25-1 강화학습 스터디 결산
25학년도 1학기 스터디 활동 결산에서 2등으로 선발된 강화학습 스터디의 칼럼입니다.
함께 배우는 강화학습의 세계
0. 프롤로그
“안녕하세요 이번에 강화학습에 관심이 생겨,
동아리원분들과 처음부터 같이 공부해보고 싶어 스터디를 모집하게 되었습니다 !”
디스코드 모집글을 통해 각자 다른 배경을 가진 네 명이 모였다. 우리가 '강화학습'이라는 공통 관심사로 만나게 된 것은 벌써 지난 3월 말이다.
그렇게 시작된 우리의 강화학습 스터디 여정을 돌아보며, 함께 배우고 성장한 이야기를 나누고자 한다.
1. 스터디 팀의 형성과 멤버들
멤버 소개
심영찬(팀장)
- 로보틱스 분야에 관심을 가지고 있으며 당면한 졸업과제의 이론적 기반을 마련하고 싶어 스터디를 만들게 되었다.
- 카카오 테크 캠퍼스, 졸업과제로 매우 바쁜 와중에도 팀장으로서 스터디를 잘 이끌었고 또한 성실히 참여했다.
- 단연 스터디의 분위기 메이커로 항상 스터디 분위기를 화기애애하게 만든다.
전진혁
- 학부 연구생으로 활동하고 있고, 분산 학습 및 연합 학습에 관심이 있다. 인공지능 강의 수강 이후 더 다양한 AI 알고리즘을 학습하고 싶어 참여했다.
- 컴퓨터 과학적 배경이 탄탄해서 가끔 등장하는 어려운 CS 개념들을 척척 설명해준다.
- 마찬가지로, 졸업과제와 연구미팅 등으로 항상 바쁜 와중에도 성실히 참여했다.
김태균
- 뚜렷한 관심사 없이 이것 저것 해보는 중이다. 밑바닥 딥러닝 독학 후 새로운 것을 찾아 헤메던 중 스터디에 참여하게 되었다.
- 실습 코드를 이해하고 돌려보는 것을 좋아하며, 이해한 내용을 그림으로 그려보는데 관심이 많다.
- 스터디 진행중에는 열정적으로 질문하는 멤버로, 때로는 너무 깊이 파고들어 시간을 초과하기도 한다.
박비원
- 팀 내 유일한 산업공학도. 데이터 분석을 주력으로 공부하다 AI 알고리즘에도 관심이 생겨 참여하게 되었다.
- 첫 입문이었던터라 책의 내용이 다소 불친절해 초반에는 힘들었지만, 발판으로 삼아 성장하는 계기가 되었다.
- 발표 자료를 항상 깔끔하게 만들어 나머지 컴퓨터공학도들의 탄성을 자아낸다.
시작
첫 온라인 회의에서 우리는 '강화학습 인 액션(Reinforcement Learning in Action)’이라는 책을 교재로 선정했다. 주변의 추천을 통해 알게 된 책으로, 이론뿐만 아니라 여러 예제 실습까지 균형 있게 다루는 점이 스터디 목표와 잘 맞아 떨어졌기 때문이다.
스터디 진행 방식
매주 화요일 오후 6시 반, 빈 강의실에 모여 한 챕터씩 진행했다. 주차마다 돌아가면서 담당 부분을 발제하고, 준비해온 질문들을 공유하며 토론하는 방식으로 진행했다. 학습 내용은 깃허브에 정리하여 공유했다.
우리가 다룬 강화학습의 핵심 개념들
한 학기의 여정을 통해 우리는 강화학습의 기초부터 최신 기법까지 폭넓게 학습할 수 있었다. 각 챕터별로 핵심 키워드를 정리해보았다.
