Data Preprocessing

입력 데이터 전처리
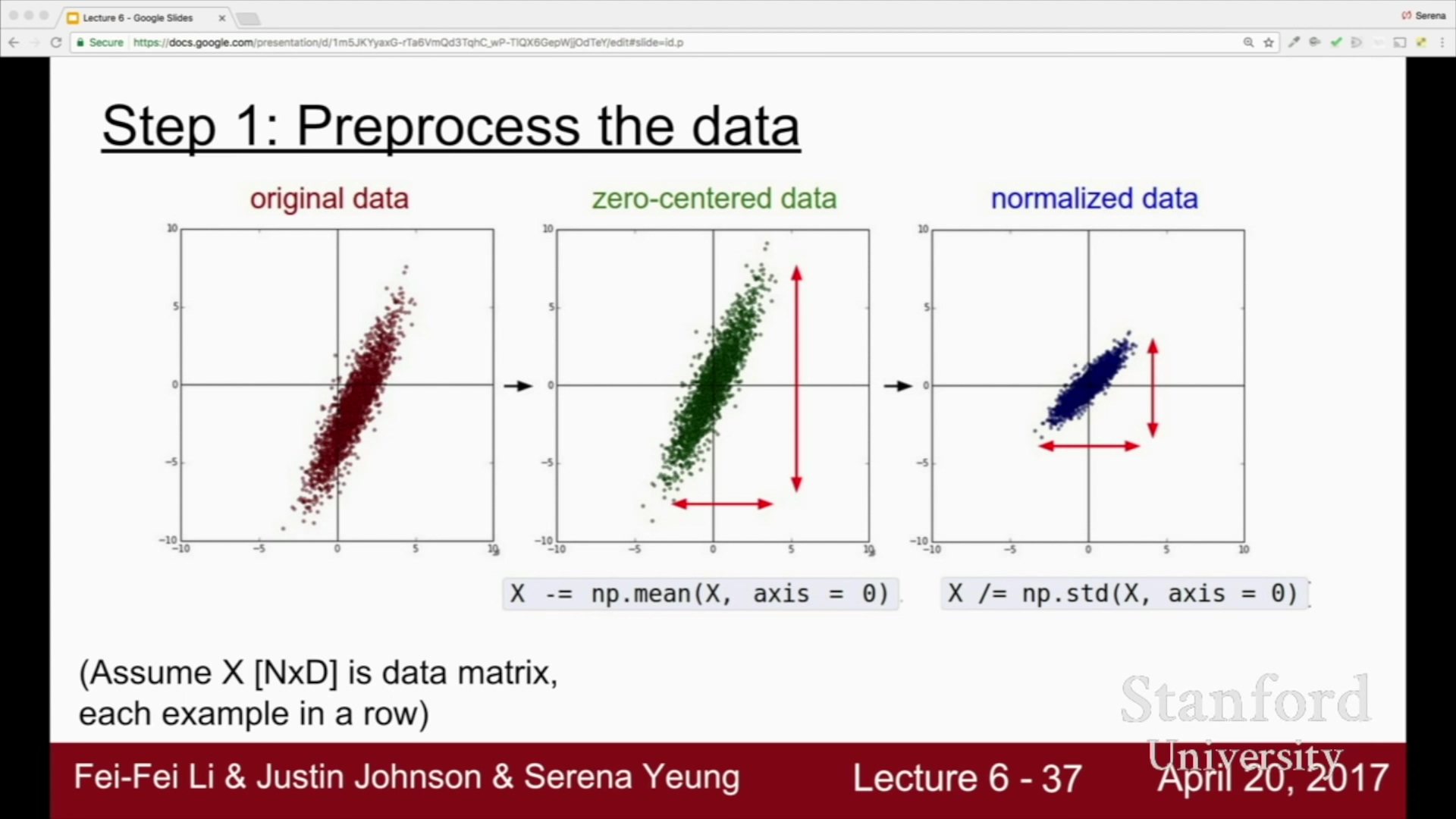
대표적인 전처리:
zero-mean 으로 만들고 normalize (보통 표준편차)
zero-centered
전체의 평균을 구하고, 각각을 빼 줌.
