이번 글에서는 Concurrency 파트의 마지막 내용인 Common Concurrency Problems에 대해 알아보도록 하겠다!
운영체제를 수강했던 당시 Concurrency 주제 이후에도 Hard Disk, RAID, File System 등의 주제를 다뤘지만, 이번 시리즈는 운영체제의 전반적인 이해를 목표로 하는 만큼 Concurrency 파트까지만 다룰 예정이다.
1. What Types Of Bugs Exist?
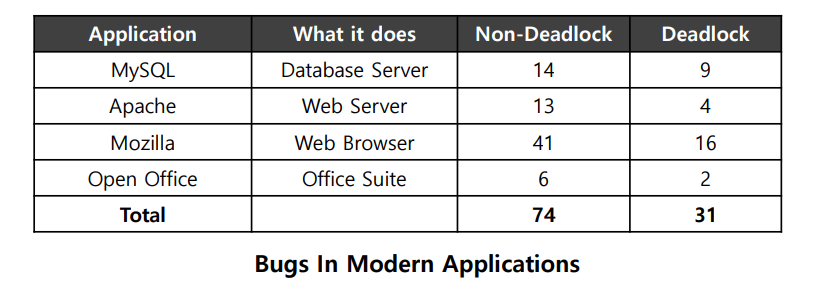
위의 표는 많은 사람들이 사용하는 오픈소스 어플리케이션인 MySQL, Apache, Mozilla, OpenOffice에서 발생한 오류들의 종류를 보여준다.
위의 표를 보면, Non-Deadlock 버그가 Deadlock 버그에 비해 두 배나 많다는 것을 볼 수 있다.
Deadlock이란?
Deadlock이란, 두 개 이상의 프로세스(또는 스레드)가 서로 자원을 점유한 채로 다른 프로세스가 점유 중인 자원을 기다리면서 아무것도 실행하지 못하는 상태를 의미한다.
우리는 이미 이전 글에서 세마포어로 유한 버퍼 문제를 해결하는 과정에서 이러한 DeadLock 문제를 마주했었다.
2. Non-Deadlock Bugs
Deadlock 버그에 비해 약 두 배 더 많이 발생하는 Non-Deadlock 버그에 대해 먼저 알아보자. Non-Deadlock 버그는 원자성 위반(Atomicity Violation)과 순서 위반(Order Violation)의 두 가지 주요 유형으로 나눌 수 있다.
1) Atomicity Violation
원자성 위반! 이제 용어만 보더라도 어떤 의미인지 유추할 수 있다.
원자성은 작업이 "모두 실행되거나, 전혀 실행되지 않아야 한다"는 속성을 의미한다. 따라서 원자성 위반이란, 한 스레드가 원자적으로 실행되지 못하고, 실행 도중 다른 스레드로 인해 의도치 않은 결과를 초래한 상황이라고 볼 수 있겠다.
그렇다! 우리가 지금까지 공부했던, Critical Section에서 Mutual Exclusion이 보장되지 않은 상황이라고 볼 수 있겠다.
Thread 1::
if (thd->proc_info) {
fputs(thd->proc_info, ...);
}
Thread 2::
thd->proc_info = NULL;위는 MySQL에서 찾을 수 있는 간단한 예시이다. 공유 자원 thd->proc_info의 접근에 대해 Mutual Exclusion이 보장되지 않았기 때문에 문제가 발생한다.
-
Thread 1이
thd->proc_info이NULL이 아닌 것을 확인한 후,fputs작업을 수행하기 직전에 Thread 2로 컨텍스트 스위칭되었다. -
여기서, Thread 2가
thd->proc_info를NULL로 바꿔버렸다. -
다시 Thread 1로 컨텍스트 스위칭되었을 때, Thread 1은
fputs부터 실행을 이어나가게 된다.fputs는 예기치 못하게NULL인자를 넘겨받게 되므로, 에러가 발생한다.
이런 종류의 문제는 이제 지겹도록 봐왔다! Mutual Exclusion이 보장되지 않은 것이 문제이므로, Lock으로 공유 자원에 접근하는 부분(Critical Section)을 감싸주면 되겠지?
