단, String.prototype.slice는 음수의 인수를 전달할 수 있다.
const str = 'hello world';
// 인수 < 0 또는 NaN인 경우 : 0으로 취급된다.
console.log(str.substring(-5)); // 'hello world'
// 뒤에서 5자리를 잘라내어 반환한다.
console.log(str.slice(-5)); // 'world'
// 2번째부터 마지막 문자까지 잘라내어 반환
console.log(str.substring(2)); // llo world
console.log(str.slice(2)); // llo world
// 0번째부터 5번째 이전 문자까지 잘라내어 반환
console.log(str.substring(0, 5)); // hello
console.log(str.slice(0, 5)); // hello#3.9 String.prototype.toLowerCase(): string
대상 문자열의 모든 문자를 소문자로 변경한다.
console.log('Hello World!'.toLowerCase()); // hello world!#3.10 String.prototype.toUpperCase(): string
대상 문자열의 모든 문자를 대문자로 변경한다.
console.log('Hello World!'.toUpperCase()); // HELLO WORLD!#3.11 String.prototype.trim(): string
대상 문자열 양쪽 끝에 있는 공백 문자를 제거한 문자열을 반환한다.
const str = ' foo ';
console.log(str.trim()); // 'foo'
// String.prototype.replace
console.log(str.replace(/\s/g, '')); // 'foo'
console.log(str.replace(/^\s+/g, '')); // 'foo '
console.log(str.replace(/\s+$/g, '')); // ' foo'
// String.prototype.{trimStart,trimEnd} : Proposal stage 3
console.log(str.trimStart()); // 'foo '
console.log(str.trimEnd()); // ' foo'#3.12 String.prototype.repeat(count: number): string
인수로 전달한 숫자만큼 반복해 연결한 새로운 문자열을 반환한다. count가 0이면 빈 문자열을 반환하고 음수이면 RangeError를 발생시킨다.
console.log('abc'.repeat(0)); // ''
console.log('abc'.repeat(1)); // 'abc'
console.log('abc'.repeat(2)); // 'abcabc'
console.log('abc'.repeat(2.5)); // 'abcabc' (2.5 → 2)
console.log('abc'.repeat(-1)); // RangeError: Invalid count value#3.13 String.prototype.includes(searchString: string, position?: number): boolean
인수로 전달한 문자열이 포함되어 있는지를 검사하고 결과를 불리언 값으로 반환한다. 두번째 인수는 옵션으로 검색할 위치를 나타내는 정수이다.
const str = 'hello world';
console.log(str.includes('hello')); // true
console.log(str.includes(' ')); // true
console.log(str.includes('wo')); // true
console.log(str.includes('wow')); // false
console.log(str.includes('')); // true
console.log(str.includes()); // false
// String.prototype.indexOf 메소드로 대체할 수 있다.
console.log(str.indexOf('hello')); // 0ㅤㅤ
📍 Array : 배열
배열(array)은 1개의 변수에 여러 개의 값을 순차적으로 저장할 때 사용한다. 자바스크립트의 배열은 객체이며 유용한 내장 메소드를 포함하고 있다.
배열은 Array 생성자로 생성된 Array 타입의 객체이며 프로토타입 객체는 Array.prototype이다.
#1. 배열의 생성
#1.1 배열 리터럴
0개 이상의 값을 쉼표로 구분하여 대괄호([])로 묶는다. 첫번째 값은 인덱스 ‘0’으로 읽을 수 있다. 존재하지 않는 요소에 접근하면 undefined를 반환한다.
const emptyArr = [];
console.log(emptyArr[1]); // undefined
console.log(emptyArr.length); // 0
const arr = ['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine'];
console.log(arr[1]); // 'one'
console.log(arr.length); // 10
console.log(typeof arr); // object위의 배열을 객체 리터럴로 유사하게 표현하면 다음과 같다.
const obj = {
0: 'zero',
1: 'one',
2: 'two',
3: 'three',
4: 'four',
5: 'five',
6: 'six',
7: 'seven',
8: 'eight',
9: 'nine',
};배열 리터럴은 객체 리터럴과 달리 프로퍼티명이 없고 각 요소의 값만이 존재한다. 객체는 프로퍼티 값에 접근하기 위해 대괄호 표기법 또는 마침표 표기법을 사용하며 프로퍼티명을 키로 사용한다. 배열은 요소에 접근하기 위해 대괄호 표기법만을 사용하며 대괄호 내에 접근하고자 하는 요소의 인덱스를 넣어준다. 인덱스는 0부터 시작한다.
두 객체의 근본적 차이는 배열 리터럴 arr의 프로토타입 객체는 Array.prototype이지만 객체 리터럴 obj의 프로토타입 객체는 Object.prototype이라는 것이다.
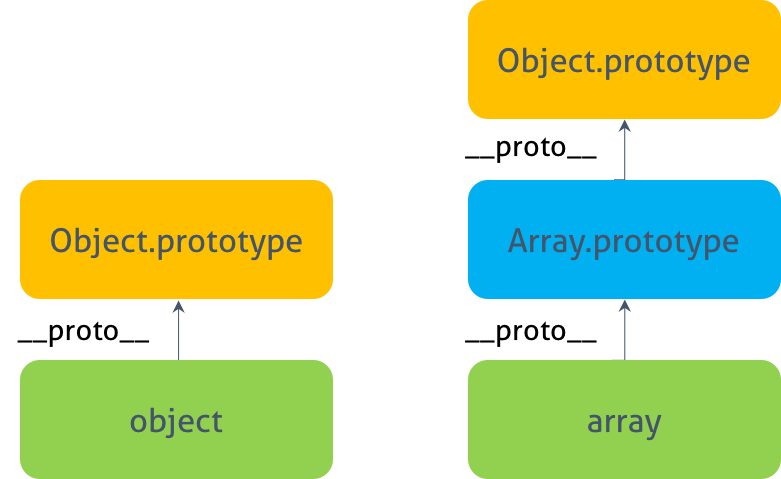
객체리터럴과 배열리터럴의 프로토타입
const emptyArr = [];
const emptyObj = {};
console.dir(emptyArr.__proto__);
console.dir(emptyObj.__proto__);
대부분의 프로그래밍 언어에서 배열의 요소들은 모두 같은 데이터 타입이어야 하지만, 자바스크립트 배열은 어떤 데이터 타입의 조합이라도 포함할 수 있다.
const misc = [
'string',
10,
true,
null,
undefined,
NaN,
Infinity,
['nested array'],
{ object: true },
function () {},
];
console.log(misc.length); // 10#1.2 Array() 생성자 함수
배열은 일반적으로 배열 리터럴 방식으로 생성하지만 배열 리터럴 방식도 결국 내장 함수 Array() 생성자 함수로 배열을 생성하는 것을 단순화시킨 것이다. Array() 생성자 함수는 Array.prototype.constructor 프로퍼티로 접근할 수 있다.
Array() 생성자 함수는 매개변수의 갯수에 따라 다르게 동작한다.
매개변수가 1개이고 숫자인 경우 매개변수로 전달된 숫자를 length 값으로 가지는 빈 배열을 생성한다.
const arr = new Array(2);
console.log(arr); // (2) [empty × 2]그 외의 경우 매개변수로 전달된 값들을 요소로 가지는 배열을 생성한다.
const arr = new Array(1, 2, 3);
console.log(arr); // [1, 2, 3]#2. 배열 요소의 추가와 삭제
#2.1 배열 요소의 추가
객체가 동적으로 프로퍼티를 추가할 수 있는 것처럼 배열도 동적으로 요소를 추가할 수 있다. 이때 순서에 맞게 값을 할당할 필요는 없고 인덱스를 사용하여 필요한 위치에 값을 할당한다. 배열의 길이(length)는 마지막 인덱스를 기준으로 산정된다.
const arr = [];
console.log(arr[0]); // undefined
arr[1] = 1;
arr[3] = 3;
console.log(arr); // (4) [empty, 1, empty, 3]
console.log(arr.lenth); // 4값이 할당되지 않은 인덱스 위치의 요소는 생성되지 않는다는 것에 주의한다. 단, 존재하지 않는 요소를 참조하면 undefined가 반환된다.
// 값이 할당되지 않은 인덱스 위치의 요소는 생성되지 않는다.
console.log(Object.keys(arr)); // [ '1', '3' ]
// arr[0]이 undefined를 반환한 이유는 존재하지 않는 프로퍼티에 접근했을 때 undefined를 반환하는 것과 같은 이치다.
console.log(arr[0]); // undefined#2.2 배열 요소의 삭제
배열은 객체이기 때문에 배열의 요소를 삭제하기 위해 delete 연산자를 사용할 수 있다. 이때 length에는 변함이 없다. 해당 요소를 완전히 삭제하여 length에도 반영되게 하기 위해서는 [Array.prototype.splice] 메소드를 사용한다.
const numbersArr = ['zero', 'one', 'two', 'three'];
// 요소의 값만 삭제된다
delete numbersArr[2]; // (4) ["zero", "one", empty, "three"]
console.log(numbersArr);
// 요소 값만이 아니라 요소를 완전히 삭제한다
// splice(시작 인덱스, 삭제할 요소수)
numbersArr.splice(2, 1); // (3) ["zero", "one", "three"]
console.log(numbersArr);#3. 배열의 순회
객체의 프로퍼티를 순회할 때 for…in 문을 사용한다. 배열 역시 객체이므로 for…in 문을 사용할 수 있다. 그러나 배열은 객체이기 때문에 프로퍼티를 가질 수 있다. for…in 문을 사용하면 배열 요소뿐만 아니라 불필요한 프로퍼티까지 출력될 수 있고 요소들의 순서를 보장하지 않으므로 배열을 순회하는데 적합하지 않다.
따라서 배열의 순회에는 forEach 메소드, for 문, for…of 문을 사용하는 것이 좋다.
const arr = [0, 1, 2, 3];
arr.foo = 10;
for (const key in arr) {
console.log('key: ' + key, 'value: ' + arr[key]);
}
// key: 0 value: 0
// key: 1 value: 1
// key: 2 value: 2
// key: 3 value: 3
// key: foo value: 10 => 불필요한 프로퍼티까지 출력
arr.forEach((item, index) => console.log(index, item));
for (let i = 0; i < arr.length; i++) {
console.log(i, arr[i]);
}
for (const item of arr) {
console.log(item);
}#4. Array Property
#4.1 Array.length
length 프로퍼티는 요소의 개수(배열의 길이)를 나타낸다. 배열 인덱스는 32bit 양의 정수로 처리된다. 따라서 length 프로퍼티의 값은 양의 정수이며 232 - 1(4,294,967,296 - 1) 미만이다.
const arr = [1, 2, 3, 4, 5];
console.log(arr.length); // 5
arr[4294967294] = 100;
console.log(arr.length); // 4294967295
console.log(arr); // (4294967295) [1, 2, 3, 4, 5, empty × 4294967289, 100]
arr[4294967295] = 1000;
console.log(arr.length); // 4294967295
console.log(arr); // (4294967295) [1, 2, 3, 4, 5, empty × 4294967289, 100, 4294967295: 1000]주의할 것은 배열 요소의 개수와 length 프로퍼티의 값이 반드시 일치하지는 않는다는 것이다.
배열 요소의 개수와 length 프로퍼티의 값이 일치하지 않는 배열을 희소 배열(sparse array)이라 한다. 희소 배열은 배열의 요소가 연속적이지 않은 배열을 의미한다. 희소 배열이 아닌 일반 배열은 배열의 요소 개수와 length 프로퍼티의 값이 언제나 일치하지만 희소 배열은 배열의 요소 개수보다 length 프로퍼티의 값이 언제나 크다. 희소 배열은 일반 배열보다 느리며 메모리를 낭비한다.
현재 length 프로퍼티 값보다 더 큰 인덱스로 요소를 추가하면 새로운 요소를 추가할 수 있도록 자동으로 length 프로퍼티의 값이 늘어난다. length 프로퍼티의 값은 가장 큰 인덱스에 1을 더한 것과 같다.
const arr = [];
console.log(arr.length); // 0
arr[1000] = true;
console.log(arr); // (1001) [empty × 1000, true]
console.log(arr.length); // 1001
console.log(arr[0]); // undefinedlength 프로퍼티의 값은 명시적으로 변경할 수 있다. 만약 length 프로퍼티의 값을 현재보다 작게 변경하면 변경된 length 프로퍼티의 값보다 크거나 같은 인덱스에 해당하는 요소는 모두 삭제된다.
const arr = [1, 2, 3, 4, 5];
// 배열 길이의 명시적 변경
arr.length = 3;
console.log(arr); // (3) [1, 2, 3]#5. Array Method
- ✏️ 메소드는
this(원본 배열)를 변경한다. - 🔒 메소드는
this(원본 배열)를 변경하지 않는다.
#5.1 Array.isArray(arg: any): boolean
정적 메소드 Array.isArray는 주어진 인수가 배열이면 true, 배열이 아니면 false를 반환한다.
// true
Array.isArray([]);
Array.isArray([1, 2]);
Array.isArray(new Array());
// false
Array.isArray();
Array.isArray({});
Array.isArray(null);
Array.isArray(undefined);
Array.isArray(1);
Array.isArray('Array');
Array.isArray(true);
Array.isArray(false);#5.2 Array.from
ES6에서 새롭게 도입된 Array.from 메소드는 유사 배열 객체(array-like object) 또는 [이터러블 객체(iterable object)]를 변환하여 새로운 배열을 생성한다.
// 문자열은 이터러블이다.
const arr1 = Array.from('Hello');
console.log(arr1); // [ 'H', 'e', 'l', 'l', 'o' ]
// 유사 배열 객체를 새로운 배열을 변환하여 반환한다.
const arr2 = Array.from({ length: 2, 0: 'a', 1: 'b' });
console.log(arr2); // [ 'a', 'b' ]
// Array.from의 두번째 매개변수에게 배열의 모든 요소에 대해 호출할 함수를 전달할 수 있다.
// 이 함수는 첫번째 매개변수에게 전달된 인수로 생성된 배열의 모든 요소를 인수로 전달받아 호출된다.
const arr3 = Array.from({ length: 5 }, function (v, i) {
return i;
});
console.log(arr3); // [ 0, 1, 2, 3, 4 ]#5.3 Array.of
ES6에서 새롭게 도입된 Array.of 메소드는 전달된 인수를 요소로 갖는 배열을 생성한다.
Array.of는 Array 생성자 함수와 다르게 전달된 인수가 1개이고 숫자이더라도 인수를 요소로 갖는 배열을 생성한다.
// 전달된 인수가 1개이고 숫자이더라도 인수를 요소로 갖는 배열을 생성한다.
const arr1 = Array.of(1);
console.log(arr1); // // [1]
const arr2 = Array.of(1, 2, 3);
console.log(arr2); // [1, 2, 3]
const arr3 = Array.of('string');
console.log(arr3); // 'string'#5.4 Array.prototype.indexOf(searchElement: T, fromIndex?: number): number
원본 배열에서 인수로 전달된 요소를 검색하여 인덱스를 반환한다.
- 중복되는 요소가 있는 경우, 첫번째 인덱스를 반환한다.
- 해당하는 요소가 없는 경우, -1을 반환한다.
const arr = [1, 2, 2, 3];
// 배열 arr에서 요소 2를 검색하여 첫번째 인덱스를 반환
arr.indexOf(2); // -> 1
// 배열 arr에서 요소 4가 없으므로 -1을 반환
arr.indexOf(4); // -1
// 두번째 인수는 검색을 시작할 인덱스이다. 두번째 인수를 생략하면 처음부터 검색한다.
arr.indexOf(2, 2); // 2indexOf 메소드는 배열에 요소가 존재하는지 여부를 확인할 때 유용하다.
const foods = ['apple', 'banana', 'orange'];
// foods 배열에 'orange' 요소가 존재하는지 확인
if (foods.indexOf('orange') === -1) {
// foods 배열에 'orange' 요소가 존재하지 않으면 'orange' 요소를 추가
foods.push('orange');
}
console.log(foods); // ["apple", "banana", "orange"]ES7에서 새롭게 도입된 Array.prototype.includes 메소드를 사용하면 보다 가독성이 좋다.
const foods = ['apple', 'banana'];
// ES7: Array.prototype.includes
// foods 배열에 'orange' 요소가 존재하는지 확인
if (!foods.includes('orange')) {
// foods 배열에 'orange' 요소가 존재하지 않으면 'orange' 요소를 추가
foods.push('orange');
}
console.log(foods); // ["apple", "banana", "orange"]#5.5 Array.prototype.concat(…items: Array<T[] | T>): T[]
인수로 전달된 값들(배열 또는 값)을 원본 배열의 마지막 요소로 추가한 새로운 배열을 반환한다. 인수로 전달한 값이 배열인 경우, 배열을 해체하여 새로운 배열의 요소로 추가한다. 원본 배열은 변경되지 않는다.
const arr1 = [1, 2];
const arr2 = [3, 4];
// 배열 arr2를 원본 배열 arr1의 마지막 요소로 추가한 새로운 배열을 반환
// 인수로 전달한 값이 배열인 경우, 배열을 해체하여 새로운 배열의 요소로 추가한다.
let result = arr1.concat(arr2);
console.log(result); // [1, 2, 3, 4]
// 숫자를 원본 배열 arr1의 마지막 요소로 추가한 새로운 배열을 반환
result = arr1.concat(3);
console.log(result); // ["1, 2, 3]
// 배열 arr2와 숫자를 원본 배열 arr1의 마지막 요소로 추가한 새로운 배열을 반환
result = arr1.concat(arr2, 5);
console.log(result); // [1, 2, 3, 4, 5]
// 원본 배열은 변경되지 않는다.
console.log(arr1); // [1, 2]#5.6 Array.prototype.join(separator?: string): string
원본 배열의 모든 요소를 문자열로 변환한 후, 인수로 전달받은 값, 즉 구분자(separator)로 연결한 문자열을 반환한다. 구분자(separator)는 생략 가능하며 기본 구분자는 ,이다.
const arr = [1, 2, 3, 4];
// 기본 구분자는 ','이다.
// 원본 배열 arr의 모든 요소를 문자열로 변환한 후, 기본 구분자 ','로 연결한 문자열을 반환
let result = arr.join();
console.log(result); // '1,2,3,4';
// 원본 배열 arr의 모든 요소를 문자열로 변환한 후, 빈문자열로 연결한 문자열을 반환
result = arr.join('');
console.log(result); // '1234'
// 원본 배열 arr의 모든 요소를 문자열로 변환한 후, 구분자 ':'로 연결한 문자열을 반환
result = arr.join(':');
console.log(result); // '1:2:3:4'#5.7 Array.prototype.push(…items: T[]): number
인수로 전달받은 모든 값을 원본 배열의 마지막에 요소로 추가하고 변경된 length 값을 반환한다. push 메소드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
// 인수로 전달받은 모든 값을 원본 배열의 마지막에 요소로 추가하고 변경된 length 값을 반환한다.
let result = arr.push(3, 4);
console.log(result); // 4
// push 메소드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 2, 3, 4]push 메소드와 concat 메소드는 유사하게 동작하지만 미묘한 차이가 있다.
- push 메소드는 원본 배열을 직접 변경하지만 concat 메소드는 원본 배열을 변경하지 않고 새로운 배열을 반환한다.
const arr1 = [1, 2];
// push 메소드는 원본 배열을 직접 변경한다.
arr1.push(3, 4);
console.log(arr1); // [1, 2, 3, 4]
const arr2 = [1, 2];
// concat 메소드는 원본 배열을 변경하지 않고 새로운 배열을 반환한다.
const result = arr2.concat(3, 4);
console.log(result); // [1, 2, 3, 4]- 인수로 전달받은 값이 배열인 경우, push 메소드는 배열을 그대로 원본 배열의 마지막 요소로 추가하지만 concat 메소드는 배열을 해체하여 새로운 배열의 마지막 요소로 추가한다.
const arr1 = [1, 2];
// 인수로 전달받은 배열을 그대로 원본 배열의 마지막 요소로 추가한다
arr1.push([3, 4]);
console.log(arr1); // [1, 2, [3, 4]]
const arr2 = [1, 2];
// 인수로 전달받은 배열을 해체하여 새로운 배열의 마지막 요소로 추가한다
const result = arr2.concat([3, 4]);
console.log(result); // [1, 2, 3, 4]push 메소드는 성능면에서 좋지 않다. push 메소드는 배열의 마지막에 요소를 추가하므로 length 프로퍼티를 사용하여 직접 요소를 추가할 수도 있다. 이 방법이 push 메소드보다 빠르다.
const arr = [1, 2];
// arr.push(3)와 동일한 처리를 한다. 이 방법이 push 메소드보다 빠르다.
arr[arr.length] = 3;
console.log(arr); // [1, 2, 3]push 메소드는 원본 배열을 직접 변경하는 부수 효과가 있다. 따라서 push 메소드보다는 ES6의 spread 문법을 사용하는 편이 좋다. spread 문법은 나중에 살펴볼 것이다.
const arr = [1, 2];
// ES6 spread 문법
const newArr = [...arr, 3];
// arr.push(3);
console.log(newArr); // [1, 2, 3]#5.8 Array.prototype.pop(): T | undefined
원본 배열에서 마지막 요소를 제거하고 제거한 요소를 반환한다. 원본 배열이 빈 배열이면 undefined를 반환한다. pop 메소드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
// 원본 배열에서 마지막 요소를 제거하고 제거한 요소를 반환한다.
let result = arr.pop();
console.log(result); // 2
// pop 메소드는 원본 배열을 직접 변경한다.
console.log(arr); // [1]pop 메소드와 push 메소드를 사용하면 스택을 쉽게 구현할 수 있다.
스택(stack)은 데이터를 마지막에 밀어 넣고, 마지막에 밀어 넣은 데이터를 먼저 꺼내는 후입 선출(LIFO - Last In First Out) 방식의 자료 구조이다. 스택은 언제나 가장 마지막에 밀어 넣은 최신 데이터를 취득한다. 스택에 데이터를 밀어 넣는 것을 푸시(push)라 하고 스택에서 데이터를 꺼내는 것을 팝(pop)이라고 한다.
// 스택 자료 구조를 구현하기 위한 배열
const stack = [];
// 스택의 가장 마지막에 데이터를 밀어 넣는다.
stack.push(1);
console.log(stack); // [1]
// 스택의 가장 마지막에 데이터를 밀어 넣는다.
stack.push(2);
console.log(stack); // [1, 2]
// 스택의 가장 마지막 데이터, 즉 가장 나중에 밀어 넣은 최신 데이터를 꺼낸다.
let value = stack.pop();
console.log(value, stack); // 2 [1]
// 스택의 가장 마지막 데이터, 즉 가장 나중에 밀어 넣은 최신 데이터를 꺼낸다.
value = stack.pop();
console.log(value, stack); // 1 []#5.9 Array.prototype.reverse(): this
배열 요소의 순서를 반대로 변경한다. 이때 원본 배열이 변경된다. 반환값은 변경된 배열이다.
const a = ['a', 'b', 'c'];
const b = a.reverse();
// 원본 배열이 변경된다
console.log(a); // [ 'c', 'b', 'a' ]
console.log(b); // [ 'c', 'b', 'a' ]#5.10 Array.prototype.shift(): T | undefined
배열에서 첫요소를 제거하고 제거한 요소를 반환한다. 만약 빈 배열일 경우 undefined를 반환한다. shift 메소드는 대상 배열 자체를 변경한다.
const a = ['a', 'b', 'c'];
const c = a.shift();
// 원본 배열이 변경된다.
console.log(a); // a --> [ 'b', 'c' ]
console.log(c); // c --> 'a'shift는 push와 함께 배열을 큐(FIFO: First In First Out)처럼 동작하게 한다.
const arr = [];
arr.push(1); // [1]
arr.push(2); // [1, 2]
arr.push(3); // [1, 2, 3]
arr.shift(); // [2, 3]
arr.shift(); // [3]
arr.shift(); // []Array.prototype.pop()은 마지막 요소를 제거하고 제거한 요소를 반환한다.
const a = ['a', 'b', 'c'];
const c = a.pop();
// 원본 배열이 변경된다.
console.log(a); // a --> ['a', 'b']
console.log(c); // c --> 'c'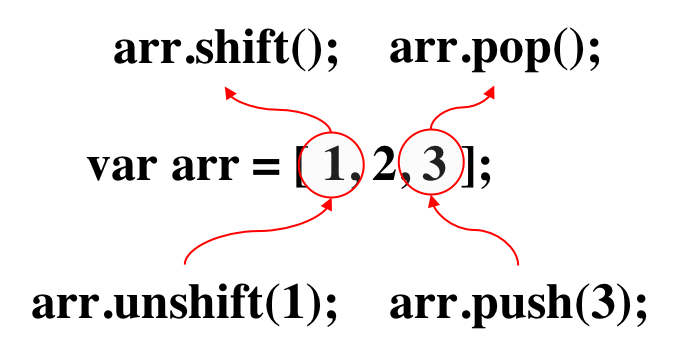
#5.11 Array.prototype.slice(start=0, end=this.length): T[]
인자로 지정된 배열의 부분을 복사하여 반환한다. 원본 배열은 변경되지 않는다.
첫번째 매개변수 start에 해당하는 인덱스를 갖는 요소부터 매개변수 end에 해당하는 인덱스를 가진 요소 전까지 복사된다.
- 매개변수
start복사를 시작할 인텍스. 음수인 경우 배열의 끝에서의 인덱스를 나타낸다. 예를 들어 slice(-2)는 배열의 마지막 2개의 요소를 반환한다.end옵션이며 기본값은 length 값이다.
const items = ['a', 'b', 'c'];
// items[0]부터 items[1] 이전(items[1] 미포함)까지 반환
let res = items.slice(0, 1);
console.log(res); // [ 'a' ]
// items[1]부터 items[2] 이전(items[2] 미포함)까지 반환
res = items.slice(1, 2);
console.log(res); // [ 'b' ]
// items[1]부터 이후의 모든 요소 반환
res = items.slice(1);
console.log(res); // [ 'b', 'c' ]
// 인자가 음수인 경우 배열의 끝에서 요소를 반환
res = items.slice(-1);
console.log(res); // [ 'c' ]
res = items.slice(-2);
console.log(res); // [ 'b', 'c' ]
// 모든 요소를 반환 (= 복사본(shallow copy) 생성)
res = items.slice();
console.log(res); // [ 'a', 'b', 'c' ]
// 원본은 변경되지 않는다.
console.log(items); // [ 'a', 'b', 'c' ]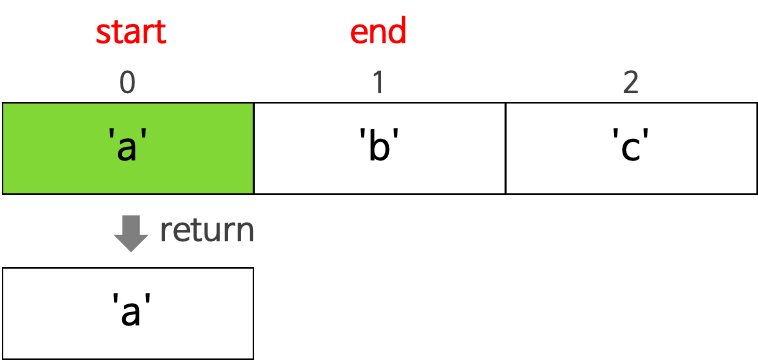
slice 메소드에 인자를 전달하지 않으면 원본 배열의 복사본을 생성하여 반환한다.
const arr = [1, 2, 3];
// 원본 배열 arr의 새로운 복사본을 생성한다.
const copy = arr.slice();
console.log(copy, copy === arr); // [ 1, 2, 3 ] false이때 원본 배열의 각 요소를 얕은 복사(shallow copy)하여 새로운 복사본을 생성한다.
const todos = [
{ id: 1, content: 'HTML', completed: false },
{ id: 2, content: 'CSS', completed: true },
{ id: 3, content: 'Javascript', completed: false },
];
// shallow copy
const _todos = todos.slice();
// const _todos = [...todos];
console.log(_todos === todos); // false
// 배열의 요소는 같다. 즉, 얕은 복사되었다.
console.log(_todos[0] === todos[0]); // trueSpread 문법과 Object.assign는 원본을 shallow copy한다. Deep copy를 위해서는 lodash의 deepClone을 사용하는 것을 추천한다.