기초 개념
- 제어과제와 마르코프 결정과정
- 탐험과 엡실론 탐욕 전략
- Context bandit 문제
심층 강화학습
- 가치와 정책의 이해
- DQN과 Grid World 예제
- 경험 재현과 목표망
고급 알고리즘
- REINFORCE 알고리즘
- 가치함수와 정책함수의 결합
- 행위자-비평자 모형
최신 기법
- 분산학습과 진화 알고리즘
- 분포 DQN
- 호기심 주도 탐험과 내재적 호기심 모듈(ICM)
기억에 남는 에피소드
- 첫 만남은 어려워 첫 모임 전 강의실에 들어갈 때의 떨림과 설렘은 아직 기억에 남는다. 동아리 OT에서 이야기를 나눠보지 못했던 조원들이어서 특히 긴장이 됐다. 어색한 웃음이 담긴 첫 인사, 그 후 옹기종기 모여 무릎을 맞대고 앉아 자기 소개하며 MBTI 얘기를 하는 것은 모든 스터디 공통이었을거라 생각한다.
- 용어 이해의 중요성 책에서는 많은 용어가 등장한다. 이번 칼럼에서 기술할 용어들과 그와 서로 비슷한 용어들.. 일상적으로도 자주 쓰는 용어들이기도 해서 한 번 읽고 “아~ 대충 이런 느낌이네” 하고 넘어갔다가 책 내용을 점점 이해하기 힘들어졌고 그러다 보니 발제하면서 놓쳤던 부분들이 많이 드러났다. 진혁님의 조언으로 기본적인 용어를 확실히 이해하는데 조금더 중점을 두기로 했고, 그래서 스터디 시간에 발제 후 기본적인 용어를 더 깊이 이해하기 위한 대토론회가 자주 열렸다. 그중에서도 기억에 남는 건 아무래도 처음 DQN을 들어갔던 2, 3주차다. 6:30에 시작해서 8:30에는 끝날 것이라고 생각했지만 9시가 넘어서도 열띤 토론을 주고받던 생각이 난다. 배가 많이 고팠다. 이번 칼럼에서 소개하는 개념의 설명들이 이러한 대토론의 결과물이기 때문에 흥미롭게 봐주셨으면 좋겠다.
2. 주제 소개: DQN
선정 이유
그동안의 학습 중에서 DQN(Deep Q-Network)을 중심으로 소개하고자 한다. 이 부분은 전통적인 강화학습과 딥러닝이 만나는 지점으로, 현대 강화학습의 출발점이라고 할 수 있다.
배경과 필요성
전통적인 Q 학습은 상태-행동 쌍에 대한 Q 값을 테이블 형태로 저장했다. 하지만 바둑처럼 상태 공간이 거대한 문제에서는 이런 접근이 불가능하다. DQN은 신경망을 사용해 Q-함수를 근사함으로써 이 문제를 해결했다!
용어 및 개념 소개
상태(S) : 환경이 제공하는 정보
정책() : 상태에 대해 동작을 선택하는 기준
보상(R) : 동작을 통해 에이전트가 얻는 신호
가치(V) : 상태 S 에대해 주어진 정책에 따라 동작을 행하는 것을 반복할때, 모든 동작으로 얻은 보상의 가중합
Q value — 동작 가치 : 상태 S에서 동작 a의 가치
수식은 이런게 있구나 정도만 알고 넘어가셔도 된다. 하지만 가치가 단순히 하나의 동작의 기대 보상이 아니라는 점만 알아주셨으면 한다.
단일 상태의 보상이 아니라, 그로 인해 계속되는 모든 행동들의 보상의 가중합이다.
개인적으로는 도미노로 이해하는게 쉬웠다. 한번 생각해보시길!
벨먼 방정식: 학습 갱신 규칙
벨먼 방정식은 신경망을 학습시키는 방식을 기술한다. 여전히 수식은 눈으로 훑고 넘어가시면 되지만, 이 부분을 유의해서 봐주셨으면 한다.
다음 상태의 Q 값 중 최대값을 구해 실제 보상값과 더해서 사용하고 있다.
위 식을 목표값이라고 하는데, 목표값과 기존 Q함수의 출력의 차를 Loss로 사용하고 있다.
따라서 학습이 진행됨에 따라 Q 신경망은 목표값과 가까운 Q 값을 출력하게 된다.
가치를 설명하면서 단일 상태의 보상이 아닌 계속되는 모든 행동들의 보상의 가중합이라고 설명했다.
