25-1 AI 논문리딩 스터디 결산
25학년도 1학기 스터디 활동 결산에서 1등으로 선발된 AI 논문리딩 스터디의 칼럼입니다.
팀 소개
안녕하세요, 지난 학기에 이어 이번에도 논문리딩스터디를 진행하게 되었습니다.
우선 스터디 멤버는
- 오지현 (5기, CV)
- 강민석 (6기, NLP)
- 김태환 (7기, NLP)
- 이치오 (7기, CV)
로 구성되어 있으며, 각자 관심 분야에 맞게 논문을 읽고 발표하며 의견을 나누는 방식으로 진행되었습니다!

하나의 기술 토픽에 대해서 다양한 활용 논문을 읽으면서 다방면으로 지식을 획득할 수 있었습니다.
사실 혼자 논문을 읽는 것은 막막한 느낌이 큰데요..
스터디 발표 자료를 제작하고, 비슷한 관심사를 가진 사람들 앞에서 설명하는 것 만으로도 성장하는 느낌이 들었습니다. (질의+ 추가 설명으로 인한 인사이트는 덤)
발표 자료 예시 (이런 느낌)

해당 스터디가 AI 리서쳐를 꿈꾸는 부원들에게는 정말 많은 도움이 될 것 같고,
매 학기마다 진행하고 싶은 마음이 큽니다.

- 스터디룸 예약하기 힘들어서 장소를 왔다갔다 했습니다.. (창마-창지실-중도-카페)

- 밥한끼 기간은 끝났지만 스터디 마무리로 맛있는 카레와 술한잔 했습니다~
코타츠<< 맛집으로 추천드립니다 ^ㅁ^
진행 상황

활동 정리
스터디 그룹원들은 각자의 관심 분야에 따라 자율적으로 리뷰를 진행하며 점차 지식의 폭을 넓혀왔습니다.
- 오지현 님은 Deep Residual Learning(ResNet)과 같은 전통적인 CNN 아키텍처부터 최근 많이 논의되는 Vision-Language Model, MVSFormer++, Zero-Shot Scene Change Detection에 이르기까지 CV 분야를 광범위하게 커버하셨습니다.
- 강민석 님은 Agentic RAG와 ReAct 논문 발표를 통해 LLM의 최신 기술에 집중하고 있습니다. 특히 언어 모델이 정보를 검색하고, 추론하며, 행동을 수행하게 하는 Agent 분야를 깊이 파고 드셨습니다.
- 김태환 님은 Attention Is All You Need와 BERT를 통해 트랜스포머의 핵심 원리를 다진 후, Word Representations in Vector Space로 자연어 처리의 기초를 복습했습니다. 최근에는 Model Compression 관련 논문을 리뷰하시고 모델의 효율성이라는 실용적 주제로 확장하셨습니다.
- 이치오 님은(저는) Vision Transformer(ViT)와 Masked Autoencoders(MAE)를 통해 현대 CV의 핵심인 트랜스포머와 Contrastive Learning을 탐구했습니다. 나아가 3D Gaussian Splatting을 리뷰하며 generic/foundational model이 아닌 다른 특이한 주제로도 관심을 가지고자 하였습니다.
시간의 흐름에 따라서는
초기 (4월) 기본기 확립 → 중기 (5월): 심화 및 확장 → 최근 (7월): 현시점 기술 탐구
가 되겠습니다.
주제 리뷰
마지막 스터디에서 발표한 3D Gaussian Splatting for Real-Time Radiance Field Rendering (Kerbl et al., 2023)이 생소한 CV의 한 분야를 잘 보여주고, 동시에 3D 장면 렌더링 방식에 혁신을 가져다준 논문이라 생각해 적어보게 되었습니다.
Core Idea → Workflows → Results → Improvements up to date → Demo 순으로 설명해 보겠습니다.
3D Gaussian Splatting for Real-Time Radiance Field Rendering (Kerbl et al., 2023)
https://arxiv.org/abs/2308.04079 — Cited by 4604 papers
Core Idea
기존에 있었던 novel-view synthesis of scenes captured with multiple photos or videos and rendering의 methods에 관해 간단히 설명해보도록 하겠습니다.