Thread 1::
pthread_mutex_lock(&proc_info_lock);
if (thd->proc_info) {
fputs(thd->proc_info, ...);
}
pthread_mutex_unlock(&proc_info_lock);
Thread 2::
pthread_mutex_lock(&proc_info_lock);
thd->proc_info = NULL;
pthread_mutex_unlock(&proc_info_lock);수정된 코드에서는 공유 자원에 접근하는 부분을 lock과 unlock으로 감싸주었다. 쉽게 해결!
2) Order Violation
순서 위반 또한, 보자마자 Condition Variable과 관련된 문제라는 것이 느껴진다면 Concurrency에 대한 내용을 전반적으로 이해한 것이다!
순서 위반은 스레드들이 메모리에 엑세스하는 순서가 기대한대로 보장되지 않은 상황이다. 이번에도 아래의 MySQL 예시를 살펴보자.
Thread 1::
void init() {
mThread = PR_CreateThread(mMain, ...);
}
Thread 2::
void mMain(...) {
mState = mThread->State;
}-
Thread 1은
init()작업을 수행하는데, 해당 부분에서mThread를 초기화하고 있다. -
Thread 2는
mThread에서State값을 읽어mState변수에 저장한다. -
우리가 기대하는 실행 흐름은 Thread 1 -> Thread 2이지만, 만약 Thread 2가 먼저 실행된다면 초기화되지 않은 메모리에 접근하는 문제 상황이 발생한다!
스레드들의 실행 순서를 보장하기 위한 방법으로, 우리는 일종의 대기열로 표현되는 Condition Variable에 대해 알아봤었다. 수정된 코드는 아래와 같다.
pthread_mutex_t mtLock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t mtCond = PTHREAD_COND_INITIALIZER;
int mtInit = 0;
Thread 1::
void init() {
...
mThread = PR_CreateThread(mMain, ...);
// signal that the thread has been created...
pthread_mutex_lock(&mtLock);
mtInit = 1;
pthread_cond_signal(&mtCond);
pthread_mutex_unlock(&mtLock);
...
}
Thread 2::
void mMain(...) {
...
// wait for the thread to be initialized...
pthread_mutex_lock(&mtLock);
while (mtInit == 0)
pthread_cond_wait(&mtCond, &mtLock);
pthread_mutex_unlock(&mtLock);
mState = mThread->State;
...
}수정된 코드에서는 Lock과 CV를 사용하여 Thread 1이 Thread 2보다 먼저 실행되도록 보장하고 있다. 초기화 여부를 나타내는 mInit 변수를 사용함으로써, 초기화 전 Thread 2가 실행되는 경우 while (mtInit == 0) 내부의 wait을 통해 대기하게 된다. 이 또한 쉽게 해결!
3. Deadlock Bugs
1) Deadlock Bugs
사실 위의 Non-Deadlock 버그는 지금까지 해결해왔던 문제들이기 때문에 어려울게 없었다. 이번에는 Deadlock 버그에 대해서 살펴보자.
앞서 Deadlock의 의미에 대해 설명했지만, 아래의 예시를 통해 Deadlock이 어떠한 문제 상황을 의미하는 것인지 명확히 이해해보자.
Thread 1: Thread 2:
pthread_mutex_lock(L1); pthread_mutex_lock(L2);
pthread_mutex_lock(L2); pthread_mutex_lock(L1);위 상황에서 Thread 1은 L1 Lock을 먼저 획득한 후 L2 Lock을 획득하려고 시도하고, 반대로 Thread 2는 L2 Lock을 먼저 획득한 후 L1 Lock을 획득하려고 시도한다. 이 상황을 그림으로 나타내면 아래와 같다.