여기서 목표값 부분을 보면 현재의 보상과 계속될 부분을 모두 가지고있다. 즉, Q value와 의미적으로 동등한 것을 알 수 있는데, 다만 첫 번째 보상으로 실제 보상을 포함하므로써 실제 Q 신경망의 출력값 보다 한 단계 더 정확한 Q value가 된다.

결국 Q 신경망은 목표값을 쫓아가면서 최종적으로 Q value를 더 잘 예측하게 된다.
핵심 아이디어
DQN의 핵심은 세 가지 혁신에 있다.
-
신경망을 통한 Q-함수 근사: 상태를 입력받아 각 행동에 대한 Q-값을 출력하는 신경망을 학습시킨다.
기존의 Q 함수는 상태-동작 쌍을 입력으로 받아 그 가치를 출력했다. 하지만 이렇게 했을 때 복잡한 문제에서는 입력으로 주어지는 상태공간의 크기가 너무 커지는 문제가 발생했다.
딥마인드의 논문 Playing Atari with Deep Reinforcement Learning 에서 처음으로 신경망을 이용해 입력으로는 상태를, 출력으로는 각 행동의 Q value를 출력하게끔하여 사용하였다.
- 논문 보기(임베드) https://arxiv.org/pdf/1312.05602
- 논문 보기(임베드) https://arxiv.org/pdf/1312.05602
-
경험 재현(Experience Replay): 과거 경험들을 메모리에 저장하고 무작위로 샘플링하여 학습한다. 이를 통해 데이터 간 상관관계를 줄이고 학습 효율성을 높인다.
예를 들어 장애물을 피하고 벽을 우회해 목표지점으로 가는 GridWorld 예제를 생각해보자.
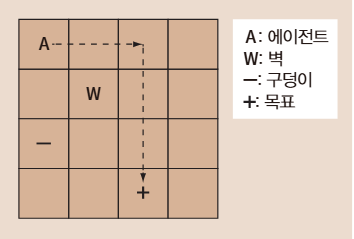
학습 과정에서, 동일한 상태지만 같은 행동을 취했을때 다른 보상을 받았다고 가정해보자, 그렇다면 Q 함수가 제대로된 학습을 했다고 볼 수 있을까? 이 문제를 해결하기 위해 경험 재현을 사용한다.
경험은 각 상태와 선택한 행동, 그때의 보상 등으로 이루어져 있다. 이러한 경험을 튜플의 형태로 저장해 자료구조에 저장해뒀다가 거기서 임의로 몇개를 뽑아 한번에 학습에 이용한다.
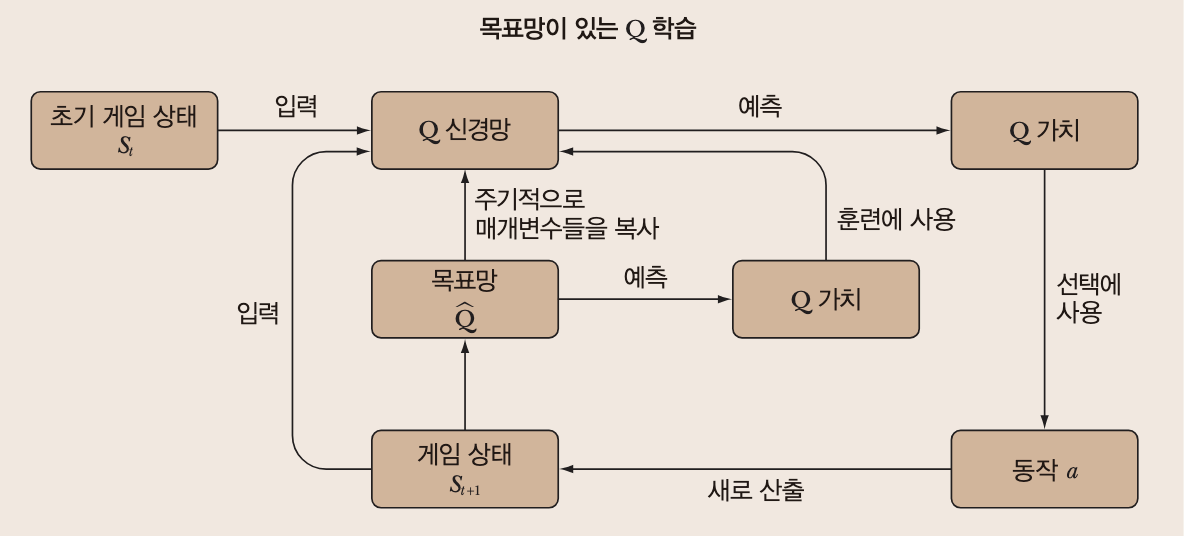
말하자면 보통의 딥러닝에서 수행하는 **배치 학습**과도 같다고 볼 수 있다.- 목표망(Target Network): 학습 안정성을 위해 별도의 목표망을 유지하고 주기적으로 업데이트한다.
