이번에 리뷰할 논문은 삼성 SDS에서 발표한 POMO논문입니다. 본 논문에서는 조합최적화 문제를 Policy 기반의 강화학습을 활용하여 풀이하였고, 그 결과는 Heuristic 기법에 비해 굉장히 향상된 성능을 보였습니다. 본 논문에서는 TSP, KP, CVRP 등의 문제를 풀었으며 문제에 관한 설명은 아래 링크를 참고하시면 좋을 것 같습니다.
- TSP : https://ko.wikipedia.org/wiki/%EC%99%B8%ED%8C%90%EC%9B%90_%EB%AC%B8%EC%A0%9C
- KP : https://ko.wikipedia.org/wiki/%EB%B0%B0%EB%82%AD_%EB%AC%B8%EC%A0%9C
- vrp : https://en.wikipedia.org/wiki/Vehicle_routing_problem
본격적인 논문 리뷰를 시작하겠습니다!
Introduction
현실에서의 조합최적화(Combinatorial optimization, CO) 문제는 어느 곳에나 있고, 각 문제마다 제약이 다릅니다. 각 환경에 따라 제약조건이 다양하기 때문에 많은 CO문제를 전문가가 직접 휴리스틱으로 해결해 왔습니다. 앞으로 소개할 POMO는 강화학습을 이용하여 CO문제를 해결하였습니다. 심층 강화 학습은 TSP, CVRP, KP와 같은 문제에 대한 최적의 솔루션을 우수한 속도로 찾을 수 있기 때문입니다.
Related Work
- Neural combinatiorial optimization with reinforcement learning : Pointer networks에 관련한 논문입니다. 해당 논문에서는 Attention Mechanism을 변형하여 PtrNet을 제시하였습니다. 뛰어난 성능을 결과로 내주지는 못하였으나 강화학습이 조합최적화 문제를 해결할 수 있다는 점을 시사하였다는 점에서 의미가 있는 모델이며 PtrNet은 현재도 많은 논문에서 활용되고 있습니다. 조합최적화 문제를 어떻게 강화학습을 사용하여 해결할 수 있었는지, 그 처음의 접근법이 궁금하신 분들은 해당 논문을 보시면 흥미롭게 읽으실 것 같습니다. 또한 Active Search와 Beam Search같은 알고리즘도 제시하여서 강화학습을 조합최적화에 적용하는 다양한 방면의 접근법을 제시하였습니다.
- Attention, learn to solve routing problems! : 해당 논문에서는 LSTM을 활용하지 않고 Graph Attention Networks를 활용한 모델을 제시합니다. 해당 모델은 Transformer의 Encoder와 매우 비슷한 형태를 가지며, 그래프의 node와 feature을 적절히 embedding할 수 있습니다. Graph Attention Networks는 아래의 블로그를 참고하시면 설명이 잘 되어 있으니 참고하시면 좋을 것 같습니다.
https://greeksharifa.github.io/machine_learning/2021/05/29/GAT/#21-graph-attentional-layer
그리고 해당 논문에서 제시하는 또 한가지의 참고할만한 의미있는 점은, Baseline을 Greedy Rollout 기법을 활용하여 결정하고 더 나은 파라미터값을 T-test 검정을 통해 업데이트 한다는 것입니다. Rollout기법은 MC Sampling과 비슷한 개념으로, 알파고 논문에서 제시된 방법을 변형하여 사용했다고 합니다. 마찬가지로 참고하실만한 링크를 아래에 적어두겠습니다.
https://brunch.co.kr/@kakao-it/102
Motivation
같은 문제를 여러 번 반복하여 얻은 결과의 평균을 사용하던 기존의 BASELINE을 강화학습에서 사용하면 Local Optima에 빠지는 문제가 발생합니다. 인공지능이 얻은 솔루션들이 크게 다르지 않기 때문입니다. 이를 해결하기 위해 같은 문제를 다양한 각도로 대칭 변형하여 다른 문제로 인식하도록 하여 문제를 해결하였습니다.