해당 task는 한 장면에 대한 여러 장의 사진을 입력으로 받아 3D 장면을 construct하는 것을 목표로 합니다. 이전 기술은 explicit과 implicit한 기술로 나눌 수 있는데,

Explicit이란 어떠한 시점에서 사물이 어떻게 보일지 이미 어느정도 메모리에 저장되어 있고, 단순 계산만 하면 scene을 구성 가능하며 이때 GPU에서 CUDA 연산으로 장면을 한번에 처리할 수 있습니다. Point cloud와 여러 개의 polygon을 합쳐 만든 Mesh 방식이 그 예이며, 모든 포인트를 메모리에 올려야 해 Space complexity가 높습니다. 또 다른 단점으로는 ML/DL 기술을 거의 적용하지 않아 사진으로 보여지지 않은 부분에 대한 재현율이 낮다는 점입니다 (일반화 기대 X).
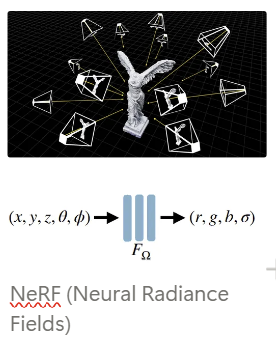
Implicit이란 어떠한 시점에서 사물이 어떻게 보일지 신경망(또는 함수)에 query를 해서 시점 하나하나에 대응하는 값을 구해야 하는 방식입니다. 이에 따라 GPU로 Acceleration을 기대하기 힘들지만 일반화가 잘 되어 사진으로 보여지지 않은 부분에 대한 재현율이 높습니다. NeRF가 한 예로, 여러 방향의 시점(카메라)의 Cartesian Coordinates와 Spherical Coordinates을 input으로 시점의 컬러 값을 유추합니다.
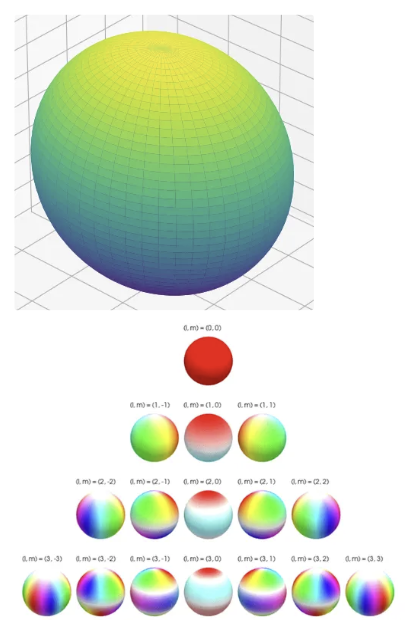
** Spherical Harmonics: 각도 등에 대응하는 값을 반환하는 함수로써 계수 조정을 통해 반환값을 방향별 색상으로 사용 가능
본 논문 3DGS의 가장 큰 특징은 NeRF 처럼 사진에 담기지 않은 부분에 대한 재현율이 좋으면서, 신경망에 의존하는 대신, 3D 가우시안이라는 explicit한 요소로 3D 장면을 표현하는 것입니다 (=두 method를 합침). 각 3D 가우시안은 다음과 같은 속성으로 정의됩니다.
- 위치 (Position, μ): 3D 공간에서의 중심점.
- 공분산 (Covariance, Σ): 가우시안의 형태와 방향을 결정하는 3x3 행렬. 이는 타원체의 크기와 회전을 나타내며, anisotropic 표현(가우시안의 방향에 따른 반지름 등을 조작 가능)을 가능하게 합니다.
- 불투명도 (Opacity, α): 가우시안의 투명도.
- 색상 (Color, c): 다양한 시점에서 변하는 색상을 표현하기 위해 구면 조화 함수(Spherical Harmonics, SH) 계수로 나타냅니다. https://xoft.tistory.com/50
System Workflows
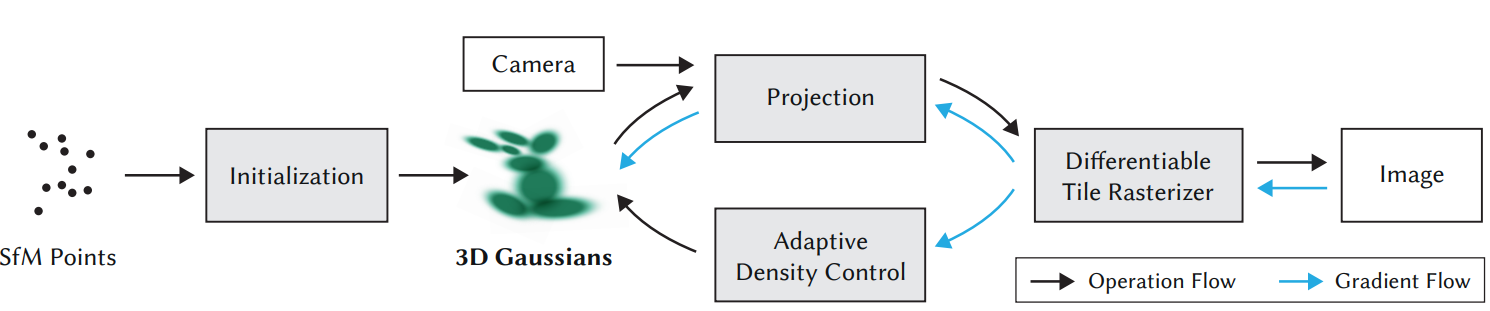
** 3D Gaussian Splatting의 시스템 워크플로우
“First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene . . . (Kerbl et al., 2023)”
3D Gaussian의 Core Idea가 잘 이해가 되지 않으시다면 System을 이해하셔서 전체적인 그림을 그려보실 수 있겠습니다. 시스템 다이어그램과 논문의 Abstract의 핵심 문단을 쪼개 설명해보겠습니다.
