비용 모델과 파일 조직법
비용 모델이란? 쿼리의 최적화를 위한 방법을 말합니다.
파일 조직법 비교 기준 연산
- 스캔(Scan)
파일에 있는 모든 레코드를 가져옴. 파일에 있는 페이지들은 디스크로 부터 버퍼 풀로 반입 되어야함 - 동등 셀렉션(Equality Selection)
질의에서 요구하는 검색어와 같은 문자열임을 만족하는 모든 레코드를 가져옴 - 범위 셀렉션(Range Selection)
1에서 10까지, 홍길동에서 이순신까지 등 범위에 해당하는 모든 레코드를 가져옴 - 삽입(Insertion)
주어진 레코드를 파일에 삽입 - 삭제(Deletion)
RID로 명세된 레코드 삭제.
힙 파일
- 정렬되지 않은 단순한 형태의 파일
- 스캔 B(D+RC)
- 동등 셀렉션 후보 키에 대한 연산일 경우 0.5B(D+RC). 후보 키가 아닌 경우 스캔과 동일
- 범위 셀렉션 스캔과 동일
- 삽입 레코드가 항상 파일의 끝에 삽입된다고 가정할 경우 2D+C
- 삭제 탐색 비용 + C + D
정렬 파일
- 특정 필드를 기준으로 정렬된 파일
- 스캔
힙 파일과 다르지 않음. B(D+RC) - 동등 셀렉션
정럴 기준 필드로 검색할 경우 이진 탐색으로 Dlog2B + Clog2R. 정렬 필드가 아닌 경우 스캔과 동일 - 범위 셀렉션
정렬 기준 필드로 검색할 경우 첫 레코드를 찾는데 동등 셀렉션과 동일. 이후 범위내 스캔 - 삽입
정렬 순서를 유지하기 위해 레코드가 삽입될 위치를 검색 후 레코드 추가. 후속 페이지를 모두 로드하여 다시 저장. 탐색 비용 + B(D + RC)
해시 파일
- 특정 필드를 기준으로 정렬된 파일
- 스캔
힙 파일과 다르지 않음. B(D+RC) - 동등 셀렉션
정럴 기준 필드로 검색할 경우 이진 탐색으로 Dlog2B + Clog2R. 정렬 필드가 아닌 경우 스캔과 동일 - 범위 셀렉션
정렬 기준 필드로 검색할 경우 첫 레코드를 찾는데 동등 셀렉션과 동일. 이후 범위내 스캔 - 삽입
정렬 순서를 유지하기 위해 레코드가 삽입될 위치를 검색 후 레코드 추가. 후속 페이지를 모두 로드하여 다시 저장. 탐색 비용 + B(D + RC)

- 힙 파일은 저장 성능이 우수하고 스캔, 삽입, 삭제 연산이 빠르지만 탐색은 느립니다.
- 정렬 파일은 저장 성능이 우수하고, 삽입과 삭제 연산이 느리지만 탐색은 대단히 빠릅니다.
- 해시 파일은 저장 성능이 떨어지지만, 삽입과 삭제가 빠르며 동등 탐색에서 대단히 우수합니다. 하지만 범위 탐색은 지원하지 못하며 스캔 성능이 떨어집니다.
일반적으로 삽입보다 삭제가 많이 일어납니다. MySQL은 B트리 구조뿐이어서 선택의 여지가 없습니다.
적용
알라딘에서 책 제목으로 검색하면 어떻게 될까?
다음과 같은 책 정보 데이터베이스가 있습니다.
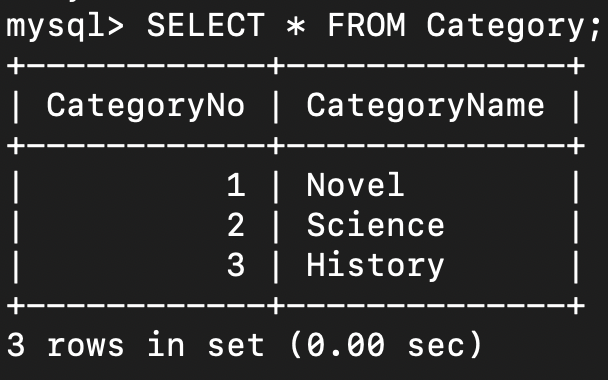
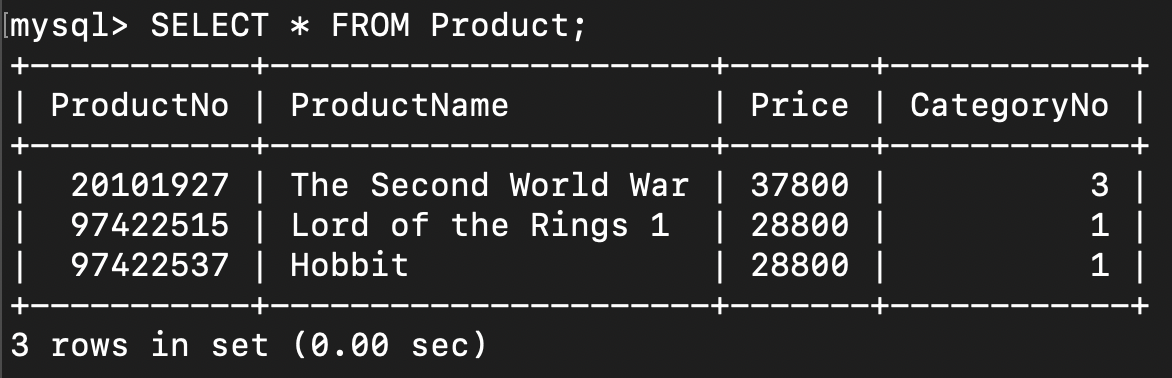
과연 책 이름으로 검색하면 얼마나 비용이 들까요?
