Posted by Jungyoon Choi, Research Engineer, Mediazen AI Edtech team
안녕하세요, 오늘 포스트에서는 교육 목적의 자연어 처리 연구를 위한 ACL 워크샵, BEA에서 올해 채택된 논문 한 편을 소개해드리려고 합니다. 본 연구에서는 언어 교육에 사용하기 위해 학습자의 수준에 알맞게 응답의 난이도를 조정할 수 있는 챗봇을 제안합니다. 전반적인 내용과 필요하다고 생각되는 부분 위주로 정리했으니 참고해주시기 바랍니다.
원문 : https://aclanthology.org/2022.bea-1.28.pdf
챗봇의 응답을 특정 레벨로 난이도를 조정해보자!
외국어 습득에서 상호작용은 중요한 요소이지만, 실제 원어민 선생님과 1:1로 대화를 진행하는 것은 비용적인 측면에서도 그렇고 어려운 점이 많습니다. 대화 시스템은 이에 대한 대안이 될 수 있어서, 언어 교육 분야에서 활발히 연구되고 있는 분야이지만, 규칙 기반이나 수작업으로 대답을 가공하는 경우가 대부분입니다. 따라서 본 연구에서는 언어 교육 분야에서 학습자의 수준에 맞게 알맞은 응답을 제공하는 챗봇을 위한 실험을 진행합니다.
관련 연구
해당 연구와 참고한 연구 분야로는 다음과 같은 주제들이 있습니다. 자세한 연구 배경 설명은 논문을 참고하시면 좋을 것 같습니다.
- 대화 시스템 (Dialogue systems)
- 디코딩 전략 (Decoding strategies)
- 텍스트 단순화 (Text simplification)
- 언어적 복잡도 (Linguistic complexity)
- 어휘적 복잡도 (Lexical complexity)
- 가독성 평가 (Readability assessment)
구현 방법
본 연구에서는 챗봇의 난이도를 6개의 CEFR 레벨 중 하나로 조정하는 5가지의 디코딩 방법을 제시합니다.
CEFR 레벨이란?
CEFR은 유럽 언어 공통 기준(Common European Framework of Reference for Languages)으로 유럽언어 학습자의 평가의 명확성을 위해 마련된 평가 기준입니다. A1, A2, B1, B2, C1, C2 총 6개의 수준으로 나뉘며, 가장 기초 단계인 A1부터 시작하여 C2는 원어민 수준으로 외국어를 구사하는 단계입니다.
베이스가 되는 챗봇 모델로는 페이스북의 블렌더봇을 사용하였지만, Beam search 또는 샘플링 기반으로 하는 생성 모델들에 모두 적용될 수 있다고 합니다. CEFR 레벨 값들을 나타내기 위해서 0-5 사이의 연속값으로 나타내었는데, 그 이유는 1) 훈련 데이터가 적기 때문에 분류 모델보다 회귀 모델이 더 좋은 성능을 보여줄 것이며, 2) 특정 레벨에만 해당되는 것이 아닌 레벨 사이에 위치하는 상황(B2-C1 사이)이 있기 때문이라고 합니다.
1. Vocabulary restriction with EVP
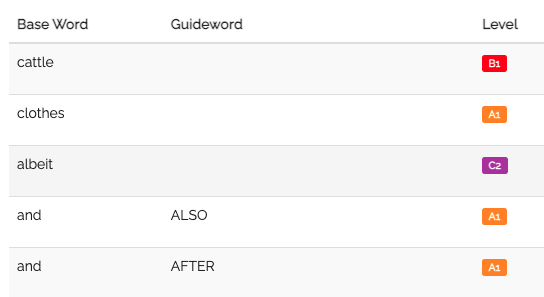
EVP 단어별 CEFR 레벨 리스트 예시베이스라인으로 사용한 방법론은 CEFR 레벨이 지정된 단어 리스트에 기반하여 간단한 단어 필터링을 하는 방법입니다. English Vocabulary Profile(EVP)는 6,750개의 단어와 구를 6개의 CEFR 레벨로 맵핑합니다. EVP에서는 다의어를 여러 레벨로 매겨놓았는데, 생성 과정에서 어떤 맥락에서 해당 단어가 사용되는지 결정하는 것이 불가능하기 때문에 본 연구에서는 그 중 가장 낮은 레벨로 맵핑하여 사용합니다.
