Posted by Jungyoon Choi, Research Engineer, Mediazen AI Edtech team
안녕하세요, 오늘 포스팅에서는 자연어 처리에서 역사가 깊으면서도 여전히 중요하게 다뤄지는 단어 중의성 해소 (Word Sense Diambiguation, WSD) 태스크에 대해서 소개드리고자 합니다.
다음 각각의 문장에서 ‘bank’는 어떤 의미를 가질까요?
- I must go to the bank and change some money.
- These flowers generally grow on river banks and near streams.
첫번째 문장의 bank는 ‘은행’을 뜻하고, 두 번째 bank는 ‘강’을 뜻합니다.
‘bank’를 사전에 검색하면 여러가지 뜻이 있는 것을 볼 수 있습니다.
bank noun (MONEY)
an organization where people and businesses can invest or borrow money, change it to foreign money, etc., or a building where these services are offered:
bank noun (RIVER)
sloping raised land, especially along the sides of a river:
여러분이 예시 문장 1,2를 읽었을 때 bank의 의미를 어떻게 추론했는지 생각해봅시다. 아마 1번 문장에서는 ‘change some money’, 2번 문장에서는 ‘river’, ‘stream’과 같은 주변 단어와 문맥을 통해서 구별하였을 것입니다. 단어 중의성 해소 태스크(WSD)는 문맥마다 달라지는 단어의 정확한 의미를 잡아내기 위해서 진행하는 자연어 처리 태스크입니다. 단어의 중의성 문제를 해결하는 것은 언어학적으로 중요하게 다루어지기 때문에 이와 관련된 연구들의 역사가 깊지만, 다른 자연어 처리 문제들처럼 딥러닝의 등장과 함께 WSD 또한 딥러닝으로 해결하고자 하는 시도들이 꾸준히 등장해왔습니다.
태스크 정의
