
Transformer
- Transformer는 2017년에 등장해서 NLP 분야에서 혁신적인 성과를 이끌어낸 논문이다. 비단 NLP 뿐만 아니라 다른 ML Domain 내에서도 수없이 활용되고 있다.
- Transformer의 가장 큰 기여는 이전의 RNN 모델이 불가능했던 병렬 처리를 가능케 했다는 점이다. GPU를 사용함으로써 얻는 가장 큰 이점은 병렬 처리를 한다는 것이다.
- Transformer는 Attention 개념을 도입해 어떤 특정 단어에 집중하고, Positional Encoding을 사용해 sequential한 위치 정보를 보존했다.
Transformer의 개괄적인 구조
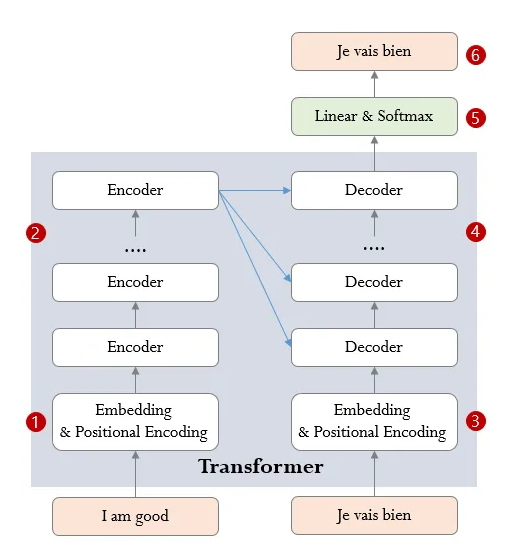