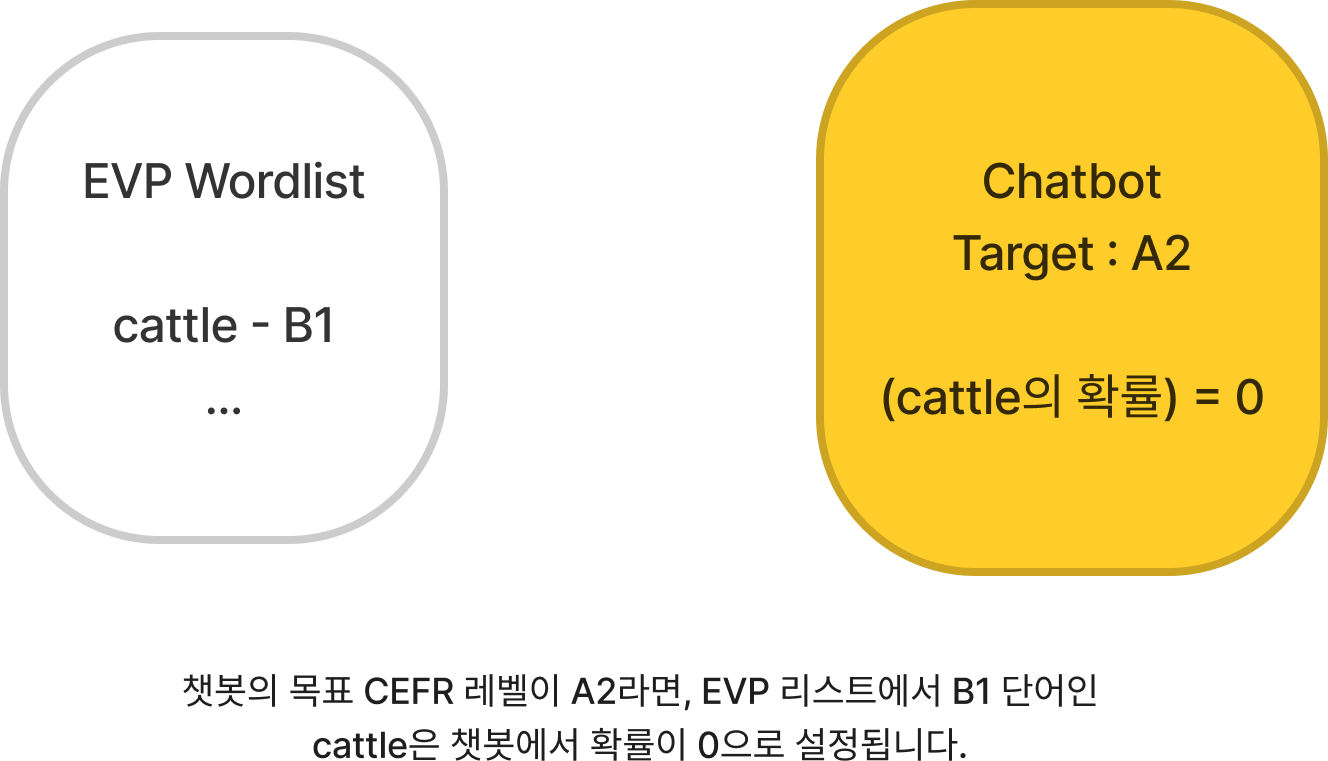
그림의 예시처럼 단어의 CEFR 레벨이 챗봇의 목표 CEFR 레벨보다 높으면, 해당 단어의 확률을 0으로 설정하여 생성되지 않도록 합니다.
