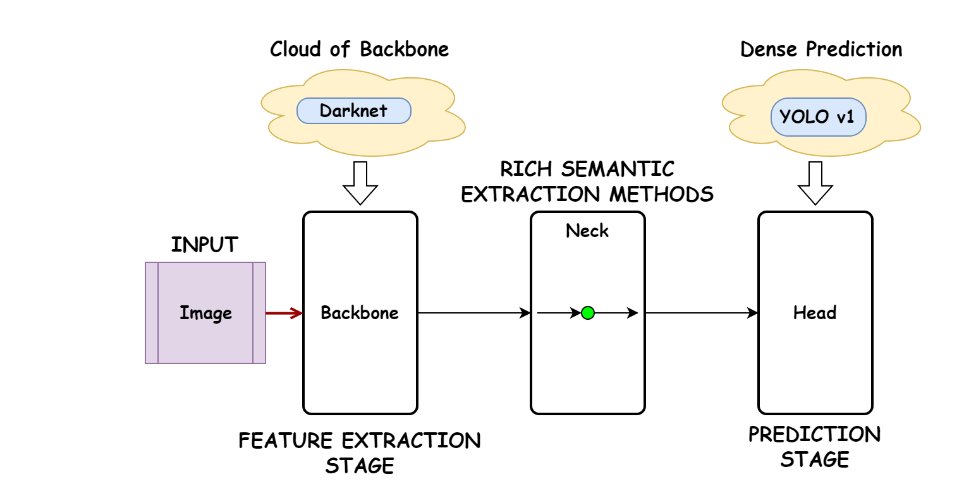
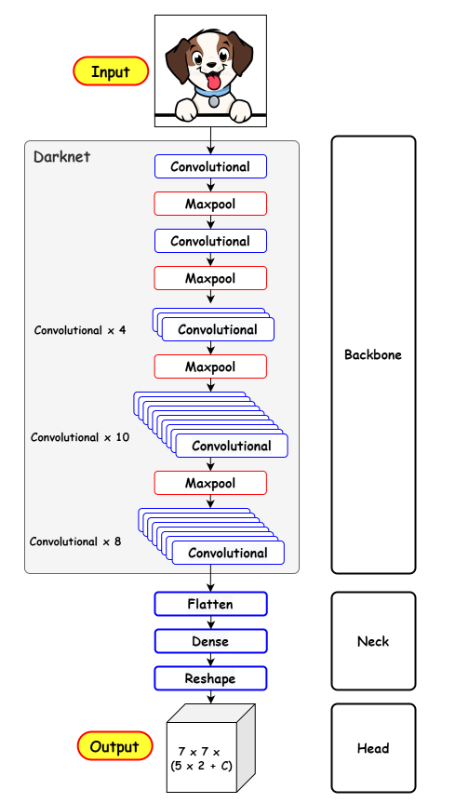
Backbone (vgg16 가능, 논문에서는 Darknet 사용)
이미지 픽셀을 풀링하는 컨볼루션 신경망
분류 데이터 세트에서 사전 훈련된다.
Neck
예측 헤드로 전달하기 전, ConvNet 레이어 표현을 결합한다.
Head
경계 상자 및 클레스 예측은 만듦. 세 가지 손실 함수로 진행. 물체가 있는 곳만 알려주고 어떤 클래스인지는 알려주지 않음.
