머신 러닝(Machine Learning)이란 “데이터를 이용해서 컴퓨터를 학습시키는 방법론”을 뜻합니다. 이때, 머신 러닝 알고리즘은 크게 세가지 분류로 나눌 수 있습니다. 바로, 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning)입니다.
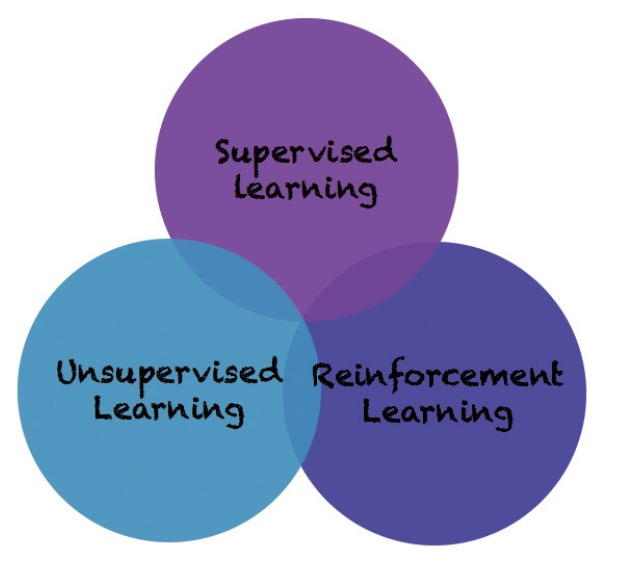
그림 1 – 머신 러닝 알고리즘의 분류
지도 학습(Supervised Learning)
지도 학습(Supervised Learning)은 데이터에 대한 레이블(Label)-명시적인 정답-이 주어진 상태에서 컴퓨터를 학습시키는 방법입니다.
즉, (데이터(data), 레이블(label)) 형태로 학습을 진행하는 방법입니다.
예를 들어서, 아래와 같은 28×28 크기의 이미지인 MNIST 데이터셋이 있으면, 이를 이용해 학습을 진행할때, 트레이닝 데이터셋(Training set)은 아래와 같이 구성됩니다.
(0을 나타내는 28×28 이미지, 0), (7을 나타내는 28×28 이미지, 7), (6을 나타내는 28×28 이미지, 6), (0을 나타내는 28×28 이미지, 0), …

그림 2 – MNIST 데이터셋
이렇게 구성된 트레이닝 데이터셋으로 학습이 끝나면, 레이블(label)이 지정되지 않은 테스트 데이터셋(Test set)을 이용해서, 학습된 알고리즘이 얼마나 정확히 예측(Prediction)하는지를 측정할 수 있습니다.
예를 들어서,
(4을 나타내는 28×28 이미지)
를 학습된 분류기에 집어 넣으면, 올바르게 4를 예측 하는지(True Prediction) 아니면 3이나 5와 같은 잘못된 레이블을 예측하는지 (False Prediction) 측정할 수 있습니다.
이때, 예측하는 결과값이 discrete value(이산값)면 classification(분류) 문제-이 이미지에 해당하는 숫자는 1인가 2인가?-,
예측하는 결과값이 continuous value(연속값)면 regression(회귀) 문제-3개월뒤 이 아파트 가격은 2억1천만원 일 것인가? 2억2천만원 일 것인가?-라고 합니다.
딥러닝에서 지도 학습(Supervised Learning) 방법론으로 주로 사용되는 구조는 Convolutional Neural Network(CNN), Recurrent Neural Networks(RNN)입니다.
비지도 학습(Unsupervised Learning)
비지도 학습(Unsupervised Learning)은 데이터에 대한 레이블(Label)-명시적인 정답-이 주어지지 상태에서 컴퓨터를 학습시키는 방법론입니다.
즉, 데이터에 대한 명시적인 정답없이 (데이터(data)) 형태로 학습을 진행하는 방법입니다. 예를 들어서, 아래와 데이터가 무작위로 분포되어 있을때, 이 데이터를 비슷한 특성을 가진 세가지 부류로 묶는 비지도 학습의 일종인 클러스터링(Clustering) 알고리즘이 있습니다.
