Multi-Level Feedback Queue (MLFQ)
이전 글에서 기본적인 스케줄링 알고리즘들에 대해 살펴봤다. SJF나 STCF 등의 스케줄링 알고리즘은 작업의 실행 시간을 미리 알지 못하는 경우 작업의 실행 시간을 예측하기 어렵기 때문에, 실제 운영체제에 적용되기 어렵다.
즉, 이러한 알고리즘이 이론적으로는 최적의 효율을 제공할 수 있을지 몰라도, 작업에 대한 사전 정보가 없는 현실 운영체제에서 사용되는 것은 거의 불가능하다.
Multi-Level Feedback Queue (MLFQ)는 과거의 작업 패턴을 학습하여 미래의 작업 실행을 예측하는 스케줄링 알고리즘이다. 이 스케줄러는 작업의 우선순위를 동적으로 조정하여 시스템 성능을 최적화한다.
1. MLFQ: Basic Rules
Multi-Level Feedback Queue (MLFQ) 스케줄링 알고리즘은 여러 개의 독립된 큐를 사용하며, 각 큐는 서로 다른 우선순위 레벨을 가진다. (우선순위 레벨이 높은 큐에 위치한 작업이 먼저 실행된다.) 같은 큐에 있는 작업들에게는 Round-Robin 스케줄링을 사용하여 공정하게 CPU 시간을 분배한다.
MLFQ의 목표는 작업의 우선순위를 동적으로 조정하여 시스템 성능을 최적화하는 것이다. 아래와 같이 MLFQ의 기본 규칙을 정리할 수 있다.
- MLFQ Rules
Rule 1. 만약 Priority(A) > Priority(B)라면, A가 실행되고 B는 실행되지 않는다.
Rule 2. 만약 Priority(A) = Priority(B)라면, A와 B는 같은 큐에서 Round-Robin 방식으로 실행된다.
그렇다면 MLFQ는 어떠한 기준으로 작업의 우선순위를 조정할까? MLFQ는 작업의 관찰된 실행 패턴에 따라 우선순위를 변경한다.
-
I/O를 자주 요청하는 작업
만약 작업이 반복적으로 CPU를 반환하고 I/O를 기다리는 경우, 이 작업의 우선순위를 상대적으로 높게 유지한다. 이는 사용자 응답 시간을 줄이고, I/O 요청을 신속하게 처리할 수 있도록 하기 위함이다. -
CPU를 집중적으로 사용하는 작업
반대로, CPU를 장시간 집중적으로 사용하는 작업은 우선순위가 낮아지도록 조정한다. 이는 긴 CPU 작업이 시스템 자원을 독점하는 것을 방지하고, 전체 시스템의 반응성을 높이기 위함이다.
결과적으로, MLFQ는 아래 그림과 같은 형태를 가진다.
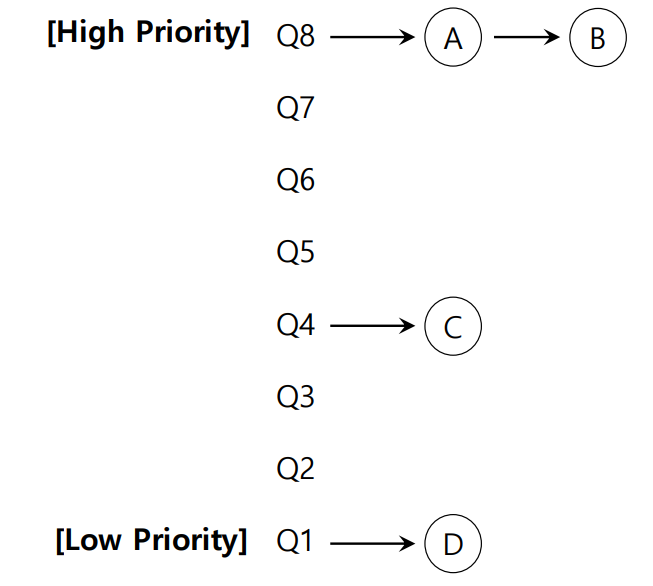
2. Change Priority
그림에서는 작업 A, B가 높은 우선순위로 설정되었고, C, D가 상대적으로 낮은 우선순위로 설정되었지만, 앞서 설명했듯이 MLFQ 알고리즘은 작업의 우선순위를 동적으로 조정한다.
