[논문 리뷰] Generating Self-Contained and Summary-Centric Question Answer Pairs via Differentiable Reward Imitation Learning
NLP
Posted by Jungyoon Choi, Research Engineer, Mediazen AI Edtech team
안녕하세요, 본 포스팅에서는 Amazon Alexa의 논문 "Generating Self-Contained and Summary-Centric Question Answer Pairs via Differentiable Reward Imitation Learning"을 리뷰하였습니다. 필자가 중요하다고 생각되는 부분 위주로 정리했으니 참고해주시길 바랍니다.
- 대화형 뉴스 추천 시스템에서의 질문 생성에서 착안한 연구
- 뉴스 기사로 데이터셋 생성, Question = 제목, Answer = 요약문
- Exposure bias(ground truth를 입력할 수 없어서, 이전 출력값을 기반으로 다음 예측을 해야하는 단점)를 해결하기 위해 Reward function 활용하여 QA pair 생성
- 자동/정성 평가 모두에서 기사의 핵심을 잘 잡아내는 것으로 판정됨
1. Introduction
대화 시스템이 어떤 질문을 받을 수 있는지 사용자에게 안내해 줄 수 있는 질문 제안(Suggested questions, SQs)이 중요해지면서 질문 생성 연구가 주목을 받고 있습니다. SQ의 효과는 다음과 같습니다:
- 모델에게 어떤 질문을 해야하는지를 사용자가 직접 알아내야 하는 부담을 덜고,
- 모델이 다음 질문을 더 명확하게 선택할 수 있다.
뉴스 기사에서 직접 얻은 질문과 요약문을 짝지어 QA pair 생성하여 기사 추천의 역할을 수행할 수 있습니다. QA pair는 다음과 같은 기준을 충족해야합니다:
- 질문은 self-contained 되어야함 (↔ context dependent, ex. “Where was the album released?”와 같은 질문은 본문 내용에 따라 정답이 달라짐. Self-contained 질문은 질문만 봐도 답변할 수 있어야함.)
- 질문은 요약 중심으로 기사의 핵심을 파악해야함
- 질문에 대한 정확한 답변이어야함
- 답변은 짧으면서도 정보를 충분히 제공해야함
본 연구에서 목표하는 QA generation task:
Article: President Biden’s infrastructure plan calls for an unprecedented boost in federal aid to the nation’s passenger rail system, seeking to address Amtrak’s repair backlog, extend service to more cities and modernize the network in the Northeast Corridor. The American Jobs Plan announced Wednesday calls for $80 billion for rail – money that could be crucial in taking passenger service to cities such as Las Vegas and Nashville, and expand operations across large metropolitan areas such as Atlanta and Houston. "President Biden’s infrastructure plan is what this nation has been waiting for," Amtrak chief executive William J. Flynn said, while echoing Biden’s push to rebuild and improve...
Suggested Question: What does President Biden’s infrastructure plan mean for Amtrak?
Short Answer: The federal funding would help Amtrak accomplish long-needed upgrades to tracks, tunnels and bridges in the Northeast.
Long Answer: The American Jobs Plan announced Wednesday calls for $80 billion for rail.
The federal funding would help Amtrak accomplish long-needed upgrades to tracks, tunnels and bridges in the Northeast, the nations busiest rail corridor. Amtrak has a $45.2 billion backlog of projects that it says are needed to bring its assets to a state of good repair.
본 연구에서는 데이터셋 구축을 위해 질문 형태의 제목을 가진 기사들과 요약 문장들을 QA pair로 수집합니다. “요약문 생성 → 질문 생성”의 파이프라인은 exposure bias (infer 과정에서는 ground truth가 없어서 이전 출력값을 기반으로 다음 예측을 해야하는 문제점)가 존재하기 때문에 Differential reward imitation learning(DRIL) 훈련 방식을 취하며, 이는 정답 요약문을 샘플링하여 정답 디코더의 hidden state를 기반으로 하여 질문을 다시 생성하는 방식입니다. 생성된 요약문은 바로 질문으로 재구성할 수 있으며, 요약문 정답에 가까운 질문이 나오기 때문에 기사의 핵심을 담고 있습니다.
본 연구의 주요 이슈들:
- 뉴스 챗봇 질문 제안에 적합한 새로운 QA 데이터셋을 수집하고,
- 기사의 핵심을 파악하는 질문과 맥락을 충분히 담고 있는 정답을 생성하는 QA 생성 모델을 제안하고,
- 기존의 MLE나 RL 보다 더 나은 성능을 보여주는 새로운 DRIL 방식을 제안한다.
