1. 논문의 핵심 아이디어
이 논문은 대규모 언어 모델(LLM, Large Language Model)과 협업 필터링(CF, Collaborative Filtering)을 결합한 새로운 추천 시스템 A-LLMRec를 소개합니다. 추천 시스템은 우리가 흔히 사용하는 스트리밍 서비스(예: 넷플릭스)나 전자상거래 플랫폼(예: 아마존)에서 어떤 콘텐츠나 상품을 사용자에게 보여줄지 결정하는 중요한 기술입니다. A-LLMRec은 LLM에 넣을 프롬프트에 협업 필터링 정보를 반영하여 기존 시스템의 약점인 "cold start 문제"를 해결하면서도, 기존 데이터가 많은 "warm scenario"에서도 우수한 성능을 보이도록 설계되었습니다.
- Cold start problem: 서비스 초기에 데이터가 부족한 현상
- Warm scenario: 데이터가 충분한 상황
2. A-LLMRec의 구조와 작동 방식
A-LLMRec는 두 단계로 구성된 구조를 가집니다. 이 구조는 각각 협업 필터링과 언어 모델의 강점을 살려 정보를 처리하는 방식입니다.
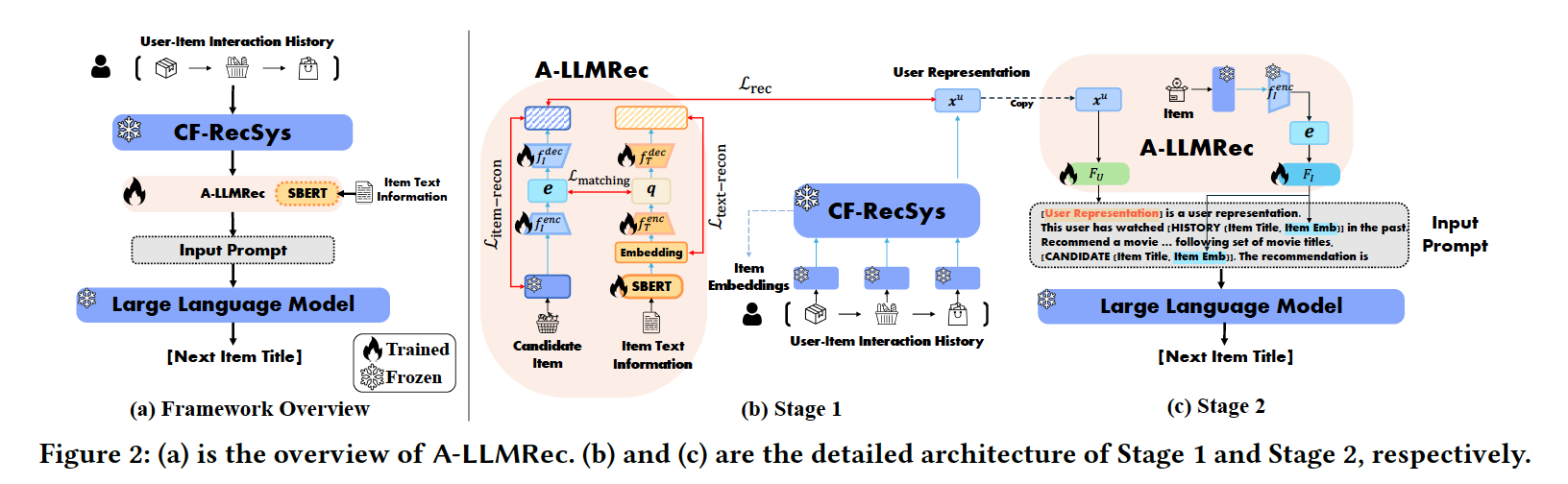
(1) 1단계: 협업 지식과 텍스트 지식의 정렬
- 협업 필터링 모델(CF-RecSys): 사용자가 상품이나 콘텐츠와 상호작용한 데이터를 기반으로, 유사한 사용자나 아이템을 찾는 모델입니다.
- 이 논문에서 쓰인 CF-RecSys 모델은 SASRec으로, 아이템의 textual information이 아닌 단순 ID sequence를 기반으로 학습해 상호작용한 아이템 정보와 유저의 특성을 임베딩합니다. - 텍스트 기반 임베딩(SBERT): 아이템의 텍스트 정보(예: 영화 설명, 제목)를 임베딩합니다.
- 정렬 네트워크(Alignment Network): 협업 필터링에서 얻은 아이템 시퀀스 정보와 SBERT에서 얻은 아이템 텍스트 정보를 동일한 공간에서 연결합니다. 이를 통해 협업 데이터와 텍스트 데이터가 서로 조화를 이루게 됩니다.
