이번 글에서는 스케줄링과 관련된, 보다 심화적인 내용을 정리하며, CPU Virtualization 파트를 마무리하도록 하겠다.
1. Proportional Share Scheduler
Proportional Share Scheduler는 Fair-share Scheduler라고도 불리는데, 각 작업이 할당된 비율에 따라 CPU 시간을 확보하도록 보장하는 방법이다.
Proportional Share Scheduler는 공정하게 CPU 시간을 배분하지만, Response Time이나 Turnaround Time을 최적화하지는 않는다. 즉, 이전에 소개한 스케줄링 기법들과 달리, 공정함에 초점을 둔 알고리즘이라고 이해할 수 있겠다.
관련 알고리즘을 살펴보기 전, 티켓(Tickets) 개념을 먼저 짚고 넘어가자. 티켓은 프로세스가 받아야 하는 자원의 비율을 나타내는 방식으로, 각 프로세스는 자원 할당에서 자신이 차지할 비율을 정의하기 위해 티켓을 사용한다.
예를 들어, 총 100개의 티켓 중 프로세스 A가 75개의 티켓을, 프로세스 B가 25개의 티켓을 가지고 있는 경우, A는 시스템 자원의 75%를, B는 시스템 자원의 25%를 할당받게 된다.
Ticket Mechanisms
-
Ticket Currency (티켓 통화)
사용자(프로세스)는 자신이 소유한 티켓을 자신의 작업들 간에 자유롭게 분배할 수 있다. 사용자는 자체적인 "통화"를 사용하여 티켓을 관리하고, 시스템은 이를 글로벌 기준으로 변환하여 자원을 할당한다.
(만약 A가 100개의 Global Currency 티켓을 소유하고 있고, 각각의 작업 A1과 A2에 티켓을 500씩 배분한다면, 결과적으로 Global 티켓을 50장씩 배분한 것이 된다.) -
Ticket Transfer (티켓 이전)
프로세스는 자신이 소유한 티켓을 다른 프로세스에 임시로 양도할 수 있다. 이를 통해 자원 요구가 더 큰 프로세스가 일시적으로 더 많은 CPU 시간을 받을 수 있도록 지원한다. -
Ticket Inflation (티켓 팽창)
프로세스가 자원 요구에 따라 일시적으로 더 많은 또는 적은 자원을 할당받기 위해, 시스템에 요청하여 티켓 수를 조정할 수 있다.
✅ Lottery Scheduling
Lottery scheduling은 말 그대로 복권 추첨 방식으로 CPU 시간을 할당하는 스케줄링 알고리즘이다.
각 프로세스는 자원을 받을 확률에 따라 티켓을 할당받는다. 티켓의 수는 프로세스가 자원을 받을 비율을 결정한다. 실제 예시를 살펴보자.

위의 예시는 프로세스 A는 75개의 티켓(티켓 번호: 0 ~ 74)을 가지고 있고, 프로세스 B는 25개의 티켓(티켓 번호: 75 ~ 99)을 가지고 있는 경우이다. 당연히 두 프로세스가 오래 경쟁하는 만큼, 배분의 결과도 초기 할당 티켓 비율과 비슷해질 것이다.
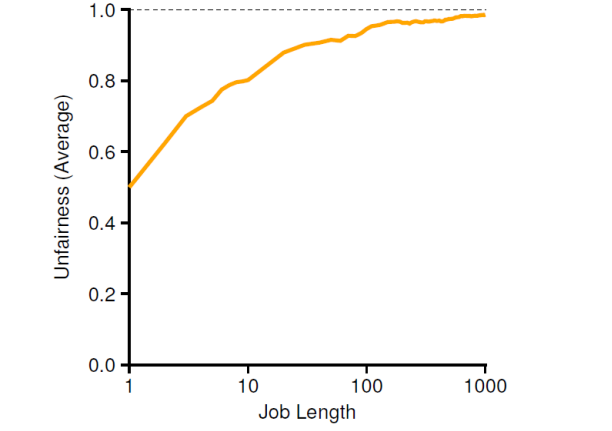
위의 그래프는 두 개의 프로세스가 같은 개수의 티켓을 소유할 경우 공정성의 변화를 보여주고 있다. 작업 실행 시간이 길어질수록 최선(1)에 가까워지는 것을 볼 수 있고, 반대로 작업 실행 시간이 충분히 길지 않다면 상당히 불공정한 결과로 이어질 수 있다는 점도 확인할 수 있다.