이를 이용하여 [arguments], HTMLCollection, NodeList와 같은 유사 배열 객체(Array-like Object)를 배열로 변환할 수 있다.
function sum() {
// 유사 배열 객체 => Array
const arr = Array.prototype.slice.call(arguments);
console.log(arr); // [1, 2, 3]
return arr.reduce(function (pre, cur) {
return pre + cur;
});
}
console.log(sum(1, 2, 3));ES6에서 유사 배열 객체를 배열로 변환하는 방법은 아래와 같다.
// 유사 배열 객체 => Array
function sum() {
...
// Spread 문법
const arr = [...arguments];
// Array.from 메소드는 유사 배열 객체를 복사하여 배열을 생성한다.
const arr = Array.from(arguments);
...
}
#5.12 Array.prototype.splice(start: number, deleteCount=this.length-start, …items: T[]): T[]
기존의 배열의 요소를 제거하고 그 위치에 새로운 요소를 추가한다. 배열 중간에 새로운 요소를 추가할 때도 사용된다.
- 매개변수
start배열에서의 시작 위치이다. start 만을 지정하면 배열의 start부터 모든 요소를 제거한다.deleteCount시작 위치(start)부터 제거할 요소의 수이다. deleteCount가 0인 경우, 아무런 요소도 제거되지 않는다. (옵션)items삭제한 위치에 추가될 요소들이다. 만약 아무런 요소도 지정하지 않을 경우, 삭제만 한다. (옵션)
- 반환값 삭제한 요소들을 가진 배열이다.
이 메소드의 가장 일반적인 사용은 배열에서 요소를 삭제할 때다.
const items1 = [1, 2, 3, 4];
// items[1]부터 2개의 요소를 제거하고 제거된 요소를 배열로 반환
const res1 = items1.splice(1, 2);
// 원본 배열이 변경된다.
console.log(items1); // [ 1, 4 ]
// 제거한 요소가 배열로 반환된다.
console.log(res1); // [ 2, 3 ]
const items2 = [1, 2, 3, 4];
// items[1]부터 모든 요소를 제거하고 제거된 요소를 배열로 반환
const res2 = items2.splice(1);
// 원본 배열이 변경된다.
console.log(items2); // [ 1 ]
// 제거한 요소가 배열로 반환된다.
console.log(res2); // [ 2, 3, 4 ]
배열에서 요소를 제거하고 제거한 위치에 다른 요소를 추가한다.
const items = [1, 2, 3, 4];
// items[1]부터 2개의 요소를 제거하고 그자리에 새로운 요소를 추가한다. 제거된 요소가 반환된다.
const res = items.splice(1, 2, 20, 30);
// 원본 배열이 변경된다.
console.log(items); // [ 1, 20, 30, 4 ]
// 제거한 요소가 배열로 반환된다.
console.log(res); // [ 2, 3 ]
배열 중간에 새로운 요소를 추가할 때도 사용된다.
const items = [1, 2, 3, 4];
// items[1]부터 0개의 요소를 제거하고 그자리(items[1])에 새로운 요소를 추가한다. 제거된 요소가 반환된다.
const res = items.splice(1, 0, 100);
// 원본 배열이 변경된다.
console.log(items); // [ 1, 100, 2, 3, 4 ]
// 제거한 요소가 배열로 반환된다.
console.log(res); // [ ]배열 중간에 배열의 요소들을 해체하여 추가할 때도 사용된다.
const items = [1, 4];
// items[1]부터 0개의 요소를 제거하고 그자리(items[1])에 새로운 배열를 추가한다. 제거된 요소가 반환된다.
// items.splice(1, 0, [2, 3]); // [ 1, [ 2, 3 ], 4 ]
Array.prototype.splice.apply(items, [1, 0].concat([2, 3]));
// ES6
// items.splice(1, 0, ...[2, 3]);
console.log(items); // [ 1, 2, 3, 4 ]slice는 배열의 일부분을 복사해서 반환하며 원본을 훼손하지 않는다. splice는 배열에서 요소를 제거하고 제거한 위치에 다른 요소를 추가하며 원본을 훼손한다.
ㅤㅤ
📍 Array : 자바스크립트 배열은 배열이 아니다
일반적으로 배열이라는 자료 구조의 개념은 동일한 크기의 메모리 공간이 빈틈없이 연속적으로 나열된 자료 구조를 말한다. 즉, 배열의 요소는 하나의 타입으로 통일되어 있으며 서로 연속적으로 인접해 있다. 이러한 배열을 밀집 배열(dense array)이라 한다.
일반적인 배열은 동일한 크기의 메모리 공간이 연속적으로 나열된 밀집 배열이다.
이처럼 배열의 요소는 동일한 크기를 갖으며 빈틈없이 연속적으로 이어져 있으므로 아래와 같이 인덱스를 통해 단 한번의 연산으로 임의의 요소에 접근(임의 접근(random access), 시간 복잡도 O(1))할 수 있다. 이는 매우 효율적이며 고속으로 동작한다.
검색 대상 요소의 메모리 주소 = 배열의 시작 메모리 주소 + 인덱스 * 요소의 바이트 수
예를 들어, 위 그림처럼 메모리 주소 1000에서 시작하고 각 요소의 크기가 8byte인 배열을 생각해 본다.
- 인덱스가 0인 요소의 메모리 주소 : 1000 + 0 * 8 = 1000
- 인덱스가 1인 요소에 메모리 주소 : 1000 + 1 * 8 = 1008
- 인덱스가 2인 요소에 메모리 주소 : 1000 + 2 * 8 = 1016
이처럼 배열은 인덱스를 통해 효율적으로 요소에 접근할 수 있다는 장점이 있다. 하지만 정렬되지 않은 배열에서 특정한 값을 탐색하는 경우, 모든 배열 요소를 처음부터 값을 발견할 때까지 차례대로 탐색(선형 탐색(linear search), 시간 복잡도 O(n))해야 한다.
// 선형 검색을 통해 주어진 배열(array)에 주어진 값(target)이 요소로 존재하는지 확인하여
// 존재하는 경우 해당 인덱스를 반환하고 존재하지 않는 경우 -1을 반환하는 함수
function linearSearch(array, target) {
const length = array.length;
for (let i = 0; i < length; i++) {
if (array[i] === target) return i;
}
return -1;
}
console.log(linearSearch([1, 2, 3, 4, 5, 6], 3)); // 2
console.log(linearSearch([1, 2, 3, 4, 5, 6], 0)); // -1또한 배열에 요소를 삽입하거나 삭제하는 경우, 배열 요소를 연속적으로 유지하기 위해 요소를 이동시켜야 하는 단점도 있다.
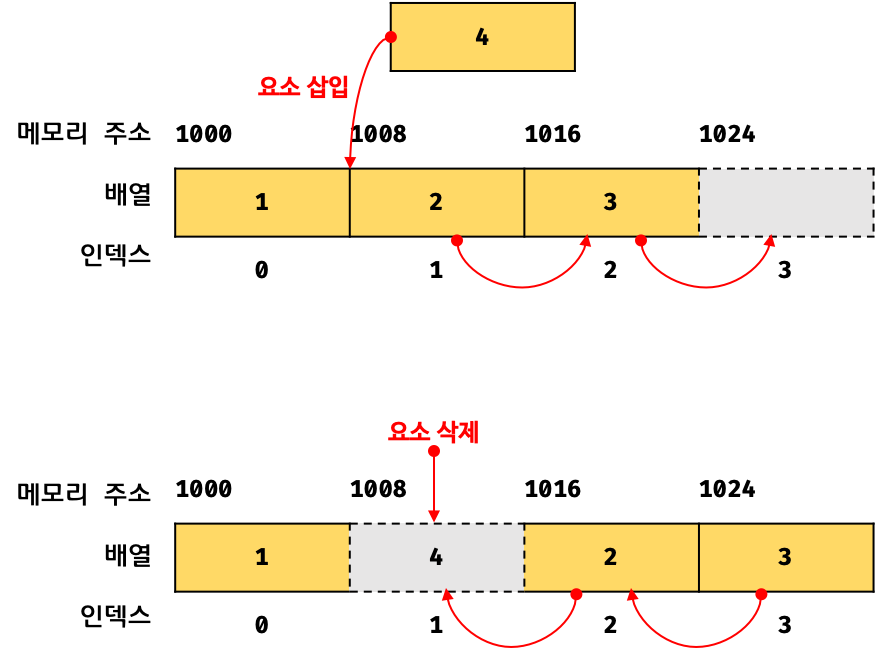
자바스크립트의 배열은 지금까지 살펴본 일반적인 의미의 배열과 다르다. 즉, 배열의 요소를 위한 각각의 메모리 공간은 동일한 크기를 갖지 않아도 되며 연속적으로 이어져 있지 않을 수도 있다. 배열의 요소가 연속적으로 이어져 있지 않는 배열을 희소 배열(sparse array)이라 한다.
이처럼 자바스크립트의 배열은 엄밀히 말해 일반적 의미의 배열이 아니다. 자바스크립트의 배열은 일반적인 배열의 동작을 흉내낸 특수한 객체이다.
console.log(Object.getOwnPropertyDescriptors([1, 2, 3]));
/*
{
'0': { value: 1, writable: true, enumerable: true, configurable: true },
'1': { value: 2, writable: true, enumerable: true, configurable: true },
'2': { value: 3, writable: true, enumerable: true, configurable: true },
length: { value: 3, writable: true, enumerable: false, configurable: false }
}
*/이처럼 자바스크립트 배열은 인덱스를 프로퍼티 키로 갖으며 length 프로퍼티를 갖는 특수한 객체이다. 자바스크립트 배열의 요소는 사실 프로퍼티 값이다. 자바스크립트에서 사용할 수 있는 모든 값은 객체의 프로퍼티 값이 될 수 있으므로 어떤 타입의 값이라도 배열의 요소가 될 수 있다.
const arr = ['string', 10, true, null, undefined, NaN, Infinity, [], {}, function () {}];일반적인 배열과 자바스크립트 배열의 장단점을 정리해보면 아래와 같다.
- 일반적인 배열은 인덱스로 배열 요소에 빠르게 접근할 수 있다. 하지만 특정 요소를 탐색하거나 요소를 삽입 또는 삭제하는 경우에는 효율적이지 않다.
- 자바스크립트 배열은 해시 테이블로 구현된 객체이므로 인덱스로 배열 요소에 접근하는 경우, 일반적인 배열보다 성능적인 면에서 느릴 수 밖에 없는 구조적인 단점을 갖는다. 하지만 특정 요소를 탐색하거나 요소를 삽입 또는 삭제하는 경우에는 일반적인 배열보다 빠른 성능을 기대할 수 있다.
즉, 자바스크립트 배열은 인덱스로 배열 요소에 접근하는 경우에는 일반적인 배열보다 느리지만 특정 요소를 탐색하거나 요소를 삽입 또는 삭제하는 경우에는 일반적인 배열보다 빠르다. 자바스크립트 배열은 인덱스로 접근하는 경우의 성능 대신 특정 요소를 탐색하거나 배열 요소를 삽입 또는 삭제하는 경우의 성능을 선택한 것이다.
이처럼 인덱스로 배열 요소에 접근할 때 일반적인 배열보다 느릴 수 밖에 없는 구조적인 단점을 보완하기 위해 대부분의 모던 자바스크립트 엔진은 배열을 일반 객체와 구별하여 보다 배열처럼 동작하도록 최적화하여 구현하였다.
아래와 같이 배열과 일반 객체의 성능을 테스트 해보면 배열이 일반 객체보다 약 2배 정도 빠른 것을 알 수 있다.
const arr = [];
console.time('Array Performance Test');
for (let i = 0; i < 10000000; i++) {
arr[i] = i;
}
console.timeEnd('Array Performance Test');
// 약 340ms
const obj = {};
console.time('Object Performance Test');
for (let i = 0; i < 10000000; i++) {
obj[i] = i;
}
console.timeEnd('Object Performance Test');
// 약 600msㅤㅤ
📍 Higher order function : 배열 고차 함수
고차 함수(Higher order function)는 함수를 인자로 전달받거나 함수를 결과로 반환하는 함수를 말한다. 다시 말해, 고차 함수는 인자로 받은 함수를 필요한 시점에 호출하거나 [클로저]를 생성하여 반환한다. 자바스크립트의 함수는 [일급 객체]이므로 값처럼 인자로 전달할 수 있으며 반환할 수도 있다.
// 함수를 인자로 전달받고 함수를 반환하는 고차 함수
function makeCounter(predicate) {
// 자유 변수. num의 상태는 유지되어야 한다.
let num = 0;
// 클로저. num의 상태를 유지한다.
return function () {
// predicate는 자유 변수 num의 상태를 변화시킨다.
num = predicate(num);
return num;
};
}
// 보조 함수
function increase(n) {
return ++n;
}
// 보조 함수
function decrease(n) {
return --n;
}
// makeCounter는 함수를 인수로 전달받는다. 그리고 클로저를 반환한다.
const increaser = makeCounter(increase);
console.log(increaser()); // 1
console.log(increaser()); // 2
// makeCounter는 함수를 인수로 전달받는다. 그리고 클로저를 반환한다.
const decreaser = makeCounter(decrease);
console.log(decreaser()); // -1
console.log(decreaser()); // -2고차 함수는 외부 상태 변경이나 가변(mutable) 데이터를 피하고 불변성(Immutability)을 지향하는 함수형 프로그래밍에 기반을 두고 있다. 함수형 프로그래밍은 순수 함수(Pure function)와 보조 함수의 조합을 통해 로직 내에 존재하는 조건문과 반복문을 제거하여 복잡성을 해결하고 변수의 사용을 억제하여 상태 변경을 피하려는 프로그래밍 패러다임이다. 조건문이나 반복문은 로직의 흐름을 이해하기 어렵게 하여 가독성을 해치고, 변수의 값은 누군가에 의해 언제든지 변경될 수 있어 오류 발생의 근본적 원인이 될 수 있기 때문이다.
함수형 프로그래밍은 결국 순수 함수를 통해 부수 효과(Side effect)를 최대한 억제하여 오류를 피하고 프로그램의 안정성을 높이려는 노력의 한 방법이라고 할 수 있다.
자바스크립트는 고차 함수를 다수 지원하고 있다. 특히 Array 객체는 매우 유용한 고차 함수를 제공한다.
- ✏️ 메소드는
this(원본 배열)를 변경한다. - 🔒 메소드는
this(원본 배열)를 변경하지 않는다.
#1. Array.prototype.sort(compareFn?: (a: T, b: T) => number): this
배열의 요소를 적절하게 정렬한다. 원본 배열을 직접 변경하며 정렬된 배열을 반환한다.
Array.prototype.sort 메서드는 10개 이상의 요소가 있는 배열을 정렬할 때 불안정한 알고리즘인 quicksort 알고리즘을 사용했다. 배열이 올바르게 정렬되도록 ECMAScript 2019는 Array.prototype.sort 메서드에 Timsort 알고리즘을 사용한다.자세한 내용은 2019년과 이후 JavaScript의 동향 - JavaScript(ECMAScript)를 참고하면 된다.
const fruits = ['Banana', 'Orange', 'Apple'];
// ascending(오름차순)
fruits.sort();
console.log(fruits); // [ 'Apple', 'Banana', 'Orange' ]
// descending(내림차순)
fruits.reverse();
console.log(fruits); // [ 'Orange', 'Banana', 'Apple' ]주의할 것은 숫자를 정렬할 때이다.
const points = [40, 100, 1, 5, 2, 25, 10];
points.sort();
console.log(points); // [ 1, 10, 100, 2, 25, 40, 5 ]기본 정렬 순서는 문자열 Unicode 코드 포인트 순서에 따른다. 배열의 요소가 숫자 타입이라 할지라도 배열의 요소를 일시적으로 문자열로 변환한 후, 정렬한다.
예를 들어, 문자열 ‘1’의 Unicode 코드 포인트는 U+0031, 문자열 ‘2’의 Unicode 코드 포인트는 U+0032이다. 따라서 문자열 ‘1’의 Unicode 코드 포인트 순서가 문자열 ‘2’의 Unicode 코드 포인트 순서보다 앞서므로 문자열 ‘1’과 ‘2’를 sort 메소드로 정렬하면 1이 2보다 앞으로 정렬된다. 하지만 10의 Unicode 코드 포인트는 U+0031U+0030이므로 2와 10를 sort 메소드로 정렬하면 10이 2보다 앞으로 정렬된다.
이러한 경우, sort 메소드의 인자로 정렬 순서를 정의하는 비교 함수를 인수로 전달한다. 비교 함수를 생략하면 배열의 각 요소는 일시적으로 문자열로 변환되어 Unicode 코드 포인트 순서에 따라 정렬된다.
const points = [40, 100, 1, 5, 2, 25, 10];
// 숫자 배열 오름차순 정렬
// 비교 함수의 반환값이 0보다 작은 경우, a를 우선하여 정렬한다.
points.sort(function (a, b) {
return a - b;
});
// ES6 화살표 함수
// points.sort((a, b) => a - b);
console.log(points); // [ 1, 2, 5, 10, 25, 40, 100 ]
// 숫자 배열에서 최소값 취득
console.log(points[0]); // 1
// 숫자 배열 내림차순 정렬
// 비교 함수의 반환값이 0보다 큰 경우, b를 우선하여 정렬한다.
points.sort(function (a, b) {
return b - a;
});
// ES6 화살표 함수
// points.sort((a, b) => b - a);
console.log(points); // [ 100, 40, 25, 10, 5, 2, 1 ]
// 숫자 배열에서 최대값 취득
console.log(points[0]); // 100객체를 요소로 갖는 배열을 정렬하는 예제는 아래와 같다.
const todos = [
{ id: 4, content: 'JavaScript' },
{ id: 1, content: 'HTML' },
{ id: 2, content: 'CSS' },
];
// 비교 함수
function compare(key) {
return function (a, b) {
// 프로퍼티 값이 문자열인 경우, - 산술 연산으로 비교하면 NaN이 나오므로 비교 연산을 사용한다.
return a[key] > b[key] ? 1 : a[key] < b[key] ? -1 : 0;
};
}
// id를 기준으로 정렬
todos.sort(compare('id'));
console.log(todos);
// content를 기준으로 정렬
todos.sort(compare('content'));
console.log(todos);#2. Array.prototype.forEach(callback: (value: T, index: number, array: T[]) => void, thisArg?: any): void
- forEach 메소드는 for 문 대신 사용할 수 있다.
- 배열을 순회하며 배열의 각 요소에 대하여 인자로 주어진 콜백함수를 실행한다. 반환값은 undefined이다.
- 콜백 함수의 매개변수를 통해 배열 요소의 값, 요소 인덱스, forEach 메소드를 호출한 배열, 즉 this를 전달 받을 수 있다.
- forEach 메소드는 원본 배열(this)을 변경하지 않는다. 하지만 콜백 함수는 원본 배열(this)을 변경할 수는 있다.
- forEach 메소드는 for 문과는 달리 break 문을 사용할 수 없다. 다시 말해, 배열의 모든 요소를 순회하며 중간에 순회를 중단할 수 없다.
- forEach 메소드는 for 문에 비해 성능이 좋지는 않다. 하지만 for 문보다 가독성이 좋으므로 적극 사용을 권장한다.
- IE 9 이상에서 정상 동작한다.
const numbers = [1, 2, 3];
let pows = [];
// for 문으로 순회
for (let i = 0; i < numbers.length; i++) {
pows.push(numbers[i] ** 2);
}
console.log(pows); // [ 1, 4, 9 ]
pows = [];
// forEach 메소드로 순회
numbers.forEach(function (item) {
pows.push(item ** 2);
});
// ES6 화살표 함수
// numbers.forEach(item => pows.push(item ** 2));
console.log(pows); // [ 1, 4, 9 ]const numbers = [1, 3, 5, 7, 9];
let total = 0;
// forEach 메소드는 인수로 전달한 보조 함수를 호출하면서
// 3개(배열 요소의 값, 요소 인덱스, this)의 인수를 전달한다.
// 배열의 모든 요소를 순회하며 합산한다.
numbers.forEach(function (item, index, self) {
console.log(`numbers[${index}] = ${item}`);
total += item;
});
// Array#reduce를 사용해도 위와 동일한 결과를 얻을 수 있다
// total = numbers.reduce(function (pre, cur) {
// return pre + cur;
// });
console.log(total); // 25
console.log(numbers); // [ 1, 3, 5, 7, 9 ]const numbers = [1, 2, 3, 4];
// forEach 메소드는 원본 배열(this)을 변경하지 않는다. 하지만 콜백 함수는 원본 배열(this)을 변경할 수는 있다.
// 원본 배열을 직접 변경하려면 콜백 함수의 3번째 인자(this)를 사용한다.
numbers.forEach(function (item, index, self) {
self[index] = Math.pow(item, 2);
});
console.log(numbers); // [ 1, 4, 9, 16 ]// forEach 메소드는 for 문과는 달리 break 문을 사용할 수 없다.
[1, 2, 3].forEach(function (item, index, self) {
console.log(`self[${index}] = ${item}`);
if (item > 1) break; // SyntaxError: Illegal break statement
});
forEach 메소드에 두번째 인자로 this를 전달할 수 있다.
function Square() {
this.array = [];
}
Square.prototype.multiply = function (arr) {
arr.forEach(function (item) {
// this를 인수로 전달하지 않으면 this === window
this.array.push(item * item);
}, this);
};
const square = new Square();
square.multiply([1, 2, 3]);
console.log(square.array); // [ 1, 4, 9 ]ES6의 [Arrow function]를 사용하면 this를 생략하여도 동일한 동작을 한다.
Square.prototype.multiply = function (arr) {
arr.forEach((item) => this.array.push(item * item));
};forEach 메소드의 이해를 돕기 위해 forEach의 동작을 흉내낸 myForEach 메소드를 작성해 본다.
Array.prototype.myForEach = function (f) {
// 첫번재 매개변수에 함수가 전달되었는지 확인
// console.log((function(){}).toString()); // function(){}
// console.log(Object.prototype.toString.call(function(){})); // [object Function]
if (!f || {}.toString.call(f) !== '[object Function]') {
throw new TypeError(f + ' is not a function.');
}
for (let i = 0; i < this.length; i++) {
// 배열 요소의 값, 요소 인덱스, forEach 메소드를 호출한 배열, 즉 this를 매개변수에 전달하고 콜백 함수 호출
f(this[i], i, this);
}
};
let total = 0;
[0, 1, 2, 3].myForEach(function (item, index, array) {
console.log(`[${index}]: ${item} of [${array}]`);
total += item;
});
console.log('Total: ', total);#3. Array.prototype.map(callbackfn: (value: T, index: number, array: T[]) => U, thisArg?: any): U[]
- 배열을 순회하며 각 요소에 대하여 인자로 주어진 콜백 함수의 반환값(결과값)으로 새로운 배열을 생성하여 반환한다. 이때 원본 배열은 변경되지 않는다.
- forEach 메소드는 배열을 순회하며 요소 값을 참조하여 무언가를 하기 위한 함수이며 map 메소드는 배열을 순회하며 요소 값을 다른 값으로 맵핑하기 위한 함수이다.
- 콜백 함수의 매개변수를 통해 배열 요소의 값, 요소 인덱스, map 메소드를 호출한 배열, 즉 this를 전달 받을 수 있다.
- IE 9 이상에서 정상 동작한다.
const numbers = [1, 4, 9];
// 배열을 순회하며 각 요소에 대하여 인자로 주어진 콜백함수를 실행
const roots = numbers.map(function (item) {
// 반환값이 새로운 배열의 요소가 된다. 반환값이 없으면 새로운 배열은 비어 있다.
return Math.sqrt(item);
});
// 위 코드의 축약표현은 아래와 같다.
// const roots = numbers.map(Math.sqrt);
// map 메소드는 새로운 배열을 반환한다
console.log(roots); // [ 1, 2, 3 ]
// map 메소드는 원본 배열은 변경하지 않는다
console.log(numbers); // [ 1, 4, 9 ]map 메소드에 두번째 인자로 this를 전달할 수 있다.
function Prefixer(prefix) {
this.prefix = prefix;
}
Prefixer.prototype.prefixArray = function (arr) {
// 콜백함수의 인자로 배열 요소의 값, 요소 인덱스, map 메소드를 호출한 배열, 즉 this를 전달할 수 있다.
return arr.map(function (x) {
// x는 배열 요소의 값이다.
return this.prefix + x; // 2번째 인자 this를 전달하지 않으면 this === window
}, this);
};
const pre = new Prefixer('-webkit-');
const preArr = pre.prefixArray(['linear-gradient', 'border-radius']);
console.log(preArr);
// [ '-webkit-linear-gradient', '-webkit-border-radius' ]ES6의 [Arrow function]를 사용하면 this를 생략하여도 동일한 동작을 한다.
map 메소드의 이해를 돕기 위해 map의 동작을 흉내낸 myMap 메소드를 작성해 본다.
Array.prototype.myMap = function (iteratee) {
// 첫번재 매개변수에 함수가 전달되었는지 확인
if (!iteratee || {}.toString.call(iteratee) !== '[object Function]') {
throw new TypeError(iteratee + ' is not a function.');
}
const result = [];
for (let i = 0, len = this.length; i < len; i++) {
/**
* 배열 요소의 값, 요소 인덱스, 메소드를 호출한 배열, 즉 this를 매개변수를 통해 iteratee에 전달하고
* iteratee를 호출하여 그 결과를 반환용 배열에 푸시하여 반환한다.
*/
result.push(iteratee(this[i], i, this));
}
return result;
};
const result = [1, 4, 9].myMap(function (item, index, self) {
console.log(`[${index}]: ${item} of [${self}]`);
return Math.sqrt(item);
});
console.log(result); // [ 1, 2, 3 ]#4. Array.prototype.filter(callback: (value: T, index: number, array: Array) => any, thisArg?: any): T[]
- filter 메소드를 사용하면 if 문을 대체할 수 있다.
- 배열을 순회하며 각 요소에 대하여 인자로 주어진 콜백함수의 실행 결과가 true인 배열 요소의 값만을 추출한 새로운 배열을 반환한다.
- 배열에서 특정 케이스만 필터링 조건으로 추출하여 새로운 배열을 만들고 싶을 때 사용한다. 이때 원본 배열은 변경되지 않는다.
- 콜백 함수의 매개변수를 통해 배열 요소의 값, 요소 인덱스, filter 메소드를 호출한 배열, 즉 this를 전달 받을 수 있다.
- IE 9 이상에서 정상 동작한다.
const result = [1, 2, 3, 4, 5].filter(function (item, index, self) {
console.log(`[${index}] = ${item}`);
return item % 2; // 홀수만을 필터링한다 (1은 true로 평가된다)
});
console.log(result); // [ 1, 3, 5 ]filter도 map, forEach와 같이 두번째 인자로 this를 전달할 수 있다.
filter 메소드의 이해를 돕기 위해 filter의 동작을 흉내낸 myFilter 메소드를 작성해 본다.