- Transformer는 input sentence를 넣어 output sentence를 생성하는 모델임
- input과 동일한 sentence를 만들어낼 수도, input의 역방향 sentence를 만들어 낼 수도, 같은 의미의 다른 언어로 된 sentence를 만들어 낼 수도 있다.
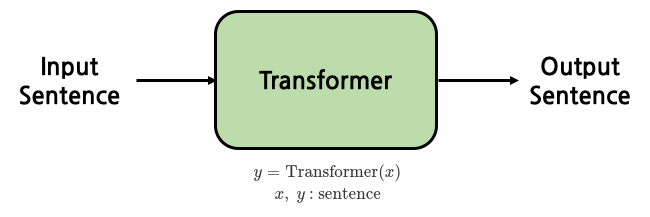
가장 유명한 그림
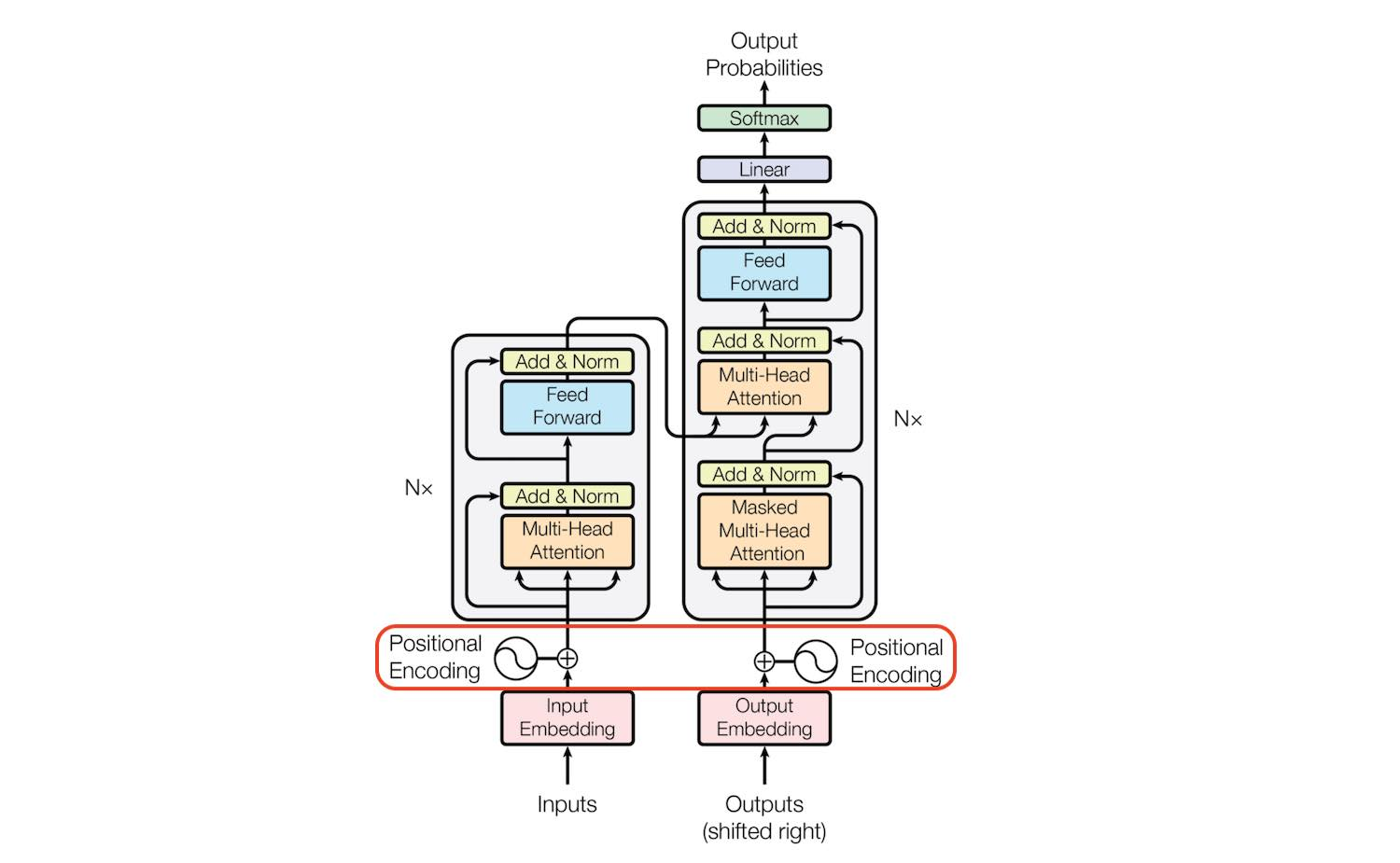
조금 더 구체화한 그림
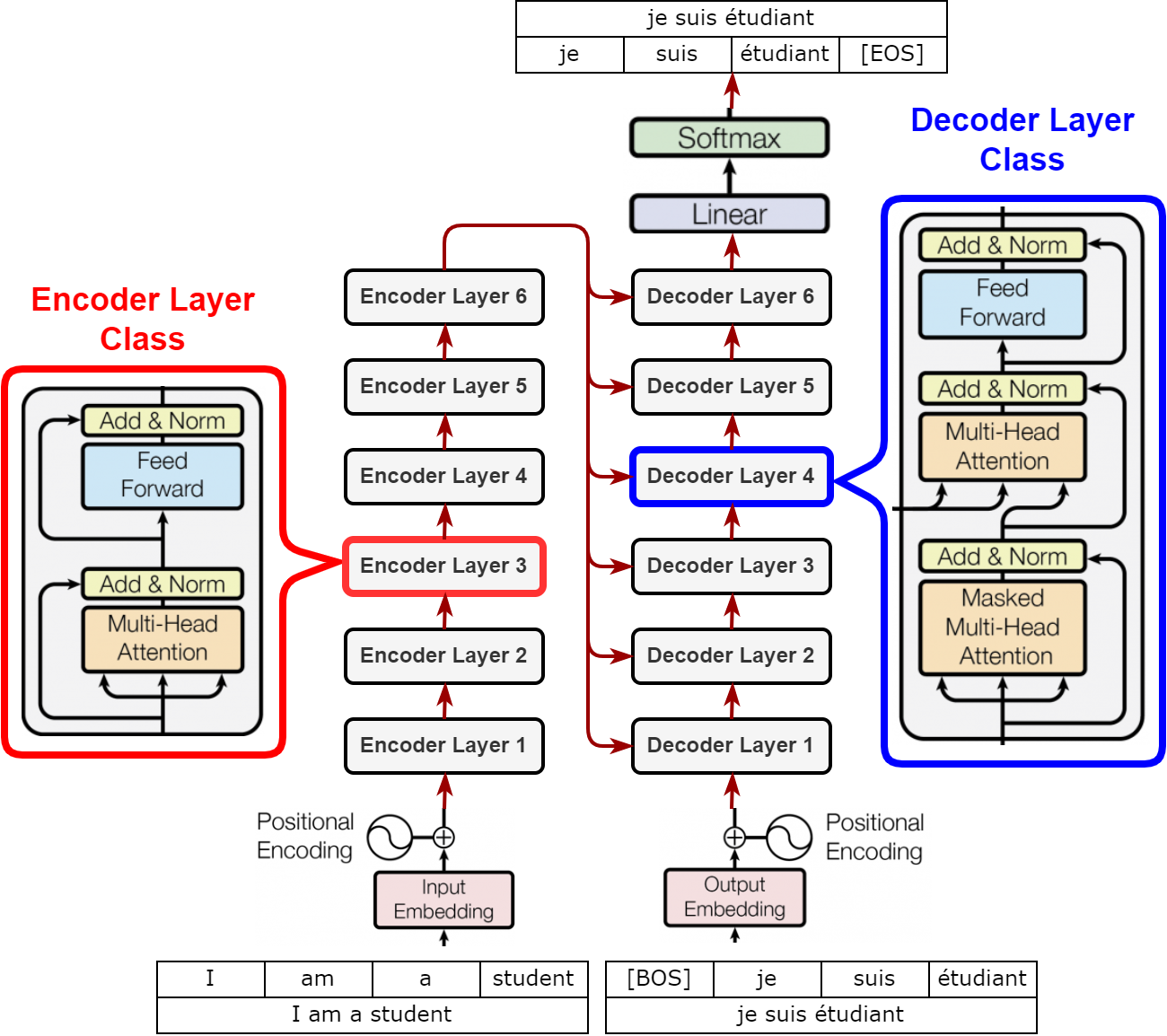
학습과정과 추론과정의 전체 흐름
학습과정
- softmax를 거친 최종 출력은 x 로서 각 위치마다 어휘사전에서의 확률값을 나타낸다.