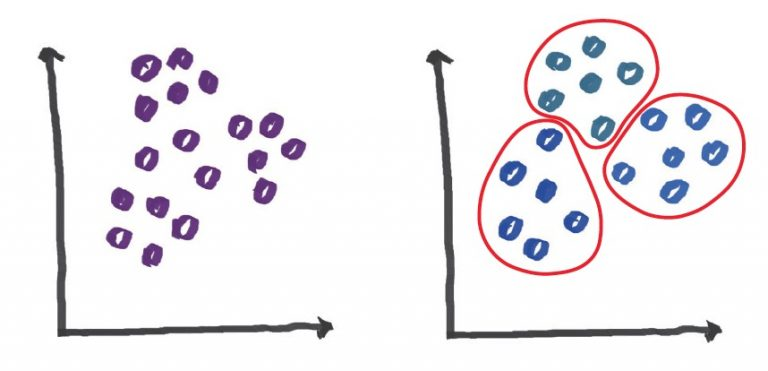
그림 3 – Clustering 알고리즘
비지도 학습은 데이터의 숨겨진(Hidden) 특징(Feature)이나 구조를 발견하는데 사용됩니다.
좀더 직관적인 예를 들어서, 우리가 대량의 뉴스기사 데이터를 가지고 있을때 이 데이터는 “뉴스기사 데이터”라는 카테고리로 분류되지만, 클러스팅 알고리즘을 사용해서 숨겨진 특징을 파악하면 A라는 뉴스기사는 “정치 카테고리”의 뉴스, B라는 뉴스기사는 “스포츠 카테고리”, C라는 뉴스기사는 “경제 카테고리” 이렇게 숨겨져있던 뉴스기사의 카테고리를 파악할 수 있게 됩니다.
딥러닝에서 비지도 학습(Unsupervised Learning) 방법론으로 주로 사용되는 구조는 오토인코더(AutoEncoder)입니다.
강화 학습(Reinforcement Learning)
강화 학습(Reinforcement Learning)은 앞서 살펴본 지도 학습(Supervised Learning)과 비지도 학습(Unsupervised Learning)과는 약간은 다른 종류의 학습 알고리즘입니다.
앞서 살펴본 알고리즘들이 데이터(data)가 주어진 정적인 상태(static environment)에서 학습을 진행하였다면, 강화 학습(Reinforcement Learning)은 에이전트가 주어진 환경(state)에 대해 어떤 행동(action)을 취하고 이로부터 어떤 보상(reward)을 얻으면서 학습을 진행합니다.
이때, 에이전트는 보상(reward)을 최대화(maximize)하도록 학습이 진행됩니다. 즉, 강화학습은 일종의 동적인 상태(dynamic environment)에서 데이터를 수집하는 과정까지 포함되어 있는 알고리즘입니다.
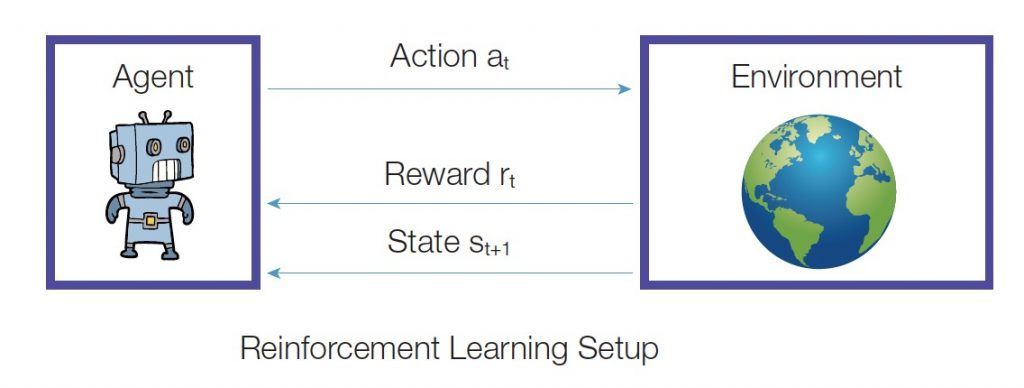
그림 4 – 강화학습(Reinforcement Learning) 알고리즘
좀더 직관적인 예를 들면, 우리가 잘 아는 딥마인드(DeepMind)사의 알파고(AlphaGo)가 대표적인 강화학습 알고리즘을 적용한 사례입니다. 알파고는 여러번의 바둑 게임을 시뮬레이션으로 두면서 게임에서 이길 경우에 +1의 양의 보상(reward) 게임에서 질 경우 -1의 음의 보상(reward)을 받으면서 학습해나갑니다.