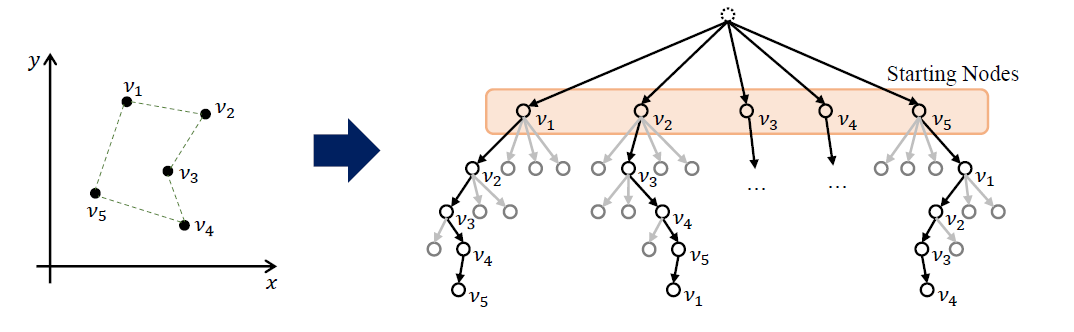
TSP로 예를 들면 (a1, a2, a3, a4, a5)와 (a2, a3, a4, a5, a1)은 동일한 최적 솔루션임을 우리는 알 수 있습니다. 즉, 어떤 노드를 먼저 출력하는지와 관계없이 동일한 솔루션을 도출하기 위해 대칭을 활용하여 폴리시를 학습하도록 하였습니다.
Policy Optimization with Multiple Optima (POMO)
Explorations from multiple starting nodes
이제, 본격적으로 POMO의 알고리즘에 대하여 설명드리겠습니다. POMO는 Starting Node를 여러군데로 지정함으로써 Multiple Optima에 관한 문제를 모델이 잘 학습하도록 하여 Local optimization의 문제를 감소시킨다고 하였습니다.
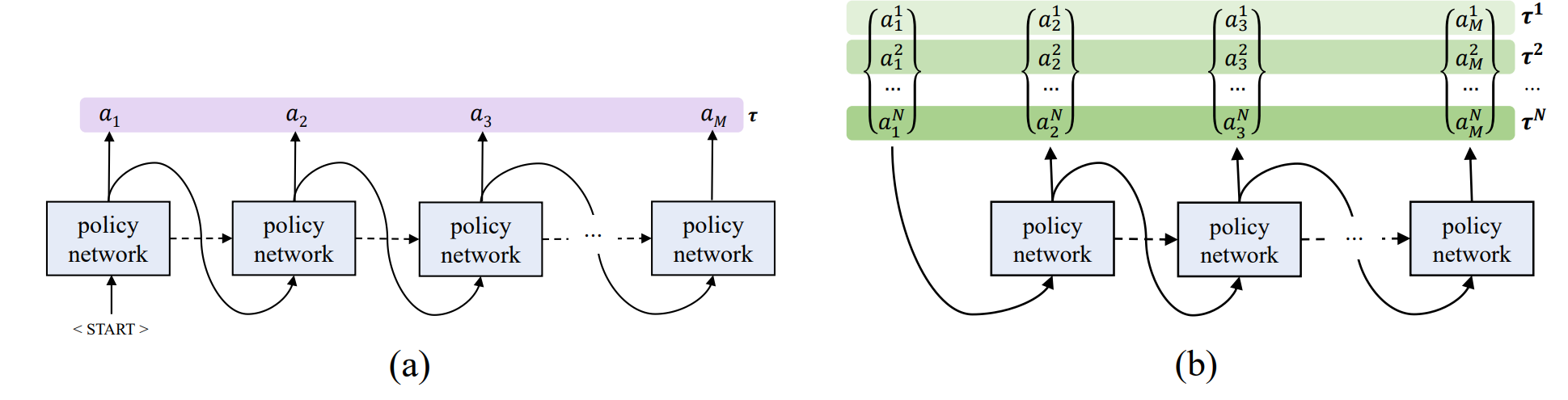
그림 (a)는 일반적인 조합최적화를 푸는 모델의 알고리즘을 나타내었습니다. 어떠한 Policy network(이 network는 RNN기반의 모델일 수도 있으며 Attention기반의 PrtNet 또는 Transformer일 수도 있습니다) 에 start token을 넣어 첫 번째 action을 뽑게 되고, TSP의 문제에서는 이 action이 어떤 노드를 방문할지를 결정하는 것입니다. 그렇게 되면 이전의 action인 output값을 다시 다음 단계의 Policy network에 넣어주고, 같은 단계를 반복합니다. 하지만 그림 (b)에서 나타나는 본 논문의 알고리즘은 그렇지 않습니다.
그림 (b)에서 보시면, POMO method는 solution을 1개가 아닌 n개를 토출합니다. 서로 다른 starting node를 Start token 대신 넣어주게 됩니다. 서로 다른 starting node에서 출발하기 때문에, 각 node에서 시작하는 tour length(TSP에서 Tour Length를 최소화시키는 문제를 푼다고 가정할 때)를 최소화하도록 구할 수 있습니다. 이 과정에서 Multiple Optima에 대한 문제를 어느 정도 해결할 수 있다는 점에 동의합니다.
