신경망 학습
퍼셉트론에서, 우리는 가중치 값을 직접 설정해주었다. 하지만 신경망 학습을 통해 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득할 수 있다. 신경망이 학습할 수 있도록 해주는 손실 함수(loss function)에 대해 알아보겠다.
손실 함수가 최솟값을 갖도록 하는 가중치 매개변수를 찾는 것이 바로 학습의 목표이다. 그 방법으로는 경사 하강법이 있다.
✔오버피팅(Overfitting)
과적합이라고도 부르며, 특정 데이터셋에 지나치게 최적화 된 상태를 말한다. 너무 training set만 최적화 되어버린 경우, test 데이터를 입력했을 때 좋지 않은 결과를 얻을 수 있다. 따라서 오버피팅을 피하고 보편적인 결과를 얻도록 학습하는 것이 중요하다.
📌손실함수(loss function)
신경망이 최적의 매개변수 값을 찾아가기 위한 지표라고 할 수 있다. 주로 평균제곱오차(MSE)와 교차 엔트로피 오차를 사용한다.
평균 제곱 오차(MSE : Mean Square Error)
가장 많이 쓰이는 손실 함수.
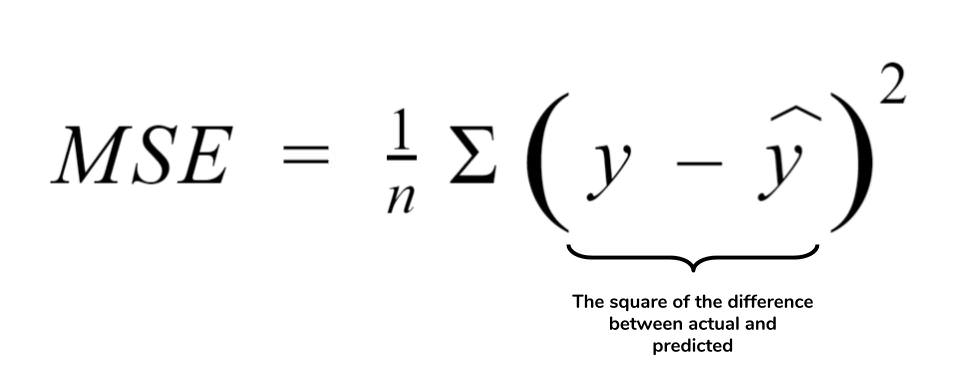
나는 평균 제곱 오차라는 말이 별로 와닿지가 않아 오차 제곱의 평균이라고 생각했더니 쉽게 다가왔다. 이렇게 하면 말 그대로 예상값과 실제값의 차이인 오차를 제곱하여 평균값을 낸 것이라고 생각할 수 있다. 제곱을 하는 이유는 오차가 음수일 수도, 양수일 수도 있기 때문에 오차값이 상쇄될 수 있기 때문이다. 따라서 상쇄되지 않도록 제곱하여 평균을 내준다.
✔원-핫-인코딩(one-hot-encoding)
정답 레이블을 나타내는 원소를 1로 표시하고, 나머지는 0으로 표시하는 방식.
예를 들어 레이블을 [0 : 사과, 1 : 바나나, 2 : 귤 ] 로 설정한 경우, 사과는 [1, 0, 0], 바나나는 [0, 1, 0], 귤은 [0, 0, 1]이 된다.
교차 엔트로피 오차(CEE : Cross Entropy Error)

미니배치 학습(Miny-batch)
train 데이터 중 일부만 무작위로 선택하여 학습하는 방법. 훈련 데이터의 수가 너무 많은 경우, 데이터의 일부를 뽑아 전체 데이터를 대표하게 하는 것이다.
데이터를 무작위로 뽑으려면 넘파이의 random.choice() 함수를 이용한다. 100개의 데이터를 무작위로 추출하는 코드이다.
train_size = x_train.shape[0]
batch_size = 100
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]학습을 함에 있어서 데이터를 무작위로 뽑아내는 것이 중요하다. 확률에서의 표본조사와 유사하게, 표본 데이터는 전체 데이터를 대표할 수 있어야 하며 한쪽에만 편향되어 있다면 잘못된 결과를 얻기 쉽기 때문이다.