- MLFQ Rules
Rule 1. 만약 Priority(A) > Priority(B)라면, A가 실행되고 B는 실행되지 않는다.
Rule 2. 만약 Priority(A) = Priority(B)라면, A와 B는 같은 큐에서 Round-Robin 방식으로 실행된다.
Rule 3. 작업이 시스템에 처음 들어오면 가장 높은 우선순위를 가진 큐에 배치된다.
Rule 4a. 작업이 지정된 Time Slice를 모두 소진하고 실행을 완료하면, 이 작업의 우선순위가 낮아진다.
Rule 4b. 작업이 Time Slice가 완료되기 전에 CPU를 반환하면, 이 작업은 현재의 우선순위 레벨에 유지된다.
Rule 3 ~ Rule 4b의 추가를 통해 우선순위 설정 정책을 보다 정규하게 수행할 수 있다. 그림을 통해 실제 예시를 살펴보자.
Example 1: A Single Long-Running Job
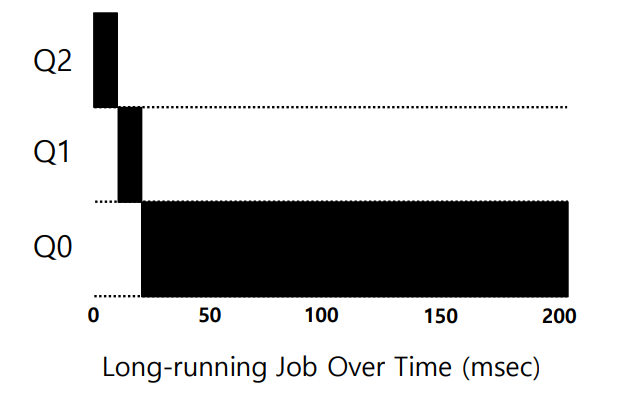
하나의 작업이 긴 시간동안 CPU를 사용할 때, 우선순위의 변동을 살펴보자.
-
작업이 시스템에 처음 도착했을 때, 가장 높은 우선순위를 가진 큐인 Q2에 배치되었다. (Rule 3)
-
해당 작업에 의 Time Slice가 주어졌고, 지정된 Time Slice를 모두 소진한 후 Q1로 우선순위가 강등되었다. (Rule 4a)
-
같은 과정에 따라 Q0으로 우선순위가 강등된 이후로는 더 떨어질 우선순위가 없고, 실행되고 있는 다른 작업도 없기 때문에 Q0에서 계속 실행된다.
Example 2: Along Came a Short Job
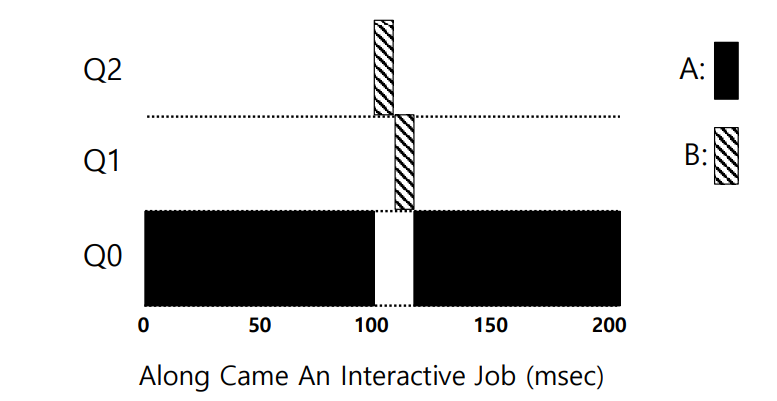
다음으로, 긴 시간동안 CPU를 사용하는 작업 A와, 짧은 실행 시간()만 필요한 작업 B가 있는 경우를 생각해보자.
-
작업 A는 이미 일정 시간 동안 CPU를 사용하고 있으며, 현재의 우선순위 레벨은 Q0이다.
-
시점에 작업 B가 도착했다. 작업 B는 가장 높은 우선순위를 가진 큐인 Q2에 배치된다. (Rule 3)
-
작업 B는 Q2에서 , 이후 Q2로 강등된 후 만큼 CPU를 사용한 후 실행이 종료된다. (Rule 4a)
여기서 알 수 있는 사실은, 실행 시간이 짧은 작업의 경우 우선순위가 높게 유지되는 단계에서 실행이 완료되므로, MLFQ가 SJF에 근사한 성능을 가질 수 있다는 점이다.
