ㅏ
46:05
Nearest Neighbor
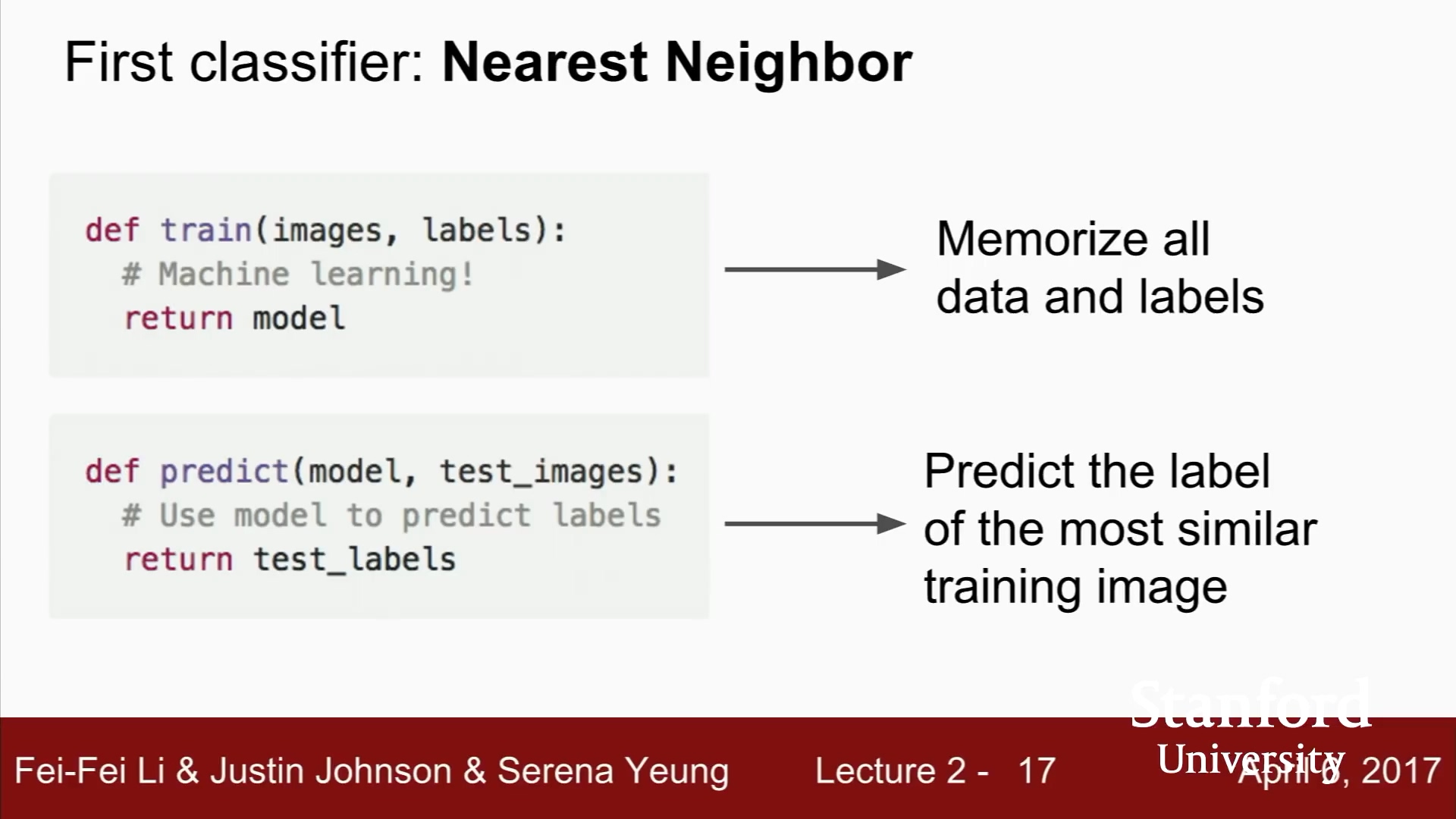




하나하나 비교하므로 시간이 오래 걸린다.
학습시간이 길고, 예측은 빨라야 하는데, 반대상황
실제로는 사용되지 않는다.

점은 학습데이터
점의 색깔로, 카테고리 5개임을 알 수 있다.
2차원으로 표현.
가장 가까운 이웃만을 보기 때문에, 초록색 가운데 노란색 등장.
파란색 영역에 초록색이 침범.