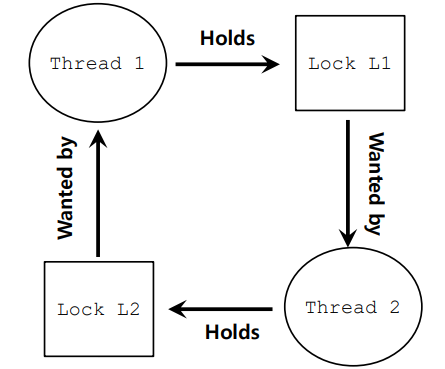
말로만 이해하려고 해도 어려울 건 없지만, 그림을 보면 문제 상황이 Cycle 형태로 발생한다는 것을 더 명확하게 인지할 수 있다. 그렇다면 어떻게 이 Cycle을 해소할 수 있을까?
2) Why Do Deadlocks Occur?
먼저 위와 같은 상황, Deadlock이 왜 발생하는 것인지 이유를 먼저 생각해보자.
-
복잡한 의존성
코드가 커지고 복잡해질수록, 서로 다른 컴포넌트 간에 복잡한 의존 관계가 생기게 된다. 이로 인해 의존성 순환 문제가 생기기 쉬워진다. -
캡슐화(encapsulation)의 특성
캡슐화는 구현 세부 사항을 숨기고, 소프트웨어를 모듈 단위로 쉽게 구축할 수 있도록 하는 중요한 개념이다. 그러나 캡슐화는 Locking과 잘 어울리는 개념이 아닌데, 이해가 부족한 상태로 여러 모듈을 채택할수록 동기화 문제가 생기기 쉬워지기 때문이다.
3) Conditional for Deadlock
이번에는 Deadlock이 발생하기 위한 조건이 무엇인지 알아보자.
-
Mutual Exclusion
스레드는 필요한 자원을 독점적으로 사용하려고 한다. -
Hold-and-wait
스레드는 이미 할당된 자원을 점유한 상태에서 추가 자원을 기다린다. -
No Preemption
스레드가 점유한 자원은 강제로 뺏길 수 없다. -
Circular Wait
스레드들 간에 순환적인 자원 요청 체인이 존재한다. 즉, 각 스레드는 다음 스레드가 점유한 자원을 요청한다.
헷갈리지 말자! Deadlock은 위의 네 가지의 조건이 모두 충족됐을 경우에만 발생할 수 있다! 한 가지라도 충족되지 않는다면 Deadlock은 발생하지 않는다. 생각보다 널널한데..? 각 조건을 하나씩 구체적으로 알아보자.
✅ Hold-and-wait
스레드는 이미 할당된 자원을 점유한 상태에서 추가 자원을 기다린다.
이 부분에서 Deadlock이 발생할 수 있는 이유는, 이미 하나의 Lock을 든 상태로 다른 Lock을 요청하고 있기 때문이다.
그렇다면 단계적으로 Lock을 획득하는 것이 아니라, 필요한 Lock을 한 번에 전부(원자적으로) 획득하도록 한다면? 아래의 코드를 보자.
pthread_mutex_lock(prevention); // begin acquisition
pthread_mutex_lock(L1);
pthread_mutex_lock(L2);
...
pthread_mutex_unlock(prevention); // end위의 코드에서는 prevention Lock을 먼저 획득한 후, 그 안에서 L1과 L2 Lock을 원자적으로 한 번에 획득하고 있다.
위의 방식을 통해 Hold-and-wait을 통한 Deadlock을 방지할 수 있긴 하지만, 두 가지 문제가 있다. 첫째, 특정 루틴을 호출하기 전에 필요한 Lock이 무엇인지 전부 알아야 한다. 둘째, 모든 락을 한 번에 획득해야 하기 때문에, 여러 스레드가 동시에 실행되기 어려워져 동시성을 감소시킨다.
개인적으로 첫 번째 문제점이 바로 이해가 되지 않았는데, Lock을 필요한 시점에 동적으로 결정하는 상황을 가정해보니 쉽게 이해할 수 있었다
if (condition1) { lock(L1); // condition1에 따라 L1을 획득 } else { lock(L2); // condition1이 아니라면 L2를 획득 }위 상황에서는
condition1에 따라 어떤 Lock(L1또는L2)을 획득할지 동적으로 결정되기 때문에, 미리 모든 Lock을 획득하기 까다롭다. (L1와L2모두 획득하면 된다고 생각했다면, 분기를 더 늘려서 생각해보자! 모든 Lock을 전부 얻어놓기는 어려울 것이다.)따라서, 위의 해결 방식을 고수하기 위해서는 코드가 예상 가능한 구조여야 할 것이다.
