Mastering the game of Go with deep neural networks and tree search
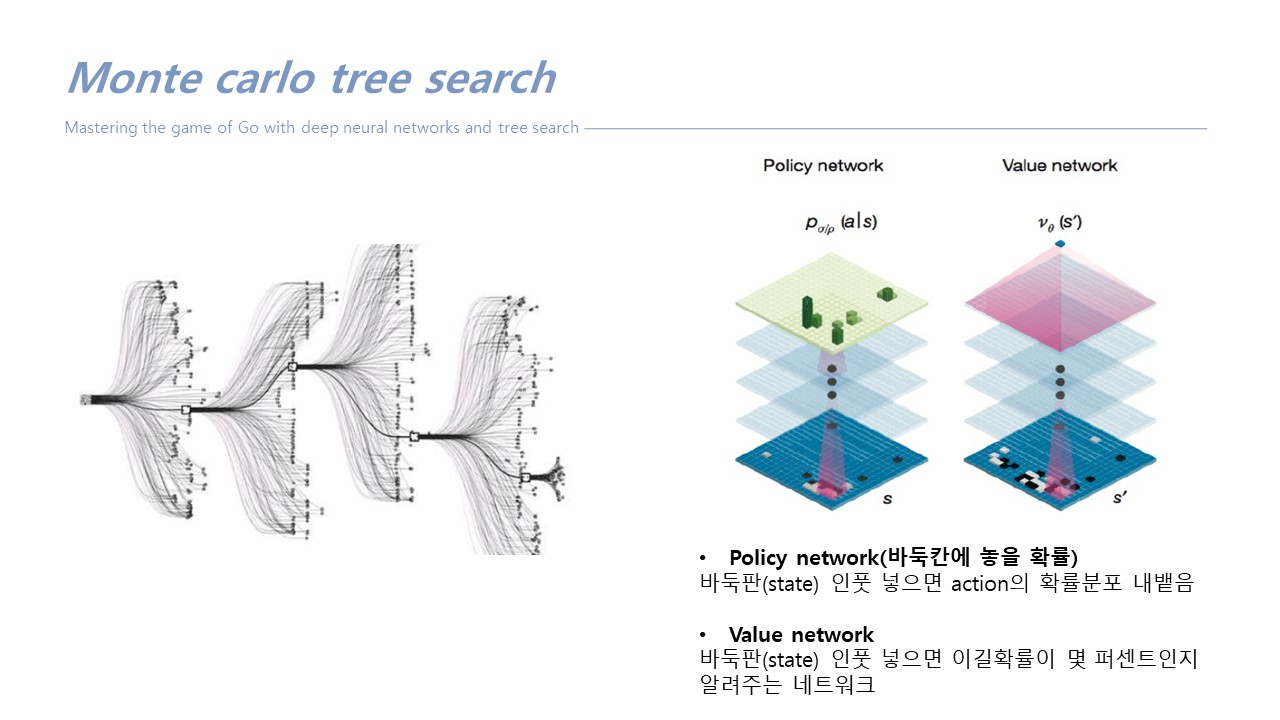