Array.prototype.myFilter = function (predicate) {
// 첫번재 매개변수에 함수가 전달되었는지 확인
if (!predicate || {}.toString.call(predicate) !== '[object Function]') {
throw new TypeError(predicate + ' is not a function.');
}
const result = [];
for (let i = 0, len = this.length; i < len; i++) {
/**
* 배열 요소의 값, 요소 인덱스, 메소드를 호출한 배열, 즉 this를 매개변수를 통해 predicate에 전달하고
* predicate를 호출하여 그 결과가 참인 요소만을 반환용 배열에 푸시하여 반환한다.
*/
if (predicate(this[i], i, this)) result.push(this[i]);
}
return result;
};
const result = [1, 2, 3, 4, 5].myFilter(function (item, index, self) {
console.log(`[${index}]: ${item} of [${self}]`);
return item % 2; // 홀수만을 필터링한다 (1은 true로 평가된다)
});
console.log(result); // [ 1, 3, 5 ]#5. Array.prototype.reduce(callback: (state: U, element: T, index: number, array: T[]) => U, firstState?: U): U
배열을 순회하며 각 요소에 대하여 이전의 콜백함수 실행 반환값을 전달하여 콜백함수를 실행하고 그 결과를 반환한다. IE 9 이상에서 정상 동작한다.
const arr = [1, 2, 3, 4, 5];
/*
previousValue: 이전 콜백의 반환값
currentValue : 배열 요소의 값
currentIndex : 인덱스
array : 메소드를 호출한 배열, 즉 this
*/
// 합산
const sum = arr.reduce(function (previousValue, currentValue, currentIndex, self) {
console.log(previousValue + '+' + currentValue + '=' + (previousValue + currentValue));
return previousValue + currentValue; // 결과는 다음 콜백의 첫번째 인자로 전달된다
});
console.log(sum); // 15: 1~5까지의 합
/*
1: 1+2=3
2: 3+3=6
3: 6+4=10
4: 10+5=15
15
*/
// 최대값 취득
const max = arr.reduce(function (pre, cur) {
return pre > cur ? pre : cur;
});
console.log(max); // 5: 최대값
Array.prototype.reduce의 두번째 인수로 초기값을 전달할 수 있다. 이 값은 콜백 함수에 최초로 전달된다.
const sum = [1, 2, 3, 4, 5].reduce(function (pre, cur) {
return pre + cur;
}, 5);
console.log(sum); // 20
// 5 + 1 => 6 + 2 => 8 + 3 => 11 + 4 => 15 + 5객체의 프로퍼티 값을 합산하는 경우를 생각해 본다.
const products = [
{ id: 1, price: 100 },
{ id: 2, price: 200 },
{ id: 3, price: 300 },
];
// 프로퍼티 값을 합산
const priceSum = products.reduce(function (pre, cur) {
console.log(pre.price, cur.price);
// 숫자값이 두번째 콜백 함수 호출의 인수로 전달된다. 이때 pre.price는 undefined이다.
return pre.price + cur.price;
});
console.log(priceSum); // NaN이처럼 객체의 프로퍼티 값을 합산하는 경우에는 반드시 초기값을 전달해야 한다.
const products = [
{ id: 1, price: 100 },
{ id: 2, price: 200 },
{ id: 3, price: 300 },
];
// 프로퍼티 값을 합산
const priceSum = products.reduce(function (pre, cur) {
console.log(pre, cur.price);
return pre + cur.price;
}, 0);
console.log(priceSum); // 600reduce로 빈 배열을 호출하면 에러가 발생한다.
const sum = [].reduce(function (pre, cur) {
console.log(pre, cur);
return pre + cur;
});
// TypeError: Reduce of empty array with no initial value초기값을 전달하면 에러를 회피할 수 있다. 따라서 reduce를 호출할 때는 언제나 초기값을 전달하는 것이 보다 안전하다.
const sum = [].reduce(function (pre, cur) {
console.log(pre, cur);
return pre + cur;
}, 0);
console.log(sum); // 0#6. Array.prototype.some(callback: (value: T, index: number, array: Array) => boolean, thisArg?: any): boolean
배열 내 일부 요소가 콜백 함수의 테스트를 통과하는지 확인하여 그 결과를 boolean으로 반환한다. IE 9 이상에서 정상 동작한다.
콜백함수의 매개변수를 통해 배열 요소의 값, 요소 인덱스, 메소드를 호출한 배열, 즉 this를 전달 받을 수 있다.
// 배열 내 요소 중 10보다 큰 값이 1개 이상 존재하는지 확인
let res = [2, 5, 8, 1, 4].some(function (item) {
return item > 10;
});
console.log(res); // false
res = [12, 5, 8, 1, 4].some(function (item) {
return item > 10;
});
console.log(res); // true
// 배열 내 요소 중 특정 값이 1개 이상 존재하는지 확인
res = ['apple', 'banana', 'mango'].some(function (item) {
return item === 'banana';
});
console.log(res); // truesome()도 map(), forEach()와 같이 두번째 인자로 this를 전달할 수 있다.
#7. Array.prototype.every(callback: (value: T, index: number, array: Array) => boolean, thisArg?: any): boolean
배열 내 모든 요소가 콜백함수의 테스트를 통과하는지 확인하여 그 결과를 boolean으로 반환한다. IE 9 이상에서 정상 동작한다.
콜백함수의 매개변수를 통해 배열 요소의 값, 요소 인덱스, 메소드를 호출한 배열, 즉 this를 전달 받을 수 있다.
// 배열 내 모든 요소가 10보다 큰 값인지 확인
let res = [21, 15, 89, 1, 44].every(function (item) {
return item > 10;
});
console.log(res); // false
res = [21, 15, 89, 100, 44].every(function (item) {
return item > 10;
});
console.log(res); // trueevery()도 map(), forEach()와 같이 두번째 인자로 this를 전달할 수 있다.
#8. Array.prototype.find(predicate: (value: T, index: number, obj: T[]) => boolean, thisArg?: any): T | undefined
ES6에서 새롭게 도입된 메소드로 Internet Explorer에서는 지원하지 않는다.
배열을 순회하며 각 요소에 대하여 인자로 주어진 콜백함수를 실행하여 그 결과가 참인 첫번째 요소를 반환한다. 콜백함수의 실행 결과가 참인 요소가 존재하지 않는다면 undefined를 반환한다.
콜백함수의 매개변수를 통해 배열 요소의 값, 요소 인덱스, 메소드를 호출한 배열, 즉 this를 전달 받을 수 있다.
참고로 filter는 콜백함수의 실행 결과가 true인 배열 요소의 값만을 추출한 새로운 배열을 반환한다. 따라서 filter의 반환값은 언제나 배열이다. 하지만 find는 콜백함수를 실행하여 그 결과가 참인 첫번째 요소를 반환하므로 find의 결과값은 해당 요소값이다.
const users = [
{ id: 1, name: 'Lee' },
{ id: 2, name: 'Kim' },
{ id: 2, name: 'Choi' },
{ id: 3, name: 'Park' },
];
// 콜백함수를 실행하여 그 결과가 참인 첫번째 요소를 반환한다.
let result = users.find(function (item) {
return item.id === 2;
});
// ES6
// const result = users.find(item => item.id === 2;);
// Array#find는 배열이 아니라 요소를 반환한다.
console.log(result); // { id: 2, name: 'Kim' }
// Array#filter는 콜백함수의 실행 결과가 true인 배열 요소의 값만을 추출한 새로운 배열을 반환한다.
result = users.filter(function (item) {
return item.id === 2;
});
console.log(result); // [ { id: 2, name: 'Kim' },{ id: 2, name: 'Choi' } ]find 메소드의 이해를 돕기 위해 find의 동작을 흉내낸 myFind 메소드를 작성해 본다.
const users = [
{ id: 1, name: 'Lee' },
{ id: 2, name: 'Kim' },
{ id: 2, name: 'Choi' },
{ id: 3, name: 'Park' },
];
Array.prototype.myFind = function (predicate) {
// 첫번재 매개변수에 함수가 전달되었는지 확인
if (!predicate || {}.toString.call(predicate) !== '[object Function]') {
throw new TypeError(predicate + ' is not a function.');
}
/**
* 배열 요소의 값, 요소 인덱스, 메소드를 호출한 배열, 즉 this를 매개변수를 통해 predicate에 전달하고
* predicate를 호출하여 그 결과가 참인 요소를 반환하고 처리를 종료한다.
*/
for (let i = 0, len = this.length; i < len; i++) {
if (predicate(this[i], i, this)) return this[i];
}
};
const result = users.myFind(function (item, index, array) {
console.log(`[${index}]: ${JSON.stringify(item)} of [${JSON.stringify(array)}]`);
return item.id === 2; // 요소의 id 프로퍼티의 값이 2인 요소를 검색
});
console.log(result); // { id: 2, name: 'Kim' }#9. Array.prototype.findIndex(predicate: (value: T, index: number, obj: T[]) => boolean, thisArg?: any): number
ES6에서 새롭게 도입된 메소드로 Internet Explorer에서는 지원하지 않는다.
배열을 순회하며 각 요소에 대하여 인자로 주어진 콜백함수를 실행하여 그 결과가 참인 첫번째 요소의 인덱스를 반환한다. 콜백함수의 실행 결과가 참인 요소가 존재하지 않는다면 -1을 반환한다.
콜백함수의 매개변수를 통해 배열 요소의 값, 요소 인덱스, 메소드를 호출한 배열, 즉 this를 전달 받을 수 있다.
const users = [
{ id: 1, name: 'Lee' },
{ id: 2, name: 'Kim' },
{ id: 2, name: 'Choi' },
{ id: 3, name: 'Park' },
];
// 콜백함수를 실행하여 그 결과가 참인 첫번째 요소의 인덱스를 반환한다.
function predicate(key, value) {
return function (item) {
return item[key] === value;
};
}
// id가 2인 요소의 인덱스
let index = users.findIndex(predicate('id', 2));
console.log(index); // 1
// name이 'Park'인 요소의 인덱스
index = users.findIndex(predicate('name', 'Park'));
console.log(index); // 3ㅤㅤ
📍 DOM : 문서 객체 모델(Document Object Model)
1. DOM (Document Object Model)
텍스트 파일로 만들어져 있는 웹 문서를 브라우저에 렌더링하려면 웹 문서를 브라우저가 이해할 수 있는 구조로 메모리에 올려야 한다. 브라우저의 렌더링 엔진은 웹 문서를 로드한 후, 파싱하여 웹 문서를 브라우저가 이해할 수 있는 구조로 구성하여 메모리에 적재하는데 이를 DOM이라 한다. 즉 모든 요소와 요소의 어트리뷰트, 텍스트를 각각의 객체로 만들고 이들 객체를 부자 관계를 표현할 수 있는 트리 구조로 구성한 것이 DOM이다. 이 DOM은 자바스크립트를 통해 동적으로 변경할 수 있으며 변경된 DOM은 렌더링에 반영된다.
브라우저는 웹 문서(HTML, XML, SVG)를 로드한 후, 파싱하여 DOM(문서 객체 모델: Document Object Model)을 생성한다.
이러한 웹 문서의 동적 변경을 위해 DOM은 프로그래밍 언어가 자신에 접근하고 수정할 수 있는 방법을 제공하는데 일반적으로 프로퍼티와 메소드를 갖는 자바스크립트 객체로 제공된다. 이를 DOM API(Application Programming Interface)라고 부른다. 달리 말하면 정적인 웹페이지에 접근하여 동적으로 웹페이지를 변경하기 위한 유일한 방법은 메모리 상에 존재하는 DOM을 변경하는 것이고, 이때 필요한 것이 DOM에 접근하고 변경하는 프로퍼티와 메소드의 집합인 DOM API이다.
DOM은 HTML, ECMAScript에서 정의한 표준이 아닌 별개의 W3C의 공식 표준이며 플랫폼/프로그래밍 언어 중립적이다. DOM은 다음 두 가지 기능을 담당한다.
HTML 문서에 대한 모델 구성브라우저는 HTML 문서를 로드한 후 해당 문서에 대한 모델을 메모리에 생성한다. 이때 모델은 객체의 트리로 구성되는데 이것을 DOM tree라 한다.
HTML 문서 내의 각 요소에 접근 / 수정DOM은 모델 내의 각 객체에 접근하고 수정할 수 있는 프로퍼티와 메소드를 제공한다. DOM이 수정되면 브라우저를 통해 사용자가 보게 될 내용 또한 변경된다.
#2. DOM tree
DOM tree는 브라우저가 HTML 문서를 로드한 후 파싱하여 생성하는 모델을 의미한다. 객체의 트리로 구조화되어 있기 때문에 DOM tree라 부른다.
<!DOCTYPE html>
<html>
<head>
<style>
.red {
color: #ff0000;
}
.blue {
color: #0000ff;
}
</style>
</head>
<body>
<div>
<h1>Cities</h1>
<ul>
<li id="one" class="red">Seoul</li>
<li id="two" class="red">London</li>
<li id="three" class="red">Newyork</li>
<li id="four">Tokyo</li>
</ul>
</div>
</body>
</html>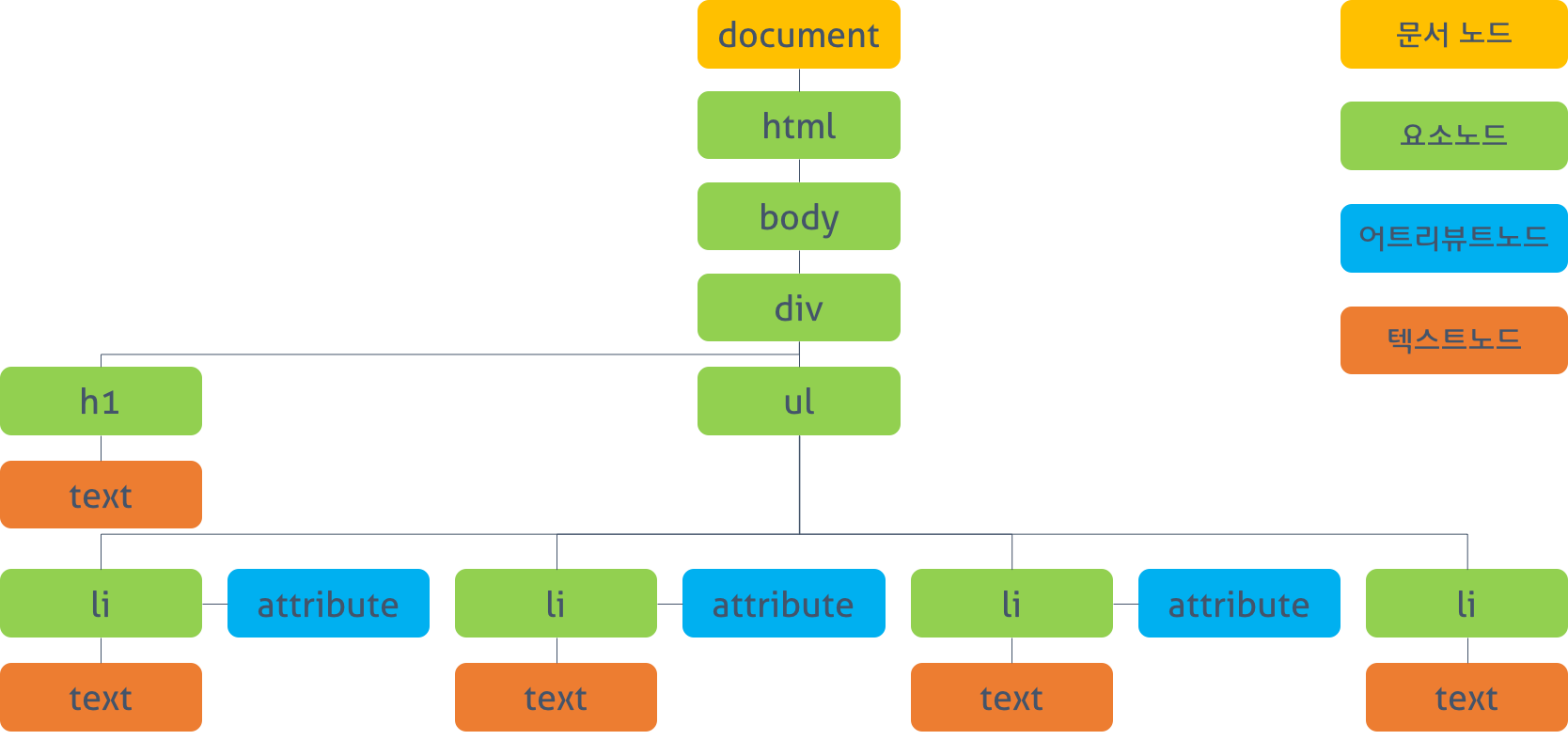
DOM에서 모든 요소, 어트리뷰트, 텍스트는 하나의 객체이며 Document 객체의 자식이다. 요소의 중첩관계는 객체의 트리로 구조화하여 부자관계를 표현한다. DOM tree의 진입점(Entry point)는 document 객체이며 최종점은 요소의 텍스트를 나타내는 객체이다.
DOM tree는 네 종류의 노드로 구성된다.
문서 노드(Document Node)트리의 최상위에 존재하며 각각 요소, 어트리뷰트, 텍스트 노드에 접근하려면 문서 노드를 통해야 한다. 즉, DOM tree에 접근하기 위한 시작점(entry point)이다.
요소 노드(Element Node)요소 노드는 HTML 요소를 표현한다. HTML 요소는 중첩에 의해 부자 관계를 가지며 이 부자 관계를 통해 정보를 구조화한다. 따라서 요소 노드는 문서의 구조를 서술한다고 말 할 수 있다. 어트리뷰트, 텍스트 노드에 접근하려면 먼저 요소 노드를 찾아 접근해야 한다. 모든 요소 노드는 요소별 특성을 표현하기 위해 HTMLElement 객체를 상속한 객체로 구성된다. (그림: DOM tree의 객체 구성 참고)
어트리뷰트 노드(Attribute Node)어트리뷰트 노드는 HTML 요소의 어트리뷰트를 표현한다. 어트리뷰트 노드는 해당 어트리뷰트가 지정된 요소의 자식이 아니라 해당 요소의 일부로 표현된다. 따라서 해당 요소 노드를 찾아 접근하면 어트리뷰트를 참조, 수정할 수 있다.
텍스트 노드(Text Node)텍스트 노드는 HTML 요소의 텍스트를 표현한다. 텍스트 노드는 요소 노드의 자식이며 자신의 자식 노드를 가질 수 없다. 즉, 텍스트 노드는 DOM tree의 최종단이다.
DOM 트리를 크롬 브라우저에서 확인하려면 개발자도구(Developer Tools)의 Elements 를 선택한 후 오른쪽의 properties을 선택한다.
크롬 개발자도구(Developer Tools)에서 확인한 DOM 트리
DOM을 통해 웹페이지를 조작(manipulate)하기 위해서는 다음과 같은 수순이 필요하다.
- 조작하고자하는 요소를 선택 또는 탐색한다.
- 선택된 요소의 콘텐츠 또는 어트리뷰트를 조작한다.
자바스크립트는 이것에 필요한 수단(API)을 제공한다.
#3. DOM Query / Traversing (요소에의 접근)
#3.1 하나의 요소 노드 선택(DOM Query)
document.getElementById(id)
• id 어트리뷰트 값으로 요소 노드를 한 개 선택한다. 복수개가 선택된 경우, 첫번째 요소만 반환한다.
• Return: HTMLElement를 상속받은 객체
• 모든 브라우저에서 동작
// id로 하나의 요소를 선택한다.
const elem = document.getElementById('one');
// 클래스 어트리뷰트의 값을 변경한다.
elem.className = 'blue';
// 그림: DOM tree의 객체 구성 참고
console.log(elem); // <li id="one" class="blue">Seoul</li>
console.log(elem.__proto__); // HTMLLIElement
console.log(elem.__proto__.__proto__); // HTMLElement
console.log(elem.__proto__.__proto__.__proto__); // Element
console.log(elem.__proto__.__proto__.__proto__.__proto__); // Nodedocument.querySelector(cssSelector)
• CSS 셀렉터를 사용하여 요소 노드를 한 개 선택한다. 복수개가 선택된 경우, 첫번째 요소만 반환한다.
• Return: HTMLElement를 상속받은 객체
• IE8 이상의 브라우저에서 동작
// CSS 셀렉터를 이용해 요소를 선택한다
const elem = document.querySelector('li.red');
// 클래스 어트리뷰트의 값을 변경한다.
elem.className = 'blue';#3.2 여러 개의 요소 노드 선택(DOM Query)
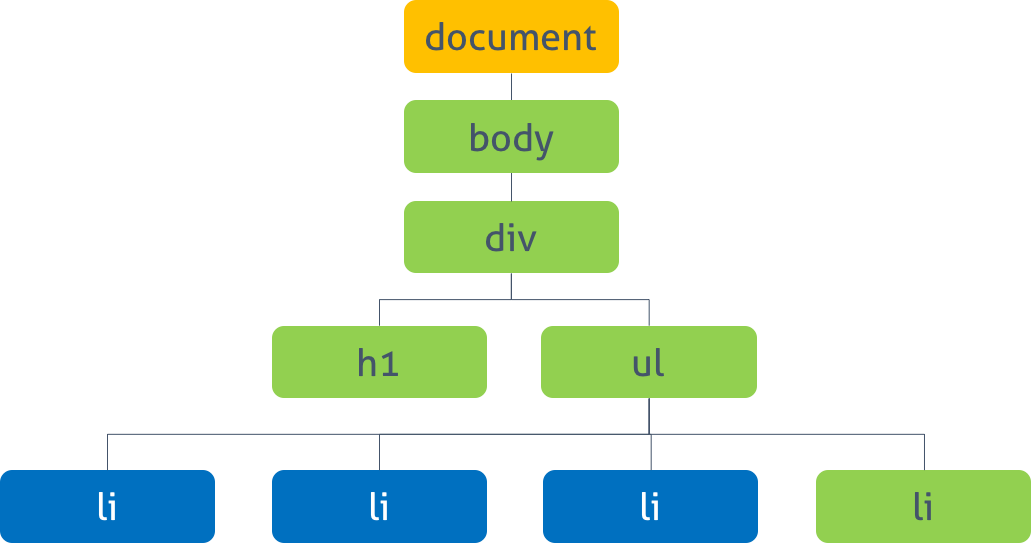
document.getElementsByClassName(class)
• class 어트리뷰트 값으로 요소 노드를 모두 선택한다. 공백으로 구분하여 여러 개의 class를 지정할 수 있다.
• Return: HTMLCollection (live)
• IE9 이상의 브라우저에서 동작
// HTMLCollection을 반환한다. HTMLCollection은 live하다.
const elems = document.getElementsByClassName('red');
for (let i = 0; i < elems.length; i++) {
// 클래스 어트리뷰트의 값을 변경한다.
elems[i].className = 'blue';
}위 예제를 실행해 보면 예상대로 동작하지 않는다. (두번째 요소만 클래스 변경이 되지 않는다.)
getElementsByClassName 메소드의 반환값은 HTMLCollection이다. 이것은 반환값이 복수인 경우, HTMLElement의 리스트를 담아 반환하기 위한 객체로 배열과 비슷한 사용법을 가지고 있지만 배열은 아닌 유사배열(array-like object)이다. 또한 HTMLCollection은 실시간으로 Node의 상태 변경을 반영한다. (live HTMLCollection)
위 예제가 예상대로 동작하지 않은 이유를 알아본다.
elems.length는 3이므로 3번의 loop가 실행된다.
- i가 0일때, elems의 첫 요소(li#one.red)의 class 어트리뷰트의 값이 className 프로퍼티에 의해 red에서 blue로 변경된다. 이때 elems는 실시간으로 Node의 상태 변경을 반영하는 HTMLCollection 객체이다. elems의 첫 요소는 li#one.red에서 li#one.blue로 변경되었으므로 getElementsByClassName 메소드의 인자로 지정한 선택 조건(‘red’)과 더이상 부합하지 않게 되어 반환값에서 실시간으로 제거된다.
- i가 1일때, elems에서 첫째 요소는 제거되었으므로 elems[1]은 3번째 요소(li#three.red)가 된다. li#three.red의 class 어트리뷰트 값이 blue로 변경되고 마찬가지로 HTMLCollection에서 제외된다.
- i가 2일때, HTMLCollection의 1,3번째 요소가 실시간으로 제거되었으므로 2번째 요소(li#two.red)만 남았다. 이때 elems.length는 1이므로 for 문의 조건식 i < elems.length가 false로 평가되어 반복을 종료한다. 따라서 elems에 남아 있는 2번째 li 요소(li#two.red)의 class 값은 변경되지 않는다.
이처럼 HTMLCollection는 실시간으로 Node의 상태 변경을 반영하기 때문에 loop가 필요한 경우 주의가 필요하다. 아래와 같은 방법으로 회피할 수 있다.
- 반복문을 역방향으로 돌린다.
const elems = document.getElementsByClassName('red');
for (let i = elems.length - 1; i >= 0; i--) {
elems[i].className = 'blue';
}- while 반복문을 사용한다. 이때 elems에 요소가 남아 있지 않을 때까지 무한반복하기 위해 index는 0으로 고정시킨다.
const elems = document.getElementsByClassName('red');
let i = 0;
while (elems.length > i) {
// elems에 요소가 남아 있지 않을 때까지 무한반복
elems[i].className = 'blue';
// i++;
}- HTMLCollection을 배열로 변경한다. 이 방법을 권장한다.
const elems = document.getElementsByClassName('red');
// 유사 배열 객체인 HTMLCollection을 배열로 변환한다.
// 배열로 변환된 HTMLCollection은 더 이상 live하지 않다.
console.log([...elems]); // [li#one.red, li#two.red, li#three.red]
[...elems].forEach((elem) => (elem.className = 'blue'));- querySelectorAll 메소드를 사용하여 HTMLCollection(live)이 아닌 NodeList(non-live)를 반환하게 한다.
// querySelectorAll는 Nodelist(non-live)를 반환한다. IE8+
const elems = document.querySelectorAll('.red');
[...elems].forEach((elem) => (elem.className = 'blue'));document.getElementsByTagName(tagName)
• 태그명으로 요소 노드를 모두 선택한다.
• Return: HTMLCollection (live)
• 모든 브라우저에서 동작
// HTMLCollection을 반환한다.
const elems = document.getElementsByTagName('li');
[...elems].forEach((elem) => (elem.className = 'blue'));document.querySelectorAll(selector)
• 지정된 CSS 선택자를 사용하여 요소 노드를 모두 선택한다.
• Return: NodeList (non-live)
• IE8 이상의 브라우저에서 동작
// Nodelist를 반환한다.
const elems = document.querySelectorAll('li.red');
[...elems].forEach((elem) => (elem.className = 'blue'));#3.3 DOM Traversing (탐색)
parentNode
• 부모 노드를 탐색한다.
• Return: HTMLElement를 상속받은 객체
• 모든 브라우저에서 동작
const elem = document.querySelector('#two');
elem.parentNode.className = 'blue';firstChild, lastChild
• 자식 노드를 탐색한다.
• Return: HTMLElement를 상속받은 객체
• IE9 이상의 브라우저에서 동작
const elem = document.querySelector('ul');
// first Child
elem.firstChild.className = 'blue';
// last Child
elem.lastChild.className = 'blue';위 예제를 실행해 보면 예상대로 동작하지 않는다. 그 이유는 IE를 제외한 대부분의 브라우저들은 요소 사이의 공백 또는 줄바꿈 문자를 텍스트 노드로 취급하기 때문이다. 이것을 회피하기 위해서는 아래와 같이 HTML의 공백을 제거하거나 jQuery: .prev()와 jQuery: .next()를 사용한다.