▶Inputs & SfM (Structure from Motion)
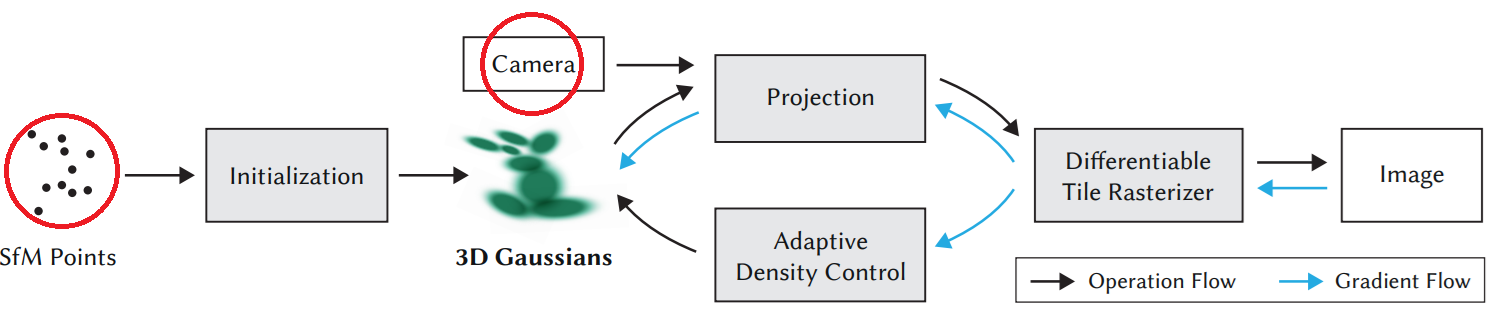
“First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene . . . (Kerbl et al., 2023)”
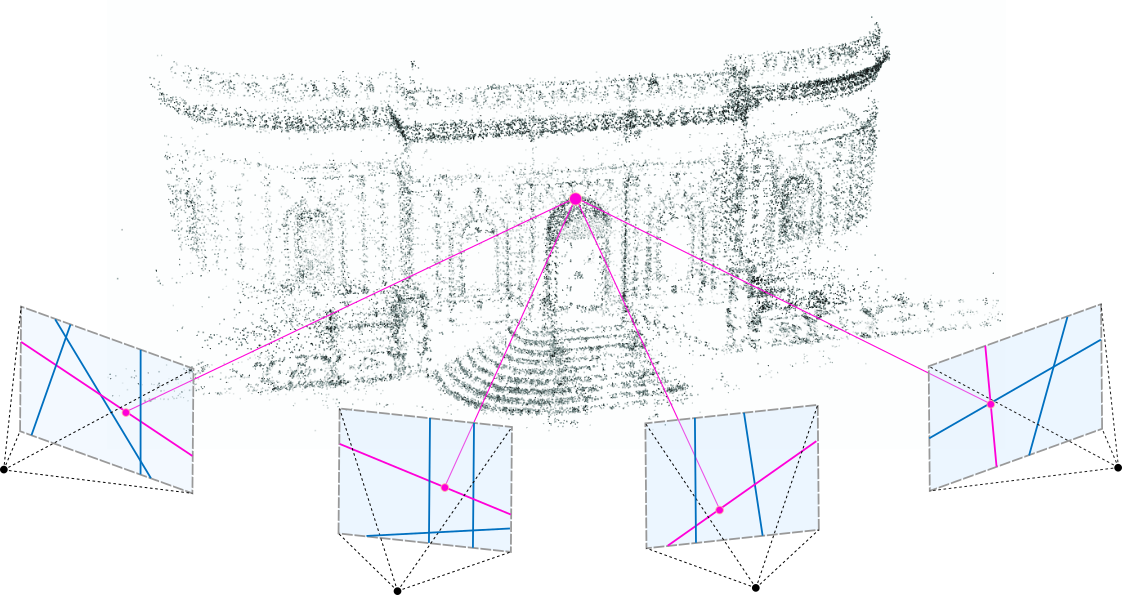
SfM은 2차원 영상이나 이미지 세트로부터 정보를 추출해 3D로 재구성하는 프로세스입니다. 이 과정에서 카메라의 대략적 위치 및 각도와 물체나 장면의 point cloud를 추출합니다. 이 과정에서 생성된 Point cloud와 카메라 위치는 3DGS의 input으로 활용됩니다.