- cross-entrophy 손실을 계산하여 학습한다.
추론과정
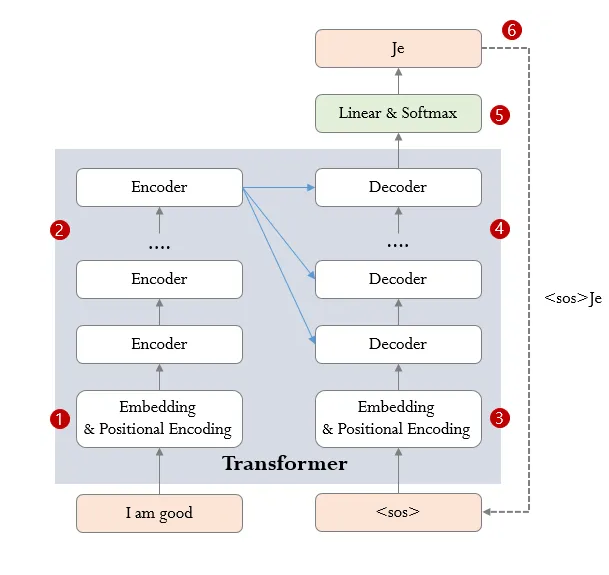
- 3~6과정을 토큰으로 시작해 토큰이 추론될 때까지 그 다음 단어의 확률분포를 유추하는 방식으로 추론한다.
Positional Encoding
- 트랜스포머는 RNN 구조와 달리 단어 입력을 순차적으로 받는 방식이 아니므로 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있음.
- 트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하는데, 이를 포지셔널 인코딩(positional encoding)이라고 함
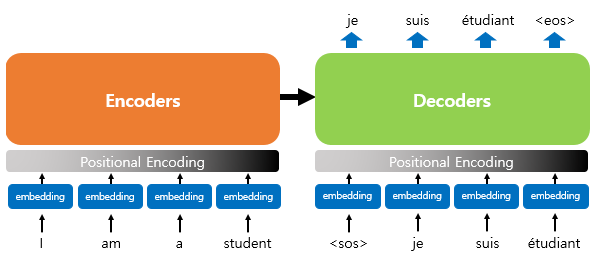
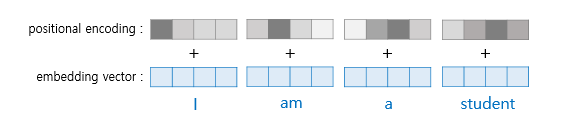
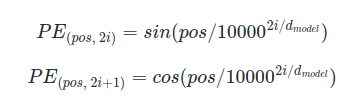
Encoder와 Decoder
- 트랜스포머는 인코더와 디코더로 구분됨
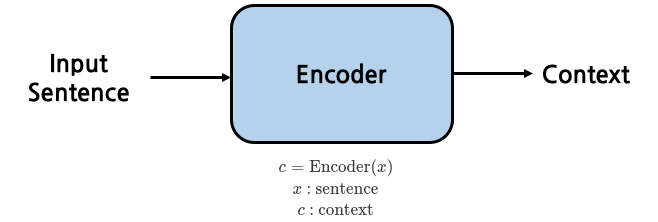
Encoder
- 인코더는 sentence를 input으로 받아 하나의 vector를 생성하는 함수임
- 문장의 문맥을 함축해 담은 vector임
- 문장의 정보들을 빠뜨리지 않고 압축하는 것을 목표로 학습됨
Decoder
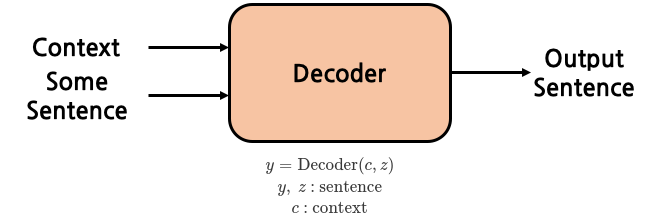
- 디코더는 context와 sentence를 입력으로 받아 sentence를 출력함
코드
class Transformer(nn.Module):
def __init__(self, encoder, decoder):
super(Transformer, self).__init__()
self.encoder = encoder
self.decoder = decoder
def encode(self, x):
out = self.encoder(x)
return out
def decode(self, z, c):
out = self.decode(z, c)
return out
def forward(self, x, z):
c = self.encode(x)
y = self.decode(z, c)
return yEncoder

- 인코더는 인코더 블럭이 N(논문에서는 6)개 쌓여진 형태임
- 이렇게 쌓을 수 있는 것은 input과 output의 shape가 동일하기 때문
- 겹겹히 쌓는 이유 : 더 추상적인 정보를 담아내기 위함
- 처음에는 단순한 context였다면 context의 context, context의 context의 context 등으로 더 높은 차원의 context가 저장되는 것
class Encoder(nn.Module):
def __init__(self, encoder_block, n_layer): # n_layer: Encoder Block의 개수
super(Encoder, self).__init__()
self.layers = []
for i in range(n_layer):
self.layers.append(copy.deepcopy(encoder_block))