<ul>
<li id='one' class='red'>
Seoul
</li>
<li id='two' class='red'>
London
</li>
<li id='three' class='red'>
Newyork
</li>
<li id='four'>Tokyo</li>
</ul>또는 firstElementChild, lastElementChild를 사용할 수도 있다. 이 두가지 프로퍼티는 모든 IE9 이상에서 정상 동작한다.
const elem = document.querySelector('ul');
// first Child
elem.firstElementChild.className = 'blue';
// last Child
elem.lastElementChild.className = 'blue';hasChildNodes()
• 자식 노드가 있는지 확인하고 Boolean 값을 반환한다.
• Return: Boolean 값
• 모든 브라우저에서 동작
childNodes
• 자식 노드의 컬렉션을 반환한다. 텍스트 요소를 포함한 모든 자식 요소를 반환한다.
• Return: NodeList (non-live)
• 모든 브라우저에서 동작
children
• 자식 노드의 컬렉션을 반환한다. 자식 요소 중에서 Element type 요소만을 반환한다.
• Return: HTMLCollection (live)
• IE9 이상의 브라우저에서 동작
const elem = document.querySelector('ul');
if (elem.hasChildNodes()) {
console.log(elem.childNodes);
// 텍스트 요소를 포함한 모든 자식 요소를 반환한다.
// NodeList(9) [text, li#one.red, text, li#two.red, text, li#three.red, text, li#four, text]
console.log(elem.children);
// 자식 요소 중에서 Element type 요소만을 반환한다.
// HTMLCollection(4) [li#one.red, li#two.red, li#three.red, li#four, one: li#one.red, two: li#two.red, three: li#three.red, four: li#four]
[...elem.children].forEach((el) => console.log(el.nodeType)); // 1 (=> Element node)
}previousSibling, nextSibling
• 형제 노드를 탐색한다. text node를 포함한 모든 형제 노드를 탐색한다.
• Return: HTMLElement를 상속받은 객체
• 모든 브라우저에서 동작
previousElementSibling, nextElementSibling
• 형제 노드를 탐색한다. 형제 노드 중에서 Element type 요소만을 탐색한다.
• Return: HTMLElement를 상속받은 객체
• IE9 이상의 브라우저에서 동작
const elem = document.querySelector('ul');
elem.firstElementChild.nextElementSibling.className = 'blue';
elem.firstElementChild.nextElementSibling.previousElementSibling.className = 'blue';#4. DOM Manipulation (조작)
#4.1 텍스트 노드에의 접근/수정

요소의 텍스트는 텍스트 노드에 저장되어 있다. 텍스트 노드에 접근하려면 아래와 같은 수순이 필요하다.
- 해당 텍스트 노드의 부모 노드를 선택한다. 텍스트 노드는 요소 노드의 자식이다.
- firstChild 프로퍼티를 사용하여 텍스트 노드를 탐색한다.
- 텍스트 노드의 유일한 프로퍼티(
nodeValue)를 이용하여 텍스트를 취득한다. nodeValue를 이용하여 텍스트를 수정한다.
nodeValue
• 노드의 값을 반환한다.
• Return: 텍스트 노드의 경우는 문자열, 요소 노드의 경우 null 반환
• IE6 이상의 브라우저에서 동작한다.
nodeName, nodeType을 통해 노드의 정보를 취득할 수 있다.
// 해당 텍스트 노드의 부모 요소 노드를 선택한다.
const one = document.getElementById('one');
console.dir(one); // HTMLLIElement: li#one.red
// nodeName, nodeType을 통해 노드의 정보를 취득할 수 있다.
console.log(one.nodeName); // LI
console.log(one.nodeType); // 1: Element node
// firstChild 프로퍼티를 사용하여 텍스트 노드를 탐색한다.
const textNode = one.firstChild;
// nodeName, nodeType을 통해 노드의 정보를 취득할 수 있다.
console.log(textNode.nodeName); // #text
console.log(textNode.nodeType); // 3: Text node
// nodeValue 프로퍼티를 사용하여 노드의 값을 취득한다.
console.log(textNode.nodeValue); // Seoul
// nodeValue 프로퍼티를 이용하여 텍스트를 수정한다.
textNode.nodeValue = 'Pusan';#4.2 어트리뷰트 노드에의 접근/수정
어트리뷰트 노드을 조작할 때 다음 프로퍼티 또는 메소드를 사용할 수 있다.
className
• class 어트리뷰트의 값을 취득 또는 변경한다. className 프로퍼티에 값을 할당하는 경우, class 어트리뷰트가 존재하지 않으면 class 어트리뷰트를 생성하고 지정된 값을 설정한다. class 어트리뷰트의 값이 여러 개일 경우, 공백으로 구분된 문자열이 반환되므로 String 메소드split(' ')를 사용하여 배열로 변경하여 사용한다.
• 모든 브라우저에서 동작한다.
classList
• add, remove, item, toggle, contains, replace 메소드를 제공한다.
• IE10 이상의 브라우저에서 동작한다.
const elems = document.querySelectorAll('li');
// className
[...elems].forEach((elem) => {
// class 어트리뷰트 값을 취득하여 확인
if (elem.className === 'red') {
// class 어트리뷰트 값을 변경한다.
elem.className = 'blue';
}
});
// classList
[...elems].forEach((elem) => {
// class 어트리뷰트 값 확인
if (elem.classList.contains('blue')) {
// class 어트리뷰트 값 변경한다.
elem.classList.replace('blue', 'red');
}
});id
• id 어트리뷰트의 값을 취득 또는 변경한다. id 프로퍼티에 값을 할당하는 경우, id 어트리뷰트가 존재하지 않으면 id 어트리뷰트를 생성하고 지정된 값을 설정한다.
• 모든 브라우저에서 동작한다.
// h1 태그 요소 중 첫번째 요소를 취득
const heading = document.querySelector('h1');
console.dir(heading); // HTMLHeadingElement: h1
console.log(heading.firstChild.nodeValue); // Cities
// id 어트리뷰트의 값을 변경.
// id 어트리뷰트가 존재하지 않으면 id 어트리뷰트를 생성하고 지정된 값을 설정
heading.id = 'heading';
console.log(heading.id); // headinghasAttribute(attribute)
• 지정한 어트리뷰트를 가지고 있는지 검사한다.
• Return : Boolean
• IE8 이상의 브라우저에서 동작한다.
getAttribute(attribute)
• 어트리뷰트의 값을 취득한다.
• Return : 문자열
• 모든 브라우저에서 동작한다.
setAttribute(attribute, value)
• 어트리뷰트와 어트리뷰트 값을 설정한다.
• Return : undefined
• 모든 브라우저에서 동작한다.
removeAttribute(attribute)
• 지정한 어트리뷰트를 제거한다.
• Return : undefined
• 모든 브라우저에서 동작한다.
<!DOCTYPE html>
<html>
<body>
<input type="text">
<script>
const input = document.querySelector('input[type=text]');
console.log(input);
// value 어트리뷰트가 존재하지 않으면
if (!input.hasAttribute('value')) {
// value 어트리뷰트를 추가하고 값으로 'hello!'를 설정
input.setAttribute('value', 'hello!');
}
// value 어트리뷰트 값을 취득
console.log(input.getAttribute('value')); // hello!
// value 어트리뷰트를 제거
input.removeAttribute('value');
// value 어트리뷰트의 존재를 확인
console.log(input.hasAttribute('value')); // false
</script>
</body>
</html>
<!DOCTYPE html>
<html>
<body>
<input class="password" type="password" value="123">
<button class="show">show</button>
<script>
const $password = document.querySelector('.password');
const $show = document.querySelector('.show');
function makeClickHandler() {
let isShow = false;
return function () {
$password.setAttribute('type', isShow ? 'password' : 'text');
isShow = !isShow;
$show.innerHTML = isShow ? 'hide' : 'show';
};
}
$show.onclick = makeClickHandler();
</script>
</body>
</html>
#4.3 HTML 콘텐츠 조작(Manipulation)
HTML 콘텐츠를 조작(Manipulation)하기 위해 아래의 프로퍼티 또는 메소드를 사용할 수 있다. 마크업이 포함된 콘텐츠를 추가하는 행위는 크로스 스크립팅 공격(XSS: Cross-Site Scripting Attacks)에 취약하므로 주의가 필요하다.
textContent
• 요소의 텍스트 콘텐츠를 취득 또는 변경한다. 이때 마크업은 무시된다. textContent를 통해 요소에 새로운 텍스트를 할당하면 텍스트를 변경할 수 있다. 이때 순수한 텍스트만 지정해야 하며 마크업을 포함시키면 문자열로 인식되어 그대로 출력된다.
• IE9 이상의 브라우저에서 동작한다.
<!DOCTYPE html>
<html>
<head>
<style>
.red { color: #ff0000; }
.blue { color: #0000ff; }
</style>
</head>
<body>
<div>
<h1>Cities</h1>
<ul>
<li id="one" class="red">Seoul</li>
<li id="two" class="red">London</li>
<li id="three" class="red">Newyork</li>
<li id="four">Tokyo</li>
</ul>
</div>
<script>
const ul = document.querySelector('ul');
// 요소의 텍스트 취득
console.log(ul.textContent);
/*
Seoul
London
Newyork
Tokyo
*/
const one = document.getElementById('one');
// 요소의 텍스트 취득
console.log(one.textContent); // Seoul
// 요소의 텍스트 변경
one.textContent += ', Korea';
console.log(one.textContent); // Seoul, Korea
// 요소의 마크업이 포함된 콘텐츠 변경.
one.textContent = '<h1>Heading</h1>';
// 마크업이 문자열로 표시된다.
console.log(one.textContent); // <h1>Heading</h1>
</script>
</body>
</html>
innerText
• innerText 프로퍼티를 사용하여도 요소의 텍스트 콘텐츠에만 접근할 수 있다. 하지만 아래의 이유로 사용하지 않는 것이 좋다.
◦ 비표준이다.
◦ CSS에 순종적이다. 예를 들어 CSS에 의해 비표시(visibility: hidden;)로 지정되어 있다면 텍스트가 반환되지 않는다.
◦ CSS를 고려해야 하므로 textContent 프로퍼티보다 느리다innerHTML
• 해당 요소의 모든 자식 요소를 포함하는 모든 콘텐츠를 하나의 문자열로 취득할 수 있다. 이 문자열은 마크업을 포함한다.
const ul = document.querySelector('ul');
// innerHTML 프로퍼티는 모든 자식 요소를 포함하는 모든 콘텐츠를 하나의 문자열로 취득할 수 있다. 이 문자열은 마크업을 포함한다.
console.log(ul.innerHTML);
// IE를 제외한 대부분의 브라우저들은 요소 사이의 공백 또는 줄바꿈 문자를 텍스트 노드로 취급한다
/*
<li id="one" class="red">Seoul</li>
<li id="two" class="red">London</li>
<li id="three" class="red">Newyork</li>
<li id="four">Tokyo</li>
*/innerHTML 프로퍼티를 사용하여 마크업이 포함된 새로운 콘텐츠를 지정하면 새로운 요소를 DOM에 추가할 수 있다.
const one = document.getElementById('one');
// 마크업이 포함된 콘텐츠 취득
console.log(one.innerHTML); // Seoul
// 마크업이 포함된 콘텐츠 변경
one.innerHTML += '<em class="blue">, Korea</em>';
// 마크업이 포함된 콘텐츠 취득
console.log(one.innerHTML); // Seoul <em class="blue">, Korea</em>위와 같이 마크업이 포함된 콘텐츠를 추가하는 것은 크로스 스크립팅 공격(XSS: Cross-Site Scripting Attacks)에 취약하다.
// 크로스 스크립팅 공격 사례
// 스크립트 태그를 추가하여 자바스크립트가 실행되도록 한다.
// HTML5에서 innerHTML로 삽입된 <script> 코드는 실행되지 않는다.
// 크롬, 파이어폭스 등의 브라우저나 최신 브라우저 환경에서는 작동하지 않을 수도 있다.
elem.innerHTML = '<script>alert("XSS!")</script>';
// 에러 이벤트를 발생시켜 스크립트가 실행되도록 한다.
// 크롬에서도 실행된다!
elem.innerHTML = '<img src="#">';#4.4 DOM 조작 방식
innerHTML 프로퍼티를 사용하지 않고 새로운 콘텐츠를 추가할 수 있는 방법은 DOM을 직접 조작하는 것이다. 한 개의 요소를 추가하는 경우 사용한다. 이 방법은 다음의 수순에 따라 진행한다.
- 요소 노드 생성 createElement() 메소드를 사용하여 새로운 요소 노드를 생성한다. createElement() 메소드의 인자로 태그 이름을 전달한다.
- 텍스트 노드 생성 createTextNode() 메소드를 사용하여 새로운 텍스트 노드를 생성한다. 경우에 따라 생략될 수 있지만 생략하는 경우, 콘텐츠가 비어 있는 요소가 된다.
- 생성된 요소를 DOM에 추가 appendChild() 메소드를 사용하여 생성된 노드를 DOM tree에 추가한다. 또는 removeChild() 메소드를 사용하여 DOM tree에서 노드를 삭제할 수도 있다.
createElement(tagName)
• 태그이름을 인자로 전달하여 요소를 생성한다.
• Return: HTMLElement를 상속받은 객체
• 모든 브라우저에서 동작한다.
createTextNode(text)
• 텍스트를 인자로 전달하여 텍스트 노드를 생성한다.
• Return: Text 객체
• 모든 브라우저에서 동작한다.
appendChild(Node)
• 인자로 전달한 노드를 마지막 자식 요소로 DOM 트리에 추가한다.
• Return: 추가한 노드
• 모든 브라우저에서 동작한다.
removeChild(Node)
• 인자로 전달한 노드를 DOM 트리에 제거한다.
• Return: 추가한 노드
• 모든 브라우저에서 동작한다.
// 태그이름을 인자로 전달하여 요소를 생성
const newElem = document.createElement('li');
// const newElem = document.createElement('<li>test</li>');
// Uncaught DOMException: Failed to execute 'createElement' on 'Document': The tag name provided ('<li>test</li>') is not a valid name.
// 텍스트 노드를 생성
const newText = document.createTextNode('Beijing');
// 텍스트 노드를 newElem 자식으로 DOM 트리에 추가
newElem.appendChild(newText);
const container = document.querySelector('ul');
// newElem을 container의 자식으로 DOM 트리에 추가. 마지막 요소로 추가된다.
container.appendChild(newElem);
const removeElem = document.getElementById('one');
// container의 자식인 removeElem 요소를 DOM 트리에 제거한다.
container.removeChild(removeElem);#4.5 insertAdjacentHTML()
insertAdjacentHTML(position, string)
• 인자로 전달한 텍스트를 HTML로 파싱하고 그 결과로 생성된 노드를 DOM 트리의 지정된 위치에 삽입한다. 첫번째 인자는 삽입 위치, 두번째 인자는 삽입할 요소를 표현한 문자열이다. 첫번째 인자로 올 수 있는 값은 아래와 같다.
◦ ‘beforebegin’
◦ ‘afterbegin’
◦ ‘beforeend’
◦ ‘afterend’• 모든 브라우저에서 동작한다.

const one = document.getElementById('one');
// 마크업이 포함된 요소 추가
one.insertAdjacentHTML('beforeend', '<em class="blue">, Korea</em>');#4.6 innerHTML vs. DOM 조작 방식 vs. insertAdjacentHTML()
innerHTML
| 장점 | 단점 |
|---|---|
| DOM 조작 방식에 비해 빠르고 간편하다. | XSS공격에 취약점이 있기 때문에 사용자로 부터 입력받은 콘텐츠(untrusted data: 댓글, 사용자 이름 등)를 추가할 때 주의하여야 한다. |
| 간편하게 문자열로 정의한 여러 요소를 DOM에 추가할 수 있다. | 해당 요소의 내용을 덮어 쓴다. 즉, HTML을 다시 파싱한다. 이것은 비효율적이다. |
| 콘텐츠를 취득할 수 있다. |
DOM 조작 방식
| 장점 | 단점 |
|---|---|
| 특정 노드 한 개(노드, 텍스트, 데이터 등)를 DOM에 추가할 때 적합하다. | innerHTML보다 느리고 더 많은 코드가 필요하다. |
insertAdjacentHTML()
| 장점 | 단점 |
|---|---|
| 간편하게 문자열로 정의된 여러 요소를 DOM에 추가할 수 있다. | XSS공격에 취약점이 있기 때문에 사용자로 부터 입력받은 콘텐츠(untrusted data: 댓글, 사용자 이름 등)를 추가할 때 주의하여야 한다. |
| 삽입되는 위치를 선정할 수 있다. |
결론
innerHTML과 insertAdjacentHTML()은 크로스 스크립팅 공격(XSS: Cross-Site Scripting Attacks)에 취약하다. 따라서 untrusted data의 경우, 주의하여야 한다. 텍스트를 추가 또는 변경시에는 textContent, 새로운 요소의 추가 또는 삭제시에는 DOM 조작 방식을 사용하도록 한다.
#5. style
style 프로퍼티를 사용하면 inline 스타일 선언을 생성한다. 특정 요소에 inline 스타일을 지정하는 경우 사용한다.
const four = document.getElementById('four');
// inline 스타일 선언을 생성
four.style.color = 'blue';
// font-size와 같이 '-'으로 구분되는 프로퍼티는 카멜케이스로 변환하여 사용한다.
four.style.fontSize = '2em';style 프로퍼티의 값을 취득하려면 window.getComputedStyle을 사용한다. window.getComputedStyle 메소드는 인자로 주어진 요소의 모든 CSS 프로퍼티 값을 반환한다.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>style 프로퍼티 값 취득</title>
<style>
.box {
width: 100px;
height: 50px;
background-color: red;
border: 1px solid black;
}
</style>
</head>
<body>
<div class="box"></div>
<script>
const box = document.querySelector('.box');
const width = getStyle(box, 'width');
const height = getStyle(box, 'height');
const backgroundColor = getStyle(box, 'background-color');
const border = getStyle(box, 'border');
console.log('width: ' + width);
console.log('height: ' + height);
console.log('backgroundColor: ' + backgroundColor);
console.log('border: ' + border);
/**
* 요소에 적용된 CSS 프로퍼티를 반환한다.
* @param {HTTPElement} elem - 대상 요소 노드.
* @param {string} prop - 대상 CSS 프로퍼티.
* @returns {string} CSS 프로퍼티의 값.
*/
function getStyle(elem, prop) {
return window.getComputedStyle(elem, null).getPropertyValue(prop);
}
</script>
</body>
</html>ㅤㅤ
📍 Asynchronous processing model : 동기식 처리 모델 vs 비동기식 처리 모델
동기식 처리 모델(Synchronous processing model)은 직렬적으로 태스크(task)를 수행한다. 즉, 태스크는 순차적으로 실행되며 어떤 작업이 수행 중이면 다음 작업은 대기하게 된다.

동기식 처리 모델과 비동기식 처리 모델
예를 들어 서버에서 데이터를 가져와서 화면에 표시하는 작업을 수행할 때, 서버에 데이터를 요청하고 데이터가 응답될 때까지 이후 태스크들은 블로킹(blocking, 작업 중단)된다.
동기식 처리 모델(Synchronous processing model)
아래는 동기식으로 동작하는 코드이다. 순차적으로 실행된다.
function func1() {
console.log('func1');
func2();
}
function func2() {
console.log('func2');
func3();
}
function func3() {
console.log('func3');
}
func1();비동기식 처리 모델(Asynchronous processing model 또는 Non-Blocking processing model)은 병렬적으로 태스크를 수행한다. 즉, 태스크가 종료되지 않은 상태라 하더라도 대기하지 않고 다음 태스크를 실행한다. 예를 들어 서버에서 데이터를 가져와서 화면에 표시하는 태스크를 수행할 때, 서버에 데이터를 요청한 이후 서버로부터 데이터가 응답될 때까지 대기하지 않고(Non-Blocking) 즉시 다음 태스크를 수행한다. 이후 서버로부터 데이터가 응답되면 이벤트가 발생하고 이벤트 핸들러가 데이터를 가지고 수행할 태스크를 계속해 수행한다.
자바스크립트의 대부분의 DOM 이벤트 핸들러와 Timer 함수(setTimeout, setInterval), Ajax 요청은 비동기식 처리 모델로 동작한다.
아래는 비동기식으로 동작하는 코드이다. 순차적으로 실행되지 않는다.
function func1() {
console.log('func1');
func2();
}
function func2() {
setTimeout(function () {
console.log('func2');
}, 0);
func3();
}
function func3() {
console.log('func3');
}
func1();위 예제를 실행하면 setTimeout 메소드에 두번째 인수 인터벌을 0초로 설정하여도 콘솔에 “func1 func2 func3”의 순서로 로그가 출력되지 않는다. 이는 setTimeout 메소드가 비동기 함수이기 때문이다.
함수 func1이 호출되면 함수 func1은 Call Stack에 쌓인다. 그리고 함수 func1은 함수 func2을 호출하므로 함수 func2가 Call Stack에 쌓이고 setTimeout가 호출된다. setTimeout의 콜백함수는 즉시 실행되지 않고 지정 대기 시간만큼 기다리다가 “tick” 이벤트가 발생하면 태스크 큐로 이동한 후 Call Stack이 비어졌을 때 Call Stack으로 이동되어 실행된다.
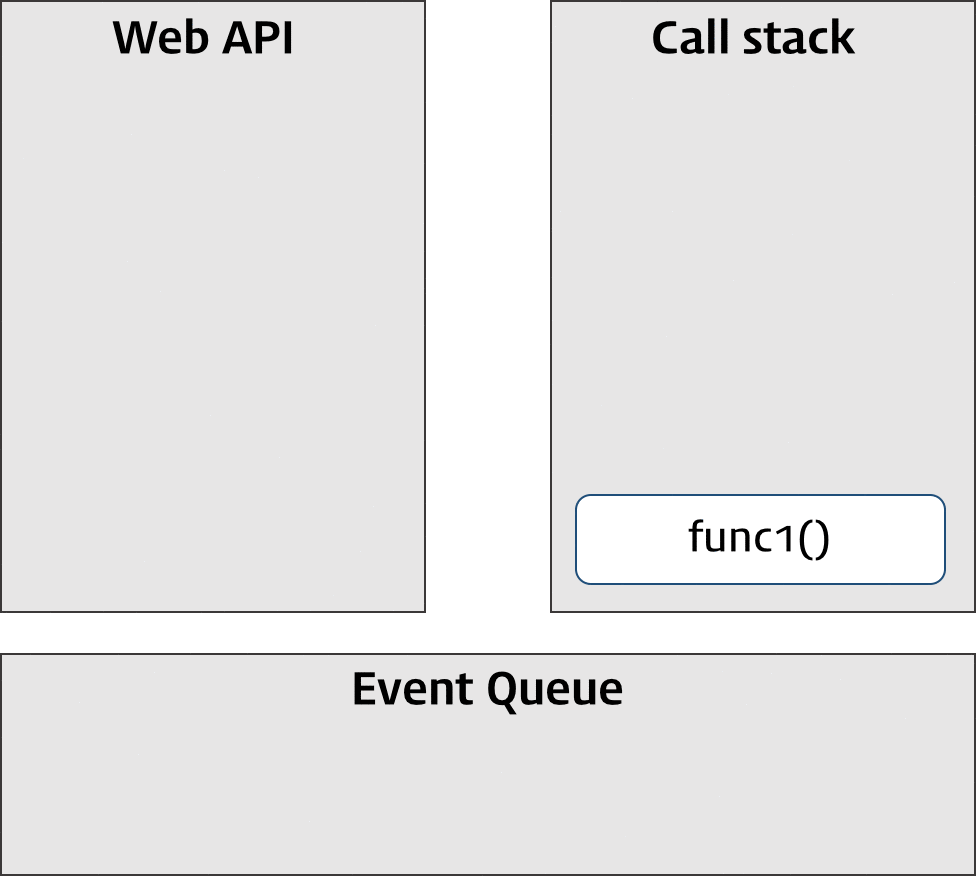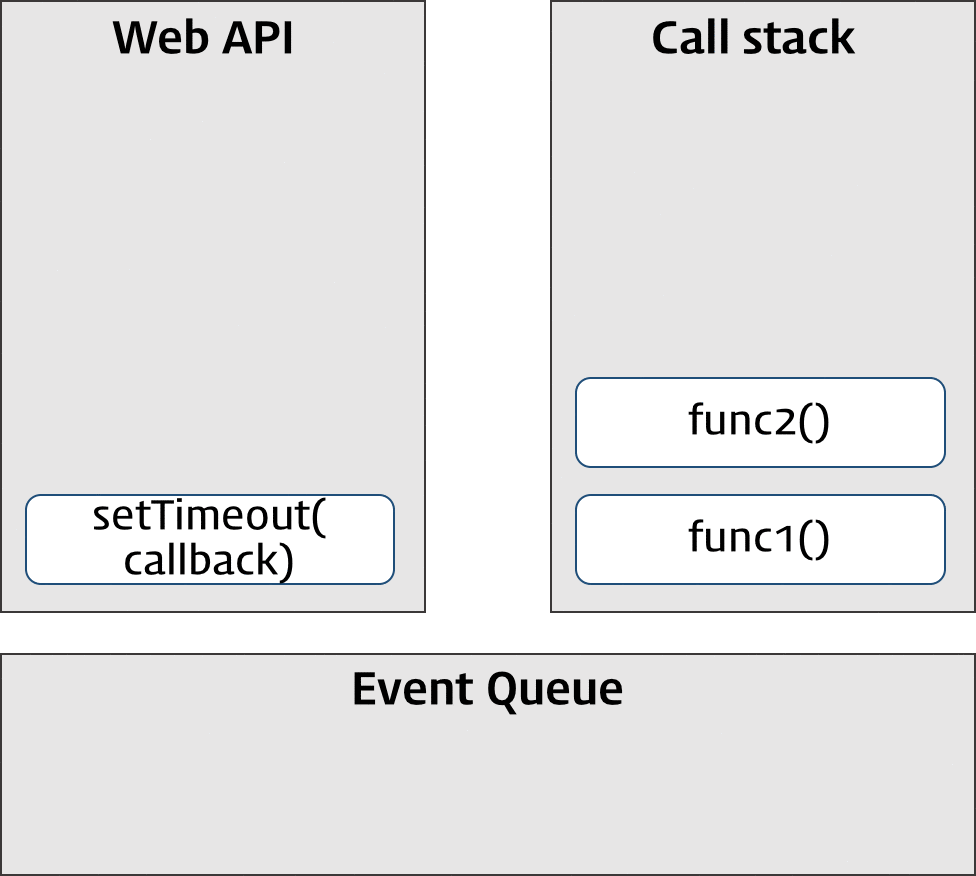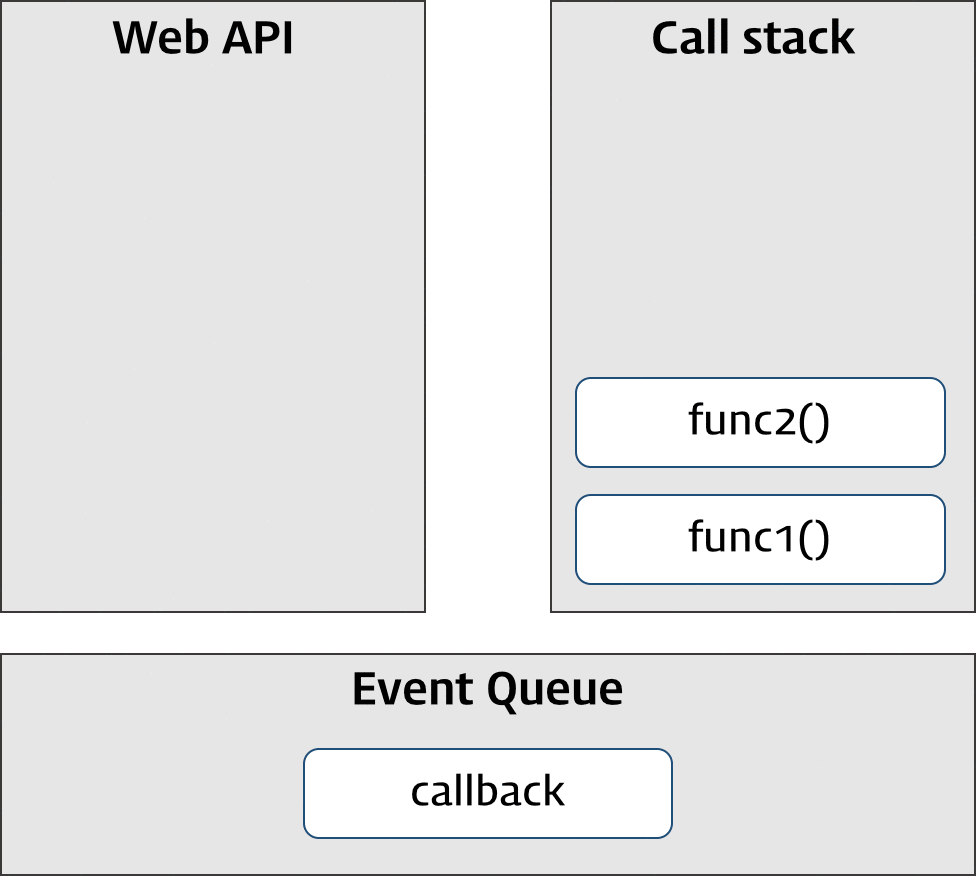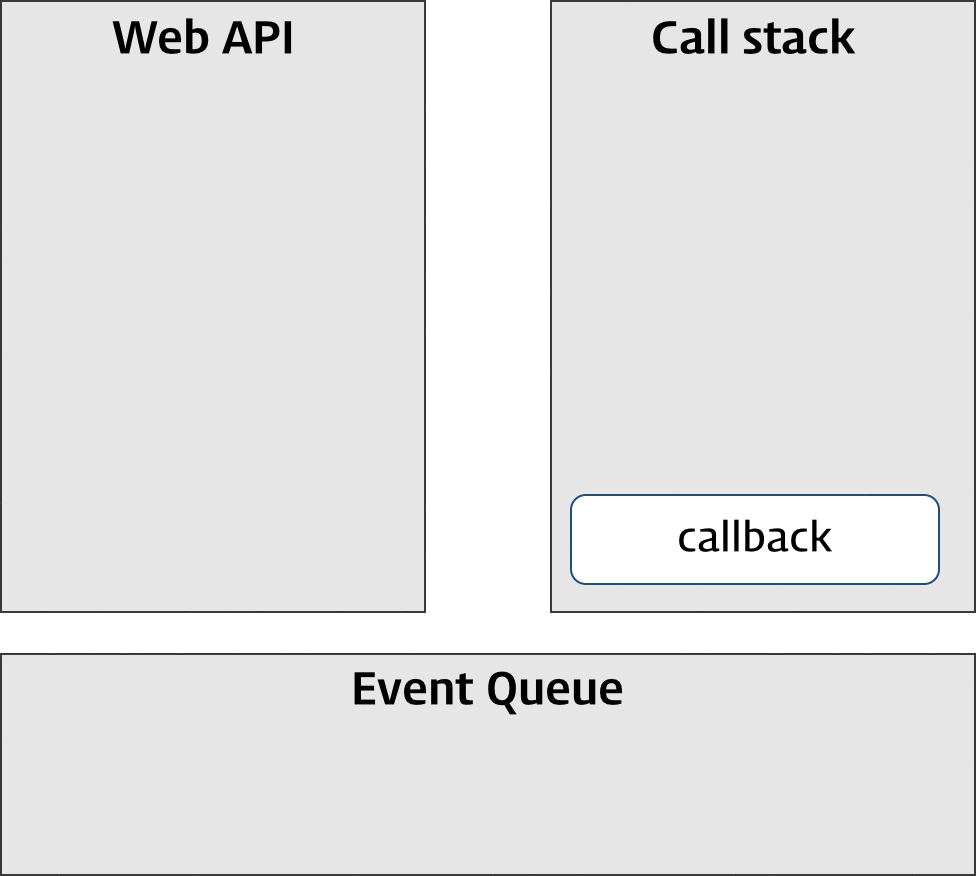
ㅤㅤ
📍 Event : 이벤트
1. Introduction
이벤트(event)는 어떤 사건을 의미한다. 브라우저에서의 이벤트란 예를 들어 사용자가 버튼을 클릭했을 때, 웹페이지가 로드되었을 때와 같은 것인데 이것은 DOM 요소와 관련이 있다.