2. A Self-Contained and Summary-Centric QA Dataset
기존의 Squad, NewsQA, Natural Question과 같은 QA 데이터셋은 기사의 핵심을 파악하고 있지 않고, self-contained된 질문, 즉 문맥 정보에 상관없이 질문만 보고 답변할 수 있는 종류의 질문이 아닙니다.. 따라서 많은 기사들인 질문 형태로 된 제목을 가지고 있다는 점을 활용하여 데이터셋을 제작하였습니다.
QA Pair 수집
2020년 9월부터 2021년 3월까지의 기사들을 정해둔 웹사이트에서 수집하였습니다. Where, What, How 등으로 시작하고 물음표로 끝나는 제목을 골라냈고, 낚시성 제목을 골라내기 위한 필터링 작업을 가졌고, 지문 안에 질문이 반복되는 경우도 제거하였습니다.
{Question, Article, Summary, Length Constraint} collection 수집
요약문을 생성하여 pseudo ground truth로 만드는 과정:
-
원하는 정답 길이 정의
문맥을 충분히 포함하는 요약문을 원하기 때문에 CNN/Dailymail 토큰들을 분석하여 0~30, 30~50, 50~72 BPE 토큰 길이 구간을 3가지로 나누었습니다.
-
요약문 생성
3개의 SOTA 요약 모델 사용 → CNN/Dailymail에 파인튜닝된 PEGASUS, BART, CTRLSum
-
잘못된 요약문 제거
1) 질문에 대한 대답이 안되거나 → MSMARCO로 훈련된 QA pair classifier 훈련
2) sota 모델이 생성한 요약문이 별로인 경우
→ 총 53746개의 튜플 생성
3. Models for QA Pair Generation
-
: Document
-
: Summary
-
: Question
-
: Length bucket indicator (LB0, LB1, LB2)