잡음(noise)거나 가짜(spurious)
이러한 단점으로, kNN 등장
단순히 가까운 이웃을 찾기 보다는,
majority vote
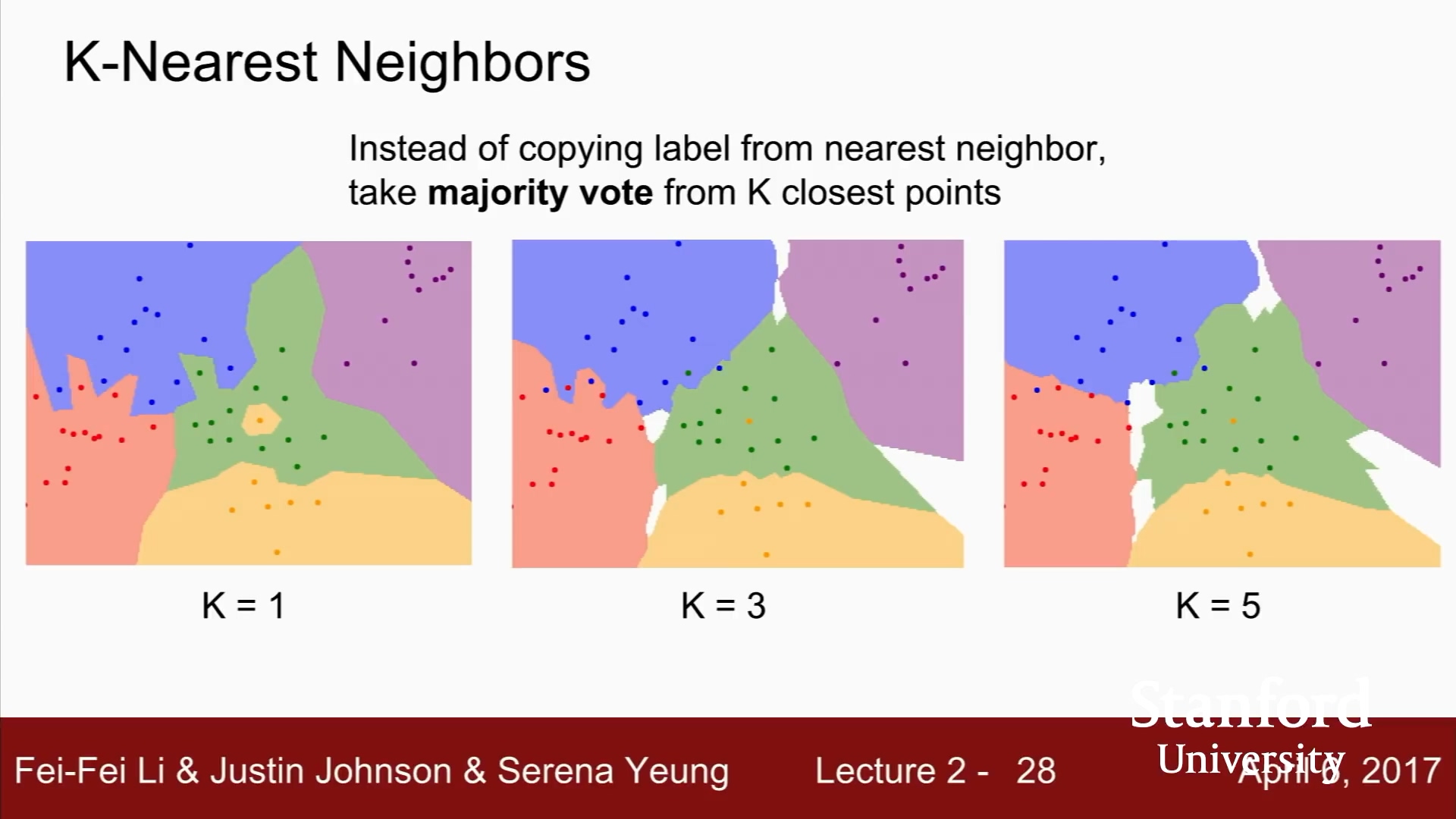
침범했던 노란색, 초록색 사라짐.
뾰족한 경계들도 사라지고 부드러워짐.
k가 1보다 커야 함.
흰색은 k-NN이 다수를 결정할 수 없는 영역.
여기서는 가장 가까운 이웃이 존재하지 않는 영역.
Computer Vision
관점
이미지를 고차원에 존재하는 하나의 점. 고차원 벡터로 보는 관점.
이미지를 이미지 자체로 보는 관점
이미지를 다루는데 k-NN은 성능이 좋지 않다.
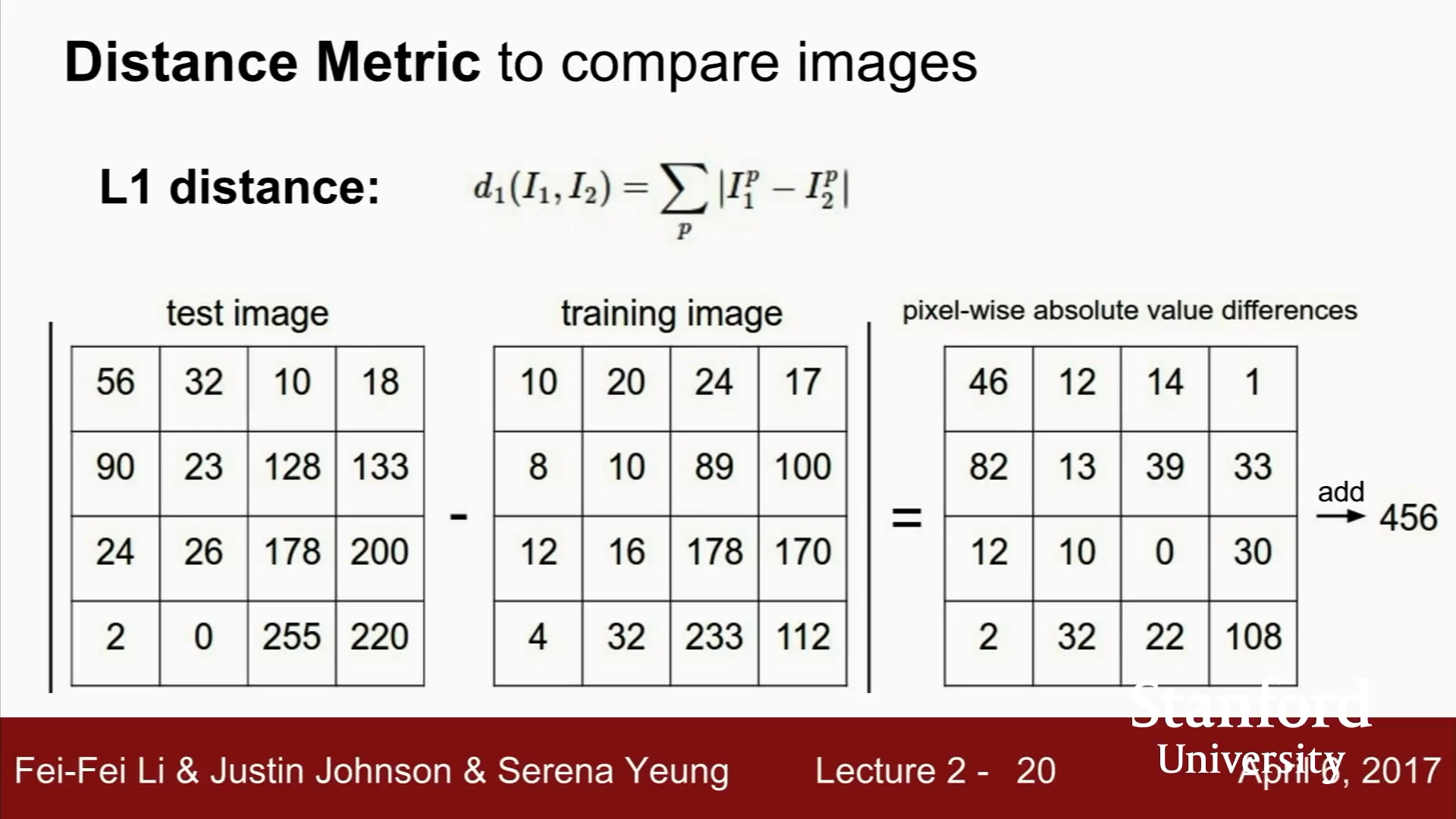
지금까지는 L1 Distance
픽셀 간의 절대값의 차이

