이전 글을 마치며, 이번 글에서는 Lock과 Condition Variable이 아닌 다른 방법을 통해 동기화를 구현하는 방법을 알아본다고 했었다. 어떻게? 이번 글에서는 세마포어(Semaphore) 동기화 기법에 대해 공부해보자!
1. Semaphore Definition
세마포어의 정의에 대해 먼저 알아보자.
세마포어는 정수 값을 가지는 객체로, 아래와 같이 초기화된다.
#include <semaphore.h>
sem_t s;
sem_init(&s, 0, 1);sem_init(&s, 0, 1)의 각 인자의 의미는 아래와 같다.
-
첫 번째 인자는 초기화할 세마포어 변수이다.
-
두 번째 인자에 0을 전달하면 프로세스 내 스레드 간 세마포어를 공유한다는 의미이다.
-
세 번째 인자에 세마포어의 초기 값을 설정하는데, 위에서는 1로 초기화되었다.
세마포어는 아래의 sem_wait, sem_post 두 가지 함수를 통해 조작된다.
int sem_wait(sem_t *s) {
decrement the value of semaphore s by one
wait if value of semaphore s is negative
}
int sem_post(sem_t *s) {
increment the value of semaphore s by one
if there are one or more threads waiting, wake one
}-
sem_wait()세마포어 값을 감소시키는 함수로, 아래와 같이 동작한다.
-
세마포어 값이 1 이상일 경우
sem_wait()가 호출되었을 때 세마포어의 값이 1 이상이면, 호출한 스레드는 즉시 반환된다. 이 경우, 세마포어 값을 1 감소시키고, 해당 스레드는 자원을 사용할 수 있게 된다. -
세마포어 값이 0일 때
호출한 스레드는 수행을 중단하고 대기 상태로 들어간다. 이후 다른 스레드가sem_post()를 호출해 세마포어 값을 증가시키면, 대기 중인 스레드가 깨어나 실행을 재개한다. -
세마포어 값이 음수일 때
세마포어의 값이 음수라면, 이는 대기 중인 스레드의 수와 동일하다. 예를 들어, 세마포어 값이 -3이라면, 현재 3개의 스레드가sem_wait()을 통해 대기 중임을 의미한다.
-
-
sem_post()세마포어 값을 증가시키는 함수이다.
대기 중인 스레드가 있다면 그 중 하나를 깨워 실행 상태로 전환한다.
2. Binary Semaphores (Locks)
세마포어가 무엇인지 알아봤으니, 이를 사용하여 어떻게 동기화를 구현하는지 살펴보자.
sem_t m;
sem_init(&m, 0, 1);
sem_wait(&m);
// critical section here
sem_post(&m);위는 sem_wait(&m);과 sem_post(&m);을 사용하여 Critical Section을 보호하는 예시인데, 여기서 중요한 점은 세마포어의 값을 1로 초기화했다는 점이다. 왜? 아래의 예시를 살펴보자.

T0이 sem_wait(&m);을 호출한 시점에 세마포어의 값이 1이었으므로, 값을 0으로 내린 후 즉시 Critical Section에서 실행될 수 있다. 실행이 끝나면, sem_post(&m);을 호출하여 세마포어의 값을 다시 1로 올려준다.
즉, 세마포어의 값을 1로 초기화하는 이유는 Critical Section에 동시에 하나의 스레드만 접근할 수 있도록 보장하기 위해서이다.