▶3D Gaussian
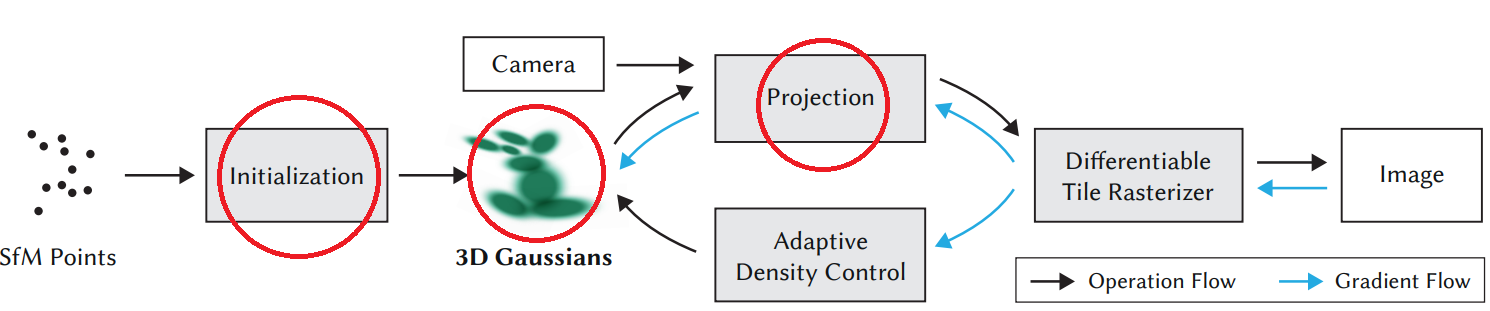
“First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene . . . (Kerbl et al., 2023)”

Initialization 프로세스는 단순히 SfM 프로세스에서 얻은 set of points들에 3D Gaussians (spheres)를 적용하여 3D 가우시안들이 장면의 모든 표면에 위치할 수 있도록 하는 과정입니다. 이때 각각의 가우시안은 아래 특성을 지니게 됩니다.
- 위치 (Position, μ): 3D 공간에서의 중심점.
- 공분산 (Covariance, Σ): 가우시안의 형태와 방향을 결정하는 3x3 행렬. 이는 타원체의 크기와 회전을 나타내며, anisotropic 표현(가우시안의 방향에 따른 반지름 등을 조작 가능)을 가능하게 합니다. 공분산은 Rotation 파라미터, Scale 파라미터 3개로 정의됩니다. Linear Algebra 복습 개념으로, RSS^TR^T에서 SS^T는 제곱된 Scale 파라미터 매트릭스를 만드는데 쓰이며, R(SS^T) 연산 이후 변형된 매트릭스 구조를 바로잡기 위해 transposed R (R^T)를 추가적으로 연산해 공분산 매트릭스를 완성합니다.
- 불투명도 (Opacity, α): 가우시안의 투명도.
- 색상 (Color, c): 다양한 시점에서 변하는 색상을 표현하기 위해 구면 조화 함수(Spherical Harmonics, SH) 계수로 나타냅니다. https://xoft.tistory.com/50
이후 3D 가우시안을 적용한 3D 장면을 렌더링하기 위해서는 2D 이미지 평면으로 투영해야 합니다. 저자들은 3D 공분산 매트릭스 를 2D의 로 변환합니다. 는 3D를 카메라 시점으로 투영하는 좌표 변환 매트릭스이고, 는 원근법을 적용하여 2D 타원으로 근사하는 행렬입니다. (는 단순 approximation 값들로 구성되어 실제 계산시 오차가 발생할 수 있어 추후 연구에서 수정되는 오류입니다.)

이후 카메라 시점 2D 장면은 이 이미지처럼 다양한 coef. (투명도, 색상, 2D 공분산 행렬, 위치) 들을 가진 3D 가우시안들이 겹쳐있는 모습입니다.
