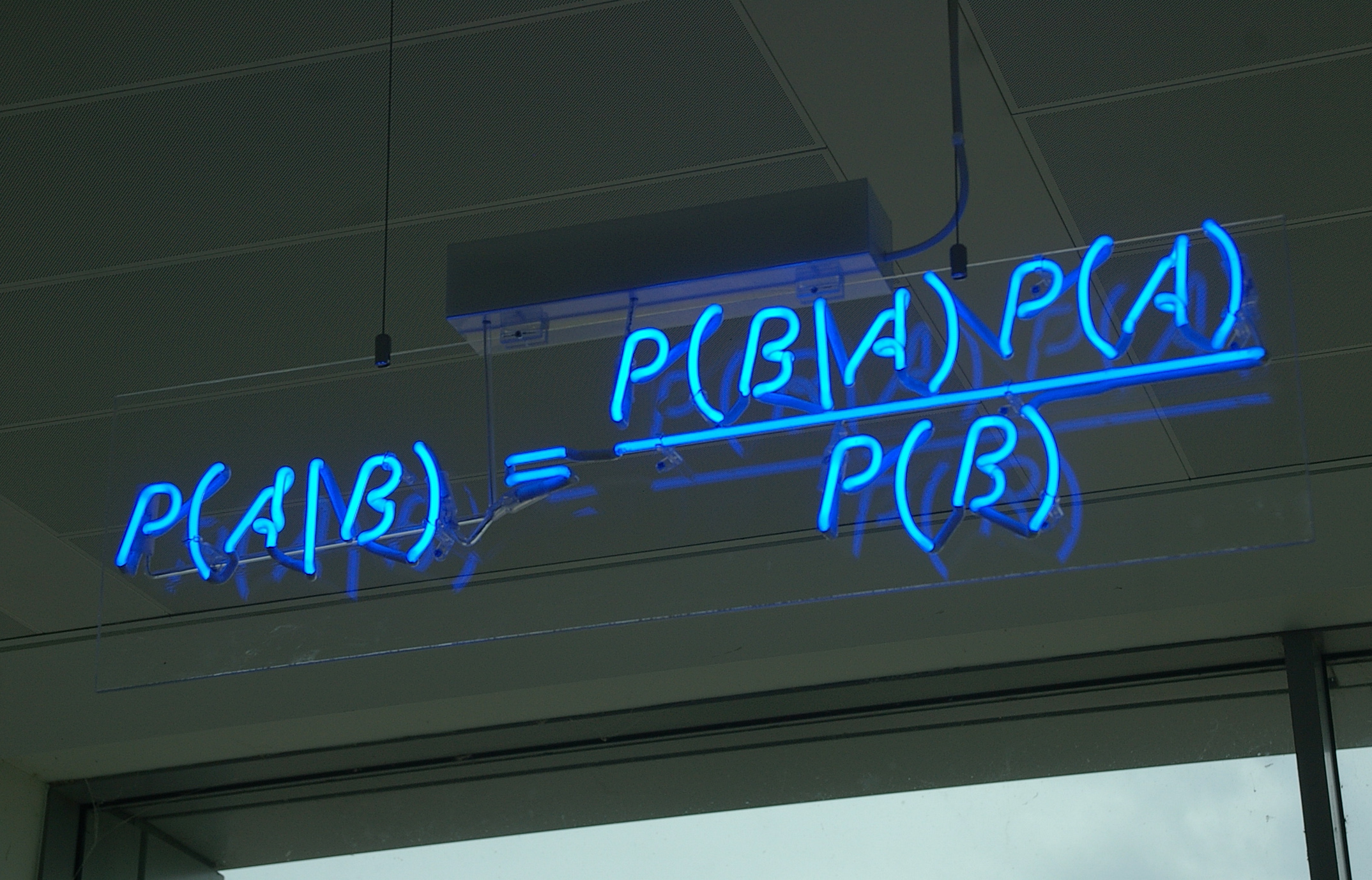
통계학 역사상 가장 중요한 이론 중에 하나이자 머신러닝에서 광범위하게 사용되는 수학적이 개념인 베이즈 정리(Bayes Theorem)-베이즈룰(Bayes Rule)-에 대해 알아봅시다.
베이즈 정리(Bayes’ Theorem)의 정의
대부분의 머신러닝과 패턴인식 교재는 첫장에서 베이즈 정리와 베이즈 분류기를 다룹니다. 그 이유로는
첫째, 베이즈 분류기는 다른 기계학습 방법론들에 비해 상대적으로 알고리즘이 간단함에도 불구하고 현실세계의 많은 문제를 효과적으로 풀 수 있다는 장점이 있습니다.
둘째, 베이즈 정리를 공부하면서 기계학습을 심도 깊게 이해하기 위해서 꼭 공부해야만하는 확률론에 대한 감을 키울수 있습니다.