Example 3: What About I/O?
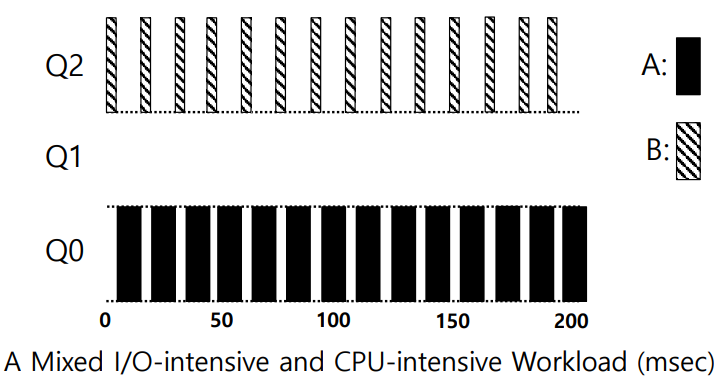
다음으로, I/O가 발생하는 경우의 예시를 살펴보자.
-
B는 매우 짧은 시간()동안 CPU를 사용한 후, I/O 작업을 수행하는 작업이다.
-
작업 B는 할당된 Time Slice인 를 전부 사용하기도 전에 I/O 요청을 수행하며 Blocked 상태로 전환되었다. 따라서 B의 우선순위는 강등되지 않는다. (Rule 4b)
Rule 4b을 통해 I/O 요청이 잦고, CPU의 사용이 적은 작업을 먼저 실행하여, 짧은 상호작용 작업을 신속하게 처리할 수 있다.
3. Problems & Solutions
위에서 MLFQ의 기본적인 동작을 알아봤다. 상당히 Reasonable한 알고리즘으로 보이지만, 역시나 문제는 존재한다. MLFQ에서 발생할 수 있는 문제점들과, 그에 대한 해결 방법을 알아보자.
Problems
-
기아 (Starvation)
시스템에 "너무 많은" 상호작용 작업이 있을 경우, 긴 실행 시간을 요구하는 작업은 CPU 시간을 전혀 받을 수 없는 상황이 발생할 수 있다. 상호작용 작업들이 높은 우선순위를 차지하게 되면, 장시간 실행되는 작업은 계속해서 낮은 우선순위 큐에 머물러 있으며, CPU를 할당받지 못해 기아 상태에 빠질 수 있다. 결과적으로 시스템의 공정성에 문제가 생긴다. -
스케줄러 조작 (Game the scheduler)
작업이 시간 슬라이스의 99%를 소진한 후 I/O 작업을 발행한다고 해보자. 해당 작업은 Rule 4b로 인해 우선순위를 유지하게 된다! 결과적으로, 해당 작업은 스케줄러를 조작하여 더 많은 CPU 시간을 할당받게 된다. 이 또한 시스템의 공정성에 문제를 주는 경우이다. -
프로그램의 행동 변화 (Behavior change)
프로그램이 시간이 지남에 따라 CPU 집약적 작업에서 I/O 중심 작업으로 변할 수 있다. 예를 들어, 처음에는 CPU를 많이 사용하는 작업일 수 있지만, 시간이 지나면서 I/O 작업을 더 많이 수행하게 될 수 있다. MLFQ는 작업의 초기 행동에 따라 우선순위를 조정하므로, 프로그램의 행동 변화에 적절히 대응하지 못할 수 있다. (현재는 우선순위의 강등만 존재할 뿐, 상승은 없다는 점에 주목하자!) 이러한 문제는 시스템의 효율성을 떨어뜨린다.
✅ Priority Boost
Priority Boost는 MLFQ에서 발생할 수 있는 기아 문제를 해결하기 위한 방법 중 하나로, 일정 시간 간격에 따라 시스템 내의 모든 작업을 가장 높은 우선순위 큐로 이동시키는 방식이다.