아키텍처 구조
Pytorch로 계산하는 output tensor
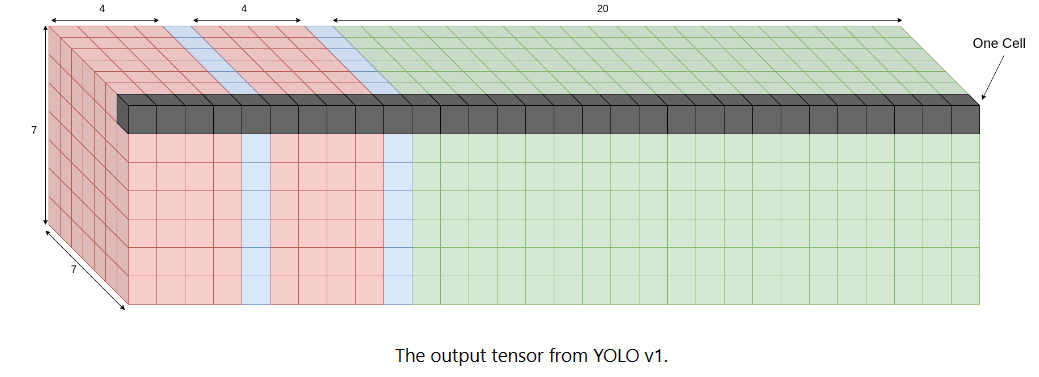
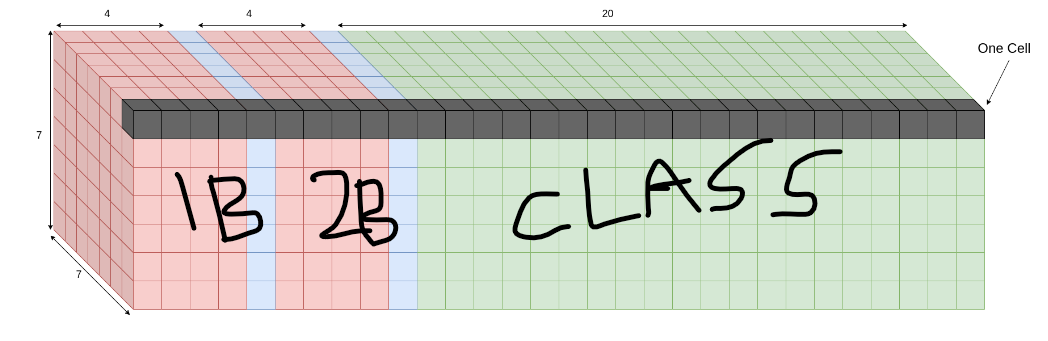
정규화
- 너비와 높이는 이미지 너비에 대해 정규화, 그러나 실제 그리드 셀과는 관련이 없다.
- 상자에 객체가 포함될 확률을 나타내는 상자에 대한 신뢰도 점수를 표시
- 상자가 아니라 각 그리드 셀에 대한 클래스 확률을 표시
code
dataset.py
def __getitem__(self, index):
label_path = os.path.join(self.label_dir, self.annotations.iloc[index, 1])
boxes = []
with open(label_path) as f:
for label in f.readlines():
class_label, x, y, width, height = [
float(x) if float(x) != int(float(x)) else int(x)
for x in label.replace("\n", "").split()
]
boxes.append([class_label, x, y, width, height])
img_path = os.path.join(self.img_dir, self.annotations.iloc[index, 0])
image = Image.open(img_path)
boxes = torch.tensor(boxes)
if self.transform:
# image = self.transform(image)
image, boxes = self.transform(image, boxes)
# Convert To Cells
label_matrix = torch.zeros((self.S, self.S, self.C + 5 * self.B))
for box in boxes:
class_label, x, y, width, height = box.tolist()
class_label = int(class_label)
# i,j represents the cell row and cell column
i, j = int(self.S * y), int(self.S * x)
x_cell, y_cell = self.S * x - j, self.S * y - i
"""
Calculating the width and height of cell of bounding box,
relative to the cell is done by the following, with
width as the example:
width_pixels = (width*self.image_width)
cell_pixels = (self.image_width)
Then to find the width relative to the cell is simply:
width_pixels/cell_pixels, simplification leads to the
formulas below.
"""
width_cell, height_cell = (
width * self.S,
height * self.S,
)
# If no object already found for specific cell i,j
# Note: This means we restrict to ONE object
# per cell!
if label_matrix[i, j, 20] == 0:
# Set that there exists an object
label_matrix[i, j, 20] = 1
# Box coordinates
box_coordinates = torch.tensor(
[x_cell, y_cell, width_cell, height_cell]
)
label_matrix[i, j, 21:25] = box_coordinates
# Set one hot encoding for class_label
label_matrix[i, j, class_label] = 1label_matrix : 7x7x30 크기의 배열
ground truth box의 중신이 특정 cell에 존재하는 경우 cell의 20번째 index(confidence score)값을 1로 지정한다. boxes 변수에는 전체 ground truth box의 x,y,w,h가 저장되어 있다. 각 GTB의 중심좌표를 계산 후, label_matrix에 confidence score와 bounding box의 좌표를 지정한다. -> loss function 계산 시 활용
model.py
architecture_config = [
(7, 64, 2, 3),
"M",
(3, 192, 1, 1),
"M",
(1, 128, 1, 0),
(3, 256, 1, 1),
(1, 256, 1, 0),
(3, 512, 1, 1),
"M",
[(1, 256, 1, 0), (3, 512, 1, 1), 4],
(1, 512, 1, 0),
(3, 1024, 1, 1),
"M",
[(1, 512, 1, 0), (3, 1024, 1, 1), 2],
(3, 1024, 1, 1),
(3, 1024, 2, 1),
(3, 1024, 1, 1),
(3, 1024, 1, 1),
]튜플은 conv layer, 문자열 maxpooling, 리스트 마지막 정수만큼 layer 반복.