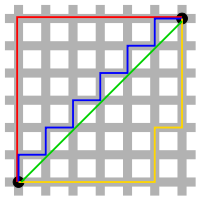
L1, Manhattan distance
L2, Euclidean distance
L1 관점에서의 원
원점을 기준으로 하는 사각형
L1은 어떤 좌표시스템이냐에 따라 많은 영향을 받음.
기존 좌표계를 회전시키면 L1 distance가 변한다.
L2 좌표계와 연관이 없다.
특징 벡터가 일반적이고, 요소들 간의 실질적인 의미를 잘 모를 때.
k-NN에 댜양한 거리 척도를 사용하면,
다양한 종류의 데이터를 다룰 수 있다.
벡터나 이미지 외에도, 문장 분류 등에도 거리를 측정할 수 있는
거리 척도가 있다면 무엇이든 사용 가능.
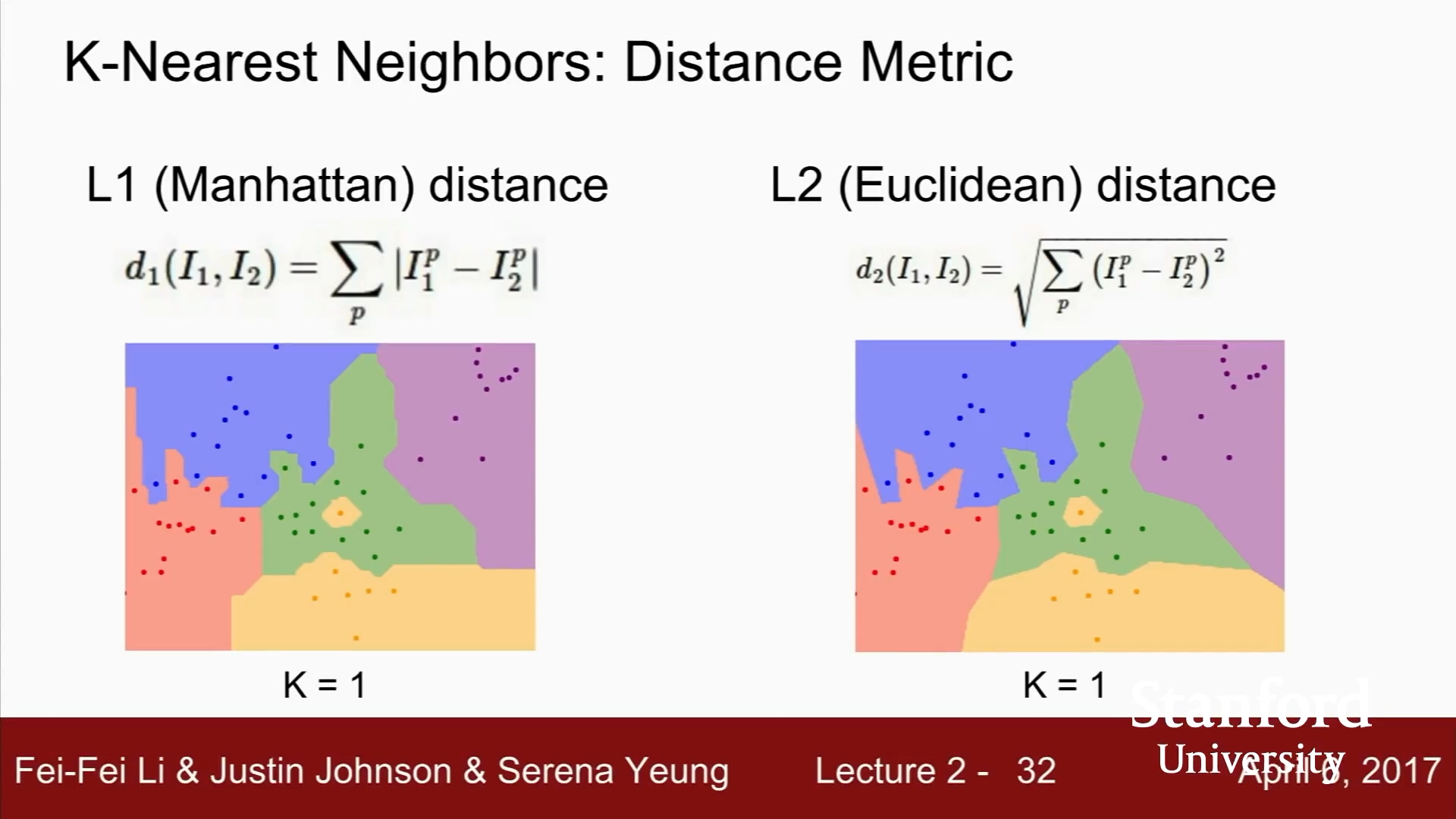
L1 Distance 는 결정 경계가 좌표축에 영향을 받음.