-
<s> : BOS
-
</s> : SEP
Base D → S → Q model (D-S model)
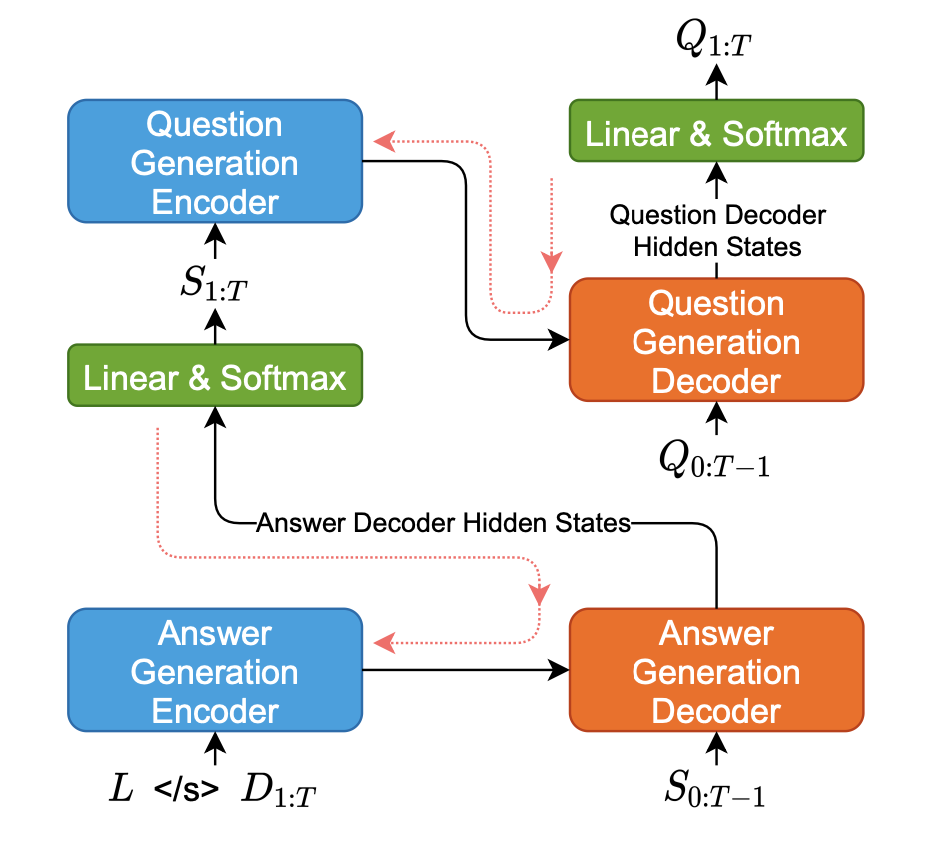
Answer Generation (AG) → Question Generation (QG)
- AG model
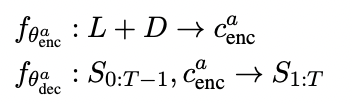
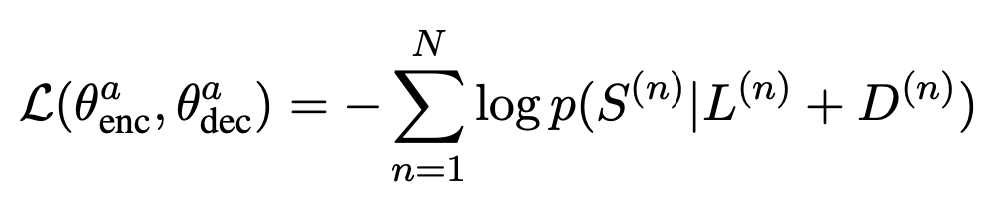
- QG model
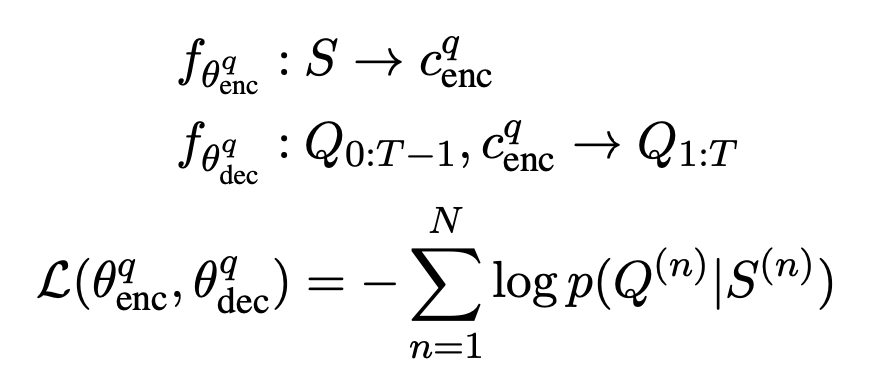
- AG, QG 모두 MLE로 훈련됨
- BART model로 파라미터 값 초기화
MLE로 훈련을 진행할 경우, 특정 타임스텝 t의 디코더 인풋이 t-1의 ground truth(Teacher forcing)이기 때문에 훈련과 추론에서의 차이로 인한 exposure bias가 존재할 수 있습니다. 따라서 MLE로 훈련된 텍스트 생성 모델들은 너무 일반적이고 반복적인 결과를 만들어내는 경우가 많습니다.
또한, 훈련 데이터의 likelihood 함수를 최적화하기 보다 ROUGE와 같은 생성 평가 지표와 사람의 피드백을 직접 활용하여 최적화하고 싶다면? 훈련 도중에 디코더 아웃풋을 샘플하고 샘플링된 아웃풋의 loss를 계산합니다. 많은 연구들은 RL을 활용하지만, reward가 sparse하기 때문에 텍스트 생성 과제에서 비효율적이고, 평가 지표들을 개선하기는 힘들다는 연구 결과가 존재합니다.
QA pair의 요약문을 생성할 때, 기사 없이 ground truth 질문을 재구성하는 것이 좋습니다. 그 이유는:
- 그 자체에서 질문을 생성해낼 수 있는 요약문은 만들어낸 질문에 대해 더 잘 대답할 수 있으며,
- ground truth 질문을 잘 구성해내는 요약문은 기사의 핵심에 더 가깝기 때문입니다.
