Posted by Jungyoon Choi, Research Engineer, Mediazen AI Edtech team
안녕하세요, 오늘 포스트에서는 교육 목적의 자연어 처리 연구를 위한 ACL 워크샵, BEA에서 올해 2022년도에 채택된 논문 한 편을 소개해드리려고 합니다. 지난번 포스트에서는 줄거리 중심의 QA 세트 생성하는 논문을 소개해드렸는데, 이번에는 같은 Question Generation 태스크지만 교육 목적에 초점을 두어 True/False 질문을 생성하는 연구입니다. 전반적인 내용과 필요하다고 생각되는 부분 위주로 정리했으니 참고해주시기 바랍니다.
원문 : https://aclanthology.org/2022.bea-1.10.pdf
연구 소개
학생들이 학습 자료에 대해서 전반적인 이해를 하였는지 평가할 때 True/False 질문을 묻는 것은 간단하면서도 직접적이고 효율적이기 때문에 교육적 측면에서 매우 중요한 방법론이라고 합니다. 하지만 모든 자료에 대해 직접 질문을 추출해내는 데에는 상당한 시간과 비용이 들어가기 때문에 자동화 방법에 대한 연구가 이루어지고 있습니다. 자동 질문 생성(Question Generation)에 관한 연구는 많지만 T/F 질문에 특정하여 진행된 연구는 비교적 적은 편이며, 많은 연구들은 질문 가치가 있는 내용을 선택하지 못한다는 한계가 있습니다.