✅ Stride Scheduling
위의 그래프에서 살펴본 바와 같이, Lottery scheduling은 정확한 점유율을 보장해주지 못한다. 이를 보완하기 위해 고안된 것이 Stride Scheduling 알고리즘이다.
Stride Scheduling 알고리즘은 각 프로세스에 대해 "Stride"라는 값을 계산하고, 이 값을 기반으로 자원을 할당한다.
Stride는 각 프로세스의 티켓 수에 따라 결정되는 값으로, 주어진 큰 수를 프로세스의 티켓 수로 나눈 값이다. 무슨 말인지 모르겠다! 실제 예시를 살펴보자.
-
큰 수를 10,000이라고 가정한다.
-
프로세스 A는 100개의 티켓을 가지고 있다. 따라서, 프로세스 A의 Stride는 이다.
-
프로세스 B는 50개의 티켓을 가지고 있다. 따라서, 프로세스 B의 Stride는 이다.
-
프로세스 C는 250개의 티켓을 가지고 있다. 따라서, 프로세스 B의 Stride는 이다.
각 프로세스는 실행될 때마다 자신의 Stride는 값만큼 패스 값을 증가시키고, 스케줄러는 현재 패스 값이 가장 낮은 프로세스를 선택하여 실행한다. 이제 좀 감이 오는가? 아래의 실행 결과를 보자!
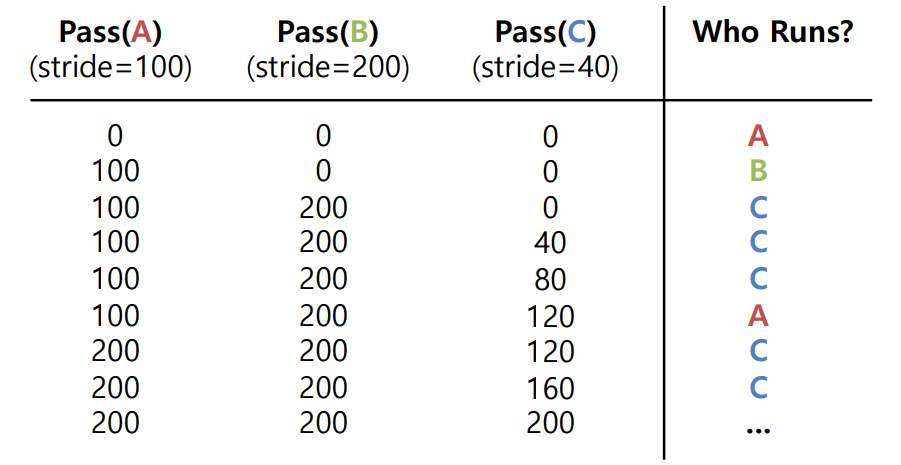
초기에는 모든 프로세스의 패스 값이 0이니 우선 A가 먼저 실행되었다고 해보자. 이후에 B가 실행되고, 이어서 C가 실행되면, 각 프로세스의 패스 값은 차례대로 100, 200, 40이 된다. 이 때 C의 패스 값이 가장 낮으므로, 한 번 더 실행되고, 또다시 한 번 더 실행된다. 이처럼 Stride Scheduling은 티켓이 많은 프로세스가 더 많이 실행될 수 있도록 보장한다. (Deterministic)
📌 Lottery Scheduling과 비교
그렇다면 Stride Scheduling은 무조건 Lottery Scheduling 보다 좋은 것인가?
그렇지는 않다. Stride Scheduling은 스케줄링을 위해 상태 값 저장이 필수적이기에 불리한 지점이 있다. 또한, 위의 예시에서 새로운 프로세스 D가 추가된 경우에는 어떻게 해야할까? D의 패스 값은 0으로 시작하므로 당분간 계속 D만 실행될 것이다. 이러한 문제를 방지하기 위해 새로운 프로세스의 패스 값을 적당한 값으로 초기화해주는 등의 로직이 필요한 수도 있다!