util.py
IOU function
def intersection_over_union(boxes_preds, boxes_labels, box_format="midpoint"):
"""
Calculates intersection over union
Parameters:
boxes_preds (tensor): Predictions of Bounding Boxes (BATCH_SIZE, 4)
boxes_labels (tensor): Correct labels of Bounding Boxes (BATCH_SIZE, 4)
box_format (str): midpoint/corners, if boxes (x,y,w,h) or (x1,y1,x2,y2)
Returns:
tensor: Intersection over union for all examples
"""
if box_format == "midpoint":
box1_x1 = boxes_preds[..., 0:1] - boxes_preds[..., 2:3] / 2
box1_y1 = boxes_preds[..., 1:2] - boxes_preds[..., 3:4] / 2
box1_x2 = boxes_preds[..., 0:1] + boxes_preds[..., 2:3] / 2
box1_y2 = boxes_preds[..., 1:2] + boxes_preds[..., 3:4] / 2
box2_x1 = boxes_labels[..., 0:1] - boxes_labels[..., 2:3] / 2
box2_y1 = boxes_labels[..., 1:2] - boxes_labels[..., 3:4] / 2
box2_x2 = boxes_labels[..., 0:1] + boxes_labels[..., 2:3] / 2
box2_y2 = boxes_labels[..., 1:2] + boxes_labels[..., 3:4] / 2
if box_format == "corners":
box1_x1 = boxes_preds[..., 0:1]
box1_y1 = boxes_preds[..., 1:2]
box1_x2 = boxes_preds[..., 2:3]
box1_y2 = boxes_preds[..., 3:4] # (N, 1)
box2_x1 = boxes_labels[..., 0:1]
box2_y1 = boxes_labels[..., 1:2]
box2_x2 = boxes_labels[..., 2:3]
box2_y2 = boxes_labels[..., 3:4]
x1 = torch.max(box1_x1, box2_x1)
y1 = torch.max(box1_y1, box2_y1)
x2 = torch.min(box1_x2, box2_x2)
y2 = torch.min(box1_y2, box2_y2)
# .clamp(0) is for the case when they do not intersect
intersection = (x2 - x1).clamp(0) * (y2 - y1).clamp(0)
box1_area = abs((box1_x2 - box1_x1) * (box1_y2 - box1_y1))
box2_area = abs((box2_x2 - box2_x1) * (box2_y2 - box2_y1))
return intersection / (box1_area + box2_area - intersection + 1e-6)예측 box와 정답 box의 좌표값을 비교하여 IOU값 구한다.
loss.py
- loss function을 클래스로 정의, grid 크기 S, grid 별 예측 bounding box의 수 B, class의 수 C, 가중치 파라미터 Nobj, coord
class YoloLoss(nn.Module):
def __init__(self, S=7, B=2, C=20):
super(YoloLoss, self).__init__()
self.mse = nn.MSELoss(reduction='sum')
self.S = S
self.B = B
self.C = C
self.lambda_noobj = 0.5
self.lambda_coord = 5- grid cell마다 2개의 Bbox를 예측하고, C 점수가 높은 1개의 Bbox를 학습에 사용한다.
def forward(self, predictions, target):
predictions = predictions.reshape(-1, self.S, self.S, self.C + self.B*5)
iou_b1 = intersection_over_union(predictions[..., 21:25], target[..., 21:25])
iou_b2 = intersection_over_union(predictions[..., 26:30], target[..., 21:25])
ious = torch.cat([iou_b1.unsqueeze(0), iou_b2.unsqueeze(0)], dim=0)
iou_maxes, bestbox = torch.max(ious, dim=0)
exists_box = target[..., 20].unsqueeze(3)predictions[..., 21:25] : 첫번째 Bbox 좌표값
predictions[..., 26:30] : 두번째 Bbox 좌표값
traget의 좌표값(정답)과 비교하여 각각의 IOU를 계산하여 bestBox 에 IOU값이 큰 box의 index가 저장된다.