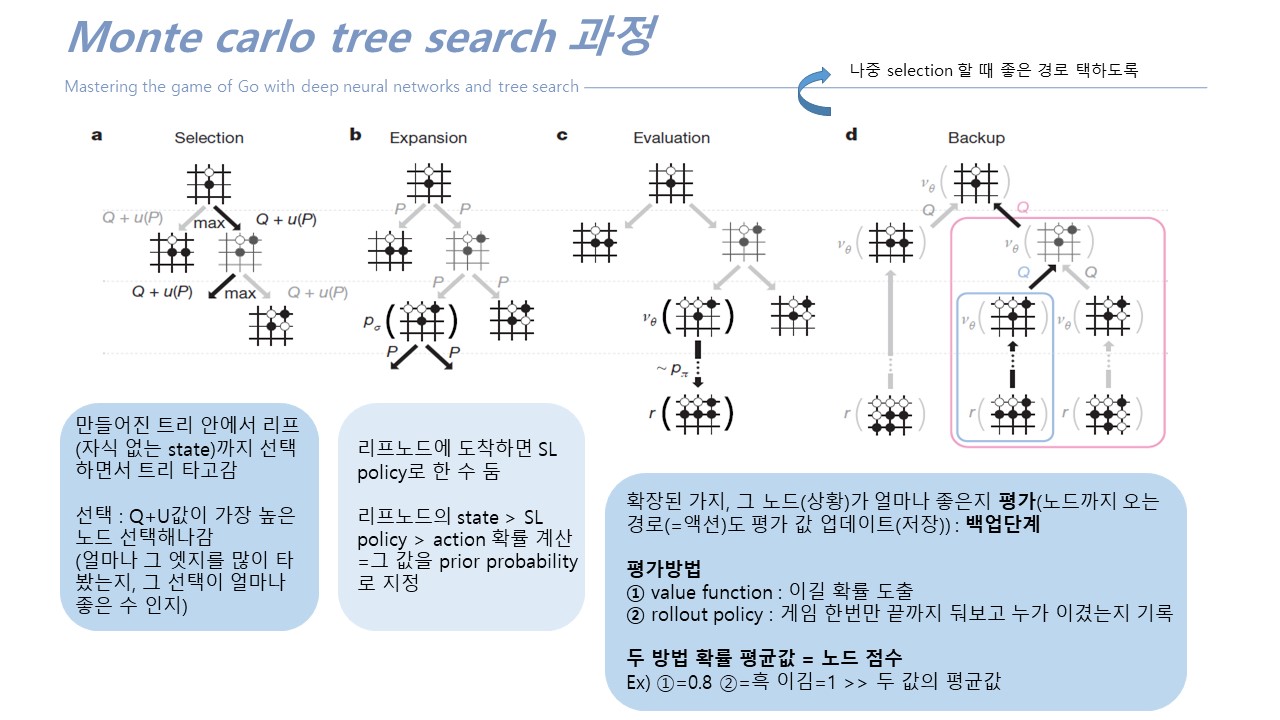
몬테칼로 트리써치 : 상대방과 내가 번갈아가면서 게임을 하는데, 게임을 현재상황에서 끝까지 다 둬보는 것
경우의 수 너무 많아! >> 똑똑하게 게임 해보자!!