NeRF가 미분 가능해 일반적 머신러닝처럼 Gradient를 이용해 최적화할 수 있는 것처럼, 각 가우시안이 point나 mesh와 다르게 미분 가능하여 최적화가 가능하여 이 방법은 point나 mesh 기반 explicit 방식보다 우위의 방식입니다.
동시에, 시점을 구성하는 모든 radiance, pixels를 순차적으로 계산하여 빈 공간을 포함한 모든 지점을 샘플링하고 계산하는 implicit 방식의 NeRF와 달리 빈 공간에는 가우시안 객체 자체가 없어 계산 자체를 수행하지 않는 이 방식은 더 속도가 빠릅니다.
▶Rasterization
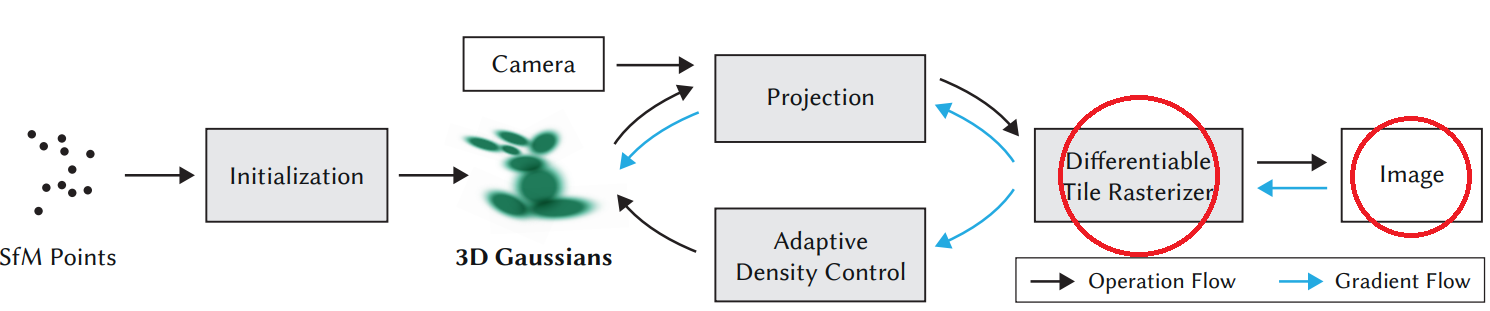
"First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene . . . (Kerbl et al., 2023)”
Rasterization은 3차원 공간의 기하학적 원시적 구조를 2D로 옮기고 컴퓨터 화면에 나타낼 수 있게 픽셀의 값들을 칠하는 단계입니다. 아까 전 단계의 3D → 2D 투영이랑 같은 말 아니냐고요? 이해를 돕기 위한 거짓말이었고, 사실 전 단계는 면밀히 하면 투영 후에도 z-axis에 따라 위치적으로 2D 가우시안의 display되는 순서가 있기 때문에 3D → 3D 입니다.
해당 논문의 Rasterizer은 NeRF 처럼 픽셀별로 정렬해 순차적으로 처리하는 대신, 프레임당 단 한 번만 모든 가우시안을 깊이 순으로 정렬(GPU Radix Sort)합니다. 그 후 화면을 16x16 타일로 나누고, 각 타일을 CUDA 스레드 블록이 가우시안들의 색상, 투명도 등을 참고해 병렬로 계산해 속도면에서 우수합니다.
최적화는 가우시안을 project 하고 rasterize 한 결과 이미지를 원본 데이터의 이미지와 비교해 손실 값을 계산하고 가우시안들의 파라미터를 조정하는 것을 반복하며 진행됩니다.
