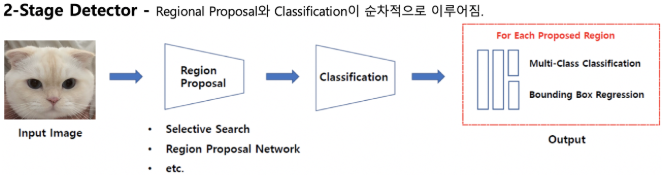
2-stage Detector (Fast R-CNN, OverFeat, DPM)
- 2-stage 객체 검출은 객체 검출과 객체 분류를 거쳐 객체를 검출함
- DPM(Deformable Part Model)
- sliding window 기법을 사용합니다.(sliding window : 이미지 픽셀 마다 일정 간격의 픽셀을 건너뛰고, 바운딩 박스를 그리는 기법)
- 전체 이미지에 대하여 작은 구역에 일정한 간격을 두고 판별합니다.

- RCNN
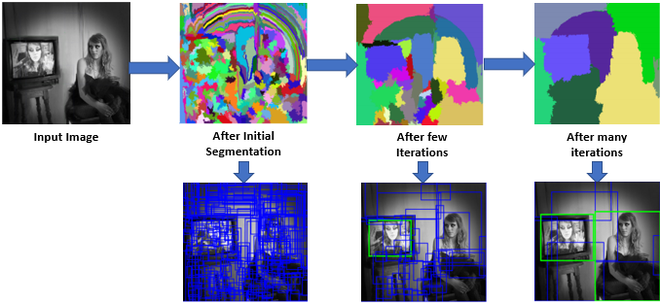
- Selective search 기법을 사용
- selectve search란? input 이미지에 sub-segmentation 진행하여, greedy-algorithm을 통해 구역에서 가장 유사한 두가지를 선택하여 반복적으로 작은 영역을 큰 영역으로 결합
- 객체가 있을 법한 구역을 제안(region proposal)하고, 그 구역을 판별
- 출력값으로 생성된 바운딩박스를 전처리 과정을 거쳐 최종 바운딩박스를 선택
2 stage Detector의 장단점
- 장점 : 정확성이 높음
- 단점 : 각 요소를 개별적으로 학습시켜줘야하기 때문에 속도가 느리고 최적화하기 어려움
1-stage Detector(YOLO,SSD)
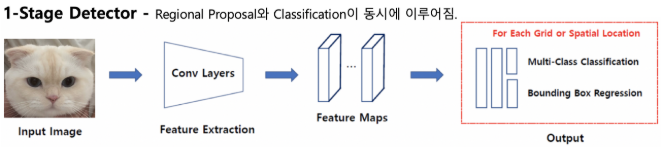
- 1-stage 검출은 특징 추출과 객체 분류를 단일 신경망을 사용
- 특히 YOLO는 single-regression 을 통해서 객체를 검출
1 stage Detector의 장단점
- 장점 : 특징 추출과 객체 분류를 한꺼번에 처리하여 속도 빠름
- 단점 : 정확도는 비교적 떨어짐
YOLO(You Only Look Once)
- 객체 검출의 개별 요소를 단일 신경망으로 통합한 모델
- 각각의 바운딩박스를 예측하기위해 이미지 전체의 특징을 활용하며, 높은 정확도를 자랑하는 end-to-end 학습 네트워크임

바운딩 박스 예측 방식
- Yolov1은 하나의 convolution network로 이미지를 입력받아, 여러 개의 바운딩 박스와 각 박스의 class를 예측
- non-max suppression을 통해 최종 바운딩박스를 선정
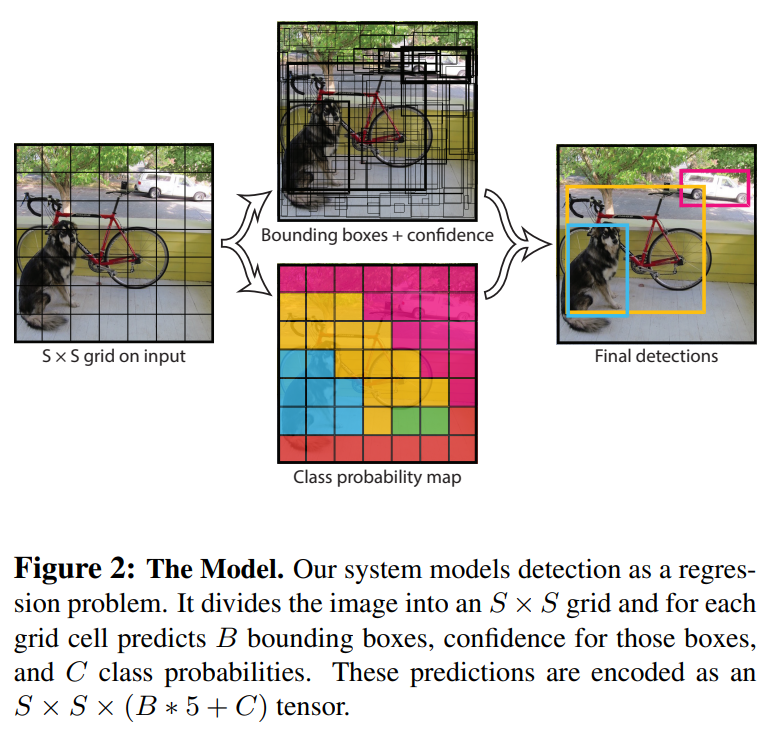
(1) 입력 이미지를 SxS grid로 분할(Pascal Voc에서 S=7,B=2,C=20로 셋팅)
(2) 만약에 grid cell안에 객체의 중심이 맞아 떨어지면 그 grid cell은 객체를 검출해야 함
(3) 각 grid cell은 B개의 바운딩박스와 각 바운딩 박스는 5개의 정보를 가짐(x,y,w,h,confidence). 각 grid cell은 각 바운딩박스에 대한 신뢰점수(confidence score)와 조건부 확률( conditional class probability)을 예측
(4) non-max suppression(score가 높은 바운딩 박스만을 선택)을 거쳐서 최종 바운딩박스를 선정
Score
- 신뢰점수(confidence score) : bounding box가 객체를 포함한다는 것을 얼마나 믿을만한지, 그리고 예측한 bounding box가 얼마나 정확한지를 나타냄
- 조건부 확률 예측( conditional class probability) : 각 grid cell은 바운딩 박스 이외에도 class 확률을 예측
- 특정 클래스 신뢰 점수(class-specific confidence score) : 바운딩박스에 특정 클래스(class) 객체가 나타날 확률과 예측된 bounding box가 그 클래스(class) 객체에 얼마나 잘 들어맞는지에 대한 점수
- confidence score