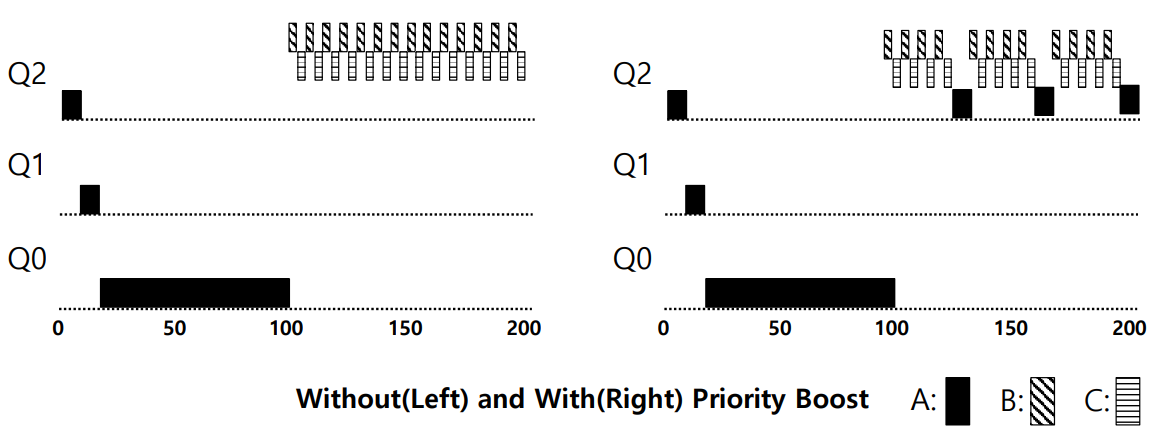
그림에서 볼 수 있듯이, 긴 시간동안 CPU를 사용하는 작업 A가 Q0로 강등되더라도, 일정 주기에 따라 가장 높은 우선순위 큐인 Q2에 배치된다. 결과적으로 A는 최소한의 실행 시간을 보장받을 수 있게 되고, 기아 문제를 해결할 수 있다.
이에 따라, MLFQ Rule에 새로운 규칙 Rule 5를 추가해야 한다.
- MLFQ Rules
Rule 1. 만약 Priority(A) > Priority(B)라면, A가 실행되고 B는 실행되지 않는다.
Rule 2. 만약 Priority(A) = Priority(B)라면, A와 B는 같은 큐에서 Round-Robin 방식으로 실행된다.
Rule 3. 작업이 시스템에 처음 들어오면 가장 높은 우선순위를 가진 큐에 배치된다.
Rule 4a. 작업이 지정된 Time Slice를 모두 소진하고 실행을 완료하면, 이 작업의 우선순위가 낮아진다.
Rule 4b. 작업이 Time Slice가 완료되기 전에 CPU를 반환하면, 이 작업은 현재의 우선순위 레벨에 유지된다.
Rule 5. 일정 시간 간격 가 지나면, 시스템 내의 모든 작업을 가장 높은 우선순위 큐로 이동시킨다.
✅ Better Accounting
Rule 4를 다음과 같이 개선하여 스케줄러의 공정성을 높이고 스케줄러 조작을 방지할 수 있다.
- MLFQ Rules
Rule 1. 만약 Priority(A) > Priority(B)라면, A가 실행되고 B는 실행되지 않는다.
Rule 2. 만약 Priority(A) = Priority(B)라면, A와 B는 같은 큐에서 Round-Robin 방식으로 실행된다.
Rule 3. 작업이 시스템에 처음 들어오면 가장 높은 우선순위를 가진 큐에 배치된다.
Rule 4. 작업이 특정 우선순위 레벨에서 주어진 시간 할당량을 모두 소모한 경우, 해당 작업의 우선순위가 자동으로 낮아진다.
Rule 5. 일정 시간 간격 가 지나면, 시스템 내의 모든 작업을 가장 높은 우선순위 큐로 이동시킨다.
헷갈리지 말자! 이전 규칙은 일회성의 Time Slice를 전부 사용했는지를 기준으로 우선순위 강등 여부를 판단했다면, 개선된 Rule 4는 CPU를 사용한 총 시간을 기준으로 우선순위를 조정한다.