2. Vocabulary restriction with extended EVP
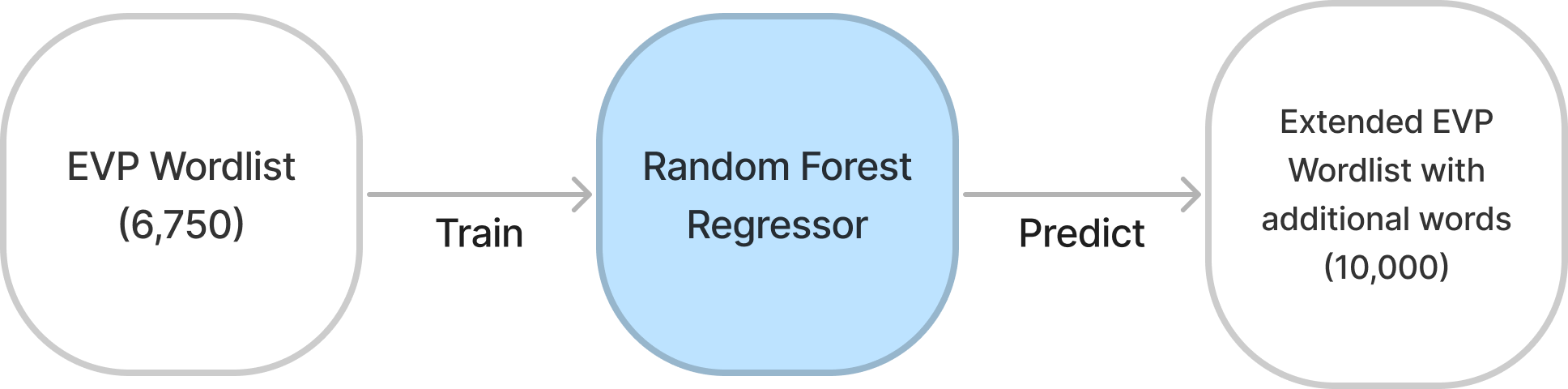
EVP의 단어 리스트는 6,750개로 적은 양이기 때문에 두 번째 방법론에서는 EVP외의 단어들의 CEFR 레벨을 예측하는 회귀모델을 훈련하여 단어 리스트를 확장합니다. 훈련 데이터 부족과 디코딩 상황에서의 문맥이 존재하지 않기 때문에 단어의 의미가 아닌, 표면적인 단어의 형태에 기반한 피쳐를 사용합니다. 랜덤 포레스트 회귀 모델을 사용하였고, 훈련을 위해 사용한 피쳐들을 종합해보면 다음과 같습니다. (자세한 설명은 논문을 참고해주세요.)
- 단어 길이
- 음절 개수
- WordNet에서 동의어, 상의어, 하의어 개수
- 영화, 위키 등 다양한 코퍼스에서의 단어 빈도 수
- 기본 영단어 리스트에서 단어 존재 유무
- 음소 개수
- 친숙도
- 명확도
- 심상성
- 습득 연령
해당 예측 모델의 성능 평가를 위해 기존의 EVP의 단어들로 테스트를 진행하였습니다.
3. Re-ranking
지금까지 소개한 단어 제한 방법론은 텍스트의 난이도가 단어 자체의 난이도에 의해서만 결정되는 것이 아니라는 단점이 있습니다. 단어 뿐만 아니라 생성되는 문장의 구조와 내용에 따라서 적절한 난이도의 텍스트를 생성하는 것도 중요합니다. 따라서 제시되는 세번째 방법론에서는 적절한 메세지를 선택하기 전에 여러개의 후보 메세지 중에서 순위를 다시 매겨 최종 선정하는 방법론을 제시합니다.
문장 난이도 예측 모델
이를 위해 문장의 CEFR 레벨을 예측하는 회귀모델을 훈련합니다. 챗봇이 작동할 때, 회귀 모델이 모든 후보 메세지들의 CEFR 레벨을 매긴 후, 기존의 순위와 예측된 순위를 종합하여 가장 높은 순위의 메세지가 사용자에게 전달됩니다. 본 연구에서는 RoBERTa 모델을 다양한 CEFR 레벨의 학습자들을 대상으로 하는 Cambridge Exams 데이터셋을 사용하여 텍스트 난이도를 예측하도록 미세 조정하였습니다.
Re-ranking
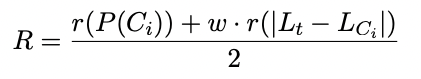
연구에서 제시한 Re-ranking 방법을 요약하자면 다음과 같습니다. 각 후보 메세지의 기존 확률(챗봇 언어 모델로부터 받은 확률, 높을수록 높은 순위) 과 각 후보의 예측 난이도와 목표 난이도 사이의 거리(거리가 짧을수록 높은 순위) 를 평균내어 최종 순위를 결정합니다. 는 목표 난이도까지의 거리의 중요도를 조절하기 위한 가중치입니다. 다시 말해, 언어 모델이 내놓은 후보의 확률과 문장 난이도 예측 모델이 내놓은 후보의 레벨을 활용하여 최종 메세지를 선정하는 것입니다.