✅ No Preemption
스레드가 점유한 자원은 강제로 뺏을 수 없다.
스레드가 점유한 자원은 강제로 뺏을 수 없기 때문에, 하나의 스레드는 L1을, 다른 스레드는 L2를 쥐고 놓지 않는 교착 상태에 빠지게 될 수 있다.
해당 문제를 해결하기 위해, trylock()이라는 방식을 사용할 수 있다. 아래의 코드를 살펴보자.
top:
pthread_mutex_lock(L1);
if (pthread_mutex_trylock(L2) != 0) {
pthread_mutex_unlock(L1);
goto top;
}-
L1 Lock을 획득한다.
-
L2 Lock을 획득하려고 시도한다. 만약 L2까지 획득할 경우 0이 아닌 값을 반환하고 if문 내부를 거치지 않는다.
-
L2를 획득하지 못할 경우, L1 Lock을 포기한 후
goto top;을 통해 L1 획득부터 다시 시도한다.
해결 방법의 핵심은, 실행에 필요한 Lock을 전부 얻지 못했다면 현재 쥐고 있는 Lock을 강제로 포기하게 하여 교착 상태를 막는 것이다!
하지만 위 방법은 Livelock이라는 문제를 유발한다. 또다른 스레드가 아래의 작업을 반복한다고 가정해보자.
top2:
pthread_mutex_lock(L2);
if (pthread_mutex_trylock(L1) != 0) {
pthread_mutex_unlock(L2);
goto top2;
}해당 스레드는 반대로 L2를 먼저 획득하고, L1을 획득하려고 하고 있다.
타이밍이 맞지 않는다면 두 스레드 모두 Lock을 획득했다가, 포기하는 작업만 반복하게 될 것이다. 이러한 문제를 Livelock이라고 하고, Deadlock과는 달리 계속 실행을 시도하긴 하지만, 아무것도 해결되지 않는 상태를 의미한다.
Livelock을 방지하기 위해, 랜덤하게 지연 시간을 넣어 스레드의 실행 시점이 엇갈리게 할 수 있다. 이 방법을 통해 두 스레드가 같은 타이밍에 계속 락을 획득하려고 시도하는 상황을 방지할 수 있다.
✅ Circular Wait
스레드들 간에 순환적인 자원 요청 체인이 존재한다. 즉, 각 스레드는 다음 스레드가 점유한 자원을 요청한다.
위의 예시 문제 상황을 다시 살펴보자.
Thread 1: Thread 2:
pthread_mutex_lock(L1); pthread_mutex_lock(L2);
pthread_mutex_lock(L2); pthread_mutex_lock(L1);왜 Deadlock이 발생했을까? Thread 1은 L1 -> L2 순서로 Lock을 획득하려고 하고, Thread 2는 L2 -> L1 순서로 Lock을 획득하려고 했다. 즉, Lock의 획득 순서가 꼬인 것이 Deadlock의 원인이 되었다!
이를 해결하기 위해, 시스템에서 자원에 대한 획일적인 순서를 정의하여, 스레드들이 항상 일정한 순서로 자원을 획득하도록 강제할 수 있다. 위 상황에서는, 항상 모든 스레드가 L1을 먼저 획득하고, 그 후에 L2를 획득하도록 순서를 강제하면 순환 대기로 인한 Deadlock이 발생하지 않는다.
📌 개인적인 생각
글을 작성하며 든 생각인데, Circular Wait의 해결 방식인 자원 획득 순서 강제 방식으로
trylock()에서 발생하는 Livelock 문제도 해결할 수 있는게 아닌가? 라는 의문이 들었다.하지만 그렇게 쉽게 Livelock을 해결할 수 있다면, 랜덤 지연 시간 등의 기법은 왜 고안된 것인지, 애매한 부분이 많았다! 이 부분에 대해서는 공부해봐야 할 것 같다.
✅ Mutual Exclusion
스레드는 필요한 자원을 독점적으로 사용하려고 한다.