베이즈 정리에 대해 알아보면서 기계학습 시스템에 대한 직관을 키워봅시다.
아래의 식이 베이즈 정리의 수학적 정의입니다.
위 식에서 p(A)는 A의 사전 확률(Prior Probability), p(A|B)는 A의 사후 확률(Posterior Probability), p(B|A)는 우도(Likelihood), p(B)는 B의 사전 확률을 나타냅니다.
확률론에 익숙하지 않고, 위 수식을 처음 접했다면 새로운 개념이 많이 나와 복잡하게 느껴질 수 있으므로 예제를 통해 위 식이 의미하는 바를 직관적으로 이해해봅시다.
베이즈 정리 적용예시1 – 거짓말 탐지기
예제 1 – 평소에 60%의 확률로 거짓말을 하는 사람이 있다고 합시다. 우리는 90%의 정확도를 가진 거짓말 탐지기를 통해 이 사람의 말이 거짓인지를 판단하고자 합니다.
위 문제는 거짓말 탐지기의 결과를 이용해서 어떤 사람의 말이 사실인지 거짓인지를 판단하는 문제입니다.
이를 좀 더 수학적으로 표현하면, 이 문제는 거짓말 탐지기의 관찰결과를 토대로 어떤 사람의 말이 거짓일 사후확률 p(A|B)를 구하는 문제입니다.
이제 사후 확률 p(A|B)을 구하기 위해서 베이즈정리를 어떻게 이용하는지 살펴봅시다.
먼저, 사전 확률 p(A)는 우리가 알고 있는 사전 지식에 의존합니다. 이 문제의 경우, 사전 확률 p(A)은 이 사람이 평소에 거짓말을 할 확률인 0.6(60%)입니다.
우도 p(B|A) 역시 보통 알려져 있다고(=이미 정보를 가지고 있다고) 가정하는 경우가 많습니다. 이 문제의 경우, 우도는 이 사람이 거짓말을 했을때 실제로 그것이 거짓이었을 확률 p(B|A)이므로 거짓말 탐지기의 정확도가 곧 우도입니다. 따라서 우도 p(B|A)는 0.9(90%)입니다.
사전 확률 p(B)는 거짓말 탐지기가 거짓이라고 판정할 확률입니다. 따라서, p(B)는 거짓말인데 거짓이라고 판정한 경우-p(B|A)p(A)-와 거짓말이 아닌데 거짓이라고 판정한 경우-p(B|A^c)p(A^c)의 합이 됩니다. 따라서 p(B)를 구하는 식은 아래와 같습니다.
이제 사후 확률을 구하는데 필요한 p(B|A), p(A), p(B)의 값을 모두 구했으니, 위에서 구한 값들을 베이즈 정리 공식에 대입해봅시다.
계산 결과 우리가 구하고자 하는 사후 확률 p(A|B)는 0.93(93%)임을 알 수 있습니다.
위의 식이 뜻하는 바에 대해서 좀 더 생각해봅시다. 우리가 처음 가지고 있던 지식에 의해서는 이 사람이 거짓말을 할 확률이 60%였습니다. 하지만 90%의 정확도를 가진 거짓말 탐지기에 의해서 이 사람의 말이 거짓이라는 결과가 관찰되었습니다. 따라서 우리는 이 관찰결과에 의해서 이 사람이 거짓말을 했을 확률을 93%로 업데이트했습니다.
즉, 베이즈 정리의 핵심은 관찰을 통해 새로운 정보를 획득하면 사후 확률(믿음의 정도)을 업데이트 한다는 점입니다. 이 개념을 통해 베이즈 정리가 의미하는 바를 직관적으로 이해할 수 있습니다.
다시 또 다른 예제를 통해 사후확률을 업데이트한다는 개념을 좀 더 견고하게 이해해봅시다.
베이즈 정리 적용예시 2 – 유방암 검사
예제 2 – 일반 여성의 유방암의 발병률은 0.1%라고 합니다. 유방암 검사는 실제 유방암에 걸린 사람의 99%에 대해서 양성반응을 나타내고, 건강한 사람에 대해서는 2%만이 양성반응을 보입니다. 이때 어떤 사람의 검사 결과가 양성 반응을 보였다면 이 사람이 실제로 유방암에 걸렸을 확률은 얼마일까요?
이 예제는 우리의 잘못된 직관을 베이즈 정리로 수정할수 있다는 사례로 자주 거론되는 예시 중에 하나입니다. 실제 의사들도 이 질문에 제대로 된 답을 내지 못했다고 합니다. 우리는 보통 양성 판정을 받으면 병에 걸렸을 확률이 매우 높다고 생각하고 걱정합니다. 그렇지만 과연 정말 그럴까요? 위 문제를 베이즈 정리를 통해 풀어보면서 우리의 인지적 오류를 바로 잡아봅시다.
