캐글 메달리스트가 알려주는 캐글 노하우
이 책 읽으면서 공부한 내용 정리함
EDA(Exploratory Data Analysis)에서 Leak과 train['target'].cumsum().plot()은 데이터 분석 과정에서 중요한 역할을 하는 요소들입니다.
1. Leak
"Leak"은 주로 데이터 유출 또는 데이터 누수를 의미하는데, 모델 학습 과정에서 테스트 데이터의 정보가 훈련 데이터에 영향을 미치는 경우를 말합니다. 이런 누수가 발생하면 모델이 과적합(overfitting)되어 실제 성능을 잘 반영하지 못하게 됩니다.
- Feature Leak: 모델이 훈련 과정에서 테스트 데이터를 사용할 때 발생할 수 있습니다. 예를 들어, 훈련 데이터에 테스트 데이터의 일부 정보가 포함되어 있으면, 모델은 그 정보를 학습하여 성능이 인위적으로 높아질 수 있습니다.
- Target Leak: 훈련 데이터에서 타겟 변수(
target)와 관련된 정보가 포함되어 있으면, 모델이 훈련 중에 타겟 값을 예측하기 쉬워지고 과적합될 수 있습니다.
이를 방지하려면 데이터를 잘 분리하고, 훈련 데이터에만 기반하여 모델을 학습시켜야 합니다.
2. train['target'].cumsum().plot()
train['target'].cumsum()은 target 열의 누적 합계를 구하는 코드입니다. 이를 통해 target의 값이 어떻게 누적되고 있는지 확인할 수 있습니다.
- cumsum(): pandas에서 제공하는 함수로, 데이터의 각 항목에 대해 누적 합계를 계산합니다. 예를 들어, 각 시점에서
target값이 계속 누적되어 가는 형태를 확인할 수 있습니다.
-
plot():
plot()함수는train['target'].cumsum()의 누적 합계 값을 시각화하는 데 사용됩니다. 이를 통해 데이터의 경향을 시각적으로 파악할 수 있습니다.예시:
train['target'].cumsum().plot()이 코드는
target열의 누적 합을 그래프 형태로 시각화하여,target값이 시간이나 다른 순서에 따라 어떻게 누적되는지 한눈에 알 수 있습니다.
결론
- Leak: 데이터 유출을 방지하려면 훈련 데이터와 테스트 데이터의 분리를 신경 써야 합니다.
- train['target'].cumsum().plot():
target값의 누적 합을 시각화하여 데이터의 경향을 분석할 수 있습니다.
numpy를 사용해서 계산하는 것이 더 빠른 이유는 다음과 같습니다:
-
벡터화 연산:
NumPy는 벡터화된 연산을 지원합니다. 즉, 반복문을 사용하지 않고 배열 전체에 대해 한 번에 연산을 수행할 수 있습니다. 이는for루프를 사용하는 방식보다 훨씬 효율적입니다.Pandas는 내부적으로NumPy를 기반으로 동작하기 때문에NumPy배열을 처리하는 방식이 훨씬 더 빠릅니다.NumPy는 배열 단위로 데이터를 처리하여 반복문을 줄여 주기 때문에 처리 속도가 빠릅니다.
-
메모리 효율성:
NumPy는 C로 구현되어 있어 메모리 사용이 매우 효율적이고, 연산 시에도 더 적은 메모리를 사용하면서 빠르게 계산을 처리할 수 있습니다.Pandas는NumPy보다 더 많은 오버헤드를 가지고 있으며, 다양한 기능을 제공하는 대신 성능에서는 약간의 손해를 볼 수 있습니다.
-
배열 연산의 최적화:
NumPy는 배열과 관련된 연산을 최적화하는 다양한 알고리즘을 내장하고 있습니다. 예를 들어,np.where()는 배열을 조건에 따라 필터링하거나 변경하는 연산을 빠르게 처리할 수 있도록 최적화되어 있습니다.