이벤트가 발생하는 시점이나 순서를 사전에 인지할 수 없으므로 일반적인 제어 흐름과는 다른 접근 방식이 필요하다. 즉, 이벤트가 발생하면 누군가 이를 감지할 수 있어야 하며 그에 대응하는 처리를 호출해 주어야 한다.
브라우저는 이벤트를 감지할 수 있으며 이벤트 발생 시에는 통지해 준다. 이 과정을 통해 사용자와 웹페이지는 상호작용(Interaction)이 가능하게 된다.
<!DOCTYPE html>
<html>
<body>
<button class="myButton">Click me!</button>
<script>
document.querySelector('.myButton').addEventListener('click', function () {
alert('Clicked!');
});
</script>
</body>
</html>이벤트가 발생하면 그에 맞는 반응을 하여야 한다. 이를 위해 이벤트는 일반적으로 함수에 연결되며 그 함수는 이벤트가 발생하기 전에는 실행되지 않다가 이벤트가 발생되면 실행된다. 이 함수를 이벤트 핸들러라 하며 이벤트에 대응하는 처리를 기술한다.
#2. 이벤트 루프(Event Loop)와 동시성(Concurrency)
브라우저는 단일 쓰레드(single-thread)에서 이벤트 드리븐(event-driven) 방식으로 동작한다.
단일 쓰레드는 쓰레드가 하나뿐이라는 의미이며 이말은 곧 하나의 작업(task)만을 처리할 수 있다는 것을 의미한다. 하지만 실제로 동작하는 웹 애플리케이션은 많은 task가 동시에 처리되는 것처럼 느껴진다. 이처럼 자바스크립트의 동시성(Concurrency)을 지원하는 것이 바로 이벤트 루프(Event Loop)이다.
브라우저의 환경을 그림으로 표현하면 아래와 같다.
구글의 V8을 비롯한 대부분의 자바스크립트 엔진은 크게 2개의 영역으로 나뉜다.
Call Stack(호출 스택)
작업이 요청되면(함수가 호출되면) 요청된 작업은 순차적으로 Call Stack에 쌓이게 되고 순차적으로 실행된다. 자바스크립트는 단 하나의 Call Stack을 사용하기 때문에 해당 task가 종료하기 전까지는 다른 어떤 task도 수행될 수 없다.
Heap
동적으로 생성된 객체 인스턴스가 할당되는 영역이다.
이와 같이 자바스크립트 엔진은 단순히 작업이 요청되면 Call Stack을 사용하여 요청된 작업을 순차적으로 실행할 뿐이다. 앞에서 언급한 동시성(Concurrency)을 지원하기 위해 필요한 비동기 요청(이벤트를 포함) 처리는 자바스크립트 엔진을 구동하는 환경 즉 브라우저(또는 Node.js)가 담당한다.
Event Queue(Task Queue)
비동기 처리 함수의 콜백 함수, 비동기식 이벤트 핸들러, Timer 함수(setTimeout(), setInterval())의 콜백 함수가 보관되는 영역으로이벤트 루프(Event Loop)에 의해 특정 시점(Call Stack이 비어졌을 때)에 순차적으로 Call Stack으로 이동되어 실행된다
Event Loop(이벤트 루프)
Call Stack 내에서 현재 실행중인 task가 있는지 그리고 Event Queue에 task가 있는지 반복하여 확인한다. 만약 Call Stack이 비어있다면 Event Queue 내의 task가 Call Stack으로 이동하고 실행된다.
function func1() {
console.log('func1');
func2();
}
function func2() {
setTimeout(function () {
console.log('func2');
}, 0);
func3();
}
function func3() {
console.log('func3');
}
func1();함수 func1이 호출되면 함수 func1은 Call Stack에 쌓인다. 그리고 함수 func1은 함수 func2을 호출하므로 함수 func2가 Call Stack에 쌓이고 setTimeout가 호출된다. setTimeout의 콜백함수는 즉시 실행되지 않고 지정 대기 시간만큼 기다리다가 “tick” 이벤트가 발생하면 태스크 큐로 이동한 후 Call Stack이 비어졌을 때 Call Stack으로 이동되어 실행된다.
DOM 이벤트 핸들러도 이와 같이 동작한다.
function func1() {
console.log('func1');
func2();
}
function func2() {
// <button class="foo">foo</button>
const elem = document.querySelector('.foo');
elem.addEventListener('click', function () {
this.style.backgroundColor = 'indigo';
console.log('func2');
});
func3();
}
function func3() {
console.log('func3');
}
func1();함수 func1이 호출되면 함수 func1은 Call Stack에 쌓인다. 그리고 함수 func1은 함수 func2을 호출하므로 함수 func2가 Call Stack에 쌓이고 addEventListener가 호출된다. addEventListener의 콜백함수는 foo 버튼이 클릭되어 click 이벤트가 발생하면 태스크 큐로 이동한 후 Call Stack이 비어졌을 때 Call Stack으로 이동되어 실행된다.
#3. 이벤트의 종류
#3.1 UI Event
| Event | Description |
|---|---|
| load | 웹페이지의 로드가 완료되었을 때 |
| unload | 웹페이지가 언로드될 때(주로 새로운 페이지를 요청한 경우) |
| error | 브라우저가 자바스크립트 오류를 만났거나 요청한 자원이 존재하지 않는 경우 |
| resize | 브라우저 창의 크기를 조절했을 때 |
| scroll | 사용자가 페이지를 위아래로 스크롤할 때 |
| select | 텍스트를 선택했을 때 |
#3.2 Keyboard Event
| Event | Description |
|---|---|
| keydown | 키를 누르고 있을 때 |
| keyup | 누르고 있던 키를 뗄 때 |
| keypress | 키를 누르고 뗏을 때 |
#3.3 Mouse Event
| Event | Description |
|---|---|
| click | 마우스 버튼을 클릭했을 때 |
| dbclick | 마우스 버튼을 더블 클릭했을 때 |
| mousedown | 마우스 버튼을 누르고 있을 때 |
| mouseup | 누르고 있던 마우스 버튼을 뗄 때 |
| mousemove | 마우스를 움직일 때 (터치스크린에서 동작하지 않는다) |
| mouseover | 마우스를 요소 위로 움직였을 때 (터치스크린에서 동작하지 않는다) |
| mouseout | 마우스를 요소 밖으로 움직였을 때 (터치스크린에서 동작하지 않는다) |
#3.4 Focus Event
| Event | Description |
|---|---|
| focus/focusin | 요소가 포커스를 얻었을 때 |
| blur/foucusout | 요소가 포커스를 잃었을 때 |
#3.5 Form Event
| Event | Description |
|---|---|
| input | input 또는 textarea 요소의 값이 변경되었을 때 |
| contenteditable 어트리뷰트를 가진 요소의 값이 변경되었을 때 | |
| change | select box, checkbox, radio button의 상태가 변경되었을 때 |
| submit | form을 submit할 때 (버튼 또는 키) |
| reset | reset 버튼을 클릭할 때 (최근에는 사용 안함) |
#3.6 Clipboard Event
| Event | Description |
|---|---|
| cut | 콘텐츠를 잘라내기할 때 |
| copy | 콘텐츠를 복사할 때 |
| paste | 콘텐츠를 붙여넣기할 때 |
#4. 이벤트 핸들러 등록
이벤트가 발생했을 때 동작할 이벤트 핸들러를 이벤트에 등록하는 방법은 아래와 같이 3가지이다.
#4.1 인라인 이벤트 핸들러 방식
HTML 요소의 이벤트 핸들러 어트리뷰트에 이벤트 핸들러를 등록하는 방법이다.
<!DOCTYPE html>
<html>
<body>
<button onclick="myHandler()">Click me</button>
<script>
function myHandler() {
alert('Button clicked!');
}
</script>
</body>
</html>
이 방식은 더 이상 사용되지 않으며 사용해서도 않된다. 오래된 코드에서 간혹 이 방식을 사용한 것이 있기 때문에 알아둘 필요는 있다. HTML과 Javascript는 관심사가 다르므로 분리하는 것이 좋다.
최근 관심을 받고 있는 CBD(Component Based Development) 방식의 Angular/React/Vue.js와 같은 프레임워크/라이브러리에서는 인라인 이벤트 핸들러 방식으로 이벤트를 처리한다. CBD에서는 HTML, CSS, 자바스크립트를 뷰를 구성하기 위한 구성 요소로 보기 때문에 관심사가 다르다고 생각하지 않는다.
주의할 것은 onclick과 같이 on으로 시작하는 이벤트 어트리뷰트의 값으로 함수 호출을 전달한다는 것이다. 다음에 살펴볼 이벤트 핸들러 프로퍼티 방식에는 DOM 요소의 이벤트 핸들러 프로퍼티에 함수 호출이 아닌 함수를 전달한다.
이때 이벤트 어트리뷰트의 값으로 전달한 함수 호출이 즉시 호출되는 것은 아니다. 사실은 이벤트 어트리뷰트 키를 이름으로 갖는 함수를 암묵적으로 정의하고 그 함수의 몸체에 이벤트 어트리뷰트의 값으로 전달한 함수 호출을 문으로 갖는다. 위 예제의 경우, button 요소의 onclick 프로퍼티에 함수 function onclick(event) { foo(); }가 할당된다.
즉, 이벤트 어트리뷰트의 값은 암묵적으로 정의되는 이벤트 핸들러의 문이다. 따라서 아래와 같이 여러 개의 문을 전달할 수 있다.
<!DOCTYPE html>
<html>
<body>
<button onclick="myHandler1(); myHandler2();">Click me</button>
<script>
function myHandler1() {
alert('myHandler1');
}
function myHandler2() {
alert('myHandler2');
}
</script>
</body>
</html>
#4.2 이벤트 핸들러 프로퍼티 방식
인라인 이벤트 핸들러 방식처럼 HTML과 Javascript가 뒤섞이는 문제는 해결할 수 있는 방식이다. 하지만 이벤트 핸들러 프로퍼티에 하나의 이벤트 핸들러만을 바인딩할 수 있다는 단점이 있다.
<!DOCTYPE html>
<html>
<body>
<button class="btn">Click me</button>
<script>
const btn = document.querySelector('.btn');
// 이벤트 핸들러 프로퍼티 방식은 이벤트에 하나의 이벤트 핸들러만을 바인딩할 수 있다
// 첫번째 바인딩된 이벤트 핸들러 => 실행되지 않는다.
btn.onclick = function () {
alert('① Button clicked 1');
};
// 두번째 바인딩된 이벤트 핸들러
btn.onclick = function () {
alert('① Button clicked 2');
};
// addEventListener 메소드 방식
// 첫번째 바인딩된 이벤트 핸들러
btn.addEventListener('click', function () {
alert('② Button clicked 1');
});
// 두번째 바인딩된 이벤트 핸들러
btn.addEventListener('click', function () {
alert('② Button clicked 2');
});
</script>
</body>
</html>
#4.3 addEventListener 메소드 방식
addEventListener 메소드를 이용하여 대상 DOM 요소에 이벤트를 바인딩하고 해당 이벤트가 발생했을 때 실행될 콜백 함수(이벤트 핸들러)를 지정한다.
addEventListener 함수 방식은 이전 방식에 비해 아래와 같이 보다 나은 장점을 갖는다.
- 하나의 이벤트에 대해 하나 이상의 이벤트 핸들러를 추가할 수 있다.
- 캡처링과 버블링을 지원한다.
- HTML 요소뿐만아니라 모든 DOM 요소(HTML, XML, SVG)에 대해 동작한다. 브라우저는 웹 문서(HTML, XML, SVG)를 로드한 후, 파싱하여 DOM을 생성한다.
if (elem.addEventListener) {
// IE 9 ~
elem.addEventListener('click', func);
} else if (elem.attachEvent) {
// ~ IE 8
elem.attachEvent('onclick', func);
}addEventListener 메소드의 사용 예제를 살펴본다.
<!DOCTYPE html>
<html>
<body>
<script>
addEventListener('click', function () {
alert('Clicked!');
});
</script>
</body>
</html>
위와 같이 대상 DOM 요소(target)를 지정하지 않으면 전역객체 window, 즉 DOM 문서를 포함한 브라우저의 윈도우에서 발생하는 click 이벤트에 이벤트 핸들러를 바인딩한다. 따라서 브라우저 윈도우 어디를 클릭하여도 이벤트 핸들러가 동작한다.
<!DOCTYPE html>
<html>
<body>
<label>User name <input type='text'></label>
<script>
const input = document.querySelector('input[type=text]');
input.addEventListener('blur', function () {
alert('blur event occurred!');
});
</script>
</body>
</html>
위 예제는 input 요소에서 발생하는 blur 이벤트에 이벤트 핸들러를 바인딩하였다. 사용자 이름이 최소 2자 이상이야한다는 규칙을 세우고 이에 부합하는지 확인해본다.
<!DOCTYPE html>
<html>
<body>
<label>User name <input type='text'></label>
<em class="message"></em>
<script>
const input = document.querySelector('input[type=text]');
const msg = document.querySelector('.message');
input.addEventListener('blur', function () {
if (input.value.length < 2) {
msg.innerHTML = '이름은 2자 이상 입력해 주세요';
} else {
msg.innerHTML = '';
}
});
</script>
</body>
</html>
2자 이상이라는 규칙이 바뀌면 이 규칙을 확인하는 모든 코드를 수정해야 한다. 따라서 이러한 방식의 코딩은 바람직하지 않다. 이유는 규모가 큰 프로그램의 경우 수정과 테스트에 소요되는 자원의 낭비도 문제이지만 수정에는 거의 대부분 실수가 동반되기 때문이다.
2자 이상이라는 규칙을 상수화하고 함수의 인수로 전달도록 수정한다. 이렇게 하면 규칙이 변경되어도 함수는 수정하지 않아도 된다.
그런데 addEventListener 메소드의 두번째 매개변수는 이벤트가 발생했을 때 호출될 이벤트 핸들러이다. 이때 두번째 매개변수에는 함수 호출이 아니라 함수 자체를 지정하여야 한다.
function foo() {
alert('clicked!');
}
// elem.addEventListener('click', foo()); // 이벤트 발생 시까지 대기하지 않고 바로 실행된다
elem.addEventListener('click', foo); // 이벤트 발생 시까지 대기한다따라서 이벤트 핸들러 프로퍼티 방식과 같이 이벤트 핸들러 함수에 인수를 전달할 수 없는 문제가 발생한다. 이를 우회하는 방법은 아래와 같다.
<!DOCTYPE html>
<html>
<body>
<label>User name <input type='text'></label>
<em class="message"></em>
<script>
const MIN_USER_NAME_LENGTH = 2; // 이름 최소 길이
const input = document.querySelector('input[type=text]');
const msg = document.querySelector('.message');
function checkUserNameLength(n) {
if (input.value.length < n) {
msg.innerHTML = '이름은 ' + n + '자 이상이어야 합니다';
} else {
msg.innerHTML = '';
}
}
input.addEventListener('blur', function () {
// 이벤트 핸들러 내부에서 함수를 호출하면서 인수를 전달한다.
checkUserNameLength(MIN_USER_NAME_LENGTH);
});
// 이벤트 핸들러 프로퍼티 방식도 동일한 방식으로 인수를 전달할 수 있다.
// input.onblur = function () {
// // 이벤트 핸들러 내부에서 함수를 호출하면서 인수를 전달한다.
// checkUserNameLength(MIN_USER_NAME_LENGTH);
// };
</script>
</body>
</html>
#5. 이벤트 핸들러 함수 내부의 this
#5.1 인라인 이벤트 핸들러 방식
인라인 이벤트 핸들러 방식의 경우, 이벤트 핸들러는 일반 함수로서 호출되므로 이벤트 핸들러 내부의 this는 전역 객체 window를 가리킨다.
<!DOCTYPE html>
<html>
<body>
<button onclick="foo()">Button</button>
<script>
function foo () {
console.log(this); // window
}
</script>
</body>
</html>
#5.2 이벤트 핸들러 프로퍼티 방식
이벤트 핸들러 프로퍼티 방식에서 이벤트 핸들러는 메소드이므로 이벤트 핸들러 내부의 this는 이벤트에 바인딩된 요소를 가리킨다. 이것은 이벤트 객체의 currentTarget 프로퍼티와 같다.
<!DOCTYPE html>
<html>
<body>
<button class="btn">Button</button>
<script>
const btn = document.querySelector('.btn');
btn.onclick = function (e) {
console.log(this); // <button id="btn">Button</button>
console.log(e.currentTarget); // <button id="btn">Button</button>
console.log(this === e.currentTarget); // true
};
</script>
</body>
</html>
#5.3 addEventListener 메소드 방식
addEventListener 메소드에서 지정한 이벤트 핸들러는 콜백 함수이지만 이벤트 핸들러 내부의 this는 이벤트 리스너에 바인딩된 요소(currentTarget)를 가리킨다. 이것은 이벤트 객체의 currentTarget 프로퍼티와 같다.
<!DOCTYPE html>
<html>
<body>
<button class="btn">Button</button>
<script>
const btn = document.querySelector('.btn');
btn.addEventListener('click', function (e) {
console.log(this); // <button id="btn">Button</button>
console.log(e.currentTarget); // <button id="btn">Button</button>
console.log(this === e.currentTarget); // true
});
</script>
</body>
</html>
#6. 이벤트의 흐름
계층적 구조에 포함되어 있는 HTML 요소에 이벤트가 발생할 경우 연쇄적 반응이 일어난다. 즉, 이벤트가 전파(Event Propagation)되는데 전파 방향에 따라 버블링(Event Bubbling)과 캡처링(Event Capturing)으로 구분할 수 있다.
자식 요소에서 발생한 이벤트가 부모 요소로 전파되는 것을 버블링이라 하고, 자식 요소에서 발생한 이벤트가 부모 요소부터 시작하여 이벤트를 발생시킨 자식 요소까지 도달하는 것을 캡처링이라 한다. 주의할 것은 버블링과 캡처링은 둘 중에 하나만 발생하는 것이 아니라 캡처링부터 시작하여 버블링으로 종료한다는 것이다. 즉, 이벤트가 발생했을 때 캡처링과 버블링은 순차적으로 발생한다.

www.w3.org/TR/DOM-Level-3-Events
addEventListener 메소드의 세번째 매개변수에 true를 설정하면 캡처링으로 전파되는 이벤트를 캐치하고 false 또는 미설정하면 버블링으로 전파되는 이벤트를 캐치한다.
<!DOCTYPE html>
<html>
<head>
<style>
html { border:1px solid red; padding:30px; text-align: center; }
body { border:1px solid green; padding:30px; }
.top {
width: 300px; height: 300px;
background-color: red;
margin: auto;
}
.middle {
width: 200px; height: 200px;
background-color: blue;
position: relative; top: 34px; left: 50px;
}
.bottom {
width: 100px; height: 100px;
background-color: yellow;
position: relative; top: 34px; left: 50px;
line-height: 100px;
}
</style>
</head>
<body>
body
<div class="top">top
<div class="middle">middle
<div class="bottom">bottom</div>
</div>
</div>
<script>
// true: capturing / false: bubbling
const useCature = true;
const handler = function (e) {
const phases = ['capturing', 'target', 'bubbling'];
const node = this.nodeName + (this.className ? '.' + this.className : '');
// eventPhase: 이벤트 흐름 상에서 어느 phase에 있는지를 반환한다.
// 0 : 이벤트 없음 / 1 : 캡처링 단계 / 2 : 타깃 / 3 : 버블링 단계
console.log(node, phases[e.eventPhase - 1]);
alert(node + ' : ' + phases[e.eventPhase - 1]);
};
document.querySelector('html').addEventListener('click', handler, useCature);
document.querySelector('body').addEventListener('click', handler, useCature);
document.querySelector('div.top').addEventListener('click', handler, useCature);
document.querySelector('div.middle').addEventListener('click', handler, useCature);
document.querySelector('div.bottom').addEventListener('click', handler, useCature);
</script>
</body>
</html>
먼저 버블링의 경우 어떻게 동작하는지 알아본다.
<!DOCTYPE html>
<html>
<head>
<style>
html, body { height: 100%; }
</style>
<body>
<p>버블링 이벤트 <button>버튼</button></p>
<script>
const body = document.querySelector('body');
const para = document.querySelector('p');
const button = document.querySelector('button');
// 버블링
body.addEventListener('click', function () {
console.log('Handler for body.');
});
// 버블링
para.addEventListener('click', function () {
console.log('Handler for paragraph.');
});
// 버블링
button.addEventListener('click', function () {
console.log('Handler for button.');
});
</script>
</body>
</html>
위 코드는 모든 이벤트 핸들러가 이벤트 흐름을 버블링만 캐치한다. 즉, 캡쳐링 이벤트 흐름에 대해서는 동작하지 않는다. 따라서 button에서 이벤트가 발생하면 모든 이벤트 핸들러는 버블링에 대해 동작하여 아래와 같이 로그된다.
Handler for button.
Handler for paragraph.
Handler for body.
만약 p 요소에서 이벤트가 발생한다면 p 요소와 body 요소의 이벤트 핸들러는 버블링에 대해 동작하여 아래와 같이 로그된다.
Handler for paragraph.
Handler for body.
캡처링의 경우 어떻게 동작하는지 살펴본다.
<!DOCTYPE html>
<html>
<head>
<style>
html, body { height: 100%; }
</style>
<body>
<p>캡처링 이벤트 <button>버튼</button></p>
<script>
const body = document.querySelector('body');
const para = document.querySelector('p');
const button = document.querySelector('button');
// 캡처링
body.addEventListener('click', function () {
console.log('Handler for body.');
}, true);
// 캡처링
para.addEventListener('click', function () {
console.log('Handler for paragraph.');
}, true);
// 캡처링
button.addEventListener('click', function () {
console.log('Handler for button.');
}, true);
</script>
</body>
</html>
위 코드는 모든 이벤트 핸들러가 이벤트 흐름을 캡처링만 캐치한다. 즉, 버블링 이벤트 흐름에 대해서는 동작하지 않는다. 따라서 button에서 이벤트가 발생하면 모든 이벤트 핸들러는 캡처링에 대해 동작하여 아래와 같이 로그된다.
Handler for body.
Handler for paragraph.
Handler for button.
만약 p 요소에서 이벤트가 발생한다면 p 요소와 body 요소의 이벤트 핸들러는 캡처링에 대해 동작하여 아래와 같이 로그된다.
Handler for body.
Handler for paragraph.
다음은 캡처링과 버블링이 혼용되는 경우이다.