정렬되지 않은 데이터로 검색하였기 때문에 B(D + RC)의 비용이 듭니다.
그렇다면 어떻게 해야할까요?
책 이름을 인덱스로 지정 해야합니다! 그럼 인덱스를 기준으로 정렬된 테이블이 생성되고 그 테이블에 원래 데이터의 RID(페이지 번호 + 레코드 번호) 가 저장됩니다.
그렇다면 스캔이 동등 샐랙션이 되면서 비용이 Dlog2B + Clog2R로 엄청 빨라집니다.
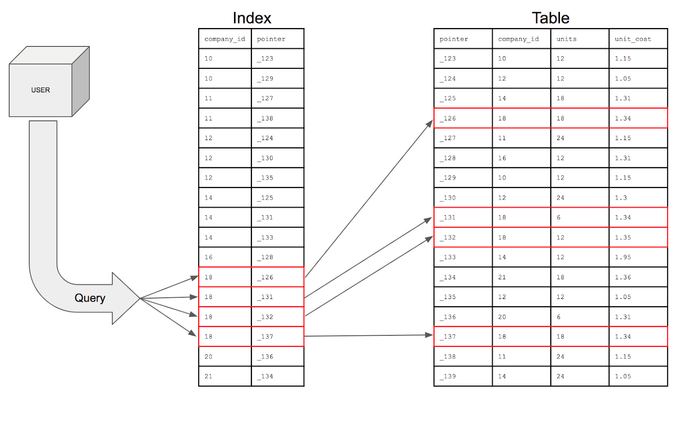
다음은 꼭 기억합시다!
⭐️ 검색이 자주 일어나는 컬럼은 인덱스처리 하기!
⭐️ 인덱스란? 데이터의 검색 속도를 높이기 위한 보조 자료 도구
⭐️ RID란? 페이지 번호 + 레코드 번호
인덱스
인덱스 개요
- 해당 파일의 기본적인 레코드 조직법으로는 효율적으로 지원되지 않는 연산의 속도를 높이기 위해 만드는 보조적인 자료구조
- 데이터 엔트리(Data Entry)들의 모임
클러스터드 인덱스 vs 넌 클러스터드 인덱스
- 파일을 조직할 때 데이터 레코드의 순서를 그 파일에 대한 어떤 인덱스의 데이터 엔트리 순서와 동일하거나 비슷하도록 조직된 인덱스를 클러스터드 인덱스(Clustered Index)라고 합니다.
- 하나의 데이터 파일은 하나의 탐색 키에 대해서만 클러스터링 될 수 있습니다. 즉, 하나의 데이터파일에는 하나의 클러스터드 인덱스만 만들 수 있습니다. 클러스터드 인덱스의 형태가 아닌 인덱스를 넌 클러스터드 인덱스(Non-clustered Index)라고 합니다.
기본 인덱스와 보조 인덱스
- 기본 키를 포함하는 필드들에 대한 인덱스를 기본 인덱스(Primary Index)라고 기본 인덱스 이외의 인덱스 이외의 인덱스들을 보조 인덱스(Secondary Index)라고 합니다.
- 기본 키가 존재하는 테이블은 기본 키가 클러스터드 인덱스가 됩니다.
복합 키 인덱스
- 인덱스가 여러 개의 필드를 포함하는 경우 복합 키(Composite Key) 또는 접합 키(Concatenated Key)라고 부름
- 데이터 조직과 쿼리 형태에 따라 높은 성능을 보임
모든 키를 인덱스화 하면 인덱스 테이블의 크기가 기존 테이블보다 훨씬 커지는 일이 발생합니다.

꿈꾸는 리얼리스트 개발자 김승규입니다.