0.Abstract
-
NLP분야에 Transformer가 등장하며, RNN을 비롯한 NN모델을 대체할 Self-Attention에 대한 연구가 활발하게 진행되고 있습니다.
-
NLP분야에서는 Transformer를 활용한 Bert나 GPT등이 SOTA를 달성하며 이제는 Transformer가 Standard하게 활용되고 있지만 아직까지 Computer Vision 분야에서는 그렇지 않습니다.
-
Computer Vision 에서는 Transformer가 주로 CNN과 함께 사용되는 경향이 있습니다. 즉 여전히 CNN에 의존적입니다. 하지만 본 논문에서 제시하는 VIT(Vision Transformer)는 이러한 한계를 극복하여 SOTA를 달성하는 모델입니다. 이제는 CNN 없이도 Computer vision을 풀 수 있습니다!
-
본격적인 논문 리뷰에 앞서, 논문의 원본 링크를 첨부하겠습니다!
-
논문 원본 링크 : https://arxiv.org/pdf/2010.11929.pdf
1.Introduction
-
Transformer는 NLP에서 굉장히 효과적이지만, 지금까지는 Computer Vision 분야에 적용하는 것은 쉽지 않았습니다.
-
본 논문에서는 Transformer의 구조를 최대한 Original로 사용하기 위하여, 수정을 최소화하였습니다.
-
이를 위해 이미지를 Patches로 분할하고, Linear Embedding Sequence로 표현하여 이를 Transformer의 Input으로 사용하였습니다.
-
Transformer 모델에 관하여 생각해보면, Transformer는 Key와 Query로 사용할 Embedding vector간의 유사도를 구하여(구하는 방식에 따라 Dot-product Attention이나 Bahdanau Attention등으로 분류됩니다.) Value에 반영하는 Attention 기반의 모델입니다. 이 때 RNN을 사용하지 않고 Self-Attention을 활용했다는 것은 혁신에 가깝다고 생각합니다. BlackBox에 가까운 NN모델에서 벗어나서, 비교적 설명 가능한 모델 제작이 가능해졌을 뿐만 아니라 연산 또한 Matrix로 수행되어 유리하기 때문입니다.
-
이러한 Transformer의 특성을 보면 어떠한 Vector간의 유사도를 구한다는 것은 언어 뿐만 아니라 Computer vision 분야에도 충분히 적용 가능하고, 좋은 성능을 낼 수 있을 것이라고 생각합니다. 사실, Real world에서는 언어처럼 거의 모든 data에는 sequence가 존재하기 때문입니다.
-
결과적으로 Strong Regulization을 사용하지 않고 Mid-size의 Dataset에 본 논문에서 제시한 VIT(Vision Transformer)를 적용하였을 때에는, ResNet보다 조금 낮은 성능을 보였습니다.
-
하지만 CNN 고유의 특성(Translation equivariance, locality등)으로 인해 더 큰 Dataset에서 CNN은 잘 일반화가 되지 않습니다. VIT는 이러한 상황에 Pre-train(더 큰 Dataset으로 Training하고 더 적은 point의 Dataset에 적용)할 때 더 우수한 결과(SOTA또는 SOTA에 가까운 결과)를 얻습니다.
3.Method
- 저자는 VIT가 기존의 Transformer구조와 최대한 가깝게 (original을 유지하도록) 설계되었고 이를 통해 확장 적용이 쉬우며 효율적 구현이 가능하도록 했다고 합니다.
1. Vision Transformer (VIT)
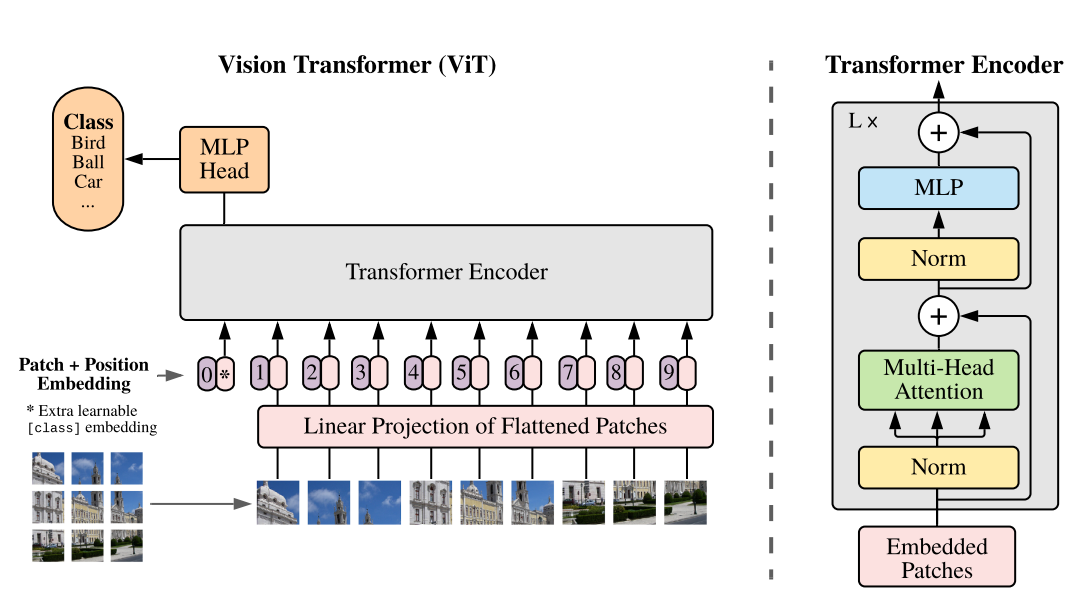
- 위 그림은 VIT의 대략적인 개요입니다. 각 Image를 Fixed-size의 patches로 split하고 linearly embedding layer를 통과시킵니다. 그 후 그 embedding vector를 Transformer의 encoder에 input으로 대입합니다. 본 논문에서는 Classification문제를 해결하기 위하여 "Classification token"을 Sequence에 추가하였습니다.