▶ADC (Adaptive Density Control)
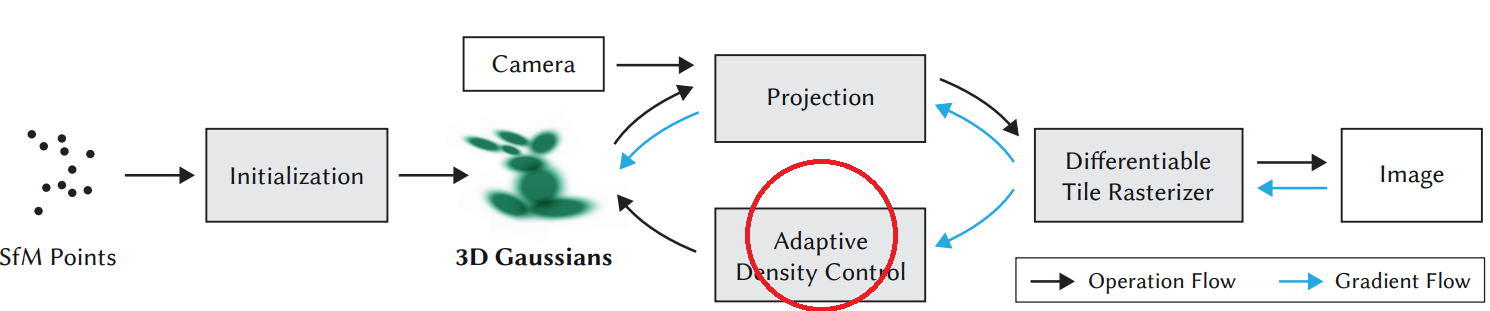
“First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene . . . (Kerbl et al., 2023)”
3DGS의 뛰어난 품질은 Adaptive Density Control 전략에 크게 기인합니다. 학습 중, 시스템은 미분 가능한 래스터라이저를 통해 얻은 위치 그래디언트를 사용하여 가우시안의 밀도를 동적으로 조절합니다.
여기서 “미분 가능한 래스터라이저를 통해 얻은 위치 그래디언트”란
“하나의 특정 3D 가우시안의 위치를 아주 약간 움직였을 때, 최종 이미지의 전체 Loss가 얼마나, 그리고 어느 방향으로 변하는가?”
를 의미합니다.
이때 얻은 위치 그라디언트 ∇μ𝓛 (mu = 가우시안 위치)의 크기에 따라 두 가지의 heuristical assumption을 할 수 있습니다.
- 크기가 클 때: 이는 해당 가우시안이 "잘못된 위치"에 있을 확률이 높다는 신호입니다. 현재 위치에서는 렌더링 결과에 큰 오차를 유발하고 있기 때문입니다. 이 영역은 아직 장면이 제대로 재구성되지 않은 "불안정한" 영역입니다.
- 크기가 작을 때: 해당 가우시안은 이미 "안정적인" 위치에 있어, 조금 움직여도 전체 Loss에 큰 변화를 주지 않는다는 뜻입니다.
따라서 3D Gaussian Splatting은 이 그래디언트 크기를 기준으로 밀도 조절을 수행합니다.
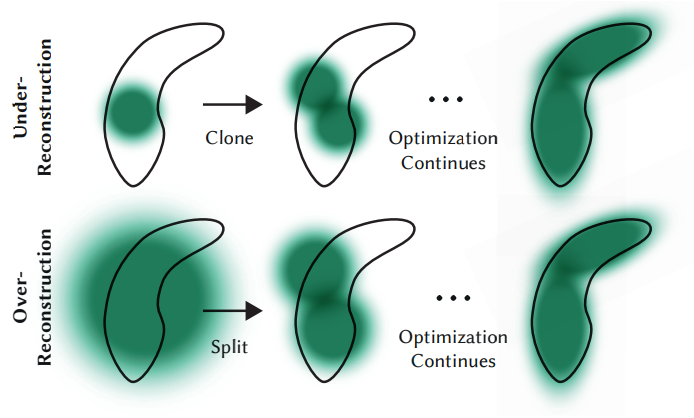
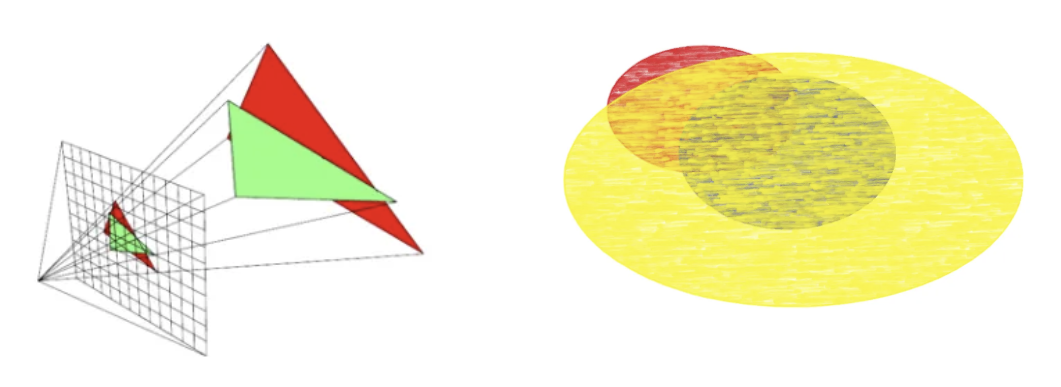
- 가지치기 (Pruning): 투명도가 임계값 이하인 가우시안은 제거합니다.