마지막으로 Mutual Exclusion, 즉 스레드들이 자원을 독점적으로 사용하는 Critical Section 자체를 없애는 방법을 검토해보자.
Critical Section을 없앤다는 것은, Locking 기법도 사용하지 않겠다는 뜻! 이게 어떻게 가능한 것일까? 방법은 강력한 Hardware Instruction을 사용하는 것이다.
int CompareAndSwap(int *address, int expected, int new) {
if (*address == expected) {
*address = new;
return 1; // success
}
return 0; // failure
}위는 CAS(CompareAndSwap) 명령어이다. 수도 코드로 작성되어 있지만, 하나의 명령어라는 점을 기억하자! 위 명령어는 단순히 "원자적으로 *address 값과 expected 값을 비교하여, 같은 경우에만 *address 위치에 new 값을 써준다." 라는 동작을 수행하고 있다. 해당 명령어를 사용하여 구현된 AtomicIncrement 함수는 아래와 같다.
void AtomicIncrement(int *value, int amount) {
do {
int old = *value;
} while (CompareAndSwap(value, old, old + amount) == 0);
}위의 CompareAndSwap(value, old, old + amount) == 0 부분을 해석해보면, AtomicIncrement 함수가 호출된 시점의 값이 CompareAndSwap을 호출하는 시점에도 같은 경우에만 값을 업데이트 해준다는 점을 알 수 있다. 따라서 thread-safe하게 값을 amount만큼 더할 수 있는 것이다.
이렇게 하드웨어 명령어를 사용하면,
- Lock이 필요하지 않다.
- 그에 따라, Deadlock 또한 발생하지 않는다.
- Livelock은 아직 발생할 가능성이 있다.
(AtomicIncrement연산 수행 시 두 스레드가 지속적으로 충돌하는 경우를 생각해보자!)
책에서는 CAS를 보다 더 복잡한 상황에 적용하는 경우도 소개하고 있다. 이번에는 연결 리스트의 삽입을 CAS로 구현하는 방법을 알아보자.
void insert(int value) {
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
n->next = head;
head = n;
}먼저, Race Condition이 발생할 수 있는 기존 코드이다. 우리가 평소에 하던 것처럼, 먼저 Lock을 통해 Critical Section을 만들어 문제를 해결해보자.
void insert(int value) {
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
pthread_mutex_lock(listlock); // begin critical section
n->next = head;
head = n;
pthread_mutex_unlock(listlock); // end critical section
}이번에는 새로 알게된 개념인 CAS를 통해서도 같은 효과를 얻어보자!
void insert(int value) {
node_t *n = malloc(sizeof(node_t));
assert(n != NULL);
n->value = value;
do {
n->next = head;
} while (CompareAndSwap(&head, n->next, n) == 0);
}위의 코드에서는 먼저 n->next = head; 부분에서 새로운 노드인 n과 head를 연결해 본 후, &head의 값과 n->next 값이 여전히 같은 경우(다른 스레드가 중간에 새로운 노드를 삽입하지 않은 경우)에만 리스트 삽입을 수행한다.
"Lock을 쓰지 않고 하드웨어 명령어만으로 thread-safe한 동작을 구현할 수 있다면, 지금까지 공부한 것들은 뭐였을까?"
당시 책과 강의에서 모두 Locking 방식과 CAS 방식을 명확히 비교해주지 않았기 때문에, 위와 같은 의문이 들었었다. 하지만 일반적으로 Locking 방식이 CAS 방식보다 더 많이 사용되고, 주된 이유는 아래와 같이 요약할 수 있을 것 같다.
-
Locking 방식은 이해하기 쉽고 구현이 간단하다.
-
Locking 방식은 복잡한 동시성 문제 해결에 적합하다. (락 계층, 타임아웃 등)
-
CAS는 단일 연산으로 효율적이지만, 특정 상황(ABA 문제 등)에서 문제가 발생할 수 있다. (관련 내용은 따로 알아보는 것을 추천한다!)