K-Nearest Neighbors Demo
http://vision.stanford.edu/teaching/cs231n-demos/knn/
데모 생략
k 와 거리척도를 바꾸면 결정경계가 어떻게 만들어지는지 직관 얻길 바람.
데이터와 문제에 맞는 모델을 찾기.
k 와 거리척도를 '하이퍼 파라미터'라고 함.
학습에서 결정하는 것이 아니므로, 학습 전 결정해야 함.
데이터로 직접 학습시킬 방법이 없음.
하이퍼 파라미터를 정하는 일은,
문제 의존적(problem-dependent)임.
데이터에 맞게 다양한 hyperparameter를 시도해 보고 가장 좋은 값을 찾는다.
[질문]
어떤 경우에 L1 Distance가 L2 Distance 보다 더 좋은가?
문제 의존적이다.
L1은 좌표계에 의존적이므로, 데이터가 좌표계에 의존적인지 판단하는 것이, 판단기준이 될 수 있다.
특징 벡터가 있고, 각 요소가 어떤 특별한 의미를 지니고 있다면,
가령, 직원 분류시, 데이터의 각 요소가 직원들의 다양한 특징에 영향을 줄 수 있다. 봉급이나 근속년수 등
각 요소가 특별한 의미를 가지고 있다면, L1이 나을 수도 있다.
hyperparameter는 데이터와 문제 의존적이다.
여러가지 시도를 해보고 좋은 것을 선택하라.
"다양한 hyperparameter를 시도하는 것"과 "그 중 최고를 선택하는 것"의 차이
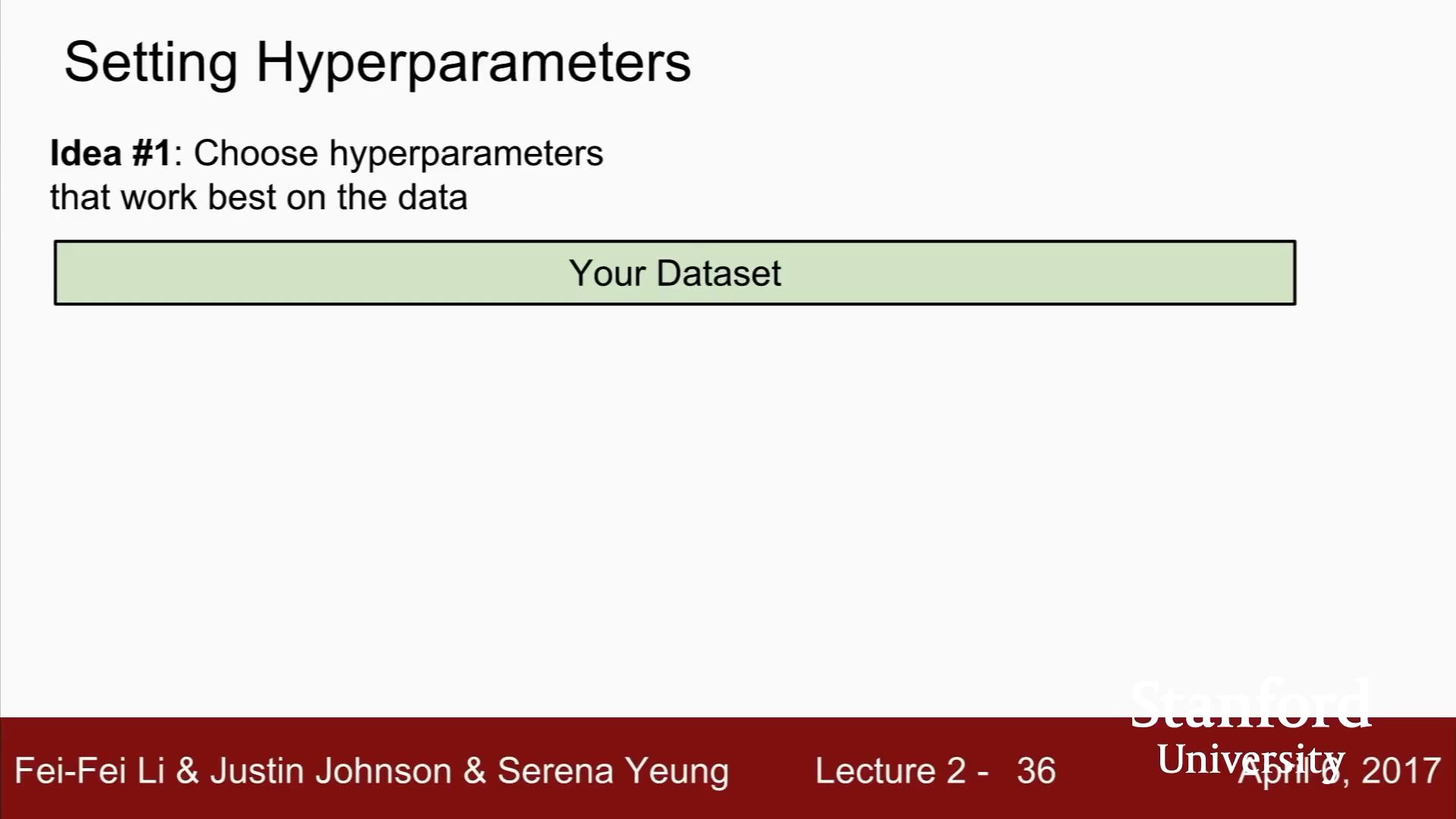
학습데이터의 정확도와 성능을 최대화 하는 하이퍼파라미터 선택.