정규화
표준편차로 나누어 줌.
-1 ~ 1 혹은 0 ~ 1 과 같이 특정범위 내로 들어가도록 함.
이미지는 이미 특정 범위 (0 ~ 255)

앞에서, 입력이 모두 Positive인 경우, 모든 뉴런이 positive인 gradient를 가짐.
입력이 전부 negative인 경우도 마찬가지.
normalization을 하는 이유는,
모든 차원이 동일한 범위 안에 있게 하여, 전부 동등한 기여를 하게 됨.
이미지의 경우는, 전처리로 zero-cetering 정도만 해 줌.
스케일링이 어느 정도 맞춰져 있기 때문.
스케일링이 다양한 경우가 아닌, 이미지에서는 정규화를 너무 잘 할 필요 없음.
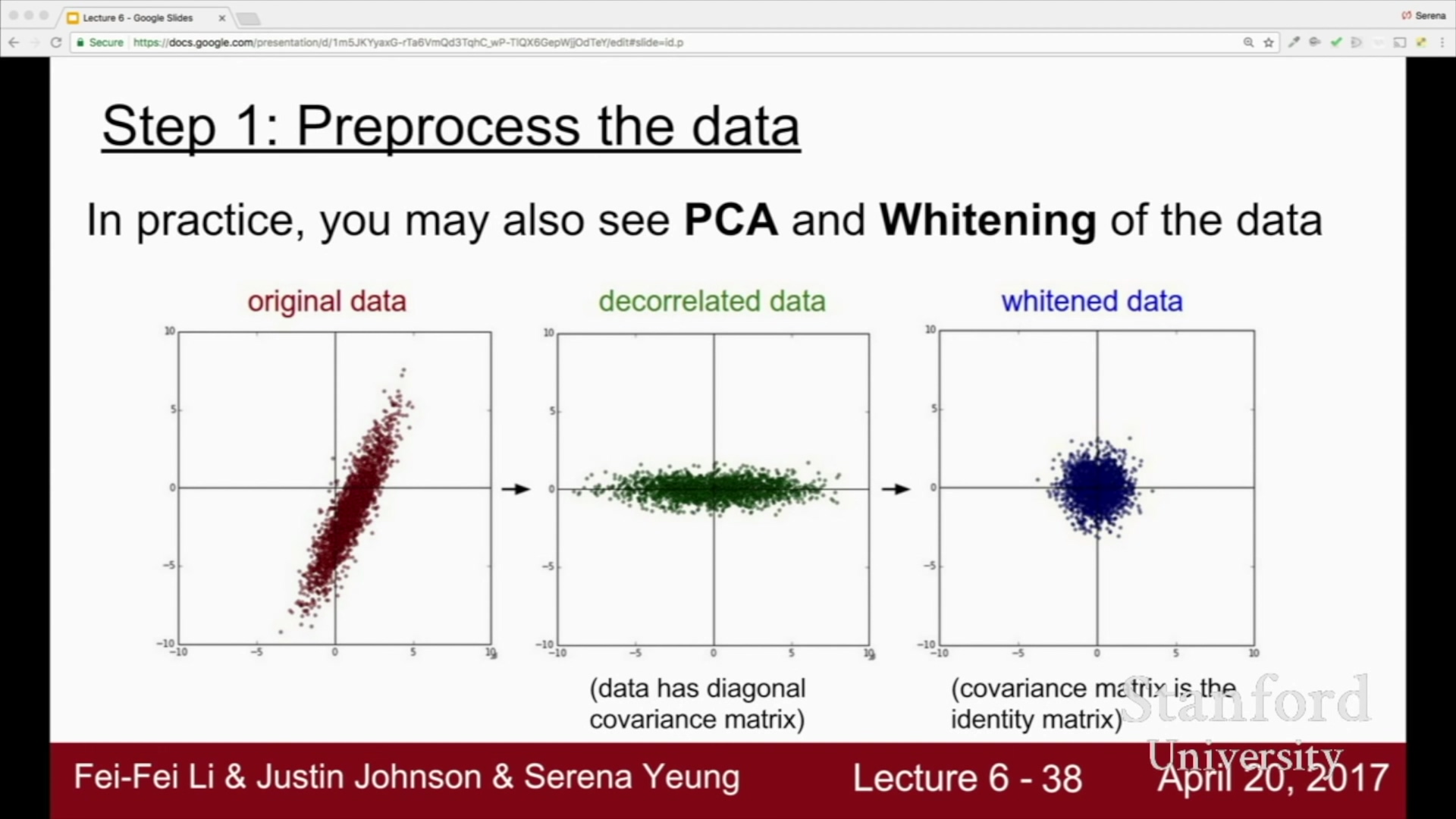
PCA (주성분 분석)나 Whitening 같은 더 복잡한 전처리 과정도 있다.