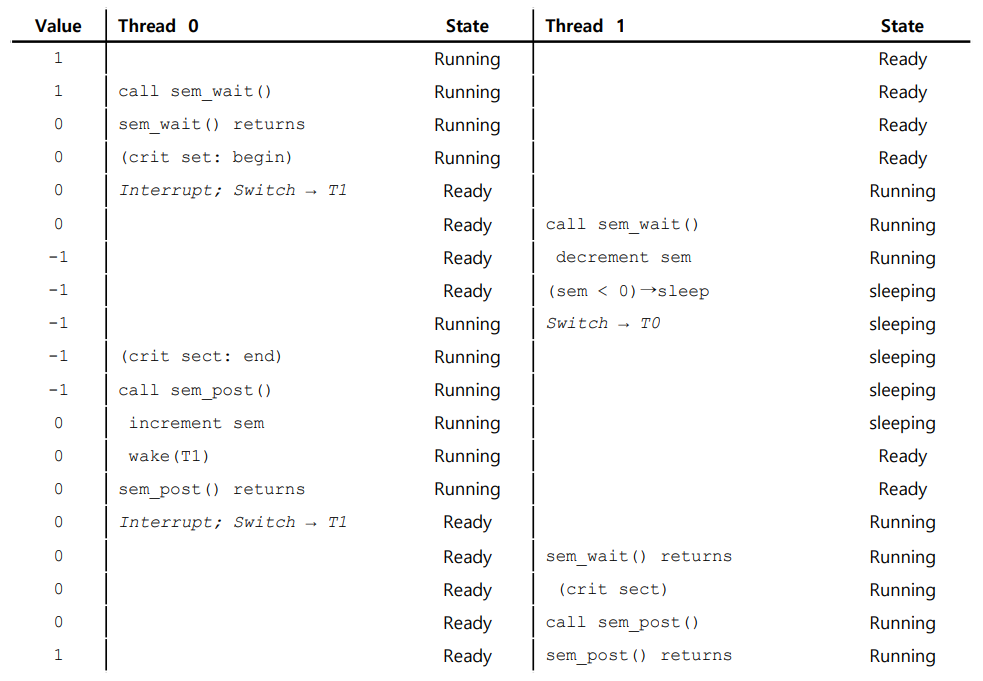
이번에는 두 개의 스레드 T0, T1이 세마포어를 사용하는 예시를 살펴보자.
-
T0이
sem_wait(&m);을 호출하여, 세마포어의 값을 0으로 내리고 즉시 실행된다. -
이 때, T0의 작업이 끝나기 전에 T1으로 컨텍스트 스위칭되어 T1 또한
sem_wait(&m);을 호출한다. 하지만 현재 세마포어의 값이 0이기에, T1이 세마포어의 값을 1만큼 감소시키며 음수가 되었고, T1은 잠들게 된다. -
다시 T0으로 컨텍스트 스위칭되어, T0은 작업을 완료한 후
sem_post(&m);을 호출하여 세마포어 값을 1 올려주고 T1을 깨워준다. -
T1으로 컨텍스트 스위칭되어, T1 또한 작업을 완료한 후
sem_post(&m);을 호출하여 세마포어 값을 1 올려준다.
먼저, 왜 Binary Semaphore, 즉 이진 세마포어일까?
위의 세마포어는 값으로 오직 두 가지 상태만 가질 수 있기 때문이다. 1, 0, -1과 같이 여러가지 상태를 가진다고 생각할 수 있지만, 결과적으로 "Lock"과 "Unlock" 두 가지 상태만 가진다고 할 수 있다. 그렇다면 세마포어는 Lock을 사용한 뮤텍스 기법과 무슨 차이가 있는걸까?
뮤텍스는 잠금(Locking) 메커니즘으로, 자원을 점유한 스레드만 잠금을 해제할 수 있기 때문에, 세마포어처럼 신호(sem_post)를 보낼 수 있는 기능은 없다. 반면, 세마포어는 신호(Signaling) 메커니즘을 사용하여, 자원을 점유하지 않은 스레드도 신호(sem_post)를 보낼 수 있다. 따라서, 이진 세마포어는 뮤텍스처럼 사용할 수 있지만, 뮤텍스는 세마포어처럼 사용할 수 없다.
지금은 둘의 차이점과 세마포어의 강력함이 와닿지 않을지라도, 글을 읽으며 다양한 문제를 세마포어로 해결해나가는 과정을 보면 자연스럽게 이해하게 될 것이다!
3. Semaphores For Ordering
세마포어를 통해 스레드의 실행 순서 또한 보장할 수 있다. 익숙한 개념이 생각나지 않는가? 맞다! 세마포어는 Condition Variable로서의 기능 또한 수행할 수 있다.