끔찍한 방법.
NN Classfier (분류기)의 경우, k = 1 일 때,
학습데이터를 가장 완벽하게 분류

k 를 더 큰 값으로 선택하는 것이, 학습데이터를 몇 개 잘못 분류할 수 있지만, 학습 데이터에 없던 데이터에 대해서 더 좋은 성능을 보일 수 있다.
궁극적으로, ML에서 train(학습) 데이터를 얼마나 잘 맞추는지는 중요하지 않다.
학습시킨 분류기가 한 번도 보지 못한 데이터를 잘 예측하는 것이 중요하다.
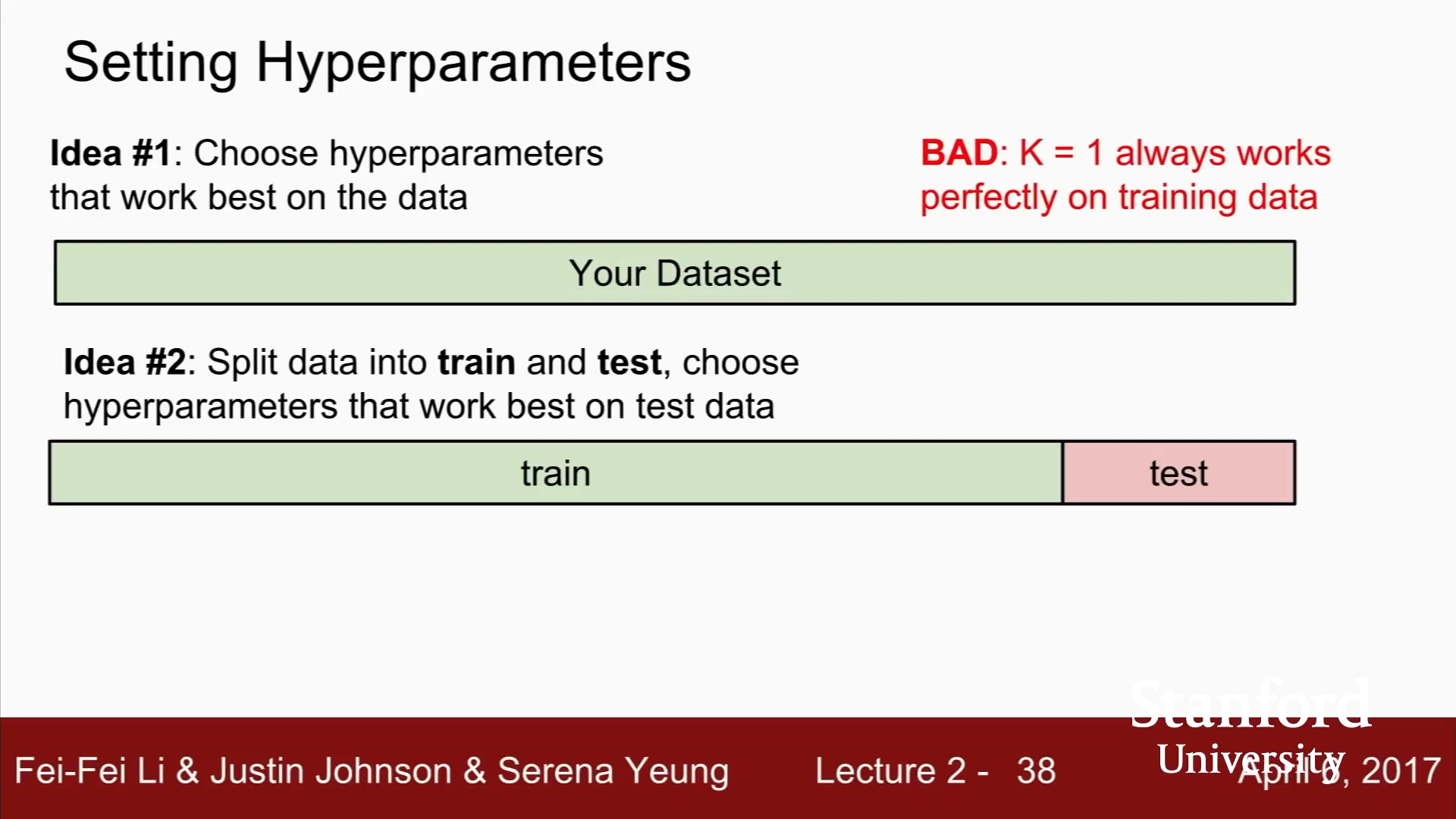
이 방법 또한 끔찍하다. 절대 해서는 안된다.
학습 시킨 모델 중에서 테스트 데이터에 가장 잘 맞는 모델을 선택한다면, 그저 테스트 셋에서만 잘 동작하는 하이퍼파라미터를 고른 것 일 수 있다.
테스트 셋에서의 성능은 한번도 보지 못한 데이터에서의 성능을 대표할 수 없다.