-
병렬화:
NumPy는 내부적으로 여러 연산을 병렬 처리할 수 있는 구조를 가지고 있기 때문에 연산 속도가 매우 빠릅니다.Pandas는 일부 연산에서 병렬화를 지원하지만,NumPy만큼 최적화되어 있지 않습니다.
코드 분석:
train[train_columns].nunique()는train_columns에 해당하는 열들의 고유 값 개수를 계산합니다.np.where(train[train_columns].nunique() < 260000)는 고유 값 개수가 260,000보다 작은 열들의 인덱스를 반환합니다.
np.where()는 train[train_columns].nunique()에서 고유 값 개수가 260,000보다 작은 인덱스를 빠르게 계산합니다. 이 과정에서 NumPy의 벡터화된 연산이 매우 빠르기 때문에, Pandas의 apply()나 for 루프 방식보다 성능상 유리합니다.
데이터프레임을 벡터화한다는 의미는 데이터를 처리할 때 각각의 원소를 하나씩 처리하는 것이 아니라, 전체 데이터(또는 컬럼)를 한 번에 처리하는 방식을 말합니다.
벡터화는 기본적으로 배열 연산으로, 배열이나 데이터프레임의 모든 값을 동시에 처리하는 방식입니다. 이는 보통 반복문을 사용하여 데이터를 하나씩 처리하는 방식보다 훨씬 효율적이고 빠릅니다.
벡터화의 주요 개념:
-
반복문을 대체:
- 전통적인 방식에서는 각 행(row) 또는 열(column)을 하나씩 순회하면서 값을 계산하거나 변환합니다. 예를 들어,
for루프를 사용하여 각 원소를 처리하는 방식이 있습니다. - 벡터화는 이러한
for루프를 사용하지 않고, 전체 배열에 대해 동시에 연산을 수행하는 방식입니다. 이로 인해 연산 속도가 크게 향상됩니다.
- 전통적인 방식에서는 각 행(row) 또는 열(column)을 하나씩 순회하면서 값을 계산하거나 변환합니다. 예를 들어,
-
배열 연산:
- 벡터화된 연산은 기본적으로 배열 또는 행렬 단위로 데이터를 처리합니다. 예를 들어,
NumPy배열이나Pandas의Series객체는 모두 배열 형태로 데이터를 처리하므로, 전체 데이터에 대해 빠르고 효율적으로 연산을 할 수 있습니다.
- 벡터화된 연산은 기본적으로 배열 또는 행렬 단위로 데이터를 처리합니다. 예를 들어,
-
효율성:
- 벡터화된 연산은 저수준의 최적화가 되어 있어 매우 빠릅니다.
NumPy나Pandas의 내부 구현은 C 언어로 작성되어 있어 고수준의 반복문 대신 배열 연산을 최적화하여 실행됩니다.
- 벡터화된 연산은 저수준의 최적화가 되어 있어 매우 빠릅니다.
벡터화의 예시:
1. 반복문 사용:
import pandas as pd
# 예시 데이터프레임
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 각 열의 값을 2배로 만드는 반복문
for column in df.columns:
df[column] = df[column] * 22. 벡터화 사용:
# 벡터화된 방식으로 전체 열을 한 번에 처리
df = df * 2위 예시에서 두 번째 방법은 벡터화를 사용하여 전체 데이터프레임을 한 번에 처리하는 방식입니다. df * 2는 각 열에 있는 모든 값을 한 번에 2배로 변환합니다. 이 방식이 더 빠르고 효율적입니다.
벡터화의 장점:
- 속도: 반복문을 사용하지 않기 때문에, 배열이나 벡터 단위로 계산을 병렬로 처리할 수 있어 훨씬 빠릅니다.
- 간결성: 코드가 간결하고 직관적이어서 가독성이 좋아집니다.