- PCA (Principal Component Analysis) :
- 고차원 데이터 집합을, 원래의 고차원 데이터와 가장 비슷하면서
더 낮은 차원의 데이터를 찾아내는 방법 - 데이터를 정규화시키고 공분산(Covariance) 행렬을 만든다.
- 데이터를 비상관화하여 차원을 줄임.
- 고차원 데이터 집합을, 원래의 고차원 데이터와 가장 비슷하면서


- Whitening
- 기저벡터(eigenbasis) 데이터를 아이젠벨류(eigenvalue)값으로 나누어
정규화하는 기법 - 1e-5 같은 작은 수가 아닌 더 큰 수를 분모에 더하는 방식으로 스무딩
(smoothing) 효과를 추가하여 노이즈를 완화시킬 수 있다. - 인접하는 픽셀의 중복을 줄여줌.
- 기저벡터(eigenbasis) 데이터를 아이젠벨류(eigenvalue)값으로 나누어


- PCA & Whitening도 이미지 전처리 주로 사용되는 것은 아니다.
CNN에서는 원본 이미지 자체의 공간 정보를 이용해서,
공간 구조를 얻을 수 있도록 함.
[질문] Train에 전처리 하면, Test에도 전처리해야 하나?
Training data에서 얻은 평균을 그대로 Test에 사용.
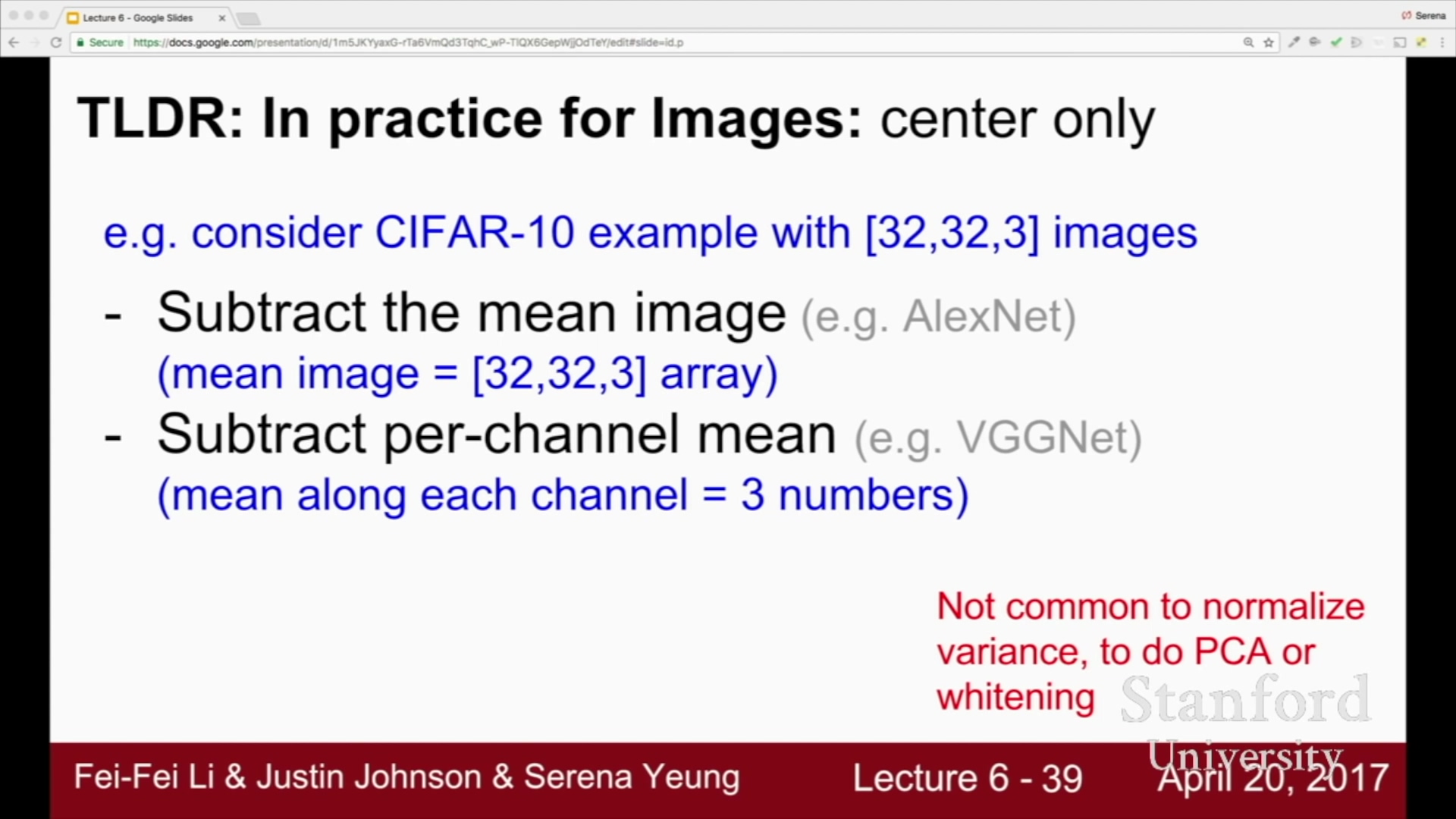