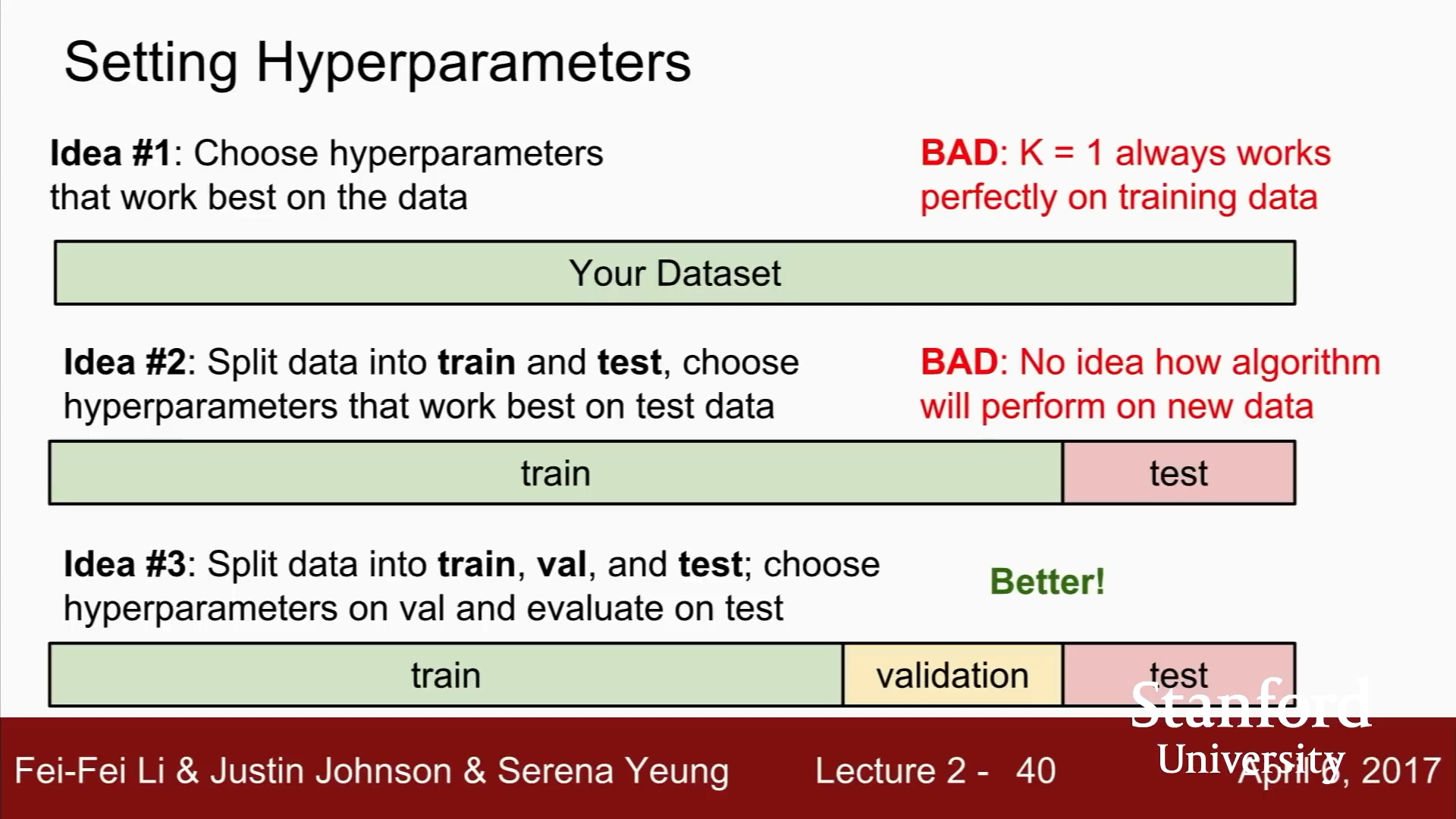
다양한 하이퍼파라미터로 '트레이닝 셋'을 학습시킨다.
그리고, '벨리데이션 셋'으로 검증하고,
'벨리데이션 셋'에서 가장 좋았던 하이퍼파라미터를 선택한다.
최종적으로 개발/디버깅 모든 일이 다 끝난 후에,
'validation set'에서 가장 좋았던 hypermarater로 딱 한 번 수행.
이 마지막 수치가 여러분의 논문과 보고서에 삽입될 것입니다.
연구논문 작성시, 테스트셋은 거의 마지막 쯤에 사용.
저저의 경우, 논문 마감 일 주일 전부터만 테스트셋 사용.
그 숫자가 여러분의 알고리즘이 한 번도 보지 못한 데이터에서,
얼마나 잘 동작하는지 실질적으로 말해 줄 수 있다.