이러한 POMO의 접근법은 같은 문제를 반복해서 각기 다른 각도로 바라보도록 합니다. multiple trajectories를 구하고, 모든 trajectories를 종합하여 baseline을 구하기 때문에 학습 효율을 매우 높일 수 있다고 생각합니다. 서로 다른 node에서 시작하더라도 결국 다 같은 경로를 가리킨다면, 학습이 아주 잘 된 것이겠지요? :)
A shared baseline for policy gradients
지금까지 대략적인 POMO 알고리즘을 설명드렸는데요. 이제 본격적으로 POMO는 어떠한 강화학습 알고리즘을 적용했는지 알아보겠습니다.
POMO는 REINFORCE algorithm에 기반한 모델입니다. 하지만 단지 REINFORCE만이 아니라, Baseline( b(s) )을 활용한 REINFORCE algorithm입니다.
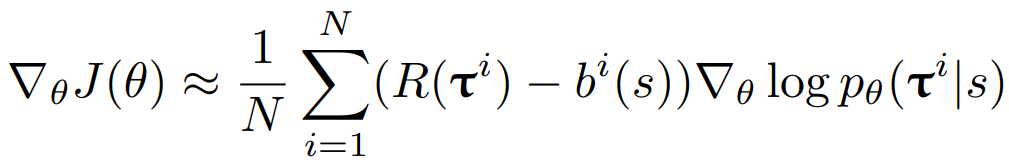
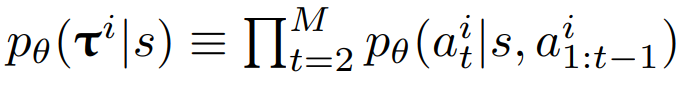
J함수는 Expected Return 함수이며 이 함수를 최소화시키기는 방향으로 critic network가 학습됩니다. 여기서 R값은 total reward(return)이며, TSP문제에서는 Tour length를 나타내므로 이 값을 최소화시키는 방향으로 학습하는 것입니다. 또한 이 baseline 함수를 구하는 식은 다음과 같습니다.
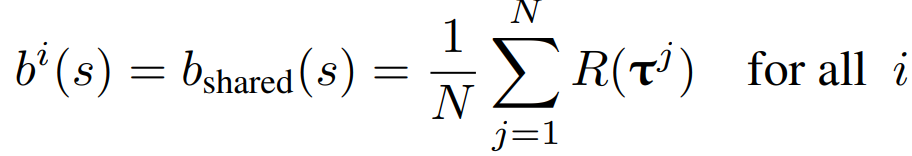
baseline은 total reward인 R의 평균값입니다. 또한 이 값이 공유됩니다. 앞서 설명드렸듯이, POMO는 한 번에 solution을 n개를 토출하게 됩니다. 이 값은 Greedy Rollout 기법을 사용합니다. (Starting node에 따라 n개의 solution) 이 n개의 solution에서 Tour length를 계산하고, 그 값들의 평균값을 b(s)로 사용한다는 의미입니다. 각 n개의 solution의 Tour length는 이 평균값보다 낮은지, 높은지를 통해 action을 평가받습니다.
이렇게 n개의 solution(trajectories)에 같은 baseline을 sharing하면 좋은 점은, local minima를 방지한다는 것입니다. N solution trajectories은 각각의 값들을 같은 값의 baseline을 활용하여 평가받기 때문에 이 액션이 좋은 액션인지, 나쁜 액션인지를 더 빠르게 파악할 수 있기에 local minima를 방지하여 학습 효율이 올라갑니다.
Multiple greedy trajectories for inference
augmentations는 한국말로 번역하자면 "보강"이라는 뜻입니다. 즉, trajectories를 augmente하겠다는 말은 solution을 보강시키겠다는 것입니다. 본 논문에서는 Ablation(증강)을 진행하였을때와 그렇지 않을때, 그리고 Ablation의 정도에 따라서도 각각 실험을 진행하여 비교함으로써 Ablation 중요성을 증명했습니다. 이에 관련한 자세한 내용은 부록에 자세히 설명되어있으니 관심 있으신 분들은 본 논문을 자세히 읽어보시기를 추천드립니다.
Training in POMO

POMO의 pseudo code를 살펴보며 POMO에서의 Training 기법을 직관적으로 이해해보겠습니다.
- 먼저, policy network parameter를 초기화합니다.
- 그리고 T step만큼 다음 내용을 진행하게 됩니다.
- Start node를 선택하고, Rollout을 통해 n개의 solution을 토출합니다.
- baseline을 Solution을 활용해 계산합니다.
- 구한 값들을 활용하여 J를 최적화시킵니다.