- 복제 (Cloning): 재구성이 부족한 영역(큰 그래디언트, 작은 가우시안)에서 가우시안을 복제하여 영역을 채웁니다.
- 분할 (Splitting): 재구성이 과도한 영역(큰 그래디언트, 큰 가우시안)에서 하나의 가우시안을 두 개의 가우시안으로 분할하여 세밀한 표현력을 높입니다.
간단히 정리하면,
SfM을 통해 카메라 위치와 point cloud를 얻고, 이 포인트를 전부 3D gaussian으로 치환한 후,
1) 저장해둔 카메라 위치로 각 카메라 시점에 해당하는 gaussian들의 projection을 얻고,
2) 이 projection들을 rasterization을 거쳐 이미지화 하고, 원본 이미지와 비교합니다.
3) Loss의 gradient를 이제 chain rule을 이용해 rasterization, projection을 지나 3D gaussians 속성 값 계수들을 (위치, 공분산, 불투명도, 색상) 최적화 하는데 사용합니다. 또한, ADC의 위치 그라디언트를 사용하는 단계에서 이 gradient를 이용합니다.
4) ADC를 통해 gaussian의 개수와 크기를 조절합니다.
위 1-4 단계를 반복합니다.Results
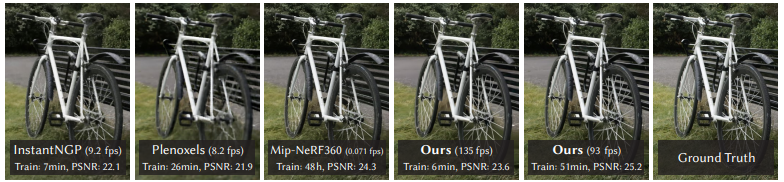
기존 NeRF 기반 기술들이 높은 품질에도 불구하고 느린 학습과 렌더링 속도로 한계를 보인 반면, 3D Gaussian Splatting은 SOTA 품질과 함께 실시간 렌더링을 넘어서는 것을 (>30 fps) 가능하게 했습니다.

Ablation study를 통해 가우시안을 SfM으로 얻은 point 위에 initialize 했을 때와 random 3D coords. 에 initialize 했을 때의 결과 차이입니다.

Ablation study로 가우시안들을 ADC를 적용했을 때와 안 했을 때의 결과 차이입니다.
Improvements up to Date
3DGS는 혁신적인 기술이지만 한계도 존재합니다. 기존 explicit 방식에선 진화했지만 아직 관찰이 부족한 영역에서는 아티팩트가 발생할 수 있으며, NeRF 기반 방법보다 더 많은 메모리를 소비합니다. 이러한 한계를 극복하기 위해 ADC의 heuristicity(유동적이지 않고 일반적 경험에 따라 그냥 설정한 threshold 등등)을 수학적으로 분석하고 개선하려는 연구 등 후속 연구가 활발히 진행되고 있습니다.
가장 인상깊은 후속 연구는 AbsGS, Fussed SSIM이 있습니다.
sGS: https://arxiv.org/abs/2404.10484