<!DOCTYPE html>
<html>
<head>
<style>
html, body { height: 100%; }
</style>
<body>
<p>버블링과 캡처링 이벤트 <button>버튼</button></p>
<script>
const body = document.querySelector('body');
const para = document.querySelector('p');
const button = document.querySelector('button');
// 버블링
body.addEventListener('click', function () {
console.log('Handler for body.');
});
// 캡처링
para.addEventListener('click', function () {
console.log('Handler for paragraph.');
}, true);
// 버블링
button.addEventListener('click', function () {
console.log('Handler for button.');
});
</script>
</body>
</html>
위 코드의 경우, body, button 요소는 버블링 이벤트 흐름만을 캐치하고 p 요소는 캡처링 이벤트 흐름만을 캐치한다. 따라서 button에서 이벤트가 발생하면 먼저 캡처링이 발생하므로 p 요소의 이벤트 핸들러가 동작하고, 그후 버블링이 발생하여 button, body 요소의 이벤트 핸들러가 동작한다.
Handler for paragraph.
Handler for button.
Handler for body.
만약 p 요소에서 이벤트가 발생한다면 캡처링에 대해 p 요소의 이벤트 핸들러가 동작하고 버블링에 대해 body 요소의 이벤트 핸들러가 동작한다.
Handler for paragraph.
Handler for body.
#7. Event 객체
event 객체는 이벤트를 발생시킨 요소와 발생한 이벤트에 대한 유용한 정보를 제공한다. 이벤트가 발생하면 event 객체는 동적으로 생성되며 이벤트를 처리할 수 있는 이벤트 핸들러에 인자로 전달된다.
<!DOCTYPE html>
<html>
<body>
<p>클릭하세요. 클릭한 곳의 좌표가 표시됩니다.</p>
<em class="message"></em>
<script>
function showCoords(e) { // e: event object
const msg = document.querySelector('.message');
msg.innerHTML =
'clientX value: ' + e.clientX + '<br>' +
'clientY value: ' + e.clientY;
}
addEventListener('click', showCoords);
</script>
</body>
</html>
위와 같이 event 객체는 이벤트 핸들러에 암묵적으로 전달된다. 그러나 이벤트 핸들러를 선언할 때, event 객체를 전달받을 첫번째 매개변수를 명시적으로 선언하여야 한다. 예제에서 e라는 이름으로 매개변수를 지정하였으나 다른 매개변수 이름을 사용하여도 상관없다.
<!DOCTYPE html>
<html>
<body>
<em class="message"></em>
<script>
function showCoords(e, msg) {
msg.innerHTML =
'clientX value: ' + e.clientX + '<br>' +
'clientY value: ' + e.clientY;
}
const msg = document.querySelector('.message');
addEventListener('click', function (e) {
showCoords(e, msg);
});
</script>
</body>
</html>
#7.1 Event Property
#7.1.1 Event.target
실제로 이벤트를 발생시킨 요소를 가리킨다.
<!DOCTYPE html>
<html>
<body>
<div class="container">
<button id="btn1">Hide me 1</button>
<button id="btn2">Hide me 2</button>
</div>
<script>
function hide(e) {
e.target.style.visibility = 'hidden';
// 동일하게 동작한다.
// this.style.visibility = 'hidden';
}
document.getElementById('btn1').addEventListener('click', hide);
document.getElementById('btn2').addEventListener('click', hide);
</script>
</body>
</html>
hide 함수를 특정 노드에 한정하여 사용하지 않고 범용적으로 사용하기 위해 event 객체의 target 프로퍼티를 사용하였다. 위 예제의 경우, hide 함수 내부의 e.target은 언제나 이벤트가 바인딩된 요소를 가리키는 this와 일치한다. 하지만 버튼별로 이벤트를 바인딩하고 있기 때문에 버튼이 많은 경우 위 방법은 바람직하지 않아 보인다.
<!DOCTYPE html>
<html>
<body>
<div class="container">
<button id="btn1">Hide me 1</button>
<button id="btn2">Hide me 2</button>
</div>
<script>
const container = document.querySelector('.container');
function hide(e) {
// e.target은 실제로 이벤트를 발생시킨 DOM 요소를 가리킨다.
e.target.style.visibility = 'hidden';
// this는 이벤트에 바인딩된 DOM 요소(.container)를 가리킨다. 따라서 .container 요소를 감춘다.
// this.style.visibility = 'hidden';
}
container.addEventListener('click', hide);
</script>
</body>
</html>
위 예제의 경우, this는 이벤트에 바인딩된 DOM 요소(.container)를 가리킨다. 따라서 container 요소를 감춘다. e.target은 실제로 이벤트를 발생시킨 DOM 요소(button 요소 또는 .container 요소)를 가리킨다. Event.target은 this와 반드시 일치하지는 않는다.
#7.1.2 Event.currentTarget
이벤트에 바인딩된 DOM 요소를 가리킨다. 즉, addEventListener 앞에 기술된 객체를 가리킨다.
addEventListener 메소드에서 지정한 이벤트 핸들러 내부의 this는 이벤트에 바인딩된 DOM 요소를 가리키며 이것은 이벤트 객체의 currentTarget 프로퍼티와 같다. 따라서 이벤트 핸들러 함수 내에서 currentTarget과 this는 언제나 일치한다.
<!DOCTYPE html>
<html>
<head>
<style>
html, body { height: 100%; }
div { height: 100%; }
</style>
</head>
<body>
<div>
<button>배경색 변경</button>
</div>
<script>
function bluify(e) {
// this: 이벤트에 바인딩된 DOM 요소(div 요소)
console.log('this: ', this);
// target: 실제로 이벤트를 발생시킨 요소(button 요소 또는 div 요소)
console.log('e.target:', e.target);
// currentTarget: 이벤트에 바인딩된 DOM 요소(div 요소)
console.log('e.currentTarget: ', e.currentTarget);
// 언제나 true
console.log(this === e.currentTarget);
// currentTarget과 target이 같은 객체일 때 true
console.log(this === e.target);
// click 이벤트가 발생하면 이벤트를 발생시킨 요소(target)과는 상관없이 this(이벤트에 바인딩된 div 요소)의 배경색이 변경된다.
this.style.backgroundColor = '#A5D9F3';
}
// div 요소에 이벤트 핸들러가 바인딩되어 있다.
// 자식 요소인 button이 발생시킨 이벤트가 버블링되어 div 요소에도 전파된다.
// 따라서 div 요소에 이벤트 핸들러가 바인딩되어 있으면 자식 요소인 button이 발생시킨 이벤트를 div 요소에서도 핸들링할 수 있다.
document.querySelector('div').addEventListener('click', bluify);
</script>
</body>
</html>
#7.1.3 Event.type
발생한 이벤트의 종류를 나타내는 문자열을 반환한다.
<!DOCTYPE html>
<html>
<body>
<p>키를 입력하세요</p>
<em class="message"></em>
<script>
const body = document.querySelector('body');
function getEventType(e) {
console.log(e);
document.querySelector('.message').innerHTML = `${e.type} : ${e.keyCode}`;
}
body.addEventListener('keydown', getEventType);
body.addEventListener('keyup', getEventType);
</script>
</body>
</html>
#7.1.4 Event.cancelable
요소의 기본 동작을 취소시킬 수 있는지 여부(true/false)를 나타낸다.
<!DOCTYPE html>
<html>
<body>
<a href="poiemaweb.com">Go to poiemaweb.com</a>
<script>
const elem = document.querySelector('a');
elem.addEventListener('click', function (e) {
console.log(e.cancelable);
// 기본 동작을 중단시킨다.
e.preventDefault();
});
</script>
</body>
</html>
#7.1.5 Event.eventPhase
이벤트 흐름(event flow) 상에서 어느 단계(event phase)에 있는지를 반환한다.
| 반환값 | 의미 |
|---|---|
| 0 | 이벤트 없음 |
| 1 | 캡쳐링 단계 |
| 2 | 타깃 |
| 3 | 버블링 단계 |
#8. Event Delegation (이벤트 위임)
<ul id='post-list'>
<li id='post-1'>Item 1</li>
<li id='post-2'>Item 2</li>
<li id='post-3'>Item 3</li>
<li id='post-4'>Item 4</li>
<li id='post-5'>Item 5</li>
<li id='post-6'>Item 6</li>
</ul>모든 li 요소가 클릭 이벤트에 반응하는 처리를 구현하고 싶은 경우, li 요소에 이벤트 핸들러를 바인딩하면 총 6개의 이벤트 핸들러를 바인딩하여야 한다.
function printId() {
console.log(this.id);
}
document.querySelector('#post-1').addEventListener('click', printId);
document.querySelector('#post-2').addEventListener('click', printId);
document.querySelector('#post-3').addEventListener('click', printId);
document.querySelector('#post-4').addEventListener('click', printId);
document.querySelector('#post-5').addEventListener('click', printId);
document.querySelector('#post-6').addEventListener('click', printId);만일 li 요소가 100개라면 100개의 이벤트 핸들러를 바인딩하여야 한다. 이는 실행 속도 저하의 원인이 될 뿐 아니라 코드 또한 매우 길어지며 작성 또한 불편하다.
그리고 동적으로 li 요소가 추가되는 경우, 아직 추가되지 않은 요소는 DOM에 존재하지 않으므로 이벤트 핸들러를 바인딩할 수 없다. 이러한 경우 이벤트 위임을 사용한다.
이벤트 위임(Event Delegation)은 다수의 자식 요소에 각각 이벤트 핸들러를 바인딩하는 대신 하나의 부모 요소에 이벤트 핸들러를 바인딩하는 방법이다. 위의 경우 6개의 자식 요소에 각각 이벤트 핸들러를 바인딩하는 것 대신 부모 요소(ul#post-list)에 이벤트 핸들러를 바인딩하는 것이다.
또한 DOM 트리에 새로운 li 요소를 추가하더라도 이벤트 처리는 부모 요소인 ul 요소에 위임되었기 때문에 새로운 요소에 이벤트를 핸들러를 다시 바인딩할 필요가 없다.
이는 이벤트가 [이벤트 흐름]에 의해 이벤트를 발생시킨 요소의 부모 요소에도 영향(버블링)을 미치기 때문에 가능한 것이다.
실제로 이벤트를 발생시킨 요소를 알아내기 위해서는 Event.target을 사용한다.
<!DOCTYPE html>
<html>
<body>
<ul class="post-list">
<li id="post-1">Item 1</li>
<li id="post-2">Item 2</li>
<li id="post-3">Item 3</li>
<li id="post-4">Item 4</li>
<li id="post-5">Item 5</li>
<li id="post-6">Item 6</li>
</ul>
<div class="msg">
<script>
const msg = document.querySelector('.msg');
const list = document.querySelector('.post-list')
list.addEventListener('click', function (e) {
// 이벤트를 발생시킨 요소
console.log('[target]: ' + e.target);
// 이벤트를 발생시킨 요소의 nodeName
console.log('[target.nodeName]: ' + e.target.nodeName);
// li 요소 이외의 요소에서 발생한 이벤트는 대응하지 않는다.
if (e.target && e.target.nodeName === 'LI') {
msg.innerHTML = 'li#' + e.target.id + ' was clicked!';
}
});
</script>
</body>
</html>
#9. 기본 동작의 변경
이벤트 객체는 요소의 기본 동작과 요소의 부모 요소들이 이벤트에 대응하는 방법을 변경하기 위한 메소드는 가지고 있다.
#9.1 Event.preventDefault()
폼을 submit하거나 링크를 클릭하면 다른 페이지로 이동하게 된다. 이와 같이 요소가 가지고 있는 기본 동작을 중단시키기 위한 메소드가 preventDefault()이다.
<!DOCTYPE html>
<html>
<body>
<a href="http://www.google.com">go</a>
<script>
document.querySelector('a').addEventListener('click', function (e) {
console.log(e.target, e.target.nodeName);
// a 요소의 기본 동작을 중단한다.
e.preventDefault();
});
</script>
</body>
</html>
#9.2 Event.stopPropagation()
어느 한 요소를 이용하여 이벤트를 처리한 후 이벤트가 부모 요소로 이벤트가 전파되는 것을 중단시키기 위한 메소드이다. 부모 요소에 동일한 이벤트에 대한 다른 핸들러가 지정되어 있을 경우 사용된다.
아래 코드를 보면, 부모 요소와 자식 요소에 모두 mousedown 이벤트에 대한 핸들러가 지정되어 있다. 하지만 부모 요소와 자식 요소의 이벤트를 각각 별도로 처리하기 위해 button 요소의 이벤트의 전파(버블링)를 중단시키기 위해서는 stopPropagation 메소드를 사용하여 이벤트 전파를 중단할 필요가 있다.
<!DOCTYPE html>
<html>
<head>
<style>
html, body { height: 100%;}
</style>
</head>
<body>
<p>버튼을 클릭하면 이벤트 전파를 중단한다. <button>버튼</button></p>
<script>
const body = document.querySelector('body');
const para = document.querySelector('p');
const button = document.querySelector('button');
// 버블링
body.addEventListener('click', function () {
console.log('Handler for body.');
});
// 버블링
para.addEventListener('click', function () {
console.log('Handler for paragraph.');
});
// 버블링
button.addEventListener('click', function (event) {
console.log('Handler for button.');
// 이벤트 전파를 중단한다.
event.stopPropagation();
});
</script>
</body>
</html>
#9.3 preventDefault & stopPropagation
기본 동작의 중단과 버블링 또는 캡처링의 중단을 동시에 실시하는 방법은 아래와 같다.
return false;단 이 방법은 jQuery를 사용할 때와 아래와 같이 사용할 때만 적용된다.
<!DOCTYPE html>
<html>
<body>
<a href="http://www.google.com" onclick='return handleEvent()'>go</a>
<script>
function handleEvent() {
return false;
}
</script>
</body>
</html>
<!DOCTYPE html>
<html>
<body>
<div>
<a href="http://www.google.com">go</a>
</div>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.12.3/jquery.min.js"></script>
<script>
// within jQuery
$('a').click(function (e) {
e.preventDefault(); // OK
});
$('a').click(function () {
return false; // OK --> e.preventDefault() & e.stopPropagation().
});
// pure js
document.querySelector('a').addEventListener('click', function(e) {
// e.preventDefault(); // OK
return false; // NG!!!!!
});
</script>
</body>
</html>
이 방법은 기본 동작의 중단과 이벤트 흐름의 중단 모두 적용되므로 이 두가지 중 하나만 중단하기 원하는 경우는 preventDefault() 또는 stopPropagation() 메소드를 개별적으로 사용한다.
ㅤㅤ
📍 Device Orientation Event : 디바이스의 방향 정보를 다루는 자바스크립트 이벤트
Device Orientation는 HTML5가 제공하는 매우 유용한 기능으로 중력과의 관계에서 디바이스의 물리적 방향의 변화를 감지할 수 있다. 이것을 이용하면 모바일 디바이스를 회전시켰을 때 이벤트를 감지하여 적절히 화면을 변화 시킬 수 있다.
디바이스의 방향 정보를 다루는 자바스크립트 이벤트는 두가지가 있다.
- DeviceOrientationEvent 가속도계(accelerometer)가 기기의 방향의 변화를 감지했을 때 발생한다.
- DeviceMotionEvent 가속도에 변화가 일어났을 때 발생한다
브라우저 별 지원 정보는 caniuse를 참조한다. 현재 사파리를 제외한 대부분의 브라우저에서 사용할 수 있다.
하지만 오래된 브라우저를 사용하는 사용자를 위해 브라우저의 이벤트 지원 여부를 먼저 확인할 필요가 있다.
if (window.DeviceOrientationEvent) {
// Our browser supports DeviceOrientation
} else {
console.log('Sorry, your browser doesn't support Device Orientation');
}
#DeviceOrientationEvent
디바이스의 방향 변화는 3개의 각도( alpha, beta, gamma )를 사용하여 측정된다. deviceorientation 이벤트에 리스너를 등록하면 리스너 함수가 주기적으로 호출되어 업데이트된 방향 데이터를 제공한다. deviceorientation 이벤트는 다음 4가지의 값을 가진다.
window.addEventListener('deviceorientation', handleOrientation, false);
function handleOrientation(event) {
var absolute = event.absolute;
var alpha = event.alpha;
var beta = event.beta;
var gamma = event.gamma;
// Do stuff with the new orientation data
}- DeviceOrientationEvent.absolute
- DeviceOrientationEvent.alpha
- DeviceOrientationEvent.beta
- DeviceOrientationEvent.gamma
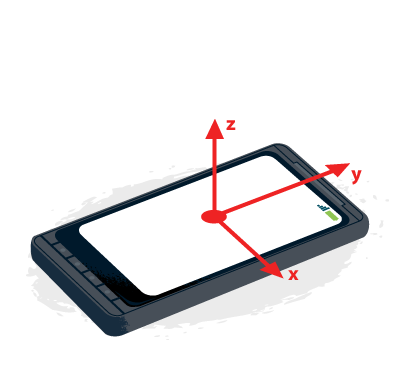
#absolute
지구좌표계(Earth coordinate system)을 사용하는 지에 대한 boolean 값이다. 일반적인 경우 사용하지 않는다.
#alpha
0도부터 360도까지 범위의 z축을 중심으로 디바이스의 움직임을 나타낸다.
#beta
- 180도부터 180도(모바일 사파리: -90도~90도)까지 범위의 x축을 중심으로 디바이스의 움직임을 나타낸다. 이는 디바이스의 앞뒤 움직임을 나타낸다.
#gamma
- 90도부터 90도(모바일 사파리: -180도~180도)까지 범위의 y축을 중심으로 디바이스의 움직임을 나타낸다. 이는 디바이스의 좌우 움직임을 나타낸다.
ㅤㅤ
📍 Ajax : 비동기식 처리 모델과 Ajax
1. Ajax (Asynchronous JavaScript and XML)
브라우저에서 웹페이지를 요청하거나 링크를 클릭하면 화면 갱신이 발생한다. 이것은 브라우저와 서버와의 통신에 의한 것이다.
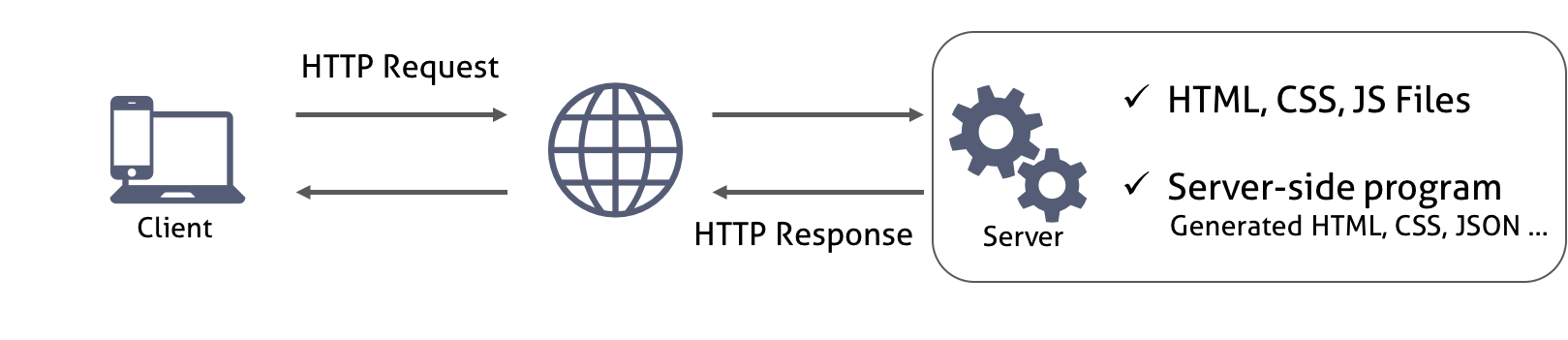
서버는 요청받은 페이지(HTML)를 반환하는데 이때 HTML에서 로드하는 CSS나 JavaScript 파일들도 같이 반환된다. 클라이언트의 요청에 따라 서버는 정적인 파일을 반환할 수도 있고 서버 사이드 프로그램이 만들어낸 파일이나 데이터를 반환할 수도 있다. 서버로부터 웹페이지가 반환되면 클라이언트(브라우저)는 이를 렌더링하여 화면에 표시한다.
Ajax(Asynchronous JavaScript and XML)는 자바스크립트를 이용해서 비동기적(Asynchronous)으로 서버와 브라우저가 데이터를 교환할 수 있는 통신 방식을 의미한다.
서버로부터 웹페이지가 반환되면 화면 전체를 갱신해야 하는데 페이지 일부만을 갱신하고도 동일한 효과를 볼 수 있도록 하는 것이 Ajax이다. 페이지 전체를 로드하여 렌더링할 필요가 없고 갱신이 필요한 일부만 로드하여 갱신하면 되므로 빠른 퍼포먼스와 부드러운 화면 표시 효과를 기대할 수 있다.
#2. JSON (JavaScript Object Notation)
클라이언트와 서버 간에는 데이터 교환이 필요하다. JSON(JavaScript Object Notation)은 클라이언트와 서버 간 데이터 교환을 위한 규칙 즉 데이터 포맷을 말한다.
JSON은 일반 텍스트 포맷보다 효과적인 데이터 구조화가 가능하며 XML 포맷보다 가볍고 사용하기 간편하며 가독성도 좋다.
자바스크립트의 객체 리터럴과 매우 흡사하다. 하지만 JSON은 순수한 텍스트로 구성된 규칙이 있는 데이터 구조이다.
{
"name": "Lee",
"gender": "male",
"age": 20,
"alive": true
}
키는 반드시 큰따옴표(작은따옴표 사용불가)로 둘러싸야 한다.
#2.1 JSON.stringify
JSON.stringify 메소드는 객체를 JSON 형식의 문자열로 변환한다.
const o = { name: 'Lee', gender: 'male', age: 20 };
// 객체 => JSON 형식의 문자열
const strObject = JSON.stringify(o);
console.log(typeof strObject, strObject);
// string {"name":"Lee","gender":"male","age":20}
// 객체 => JSON 형식의 문자열 + prettify
const strPrettyObject = JSON.stringify(o, null, 2);
console.log(typeof strPrettyObject, strPrettyObject);
/*
string {
"name": "Lee",
"gender": "male",
"age": 20
}
*/
// replacer
// 값의 타입이 Number이면 필터링되어 반환되지 않는다.
function filter(key, value) {
// undefined: 반환하지 않음
return typeof value === 'number' ? undefined : value;
}
// 객체 => JSON 형식의 문자열 + replacer + prettify
const strFilteredObject = JSON.stringify(o, filter, 2);
console.log(typeof strFilteredObject, strFilteredObject);
/*
string {
"name": "Lee",
"gender": "male"
}
*/
const arr = [1, 5, 'false'];
// 배열 객체 => 문자열
const strArray = JSON.stringify(arr);
console.log(typeof strArray, strArray); // string [1,5,"false"]
// replacer
// 모든 값을 대문자로 변환된 문자열을 반환한다
function replaceToUpper(key, value) {
return value.toString().toUpperCase();
}
// 배열 객체 => 문자열 + replacer
const strFilteredArray = JSON.stringify(arr, replaceToUpper);
console.log(typeof strFilteredArray, strFilteredArray); // string "1,5,FALSE"#2.2 JSON.parse
JSON.parse 메소드는 JSON 데이터를 가진 문자열을 객체로 변환한다.
서버로부터 브라우저로 전송된 JSON 데이터는 문자열이다. 이 문자열을 객체로서 사용하려면 객체화하여야 하는데 이를 역직렬화(Deserializing)이라 한다. 역직렬화를 위해서 내장 객체 JSON의 static 메소드인 JSON.parse를 사용한다.
const o = { name: 'Lee', gender: 'male', age: 20 };
// 객체 => JSON 형식의 문자열
const strObject = JSON.stringify(o);
console.log(typeof strObject, strObject);
// string {"name":"Lee","gender":"male","age":20}
const arr = [1, 5, 'false'];
// 배열 객체 => 문자열
const strArray = JSON.stringify(arr);
console.log(typeof strArray, strArray); // string [1,5,"false"]
// JSON 형식의 문자열 => 객체
const obj = JSON.parse(strObject);
console.log(typeof obj, obj); // object { name: 'Lee', gender: 'male' }
// 문자열 => 배열 객체
const objArray = JSON.parse(strArray);
console.log(typeof objArray, objArray); // object [1, 5, "false"]배열이 JSON 형식의 문자열로 변환되어 있는 경우 JSON.parse는 문자열을 배열 객체로 변환한다. 배열의 요소가 객체인 경우 배열의 요소까지 객체로 변환한다.
const todos = [
{ id: 1, content: 'HTML', completed: true },
{ id: 2, content: 'CSS', completed: true },
{ id: 3, content: 'JavaScript', completed: false },
];
// 배열 => JSON 형식의 문자열
const str = JSON.stringify(todos);
console.log(typeof str, str);
// JSON 형식의 문자열 => 배열
const parsed = JSON.parse(str);
console.log(typeof parsed, parsed);#3. XMLHttpRequest
브라우저는 XMLHttpRequest 객체를 이용하여 Ajax 요청을 생성하고 전송한다. 서버가 브라우저의 요청에 대해 응답을 반환하면 같은 XMLHttpRequest 객체가 그 결과를 처리한다.
#3.1 Ajax request
다음은 Ajax 요청 처리의 예이다.
// XMLHttpRequest 객체의 생성
const xhr = new XMLHttpRequest();
// 비동기 방식으로 Request를 오픈한다
xhr.open('GET', '/users');
// Request를 전송한다
xhr.send();#3.1.1 XMLHttpRequest.open
XMLHttpRequest 객체의 인스턴스를 생성하고 XMLHttpRequest.open 메소드를 사용하여 서버로의 요청을 준비한다. XMLHttpRequest.open의 사용법은 아래와 같다.
XMLHttpRequest.open(method, url[, async])
| 매개변수 | 설명 |
|---|---|
| method | HTTP method (“GET”, “POST”, “PUT”, “DELETE” 등) |
| url | 요청을 보낼 URL |
| async | 비동기 조작 여부. 옵션으로 default는 true이며 비동기 방식으로 동작한다. |
#3.1.2 XMLHttpRequest.send
XMLHttpRequest.send 메소드로 준비된 요청을 서버에 전달한다.
기본적으로 서버로 전송하는 데이터는 GET, POST 메소드에 따라 그 전송 방식에 차이가 있다.
- GET 메소드의 경우, URL의 일부분인 쿼리문자열(query string)로 데이터를 서버로 전송한다.
- POST 메소드의 경우, 데이터(페이로드)를 Request Body에 담아 전송한다.

Example of a HTTP Request/Response message pair
XMLHttpRequest.send 메소드에는 request body에 담아 전송할 인수를 전달할 수 있다.
xhr.send(null);
// xhr.send('string');
// xhr.send(new Blob()); // 파일 업로드와 같이 바이너리 컨텐트를 보내는 방법
// xhr.send({ form: 'data' });
// xhr.send(document);만약 요청 메소드가 GET인 경우, send 메소드의 인수는 무시되고 request body은 null로 설정된다.
#3.1.3 XMLHttpRequest.setRequestHeader
XMLHttpRequest.setRequestHeader 메소드는 HTTP Request Header의 값을 설정한다. setRequestHeader 메소드는 반드시 XMLHttpRequest.open 메소드 호출 이후에 호출한다.
자주 사용하는 Request Header인 Content-type, Accept에 대해 살펴본다.
Content-type
Content-type은 request body에 담아 전송할 데이터의 MIME-type의 정보를 표현한다. 자주 사용되는 MIME-type은 아래와 같다.
| 타입 | 서브타입 |
|---|---|
| text 타입 | text/plain, text/html, text/css, text/javascript |
| Application 타입 | application/json, application/x-www-form-urlencode |
| File을 업로드하기 위한 타입 | multipart/formed-data |
다음은 request body에 담아 서버로 전송할 데이터의 MIME-type을 지정하는 예이다.
