- 주의: 이 포스팅은 참고자료의 내용을 노트 정리하듯 정리한 것이라 글을 그대로 갖다 쓰는 부분이 있을 수 있습니다. 또한 대회의 베이스라인에서 필요한 정보만 정리한 것이라 U-Net의 모든 정보를 담고 있지 않습니다.
U-Net
- U-Net: Biomedical 분야에서 이미지 분할(Image Segmentation)을 목적으로 제안된 End-to-End 방식의 Fully-Convolutional Network 기반 모델
End-to-End Learning: 어떤 문제를 해결할 때 필요한 여러 스텝을 하나의 신경망을 통해 '재배치'하는 과정. 데이터 크기가 클 때 효율적. 즉 데이터가 클 때 두 단계로 나누어 각각 네트워크를 구축한 후 학습한 후 그 결과를 합치는 방법이다. 이렇게 하는 이유는 스텝을 나누는 것이 성능이 더 좋기 때문이다. (참고: https://pongdangstory.tistory.com/424)
U-Net 구조(U 모양으로 생겨서 U-Net)
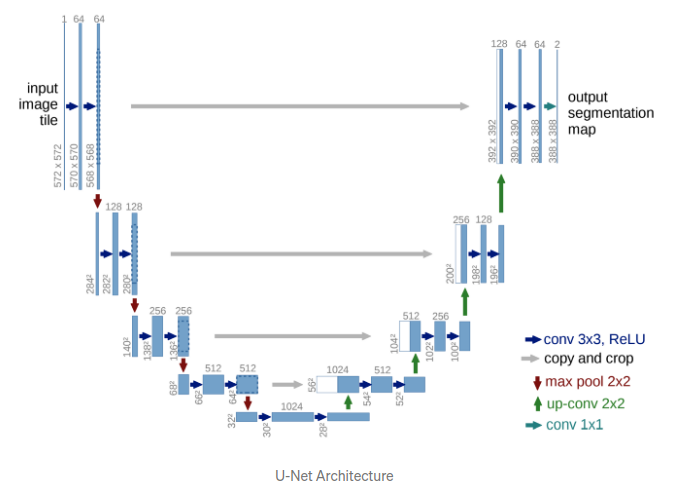
- 이미지의 전반적인 컨텍스트 정보를 얻기 위한 네트워크 + 정확한 지역화(localizataion)을 위한 네트워크
컨텍스트: 이웃한 픽셀 간의 정보, 이미지의 일부를 보고 이미지의 문맥 파악

Expanding Path는 Contracting Path에서 나온 최종 특징 맵으로부터 높은 해상도의 segmentation 결과를 얻기 위해 여러 번 Up-sampling한다. (Coarse Map-> Dense Prediction 위한 구조)
FCN(Fully convolutional network)을 토대로 확장했기 때문에 FCN을 먼저 이해해야 함. (참고: FCN 논문 리뷰)
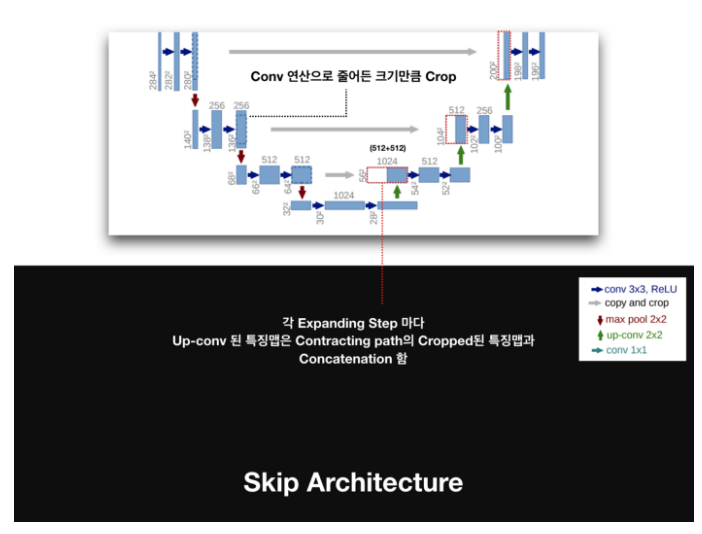
U-Net은 FCN의 "skip architecture" 개념을 활용해 얕은 층의 특징맵을 깊은 층의 특징맵과 결합하는 방식을 제안함.
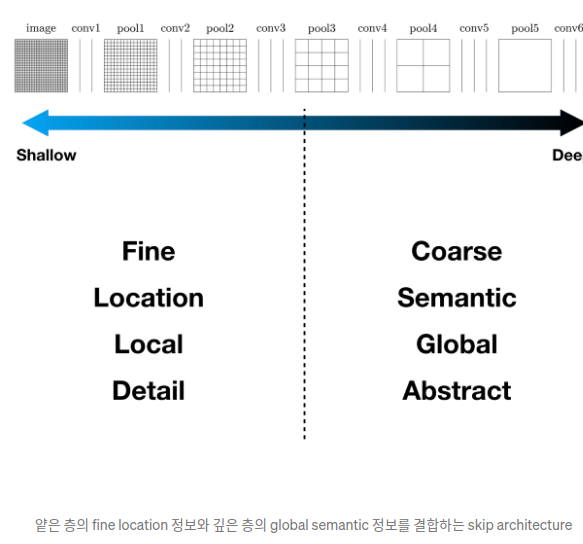
"CNN 네트워크의 Feature hierarchy의 결합을 통해 Localization과 Context (Semantic Information) 사이의 트레이드 오프를 해결할 수 있다." 의 해석
-> CNN 네트워크의 얕은 층은 국소적이고 세밀한 부분의 특징을 추출하고 깊은 층은 전반적이고 추상적인 특징을 추출한다. 서로 다른 특징을 추출하는 이 두 층을 결합해 주어서 국소적인 정보와 전역적인 정보를 모두 포함할 수 있게 한다.