def forward(self, x):
out = x
for layer in self.layers:
out = layer(out)
return outEncoder Block
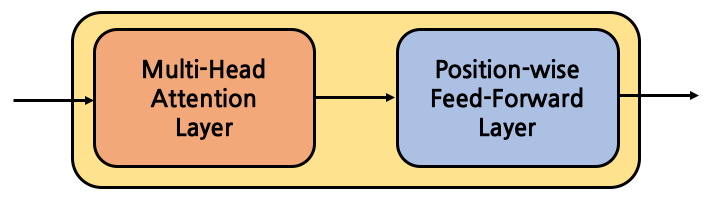
- 인코더 블럭은 Multi-Head Attention Layer, Position-wise Feed Forward Layer로 구성
- Multi-Head Attention이란?
- Attention = Scaled Dot-Product Attention
- Multi-Head Attention = Scaled Dot-Product Attention을 병렬적으로 동시에 수행
- 한마디로 확장한 것 뿐 큰 차이는 없음
- Attention은 단어(token)와 단어 사이의 연관정도를 계산하는 방법론
- Encoder Block의 큰 부분만을 간단히 코드로 살펴보자.
class EncoderBlock(nn.Module):
def __init__(self, self_attention, position_ff):
super(EncoderBlock, self).__init__()
self.self_attention = self_attention
self.position_ff = position_ff
def forward(self, x):
out = x
out = self.self_attention(out)
out = self.position_ff(out)
return outAttention과 Query, Key, Value
- Attention 계산에는 Query, Key, Value라는 3가지 vector가 사용됨
- Query, Key, Value라는 이름으로 명명한 것에 특별한 의미는 없음
- Query : current token
- Key : attention을 계산하려는 대상 token
- Value : attention을 계산하려는 대상 token (Key와 동일한 token)
animal didn’t cross the street, because it was too tired.
- 위의 문장을 예로 든다면, 'it'이 어느 것을 지칭하는 지 알아내고자 한다면, 'it' token과 문장 내의 다른 모든 token에 대해 attention을 구하는 것
- 예를들어, Query가 'it'인 경우, Key, Value는 'animal'를 가리킬 경우, 'it'과 'animal'사이의 연관성을 구하는 것이 됨
- 그림으로 보면 아래와 같다.
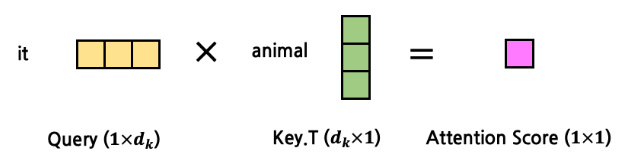
- 두 단어를 위와 같이 계산하면 하나의 값으로 표현할 수 있다!
- Key, Value는 실제 값은 다르지만 의미적으로 같은 token을 가리킴(attention)
- 각 token embedding vector를 각 FC layer에 넣어서 세 vector를 생성한다.
- 서로 다른 FC layer 통해서 Key, Value가 구해지므로 값은 다르지만 가리키는 token 갖도록 학습됨
Scaled Dot-Product Attention
- Scaled Dot-Product Attention을 이해해보자.