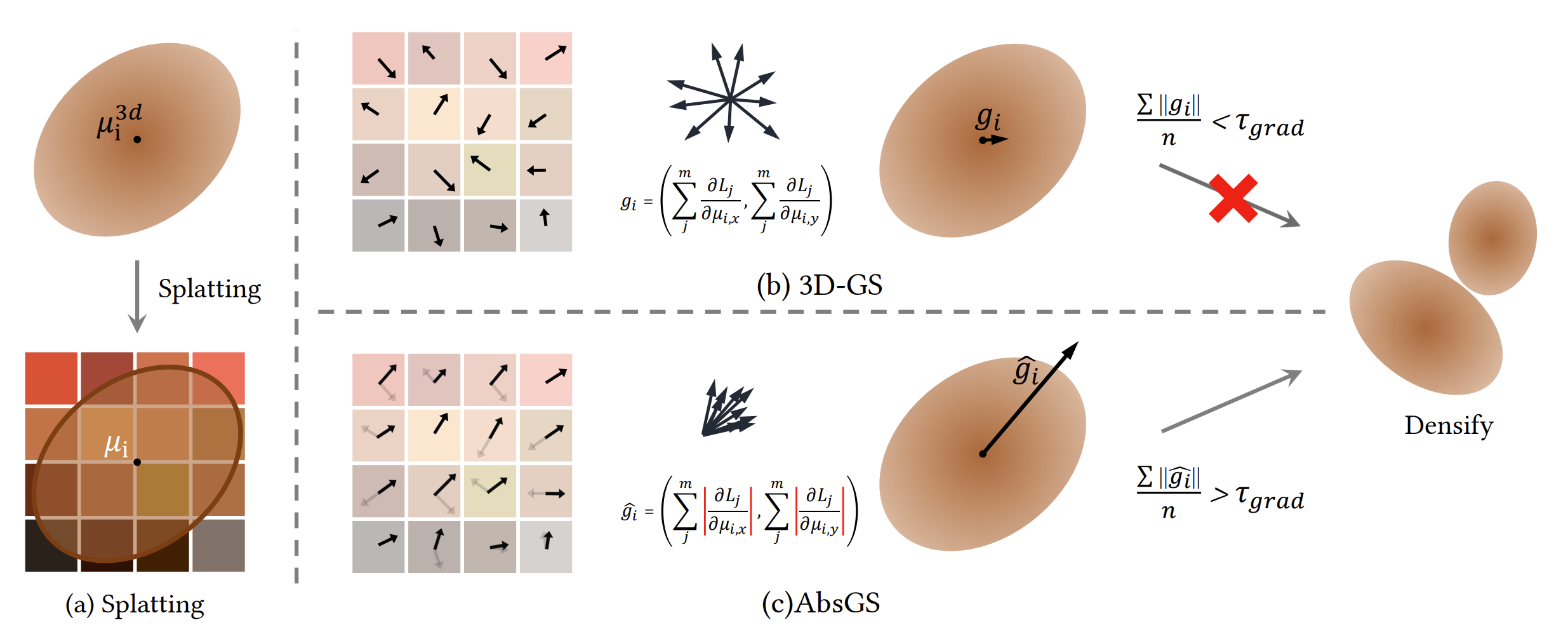
기존 ADC가 각 가우시안의 그래디언트를 평가할때 절대값이 아닌 raw value들을 더해 실제로는 큰 위치 gradient를 가진 가우시안이 위치 그라디언트 값이 작게 나올 수 있는 문제가 있었습니다. 이에 타일별 그래디언트를 합산할 때, 벡터 합 대신 각 그래디언트의 절대값의 합을 사용하여 그래디언트 상쇄 문제를 해결합니다.
Fused-SSIM: https://arxiv.org/abs/2406.15643
원본 3DGS의 손실 함수에서 D-SSIM 계산시 병목 현상이 있었으나 위 연구에서 이를 최적화했습니다.
원래 손실 함수는 다음과 같이 각 카메라 시점에서 원래 input image의 각 픽셀값과 rasterization을 거친 본 논문의 시스템이 만든 이미지의 픽셀값의 단순 차이를 계산하는 loss, 그리고 convolution을 이용해 이미지의 구조적 차이를 비교하는 loss가 있는데, 이 과정에서 2D filter가 여러 번 호출되고, 중간 결과가 별도로 저장되면서 메모리 접근 비용과 연산 중복이 발생합니다.
이를 해결하기 위해 위 논문에선 convoultion에 사용하는 필터를 1D 두 개로 나누어,
두 번의 1D convolution을 사용하여 연산량을 에서 로 줄이고, 훈련 시간 감소 효과를 2.7배로 늘였습니다.
Demo
RTX 3080 Laptop GPU 기준, 이미지 200장에 대해 SfM은 4분, System Optimization은 32분 걸렸습니다.
 원본 이미지 세트
원본 이미지 세트
 3DGS로 생성된 3D 장면을 직접 조작하는 영상
3DGS로 생성된 3D 장면을 직접 조작하는 영상
 Point Cloud
Point Cloud
 3D Gaussian w/ opacity level 100
3D Gaussian w/ opacity level 100
RTX 3080 Laptop GPU 기준, 이미지 150장에 대해 SfM은 3분, System Optimization은 16분 걸렸습니다. 이때 Fused-SSIM을 구현한 Cuda 스크립트로 원본 D-SSIM loss 계산 스크립트를 대체하였습니다.
 원본 이미지 세트
원본 이미지 세트
 3DGS로 생성된 3D 장면을 직접 조작하는 영상
3DGS로 생성된 3D 장면을 직접 조작하는 영상
 Point Cloud
Point Cloud
3D Gaussian w/ opacity level 100
용량을 줄인 GIF라서 화질이 많이 낮아서 비디오도 첨부합니다.
비디오 링크
논문리딩 스터디가 에이드의 대표 스터디가 되길 바라며, 이만 줄이겠습니다.