5-Fold Cross Validation
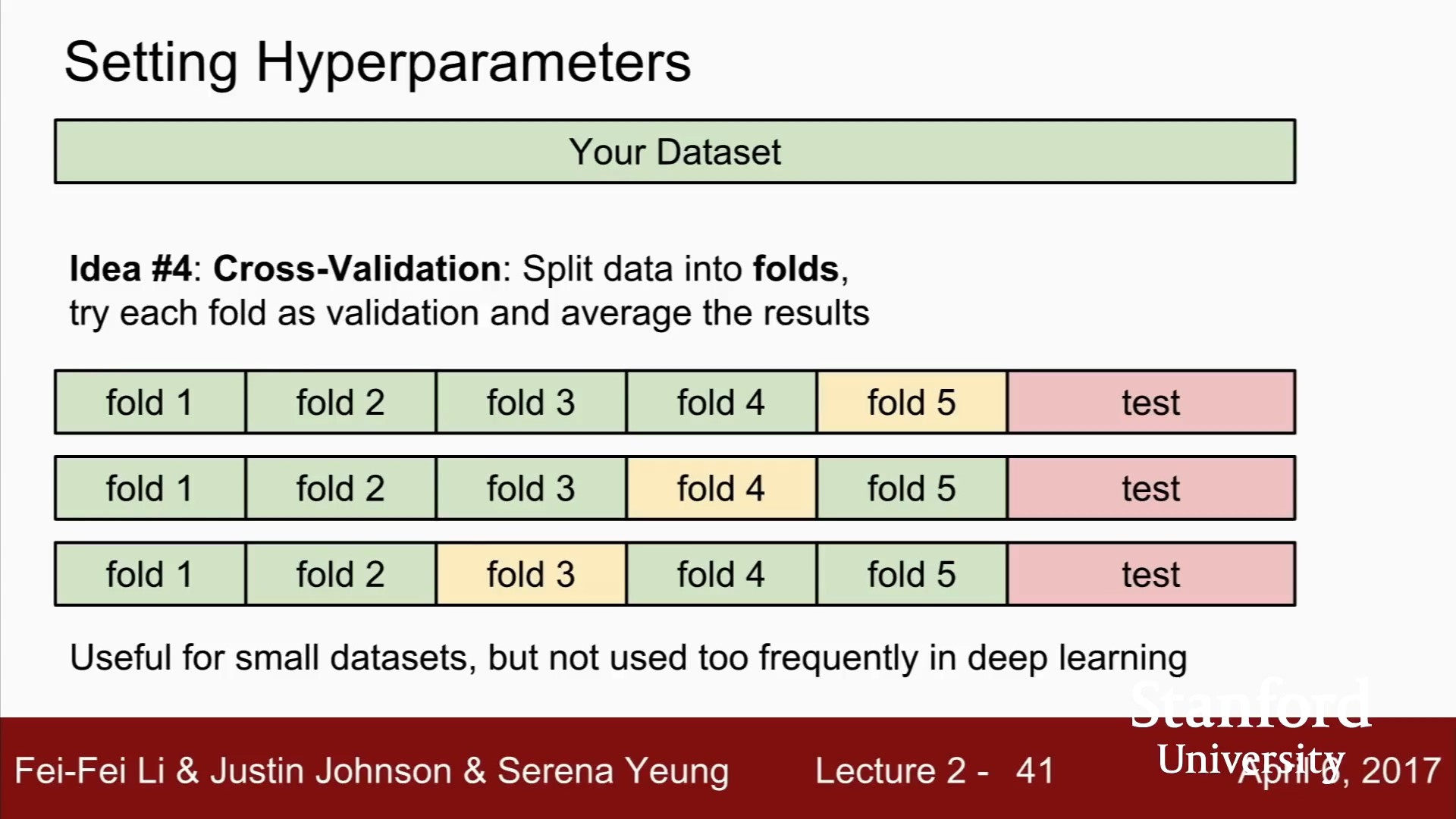
fold 1~4 학습하고, fold5로 평가
fold 1~3, fold 5 학습하고, fold 4로 평가
...
최적의 하이퍼파라미터를 확인할 수 있고, 표준이지만,
딥러닝 같은 큰 모델은 학습시 계산량이 많아서,
실제로는 잘 쓰지 않는다.
[질문]
트레이닝셋은 레이블을 기억하고 있는 이미지.
이미지를 분류하려면 트레이닝 셋의 모든 이미지들과 비교.
그리고 가장 근접한 레이블을 기억.
알고리즘은 트레이닝 셋 자체를 기억할 것이다.
벨리데이션 셋에서는,
분류기가 정확도가 얼마나 나오는지 확인.
벨리데이션 셋의 레이블은 알고리즘이 얼마나 잘 동작하는지 확인에만 사용.
[질문]
테스트셋이 한번도 보지 못한 데이터를 대표할 수 있는가?
통계학적 가정.
여러분의 데이터는 독립적이며, 유일한 하나의 분포에서 나온다는 가정.
모든 데이터는 동일한 분포를 따른다고 생각해야 함.
실제로는 그렇지 않은 경우가 많습니다.
datasets crators 와 dataset curators가 생각해 볼 문제.
데이터 수집시, 일관된 방법론을 가지고, 대량의 데이터를 한번에 수집하는 전략.
이후, 무작위로 트레이닝과 테스트 데이터로 나눔.
- 데이터를 지속적으로 모을 시 주의.
먼저 수집한 데이터를 트레이닝 데이터로 쓰고,
이후 모은 데이터를 테스트 데이터로 쓰면 문제가 될 수 있다.
데이터셋 전체를 무작위로 섞어서 데이터셋을 나누는 것이, 문제를 완화시킬 수 있는 한 가지 방법.