Differentiable Rewards imitation learning를 통한 정답 생성 최적화 (D-S-DRIL)
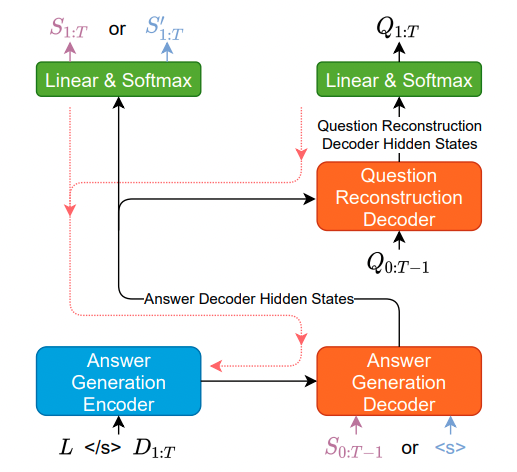
-
AG model
- vanilla sampling
- Teacher Forcing X, 훈련 중에 요약문이 샘플링 됨
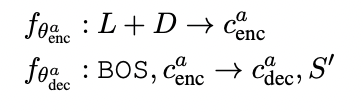
-
Reconstruction Decoder (Transformer-based)
- AG 디코더의 은닉 상태만 받아서 함 (이전에는 L+D) → 요약문으로부터만 질문 생성
- 요약문의 유창성을 확보하기 위해서 MLE loss 또한 추가함
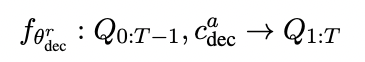
-
AG model의 loss function
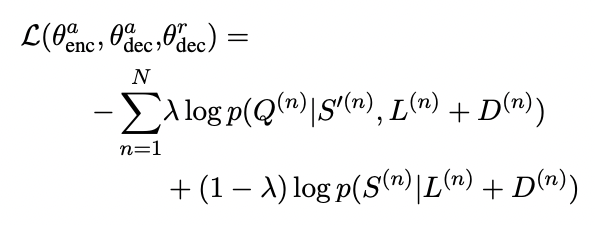
최종 DRIL 모델에서는 AG 모델의 훈련 방식을 사용하지만, QG 모델은 reconstruction decoder를 사용하지 않고 base model을 사용합니다. Reconstruction 디코더를 사용할 경우, input이 단방향 표현인 이 되기 때문입니다.
기존의 RL, Unlikelihood, SeqGAN, Professor-forcing은 훈련 도중에 샘플링된 시퀀스의 loss를 계산하므로서 exposure bias를 완화하는 방식들입니다.
- Unlikelihood : 원하지 않는 시퀀스의 likelihood에 페널티 부여
- SeqGAN, Professor-forcing : 생성된 시퀀스와 정답 시퀀스를 구분하는 구별기를 사용하여 loss 계산 → 외적인 보상함수를 최적화하지는 않음.
DRIL모델은 최종 목적에 맞는 미분가능한 보상 함수를 최적화하며, RL에 비해 낮은 그래디언트 분산을 갖습니다. 그렇기 때문에 DRIL은 다른 시퀀스 예측 문제에서 응용될 수 있습니다.
- ALFRED task : 이어지는 설명을 재구성하는 방식으로 현재의 행동 궤적을 최적화
- Conversational AI : 답변과 대화 맥락이 다음 유저와 시스템의 답변을 재구성하도록 각 턴마다 답변 생성 최적화
Base Model Variants
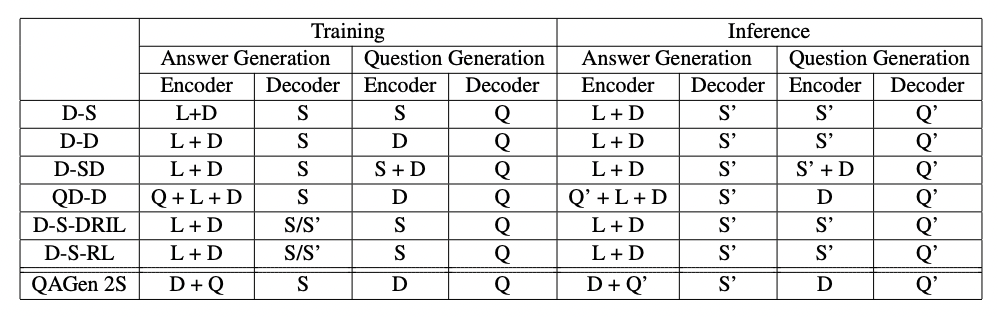 Summary of models.
Summary of models.
- (AG model input) - (QG model input)
- D-S (base)
- D-D
- QD-D : AG model = QA model
- D-SD
- D-S-DRIL : AG model of D-S using RL
4. Experiments
- 실험 기준
- 각 알고리즘에 의해 생성된 QA pair가 얼마나 괜찮은가?
- QA pair 생성에 있어 DRIL이 MLE과 RL을 능가하는가?