아래는 이제는 익숙한 부모 스레드가 자식 스레드의 완료를 기다리는 예제이다.
sem_t s;
void *child(void *arg) {
printf("child\n");
sem_post(&s); // signal here: child is done
return NULL;
}
int main(int argc, char *argv[]) {
sem_init(&s, 0, 0);
printf("parent: begin\n");
pthread_t c;
Pthread_create(&c, NULL, child, NULL);
sem_wait(&s); // wait here for child
printf("parent: end\n");
return 0;
}이번에도 중요한 점은, 세마포어의 값을 0으로 초기화했다는 점이다. 아래의 과정을 통해 그 이유를 이해해보자.

-
세마포어의 값이 0인 상태에서, 부모 스레드가
sem_wait()을 호출하여 세마포어의 값을 1 내렸다. 세마포어의 값은 -1이 되고, 부모 스레드는 잠들게 되었다. -
부모 스레드가 잠들었기 때문에, 대기중이던 자식 스레드가 실행된다. 자식 스레드의 실행이 완료된 후
sem_post()를 통해 세마포어의 값을 다시 0으로 올려주고, 부모 스레드를 깨워준다. -
깨어난 부모 스레드는 작업을 이어간다.
이번에는 부모 스레드가 잠들기 전에 자식 스레드로 컨텍스트 스위칭된 상황을 살펴보자.

-
부모 스레드가
sem_wait()을 호출하기 전 자식 스레드로 컨텍스트 스위칭되었다. -
자식 스레드는 실행을 완료한 후
sem_post()를 통해 세마포어의 값을 1로 올려주고, 현재 대기하고 있는 스레드가 없으므로 아무 작업도 수행하지 않고 반환된다. -
다시 부모 스레드로 컨텍스트 스위칭되어
sem_wait()을 호출하였다. 하지만 자식 스레드로 인해 현재 세마포어의 값은 1이기 때문에, 부모 스레드는 잠들지 않고 작업을 완료할 수 있게 된다.
결과적으로 두 경우 모두 정상적으로 작동하는 것을 볼 수 있다. 부모 스레드가 자식 스레드의 작업 완료를 기다리도록 하기 위해 이번에는 세마포어의 초기값을 0으로 설정했다는 점을 알 수 있다. 이제 슬슬 세마포어의 유연함이 보이는가?
4. The Producer/Consumer (Bounded Buffer) Problem
이전에 Lock과 Conditional Variable로 해결했던 유한 버퍼 문제를 이번에는 세마포어를 통해 해결해보자!
유한 버퍼 문제가 무엇인지 잘 모르겠다면 이전 글 Conditional Variables을 먼저 읽어보는 것을 추천한다.
int buffer[MAX];
int fill = 0;
int use = 0;
void put(int value) {
buffer[fill] = value; // Line F1
fill = (fill + 1) % MAX; // Line F2
}
int get() {
int tmp = buffer[use]; // Line G1
use = (use + 1) % MAX; // Line G2
return tmp;
}위는 초기 코드이다. fill은 생산자가 데이터를 넣을 버퍼의 인덱스. use는 소비자가 데이터를 가져올 버퍼의 인덱스로, 모두 순차적으로 증가하며 Circular Queue를 순회한다.
해당 코드는 멀티 스레드 환경에서 정상적으로 동작할 수 없다. (Race Condition) 세마포어를 사용하여 문제를 단계적으로 해결해보자.
1) First Attempt
세마포어를 적용한 첫 번째 버전이다.
sem_t empty;
sem_t full;
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&empty); // Line P1
put(i); // Line P2
sem_post(&full); // Line P3
}
}
void *consumer(void *arg) {
int tmp = 0;
while (tmp != -1) {
sem_wait(&full); // Line C1
tmp = get(); // Line C2
sem_post(&empty); // Line C3
printf("%d\n", tmp);
}
}
int main(int argc, char *argv[]) {
// ...
sem_init(&empty, 0, MAX); // MAX are empty
sem_init(&full, 0, 0); // 0 are full
// ...
}위의 코드는 이전에 Lock과 CV를 이용하여 구현했던 것처럼, empty와 full 두 개의 세마포어를 사용하여 여러 생산자와 소비자가 안전하게 공유 버퍼를 사용하도록 한 예시이다.