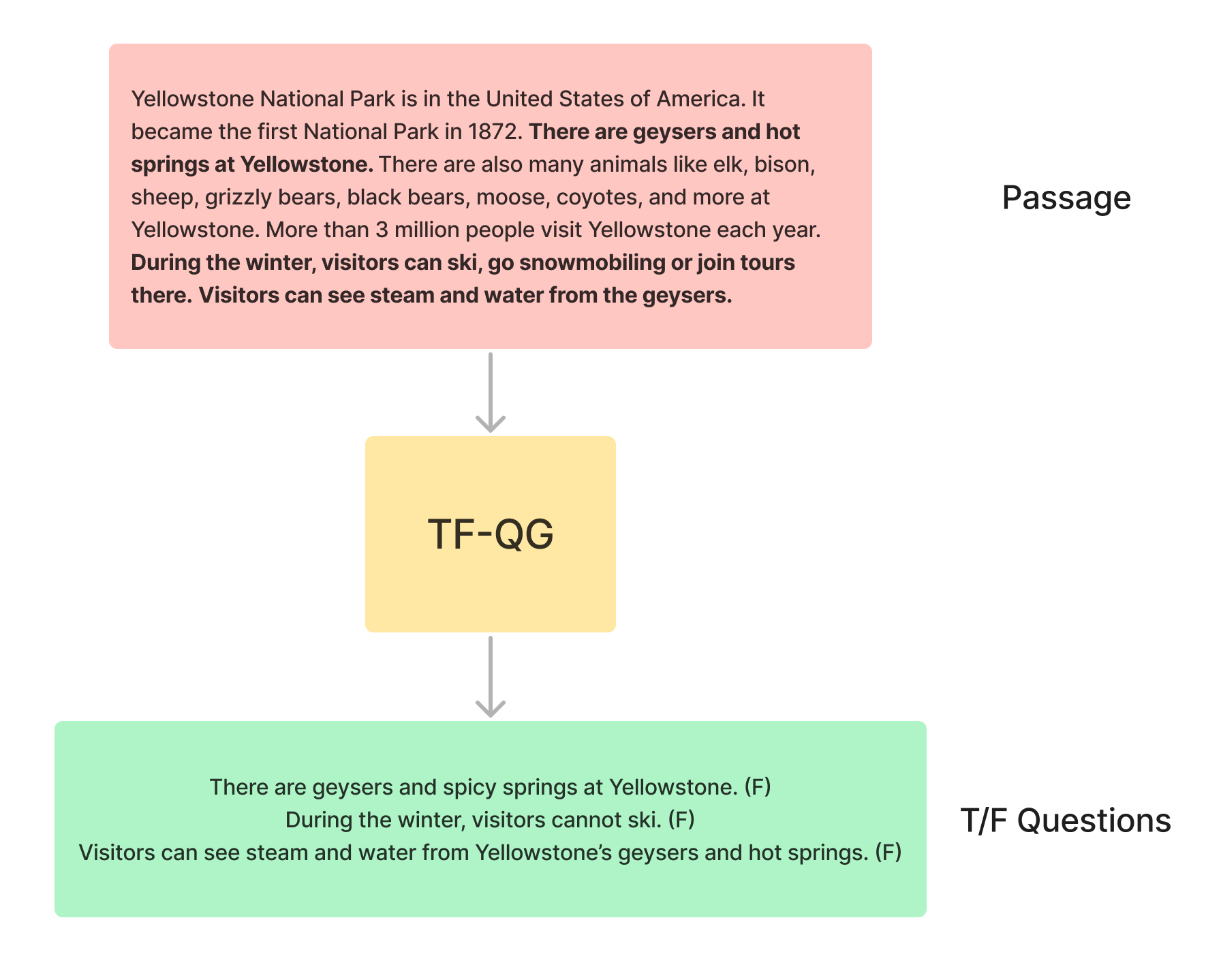
본 연구에서는 지문이 주어졌을 때 True/False 질문을 자동으로 생성해내는 태스크를 수행하는 TF-QG 모델을 제안합니다. 위의 그림에 예시가 나와 있는데, 지문이 모델의 input으로 들어가게 되면, 지문 내의 각 문장들을 변형하여 T/F 문제를 output으로 출력하고자 합니다. 지문에 볼드체로 표시되어 있는 부분이 각각 변형되어 T/F 문제가 된 것을 보실 수 있습니다. 그렇다면 해당 모델의 구조를 뜯어봅시다.
TF-QG Model
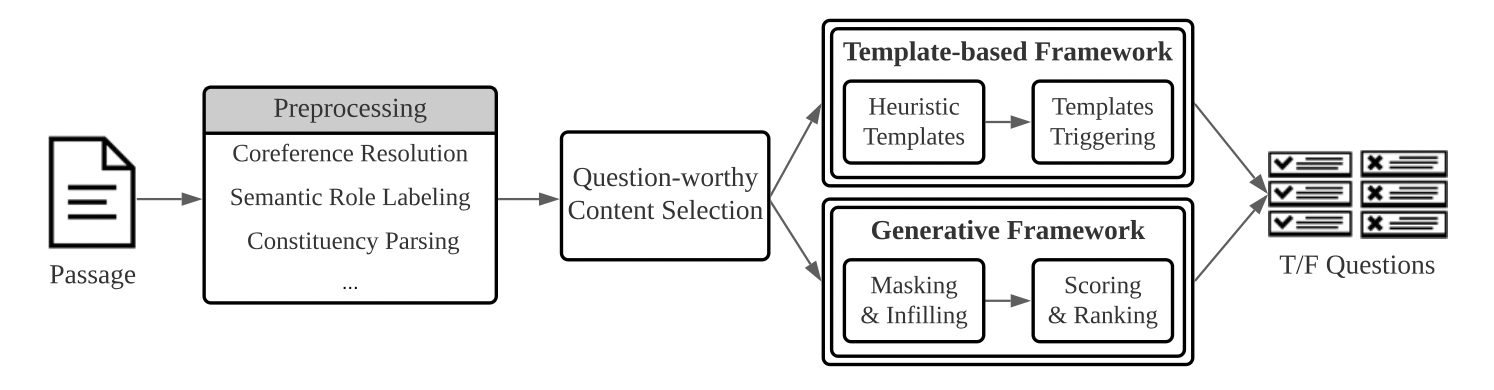
TF-QG 모델은 전처리를 통해 문법적, 의미적 정보를 추출한 후에 두 가지 종류의 프레임워크를 각각 통과할 수 있습니다. 연구에서 제시하는 첫 번째 프레임워크는 언어 교육적 측면에서 전문가들이 질문 가치가 있다고 생각하는 규칙에 따라 질문을 만드는 템플렛 기반 프레임워크입니다. 다음으로 제시하는 것은 규칙 기반 모델의 한계를 보완하여 더 유연하고 복잡한 질문을 생성할 수 있는 BART 모델을 활용한 생성 기반 프레임워크입니다. 두 가지 프레임워크를 통해 교육적으로 질문 가치가 있는 내용을 선정할 수 있습니다. 세부적으로 어떻게 모델이 구성되어 있는지 알아보도록 하겠습니다.