Stride Scheduling의 패스 값 처리 작업은 실제로 CPU 사용량의 5% 정도를 소모한다고 한다. 따라서 현재 Linux 시스템에서는 가상 런타임(Virtual Runtime) 개념을 사용한 Completely Fair Scheduler(CFS)라는 방법을 사용하고 있다.
2. Multiprocessor Scheduling
다음으로 Multiprocessor Scheduling과 관련된 내용을 살펴보자. Multiprocessor Scheduling는 멀티코어 프로세서 환경에서 작업을 효율적으로 분배하기 위해 설계된 스케줄링 기법이다.
멀티코어 프로세서는 하나의 칩에 여러 개의 CPU 코어가 장착된 구조를 가지고 있어, 동시에 여러 작업을 처리할 수 있다. 하지만 단순히 CPU를 추가하는 것만으로 단일 애플리케이션의 실행 속도가 높아지는 것은 아니다. 멀티코어 프로세서의 성능을 극대화하려면 애플리케이션을 병렬로 실행할 수 있어야 한다.
1) Cache Coherence (캐시 일관성)
먼저 멀티코어 프로세서 시스템에서 발생할 수 있는 문제인 캐시 일관성 문제에 대해 살펴보자.
캐시 일관성 문제는 각 코어가 독립적으로 데이터를 캐시에 저장할 때 발생하는 문제이다. 문제가 발생하는 과정을 먼저 살펴보자.
Cache Coherence 문제
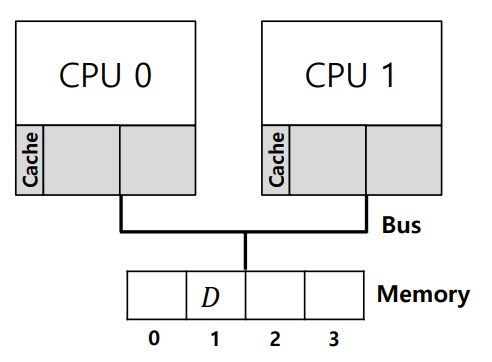
- CPU0과 CPU1는 각각 자신의 캐시를 가지고 있으며, 동일한 메모리 공간을 공유하고 있다.
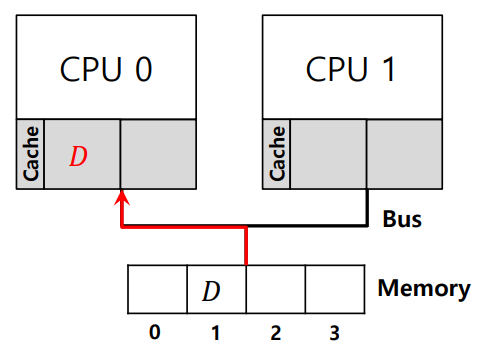
- CPU0이 메모리 주소 1에 저장된 데이터를 읽는다. 이 데이터는 CPU0의 캐시에 저장된다.
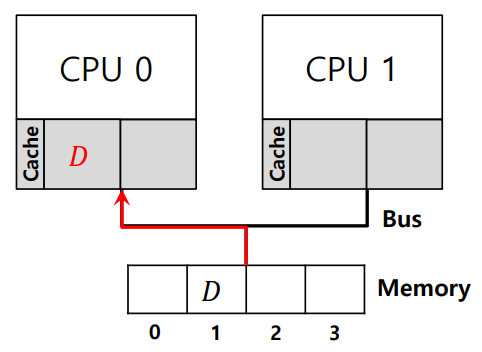
- CPU0이 메모리 주소 1의 데이터를 업데이트한다. 이 데이터 변경 사항이 메모리에 반영되기 전, CPU1이 스케줄되어 실행된다.
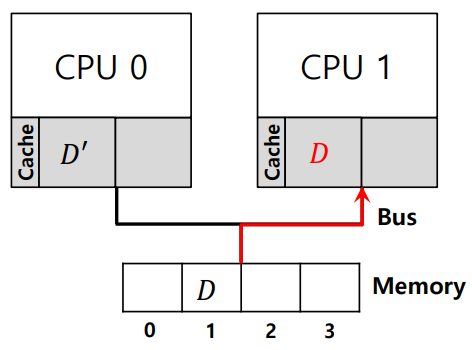
- CPU1이 메모리 주소 1의 값을 읽는다. 그러나, CPU1은 CPU0로 인해 업데이트된 값을 읽지 못하고, 이전에 저장된 (구 버전의) 값을 읽게 된다.