- 메모리 효율성:
NumPy나Pandas는 내부적으로 메모리 최적화를 잘 하기 때문에 대규모 데이터셋을 처리하는 데 유리합니다.
벡터화의 내부 동작 원리:
Pandas와NumPy는 C언어로 작성된 최적화된 라이브러리로, 내부에서 매우 효율적인 배열 연산을 수행합니다. 이 때문에 데이터프레임이나 시리즈의 연산이for루프보다 훨씬 빠르게 실행됩니다.
예시:
import numpy as np
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [5, 6, 7, 8]})
# 벡터화된 연산 (각 열에 대해 1을 더함)
df['A'] = df['A'] + 1 # 열 A에 대해 모든 값을 1만큼 증가
df['B'] = df['B'] + 1 # 열 B에 대해 모든 값을 1만큼 증가
print(df)이 방식은 내부적으로 NumPy 배열 연산을 사용하여 열 전체에 대해 한 번에 계산이 이루어집니다. for 루프를 사용할 때와 비교해 코드가 훨씬 간결하고 빠릅니다.
Pandas의 describe() 함수는 데이터프레임 또는 시리즈에 대해 기초 통계량을 계산하여 요약된 정보를 제공합니다. 이 함수는 숫자형 데이터에 대해 다음과 같은 기본 통계량을 계산합니다:
1. count: 데이터의 개수
- 데이터에서 결측치(NaN)를 제외한 실제 값의 개수를 나타냅니다.
2. mean: 평균
- 해당 변수(열)의 평균값을 계산합니다.
3. std: 표준편차
- 변수의 값들이 평균을 기준으로 얼마나 분포해 있는지를 나타냅니다. 표준편차가 클수록 값들의 분포가 넓고, 작을수록 값들이 평균에 가까운 분포를 보입니다.
4. min: 최소값
- 해당 변수에서 가장 작은 값입니다.
5. 25% (1사분위수):
- 데이터의 하위 25%에 해당하는 값입니다. 즉, 값들의 25%가 이 값보다 작거나 같고, 75%는 이 값보다 큽니다.
6. 50% (중앙값 또는 2사분위수):
- 데이터의 중앙값입니다. 전체 데이터의 중간에 위치한 값으로, 데이터가 정렬되었을 때 중간 위치에 해당하는 값입니다.
7. 75% (3사분위수):
- 데이터의 상위 25%에 해당하는 값입니다. 즉, 값들의 75%가 이 값보다 작거나 같고, 25%는 이 값보다 큽니다.
8. max: 최대값
- 해당 변수에서 가장 큰 값입니다.
추가 옵션:
describe()함수는 기본적으로 숫자형 데이터에 대해서만 통계량을 계산하지만,include='all'옵션을 주면 범주형 데이터에 대한 통계량도 함께 계산할 수 있습니다.
df.describe(include='all')이렇게 하면, 숫자형 데이터 외에도 범주형 데이터에 대한 고유값의 개수, 최빈값(mode), 빈도 등의 정보를 함께 볼 수 있습니다.
이처럼 describe()는 데이터의 분포와 특성을 간략하게 이해하는 데 유용한 통계량을 제공합니다.