전처리
전처리 과정에서는 AllenNLP 라이브러리를 활용하여 지문에 대한 정보를 수집하며, 다음과 같은 자연어 처리 태스크를 수행하여 지문에 대한 핵심 정보들을 구조적으로 추출합니다.
- 상호 참조 해결 (Coreference resolution) → 개체 집합
- 의미역 결정 (Semantic role labeling) → 개체들에 대한 의미역 집합
- 구문 분석기 (Syntactic parsing) → 구문 트리
- 숫자 집합
템플렛 기반 프레임워크
교육에 도움이 되는 T/F Question의 조건으로서 지문과 비슷한 형태를 가지고 있으면서도, 교육적으로 의미 있는 부분을 잡아내야한다고 합니다. 따라서 본 연구에서는 언어 교육을 위해 중요하다고 판단되는 부분에 초점을 두어 휴리스틱한 템플렛들을 제시하였는데, 교육 목적의 여러 자연어 처리 태스크를 위해 참고해볼만한 부분인 것 같습니다. 제시된 템플렛들은 다음과 같습니다.
- 상호 참조 대체 (Coreference substitution, Coref)
- 대명사가 선행 명사로부터 한 문장 너머에 있다면 대명사에 선행명사를 넣어 True 문장 생성
- 관계 없는 명사를 넣어 False 문장 생성
- 등위 구조 변경 (Coordination modification, Coord)
- [명사1 접속사 명사2] 또는 [명사1, 명사2, .. 접속사 명사k]의 구조
- 임의의 명사를 선택한 후 ‘오직 명사 i 만이 …’ 또는 ‘어떤 명사도 …’의 템플렛을 사용하여 False 문장 생성
- 의미역 변경 (SRL modification, SRL)
- SRL set에 같은 의미역의 단어가 있다면, 두 개의 의미역을 각각의 문장으로 넣어 False 문장 생성
- 동의어/반의어 대체 (Synonym/Antonym substitution, Synonym/Antonym)
- 15 단어 이하의 짧은 문장에 형용사/부사가 있다면 동의어/반의어로 대체
- WordNet 사용
- 부정문 변경 (Negation Modification, Negation)
- 동사의 부정형 또는 단어가 Bioscope의 negative cue list에 있다면 부정 단어를 제거하여 False 문장 생성
- 숫자 변경 (Number Modification, Num)
- Numeral set에 한 개 이상 있다면, 각각의 문장에서 바꿔넣어 두 개의 False 문장 생성
- 정의 변경 (Definition Modification, Def)
- [NP1 <comma> NP2] → [NP1 <copula> NP2] 바꾸어 True 문장 생성
- 단순화 규칙 (Simplification Rule)
- 통사구조에서 SBAR와 IN+S 제거
- 두 콤마 사이의 내용 제거
- 문장 앞에 PP와 ADVP 제거
위의 템플렛들이 어떤 측면에 각각 초점을 두는지 다시 그룹화를 해보자면, 문맥, 단어, 문법/의미적인 측면으로 나누어 볼 수 있습니다.