위와 같은 과정으로 인해 캐시 일관성 문제가 발생하게 된다.
Cache Coherence 해결
이러한 캐시 일관성 문제를 해결하기 위해 Bus Snooping과 같은 기술을 사용할 수 있다. Bus Snooping은 아래와 같이 동작한다.
Bus Observing: 각 CPU의 캐시가 시스템 버스를 모니터링하여 메모리 업데이트를 감지한다.
복사본 무효화 또는 업데이트: 데이터 업데이트가 감지되면, 각 캐시는 해당 데이터의 복사본을 무효화하거나 업데이트하여 캐시 일관성을 유지한다.
추가적으로, 동기화(Synchronization) 문제를 잊지 말자! 동기화 문제는 여러 스레드나 프로세스가 동시에 같은 자원에 접근할 경우 발생하는 문제이다. 자세한 부분은 이후 동시성(Concurrency) 파트에서 다루도록 하겠지만, 맛보기 정도로 간단하게 짚고 넘어가자.
typedef struct __Node_t {
int value;
struct __Node_t *next;
} Node_t;
int List_Pop() {
Node_t *tmp = head;
int value = head->value;
head = head->next;
free(tmp);
return value;
}위는 동기화를 고려하지 않은 코드로, 여러 프로세서가 동시에 List_Pop을 호출하면 head 포인터가 동시에 수정되어 데이터의 무결성이 깨질 수 있다.
pthread_mutex_t m;
typedef struct __Node_t {
int value;
struct __Node_t *next;
} Node_t;
int List_Pop() {
lock(&m);
Node_t *tmp = head;
int value = head->value;
head = head->next;
free(tmp);
unlock(&m);
return value;
}수정된 코드에서는 pthread_mutex_t를 사용하여 상호 배제가 구현되었다. lock(&m)과 unlock(&m) 호출을 통해 List_Pop 함수 내에서 공유 데이터에 대한 접근이 동기화된다. 우선 lock은 말 그대로 "다른 스레드로부터의 접근을 잠그는 행위" 정도로 이해하고 넘어가자!
2) Cache Affinity
Cache Affinity란, 멀티프로세서 시스템에서 프로세스를 가능한 한 같은 CPU에서 계속 실행하여 CPU의 캐시 메모리 상태를 재활용하는 개념이다.
Cache Affinity를 고려하면, 프로세스가 특정 CPU의 캐시에 저장된 데이터와 명령어를 활용할 수 있게 되어 캐시 미스를 줄이고 시스템 성능이 향상될 수 있다. 관련하여 아래의 개념들을 살펴보자.
✅ Single Queue Multiprocessor Scheduling (SQMS)
SQMS는 모든 작업을 하나의 공통 큐에 넣고, 각 CPU가 이 전역 큐에서 다음 작업을 선택하여 실행하는 스케줄링 방법이다.
SQMS 방식에서는 모든 스케줄링이 필요한 작업을 단일 큐에 모으고, 각 CPU는 단순히 이 큐에서 작업을 선택한다.
SQMS의 단점은 큐에 대한 접근을 조정하기 위해 잠금 메커니즘이 필요하여 시스템의 확장성이 제한될 수 있고, 프로세스가 자주 CPU를 이동하면 캐시 어피니티가 감소하고 성능 저하가 발생할 수 있다는 점이다.

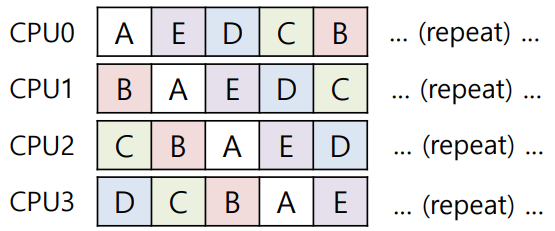
만약 위와 같은 형태로 작업이 수행될 경우 최악이라고 할 수 있다. 각 작업이 일관된 프로세스에서 실행되지 않고 있기에 Cache Affinity를 전혀 고려하지 않은 형태라고 볼 수 있다.