// json으로 전송하는 경우
xhr.open('POST', '/users');
// 클라이언트가 서버로 전송할 데이터의 MIME-type 지정: json
xhr.setRequestHeader('Content-type', 'application/json');
const data = { id: 3, title: 'JavaScript', author: 'Park', price: 5000 };
xhr.send(JSON.stringify(data));// x-www-form-urlencoded으로 전송하는 경우
xhr.open('POST', '/users');
// 클라이언트가 서버로 전송할 데이터의 MIME-type 지정: x-www-form-urlencoded
// application/x-www-form-urlencoded는 key=value&key=value...의 형태로 전송
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
const data = { title: 'JavaScript', author: 'Park', price: 5000 };
xhr.send(
Object.keys(data)
.map((key) => `${key}=${data[key]}`)
.join('&'),
);
// escaping untrusted data
// xhr.send(Object.keys(data).map(key => `${key}=${encodeURIComponent(data[key])}`).join('&'));Accept
HTTP 클라이언트가 서버에 요청할 때 서버가 센드백할 데이터의 MIME-type을 Accept로 지정할 수 있다.
다음은 서버가 센드백할 데이터의 MIME-type을 지정하는 예이다.
// 서버가 센드백할 데이터의 MIME-type 지정: json
xhr.setRequestHeader('Accept', 'application/json');만약 Accept 헤더를 설정하지 않으면, send 메소드가 호출될 때 Accept 헤더가 */*으로 전송된다.
#3.2 Ajax response
다음은 Ajax 응답 처리의 예이다.
// XMLHttpRequest 객체의 생성
const xhr = new XMLHttpRequest();
// XMLHttpRequest.readyState 프로퍼티가 변경(이벤트 발생)될 때마다 onreadystatechange 이벤트 핸들러가 호출된다.
xhr.onreadystatechange = function (e) {
// readyStates는 XMLHttpRequest의 상태(state)를 반환
// readyState: 4 => DONE(서버 응답 완료)
if (xhr.readyState !== XMLHttpRequest.DONE) return;
// status는 response 상태 코드를 반환 : 200 => 정상 응답
if (xhr.status === 200) {
console.log(xhr.responseText);
} else {
console.log('Error!');
}
};XMLHttpRequest.send 메소드를 통해 서버에 Request를 전송하면 서버는 Response를 반환한다. 하지만 언제 Response가 클라이언트에 도달할 지는 알 수 없다. XMLHttpRequest.onreadystatechange는 Response가 클라이언트에 도달하여 발생된 이벤트를 감지하고 콜백 함수를 실행하여 준다. 이때 이벤트는 Request에 어떠한 변화가 발생한 경우 즉 XMLHttpRequest.readyState 프로퍼티가 변경된 경우 발생한다.
// XMLHttpRequest 객체의 생성
var xhr = new XMLHttpRequest();
// 비동기 방식으로 Request를 오픈한다
xhr.open('GET', 'data/test.json');
// Request를 전송한다
xhr.send();
// XMLHttpRequest.readyState 프로퍼티가 변경(이벤트 발생)될 때마다 콜백함수(이벤트 핸들러)를 호출한다.
xhr.onreadystatechange = function (e) {
// 이 함수는 Response가 클라이언트에 도달하면 호출된다.
};XMLHttpRequest 객체는 response가 클라이언트에 도달했는지를 추적할 수 있는 프로퍼티를 제공한다. 이 프로퍼티가 바로 XMLHttpRequest.readyState이다. 만일 XMLHttpRequest.readyState의 값이 4인 경우, 정상적으로 Response가 돌아온 경우이다.
readXMLHttpRequest.readyState의 값은 아래와 같다.
| Value | State | Description |
|---|---|---|
| 0 | UNSENT | XMLHttpRequest.open() 메소드 호출 이전 |
| 1 | OPENED | XMLHttpRequest.open() 메소드 호출 완료 |
| 2 | HEADERS_RECEIVED | XMLHttpRequest.send() 메소드 호출 완료 |
| 3 | LOADING | 서버 응답 중(XMLHttpRequest.responseText 미완성 상태) |
| 4 | DONE | 서버 응답 완료 |
// XMLHttpRequest 객체의 생성
var xhr = new XMLHttpRequest();
// 비동기 방식으로 Request를 오픈한다
xhr.open('GET', 'data/test.json');
// Request를 전송한다
xhr.send();
// XMLHttpRequest.readyState 프로퍼티가 변경(이벤트 발생)될 때마다 콜백함수(이벤트 핸들러)를 호출한다.
xhr.onreadystatechange = function (e) {
// 이 함수는 Response가 클라이언트에 도달하면 호출된다.
// readyStates는 XMLHttpRequest의 상태(state)를 반환
// readyState: 4 => DONE(서버 응답 완료)
if (xhr.readyState !== XMLHttpRequest.DONE) return;
// status는 response 상태 코드를 반환 : 200 => 정상 응답
if (xhr.status === 200) {
console.log(xhr.responseText);
} else {
console.log('Error!');
}
};XMLHttpRequest의.readyState가 4인 경우, 서버 응답이 완료된 상태이므로 이후 XMLHttpRequest.status가 200(정상 응답)임을 확인하고 정상인 경우, XMLHttpRequest.responseText를 취득한다. XMLHttpRequest.responseText에는 서버가 전송한 데이터가 담겨 있다.
만약 서버 응답 완료 상태에만 반응하도록 하려면 readystatechange 이벤트 대신 load 이벤트를 사용해도 된다. load 이벤트는 서버 응답이 완료된 경우에 발생한다.
// XMLHttpRequest 객체의 생성
var xhr = new XMLHttpRequest();
// 비동기 방식으로 Request를 오픈한다
xhr.open('GET', 'data/test.json');
// Request를 전송한다
xhr.send();
// load 이벤트는 서버 응답이 완료된 경우에 발생한다.
xhr.onload = function (e) {
// status는 response 상태 코드를 반환 : 200 => 정상 응답
if (xhr.status === 200) {
console.log(xhr.responseText);
} else {
console.log('Error!');
}
};#4. Web Server
웹서버(Web Server)는 브라우저와 같은 클라이언트로부터 HTTP 요청을 받아들이고 HTML 문서와 같은 웹 페이지를 반환하는 컴퓨터 프로그램이다.
Ajax는 웹서버와의 통신이 필요하므로 예제를 실행하기 위해서는 웹서버가 필요하다.
[Node.js]가 설치되어 있다면 [Express]로 간단한 웹서버를 생성한다.
## 데스크탑에 webserver-express 폴더가 생성된다.
$ cd ~/Desktop
$ git clone https://github.com/ungmo2/webserver-express.git
$ cd webserver-express
## install express
$ npm install
## create public folder
$ mkdir public
webserver-express 디렉터리 내에 있는 public 디렉터리가 루트 디렉터리이다.
웹서버를 실행한다.
## start webserver
$ npm start
http://localhost:3000에 접속하여 Hello World!가 표시되면 웹서버가 정상 동작하는 것이다.
#5. Ajax 예제
#5.1 Load HTML
Ajax를 이용하여 웹페이지에 추가하기 가장 손쉬운 데이터 형식은 HTML이다. 별도의 작업없이 전송받은 데이터를 DOM에 추가하면 된다.
<!-- 루트 폴더(webserver-express/public)/loadhtml.html -->
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<link rel="stylesheet" href="https://poiemaweb.com/assets/css/ajax.css">
</head>
<body>
<div id="content"></div>
<script>
// XMLHttpRequest 객체의 생성
const xhr = new XMLHttpRequest();
// 비동기 방식으로 Request를 오픈한다
xhr.open('GET', 'data/data.html');
// Request를 전송한다
xhr.send();
// Event Handler
xhr.onreadystatechange = function () {
// 서버 응답 완료 && 정상 응답
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status === 200) {
console.log(xhr.responseText);
document.getElementById('content').innerHTML = xhr.responseText;
} else {
console.log(`[${xhr.status}] : ${xhr.statusText}`);
}
};
</script>
</body>
</html>
<!-- 루트 폴더(webserver-express/public)/data/data.html -->
<div id="tours">
<h1>Guided Tours</h1>
<ul>
<li class="usa tour">
<h2>New York, USA</h2>
<span class="details">$1,899 for 7 nights</span>
<button class="book">Book Now</button>
</li>
<li class="europe tour">
<h2>Paris, France</h2>
<span class="details">$2,299 for 7 nights</span>
<button class="book">Book Now</button>
</li>
<li class="asia tour">
<h2>Tokyo, Japan</h2>
<span class="details">$3,799 for 7 nights</span>
<button class="book">Book Now</button>
</li>
</ul>
</div>
http://localhost:3000/loadhtml.html
#5.2 Load JSON
서버로부터 브라우저로 전송된 JSON 데이터는 문자열이다. 이 문자열을 객체화하여야 하는데 이를 역직렬화(Deserializing)이라 한다. 역직렬화를 위해서 내장 객체 JSON의 static 메소드인 JSON.parse()를 사용한다.
<!-- 루트 폴더(webserver-express/public)/loadjson.html -->
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<link rel="stylesheet" href="https://poiemaweb.com/assets/css/ajax.css">
</head>
<body>
<div id="content"></div>
<script>
// XMLHttpRequest 객체의 생성
var xhr = new XMLHttpRequest();
// 비동기 방식으로 Request를 오픈한다
xhr.open('GET', 'data/data.json');
// Request를 전송한다
xhr.send();
xhr.onreadystatechange = function () {
// 서버 응답 완료 && 정상 응답
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status === 200) {
console.log(xhr.responseText);
// Deserializing (String → Object)
responseObject = JSON.parse(xhr.responseText);
// JSON → HTML String
let newContent = '<div id="tours"><h1>Guided Tours</h1><ul>';
responseObject.tours.forEach(tour => {
newContent += `<li class="${tour.region} tour">
<h2>${tour.location}</h2>
<span class="details">${tour.details}</span>
<button class="book">Book Now</button>
</li>`;
});
newContent += '</ul></div>';
document.getElementById('content').innerHTML = newContent;
} else {
console.log(`[${xhr.status}] : ${xhr.statusText}`);
}
};
</script>
</body>
</html>
경로: 루트 폴더(webserver-express/public)/data/data.json
{
"tours": [
{
"region": "usa",
"location": "New York, USA",
"details": "$1,899 for 7 nights"
},
{
"region": "europe",
"location": "Paris, France",
"details": "$2,299 for 7 nights"
},
{
"region": "asia",
"location": "Tokyo, Japan",
"details": "$3,799 for 7 nights"
}
]
}
http://localhost:3000/loadjson.html
#5.3 Load JSONP
요청에 의해 웹페이지가 전달된 서버와 동일한 도메인의 서버로 부터 전달된 데이터는 문제없이 처리할 수 있다. 하지만 보안상의 이유로 다른 도메인(http와 https, 포트가 다르면 다른 도메인으로 간주한다)으로의 요청(크로스 도메인 요청)은 제한된다. 이것을 동일출처원칙(Same-origin policy)이라고 한다.
동일출처원칙(Same-origin policy)
동일출처원칙을 우회하는 방법은 세가지가 있다.
1. 웹서버의 프록시 파일
서버에 원격 서버로부터 데이터를 수집하는 별도의 기능을 추가하는 것이다. 이를 프록시(Proxy)라 한다.
2. JSONP
script 태그의 원본 주소에 대한 제약은 존재하지 않는데 이것을 이용하여 다른 도메인의 서버에서 데이터를 수집하는 방법이다. 자신의 서버에 함수를 정의하고 다른 도메인의 서버에 얻고자 하는 데이터를 인수로 하는 함수 호출문을 로드하는 것이다.
<!-- 루트 폴더(webserver-express/public)/loadjsonp.html -->
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<link rel="stylesheet" href="https://poiemaweb.com/assets/css/ajax.css">
</head>
<body>
<div id="content"></div>
<script>
function showTours(data) {
console.log(data); // data: object
// JSON → HTML String
let newContent = `<div id="tours">
<h1>Guided Tours</h1>
<ul>`;
data.tours.forEach(tour => {
newContent += `<li class="${tour.region} tour">
<h2>${tour.location}</h2>
<span class="details">${tour.details}</span>
<button class="book">Book Now</button>
</li>`;
});
newContent += '</ul></div>';
document.getElementById('content').innerHTML = newContent;
}
</script>
<script src='https://poiemaweb.com/assets/data/data-jsonp.js'></script>
<!-- <script>
showTours({
"tours": [
{
"region": "usa",
"location": "New York, USA",
"details": "$1,899 for 7 nights"
},
{
"region": "europe",
"location": "Paris, France",
"details": "$2,299 for 7 nights"
},
{
"region": "asia",
"location": "Tokyo, Japan",
"details": "$3,799 for 7 nights"
}
]
});
</script> -->
</body>
</html>
// https://poiemaweb.com/assets/data/data-jsonp.js
showTours({
tours: [
{
region: 'usa',
location: 'New York, USA',
details: '$1,899 for 7 nights',
},
{
region: 'europe',
location: 'Paris, France',
details: '$2,299 for 7 nights',
},
{
region: 'asia',
location: 'Tokyo, Japan',
details: '$3,799 for 7 nights',
},
],
});http://localhost:3000/loadjsonp.html
3. Cross-Origin Resource Sharing
HTTP 헤더에 추가적으로 정보를 추가하여 브라우저와 서버가 서로 통신해야 한다는 사실을 알게하는 방법이다. W3C 명세에 포함되어 있지만 최신 브라우저에서만 동작하며 서버에 HTTP 헤더를 설정해 주어야 한다.
Node.js로 구현한 서버의 경우, CORS package를 사용하면 간단하게 Cross-Origin Resource Sharing을 구현할 수 있다.
const express = require('express');
const cors = require('cors');
const app = express();
app.use(cors());
app.get('/products/:id', function (req, res, next) {
res.json({ msg: 'This is CORS-enabled for all origins!' });
});
app.listen(80, function () {
console.log('CORS-enabled web server listening on port 80');
});ㅤㅤ
📍 REST API : REST(Representational State Transfer) API
REST(Representational State Transfer)는 HTTP/1.0과 1.1의 스펙 작성에 참여하였고 아파치 HTTP 서버 프로젝트의 공동설립자인 로이 필딩 (Roy Fielding)의 2000년 논문에서 처음 소개되었다. 발표 당시의 웹이 HTTP의 설계 상 우수성을 제대로 사용하지 못하고 있는 상황을 보고 웹의 장점을 최대한 활용할 수 있는 아키텍쳐로서 REST를 소개하였고 이는 HTTP 프로토콜을 의도에 맞게 디자인하도록 유도하고 있다. REST의 기본 원칙을 성실히 지킨 서비스 디자인을 “RESTful”이라고 표현한다.
#1. REST API 중심 규칙
REST에서 가장 중요한 기본적인 규칙은 두 가지이다. URI는 자원을 표현하는 데에 집중하고 행위에 대한 정의는 HTTP Method를 통해 하는 것이 REST한 API를 설계하는 중심 규칙이다.
1. URI는 정보의 자원을 표현해야 한다.
리소스명은 동사보다는 명사를 사용한다. URI는 자원을 표현하는데 중점을 두어야 한다. get 같은 행위에 대한 표현이 들어가서는 안된다.
# bad
GET /getTodos/1
GET /todos/show/1
# good
GET /todos/1
2. 자원에 대한 행위는 HTTP Method(GET, POST, PUT, DELETE 등)으로 표현한다.
# bad
GET /todos/delete/1
# good
DELETE /todos/1
#2. HTTP Method
주로 5가지의 Method(GET, POST, PUT, PATCH, DELETE)를 사용하여 CRUD를 구현한다.
| Method | Action | 역할 | 페이로드 |
|---|---|---|---|
| GET | index/retrieve | 모든/특정 리소스를 조회 | x |
| POST | create | 리소스를 생성 | ○ |
| PUT | replace | 리소스의 전체를 교체 | ○ |
| PATCH | modify | 리소스의 일부를 수정 | ○ |
| DELETE | delete | 모든/특정 리소스를 삭제 | x |
#3. REST API의 구성
REST API는 자원(Resource), 행위(Verb), 표현(Representations)의 3가지 요소로 구성된다. REST는 자체 표현 구조(Self-descriptiveness)로 구성되어 REST API만으로 요청을 이해할 수 있다.
| 구성 요소 | 내용 | 표현 방법 |
|---|---|---|
| Resource | 자원 | HTTP URI |
| Verb | 자원에 대한 행위 | HTTP Method |
| Representations | 자원에 대한 행위의 내용 | HTTP Message Pay Load |
#4. REST API의 Example
#4.1 json-server
[json-server]를 사용하여 REST API를 사용하여 본다.
$ mkdir rest-api-exam && cd rest-api-exam
$ npm init -y
$ npm install json-server
db.json 파일을 아래와 같이 생성한다.
{
"todos": [
{ "id": 1, "content": "HTML", "completed": false },
{ "id": 2, "content": "CSS", "completed": true },
{ "id": 3, "content": "Javascript", "completed": false }
]
}npm script를 사용하여 json-server를 실행한다. 아래와 같이 package.json을 수정한다.
{
"name": "rest-api-exam",
"version": "1.0.0",
"description": "",
"scripts": {
"start": "json-server --watch db.json --port 5000"
},
"dependencies": {
"json-server": "^0.15.0"
}
}json-server를 실행한다. 포트는 5000을 사용한다.
$ npm start
#4.2 GET
todos 리소스에서 모든 todo를 조회(index)한다.
$ curl -X GET http://localhost:5000/todos
[
{
"id": 1,
"content": "HTML",
"completed": false
},
{
"id": 2,
"content": "CSS",
"completed": true
},
{
"id": 3,
"content": "Javascript",
"completed": false
}
]
const xhr = new XMLHttpRequest();
xhr.open('GET', 'http://localhost:5000/todos');
xhr.send();
xhr.onreadystatechange = function (e) {
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status === 200) {
// 200: OK => https://httpstatuses.com
console.log(xhr.responseText);
} else {
console.log('Error!');
}
};todos 리소스에서 id를 사용하여 특정 todo를 조회(retrieve)한다.
$ curl -X GET http://localhost:5000/todos/1
{
"id": 1,
"content": "HTML",
"completed": false
}
const xhr = new XMLHttpRequest();
xhr.open('GET', 'http://localhost:5000/todos/1');
xhr.send();
xhr.onreadystatechange = function (e) {
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status === 200) {
console.log(xhr.responseText);
} else {
console.log('Error!');
}
};#4.3 POST
todos 리소스에 새로운 todo를 생성한다.
$ curl -X POST http://localhost:5000/todos -H "Content-Type: application/json" -d '{"id": 4, "content": "Angular", "completed": true}'
{
"id": 4,
"content": "Angular",
"completed": true
}
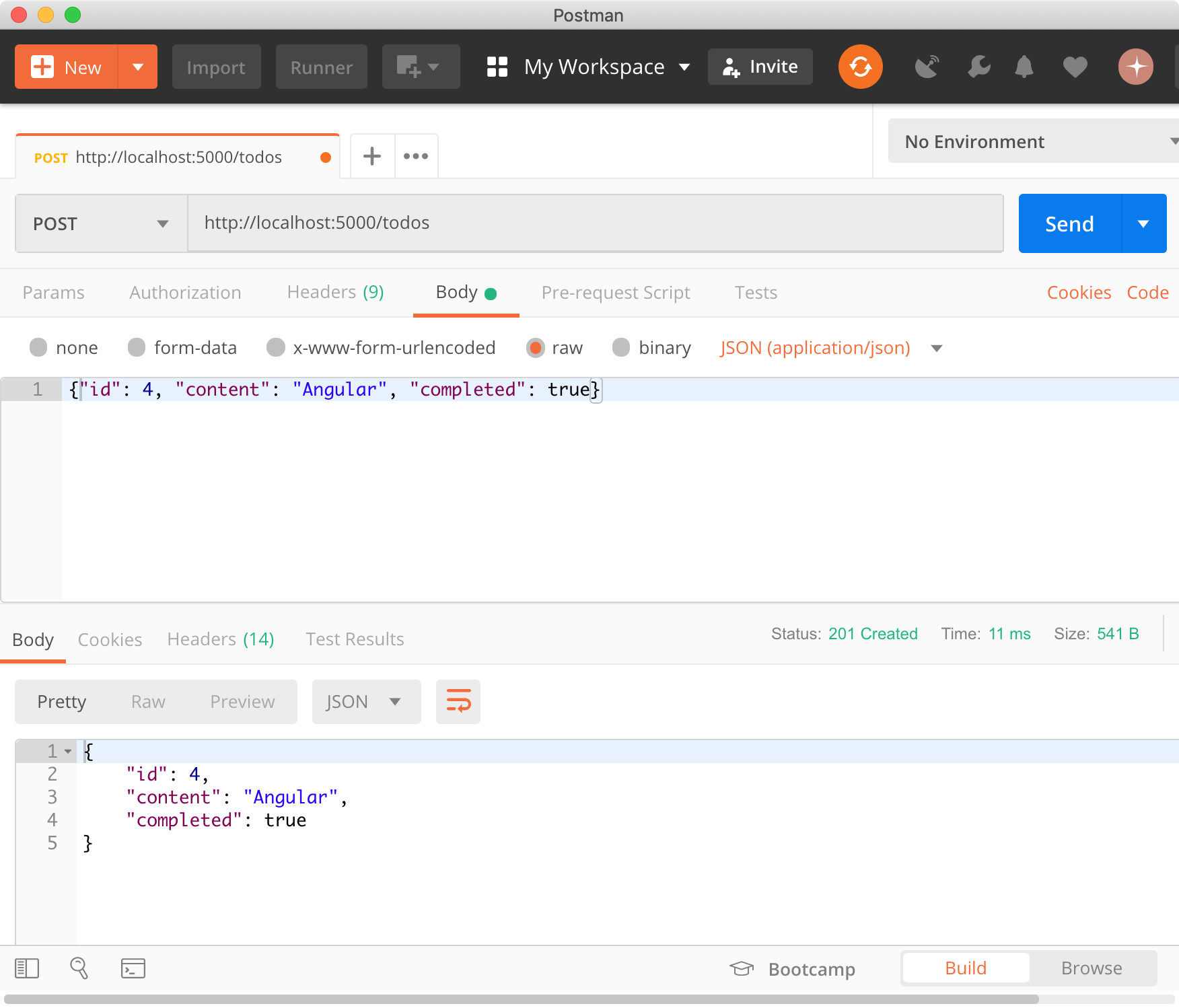
const xhr = new XMLHttpRequest();
xhr.open('POST', 'http://localhost:5000/todos');
xhr.setRequestHeader('Content-type', 'application/json');
xhr.send(JSON.stringify({ id: 4, content: 'Angular', completed: true }));
xhr.onreadystatechange = function (e) {
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status === 201) {
// 201: Created
console.log(xhr.responseText);
} else {
console.log('Error!');
}
};#4.4 PUT
PUT은 특정 리소스의 전체를 갱신할 때 사용한다. todos 리소스에서 id를 사용하여 todo를 특정하여 id를 제외한 리소스 전체를 갱신한다.
$ curl -X PUT http://localhost:5000/todos/4 -H "Content-Type: application/json" -d '{"id": 4, "content": "React", "completed": false}'
{
"content": "React",
"completed": false,
"id": 4
}
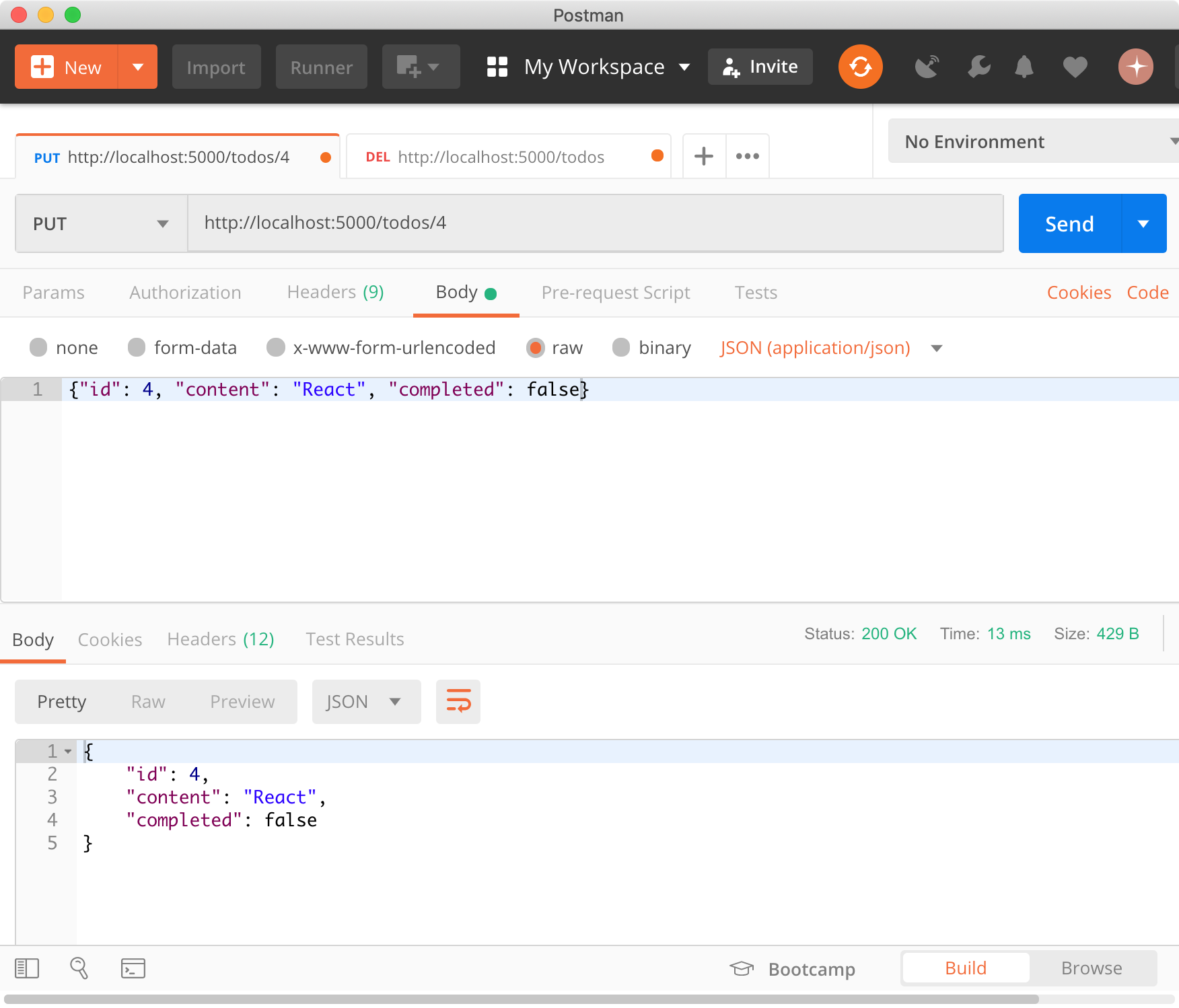
const xhr = new XMLHttpRequest();
xhr.open('PUT', 'http://localhost:5000/todos/4');
xhr.setRequestHeader('Content-type', 'application/json');
xhr.send(JSON.stringify({ id: 4, content: 'React', completed: false }));
xhr.onreadystatechange = function (e) {
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status === 200) {
console.log(xhr.responseText);
} else {
console.log('Error!');
}
};#4.5 PATCH
PATCH는 특정 리소스의 일부를 갱신할 때 사용한다. todos 리소스의 id를 사용하여 todo를 특정하여 completed만을 true로 갱신한다.