📌경사하강법(Gradient descent)
경사하강법에서는 기울기를 기준으로 나아갈 방향을 정한다.
Linear Regression에서, 우리는 training 데이터를 대표할 수 있는 그래프를 찾아야 한다. 이 그래프를 찾을 때 함수의 매개변수를 구하게 되는데, 최적의 매개변수를 찾기 위한 방법 중 많이 사용되는 것이 경사하강법이다.
어떤 매개변수가 최적인가? 그것을 판단하는 것이 바로 손실함수이고 손실, 즉 오차가 가장 적을 때 최적이라고 할 수 있다.
손실함수 값이 최소가 되는 지점은 기울기가 0이 되는 지점이고, 기울기가 0이 되는 지점을 찾기 위해 손실함수의 기울기를 점점 줄여나가는 것이 경사하강법이다.
이를 수식으로 나타내면,
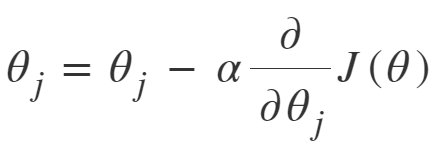
알파는 학습률(learning rate)을 나타낸다. 한번에 얼마만큼 학습할지를 정하는 값이다. 그래프에서 얼마나 이동할지 혹은 매개변수 값을 얼마나 증가/감소할 지 정한다고 생각하면 된다.
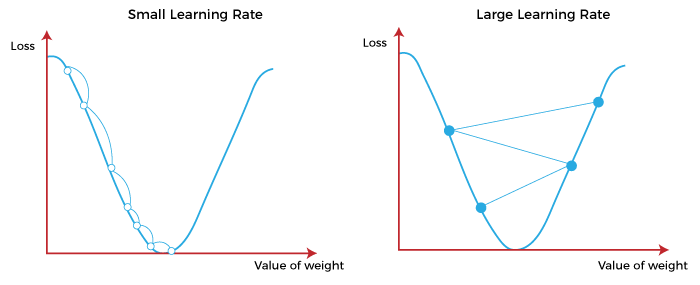
학습률은 개발자가 정하는 것으로, 너무 크거나 작아도 좋지 않다. 너무 크다면 그래프 상에서 너무 많이 이동하므로 원하는 값에서 크게 벗어날 수 있고, 너무 작다면 학습에 오래 걸린다.
✔에포크(epoch)
1 에포크는 학습에서 훈련 데이터를 모두 사용했을 때의 횟수이다. 예를 들어 100000개의 훈련 데이터를 100개의 미니배치로 학습할 경우, 경사 하강법을 1000회 반복하면 훈련 데이터를 모두 소진한 것으로 생각할 수 있다. 이 때, 1000회가 1에포크가 된다.
✔하이퍼파라미터(hyper parameter)
사람이 직접 설정하는 매개변수. 여러 후보 값을 넣어가며 테스트를 통해 최적의 값을 선택한다. 가중치나 편향같이 학습을 통해 자동으로 얻어지는 매개변수와는 다르다.
📌신경망 학습 알고리즘 구현 - 확률적 경사 하강법 (SGD : Stochastic Gradient Descent)
신경망에서 구해야하는 가중치와 편향을 train data를 통해 훈련시켜 조정하는 과정을 학습이라고 한다.
학습의 과정은 다음과 같다.
👉미니배치 학습을 위해 train data 중 일부 값을 랜덤하게 가져온다.
손실함수 값을 줄이기 위해 가중치 매개변수의 기울기를 계산한다.
가중치 매개변수를 기울기 방향으로 갱신한다.
갱신 정도는 학습률이 결정한다.Linear Regression 공부를 하면서 이미 포스팅을 한 줄 알았으나 포스팅하지 않은 것을 지금 알게 되었다. Linear regression에서 경사하강법을 다루고 있으므로 따로 포스팅하는 것이 도움이 될 것 같다. 가능한 한 logistic regression을 올리기 전에 빨리 써두고 싶은데 가능할지 모르겠다.