위에서 설명한 목표값을 출력하는 용도로만 사용한다.
즉 두개의 신경망을 가용하는데, 흥미로운 점은 이 목표망은 학습시키지 않고 주기적으로 Q신경망의 매개변수를 복사해 사용한다는 것이다.
따라서 평시의 목표망은 이전 단계의 Q 신경망이 된다. 이를 통해 급격한 매개변수 변화를 조절하면서 안정적으로 학습할 수 있다.
Grid World 예제로 보는 DQN의 동작
위 내용을 적용해 스터디에서 구현한 Grid World 예제를 통해 DQN코드다.
주석으로 부연 설명을 해놓았기 때문에 주석부분만 읽으며 이론이 적용되는 부분만 보셔도 충분하실것 같다.
- 구현
환경: 4x4 격자 세계 목표: 시작점에서 목표점까지 최단 경로로 이동 보상: 목표 도달 시 +10, 장애물 도달 시 -10, 그외 행동 -1-
환경
```python import numpy as np import random import sys import torch import copy from collections import deque from matplotlib import pyplot as plt def randPair(s,e): return np.random.randint(s,e), np.random.randint(s,e) class BoardPiece: def __init__(self, name, code, pos): self.name = name #name of the piece self.code = code #an ASCII character to display on the board self.pos = pos #2-tuple e.g. (1,4) class BoardMask: def __init__(self, name, mask, code): self.name = name self.mask = mask self.code = code def get_positions(self): #returns tuple of arrays return np.nonzero(self.mask) def zip_positions2d(positions): #positions is tuple of two arrays x,y = positions return list(zip(x,y)) class GridBoard: def __init__(self, size=4): self.size = size #Board dimensions, e.g. 4 x 4 self.components = {} #name : board piece self.masks = {} def addPiece(self, name, code, pos=(0,0)): newPiece = BoardPiece(name, code, pos) self.components[name] = newPiece #basically a set of boundary elements def addMask(self, name, mask, code): #mask is a 2D-numpy array with 1s where the boundary elements are newMask = BoardMask(name, mask, code) self.masks[name] = newMask def movePiece(self, name, pos): move = True for _, mask in self.masks.items(): if pos in zip_positions2d(mask.get_positions()): move = False if move: self.components[name].pos = pos def delPiece(self, name): del self.components['name'] def render(self): dtype = '<U2' displ_board = np.zeros((self.size, self.size), dtype=dtype) displ_board[:] = ' ' for name, piece in self.components.items(): displ_board[piece.pos] = piece.code for name, mask in self.masks.items(): displ_board[mask.get_positions()] = mask.code return displ_board def render_np(self): num_pieces = len(self.components) + len(self.masks) displ_board = np.zeros((num_pieces, self.size, self.size), dtype=np.uint8) layer = 0 for name, piece in self.components.items(): pos = (layer,) + piece.pos displ_board[pos] = 1 layer += 1 for name, mask in self.masks.items(): x,y = self.masks['boundary'].get_positions() z = np.repeat(layer,len(x)) a = (z,x,y) displ_board[a] = 1 layer += 1 return displ_board def addTuple(a,b): return tuple([sum(x) for x in zip(a,b)]) ``` ```python class Gridworld: def __init__(self, size=4, mode='static'): if size >= 4: self.board = GridBoard(size=size) else: print("Minimum board size is 4. Initialized to size 4.") self.board = GridBoard(size=4) #Add pieces, positions will be updated later self.board.addPiece('Player','P',(0,0)) self.board.addPiece('Goal','+',(1,0)) self.board.addPiece('Pit','-',(2,0)) self.board.addPiece('Wall','W',(3,0)) if mode == 'static': self.initGridStatic() elif mode == 'player': self.initGridPlayer() else: self.initGridRand() #Initialize stationary grid, all items are placed deterministically def initGridStatic(self): #Setup static pieces self.board.components['Player'].pos = (0,3) #Row, Column self.board.components['Goal'].pos = (0,0) self.board.components['Pit'].pos = (0,1) self.board.components['Wall'].pos = (1,1) #Check if board is initialized appropriately (no overlapping pieces) #also remove impossible-to-win boards def validateBoard(self): valid = True player = self.board.components['Player'] goal = self.board.components['Goal'] wall = self.board.components['Wall'] pit = self.board.components['Pit'] all_positions = [piece for name,piece in self.board.components.items()] all_positions = [player.pos, goal.pos, wall.pos, pit.pos] if len(all_positions) > len(set(all_positions)): return False corners = [(0,0),(0,self.board.size), (self.board.size,0), (self.board.size,self.board.size)] #if player is in corner, can it move? if goal is in corner, is it blocked? if player.pos in corners or goal.pos in corners: val_move_pl = [self.validateMove('Player', addpos) for addpos in [(0,1),(1,0),(-1,0),(0,-1)]] val_move_go = [self.validateMove('Goal', addpos) for addpos in [(0,1),(1,0),(-1,0),(0,-1)]] if 0 not in val_move_pl or 0 not in val_move_go: #print(self.display()) #print("Invalid board. Re-initializing...") valid = False return valid #Initialize player in random location, but keep wall, goal and pit stationary def initGridPlayer(self): #height x width x depth (number of pieces) self.initGridStatic() #place player self.board.components['Player'].pos = randPair(0,self.board.size) if (not self.validateBoard()): #print('Invalid grid. Rebuilding..') self.initGridPlayer() #Initialize grid so that goal, pit, wall, player are all randomly placed def initGridRand(self): #height x width x depth (number of pieces) self.board.components['Player'].pos = randPair(0,self.board.size) self.board.components['Goal'].pos = randPair(0,self.board.size) self.board.components['Pit'].pos = randPair(0,self.board.size) self.board.components['Wall'].pos = randPair(0,self.board.size) if (not self.validateBoard()): #print('Invalid grid. Rebuilding..') self.initGridRand() def validateMove(self, piece, addpos=(0,0)): outcome = 0 #0 is valid, 1 invalid, 2 lost game pit = self.board.components['Pit'].pos wall = self.board.components['Wall'].pos new_pos = addTuple(self.board.components[piece].pos, addpos) if new_pos == wall: outcome = 1 #block move, player can't move to wall elif max(new_pos) > (self.board.size-1): #if outside bounds of board outcome = 1 elif min(new_pos) < 0: #if outside bounds outcome = 1 elif new_pos == pit: outcome = 2 return outcome def makeMove(self, action): #need to determine what object (if any) is in the new grid spot the player is moving to #actions in {u,d,l,r} def checkMove(addpos): if self.validateMove('Player', addpos) in [0,2]: new_pos = addTuple(self.board.components['Player'].pos, addpos) self.board.movePiece('Player', new_pos) if action == 'u': #up checkMove((-1,0)) elif action == 'd': #down checkMove((1,0)) elif action == 'l': #left checkMove((0,-1)) elif action == 'r': #right checkMove((0,1)) else: pass def reward(self): if (self.board.components['Player'].pos == self.board.components['Pit'].pos): return -10 elif (self.board.components['Player'].pos == self.board.components['Goal'].pos): return 10 else: return -1 def display(self): return self.board.render() ```모델 정의