- 우선 단일 Query에 대한 Attention을 살펴보자.
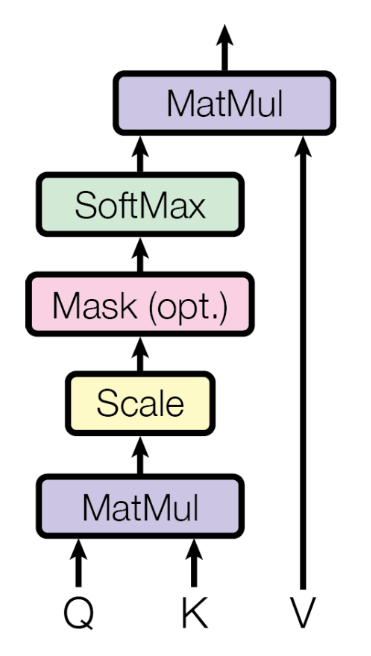
- Q는 현재 시점의 token을, K와 V는 대상 token을 의미 (해당 token은 별도의 FC Layer로)
- 각 token의 vector 차원이 3이라면 아래와 같은 모양일 것

Query, Key, Value 준비
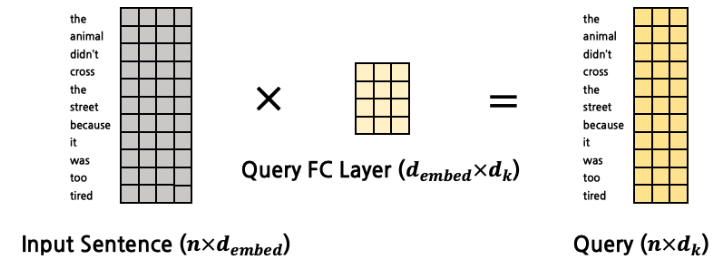
- Query, Key, Value는 token 그 자체가 아니다! (생성해야 하는 것)
- Query FC Layer, Key, FC Layer, Value FC Layer가 존재해서 거기에 token vector를 입력하여 추출하는 것들이다.
- Q,K,V에서 정의된 차원과 word embedding vector에 정의된 차원이 다르다는 걸 기억하라.
- Q,K,V FC Layer는 input sentence embedding vector를 Q,K,V 차원으로 매핑하기 위한 차원 x 으로 구성되어 있다.
Matmul
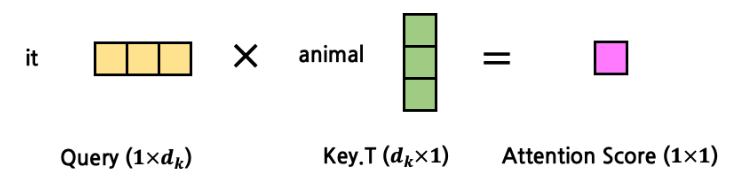
- Q와 K를 MatMul 하면 scalar 값이 출력됨
- 내적이 바로 벡터의 각도 혹은 유사도를 의미하지는 않음
- 위의 예는 하나의 token에 대한 하나의 token과의 attention을 구한 것임
- 이제 모든 Key Token에 대해 동시에 계산을 한다면?
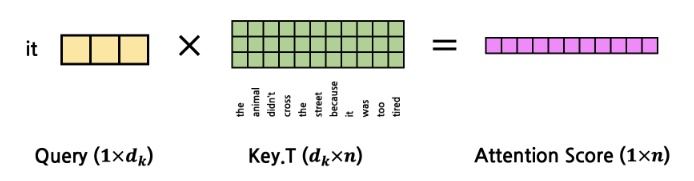
- 이걸 모든 Query Token을 한꺼번에 계산한다면?
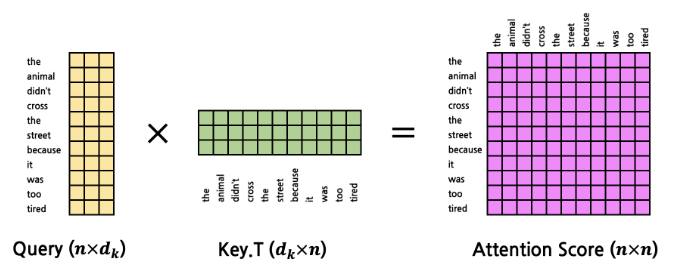
- 하나의 표를 생성하는 것과 같다.
- 위와 같이 Key를 x 행렬로 바꾸면 행렬곱으로 한꺼번에 attention score를 계산할 수 있게 되는 것임 (은 token 갯수.. 나중에는 batch내 token 최대값.. 을 사용)
Scale
- scale은 차원 수의 루트를 씌워서 나누어주는 방식으로 수행하는데 그 이유는 값이 너무 커지는 것을 방지
Mask (opt.)