단어 중의성 해소 태스크를 딥러닝의 관점에서 좀 더 명확하게 정의해보겠습니다.
문맥(Context) 문장과 목표 단어가 입력으로 들어가면, WSD 모델은 목표 단어가 어휘의미망에서 어떤 의미에 해당되는지를 구별해내야 합니다. 다음 그림을 통해 예시를 보겠습니다.
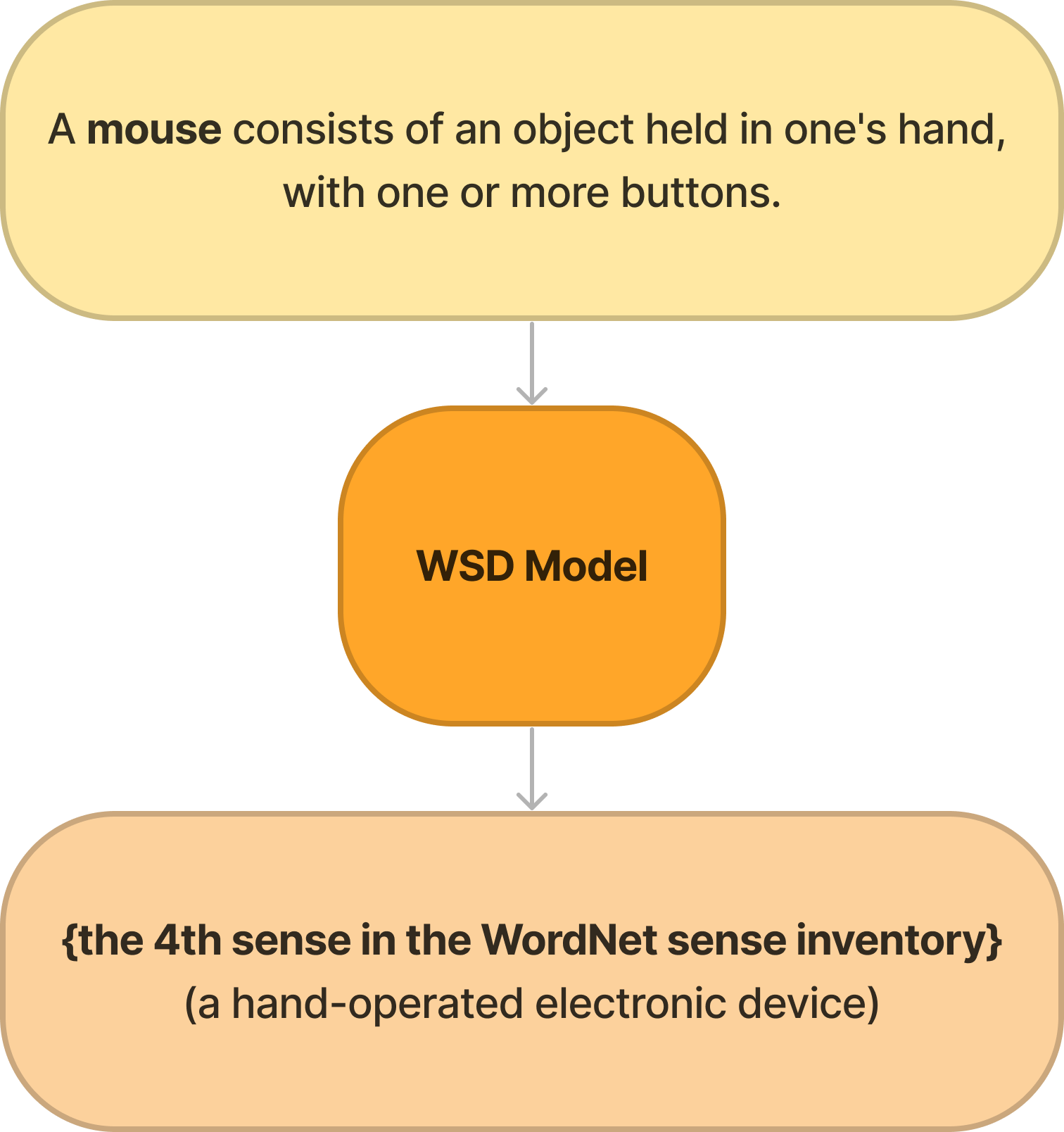
입력으로 “A mouse consists of an object held in one's hand, with one or more buttons.” 와 같은 문장이 들어간다면, 목표 단어인 mouse에는 여러 의미가 있지만 주변 문맥을 본다면 ‘컴퓨터에 쓰이는 마우스’인 것을 알 수 있습니다. 이 과정을 WSD 모델 내부에서 수행한 후, wordnet과 같은 어휘의미망에서 어떤 의미에 해당되는지 의미 태그와 맵핑을 하게 됩니다. Wordnet에서의 mouse 검색 결과를 확인해보시면, 4번째에 해당되는 의미를 결과로 얻게 됩니다. 이와 같은 WSD 태스크는 단어의 의미를 분명하게 확인해야하는 기계 번역, 정보 검색 뿐만 아니라 다양한 NLP 태스크에 응용될 수 있습니다.
데이터셋
WSD 태스크에 쓰이는 표준 데이터셋으로는 Senseval-2, Senseval-3 task 1, SemEval-07 task 17, SemEval-13 task 12 등의 여러 WSD 대회 데이터셋이 존재합니다. 이번 포스트에서는 가장 최신의 SemEval-15 task 13에서 사용한 데이터셋을 통해 WSD 태스크에 사용되는 데이터셋의 형태를 간단하게 살펴 보겠습니다.
SemEval-15 task 13 데이터셋은 생명과학, 수학, 사회 분야의 4개의 문서에서 BabelNet 2.5.1 어휘의미망을 활용하여 문서 내 각 단어에 대한 BabelNet id로 의미 태깅을 한 데이터셋입니다. BabelNet은 WordNet 의미과 Wikipedia 관련 문서 제목에 대한 태그가 통합되어 있어서 이 또한 데이터셋에 반영되어 있습니다.

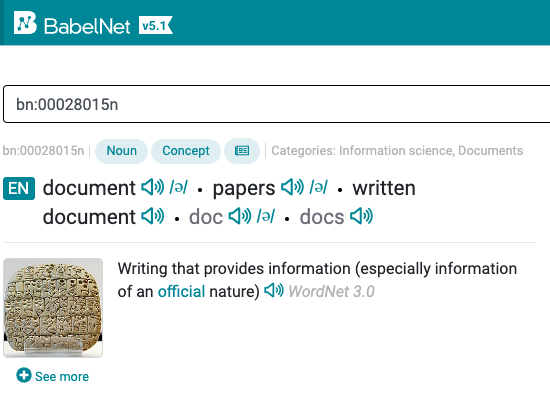
BabelNet 검색 결과
연구 동향
 .
.