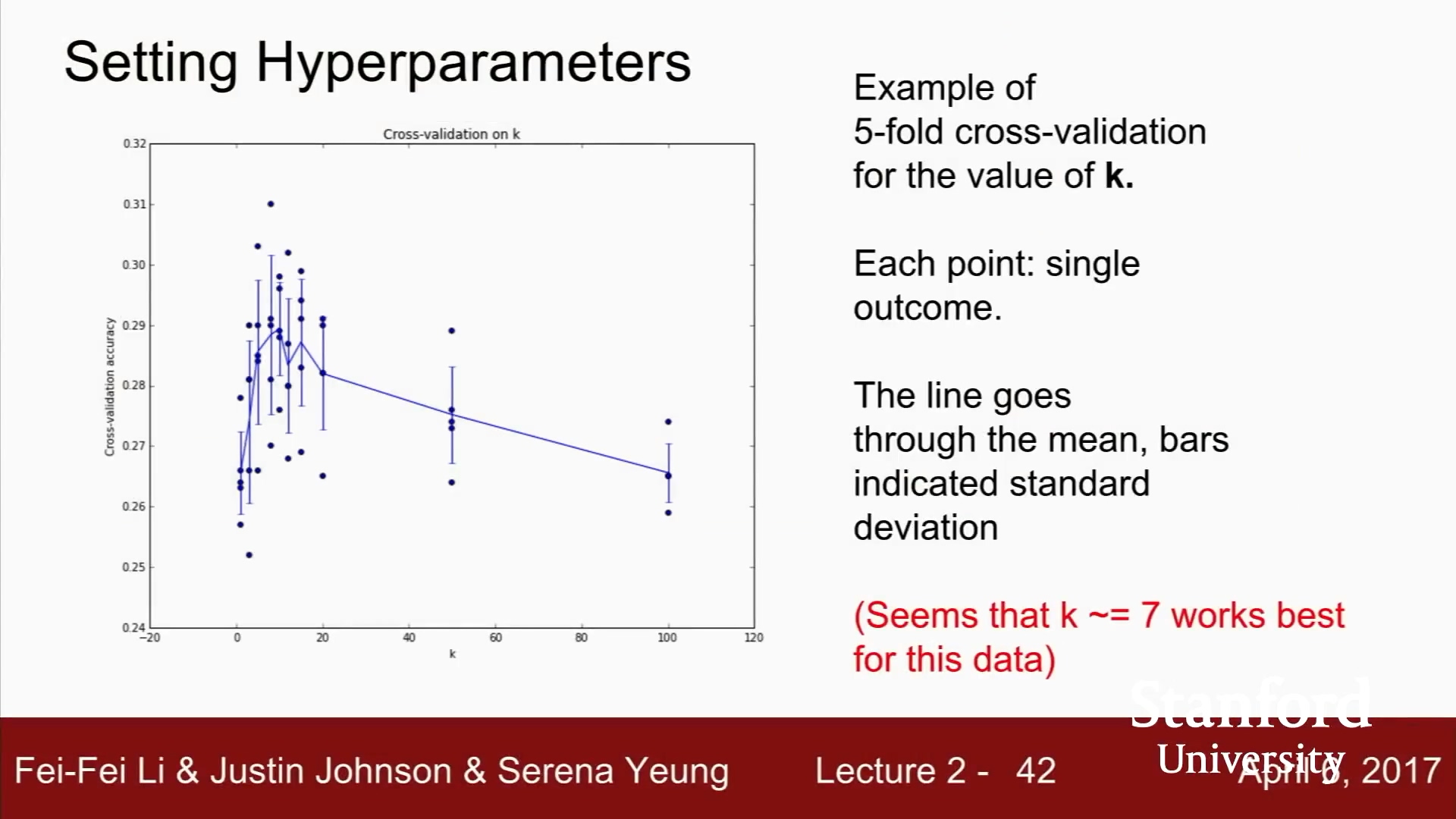
x축은 k-NN의 k.
y축은 분류정확도
이 경우는 k가 7일 때 가장 좋았다고 함.

이미지 분류에 k-NN은 잘 사용하지 않는다.
-
k-NN은 너무 느리다.
-
L1, L2 distance가 이미지 간의 거리를 측정하기에 적절하지 않다.
이미지 간의 '지각적 유사성'을 측정하는 척도로 적절하지 않다.
이미지를 변화시킨 다음, 유클리드 거리 측정 해 보면,
모두 동일한 L2 distance를 가진다.
다른 이미지라고 함.
'지각적 차이'를 캡쳐하지 못함.
- 차원의 저주
k-NN이 하는 일은 학습 데이터를 이용하여, 공간을 분할 하는 일.
k-NN이 잘 동작하려면, 전체공간을 조밀하게 커버하는 충분한 샘플 데이타가 필요함.
공간을 덮으려면, 충분한 학습 데이터가 필요하고, 그 양은 차원이 증가함에 따라 기하급수적으로 증가함.
고차원 이미지라면, 모든 공간을 조밀하게 메울만한 데이터를 모으는 일이 불가능 하다고 함.
이미지 분류가 무엇인지 설명하기 위해, k-NN 예제를 들어보았다.

[질문]
각 점의 의미?
각 점은 데이타를 의미.
각 점의 색은 속한 카테고리를 나타냄.

차원이 커지면, 덮어야 할 데이터가 기하급수적으로 증가한다.
2차원에서는 곡선이지만,
3차원이 되면, 여러 곡선이 보인다.
하지만, k-NN 알고리즘은 샘플들의 manifolds를 가정하지 않는다.

[질문]
이미지의 L2 distance 무슨 의미인가?
L2 distance가 맞지 않음을 보여주기 위해, 그렇게 만들었다.
실제 이 이미지들은 서로 다르다.
여러분이 k-NN을 사용한다면,
이미지 간의 유사도를 특정할 수 있는 유일한 방법은,
단일 거리 성능 척도 (L1, L2 등)를 이용하는 수 밖에 없다.
Distance metric이 실제로는 이미지 간의 유사도를 잘 포착하지 못한다.
- 이 예시는 이러한 translation과 offset에도 distance가 일치하도록 임의로 만들었다.
[질문]
이미지가 모두 같은 사람이므로,
distance가 같으면 좋은 것이 아닌가?
이 예시에서는 그럴 수도 있다.
하지만, 서로 다른 2개의 원본 이미지가 있고,
어떤 적절한 위치에, 박스를 놓거나, 색을 더하거나 하면,
2개의 distance가 엄청 가깝게 만들 수 있다.
임의로 움직이면, distance가 제멋대로 변한다.
[질문]
최적의 하이퍼파라미터를 찾을 때까지 학습을 다시 시키는 것이 흔한 방법인가?
실제로 사람들이 가끔 그렇게 하곤 합니다.
하지만 그때그때 다르다고 할 수 있습니다.
만일 데드라인에 쫓기거나, 당장 모델을 사용해야 한다면,
데이텃셋 전부를 다시 학습시키는 것이 너무 오래 걸리면,
다시 학습시키기 쉽지 않겠죠.
하지만, 학습시킬 여유가 있고,
1%의 성능이라도 더 짜내고 싶으면,
여러분이 할 수 있는 하나의 트릭이 될 수 있습니다.