위의 문제를 수학적으로 해석하면 이 문제는 검사결과가 양성일때 이 사람이 실제로 유방암에 걸렸을 사후확률 p(A|B)를 구하는 문제입니다.
위의 예제 2에서 사전 확률 p(A)는 아무런 추가정보가 없을때 어떤 사람이 유방암에 걸렸을 확률이므로 유방암 발병율인 0.001(0.1%)입니다.
우도 p(B|A)는 실제 유방암에 걸렸을 때 검사 결과가 양성이 나올 확률입니다. 따라서 우도 p(B|A)는 검사결과 실제 유방암 환자에 대한 양성 반응이 나올 확률인 0.99(99%)입니다.
p(B)는 검사결과 양성판정이 나올 확률입니다. 따라서, 사전 확률 p(B)는 실제 유방암 환자일 때 나온 양성반응-p(B|A)p(A)-와 건강한 사람인데 나온 양성반응-p(B|A^c)P(A^c)-의 합입니다. 따라서 p(B)를 구하는 식은 아래와 같습니다.
이제 위에서 구한 p(A), p(B|A), p(B)값을 베이즈 정리에 대입해서 A의 사후 확률 p(A|B)를 구해봅시다.
따라서 위 결과에 의해 이 사람이 유방암 양성 판정을 받았을 때, 실제 유방암에 걸렸을 확률은 4.9%(0.049)입니다. 이와 같은 결과가 나온 이유는 유방암 환자에 비해 건강한 사람의 비율이 압도적으로 많기 때문입니다.(
라는 사실에 주목합시다.)
즉, 베이즈 정리 공식에서 분모 p(B)가 분자 p(B|A)p(A)보다 압도적으로 큰 값을 가지게 되기 때문에 우리가 구하고자하는 사후확률 p(A|B)는 우리의 예상과는 다르게 상대적으로 작은 값을 갖게 됩니다.
따라서 유방암 검사에서 한번 양성 판정을 받았다고 크게 걱정할 필요는 없습니다. 하지만 사후 확률이 4.9%로 검사전 사전 확률인 0.1%보다 매우 증가했으므로 이 사람은 다시 검사해 볼 필요가 있습니다.
이 사람이 한번더 검사하는 경우를 다시 베이즈 정리에 대입해서 생각해봅시다.
이제 사전 확률 p(A)는 아무런 관찰없이 가정한 유방암 발병율인 0.001(0.1%)이 아니라 이전 검사 결과를 토대로 구한 사후 확률인 0.049(4.9%)가 됩니다.
우도 p(B|A)는 실제 유방암에 걸렸을 때 검사 결과가 양성이 나올 확률입니다. 따라서 우도 p(B|A)는 검사결과 실제 유방암 환자에 대한 양성 반응이 나올 확률인 0.99(99%)입니다.
p(B)는 검사결과 양성판정이 나올 확률입니다. 따라서, 사전 확률 p(B)는 실제 유방암 환자일 때 나온 양성반응-p(B|A)p(A)-와 건강한 사람인데 나온 양성반응-p(B|A^c)P(A^c)-의 합입니다. 따라서 p(B)를 구하는 식은 아래와 같습니다.
이제 위에서 구한 p(A), p(B|A), p(B)값을 베이즈 정리에 대입해서 A의 사후 확률 p(A|B)를 구해봅시다.
위 식을 보면 어떤 사람이 두번의 검사 결과 모두 유방암 양성 판정을 받았을 때, 실제 유방암에 걸렸을 확률은 71.8%(0.718)입니다. 따라서 두 번의 검사에서 양성 판정을 받았을 경우에는 실제로 유방암에 걸렸을 확률이 매우 높습니다.
베이즈 정리의 의의와 머신러닝과의 연관성
이처럼 베이즈 정리를 이용할 경우 , 관찰결과를 토대로 사후 확률(믿음의 정도)를 지속적으로 업데이트 해나갈 수 있습니다. 우리가 마주치는 머신러닝 문제들도 어떤 가설을 설정하고 데이터(=관찰 결과)를 토대로 가설을 지속적으로 업데이트 해나가는 과정이기 때문에 많은 부분에 베이즈 정리를 적용할 수 있고 베이즈 정리에 기반한 기법들이 광범위하게 사용되고 있습니다. 따라서 머신러닝 전문가가 되기 위해서는 베이즈 정리에 대한 제대로된 이해가 필수적입니다.
References
[1] https://en.wikipedia.org/wiki/Bayes%27_theorem
[2][불멸의 이론 : 베이즈 정리는 어떻게 250년 동안 불확실한 세상을 지배하였는가], 샤론 버치 맥그레인, 휴먼사이언스, 2013