- QA pair 생성에서 데이터셋은 기존의 데이터셋보다 괜찮은가?
- 생성된 QA pair에 대한 평가 기준
- 길이가 제한된 요약이 질문에 대답이 되는가?
- 질문이 기사의 핵심을 파악하고 있는가?
- 질문이 self-contained 되었는가?
Automated Metrics
- ROUGE-L
- BLEU
- QA pair classifier scores
- Answer에 대한 ground truth가 없기 때문에 생성된 정답이 얼마나 Question에 대해 잘 대답하고 있는지 평가해야함
Human Evaluation
- 7 Annotation Tasks (ATs)
- AT1: 기사 내용과 정답 없이 질문을 이해할 수 있는가?
- AT2: 정답이 질문에 대한 대답이 되는가?
- AT5: 질문이 기사의 핵심을 파악하고 있는가?
- AT6: (다른 모델에 의해서 생성된 질문 리스트 중) 어떤 질문이 가장 기사의 핵심을 파악하는가?
Baseline
- Gen2S
- CTRLSum
- QA Transfer
- D-S-NewsQA
- D-S-NQ
Quality of Generated Answers
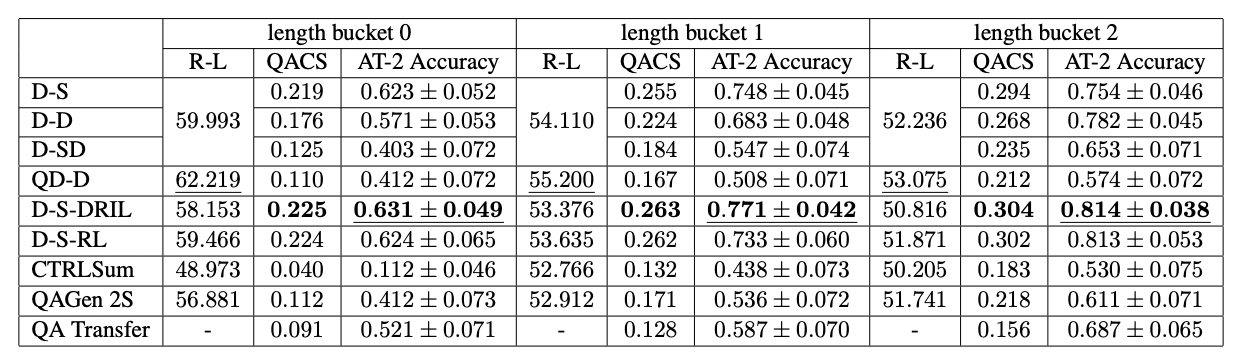
: 정답 기반 질문을 생성하는 모델(AG→QG) > 질문 기반 정답을 생성하는 모델(QG→AG)
{D-S, D-D, D-S-DRIL, D-S-RL} → 더 높은 QACS와 AT2 점수
⇒ 답변 생성 후 질문 생성을 해야한다.
Quality of Generated Questions
 Evaluation of Question Quality.
Evaluation of Question Quality.
: DRIL과 RL이 Question reconstruction loss로 AG를 강화시키고 더 나은 질문을 재구성하고 기사의 핵심을 파악하고 있다.
⇒ D-S-DRIL이 모든 길이에서 가장 좋은 QACS와 AT2-accuracy를 보여주며, 기사의 핵심을 잘 파악하고 있다.
⇒ NewsQA와 Natural Question 데이터셋으로 훈련한 QG 모델은 데이터셋의 특성으로 인해 질문이 기사의 핵심을 파악하고 있지 않다. (질문만 보고 기사의 내용을 추측할 수 없음)
Overall QA Pairs
- D-S-DRIL이 다른 베이스라인보다 가장 성능이 좋음
- DRIL이 RL과 MLE보다 성능이 좋음
본 연구에서 주목해볼만한 내용
- Context의 핵심을 물어보는 질문을 생성해내는 연구
- 데이터셋 구축 방식
- RL을 활용하여 Rouge 점수를 직접 훈련에 활용한 DRIL 제안
참고
"Self-contained"(Self-explanatory)에 관해 설명된 논문 https://arxiv.org/pdf/2010.09692.pdf
Exposure Bias에 관한 설명 https://ckm4514.github.io/nlp/Seq2Seq/
※ 잘못된 해석이나 내용, 피드백 사항은 댓글에 남겨주시면 감사하겠습니다.