l1 = 64 l2 = 150 l3 = 100 l4 = 4 # 모델 정의: Q 신경망 model = torch.nn.Sequential( torch.nn.Linear(l1, l2), torch.nn.ReLU(), torch.nn.Linear(l2, l3), torch.nn.ReLU(), torch.nn.Linear(l3, l4) ) #모델 정의: 목표망 model2 = copy.deepcopy(model) model2.load_state_dict(model.state_dict()) loss_fn = torch.nn.MSELoss() learning_rate = 1e-3 optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) gamma = 0.9 epsilon = 1.0훈련 루프
epochs = 5000 losses = [] mem_size = 1000 batch_size = 200 action_set = { 0: 'u', 1: 'd', 2: 'l', 3: 'r', } replay = deque(maxlen = mem_size) # 데크: 경험 재현에 사용될 최대 메모리 크기 지정 max_moves = 50 # 최대 동작 수 h = 0 sync_freq = 500 # 목표망 동기화 주기 j = 0 for i in range(epochs): game = Gridworld(size= 4, mode = 'random') state1_ = game.board.render_np().reshape(1,64) + np.random.rand(1,64)/100.0 state1 = torch.from_numpy(state1_).float() status = 1 mov = 0 while(status == 1): # 한 게임이 종료될때 까지 반복 ( 한 에피소드 ) mov += 1 qval = model(state1) # qval = 현재 상태 Q값 qval_ = qval.data.numpy() # 정책을 통한 행동 선택 if (random.random() < epsilon): action_ = np.random.randint(0,4) else: action_ = np.argmax(qval_) action = action_set[action_] # state2 : 선택한 행동으로 갱신된 상태 game.makeMove(action) state2_ = game.board.render_np().reshape(1, 64) + np.random.rand(1,64)/100.0 state2 = torch.from_numpy(state2_).float() # 실제 보상 reward = game.reward() done = True if reward > 0 else False # 경험을 튜플 상태로 저장 exp = (state1, action_, reward, state2, done) replay.append(exp) # 상태 갱신 state1 = state2 # 배치 사이즈 만큼 경험이 쌓였다면 학습 (아니면 학습 진행 X) if len(replay) > batch_size: minibatch = random.sample(replay, batch_size) state1_batch = torch.cat([s1 for (s1, a, r, s2, d) in minibatch]) action_batch = torch.Tensor([a for (s1, a, r, s2, d) in minibatch]) reward_batch = torch.Tensor([r for (s1, a, r, s2, d) in minibatch]) state2_batch = torch.cat([s2 for (s1, a, r, s2 ,d) in minibatch]) done_batch = torch.Tensor([d for (s1, a, r, s2, d) in minibatch]) # 배치 인풋으로 Q값 및 목표 값 연산 Q1 = model(state1_batch) with torch.no_grad(): # 목표망을 사용한 목표값 Q2 = model2(state2_batch) Y = reward_batch + gamma * ((1 - done_batch) * torch.max(Q2, dim=1)[0]) X = Q1.gather(dim=1, index=action_batch.long().unsqueeze(dim=1)).squeeze() # 손실 값 계산 및 학습 loss = loss_fn(X, Y.detach()) optimizer.zero_grad() loss.backward() losses.append(loss.item()) optimizer.step() # 정해진 주기대로 목표망 동기화 if j % sync_freq == 0: model2.load_state_dict(model.state_dict()) if reward != -1 or mov > max_moves: status = 0 mov = 0 losses = np.array(losses)plt.plot(losses, label='training loss') plt.xlabel('epochs') plt.ylabel('loss') plt.title('training loss') plt.legend() plt.show()
-
DQN 에이전트는 처음에는 무작위로 행동하지만, 학습이 진행될수록 효율적인 경로를 찾아간다.
신경망이 각 상태 (에이전트 위치, 벽의 위치, 장애물의 위치, 보상의 위치)에서 상/하/좌/우 행동의 가치를 점차 정확히 예측하게 되는 것이다.