INPUT SETTING
- 일반적인 Transformer은 토큰 임베딩에 대한 1차원의 시퀀스를 입력으로 받음
- 2차원의 이미지를 다루기 위해 논문에서는 이미지를 flatten된 2차원의 패치의 시퀀스로 변환함
- 즉, H x W x C → N x (P^2 x C) 로 변환
(H, W)는 원본 이미지의 크기, C는 채널 개수를 의미
(P, P)는 이미지 패치의 크기
N = HW/P^2 = 패치의 개수- Transformer은 모든 레이어에서 고정된 벡터 크기 D를 사용하기 때문에 이미지 패치는 펼친 다음 D차원 벡터로 linear projection 시킴
- BERT의 [CLS]토큰과 비슷하게 임베딩 된 패치의 시퀀스에 z0 = x_class 임베딩을 추가로 붙여 넣음
- 이후 이 패치에 대해 나온 인코더 아웃풋은 이미지 representation으로 해석하여 분류에 사용
- Position embedding은 위치정보를 유지하기 위하여 Patch embedding과 함께 사용됩니다.
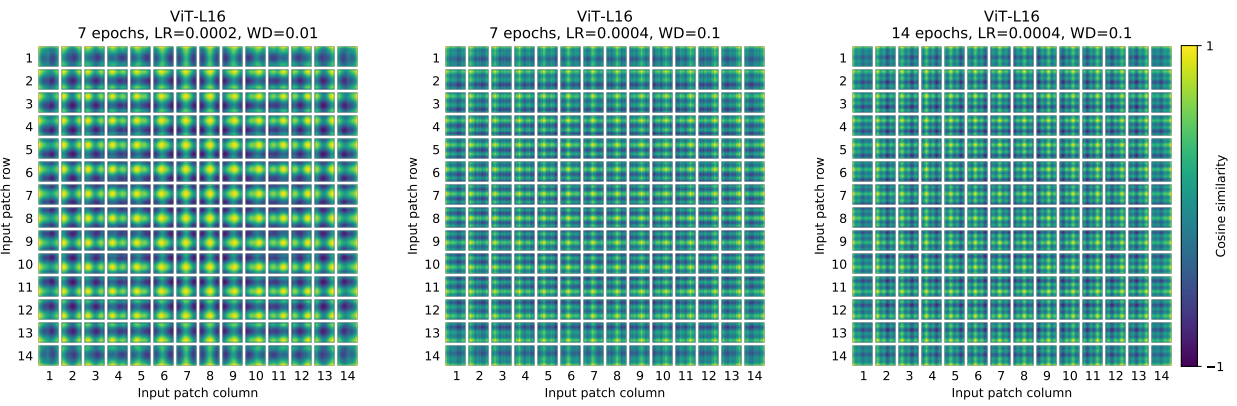
-
위 사진은 Position embedding을 본 논문에서 사용한 vector에 따른 그림입니다.(부록 D.4) 이와 같이 학습을 통해 PE(position embedding) matrix(vercor)를 구했습니다. 추가적으로, Transformer에서는 PE matrix를 sin과 cos함수를 활용하여 구하였습니다. 하지만 BERT에서는 본 논문과 같이 PE를 학습을 통하여 구했기에, 이 방법을 채택한 것 같습니다.
-
또한 PE벡터는 1차원으로 사용했는데, 이는 2차원으로 사용했을때와 큰 유의미한 차이가 없었기 때문이라고 합니다.
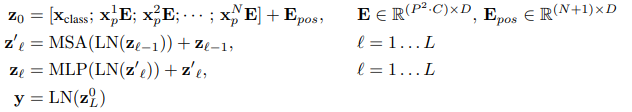
-
Transformer의 Encoder는 위와같이 MSA(Multihead Self-Attention) Layer와 MLP Layer, LN(Layer Nomalization) Layer로 구성됩니다.
-
MLP는 부록 A에 설명되어있는 수식을 좀 더 자세히 보겠습니다.