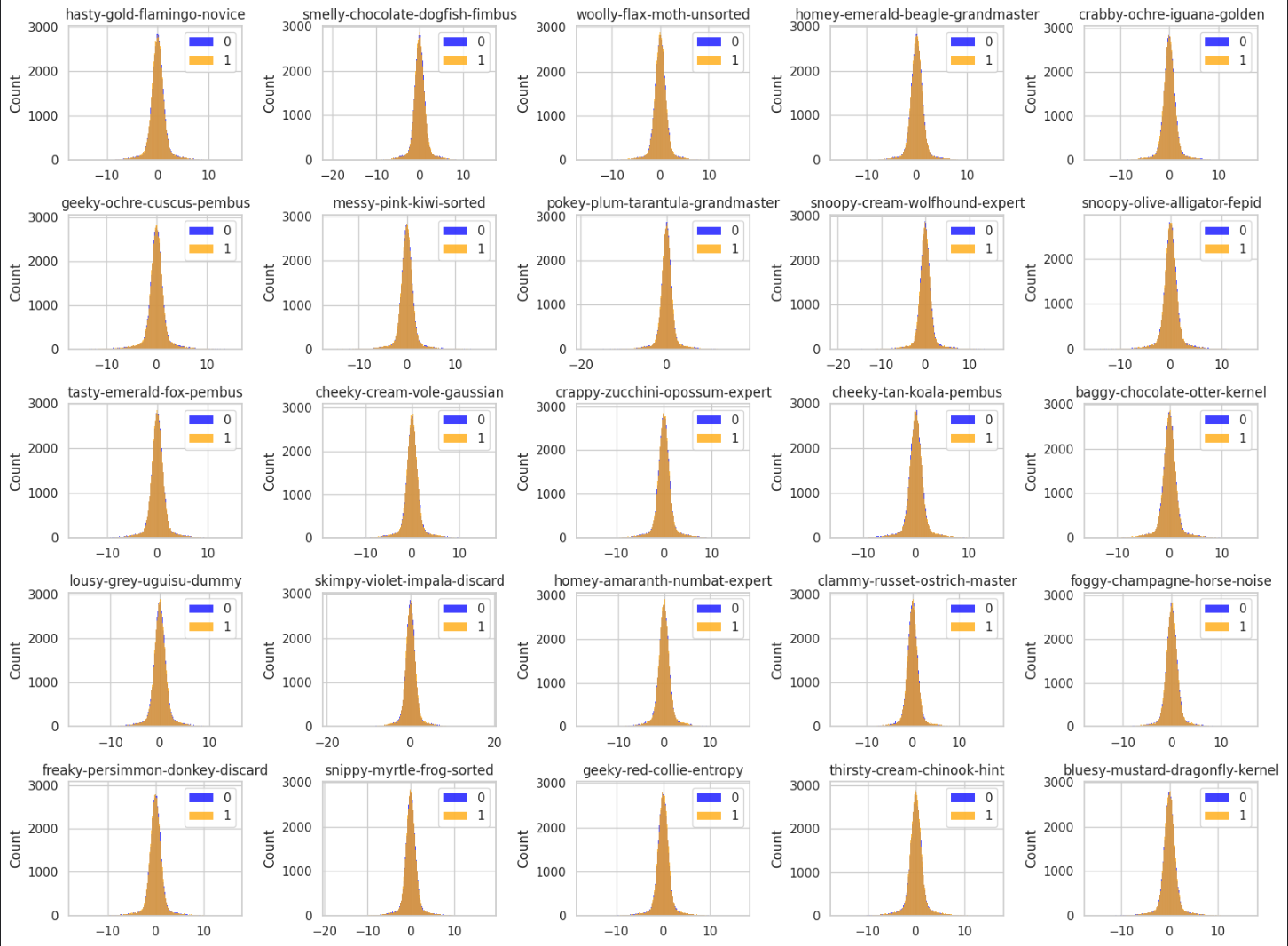
sns.histplot(target_0_df[name], color='blue')
sns.histplot(target_1_df[name], color='orange')두 히스토그램의 분포가 다른 컬럼은 모델에서 중요한 feature가 될 가능성이 큽니다.
특히, target 값이 0인 경우와 1인 경우에 각 컬럼의 값들이 다른 분포를 보인다면, 그 컬럼은 두 target 클래스 간의 차이를 구별하는 데 중요한 정보를 제공할 수 있습니다. 이런 feature들은 분류 모델에서 유의미한 역할을 할 수 있기 때문에, 모델의 성능 향상에 기여할 가능성이 있습니다.
따라서, 이러한 컬럼들을 중요한 feature로 다루고, 모델에 포함시키는 것이 좋습니다.