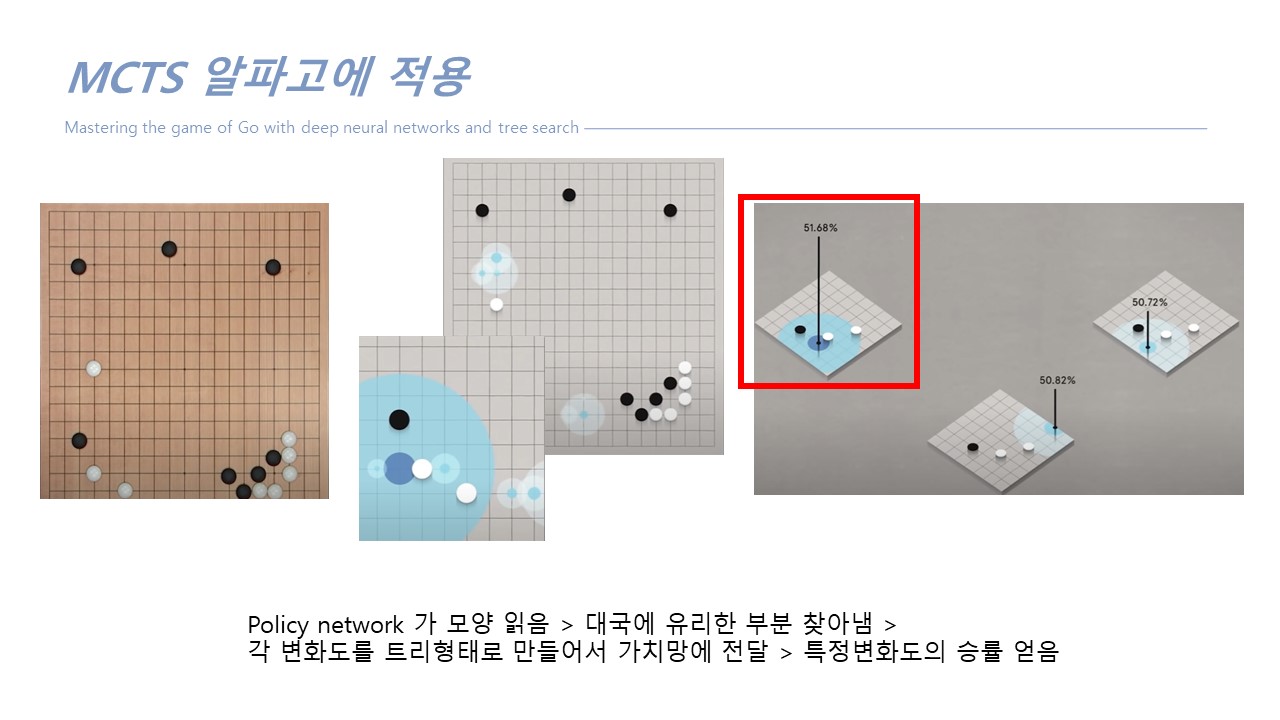
- policy network : 19*19의 수 다 둬보는 게 아니라 좋은 수 위주로 내가 어디다가 두면 좋을지
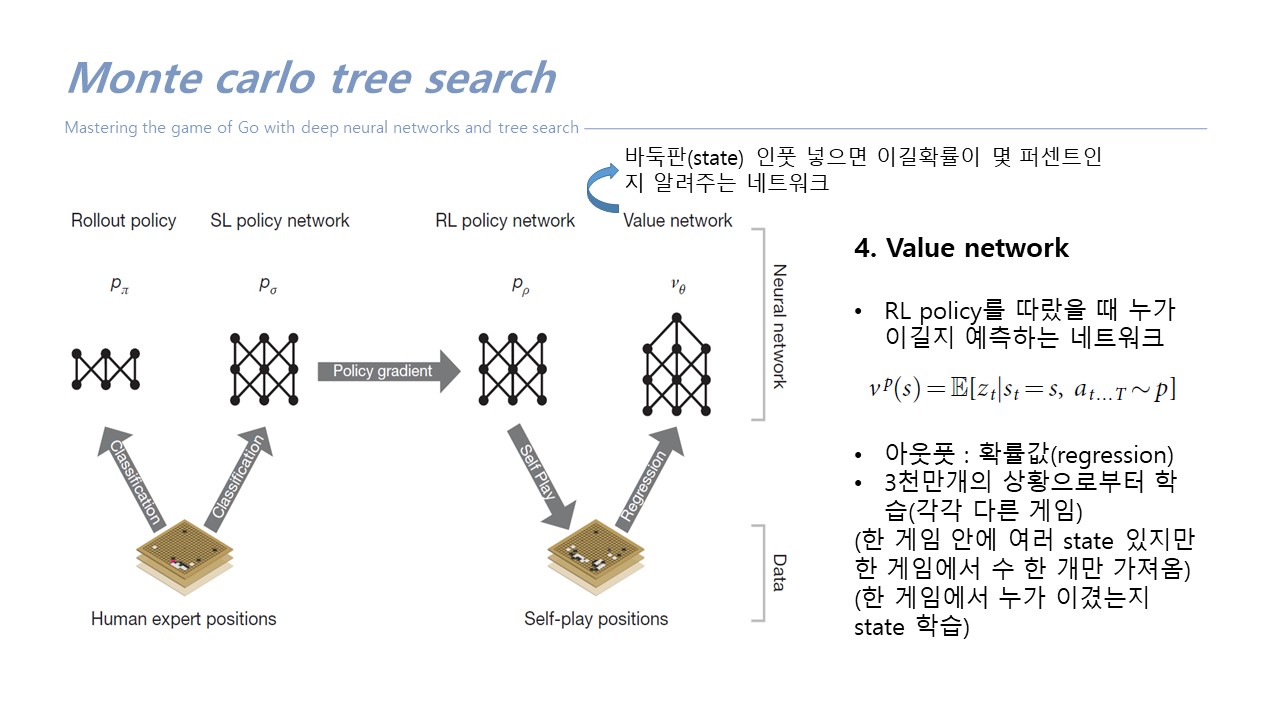