- mask작업이 필요한 이유는 문장마다 token 갯수가 다르기 때문이다!
- 만일 token 개수가 11개이면 문장 전체의 matrix는 x 가 될 것이다.
- 그런데 token 갯수가 다르면 차원이 달라질 수 있는데, 모델 학습시 mini-batch로 묶어서 input을 넣어야 하는데 길이가 다르면 묶을 수 없다.
- 따라서 mini-batch 내의 token 개수 최대값으로 나머지는 pad로 채워서 matrix를 만들어야 한다.
- 그러나 pad token에는 attention이 부여되어서는 안되므로 행렬곱 이후에 사용해야 한다.
Softmax
- 이 attention score vector에 Softmax를 취하면 확률값으로 사용할 수 있음
- 이것을 attention probability로 명명하자.
다시 Matmul
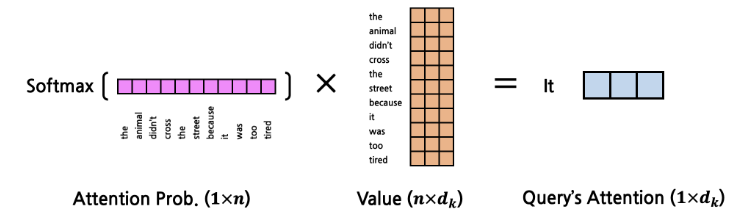
- 이를 최종적으로 다시 V에 곱하여 attention을 생성한다.
- Value에 Query에 대한 attention probability를 계산해서 Query의 Attention이 반영된 Query의 attention이 출력된다.
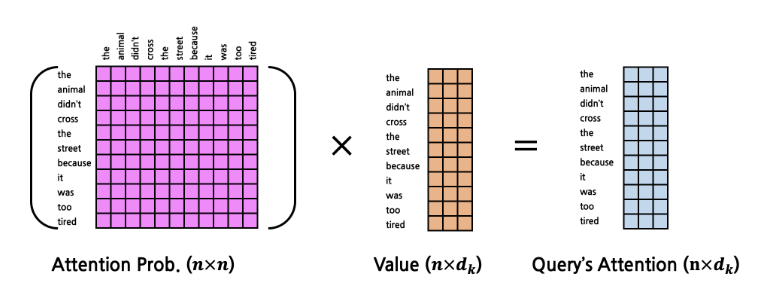
- 모든 token을 Query로 하여 한꺼번에 계산한다면?
- 아래 그림과 같이 될 것이다.
코드
def calculate_attention(query, key, value, mask):
# query, key, value: (n_batch, seq_len, d_k)
# mask: (n_batch, seq_len, seq_len)
d_k = key.shape[-1]
# Q x K를 계산해야 하는데, 3차원 이상의 matrix의 matmul 연산은 가장 마지막 차원 2개로 연산함.
# 따라서 가장 마지막 차원 2개를 transpose 한 후, matmul 수행. n x n의 표가 생성됨
attention_score = torch.matmul(query, key.transpose(-2, -1)) # Q x K^T, (n_batch, seq_len, seq_len)
# scaled를 수행
attention_score = attention_score / math.sqrt(d_k)
if mask is not None:
# 마스크 tensor의 값이 0인 위치에 대해 아주 작은 값을 대입하여 softmax 통과시 0가 되도록 함
attention_score = attention_score.masked_fill(mask==0, -1e9)
# 가장 마지막 차원을 확률값으로 변경
attention_prob = F.softmax(attention_score, dim=-1) # (n_batch, seq_len, seq_len)
out = torch.matmul(attention_prob, value) # (n_batch, seq_len, d_k)
return outMulti-Head Attention Layer
- 이제까지의 내용을 토대로 Multi-Head Attention Layer를 이해해보자.
- Multi-Head는 한 인코더마다 1회씩 수행하는 것이 아니라 병렬적으로 h회를 수행하여 종합해서 사용한다.
- 예시 문장에서 'it'의 Attention에는 'animal'의 것만 차지하게 될 수 있는데, 실제 의미에서는 다양한 attention이 존재할 수 있으므로, 다양한 정보를 반영하기 위해서 Multi-head를 사용하는 것이다.
연산방법
- Scaled Dot-Product Attention에서 , , 를 위해 FC layer가 총 3개 필요하다는 것을 확인했다.
- Multi-Head Attention Layer는 이를 회 수행하는 것 뿐이다. (,, Layer가 개)
- 그러나 순차적으로 회 수행하는 것은 비효율적이므로 x 를 번 하는 대신, 열의 길이가 인 matrix 하나로 한번에 계산을 한다. 이 * 를 이라 부르자.