| Template | Focusing aspect |
|---|---|
| Coref, Num, Def | Context meaning, number, definition |
| Synonym, Antonym | Lexical understanding |
| Coord, SRL, Negation | Syntactic or semantic understanding |
이러한 규칙 기반 질문 생성은 추후에도 교육자들의 필요에 따라 수정 및 2차 가공이 쉽고, 특정 답을 가정해두고 만들어진 템플렛이기 때문에 정답과 함께 질문 생성이 가능합니다. 하지만 다른 규칙 기반 자연어 처리의 한계점들처럼 템플렛을 만드는 교육자들이 어떤 종류의 질문을 할 것인지 high-level로 이해하고 있어야하며, 동시에 자연어 처리의 기본 공식들을 이해하고 있어야한다는 단점들이 있습니다.
딥러닝 기반 프레임워크
정해진 틀의 문장들만 생성해내는 규칙 기반 프레임워크와 달리 딥러닝을 기반으로 하면 조금 더 유연하고 어려운 문장 생성을 기대해 볼 수 있습니다. 연구에서 제시하는 딥러닝 기반 프레임워크의 큰 그림은 다음과 같습니다.
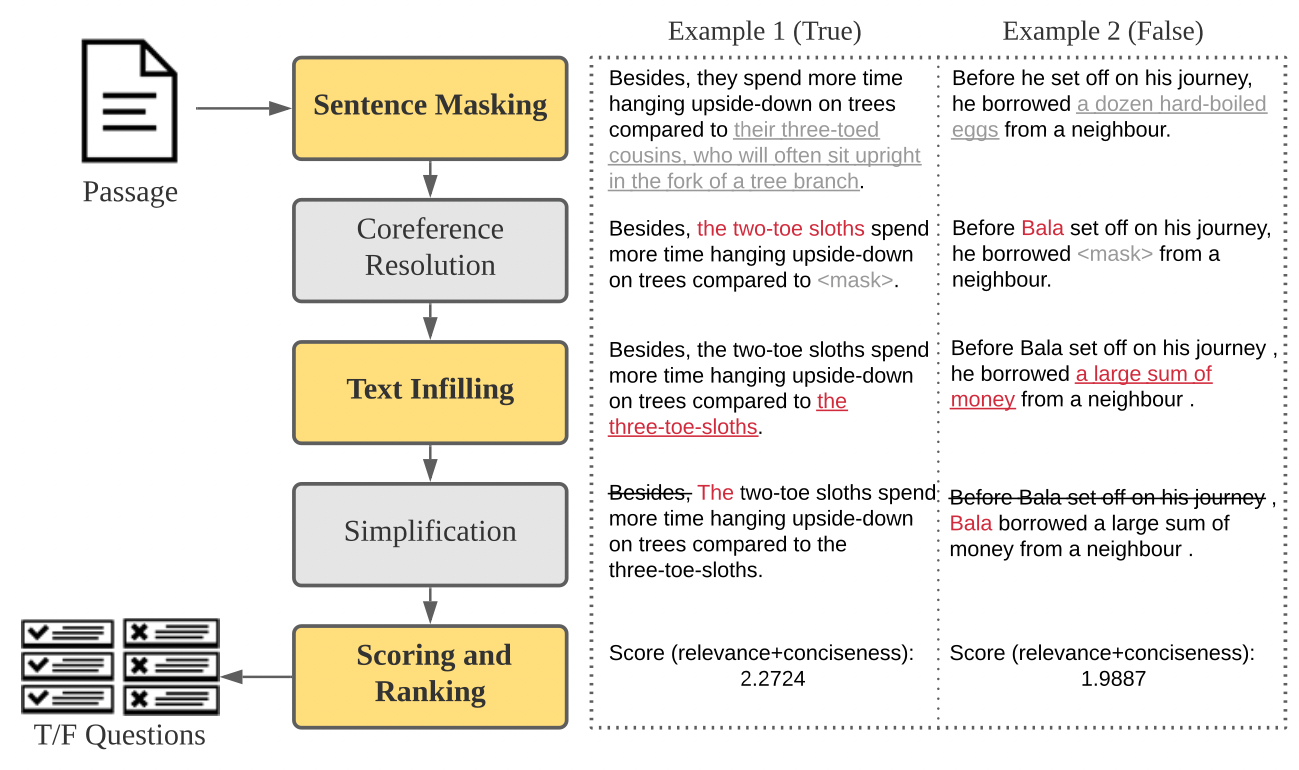
- 문장 마스킹 : 오른쪽의 두 예시를 보시면 우선 문장에서 중요하다고 판단되는 부분을 <mask> 처리합니다. 마스킹할 부분은 전처리한 결과를 사용하여 규칙 기반으로 선정합니다.