하지만 문제는 MAX 값이 1보다 클 경우 발생한다! 왜? MAX 값이 10이고, 두 생산자가 거의 동시에 put을 수행하는 경우를 생각해보자.
sem_init(&empty, 0, MAX);해당 부분에서, 세마포어는 10으로 초기화되기 때문에, 두 생산자 모두 wait 하지 않고 버퍼에 값을 넣으려고 시도한다. 이 경우, 두 생산자가 거의 동시에 put 요청을 수행할 경우, 큐의 같은 인덱스에 두 생산자의 데이터가 덮어 씌워져버리는 Race Condition이 발생하게 된다!
void put(int value) {
buffer[fill] = value; // Line F1
fill = (fill + 1) % MAX; // Line F2
}put의 위 부분에서, 두 생산자가 같은 fill 인덱스에 접근하는 문제가 생기게 된다.
왜 이런 문제가 발생했을까? 우리는 현재 세마포어를 Condition Variable처럼 사용하려고 했지만, 큐의 인덱스를 업데이트하는 과정에서 Mutual Exclusion을 깜박한 것이 문제이다!
2) Adding Mutual Exclusion (Incorrectly)
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&mutex); // Line P0 (NEW LINE)
sem_wait(&empty); // Line P1
put(i); // Line P2
sem_post(&full); // Line P3
sem_post(&mutex); // Line P4 (NEW LINE)
}
}
void *consumer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&mutex); // Line C0 (NEW LINE)
sem_wait(&full); // Line C1
int tmp = get(); // Line C2
sem_post(&empty); // Line C3
sem_post(&mutex); // Line C4 (NEW LINE)
printf("%d\n", tmp);
}
}
int main(int argc, char *argv[]) {
// . . .
sem_init(&empty, 0, MAX);
sem_init(&full, 0, 0);
sem_init(&mutex, 0, 1);
// . . .
}수정된 코드에서는 sem_wait(&mutex);와 sem_post(&mutex);을 추가하여 put, get 과정에서 Mutual Exclusion을 보장하였다. 하지만 위의 방법은 DeadLock 문제를 유발한다. 아래의 동작 과정을 살펴보자.
-
소비자는
sem_wait(&mutex);를 통해 뮤텍스 세마포어를 먼저 획득한다. (Line C0) -
그 후, 소비자는
sem_wait(&full);을 사용해full세마포어를 기다린다. (Line C1) -
sem_wait(&full)을 호출한 후, 만약full세마포어의 값이 0이면 소비자는 블록되어 대기 상태에 들어가게 된다. -
이후, 생산자는
sem_wait(&mutex);을 사용해 뮤텍스 세마포어를 기다린다. (Line P0) -
하지만, 이 때 소비자가 여전히 뮤텍스 세마포어를 들고 있기 때문에, 생산자는 뮤텍스를 획득할 수 없고 대기 상태에 들어간다.
이는 두 스레드가 무한 대기 상태에 빠지는 전형적인 DeadLock 문제이다. (DeadLock 문제는 다음 글에서 자세히 알아보도록 하자.) 해당 어떻게 문제를 해결할 수 있을지 생각해보자.
3) Finally, A Working Solution
소비자가 뮤텍스 세마포어를 들고 잠들어버린 문제의 본질에 대해 생각해보면, 이후 잠들지 말지 확실하지 않은 상태에서 뮤텍스 세마포어를 들고 있었다는 것이 문제라는 결론에 도달하게 된다.
그렇다면? full, empty 세마포어를 획득했을 경우에만 뮤텍스 세마포어(글로벌 락)을 획득하도록, 단순히 순서만 바꿔주면 될 일이다! 아래의 코드를 읽어보자.
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&empty); // Line P1
sem_wait(&mutex); // Line P1.5 (MUTEX HERE)
put(i); // Line P2
sem_post(&mutex); // Line P2.5 (AND HERE)
sem_post(&full); // Line P3
}
}
void *consumer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
sem_wait(&full); // Line C1
sem_wait(&mutex); // Line C1.5 (MUTEX HERE)
int tmp = get(); // Line C2
sem_post(&mutex); // Line C2.5 (AND HERE)
sem_post(&empty); // Line C3
printf("%d\n", tmp);
}
}위와 같이 DeadLock 문제를 해결할 수 있고, 이것이 세마포어로 유한 버퍼 문제를 성공적으로 해결한 버전이다.