- 그림으로 보자면 이러하다.
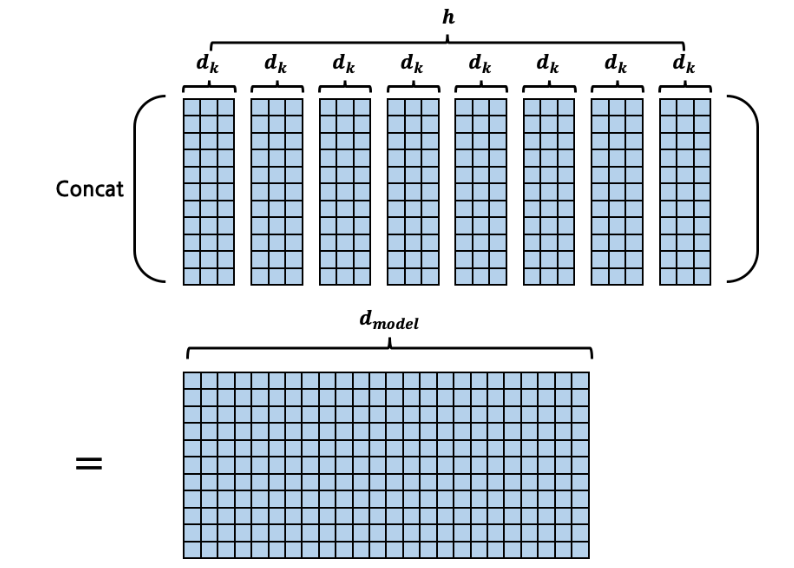
- 단지 더 많은 정보를 담기 위해 를 로 확장한 것이라고 해석할 수도 있음
input
- input : x
- 이를 각각 Q, K, V에 넣는다.
FC Layer
- Q,K,V를 만드는 것이 목적이다. 사실 특별한 것이 아니다. 어텐션 연산을 위한 차원으로 변형하기 위한 목적인 것
- 어텐션 차원은 / 이다.
- 논문기준 = 512, = 8이므로 = 64임
- FC Layer(Q, K, V) : x
- Q, K, V(즉 FC Layer Ouput) : x
- 이렇게 Q(K, V 동일)를 만든 후, 는 여러 연산의 결과를 연결시키는 개념임으로 앞으로 이동시키고, 각 token에 대한 Query 형태인 x 로 차원을 변형시켜 attention score를 추출하기 위한 준비를 한다.
- 차원변형 : x x -> x x
x MatMul
- ( x x )
- ( x x ) : 를 제외하고 transpose
- x Output : x x
Scaling
- math.sqrt()로 나눈다.
Mask
- masked_fill 호출
Softmax
- F.softmax(attention_score, dim=-1)
Attention Prob. x
- attention prob. : x x
- ( x x )
- x Output : x x
차원변환
- transpose : x x
- contiguous : x
Final FC Layer
- input과 동일한 shape으로 맞추기 위한 작업
- FC Layer : x
- FC Layer Output : x
- 최종적 FC Layer 연산은 아래와 같은 그림으로 설명될 수 있다.
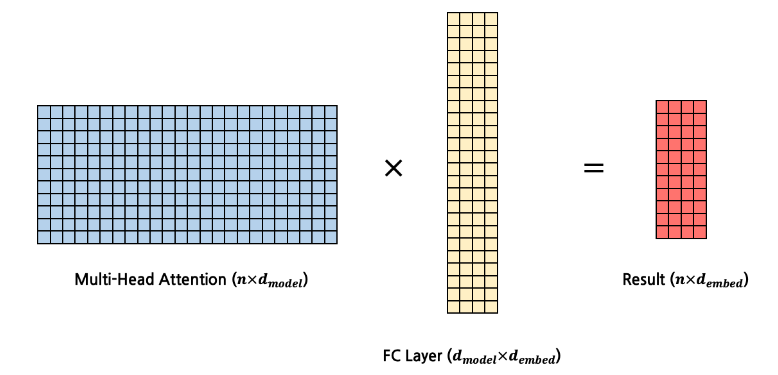
input -> Output
- input : x
- output : x
- 전체 input, output은 아래 그림으로 정리할 수 있다.
