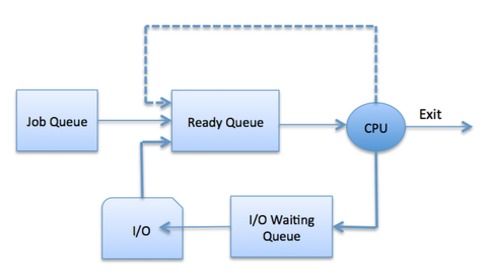
스케줄링 (Scheduling)
이전 글에서 Context Switching에 대해 알아보며, 인터럽트를 통해 운영체제가 현재 프로세스를 계속 실행할지, 다른 프로세스를 실행할지 결정한다고 설명했다. 그렇다면 운영체제는 어떤 Policy를 통해 이를 결정하는 것일까?
운영체제는 스케줄링 알고리즘을 사용하여 어떤 프로세스가 언제 CPU를 사용할지 결정한다. 여기서 스케줄링이란 운영체제가 여러 프로세스나 스레드에 CPU 시간을 효율적으로 분배하여 실행 순서를 결정하는 과정이라고 할 수 있다. 이번 글에서는 여러 스케줄링 알고리즘을 정리하고, 각각의 장단점을 알아보도록 하겠다.
용어 정리
OSTEP 책에서는 스케줄링 알고리즘의 원활한 분석과 이해를 위해, 먼저 용어의 의미를 아래와 같이 정리하고 있다.
✅ Workload
Workload는 작업(=프로세스)의 도착 시간(arrival time)과 실행 시간(run time)을 포함하는 작업 설명이다.
- Workload 가정
1. 각 작업은 동일한 시간 동안 실행된다.
2. 모든 작업은 동시에 도착한다.
3. 모든 작업은 CPU만 사용하고, I/O 작업은 수행하지 않는다.
4. 각 작업의 실행 시간은 미리 알려져 있다.
Workload 가정의 경우 현재는 이해를 돕기 위해 비현실적인 가정을 하고 있지만, 내용이 진행됨에 따라 가정을 조금씩 고쳐나가는 방식으로 설명이 완성되는 것을 볼 수 있을 것이다.
✅ Scheduler
스케줄러는 준비된 작업(ready job) 중 어떤 작업을 실행할지 결정하는 로직이다.
✅ Metric
Metric 스케줄링 품질을 평가하기 위한 측정 기준이다.
-
Turnaround Time (반환 시간)
Turnaround Time은 작업이 시스템에 들어온 시점부터 작업이 완료될 때까지 걸린 총 시간을 의미한다. Turnaround Time는 스케줄러의 성능을 평가하기 위해 사용되는 Metric이다.
-
Fairness (공정성)
공정성은 스케줄링에서 또 다른 중요한 지표이다. 성능과 공정성은 상충하는 경우가 많다. 예를 들어, 성능을 극대화하기 위해서는 특정 작업을 우선적으로 처리하는 방식이 필요할 수 있다. 따라서 스케줄링에서는 성능과 공정성 간의 균형을 맞추는 것이 중요하다.
Metric의 경우, 우선 Turnaround Time을 기준으로 스케줄링의 성능을 평가해 보도록 하자.
1. First In, First Out (FIFO)
지금부터 스케줄링 알고리즘을 하나씩 알아보며, 장단점을 분석해보도록 하겠다. 먼저 First In, First Out (FIFO) 알고리즘부터 살펴보자.
- Workload 가정
1. 각 작업은 동일한 시간 동안 실행된다.
2. 모든 작업은 동시에 도착한다.
3. 모든 작업은 CPU만 사용하고, I/O 작업은 수행하지 않는다.
4. 각 작업의 실행 시간은 미리 알려져 있다.- Metrics
Turnaround Time
FIFO는 가장 단순하고 구현하기 쉬운 스케줄링 알고리즘으로, 작업을 도착한 순서대로 처리하며, 먼저 도착한 작업이 먼저 실행되는 방식이다.

우리는 현재 "각 작업은 동일한 시간 동안 실행된다." 라는 가정을 기반으로 FIFO의 성능을 측정하였다. 만약, 해당 가정을 지우면 어떻게 될까?