Architecture
- GoogLeNet에서 영향을 받아앞단은 컨볼루션(24개) 뒷단은 전결합 계층(2개)
- CNN Layer : 이미지 특징 추출
- FC Layer : 바운딩박스와 클래스 확률 예측
- inception 대신 1x1 차원 감소 layer 와 그 뒤에 3x3 convolutional layer를 이용
- 최종 output 크기는 7x7x30 tensor 출력
- Fast YOLO는 더 적은 계층 수

YOLO v1의 장점
속도
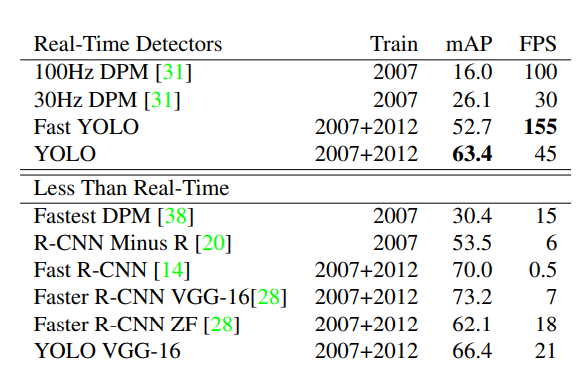
- YOLO는 기존 2-stage 방식 객체 검출의 복잡한 객체 검출 프로세스를 하나의 회귀 문제로 바꾸었습니다. 덕분에 YOLO의 기본 네트워크(base network)는 배치 처리(batch processing) 없이 1초에 45 프레임을 처리합니다. 빠른 버전의 YOLO(Fast YOLO)는 1초에 150 프레임을 처리합니다. 이는 동영상을 실시간으로 처리할 수 있습니다. YOLO는 다른 실시간 객체 검출 모델보다 2배 이상의 mAP를 갖습니다.
검출 성능
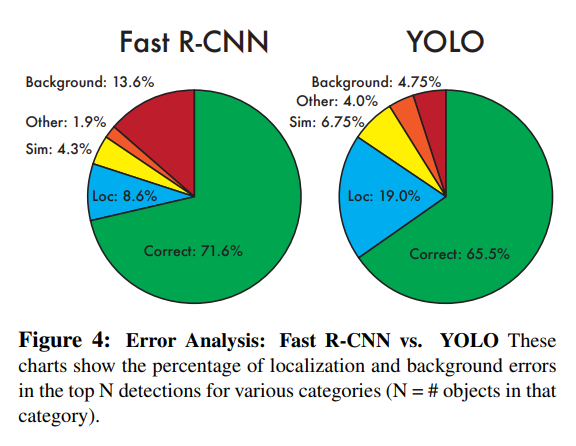
- 기존 2-stage 방식 객체 검출과 달리 YOLO는 예측을 할 때 이미지 전체를 처리합니다. 슬라이딩 윈도(sliding window)나 region proposal 방식과 달리, YOLO는 훈련과 테스트 단계에서 이미지 전체를 보기때문에 클래스의 모양에 대한 정보뿐만 아니라 주변 정보까지 학습합니다. Background error가 2배 이상 적습니다.
(Background error : 아무 물체가 없는 배경(background)에 반점이나 노이즈가 있으면 그것을 물체로 인식) - 객체의 일반화된 representations을 학습하여 다른 도메인에서 좋은 성능을 보임
- YOLO는 물체를 일반화하여 학습합니다. 일반적인 부분을 학습하기 때문에 자연 이미지를 학습하여 그림 이미지로 테스트할 때, YOLO의 성능은 DPM이나 R-CNN보다 월등히 뛰어납니다. 따라서 다른 모델에 비해 YOLO는 훈련 단계에서 보지 못한 새로운 이미지에 대해 더 높은 검출 정확도를 냅니다. 하지만, YOLO는 최신(SOTA, state-of-the-art) 객체 검출 모델에 비해 정확도가 다소 떨어진다는 단점이 있습니다. 빠르게 객체를 검출할 수 있다는 장점은 있지만 정확성이 다소 떨어집니다. 특히 작은 물체에 대한 검출 정확도가 떨어집니다. 속도와 정확성은 trade-off 관계입니다.
YOLOv1 한계
- 각 grid cell은 하나의 클래스만을 예측하기 때문에 객체가 겹쳐있으면 제대로 예측하지못함
- 바운딩 박스 형태가 이미지 데이터를 통하여 학습되기 때문에 새로운 형태의 바운딩박스의 경우 정확히 예측 어려움
- 작은 바운딩 박스의 loss가 IoU에 더 민감한 영향을 줌. Localization에 안좋은 영향

늘 성장을 꿈꾸는 자들을 위한 블로그입니다.