- value network : 아웃풋 = 숫자 하나
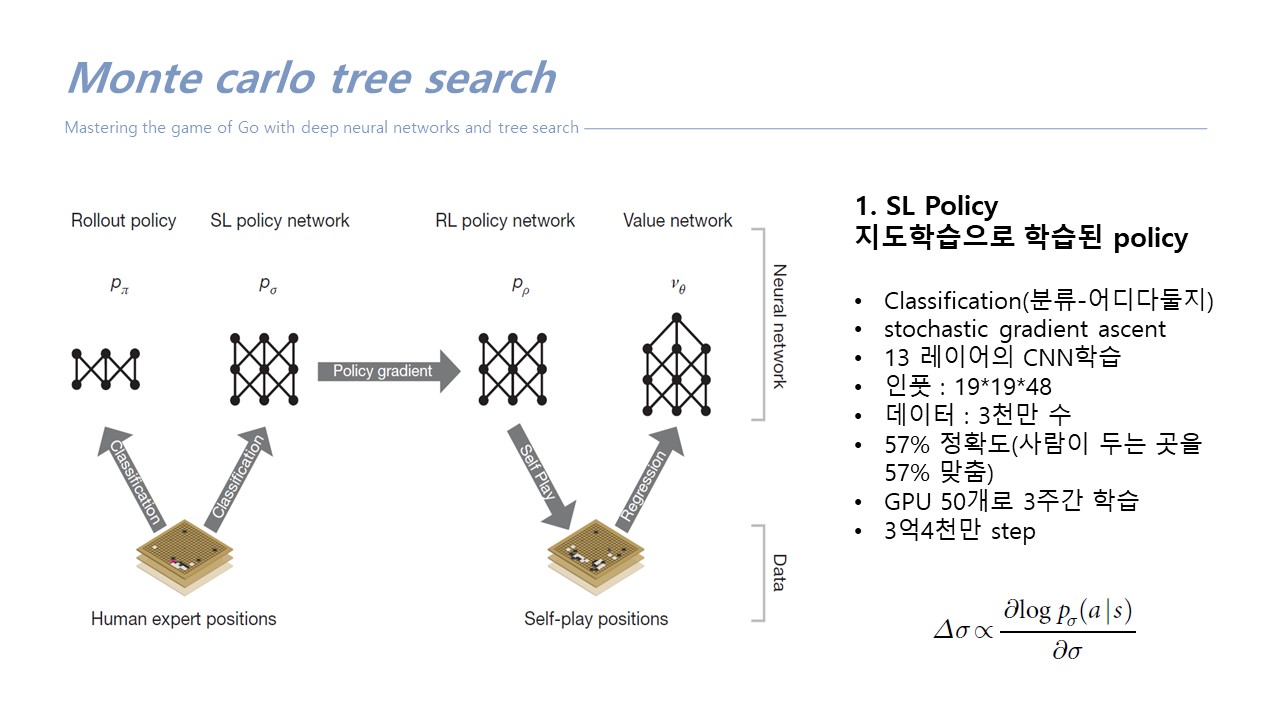

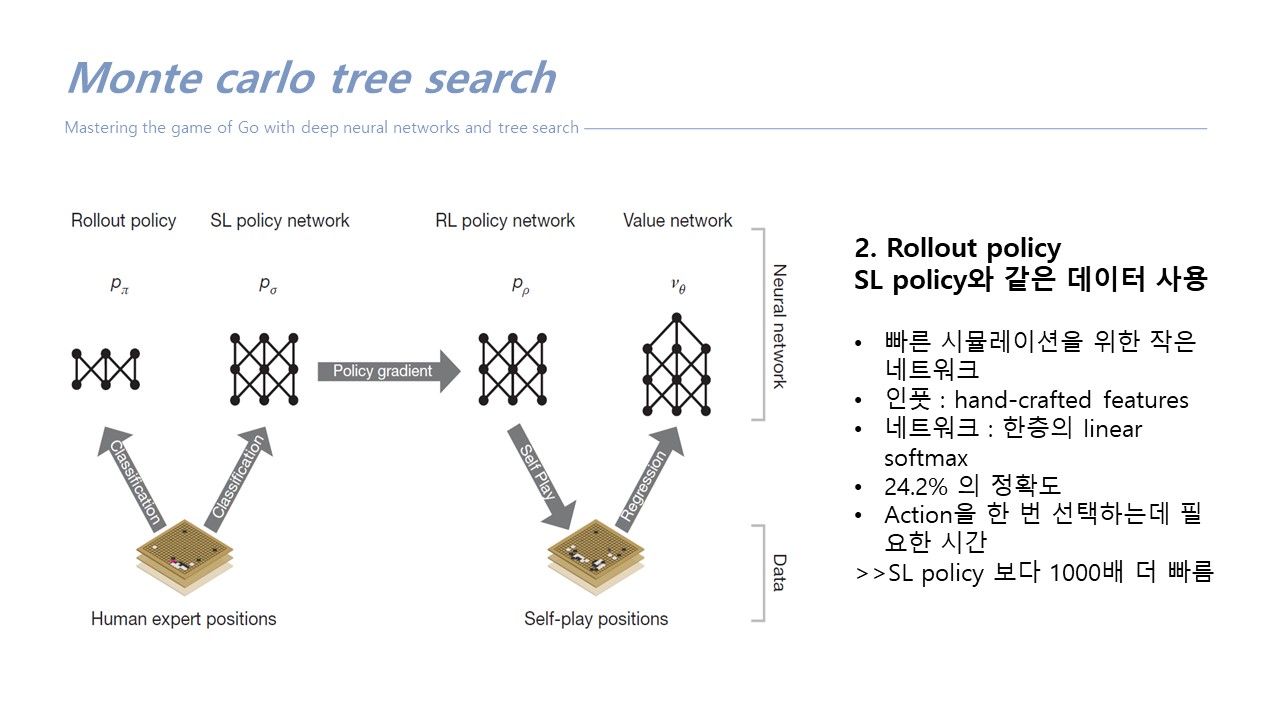