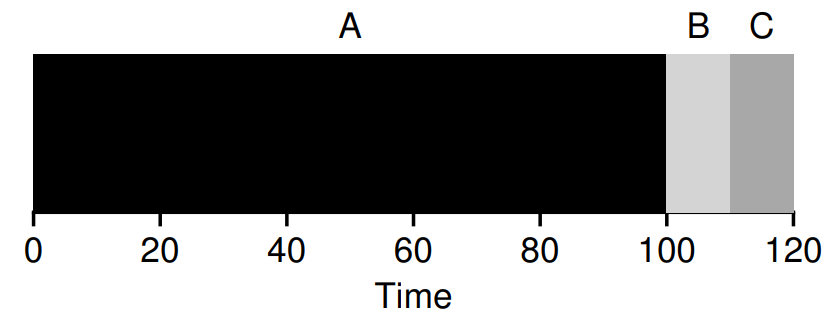
위의 경우, A는 실행 시간이 100초이고, B와 C는 실행 시간이 10초이다. A가 먼저 실행될 경우, B와 C는 A의 실행 완료를 기다려야 하기 때문에 성능이 아래와 같이 매우 악화된다.
이러한 현상을 Convoy Effect라고 부르고, FIFO 알고리즘 성능의 문제점이다.
2. Shortest Job First (SJF)
- Workload 가정
1. 각 작업은 동일한 시간 동안 실행된다.
2. 모든 작업은 동시에 도착한다.
3. 모든 작업은 CPU만 사용하고, I/O 작업은 수행하지 않는다.
4. 각 작업의 실행 시간은 미리 알려져 있다.- Metrics
Turnaround Time
Shortest Job First (SJF) 알고리즘은 가장 짧은 작업을 먼저 실행한 후, 그 다음으로 짧은 작업을 실행하는 방식이다.
한 번 시작된 작업은 중간에 중단되지 않고 끝까지 실행된다.
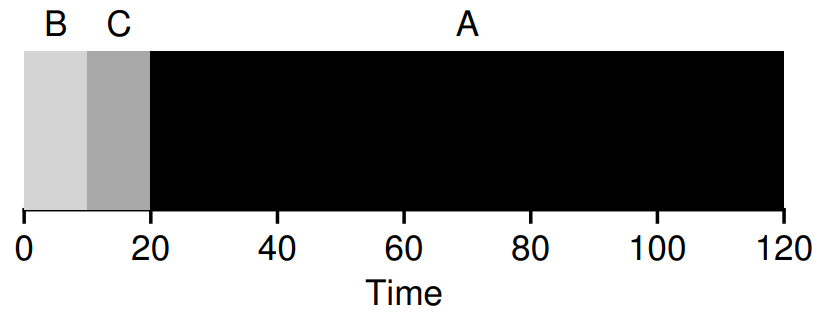
FIFO의 단점을 설명한 예시를 SJF 관점에서 다시 살펴보자.
A, B, C가 거의 동시에 도착한 경우, SJF 알고리즘에서는 B와 C가 더 짧기 때문에 이들이 먼저 실행된다. 따라서 같은 경우이지만, 성능이 크게 나아진 것을 확인할 수 있다.
여기서 다시 가정을 살펴보자. 우리는 현재 "모든 작업은 동시에 도착한다." 라는 가정을 하고 있지만, 만약 해당 가정을 지운 뒤, 예시 경우에서 A가 먼저 도착한다면? 한 번 시작된 작업은 중간에 중단되지 않고 끝까지 실행되므로, Convoy Effect 현상이 다시 발생한다.
이처럼 FIFO와 SJF에서는 한 번 작업이 CPU를 차지하면, 그 작업이 자발적으로 CPU를 반환할 때까지 다른 작업이 CPU를 사용할 수 없고, 이를 비선점형 스케줄링 알고리즘이라고 한다.
3. Shortest Time-to-Completion First (STCF)
- Workload 가정
1. 각 작업은 동일한 시간 동안 실행된다.
2. 모든 작업은 동시에 도착한다.
3. 모든 작업은 CPU만 사용하고, I/O 작업은 수행하지 않는다.
4. 각 작업의 실행 시간은 미리 알려져 있다.- Metrics
Turnaround Time
STCF (Shortest Time-to-Completion First) 알고리즘은 선점형 스케줄링의 예시로, 해당 알고리즘에서는 언제든지 현재 실행 중인 작업을 중단시키고, 남은 시간이 가장 적게 남은 작업을 대신 실행한다.