코드
class MultiHeadAttentionLayer(nn.Module):
def __init__(self, d_model, h, qkv_fc, out_fc):
super(MultiHeadAttentionLayer, self).__init__()
self.d_model = d_model
self.h = h
self.q_fc = copy.deepcopy(qkv_fc) # (d_embed, d_model)
self.k_fc = copy.deepcopy(qkv_fc) # (d_embed, d_model)
self.v_fc = copy.deepcopy(qkv_fc) # (d_embed, d_model)
self.out_fc = out_fc # (d_model, d_embed)
... class MultiHeadAttentionLayer(nn.Module):
...
def forward(self, *args, query, key, value, mask=None):
# query, key, value: (n_batch, seq_len, d_embed)
# mask: (n_batch, seq_len, seq_len)
# return value: (n_batch, h, seq_len, d_k)
n_batch = query.size(0)
def transform(x, fc): # (n_batch, seq_len, d_embed)
out = fc(x) # (n_batch, seq_len, d_model)
out = out.view(n_batch, -1, self.h, self.d_model//self.h) # (n_batch, seq_len, h, d_k)
out = out.transpose(1, 2) # (n_batch, h, seq_len, d_k)
return out
query = transform(query, self.q_fc) # (n_batch, h, seq_len, d_k)
key = transform(key, self.k_fc) # (n_batch, h, seq_len, d_k)
value = transform(value, self.v_fc) # (n_batch, h, seq_len, d_k)
out = self.calculate_attention(query, key, value, mask) # (n_batch, h, seq_len, d_k)
out = out.transpose(1, 2) # (n_batch, seq_len, h, d_k)
out = out.contiguous().view(n_batch, -1, self.d_model) # (n_batch, seq_len, d_model)
out = self.out_fc(out) # (n_batch, seq_len, d_embed)
return outPosition-wise Feed Forward Layer
- 어텐션 메커니즘만으로는 비선형성을 도입하는데 한계가 있음.
- 비선형성은 모델이 더 복잡한 관계를 학습할 수 있게 해주며, 이를 통해 모델이 더 다양한 패턴과 특징을 학습할 수 있게 하는데, 그러한 기능을 함
- 단순하게 2개의 FC Layer를 갖는 Layer이다.
- first layer's shape : x
- second layer's shape : x
- shape을 보면 알겠지만 두 FC Layer를 통과하면 다시 x 가 된다. Encoder Block는 input과 동일한 output을 내야 하므로..
- 최종적으로 ReLU를 적용하여 output 함
- code로 구성하면 다음과 같다.
class PositionWiseFeedForwardLayer(nn.Module):
def __init__(self, fc1, fc2):
super(PositionWiseFeedForwardLayer, self).__init__()
self.fc1 = fc1 # (d_embed, d_ff)
self.relu = nn.ReLU()
self.fc2 = fc2 # (d_ff, d_embed)
def forward(self, x):
out = x
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
return outResidual Connection Layer
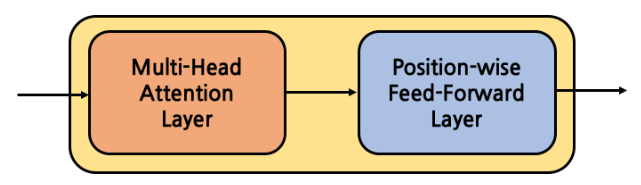
- Encoder Block은 위의 그림과 같다.
- Multi-Head Attention Layer와 Position-wise Feed-Forward Layer로 구성된다.
- 그런데 여기서 잠깐! output을 input으로만 사용하지 않고, Residual Layer로 연결되어 있다.
- = 가 아니라 = + 라는 것!
- Back Propagation 중 발생할 수 있는 Gradient Vanishing을 방지하기 위한 목적
- 코드로 확인
class ResidualConnectionLayer(nn.Module):
def __init__(self):
super(ResidualConnectionLayer, self).__init__()
def forward(self, x, sub_layer):
out = x
out = sub_layer(out)
out = out + x
return outclass EncoderBlock(nn.Module):
def __init__(self, self_attention, position_ff):
super(EncoderBlock, self).__init__()
self.self_attention = self_attention
self.position_ff = position_ff
self.residuals = [ResidualConnectionLayer() for _ in range(2)]
def forward(self, src, src_mask):
out = src
out = class EncoderBlock(nn.Module):
def __init__(self, self_attention, position_ff):
super(EncoderBlock, self).__init__()
self.self_attention = self_attention
self.position_ff = position_ff
self.residuals = [ResidualConnectionLayer() for _ in range(2)]
def forward(self, src, src_mask):
out = src
out = self.residuals[0](out, lambda out: self.self_attention(query=out, key=out, value=out, mask=src_mask))
out = self.residuals[1](out, self.position_ff)
return outself.residuals[0](out, lambda out: self.self_attention(query=out, key=out, value=out, mask=src_mask))
out = self.residuals[1](out, self.position_ff)
return out참고

늘 성장을 꿈꾸는 자들을 위한 블로그입니다.