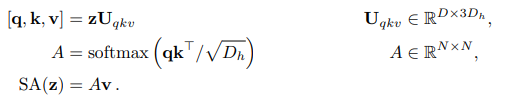
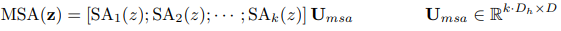
- 일반적인 Transformer의 구조를 거의 그대로 사용했음을 알 수 있습니다.
Transformer에 관한 논문 링크를 아래에 첨부하겠습니다. 더 자세한 내용은 아래 논문을 참고해주세요!
논문 링크 (Attention is all you need) : https://arxiv.org/abs/1706.03762
Hybrid Architecture
- 이미지 패치를 그대로 사용하는 대신, CNN의 결과 나온 feature map을 인풋 시퀀스로 사용할 수 있음
- 하이브리드 모델에서는 패치 임베딩 프로젝션을 CNN feature map에서 결과로 나온 패치에 대해 적용함
- 특수한 케이스로 패치는 1x1 크기를 가질 수 있는데, 이 경우는 인풋 시퀀스를 단순히 feature map에 대한 차원으로 flatten 한 후 Transformer의 차원으로 projection 한 결과임
- [CLS]에 해당하는 인풋 임베딩과 위치 임베딩은 기존 모델과 동일하게 적용함
2. Fine-tuning and higher resolution
-
VIT는 대량의 데이터셋에 대해 사전 학습한 후 더 작은 다운스트림 태스크에 fine-tuning 하는 방법을 취합니다.
-
Fine-tuning시에는 사전 학습된 prediction head를 제거하고, 0으로 초기화된 D x K차원의 FC-Layer를 연결하는 방법을 사용합니다. (K=다운스트림 태스크 카테고리 개수)
-
이때 fine-tuning단계에서는 더 높은 해상도에서 학습하는 것이 정확도 향상에 좋다는 것이 일반적으로 알려져 있습니다. 그렇기 때문에 더 높은 해상도의 이미지를 처리해야 할 경우, 이미지 패치 크기를 동일하게 유지함으로써 더 긴 패치 시퀀스를 사용하였습니다.
-
ViT는 더 높은 하드웨어의 메모리가 허용하는 한, 임의의 길이의 시퀀스를 처리할 수 있는 것이 또 하나의 장점이지만, 이 경우 사전 학습된 위치 임베딩이 의미없어지게 됩니다. 이 경우 사전학습된 위치 임베딩에 원본 이미지에서의 위치에 따라 2D interpolation을 수행해야 합니다. (제가 생각하기에는 이 부분이 본 논문에서 조금 개선되면 좋을 점인 것 같습니다.)
4.Experiments
본 논문에서 실험한 모델 사이즈는 아래 표와 같습니다.
이에 따른 결과입니다.
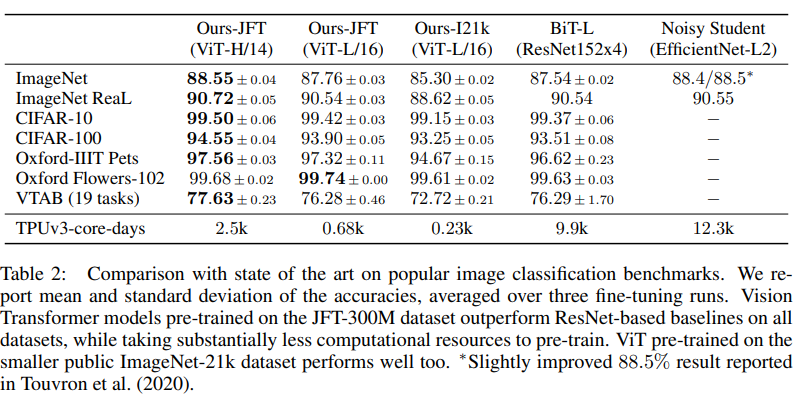
score만 가지고 ViT가 좋다라고 하기에는 실질적으로 적용하기에 힘들다는 생각이 듭니다. 이 정도 큰 dataset이 아니면 inductive bias 문제로 성능이 떨어질것이기 때문입니다.
그럼에도 연산량 면에서는 CNN 기반보다는 좋아졌고, 이것이 Multi-head의 이점입니다.
5.Conclusion
본 논문에서 이미지 인식에 트랜스포머를 직접 적용하는 방법이 제시되었습니다. 단순하지만 강력한(단순하기에 더 강력하기도 하다.) 모델은 대규모 데이터셋으로 사전학습을 진행할 때 더욱 좋은 성능을 보입니다.
즉, 성능은 다른 최신 기술들과 비교하여 더 좋거나 비슷하지만 비용이 비교적 효율적입니다.
이러한 결과는 긍정적이지만 아직 발전해야 할 과제가 남아있습니다. 그것을 아래 세 가지로 정리하였습니다.
1. ViT를 감지나 세분화와 같은 다른 컴퓨터 비전 작업에 적용
2. self-supervised 사전학습 방법 탐색을 지속
3. ViT를 추가로 확장하면 성능이 향상될 수 있음
이상으로 논문 리뷰를 마치겠습니다!