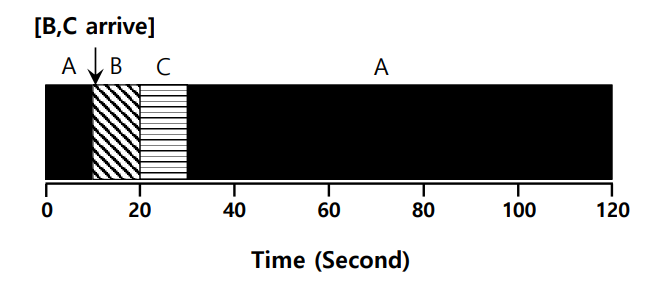
위는 실행 시간이 100초인 A가 0초에 도착하고, 실행 시간이 10초인 B, C가 10초에 도착한 경우이다. 각 작업이 도착한 시점과, 완료된 시점을 기준으로 계산했을 때, 긴 작업이 먼저 도착하더라도 안정적인 성능이 유지된다는 것을 확인할 수 있다.
✅ New Metric
- Response Time (응답 시간)
앞선 설명에서 Metric을 성능과 공정성 두 가지로 나누었다. 지금까지 Turnaround Time으로 스케줄링의 성능을 평가했다면, 지금부터는 Response Time을 기준으로 스케줄링의 공정성에 대해 얘기해보도록 하자.Response Time은 작업이 도착한 시점부터 처음으로 스케줄링되는 시점까지의 시간이다.
STCF 포함하여, 위에서 설명한 스케줄링 방식들은 일반적으로 Response Time에 대해서 효과적이지 않다. 아래의 예시를 살펴보자.
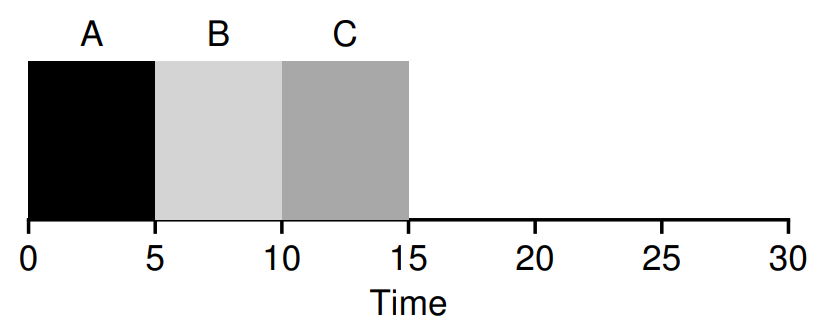
단순히 작업 A, B, C를 SJF 방식으로 수행하는 경우, Response Time은 아래와 같이 계산된다.
컴퓨터로 특정 작업을 수행할 때, 5초 동안 아무런 응답이 없다고 생각해보자. 5초라는 시간은 너무나도 길다! 최소한 로딩 중인지, 현재 실행된 것이 맞는지는 확인할 수 있어야 하지 않을까?
지금부터 Response Time을 줄일 수 있는 방법들에 대해 알아보자.
4. Round Robin (RR) Scheduling
- Workload 가정
1. 각 작업은 동일한 시간 동안 실행된다.
2. 모든 작업은 동시에 도착한다.
3. 모든 작업은 CPU만 사용하고, I/O 작업은 수행하지 않는다.
4. 각 작업의 실행 시간은 미리 알려져 있다.- Metrics
Response Time
Round Robin (RR) 알고리즘은 Time Slicing 기법을 사용하는 스케줄링 방식이다.
RR은 각 작업에 동일한 시간, 즉 Time Slice를 할당하고, 그 시간 동안 작업을 실행한 후 대기 중인 다음 작업으로 전환하는 방식으로 동작한다. 물론, Time Slice는 Timer Interrupt 주기의 배수여야 한다.

같은 경우에 SJF와 RR의 Response Time을 비교해보자. 현재 Time Slice의 길이는 1이므로, RR의 Response Time은 아래와 같이 계산된다.
앞서 SJF 방식의 Response Time이 5초로 계산된 것과 비교하면 훨씬 개선되었다는 점을 확인할 수 있다. 그렇다면 Time Slice의 길이를 줄이면 줄일수록 Response Time이 짧아지니 더 좋지 않을까?
역시나 세상에 공짜는 없다. Time Slice의 길이를 과도하게 짧게 설정하면 Context Switching의 횟수가 급격히 증가하게 되고, Context Switching 또한 CPU 자원을 소모하는 작업이기에 전체적인 시스템 성능에 악영향을 주게 된다.
앞선 Metric의 설명에서 성능과 공정함 사이의 균형을 맞춰야 한다고 언급했는데, 이것이 바로 성능과 공정함 사이의 Trade-Off라고 볼 수 있다.