3. 함께 성장한 기록


스터디의 성과
- 진행률: 한 학기 동안 총 7주 완주
- 정리된 문서: 10개의 챕터 중 총 8개 챕터 정리
각자의 후기
심영찬: "배운 이론을 졸업과제 알고리즘에 적용시켜보면서 더 깊이있게 이해하고 졸업과제 퀄리티가 올라간 것 같습니다. 스터디를 이끄는게 처음이라 걱정했는데 이런 부분에서도 성장한 것 같습니다."
전진혁: "논문 연구에 필요한 기초지식이 탄탄해졌습니다. 무엇보다 꽤나 최신의 이론까지 배울줄 몰랐는데, 이 부분이 가장 좋았습니다. 또한 복잡한 개념들을 다른 사람에게 설명해보는 경험도 좋았던 것 같습니다,"
김태균: "스터디를 처음 해보면서 그동안 혼자 공부하면서 잘못된 것들, 부족한 점을 깨달을 수 있었습니다. 그리고 이론적인 내용이 코드로 구현되는 것을 보면서 많은 것을 배울 수 있었습니다."
박비원: “혼자서는 포기했을 심화 내용들을 팀원들과 함께 끝까지 해낼 수 있었습니다. 특히 DQN 이후의 부분은 정말 어려웠는데, 다 같이 토론하면서 이해할 수 있었던 것 같습니다.”
아쉬웠던 점과 개선 방향
-
시간 부족: 학기 중 스터디기 때문에 다양한 대외활동과 시험기간으로 인해 모든 주차에 모여서 스터디를 진행하고 책을 끝내기가 어려웠다. 또한 처음 시작할때는 질문 정리 후 답변 내용을 깃허브에 정리하는 등 다양한 계획이 있었지만, 팀원 모두 고학년이고 학기 중의 과제와 프로젝트에 치이느라 끝내 하지는 못했다.
-
실습의 깊이: 실습을 더 깊이 있게 못한점이 아쉽다. 책에 나오는 코드들을 이해하고 따라치고, 환경세팅 후 돌려본 뒤 loss그래프 그리는 정도가 한계였다. 더 깊이하려고 하기에는 학기중이라 시간이 부족해 애매했던 것 같다.
-
논문 리딩: 책에서 강화학습이나 딥러닝에서 중요한 분기점이 되었던 논문들을 가끔씩 소개해준다. 이러한 논문까지 읽고 넘어간다면 더 풍부한 스터디가 됐을 것 같다. 하지만… 위와 같은 한계로 못하고 넘어가게 되었다.
아쉬웠던 점을 종합하면서 사실 많은 부분이 “책을 끝내야만 한다..!”의 목표에서 비롯된 것 같다고 느꼈다. 만일 “책을 다 끝내기” 말고 다른 목표를 고려해서 스터디 계획을 짜려고 한다면 책에 없는 프로젝트를 정해서 책에서 배운 내용을 적용시켜보기, 책에서 소개된 논문등을 읽고 리뷰하기 정도의 추가적인 활동을 추천드린다.
4. 에필로그
스터디 이후의 계획
“칼을 뽑았으면 무라도 썰어야한다.”
우리의 스터디는 한 학기로 끝났지만, 학습은 계속된다.
일단 한 권의 책을 시작했고, 한 학기 동안에는 두번의 시험기간, 멤버들의 대외활동으로 몇 주를 쉬어야 했다. 아직 남은 챕터들이 있기 때문에, 방학 기간을 이용해서 시간이 되는 멤버 끼리 모여서라도 책을 다 끝내려한다.
마무리하며
"빨리 가려면 혼자 가고, 멀리 가려면 함께 가라"
책의 내용이 살짝 불친절한 감이 있었기 때문에 분명 혼자 했더라면 빠르게 작심삼일로 끝났을 것이다. 각자 다른 출발점에서 시작했지만, 같은 목표를 향해 꾸준히 함께하며 모두가 한 단계 성장할 수 있었다고 생각한다.
앞으로도 계속될 AID의 다른 많은 스터디에 응원 부탁드리며, 읽어주신 모든 분들께 감사드린다.
작성 — 김태균
부록: 깃허브