$ curl -X PATCH http://localhost:5000/todos/4 -H "Content-Type: application/json" -d '{"completed": true}'
{
"id": 4,
"content": "React",
"completed": true
}
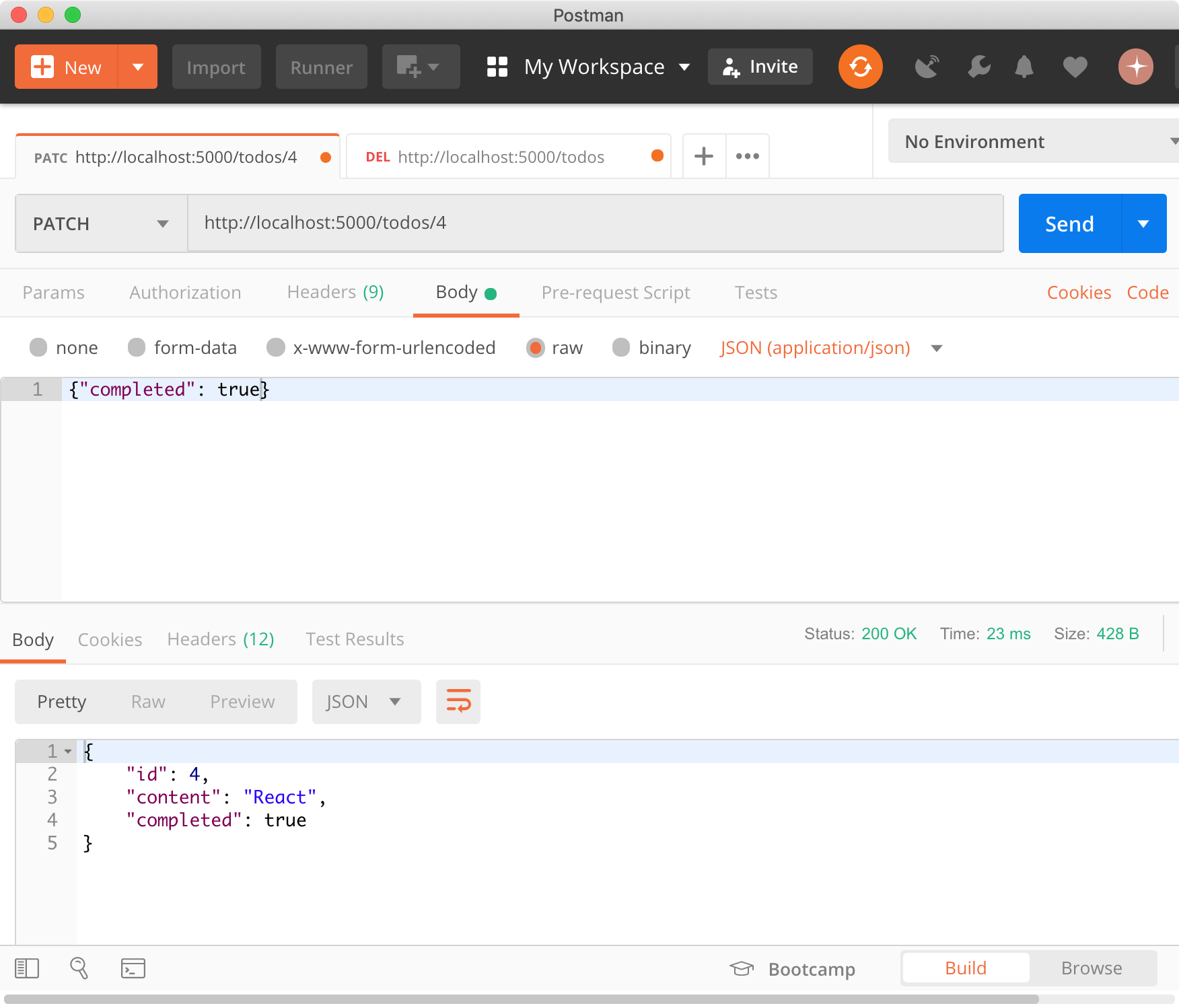
const xhr = new XMLHttpRequest();
xhr.open('PATCH', 'http://localhost:5000/todos/4');
xhr.setRequestHeader('Content-type', 'application/json');
xhr.send(JSON.stringify({ completed: true }));
xhr.onreadystatechange = function (e) {
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status === 200) {
console.log(xhr.responseText);
} else {
console.log('Error!');
}
};#4.6 DELETE
todos 리소스에서 id를 사용하여 todo를 특정하고 삭제한다.
$ curl -X DELETE http://localhost:5000/todos/4
{}
const xhr = new XMLHttpRequest();
xhr.open('DELETE', 'http://localhost:5000/todos/4');
xhr.send();
xhr.onreadystatechange = function (e) {
if (xhr.readyState !== XMLHttpRequest.DONE) return;
if (xhr.status === 200) {
console.log(xhr.responseText);
} else {
console.log('Error!');
}
};ㅤㅤ
📍 SPA & Routing : Single Page Application & Routing
1. SPA (Single Page Application)
단일 페이지 애플리케이션(Single Page Application, SPA)는 모던 웹의 패러다임이다. SPA는 기본적으로 단일 페이지로 구성되며 기존의 서버 사이드 렌더링과 비교할 때, 배포가 간단하며 네이티브 앱과 유사한 사용자 경험을 제공할 수 있다는 장점이 있다.
link tag를 사용하는 전통적인 화면 전환 방식은 새로운 페이지 요청 시마다 정적 리소스가 다운로드되고 전체 페이지를 다시 렌더링하는 방식을 사용하므로 새로고침이 발생되어 사용성이 좋지 않다. 그리고 변경이 필요없는 부분까지 포함하여 전체 페이지를 갱신하므로 비효율적이다.
SPA는 기본적으로 웹 애플리케이션에 필요한 모든 정적 리소스를 최초 접근시 단 한번만 다운로드한다. 이후 새로운 페이지 요청 시, 페이지 갱신에 필요한 데이터만을 JSON으로 전달받아 페이지를 갱신하므로 전체적인 트래픽을 감소시킬 수 있고, 전체 페이지를 다시 렌더링하지 않고 변경되는 부분만을 갱신하므로 새로고침이 발생하지 않아 네이티브 앱과 유사한 사용자 경험을 제공할 수 있다.
모바일 사용이 데스크톱을 넘어선 현재, 트래픽의 감소와 속도, 사용성, 반응성의 향상은 매우 중요한 이슈이다. SPA의 핵심 가치는 사용자 경험(UX) 향상에 있으며 부가적으로 애플리케이션 속도의 향상도 기대할 수 있어서 모바일 퍼스트(Mobile First) 전략에 부합한다.
모든 소프트웨어 아키텍처에는 트레이드오프(trade-off)가 존재하며 모든 애플리케이션에 적합한 은탄환(Silver bullet)은 없듯이 SPA 또한 구조적인 단점을 가지고 있다. 대표적인 단점은 다음과 같다.
초기 구동 속도
SPA는 웹 애플리케이션에 필요한 모든 정적 리소스를 최초 접근시 단 한번 다운로드하기 때문에 초기 구동 속도가 상대적으로 느리다. 하지만 SPA는 웹페이지보다는 애플리케이션에 적합한 기술이므로 트래픽 감소와 속도, 사용성, 반응성의 향상 등의 장점을 생각한다면 결정적인 단점이라고 할 수는 없다.
SEO(검색엔진 최적화) 이슈
SPA는 일반적으로 서버 사이드 렌더링(SSR) 방식이 아닌 자바스크립트 기반 비동기 모델의 클라이언트 사이드 렌더링(CSR) 방식으로 동작한다. 클라이언트 사이드 렌더링(CSR)은 일반적으로 데이터 패치 요청을 통해 서버로부터 데이터를 응답받아 뷰를 동적으로 생성하는데 이때 브라우저 주소창의 URL이 변경되지 않는다. 이는 사용자 방문 history를 관리할 수 없음을 의미하며 SEO 이슈의 발생 원인이기도 하다. SPA의 SEO 이슈는 언제나 단점으로 부각되어 왔다. SPA는 정보 제공을 위한 웹페이지보다는 애플리케이션에 적합한 기술이므로 SEO 이슈는 심각한 문제로 취급할 수 없다고 생각할 수도 있지만 블로그와 같이 애플리케이션의 경우 SEO는 무시할 수 없는 중요한 의미를 갖는다. Angular나 React 등의 SPA 프레임워크는 서버 사이드 렌더링(SSR)을 지원하는 기능이 이미 존재하고 있고 크롬 등의 모던 브라우저는 SPA의 SEO 문제를 해결하고 있는 것으로 알려져 있다.
#2. Routing
라우팅이란 출발지에서 목적지까지의 경로를 결정하는 기능이다. 애플리케이션의 라우팅은 사용자가 태스크를 수행하기 위해 어떤 화면(view)에서 다른 화면으로 화면을 전환하는 내비게이션을 관리하기 위한 기능을 의미한다. 일반적으로 라우팅은 사용자가 요청한 URL 또는 이벤트를 해석하고 새로운 페이지로 전환하기 위해 필요한 데이터를 서버에 요청하고 페이지를 전환하는 위한 일련의 행위를 말한다.
브라우저가 화면을 전환하는 경우는 다음과 같다.
- 브라우저의 주소창에 URL을 입력하면 해당 페이지로 이동한다.
- 웹페이지의 링크(a 태그)를 클릭하면 해당 페이지로 이동한다.
- 브라우저의 뒤로가기 또는 앞으로가기 버튼을 클릭하면 사용자 방문 기록(history)의 뒤 또는 앞으로 이동한다. history 관리를 위해서는 각 페이지는 브라우저의 주소창에서 구별할 수 있는 유일한 URL을 소유해야 한다.
#3. SPA와 Routing
전통적인 링크 방식에서 SPA까지 발전하게 된 과정과 SPA의 라우팅(Routing)에 대해 살펴보도록 한다. 예제를 실행하기 위해 과정은 다음과 같다.
github에서 소스코드를 clone한다.
$ git clone https://github.com/ungmo2/spa-router.git
$ cd spa-router
$ npm install
예제의 실행 방법은 다음과 같다.
# 전통적 링크 방식
$ npm run link
# ajax 방식
$ npm run ajax
# hash 방식
$ npm run hash
# pjax(pushState + ajax) 방식
$ npm run pjax
#3.1. 전통적 링크 방식
전통적 링크 방식은 link tag로 동작하는 기본적인 웹페이지의 동작 방식이다.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>SPA-Router - Link</title>
<link rel="stylesheet" href="css/style.css" />
</head>
<body>
<nav>
<ul>
<li><a href="/">Home</a></li>
<li><a href="/service.html">Service</a></li>
<li><a href="/about.html">About</a></li>
</ul>
</nav>
<section>
<h1>Home</h1>
<p>This is main page</p>
</section>
</body>
</html>
link tag(<a href="/service.html">Service</a> 등)을 클릭하면 href 어트리뷰트 값인 리소스 경로가 URL의 path에 추가되어 주소창에 나타나고 해당 리소스를 서버에 요청한다.
이때 서버는 html로 화면을 표시하는데 부족함이 없는 완전한 리소스를 클라이언트에 응답한다. 이를 서버 사이드 렌더링(SSR)이라 한다. 브라우저는 서버가 응답한 html을 응답받아 렌더링한다. 이때 응답받은 html로 전체 페이지를 다시 렌더링하게 되므로 새로고침이 발생한다.
이 방식은 자바스크립트의 도움 없이 응답받은 html만으로 렌더링이 가능하며 각 페이지마다 고유의 URL이 존재하므로 history 관리 및 SEO 대응에 아무런 문제가 없다. 하지만 요청마다 중복된 리소스를 응답받아야 하며 전체 페이지를 다시 렌더링하는 과정에서 새로고침이 발생하여 사용성이 좋지 않은 단점이 있다.
위 예제를 실행하려면 다음 명령을 실행한다.
$ npm run link
#3.2. ajax 방식
전통적 링크 방식은 현재 페이지에서 수신된 html로 화면을 전환하는 과정에서 전체 페이지를 새롭게 렌더링하게 되므로 새로고침이 발생한다. 간단한 웹페이지라면 문제될 것이 없겠지만 복잡한 웹페이지의 경우, 요청마다 중복된 HTML과 CSS, JavaScript를 매번 다운로드해야하므로 속도 저하의 요인이 된다.
전통적 링크 방식의 단점을 보완하기 위해 등장한 것이 ajax(Asynchronous JavaScript and XML)이다. ajax는 자바스크립트를 이용해서 비동기적(asynchronous)으로 서버와 브라우저가 데이터를 교환할 수 있는 통신 방식을 의미한다.
서버로부터 웹페이지가 응답되면 화면 전체를 새롭게 렌더링해야 하는데 페이지 일부만 갱신하고도 동일한 효과를 볼 수 있도록 하는 것이 ajax이다.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>SPA-Router - ajax</title>
<link rel="stylesheet" href="css/style.css" />
<script type="module" src="js/index.js"></script>
</head>
<body>
<nav>
<ul id="navigation">
<li><a href="/">Home</a></li>
<li><a href="/service">Service</a></li>
<li><a href="/about">About</a></li>
</ul>
</nav>
<div id="root">Loading...</div>
</body>
</html>
위 예제를 살펴보면 link tag(<a href="/service">Service</a> 등)의 href 어트리뷰트에 path를 사용하고 있다. 따라서 내비게이션이 클릭되면 path가 추가된 URL이 서버로 요청된다. 하지만 ajax 방식은 내비게이션 클릭 이벤트를 캐치하고 preventDefault 메서드를 사용해 서버로의 요청을 방지한다. 이후, href 어트리뷰트에 path을 사용하여 ajax 요청을 하는 방식이다.
그리고 div.#root 요소에 웹페이지의 내용이 비어있는 것을 알 수 있다. 요청된 리소스(html, json 등)가 응답되면 클라이언트에서 div#root 요소에 응답받은 데이터를 기반으로 html을 생성해 추가한다.
이를 통해 불필요한 리소스의 중복 요청을 방지할 수 있다. 또한 페이지 전체를 리렌더링할 필요없이 갱신이 필요한 일부만 갱신하면 되므로 빠른 퍼포먼스와 부드러운 화면 표시 효과를 기대할 수 있어 새로고침이 없는 보다 향상된 사용자 경험을 구현할 수 있다는 장점이 있다.
JavaScript의 구현은 다음과 같다.
// index.js
import { Home, Service, About, NotFound } from './components.js';
const $root = document.getElementById('root');
const $navigation = document.getElementById('navigation');
const routes = [
{ path: '/', component: Home },
{ path: '/service', component: Service },
{ path: '/about', component: About },
];
const render = async (path) => {
try {
const component = routes.find((route) => route.path === path)?.component || NotFound;
$root.replaceChildren(await component());
} catch (err) {
console.error(err);
}
};
// TODO: ajax 요청은 주소창의 url을 변경시키지 않으므로 history 관리가 되지 않는다.
$navigation.onclick = (e) => {
if (!e.target.matches('#navigation > li > a')) return;
e.preventDefault();
const path = e.target.getAttribute('href');
render(path);
};
// TODO: 주소창의 url이 변경되지 않기 때문에 새로고침 시 현재 렌더링된 페이지가 아닌 루트 페이지가 요청된다.
window.addEventListener('DOMContentLoaded', () => render('/'));// components.js
const createElement = (domString) => {
const $temp = document.createElement('template');
$temp.innerHTML = domString;
return $temp.content;
};
const fetchData = async (url) => {
const res = await fetch(url);
const json = await res.json();
return json;
};
export const Home = async () => {
const { title, content } = await fetchData('/api/home');
return createElement(`<h1>${title}</h1><p>${content}</p>`);
};
export const Service = async () => {
const { title, content } = await fetchData('/api/service');
return createElement(`<h1>${title}</h1><p>${content}</p>`);
};
export const About = async () => {
const { title, content } = await fetchData('/api/about');
return createElement(`<h1>${title}</h1><p>${content}</p>`);
};
export const NotFound = () => createElement('<h1>404 NotFound</p>');ajax 요청은 주소창의 URL을 변경시키지 않는다. 이는 브라우저의 뒤로가기, 앞으로가기 등의 history 관리가 동작하지 않음을 의미한다. 따라서 history.back(), history.go(n) 등도 동작하지 않는다. 주소창의 URL이 변경되지 않기 때문에 새로고침을 해도 언제나 첫페이지가 다시 로딩된다. 동일한 하나의 URL로 동작하는 ajax 방식은 SEO 이슈에서도 자유로울 수 없다.
위 예제를 실행하려면 다음 명령을 실행한다.
$ npm run ajax
#3.3 Hash 방식
ajax 방식은 불필요한 리소스 중복 요청을 방지할 수 있고 새로고침이 없는 사용자 경험을 구현할 수 있다는 장점이 있지만 history 관리가 되지 않는 단점이 있다. 이를 보완한 방법이 Hash 방식이다.
Hash 방식은 URI의 fragment identifier(#service)의 고유 기능인 앵커(anchor)를 사용한다. fragment identifier는 hash mark 또는 hash라고 부르기도 한다.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>SPA-Router - Hash</title>
<link rel="stylesheet" href="css/style.css" />
<script type="module" src="js/index.js"></script>
</head>
<body>
<nav>
<ul>
<li><a href="#">Home</a></li>
<li><a href="#service">Service</a></li>
<li><a href="#about">About</a></li>
</ul>
</nav>
<div id="root">Loading...</div>
</body>
</html>
위 예제를 살펴보면 link tag(<a href="#service">Service</a> 등)의 href 어트리뷰트에 hash를 사용하고 있다. 즉, 내비게이션이 클릭되면 hash가 추가된 URI가 주소창에 표시된다. 단, URL이 동일한 상태에서 hash만 변경되면 브라우저는 서버에 어떠한 요청도 하지 않는다. 즉, URL의 hash는 변경되어도 서버에 새로운 요청을 보내지 않으며 따라서 페이지가 갱신되지 않는다. hash는 요청을 위한 것이 아니라 fragment identifier(#service)의 고유 기능인 앵커(anchor)로 웹페이지 내부에서 이동을 위한 것이기 때문이다.
또한 hash 방식은 서버에 새로운 요청을 보내지 않으며 따라서 페이지가 갱신되지 않지만 페이지마다 고유의 논리적 URL이 존재하므로 history 관리에 아무런 문제가 없다.
JavaScript의 구현은 다음과 같다.
// index.js
// components.js는 위와 동일하다.
import { Home, Service, About, NotFound } from './components.js';
const $root = document.getElementById('root');
const routes = [
{ path: '', component: Home },
{ path: 'service', component: Service },
{ path: 'about', component: About },
];
const render = async () => {
try {
// url의 hash를 취득
const hash = window.location.hash.replace('#', '');
const component = routes.find((route) => route.path === hash)?.component || NotFound;
$root.replaceChildren(await component());
} catch (err) {
console.error(err);
}
};
// 네비게이션을 클릭하면 url의 hash가 변경되기 때문에 history 관리가 가능하다.
// 단, url의 hash만 변경되면 서버로 요청은 수행하지 않는다.
// url의 hash가 변경하면 발생하는 이벤트인 hashchange 이벤트를 사용하여 hash의 변경을 감지하여 필요한 ajax 요청을 수행한다.
// hash 방식의 단점은 url에 /#foo와 같은 해시뱅(HashBang)이 들어간다는 것이다.
window.addEventListener('hashchange', render);
// 새로고침을 하면 DOMContentLoaded 이벤트가 발생하고
// render 함수는 url의 hash를 취득해 새로고침 직전에 렌더링되었던 페이지를 다시 렌더링한다.
window.addEventListener('DOMContentLoaded', render);hash 방식은 url의 hash가 변경하면 발생하는 이벤트인 hashchange 이벤트를 사용해 hash의 변경을 감지하고 url의 hash를 취득해 필요한 ajax 요청을 수행한다.
hash 방식의 단점은 url에 불필요한 #이 들어간다는 것이다. 일반적으로 hash 방식을 사용할 때 #!을 사용하기도 하는데 이를 해시뱅(Hash-bang)이라고 부른다.
hash 방식은 과도기적 기술이다. HTML5의 History API인 pushState가 모든 브라우저에서 지원이 된다면 해시뱅은 사용하지 않아도 되지만 현재 pushState는 일부의 브라우저(IE 10 이상)에서만 지원이 가능하다.
또 다른 문제는 SEO 이슈이다. 웹 크롤러는 검색 엔진이 웹사이트의 콘텐츠를 수집하기 위해 HTTP와 URL 스펙(RFC-2396같은)을 따른다. 이러한 크롤러는 JavaScript를 실행시키지 않기 때문에 hash 방식으로 만들어진 사이트의 콘텐츠를 수집할 수 없다. 구글은 해시뱅을 일반적인 URL로 변경시켜 이 문제를 해결한 것으로 알려져 있지만 다른 검색 엔진은 hash 방식으로 만들어진 사이트의 콘텐츠를 수집할 수 없을 수도 있다.
위 예제를 실행하려면 다음 명령을 실행한다.
$ npm run hash
#3.4 pjax 방식
hash 방식의 가장 큰 단점은 SEO 이슈이다. 이를 보완한 방법이 HTML5의 History API인 pushState와 popstate 이벤트를 사용한 pjax(pushState + ajax) 방식이다.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>SPA-Router - pjax</title>
<link rel="stylesheet" href="css/style.css" />
<script defer src="js/index.js"></script>
</head>
<body>
<nav>
<ul id="navigation">
<li><a href="/">Home</a></li>
<li><a href="/service">Service</a></li>
<li><a href="/about">About</a></li>
</ul>
</nav>
<div id="root">Loading...</div>
</body>
</html>
위 예제를 살펴보면 link tag(<a href="/service">Service</a> 등)의 href 어트리뷰트에 path를 사용하고 있다. 따라서 내비게이션이 클릭되면 path가 추가된 URL이 서버로 요청된다. 하지만 pjax 방식은 내비게이션 클릭 이벤트를 캐치하고 preventDefault 메서드를 사용해 서버로의 요청을 방지한다. 이후, href 어트리뷰트에 path을 사용하여 ajax 요청을 하는 방식이다.
이때 ajax 요청은 브라우저 주소창의 URL을 변경시키지 않아 history 관리가 불가능하다. 이때 사용하는 것이 pushState 메서드이다. pushState 메서드는 주소창의 URL을 변경하고 URL을 history entry로 추가하지만 서버로 HTTP 요청을 하지는 않는다.
JavaScript의 구현은 다음과 같다.
// index.js
// components.js는 위와 동일하다.
import { Home, Service, About, NotFound } from './components.js';
const $root = document.getElementById('root');
const $navigation = document.getElementById('navigation');
const routes = [
{ path: '/', component: Home },
{ path: '/service', component: Service },
{ path: '/about', component: About },
];
// TODO: path를 상태로 관리
const render = async (path) => {
// $navigation의 a 요소를 클릭하면 path(a 요소의 href)가 전달된다.
// 하지만 웹페이지가 처음 로딩되거나 앞으로/뒤로 가기 버튼을 클릭하면 path를 전달하지 않는다.
// 이때 window.location.pathname를 키로 routes에서 컴포넌트를 결정해 뷰를 전환한다.
const _path = path ?? window.location.pathname;
try {
const component = routes.find((route) => route.path === _path)?.component || NotFound;
$root.replaceChildren(await component());
} catch (err) {
console.error(err);
}
};
$navigation.addEventListener('click', (e) => {
if (!e.target.matches('#navigation > li > a')) return;
/**
* 네비게이션을 클릭하면 주소창의 url이 변경되므로 HTTP 요청이 서버로 전송된다.
* preventDefault를 사용하여 이를 방지하고 history 관리를 위한 처리를 실행한다.
*/
e.preventDefault();
// 이동할 페이지의 path
const path = e.target.getAttribute('href');
// 현재 페이지와 이동할 페이지가 같으면 이동하지 않는다.
if (window.location.pathname === path) return;
// pushState는 주소창의 url을 변경하지만 HTTP 요청을 서버로 전송하지는 않는다.
window.history.pushState(null, null, path);
render(path);
});
/**
* pjax 방식은 hash를 사용하지 않으므로 hashchange 이벤트를 사용할 수 없다.
* popstate 이벤트는 pushState에 의해 발생하지 않고 앞으로/뒤로 가기 버튼을 클릭하거나
* history.forward/back/go(n)에 의해 history entry가 변경되면 발생한다.
* 앞으로/뒤로 가기 버튼을 클릭하면 window.location.pathname를 참조해 뷰를 전환한다.
*/
window.addEventListener('popstate', () => {
console.log('[popstate]', window.location.pathname);
render();
});
/**
* 웹페이지가 처음 로딩되면 window.location.pathname를 확인해 페이지를 이동시킨다.
* 새로고침을 클릭하면 현 페이지(예를 들어 localhost:5004/service)가 서버에 요청된다.
* 이에 응답하는 처리는 서버에서 구현해야 한다.
*/
window.addEventListener('DOMContentLoaded', () => {
render();
});pjax 방식에서 사용하는 history.pushState 메서드는 주소창의 url을 변경하지만 HTTP 요청을 서버로 전송하지는 않는다. 따라서 페이지가 갱신되지 않는다. 하지만 페이지마다 고유의 URL이 존재하므로 history 관리에 아무런 문제가 없다. 또한 hash를 사용하지 않으므로 SEO에도 문제가 없다.
단, 브라우저의 새로고침 버튼을 클릭하면 브라우저 주소창의 url이 변경되지 않는 ajax 방식과 해시(fragment identifier)만 추가되는 hash 방식은 서버에 별도의 요청을 보내지 않지만 pjax 방식은 브라우저 주소창의 url이 변경되기 때문에 요청(예를 들어 localhost:5004/service)이 서버로 전달된다. 즉, pjax 방식은 서버 렌더링 방식과 ajax 방식이 혼재되어 있는 방식으로 서버의 지원이 필요하다. 이에 대한 서버 구현은 다음과 같다.
const express = require('express');
const path = require('path');
const app = express();
const port = 5004;
app.use(express.static(path.join(__dirname, 'public')));
app.get('/api/:page', (req, res) => {
const { page } = req.params;
res.sendFile(path.join(__dirname, `/data/${page}.json`));
});
// 브라우저 새로고침을 위한 처리 (다른 route가 존재하는 경우 맨 아래에 위치해야 한다)
// 브라우저 새로고침 시 서버는 index.html을 전달하고 클라이언트는 window.location.pathname를 참조해 다시 라우팅한다.
app.get('*', (req, res) => {
res.sendFile(path.join(__dirname, 'public/index.html'));
});
app.listen(port, () => {
console.log(`Server listening on http:/localhost:${port}`);
});pjax 방식의 예제를 실행하려면 다음 명령을 실행한다.
$ npm run pjax
#4. Conclusion
전통적 링크 방식에서 pjax 방식까지 SPA의 발전 과정을 살펴보았다. 지금까지 살펴본 4가지 방식을 History 관리, SEO 대응, 사용자 경험 등의 관점에서 정리하면 다음과 같다.
| 구분 | History 관리 | SEO 대응 | 사용자 경험 | 서버 렌더링 | 구현 난이도 | IE 대응 |
|---|---|---|---|---|---|---|
| 전통적 링크 방식 | ◯ | ◯ | ✗ | ◯ | 간단 | |
| ajax 방식 | ✗ | ✗ | ◯ | ✗ | 보통 | 7 이상 |
| hash 방식 | ◯ | ✗ | ◯ | ✗ | 보통 | 8 이상 |
| pjax 방식 | ◯ | ◯ | ◯ | △ | 복잡 | 10 이상 |
모든 소프트웨어 아키텍처에는 트레이드오프(trade-off)가 존재한다. SPA 또한 모든 애플리케이션에 적합한 은탄환(Silver bullet)은 아니다. 애플리케이션의 상황을 고려하여 적절한 방법을 선택할 필요가 있다.
본 포스트는 [웹 프로그래밍 튜토리얼 PoiemaWeb의 JavaScript] 를 정독하며 정리한 글입니다.