✅ Incorporating I/O
이번에는 "모든 작업은 CPU만 사용하고, I/O 작업은 수행하지 않는다." 라는 가정을 삭제해보자.
- Workload 가정
1. 각 작업은 동일한 시간 동안 실행된다.
2. 모든 작업은 동시에 도착한다.
3. 모든 작업은 CPU만 사용하고, I/O 작업은 수행하지 않는다.
4. 각 작업의 실행 시간은 미리 알려져 있다.- Metrics
Turnaround Time
이전 프로세스 설명 글에서, 프로세스는 3가지 상태 Running, Ready, Blocked 상태를 가진다고 설명하였고, 프로세스가 I/O 요청을 수행하는 경우, 다른 프로세스가 프로세서를 사용할 수 있도록 Blocked 상태로 전환된다고 설명하였다.
아래의 그림을 살펴보며, 해당 내용을 점검해보자.
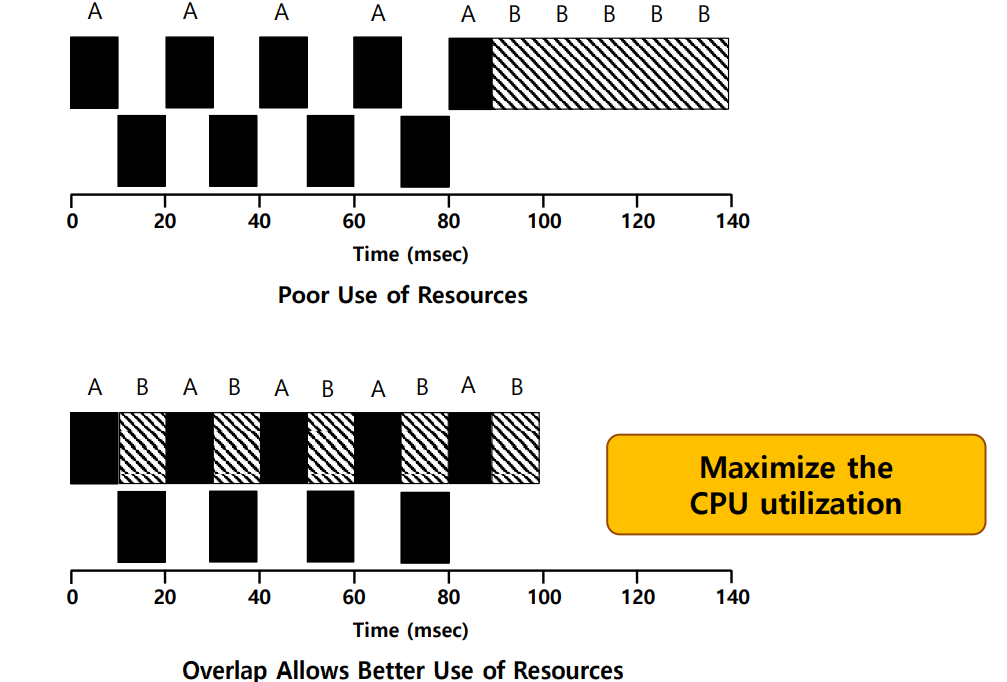
프로그램 A와 B는 각각 의 CPU 시간이 필요하며, A는 동안 실행될 때마다 가 소요되는 I/O 요청을 발생시킨다고 가정해보자.
첫 번째 그림에서는 A가 I/O 요청을 진행하는 동안 B는 단순히 기다리고 있다. A가 CPU 자원을 사용하고 있는 시점이 아닌데도! 따라서 두 번째 그림처럼 A가 I/O 요청을 위해 잠시 CPU를 놓고 기다리는 동안, 스케줄러가 CPU를 B에게 할당한다면 전체 시스템 효율을 높일 수 있다.
마치며
- Workload 가정
1. 각 작업은 동일한 시간 동안 실행된다.
2. 모든 작업은 동시에 도착한다.
3. 모든 작업은 CPU만 사용하고, I/O 작업은 수행하지 않는다.
4. 각 작업의 실행 시간은 미리 알려져 있다.
마지막 가정, "각 작업의 실행 시간은 미리 알려져 있다." 를 아직 해결하지 못했다. 작업의 실행 시간을 미리 알지 못하는 경우에도, 스케줄링의 성능과 공정함을 보장할 수 있는 방법은 없을까?
다음 글에서는 가장 중요한 스케줄링 알고리즘인 Multi-Level Feedback Queue (MLFQ) 대해 구체적으로 알아보도록 하겠다.