rollout policy : 빠른, 아주 작은 네트워크를 따로 학습
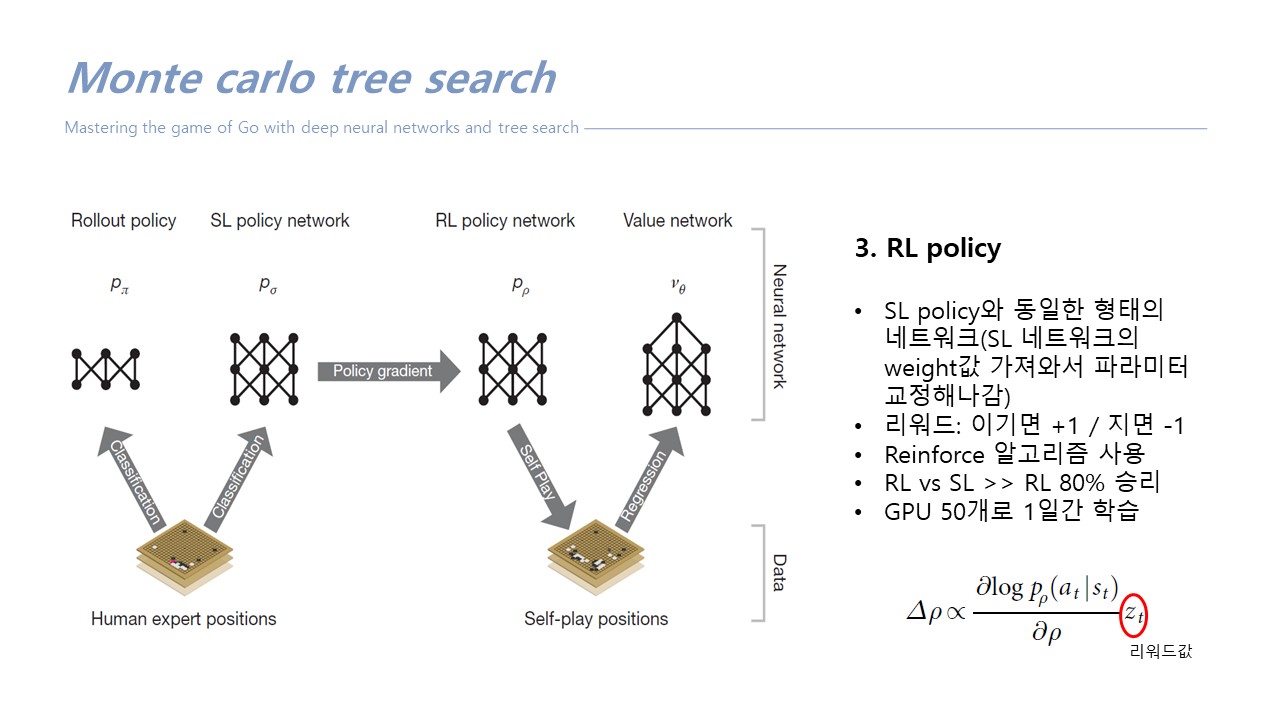
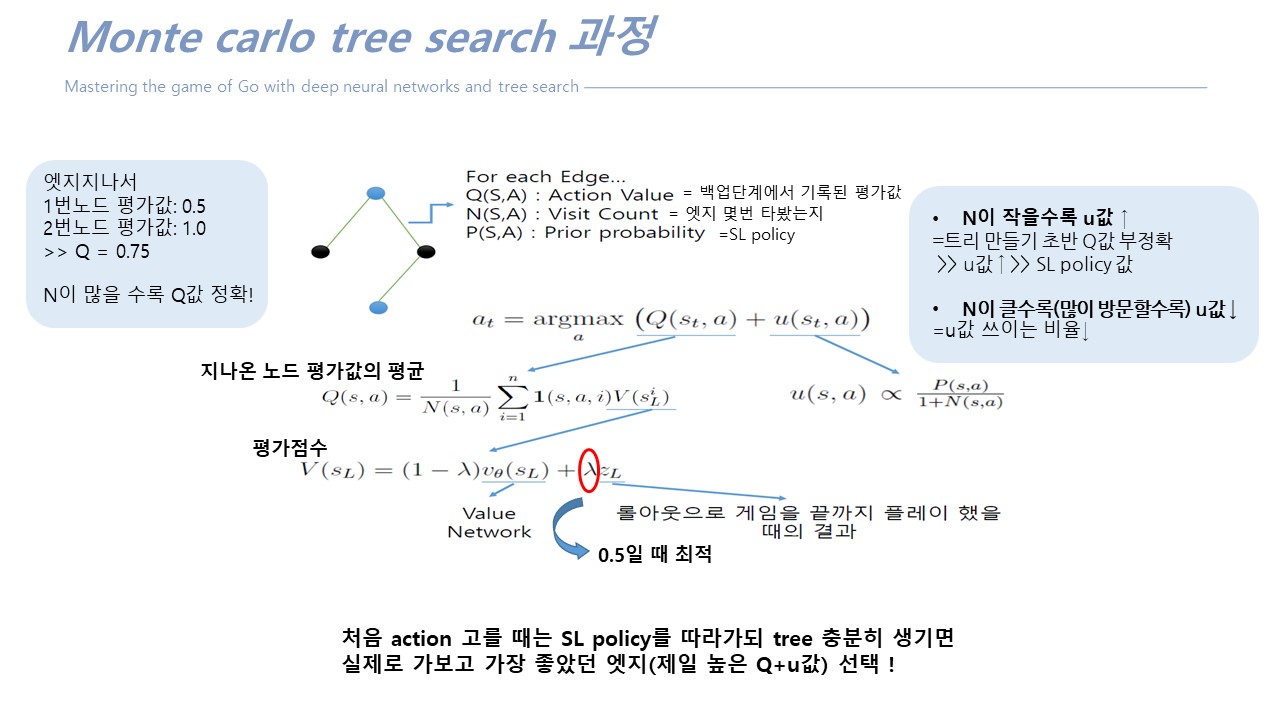