- 이 정렬 네트워크에서 학습하는 정보 2가지
1. 아이템 시퀀스 정보와 텍스트 정보가 얼마나 유사한지
2. 유저 representation이 주어졌을 때 아이템 추천을 얼마나 잘 하는지
-> 위 과정을 통해 CF-RecSys 모델이 유저와 아이템을 임베딩하는 과정을 학습합니다.
(2) 2단계: LLM과의 통합
- 프롬프트 설계: LLM이 사용자 데이터를 자연스럽게 이해하도록 텍스트 명령(프롬프트)을 구성합니다. 예를 들어, "이 사용자[User representation]는 이전에 [과거 상호작용한 아이템 목록]을 시청했습니다. [후보 아이템 중] 다음에 볼 영화를 추천해 주세요." 같은 형태로 모델에 입력합니다.
- [괄호]친 곳에 CF-RecSys를 거친 각각의 임베딩 정보가 들어가게 되고, 이는 LLM에게 단순히 자연어로 정보를 집어넣는 것보다 협업 필터링 정보를 반영해서 예측을 수행할 수 있게 합니다. - LLM 활용: 설계한 프롬프트를 기반으로 사용자가 좋아할 콘텐츠를 예측합니다.
- 효율성 극대화: LLM과 CF 모델 자체는 수정하지 않고, "정렬 네트워크"만 학습하기 때문에 훈련 시간이 짧고 적용이 쉽습니다(CF-RecSys는 사전학습 모델을 사용합니다).
3. A-LLMRec의 장점
- 모델 독립성: A-LLMRec는 기존에 사용 중인 CF 모델이나 LLM과 쉽게 결합할 수 있습니다. CF 모델과 LLM 모델이 독립적으로 시스템을 구성하고 있기 때문에, 본인이 원하는 모델로 갈아끼울 수 있습니다.
- 효율성: 파라미터 수가 수 십억~수 백억개가 넘는 LLM 파인튜닝을 하지 않기 때문에 기존 LLM 기반 시스템(TALLRec)보다 훈련 속도가 2.53배, 추론 속도가 1.71배 빠릅니다.
- 범용성: "cold start 문제"(데이터가 적은 상황)에 높은 성능을 보이는 LLM과 "warm scenario"(데이터가 많은 상황)에 높은 성능을 보이는 협업 필터링 모델을 결합하여 두 상황 모두에서 뛰어난 성능을 보입니다.
4. 실험 결과
일반적인 성능 뿐만 아니라 다양한 시나리오에서 A-LLMRec의 성능이 확인되었습니다.
-
cold/warm 아이템 추천:
- cold scenario에서 기존 CF 모델(SASRec)보다 최대 2배 성능 향상.
- warm scenario에서도 CF 모델과 비슷하거나 더 나은 성능.
-
cold 유저 추천:
- 데이터를 가진 사용자가 적을수록 텍스트 기반 정보가 중요해지는데, A-LLMRec가 기존 CF 모델보다 훨씬 높은 성능을 보였습니다.
-
크로스 도메인 추천:
- "영화 데이터로 학습 후 게임 데이터로 평가" 같은 도메인 간 테스트에서도 기존 모델을 압도했습니다.
-
Few-shot 학습:
- 학습 데이터가 극도로 적은 상황에서도 A-LLMRec는 협업 필터링과 텍스트 정보를 효과적으로 활용해 높은 추천 성능을 발휘했습니다.
---
5. 왜 쉽게 작동할까? A-LLMRec의 비결
A-LLMRec가 쉽게 적용될 수 있는 이유는 간단합니다. 기존 CF 모델과 LLM 사이에 연결 고리(Alignment Network) 역할을 하는 "얇은 네트워크"만 학습하면 되기 때문입니다. LLM이나 CF 모델 자체를 변경할 필요가 없어서 복잡도가 낮고 효율적입니다. 특히, 모델 간 데이터를 서로 이어주는 과정에서 협업 정보와 텍스트 정보가 균형 있게 활용됩니다.
6. 마무리
A-LLMRec는 추천 시스템의 "cold start 문제"와 "warm scenario"를 동시에 해결한 혁신적인 접근법입니다. 협업 필터링과 LLM을 정교하게 결합한 구조는 추천 시스템의 새로운 가능성을 제시하며, 특히 두 모델의 강점을 잃지 않으면서도 간단한 연결 구조를 통해 효율성과 성능을 동시에 확보한 점에 주목할만한 것 같습니다.
작성자: 2기 정지윤