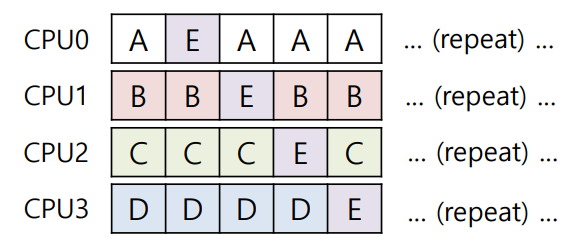
위의 경우는 최선이라고 할 수 있다. A ~ D 작업은 프로세서를 이동하지 않고 있고, 오직 E만 여러 프로세스를 이동하고 있기 때문이다. 하지만 이와 같은 작업 이동은 구현이 복잡할 수 있다.
✅ Multi-queue Multiprocessor Scheduling (MQMS)
MQMS는 SQMS와 달리 여러 개의 스케줄링 큐를 사용하는 스케줄링 방식이다.
이 방법에서는 각 큐가 특정 스케줄링 규칙을 따르며, 시스템에 작업이 들어오면 해당 작업은 정확히 하나의 큐에 배정된다.
MQMS의 주요 장점은 큐 간에 정보 공유나 동기화 문제를 피할 수 있다는 점이다. (각 작업은 정확히 하나의 큐에만 배정되기 때문)
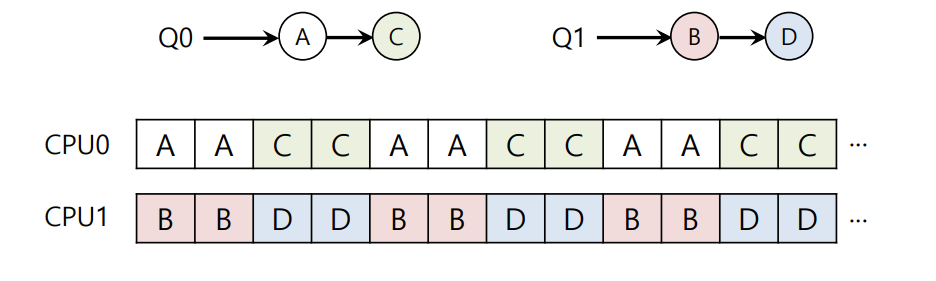
Round Robin 방식을 사용할 경우, 시스템은 위와 유사한 스케줄을 생성할 수 있다. MQMS는 보다 높은 확장성과 캐시 어피니티를 제공한다.
MQMS Load Imbalance 문제
MQMS에서는 Load Imbalance(부하 불균형) 문제가 발생할 수 있는데, 이는 각 큐에 할당되는 작업의 수나 작업의 무게가 균등하지 않은 문제이다. 아래의 예시를 보자.
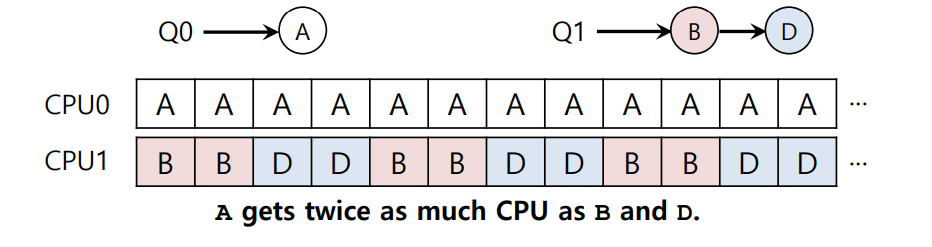
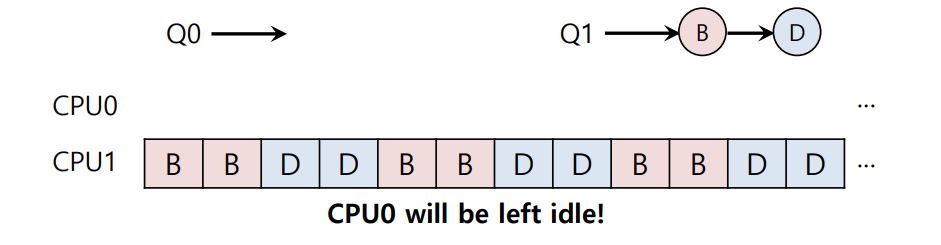
이전 예시에서 CPU0의 작업 중 C가 끝나면, CPU0는 A만 실행하게 되는데, 이 때 A는 B와 D에 비해 두 배로 많은 CPU 시간을 할당받게 된다. 또한, A마저 끝나는 경우 CPU0이 사용되지 않는 idle 상태가 되어버린다.