- parameter를 업데이트합니다.
POMO Inference

이번에는 POMO의 Test pseudo code를 설명하겠습니다.
- 구한 solution을 Agment합니다.
- Start Node를 선택합니다.
- Greedy Rollout을 통해 solution을 구합니다.
- Reward를 최대화시키는 solution을 Return합니다.
greedy rollout을 baseline에 활용하는 기법은 앞서 Related work에서 설명드린 kool의 paper를 참고하였다고 합니다. 그 기법에 대해 자세히 알고싶으시다면 해당 논문을 아래 링크로 올려둘테니, 참고하시길 바랍니다.
Kool ; Attention, learn to solve routing problems! ; https://arxiv.org/pdf/1803.08475.pdf
Experiments
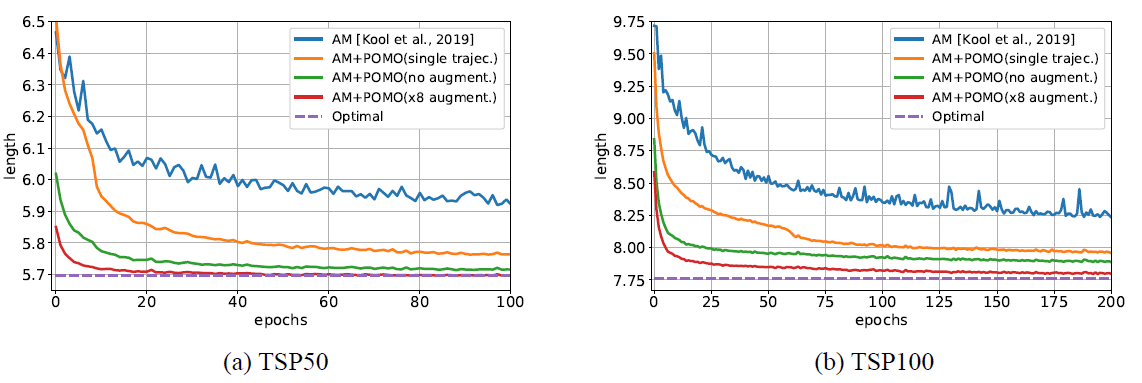
위의 두 그래프는 TSP문제의 학습곡선을 나타낸 것입니다. 기존의 방식인 파란색 선과 달리 POMO방식인 아래 세 선(노란색, 초록색, 빨간색)들이 Optimal에 더 가까운 것을 알 수 있습니다.
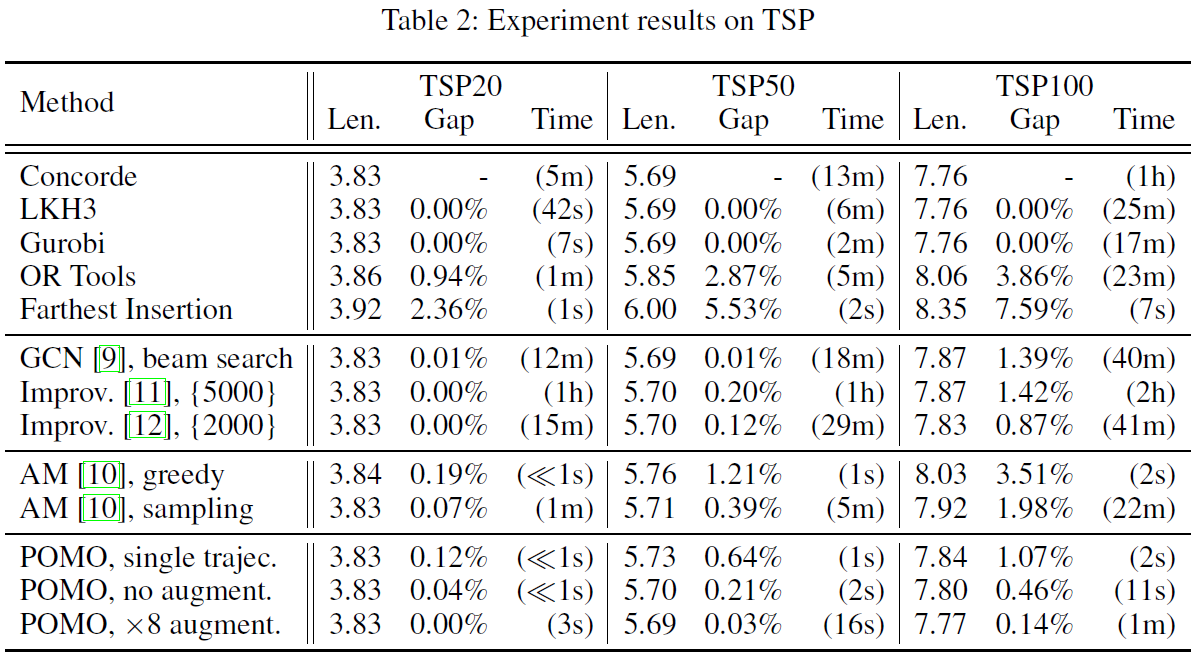
학습이 끝나고 performance를 살펴보면, TSP에 최적화된 Concorde와 비교하였을 때 시간적인 측면에서 POMO가 굉장히 우수함을 알 수 있습니다.