- 문장을 명확하게 하기 위해서 상호 참조 태스크를 통해 대명사는 선행 명사로 바꿔줍니다.
- 빈 칸 채우기 : 마스킹한 부분을 이전과 이후 맥락을 참고하여 채우는 태스크를 수행합니다. 빈 칸 채우기 태스크로 훈련된 BART 모델을 활용하여 이 단계를 수행합니다.
- 규칙 기반의 단순화 규칙으로 문장의 보조적인 요소들을 제거하여 문장을 간단하게 만들어 줍니다.
- 관련도와 정확도를 수치화하여 문장 점수를 내고 가장 높은 점수를 가진 문장을 최종 질문으로 채택합니다.
Results
평가 방식
해당 연구를 위한 자동 평가 데이터셋이 따로 존재하지 않기 때문에 임의의 20개의 지문들을 모델에 입력으로 넣어 생성된 문장들을 인간 평가자가 직접 여러 영역에 대해서 평가를 하였습니다. 평가자들은 교육 분야의 전문가들이며, 문장들에 대해 유창성, 문장 내의 의미적 연결성, 지문과의 관련성, 답변 가능 유무, 난이도에 대해서 평가를 하였습니다. 1개의 지문 당 템플렛 기반과 딥러닝 기반의 모델을 모두 통과하여 약 20개의 질문들을 생성하였습니다.
결과
평가된 문장들의 통계는 다음과 같습니다. 윗 줄은 규칙 기반으로 생성된 문장, 아래 줄은 딥러닝 기반으로 생성된 문장에 대한 결과입니다.
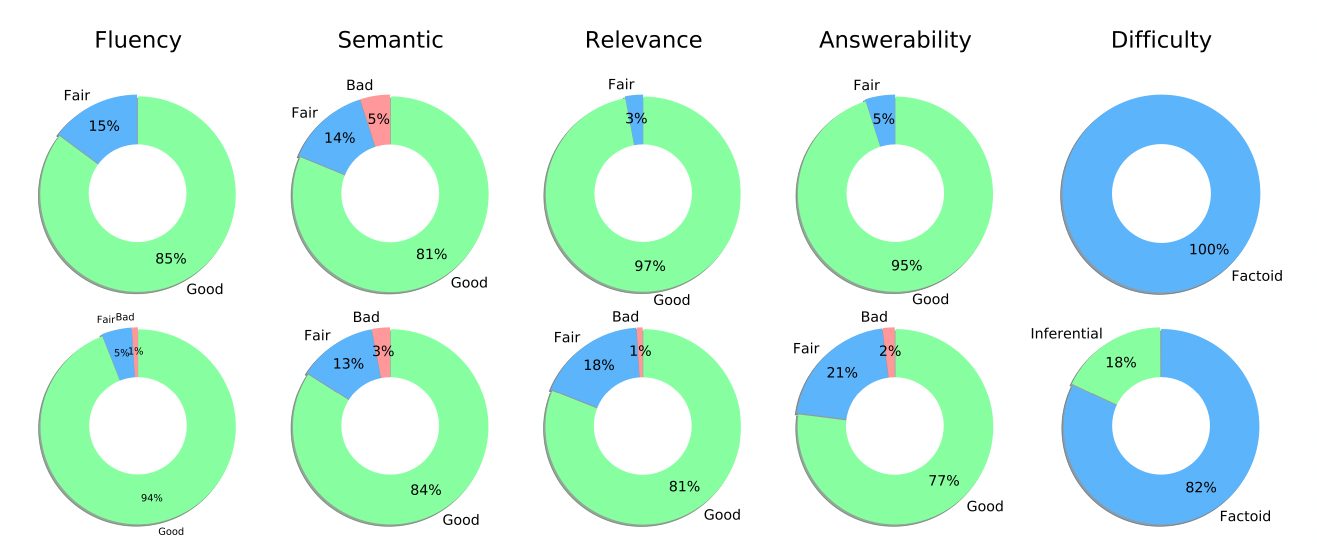
전반적으로 유창성, 의미, 관련도, 답변 가능 유무에서 좋은 결과를 보여주고 있습니다. 그래서 본 연구에서는 해당 모델은 교육 목적으로 학습 독해 능력 평가를 하기에 적합한 질문들을 생성한다고 이야기합니다. 하지만 난이도 통계를 보시면, 사실에 대해서만 묻는 단순한 문장들이 대부분입니다. 그나마 추론형 질문을 생성한 딥러닝 프레임워크마저도 18% 밖에 생성해내지 못했습니다. 연구자들은 현재 수준에서는 복잡한 질문을 생성하기에는 갈 길이 멀다고 이야기합니다.
각 프레임워크 별로 뜯어보자면, 규칙 기반 프레임워크는 관련성와 답변 가능성에서 좋은 성능을 보여주어 교육 목적에 적합한 질문을 만들어냈습니다. 정답을 염두에 두고 만들었기 때문에 더 좋은 성능을 보였을 것입니다. 다만, 정해진 틀에 의해 만들어졌기 때문에 문법이나 논리 오류가 존재하는 문장들이 있었습니다.