5. Reader-Writer Locks
다음 주제로 넘어가자. 이번에는 Reader-Writer Lock에 대해 알아보자.
Reader-Writer Lock은 여러 개의 reader 스레드가 동시에 공유 자원에 접근할 수 있도록 하면서, writer는 자원에 대한 독점적인 접근을 보장하는 방식이다. 즉, 읽기 작업은 동시에 여러 스레드가 가능하지만, 쓰기 작업은 독점적으로 이루어지도록 한다.
코드가 복잡해보이지만 천천히 보면 별게 없다.
typedef struct _rwlock_t {
sem_t lock; // binary semaphore (basic lock)
sem_t writelock; // allow ONE writer/MANY readers
int readers; // #readers in critical section
} rwlock_t;
void rwlock_init(rwlock_t *rw) {
rw->readers = 0;
sem_init(&rw->lock, 0, 1);
sem_init(&rw->writelock, 0, 1);
}
void rwlock_acquire_readlock(rwlock_t *rw) {
sem_wait(&rw->lock);
rw->readers++;
if (rw->readers == 1) // first reader gets writelock
sem_wait(&rw->writelock);
sem_post(&rw->lock);
}
void rwlock_release_readlock(rwlock_t *rw) {
sem_wait(&rw->lock);
rw->readers--;
if (rw->readers == 0) // last reader lets it go
sem_post(&rw->writelock);
sem_post(&rw->lock);
}
void rwlock_acquire_writelock(rwlock_t *rw) {
sem_wait(&rw->writelock);
}
void rwlock_release_writelock(rwlock_t *rw) {
sem_post(&rw->writelock);
}-
rwlock_t구조체는 바이너리 세마포어lock, 세마포어writelock, 현재 읽기 작업을 수행 중인 reader의 수readers를 갖고 있다. -
writelock은 단순히 write 작업 전sem_wait(&rw->writelock);을 통해 접근을 막고, write 작업 이후sem_post(&rw->writelock);을 통해 접근을 풀어주도록 동작한다. -
readers의 경우, read 작업이 수행될 때마다rw->readers++;를 수행한 후,if (rw->readers == 1)조건을 통해, write 스레드가 read 작업을 기다리도록sem_wait(&rw->writelock);을 호출한다. -
반대로, 현재 reader가 0일 경우,
sem_post(&rw->writelock);을 통해 write 스레드가 실행될 수 있도록 한다.
단순히 살펴보더라도, writer 입장에서는 상당히 불공정한 방식이라는 점을 알 수 있다.
이러한 writer thread starvation 문제를 해결하는 방법으로, writer thread에 우선순위를 주는 방식이 있다. 엥? 그러면 reader thread는? reader thread는 writer thread와 달리 여러 스레드가 병렬 실행이 가능하므로(읽기 작업), 우선권이 없더라도 크게 성능이 떨어지지 않을 가능성이 높다.
6. The Dining Philosophers
이번에는 다들 한번쯤 들어봤을 정도로 유명한 Dining Philosophers 문제를 세마포어를 사용하여 해결해보자.
먼저 Dining Philosophers 문제가 무엇인지 알아볼까?
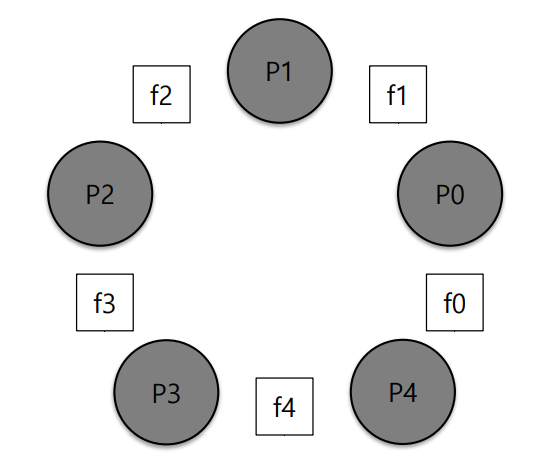
원탁에 철학자들(P0~P4)와 포크(f0~f4)가 있을 때, 철학자들이 음식을 먹기 위해 두 개의 포크를 짚는 과정을 수도 코드로 나타내면 아래와 같다. (각 철학자는 음식을 먹기 위해 두 개의 포크 모두 필요하다고 가정한다.)
while (1) {
think();
get_forks(p);
eat();
put_forks(p);
}각 철학자는 생각하고, 포크를 짚고, 먹고, 포크를 내려놓는다. 그러면 포크를 짚는 과정 또한 수도 코드로 나타내보자.
int left(int p) { return p; }
int right(int p) { return (p+1) % 5; }left는 왼쪽 포크를, right는 오른쪽 포크를 짚는 과정이다.