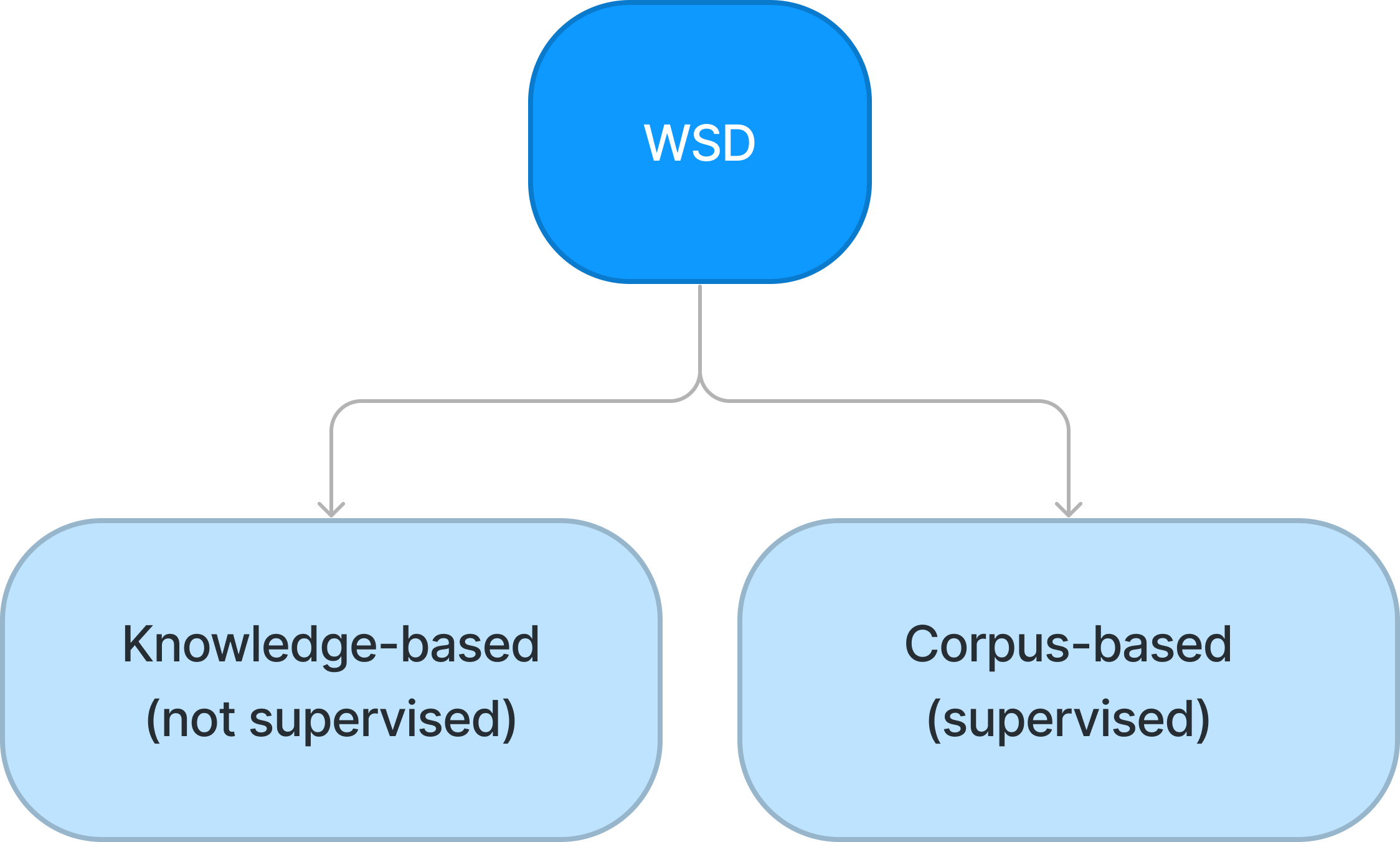
WSD 태스크의 연구 방향은 크게 지식 기반(Knowledge-based), 지도 학습(Supervised-method) 방법론으로 나누어집니다. 지식 기반 WSD는 문맥 내의 단어의 정확한 의미를 추론하기 위해 어휘의미망과 같은 이미 구축된 지식 기반을 활용하는 것에 초점을 둡니다. 반면 지도 학습 기반은 WSD를 다중 라벨 분류 문제(multi-label classification)로 취급하여 거대한 양의 단어들에 대해 각각 어떤 의미 라벨을 가지는지 찾아내는 분류기를 훈련하는 방식입니다.
지도 학습 기반의 WSD는 트랜스포머를 활용한 딥러닝 모델들이 도입되면서부터 성능이 향상되기 시작했고 트랜스포머 기반 연구들이 주를 이루고 있습니다. 하지만 지도 학습은 훈련 데이터에서 등장한 특정 의미의 단어만 학습하는 경향이 있기 때문에 훈련 데이터 이외의 새로운 단어 또는 단어가 가질 수 있는 또 다른 의미에 대해서 예측하지 못하게 됩니다.
이를 극복하기 위해 많은 연구들이 사전에 명시된 단어의 정의 문장(gloss)을 모델 훈련할 때 활용하는 방법을 도입하였습니다. 이 방법론을 통해 단어에 존재할 수 있는 사전적 정의들을 모두 다루어 기존 지도학습 모델들의 한계를 극복할 수 있게 되어, 대다수의 최신 연구의 기반이 되는 추세입니다.
현재 sota를 달성하고 있는 모델은 EMNLP 2021에서 발표한 “ConSeC: Word Sense Disambiguation as Continuous Sense Comprehension”논문의 ConSeC 모델입니다. 기존의 WSD 모델들이 문맥 문장, 목표 단어의 사전적 정의, 어휘의미망 내의 관계적 지식들을 활용한 트랜스포머 모델을 사용해왔다면, 이 모델은 목표 단어의 주변 단어 의미들까지 고려하여 성능을 높였습니다.
마무리
이번 포스팅에서는 WSD 태스크가 NLP에서 어떤 것인지 간단하게 알아보았습니다. 현재의 SOTA 모델이 등장하기까지 다양한 시도와 연구들이 있었는데, 앞으로 업로드 될 WSD 시리즈에서는 과거의 연구 동향부터 어떤 모델이 쓰이고 어떻게 성능을 보여왔는지 살펴볼 예정입니다.
참고 문헌 및 사이트