국소와 전역은 서로 trade-off 관계
넓은 이미지를 한번에 인식하면 context 인식에는 효과적이나 localization는 잘 하지 못함. 좁은 이미지를 인식하면 그 반대!
구조 자세히 보기
- The Contracting Path: 이미지의 context 포착
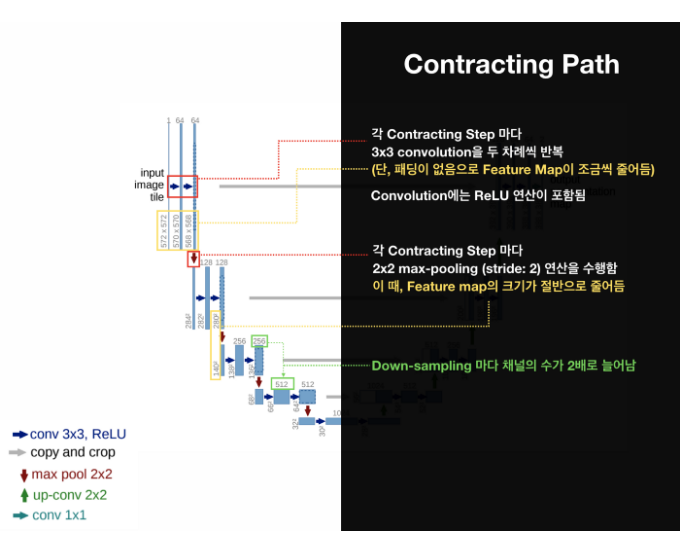
- The Expanding Path: 특징맵을 확장, 정확한 localization!
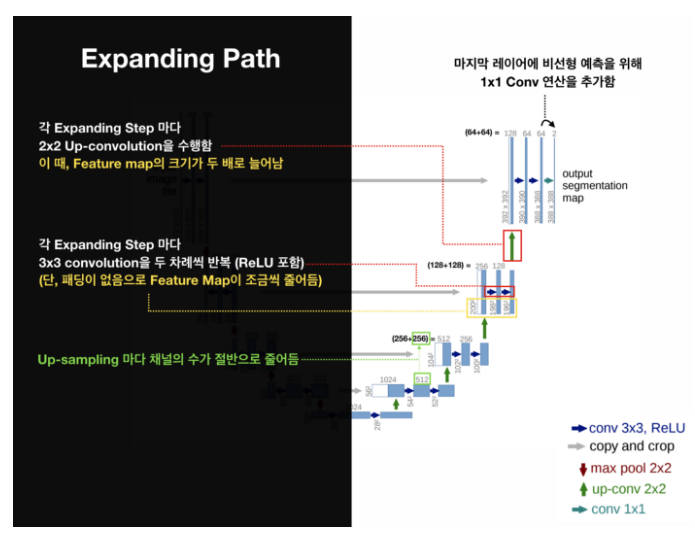
- 2x2 convolution(up-convolution): 초록
- 총 23-layers fully convolutional networks
- 최종 출력인 segmentation map의 크기는 input image 크기보다 작다. (conv 연산에서 패딩 사용하지 않아서)
이미지 경계부분 픽셀에 대한 세그멘텐이션을 위해 0이나 임의의 패딩값을 사용하는 대신 이미지 경계 부분의 미러링을 이용한 extrapolation기법(interpolation은 안의 것을 추가, extrapolation은 바깥 부분을 추가)을 사용함.
U-Net의 장점
- 양의 학습 데이터로도 Data Augmentation을 활용해 여러 Biomedical Image Segmentation 문제에서 우수한 성능을 보임
- 컨텍스트 정보를 잘 사용하면서도 정확히 지역화함
- End-to-End 구조로 속도가 빠름
- 속도가 빠른 이유: 검증이 끝난 곳은 건너뛰고 다음 Patch부터 새 검증을 하기 때문.
그래서 왜 해빙 예측에서는 U-Net을 썼는가?
"보통 연구에서 U-Net을 활용했다고 하면 기본구조(인코더, 디코더, 스킵커녁션)을 유지하고, 인코더/디코더의 구성방식이나 학습 방식을 조정했다"는 뜻이다. 즉 해빙예측에서는 이미지의 크기를 줄이면서도 이미지 내의 중요한 정보를 직접 전달(skip-connection)하여 디코더에서 선명한 이미지를 얻게 하여 보다 정확한 예측 을 할 수 있도록 한 것!
원래 U-Net은 의료 영상을 다루기 위해 개발된 모델이므로 모델 내에 Data Augmentation이 포함되어 있다. 베이스라인에서는 Data Augmentation이 빠져있지만 이 부분을 제안하는 것으로 보아 U-Net의 원래 구조에서 아이디어를 얻지 않았을까 생각함.
이 글의 출처는 velog guide333님의 글입니다.