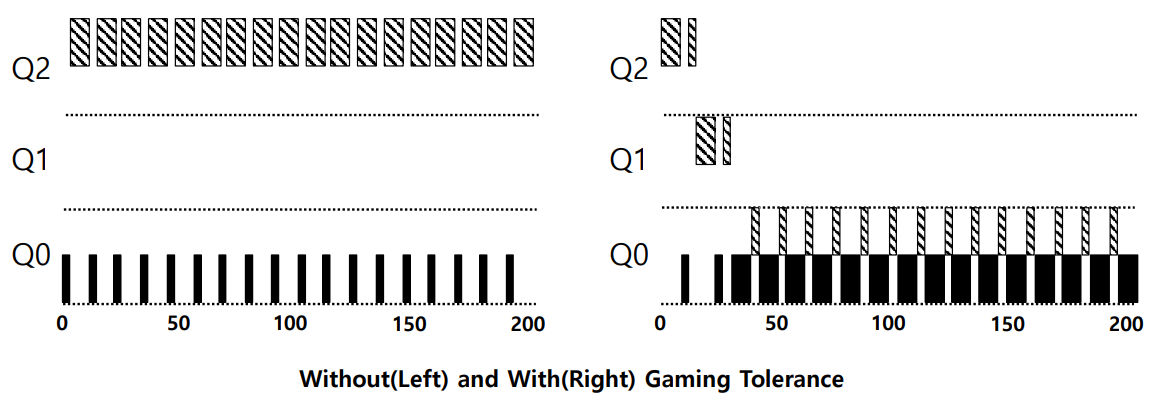
그림에서 볼 수 있듯이, 개선된 Rule 4 방식으로 동작할 경우 Time Slice를 기준으로 강등을 수행하지 않고, CPU를 사용한 총 시간을 기준으로 강등을 수행한다. 따라서 작업 B가 스케줄러를 조작할 수 없고, A와 같은 Q0까지 우선순위가 강등된 후, 두 작업이 Round Robin 방식으로 실행된다.
✅ Other Issues
Priority Boost와 Better Accounting 방식을 통해 위에서 언급한 세 가지 문제들은 해결될 수 있지만, 추가적인 작업이 필요할 수 있다.
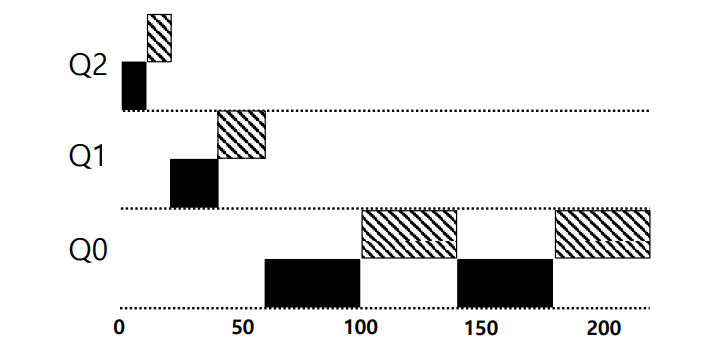
위의 그림은 우선순위 큐에 따른 Time Slice 조정을 보여주고 있다. 위의 예시에서는, 높은 우선순위 큐는 자주 실행되는 만큼 짧은 Time Slice를 할당하고, 낮은 우선순위 큐는 자주 실행될 수 없는 만큼 한 번 실행할 때 충분한 Time Slice를 할당하는 방식으로 조정되었다. 이처럼 보다 고수준의 제어가 필요할 수 있다.
마치며
최종적인 MLFQ Rule을 정리하면 아래와 같다.
- MLFQ Rules
Rule 1. 만약 Priority(A) > Priority(B)라면, A가 실행되고 B는 실행되지 않는다.
Rule 2. 만약 Priority(A) = Priority(B)라면, A와 B는 같은 큐에서 Round-Robin 방식으로 실행된다.
Rule 3. 작업이 시스템에 처음 들어오면 가장 높은 우선순위를 가진 큐에 배치된다.
Rule 4. 작업이 특정 우선순위 레벨에서 주어진 시간 할당량을 모두 소모한 경우, 해당 작업의 우선순위가 자동으로 낮아진다.
Rule 5. 일정 시간 간격 가 지나면, 시스템 내의 모든 작업을 가장 높은 우선순위 큐로 이동시킨다.
저번 글에 이어서 이번 글까지 스케줄링 알고리즘과 정책에 대해서 알아보았다. 다음 글에서 스케줄링에 대한 부가적인 내용들을 마저 살펴본 후, 다음 파트인 Memory Virtualization 파트로 넘어가자.