4. Re-ranking with sub-token penalties
세 번째 방법론에서 20개의 생성된 후보 메세지들이 목표하는 학습자의 CEFR 레벨과 많이 떨어져 있는 경우들이 있었습니다. 예를 들어, 20개의 후보 메세지들이 C1 레벨에 있으나, 학습자의 CEFR 레벨은 B1인 상황입니다. 후보 메세지들이 학습자의 CEFR 레벨에 가깝게 하기 위해서, 네번째 방법론에서는 너무 어려운 하위 토큰(sub-token)들에 페널티를 주는 추가적인 페널티 시스템을 제안합니다. 너무 쉬운 토큰에는 많은 기능어들이 포함되어 있기 때문에 페널티를 주지 않습니다. 하위 토큰은 단어와 구분되어 생각되어야 하는데, 하위 토큰들이 모여 단어가 완성됩니다.
하위 토큰의 CEFR 레벨을 결정하기 위해서, Cambridge Exam 데이터셋 내의 텍스트를 토큰화하여 하위 토큰들이 어느 CEFR 레벨에 나타났는지 확인하였습니다. 그리고 목표 학습자의 CEFR 레벨보다 어려울수록 하위 토큰에 큰 페널티를 줍니다.
5. Re-ranking with sub-token penalties and filtering
하지만 하위 토큰에 페널티를 주는 방식은 단어가 아닌 하위 토큰에 페널티를 주었기 때문에 종종 의미 없는 단어 (non-sense words)가 생성되는 경우들이 있었다고 합니다. 이를 처리하기 위해서 다섯번째 방법론에서는 out-of-vocabulary 단어 리스트를 추가하여, 해당 리스트에 단어가 존재하면 이를 제외하고 메세지를 생성하게끔 하였습니다.
Evaluation
각각의 방법론들에 대해 블렌더봇이 스스로에게 이야기하는 300개의 셀프 채팅(self-chat) 대화문을 생성하여 이에 대해 평가를 진행하였습니다. 각 방법론들이 의도된 레벨의 메세지를 생성하였는지 확인하기 위해, 본 연구에서는 10명의 영어 학습자들을 모집하여 각 셀프 채팅의 난이도를 판정하는 평가를 진행하였습니다.
각 셀프 채팅 대화문은 “Hello!”로 시작하여 18개의 메세지로 구성되어 있습니다. 아래의 예시 대화문은 5번째 방법론(하위 토큰과 필터링으로 순위를 다시 매긴 방법)을 통해 C1 수준을 목표로 하여 생성된 대화문입니다.

Results and Discussion
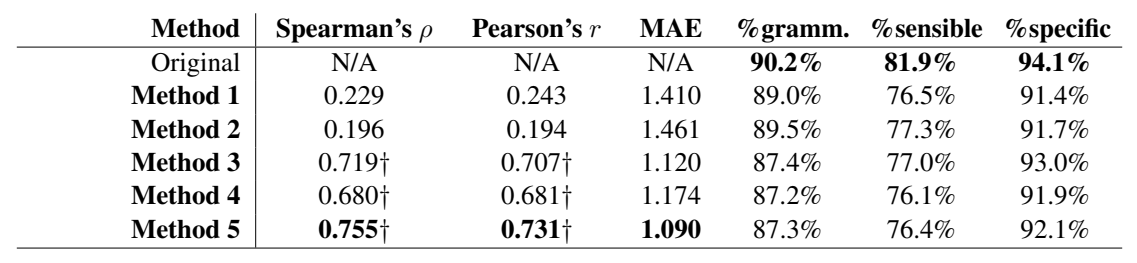
지표들에 대해서 간단하게 설명드리자면, Spearman, Pearson 상관계수는 목표 CEFR과 평가자들이 선정한 실제 CEFR 간의 상관 관계를 나타낸 것이며, MAE는 평균 절대 오차로, 1 MAE는 CEFR 레벨 1을 의미합니다. 각 메세지들이 문법적으로 올바른지(gramm.), 말이 되는지(sensible), 구체적인지(specific)에 대한 수치는 퍼센트로 표시가 되어있습니다.