출처: https://f-lab.kr/insight/java-synchronization-and-cas
따라서, CAS는 성능이 중요한 경우, 특히 멀티스레딩 환경에서 락을 사용하지 않고 성능을 최적화하려는 경우에 사용된다고 한다.
4. Deadlock Avoidance via Scheduling
조금 관점을 바꾸어보자. 위에서는 Race Condition을 막는 과정(Mutual Exclusion, Hold-and-wait, No Preemption, Circular Wait)에서 Deadlock 발생 조건이 충족되는 상황을 방지하는 방법을 알아봤다.
그렇다면 애초에 Race Condition이 발생하지 않는 환경을 만들어준다면 어떨까? 애초에 Race Condition은 이해 관계가 얽혀있는 스레드들이 서로의 상황을 고려하지 않고 실행되며 발생하는 문제이다.
따라서 이해 관계가 없는 스레드는 병렬적으로 실행하고, 이해 관계가 얽힌 스레드는 병렬적으로 실행될 수 없도록 스케줄링하면 Race Condition이 발생하는 환경 자체가 갖춰지지 않는다!
아래의 예시를 보자.
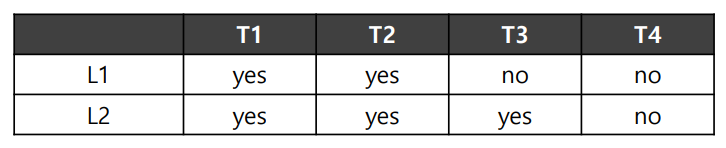
위의 표는 각 스레드가 요구하는 Lock(L1, L2)를 보여준다. L1과 L2를 모두 필요로 하는 스레드는 T1과 T2 뿐이므로, T1과 T2가 병렬 실행되지만 않으면 Deadlock은 절대 발생하지 않는다!
따라서 똑똑한 스케줄러라면 아래와 같이 스케줄링을 진행할 것이다.

아래는 또다른 예시이다.
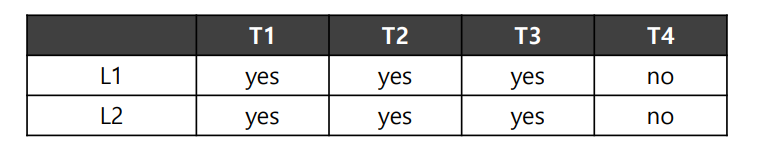
이번에는 L1와 L2를 모두 요구하는 스레드에 T3도 추가되었다. 이러면 스케줄링 또한 아래와 같이 바뀌게 될 것이다.

물론, 이 경우 CPU 1과 CPU 2에 작업이 균등하게 분배되지 않았으므로, 병목 현상이 발생하게 된다. 이를 해결하기 위한 방법으로 Banker's Algorithm이라는 알고리즘이 있는데, 해당 글에서 다루지는 않겠다!
5. Detect and Recover
마지막 방법은, 그냥 Deadlock이 발생하게 두고, 발생한다면 복구해주는 Detect and Recover 방식이다!
물론, 이 경우는 Deadlock이 굉장히 희박하게 발생하는 경우 채택할 수 있는 방식이다. 단순한 예시로, 운영체제가 멈춘다면 시스템을 재부팅하는 방식이다.
많은 데이터베이스는 Detect and Recover 방식을 사용하고 있다. (트랜잭션이 자원을 어떻게 요청할지 예측하기 어렵고, 잘 설계된 트랜잭션과 쿼리 구조에서는 데드락이 거의 발생하지 않기 때문!) Deadlock 감지기가 주기적으로 실행되고, 자원의 순환 관계를 그래프를 통해 확인하며, Deadlock이 감지되는 경우 시스템을 재시작한다.
마치며
운영체제 시리즈가 마무리되었다! 서론에서 말한 바와 같이 운영체제와 관련된 여러 주제가 남아있지만, 해당 주제에 대해 우선은 글을 쓸 계획이 없다.
학부 시절 가장 재미있게 공부했던 과목 중 하나가 운영체제였기 때문에 스스로의 언어로 내용들을 정리해보고 싶었다. 아마 지금부터는 CS보다는 백엔드 개발과 관련된 포스팅이 주를 이룰 예정!