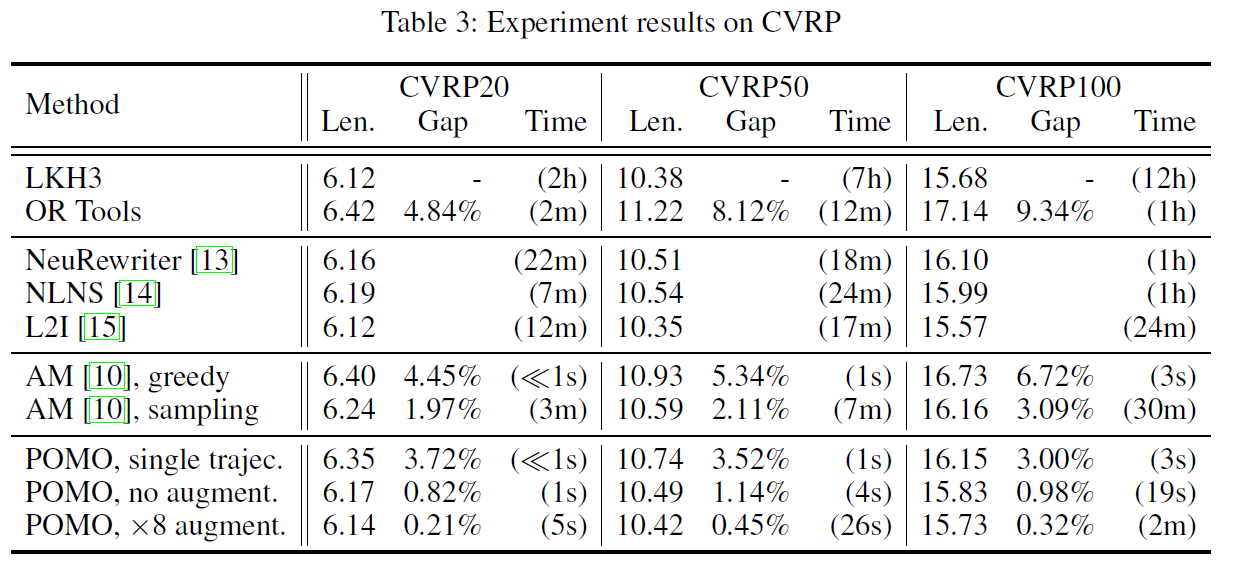
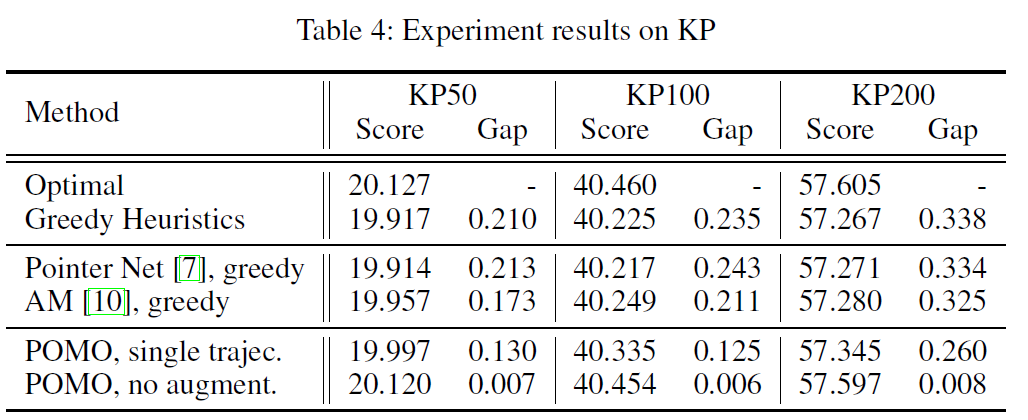
Conclusion
TSP, CVRP, KP문제를 평가해본 결과 POMO가 다른 심층강화학습 방법에 비해 시간을 단축하는데 있어 최고수준을 달성했습니다.