이후 target[..., 20]를 통해 해당 grid cell의 ground truth box의 중심이 존재하는지 여부 확인.
존재한다면 1, 존재하지 않는다면 0
근데 unsqueeze로 차원은 왜 늘려줌???
unsqueeze(x)?
x번 index에 1인 차원을 생성한다.
왜 두 개의 Bbox를 예측하는가?
Because the cell predicts two boxes, it will shift and stretch the prior box in two different ways, possibly to cover two different objects (but both are constrained to have the same class). You might wonder why it's trying to do two boxes. The answer is probably because 49 boxes isn't enough, especially when there are lots of objects close together, although what tends to happen during training is that the predicted boxes become specialised. So one box might learn to find big things, the other might learn to find small things, this may help the network generalise to other domains.
셀은 두 개의 상자를 예측하기 때문에 이전 상자를 두 가지 다른 방식으로 이동 및 늘이기 때문에 두 개의 다른 객체를 포함할 수 있습니다(그러나 둘 다 동일한 클래스를 갖도록 제한됨). 왜 두 개의 상자를 만들려고 하는지 궁금할 것입니다. 대답은 아마도 49개의 상자가 충분하지 않기 때문일 것입니다. 특히 많은 개체가 가까이에 있을 때 예측된 상자가 전문화되는 경향이 있지만 훈련 중에 발생하는 경향이 있습니다. 따라서 한 상자는 큰 것을 찾는 법을 배우고 다른 상자는 작은 것을 찾는 법을 배울 수 있습니다. 이것은 네트워크가 다른 도메인으로 일반화하는 데 도움이 될 수 있습니다.
box_predictions = exists_box * (
(
bestbox * predictions[..., 26:30]
+ (1 - bestbox) * predictions[..., 21:25]
)
)
box_targets = exists_box * target[..., 21:25]**만약 box가 존재한다면?
실제 bounding box 예측 중 더 큰 box를 최종 예측으로 사용한다.->?
1.Localization loss
box_predictions[..., 2:4] = torch.sign(box_predictions[..., 2:4]) * torch.sqrt(
torch.abs(box_predictions[..., 2:4] + 1e-6)
)
box_targets[..., 2:4] = torch.sqrt(box_targets[..., 2:4])
box_loss = self.mse(
torch.flatten(box_predictions, end_dim=-2),
torch.flatten(box_targets, end_dim=-2)
)이후 w,h에 루트를 씌운 뒤 MSE 계산
- Confidence loss
(1) object가 있는 경우
pred_box = (
bestbox * predictions[..., 25:26] + (1 - bestbox) * predictions[..., 20:21]
)
# (N*S*S)
object_loss = self.mse(
torch.flatten(exists_box * pred_box),
torch.flatten(exists_box * target[..., 20:21])
)
no_object_loss = self.mse(
torch.flatten((1 - exists_box) * predictions[..., 20:21], start_dim=1),
torch.flatten((1 - exists_box) * target[..., 20:21], start_dim=1)
)
predictions[..., 25:26] : 첫번째 box의 confidence score
predictions[..., 20:21] : 두번째 box의 confidence score
(2) object가 없는 경우
no_object_loss += self.mse(
torch.flatten((1 - exists_box) * predictions[..., 25:26], start_dim=1),
torch.flatten((1 - exists_box) * target[..., 20:21], start_dim=1)
)두 Bbox를 모두 학습에 참여시킨다.
- Class loss
class_loss = self.mse(
torch.flatten(exists_box * predictions[..., :20], end_dim=-2),
torch.flatten(exists_box * target[..., :20], end_dim=-2)
)
20개의 class score를 target과 비교하여 MSE 손실을 구한다.
loss = (
self.lambda_coord * box_loss # first two rows in paper
+ object_loss # third row in paper
+ self.lambda_noobj * no_object_loss # fourth row
+ class_loss # fifth row
)모든 loss를 더해 최종 loss산출.