이러한 비효율을 피하기 위해, 작업 이동(Migration) 방법이 사용된다. 이는 단순히 큐에서 다른 큐로 작업을 이동시키는 것이다.
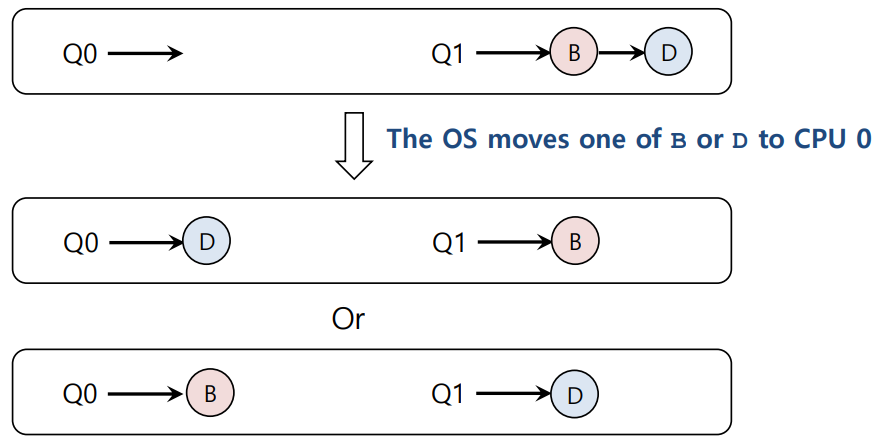
그림으로 예시 상황을 표현하면 위와 같다.
작업 이동 외에, Work Stealing 방법을 사용할 수도 있다. Work Stealing은 작업이 적은 CPU가 주기적인 모니터링을 통해 작업이 많은 다른 CPU의 작업을 "훔쳐" 오는 방법이다.
Work Stealing은 상대적으로 더 동적이고 자율적이지만, 그만큼 오버헤드와 확장성 문제를 동반할 수 있다.
3. Linux Multiprocessor Schedulers
실제 Linux Multiprocessor Schedulers는 다중 프로세서 환경에서 작업을 효율적으로 스케줄링하기 위해 다양한 알고리즘을 사용한다. 그 중 O(1) 스케줄러와 Completely Fair Scheduler (CFS)를 간단히 살펴보자.
✅ O(1) Scheduler
-
우선순위 기반 스케줄러
O(1) 스케줄러는 프로세스의 우선순위를 기반으로 작업을 스케줄링한다. -
다중 큐 사용
프로세스는 여러 개의 큐 중 하나에 배치된다. 각 큐는 서로 다른 우선순위 레벨을 갖는다. -
우선순위 변동
프로세스의 우선순위는 시간이 지남에 따라 변경될 수 있다. 이는 프로세스의 상호작용 성향(interactivity)에 따라 조정된다. -
상호작용 집중
상호작용이 중요한 프로세스(즉, 사용자의 입력에 빠르게 반응해야 하는 프로세스)는 높은 우선순위를 부여받아 빠르게 스케줄링된다.
✅ Completely Fair Scheduler (CFS)
-
Deterministic 비례 배분 접근 방식
CFS는 각 프로세스가 CPU 시간의 비율을 보장받도록 설계된 스케줄링 알고리즘이다. -
다중 큐 사용
CFS는 여러 큐를 사용할 수 있지만, 큐의 수와 구조는 O(1)과 다를 수 있으며, 프로세스가 공정하게 배분될 수 있도록 설계되었다. -
특징
CFS는 각 프로세스가 공정하게 CPU 시간을 할당받도록 하기 위해 "가상 런타임"이라는 개념을 사용한다. 이는 프로세스가 CPU에서 소비한 시간을 기준으로 공정하게 스케줄링되도록 보장한다.
마치며
이번 글을 마지막으로 OSTEP 책의 CPU Virtualization 파트가 끝났다. 다음 글부터는 Memory Virtualization을 알아보자.