*MCTS에 self play로 value function 학습(value function학습시에만 쓰임)
- SL ver1 VS RL >> 미니배치 업데이트 >> ver2
- opponent pool [ver1, ver2, ver3, ...] 에서 랜덤하게 뽑아서 게임 진행
->과적합 문제 해결

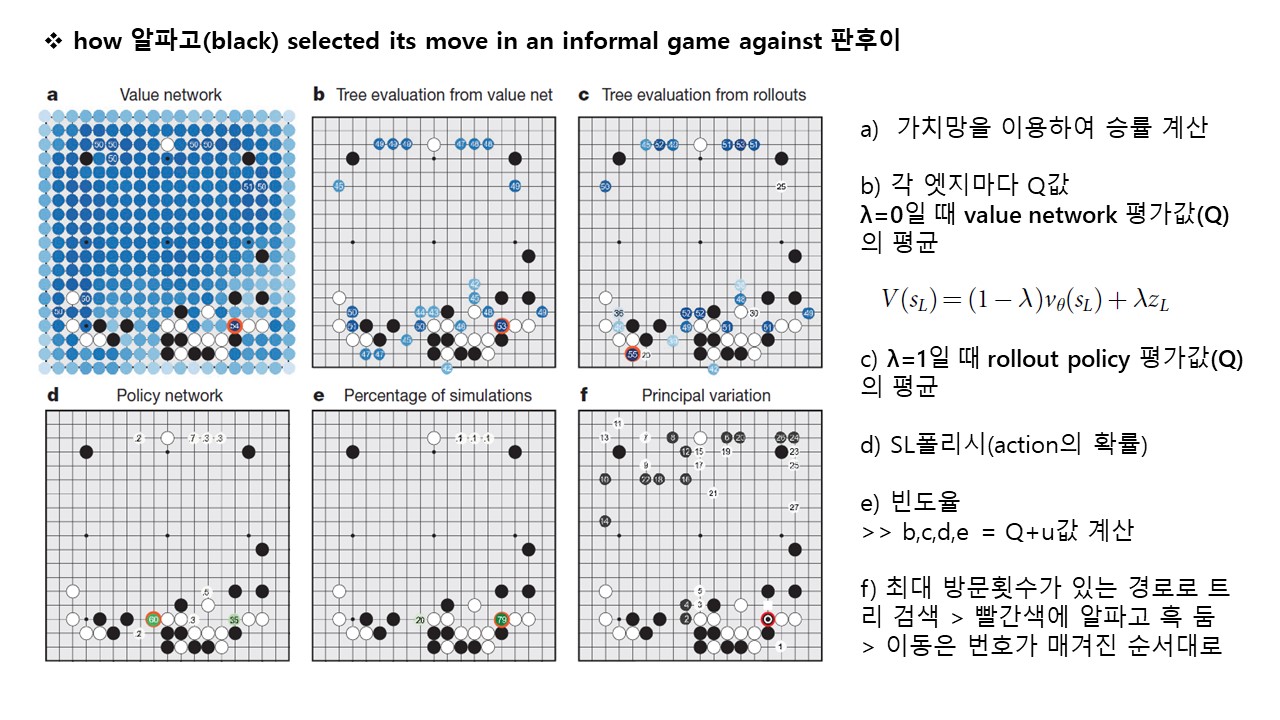

기억하고 싶은 것들 모음.zip
알파고 논문에대한 자세한 리뷰 감사합니다 :)