보통 입력이미지의 사이즈를 서로 맞춰줌.
-
AlexNet의 경우, 오렌지 색을 빼줌.
-
전체의 평균을 구하지 않고,
채널마다 평균을 독립적으로 계산하는 경우도 있음.
VGGNet -
평균은 어떻게 구하는가?
Training data 전체에 대하여 평균을 구함. -
질문은 미니배치 단위로 학습해도, 평균은 미니배치 단위가 아니라 전체로 계산하는가?
Yes. 트레이닝 데이터 전체의 평균
배치에서 뽑은 데이터도 전체 데이터에서 나온 것이고,
결국 배치 평균이나 전체 평균이나 구해보면 이상적으로는 같다.
그러나 반대로, 엄청나게 큰 데이터의 전체 평균을 구할 때는,
적절하게 샘플링하여 구할 수도 있다.
- 데이터 전처리가 Sigmoid 문제를 해결할 수 있는가?
우리가 수행할 전처리가 zero mean.
Sigmoid에게는 zero-mean이 필요하다.
데이터 전처리가 Sigmoid의 zero-mean 문제에 대해서는, 1번째 레이어에만 효과 있음.
하지만, 다음 레이어부터는 똑같은 문제가 반복될 것.
깊으면 깊을수록 더 심해짐. non-zero-mean
- RGB를 0~1 로 normalization 하는 이유
https://light-tree.tistory.com/132