딥러닝 기반 프레임워크는 사전 훈련된 언어 모델 덕에 유창성과 의미적 연결성 측면에서 좋은 성능을 보여줍니다. 자연스럽게 읽히는 문장을 만들어내는 것은 학습자가 지속적으로 공부하게끔 동기 부여 하는 데에 중요한 요소입니다. 또한 추론형 문장을 생성해내는 것처럼 더 복잡한 형태의 문장을 기대해 볼 수 있습니다. 하지만 너무 유연한 나머지 문맥과 관련없거나 정답을 찾을 수 없는 문장을 만들어내는 것을 발견할 수 있었습니다.
Case Study
논문에서는 Yellowstone National Park에 대한 다음 지문을 가지고 case study를 진행하였는데, 향후 연구에 대한 인사이트를 줄 수 있는 것 같아 발췌해보았습니다.

템플렛 기반 생성 문장
해당 문장들은 상호 참조, 단어, 정의 이해와 같은 특정 지식들을 테스트하는 목적에 적합합니다.
원문: There are geysers and hot springs at Yellowstone
생성문: There are geysers and spicy springs at Yellowstone. (F)
- Template : 동의어
템플렛을 기반으로 생성된 문장들은 교육 목적에 맞는 지식을 물어보지만, 문맥정보를 반영하지 않기 때문에 잘못된 동의어로 변경되어 있습니다.
원문: During the winter, visitors can ski, go snowmobiling or join tours there
생성문: During the winter, visitors cannot ski. (F)
- Template : 등위 구조 변경 + 부정문
단순하게 동사를 부정으로 만들었습니다.
원문: Most visitors want to see Old Faithful, a very predictable geyser at Yellowstone.
생성문: Old Faithful is a very predictable hot spring at Yellowstone. (F)
- Template : 정의 변경 + 등위 구조 변경
템플렛의 목적에 맞게 비슷해보이는 개념을 구별할 수 있는지 물어보는 질문을 생성했습니다.