1) Broken Solution
void get_forks(int p) {
sem_wait(&forks[left(p)]);
sem_wait(&forks[right(p)]);
}
void put_forks(int p) {
sem_post(&forks[left(p)]);
sem_post(&forks[right(p)]);
}포크를 짚는다는 행위 자체가, 해당 포크에 대해 Lock을 걸어놓는 것과 같으므로 위와 같이 세마포어를 통해 get_forks, put_forks 수도 코드를 표현할 수 있다.
모든 철학자가 위의 수도 코드대로 움직인다면 어떤 상황이 발생할까? 모든 철학자들이 먼저 자신의 왼쪽에 있는 포크를 짚으면, 당연히 오른쪽에 있는 포크는 짚을 수 없게 된다. 결과적으로, 그 누구도 밥을 먹을 수 없는 DeadLock이 발생하게 된다.
2) A Solution: Breaking The Dependency
위의 문제는 의존 순환으로 인해 발생한다. 즉, P0 철학자는 P4로 인해, P4는 P3으로 인해 오른쪽 포크를 얻지 못하게 되는 것이다.
따라서 이 순환을 끊어주기 위해, 한 명의 철학자는 오른쪽 포크부터 짚도록 수정할 수 있다.
void get_forks(int p) {
if (p == 4) {
sem_wait(&forks[right(p)]);
sem_wait(&forks[left(p)]);
} else {
sem_wait(&forks[left(p)]);
sem_wait(&forks[right(p)]);
}
}위와 같이 구현할 경우, 마지막 철학자는 오른쪽 포크부터 짚도록 시도한다. 마지막 철학자가 오른쪽 포크를 짚는 데 성공할 경우, 마지막 철학자는 밥을 먹을 수 있게 되고, 마지막 철학자가 오른쪽 포크를 짚는 데 실패할 경우, 마지막 철학자의 오른쪽에 있는 철학자가 밥을 먹을 수 있게 된다.
어찌 보면 바보 같고 엉뚱한(?) 문제인 Dining Philosophers 문제를 세마포어를 사용한 수도 코드로 해결해봤다.
7. How To Implement Semaphores
마지막으로, 우리의 세마포어인 Zemaphore를 구현하는 과정을 살펴보자.
typedef struct __Zem_t {
int value;
pthread_cond_t cond;
pthread_mutex_t lock;
} Zem_t;
// only one thread can call this
void Zem_init(Zem_t *s, int value) {
s->value = value;
Cond_init(&s->cond);
Mutex_init(&s->lock);
}
void Zem_wait(Zem_t *s) {
Mutex_lock(&s->lock);
while (s->value <= 0)
Cond_wait(&s->cond, &s->lock);
s->value--;
Mutex_unlock(&s->lock);
}
void Zem_post(Zem_t *s) {
Mutex_lock(&s->lock);
s->value++;
Cond_signal(&s->cond);
Mutex_unlock(&s->lock);
}-
위에서 설명한 세마포어와 유사하게
value,cond,lock을 멤버 변수로 갖고 있다. -
다른 점은 세마포어의 값이 음수가 될 수 없다는 점이다.
-
즉, Zemaphore에서는 대기 중인 스레드 수를 직접 추적하지 않고, 세마포어 값이 음수가 되는 것을 방지한다. 이는 세마포어를 더 간단한 방식으로 구현할 수 있도록 하는데, 현재 리눅스 구현과 일치한다.
마치며
운영체제 시리즈의 마지막이 보이기 시작하는 것 같다! 다음 글은 Concurrency 파트의 마지막 내용인 Common Concurrency Problems에 대해 알아보도록 하겠다.