MAE와 상관계수 점수를 보면, 하위 토큰 페널티와 필터링을 통해 순위를 다시 매기는 방법론(5번째)이 가장 높은 점수를 기록하고 있습니다. 단어 기반 방법론은 성능이 매우 좋지 않았는데, 단어가 텍스트의 난이도를 결정하는 중요한 요소라는 의견에 반하는 결과이기 때문에 의외의 결과라고 합니다. 하지만 본 연구에서 다의어와 구들을 제거하고 실험하였기 때문에 이런 결과가 나왔을 수 있다고 이야기합니다.
문법성, 의미, 구체성에 대한 수치는 통계적으로 같다는 결과가 나왔지만, 위의 표를 보시면 기존 언어 모델에서 디코딩 전략을 추가할 수록 성능이 조금씩 떨어지는 것을 보실 수 있습니다. 본 연구는 디코딩 전략에 대한 연구이지, 언어 모델에 대한 연구가 아니기 때문에 이에 대해 다루지는 않지만 학습자 경험에서 양질의 메세지를 출력하는 것이 중요하기 때문에 추후에 이에 대한 연구가 필요하다고 이야기합니다. 실험에서 사용된 블렌더봇은 대량의 Reddit 데이터로 사전 학습이 되었기 때문에, 온라인 커뮤니티에서만 허용될 수 있는 비문이 출력되는 경우가 많다고 합니다.
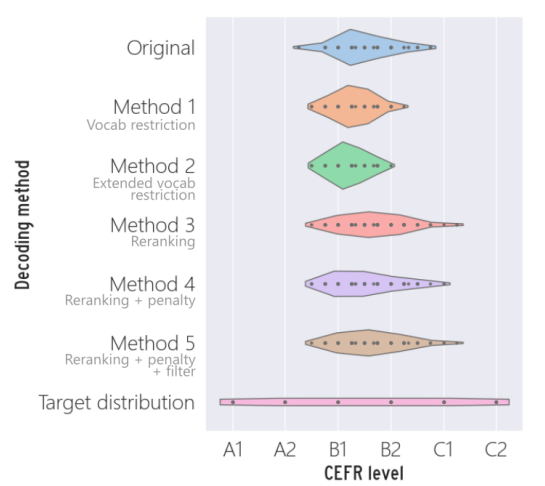
위의 바이올린 플롯은 각 방법론에 대한 CEFR 분포를 보여주고 있습니다. 마지막의 플롯이 가장 이상적인 분포로, 6개의 레벨에 대해서 가장 고르게 메세지의 분포가 그려지고 있습니다.
이 연구에서는 실험 중 발견한 몇 가지 의미 있는 결과들을 공유하는데요,
- 기존 언어 모델이 생성해내는 대화문의 CEFR 레벨은 대체로 B1과 B2 사이에 위치해있었습니다.
- 단어 제한 기법들은 난이도를 낮추는 경향이 있어서 C1, C2의 대화문은 전혀 없었습니다.
- 순위를 다시 매기는 기법들이 더 나은 성능을 보인 이유는 후보들 중 가장 목표 레벨에 가까운 후보를 고르기 때문입니다.
- 언어 모델 자체가 만들어내는 대화문에서 CEFR 레벨의 불균형이 낮은 성능에 영향을 끼쳤을 것입니다.
- A1으로 라벨링된 대화문은 존재하지 않았습니다.
- 대화 상황 자체가 초심자들에게 어려운 과제이기 때문에 그럴 것이라고 예상됩니다.
- A1 학습자에게 딱 들어맞는 대화를 생성하기에는 주제와 단어가 너무 적기 때문입니다.
리뷰를 마치며
챗봇 응답의 난이도를 조절한다는 것에 의미가 있기도 하지만, 그 기준을 CEFR 레벨로 잡아서 연구를 진행했다는 점이 흥미로웠습니다. CEFR을 토대로 만들어진 교육 자료들이 많기 때문에 CEFR 레벨을 기반으로 한 연구는 실제 교육적인 측면에서 바로 적용을 시켜볼 수 있다는 장점이 있습니다. 또한 CEFR 레벨이 매겨진 단어 리스트를 어떻게 활용하여 모델을 훈련했는지도 눈여겨볼만한 점이라고 생각했습니다. 마지막으로 실험 결과에서 딥러닝 기반 교육용 챗봇이 내놓는 대답이 어떤 경향성을 가지고 있는지 인사이트를 얻을 수 있는 연구였습니다.
※ 잘못된 해석이나 내용, 피드백 사항은 댓글에 남겨주시면 감사하겠습니다.