원문: Boiling water is 100 degrees Celsius, or 212 degrees Fahrenheit - that’s very hot!
생성문: Boiling water is 212 degrees Celsius. (F)
- Template : 숫자 변경
이 문장 또한 템플렛의 목적에 맞게 섭씨와 화씨의 개념을 구분할 수 있는지 묻고 있습니다.
원문: It has many beautiful colors, which are caused by bacteria in the water.
생성문: The Grand Prismatic Spring has many ugly colors, which are caused by bacteria in the water. (F)
- Template : 상호 참조 대체 + 반의어
대명사와 단어 이해를 제대로 했는지를 묻고 있습니다.
딥러닝 기반 생성 문장
해당 문장들은 더 유연하고 비교적 어려우며, 학습자가 문맥 정보를 파악했는지 알 수 있는 추론형 질문을 만들 수 있습니다.
원문: Visitors can see steam and water from the geysers.
생성문: Visitors can see steam and water from Yellowstone’s geysers and hot springs. (F)
- Protocol : 전치사구
원문: Most visitors want to see Old Faithful, a very predictable geyser at Yellowstone.
생성문: Most visitors want to see Old Faithful when it is erupting. (T)
- Protocol : 의미역
Old Faithful이 erupt 한다는 문맥적 정보를 파악하고 있어야 생성할 수 있는 문장입니다.
원문: Great Fountain Geyser erupts every 11 hours up to a height of 67 metres.
생성문: Yellowstone National Park is home to the world’s largest geyser, Yellowstone Geyser, which erupts every 11 hours up to a height of 67 metres.(F)
- Protocol : 의미역
원문: Boiling water is 100 degrees Celsius, or 212 degrees Fahrenheit - that’s very hot!
생성문: The temperature of the geyser water is about 100 degrees Celsius, or 212 degrees
Fahrenheit - that’s very hot! (T)
- Protocol : 숫자
“끓는 물은 geyser로부터 나온다"라는 전제를 모델이 인지하고 있다는 것을 알 수 있는 문장입니다. 이러한 추론형 문제는 학습자의 문맥적 일관성 이해 여부를 파악할 수 있습니다.
원문 : These are forms of life that have only one cell.
생성문: These are forms of life that live on the surface of water. (?)
- Protocol : 종속절
하지만 잘못된 상호 참조 또는 관련없는 내용을 생성하여 답변할 수 없는 문장을 만들기도 합니다
리뷰를 마치며
본 논문을 리뷰하면서 교육 도메인에서의 NLP 태스크를 수행할 때 참고해 볼 만한 점들이 있었습니다. 교육적 측면에서 “Question-worthy”한 질문에 대한 개념에 초점을 두어 체계화하였고, 규칙 기반, 딥러닝 기반 방법론들을 통해 질문의 가치가 있는 부분들을 잡아내어 질문을 생성하였습니다. 특히 규칙 기반 프레임워크에서는 직접 다양한 템플렛을 가공하였는데, 교육적 측면에서 어떤 feature들을 사용하여 언어적 이해도를 측정할 수 있는지 생각해볼 수 있는 지점이었습니다. 또한 교육 목적을 위한 자연어 처리 태스크는 자동 평가를 위해 가공된 데이터셋이 없는 경우가 대다수인데 이 경우에 annotator를 활용하여 간단하게 평가할 수 있는 지표와 방법론 또한 참고해볼 만하다고 생각했습니다. 마지막으로 Case study에서 규칙과 딥러닝 기반의 프레임워크가 생성해내는 문장들을 짚어보면서 각 프레임워크의 장점과 한계점을 파악할 수 있었으며, 향후 연구에서 문맥적 정보를 고려하면서도 교육 목적에 맞는 문장들을 생성할 수 있을 지 생각해 볼 좋은 기회가 되었던 것 같습니다.
※ 잘못된 해석이나 내용, 피드백 사항은 댓글에 남겨주시면 감사하겠습니다.