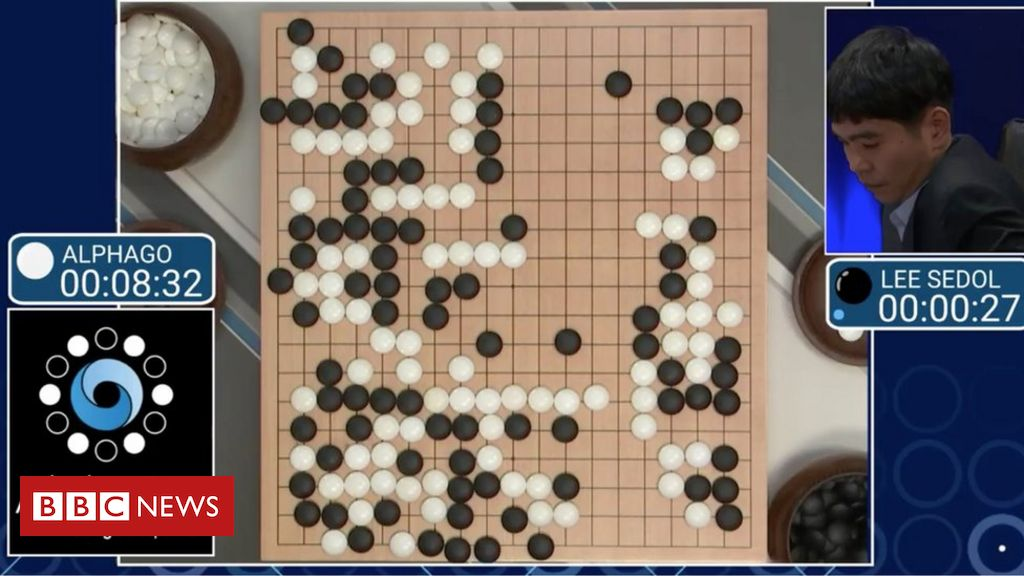
그림 5 – 대표적인 강화학습(Reinforcement Learning) 알고리즘의 적용사례인 알파고(AlphaGo)
강화학습의 대표적인 알고리즘은 Q-Learning이 있고, 딥러닝과 결합하여 Deep-Q-Network(DQN) 방법으로도 사용되고 있습니다.
머신러닝의 한계와 더 나아갈 길
현재 2021년 기준으로 95%이상의 실용적인 머신러닝 알고리즘은 위 세가지 알고리즘 중에서 지도 학습(Supervised Learning) 방법론을 취하고 있습니다. 하지만 지도 학습 방법론은 대량의 정답 데이터가 포함된 트레이닝 데이터가 필요하고, 학습된 데이터와 다른 형태의 데이터에 대해서는 잘 동작하지 못한다는 문제점을 가지고 있습니다.

그림 6 – 범용 인공지능(Artificial General Intelligence)을 향한 길
따라서 우리가 인간처럼 생각하고 행동하는 진정한 범용 인공지능(Artificial General Intelligence)을 구현하기 위해서는 앞으로 지도 학습(Supervised Learning) 외에 비지도 학습(Unsupervised Learning)과 강화 학습(Reinforcement Learning)에 기반한 머신러닝 알고리즘에 대한 연구를 가속화해야만합니다.
References
[1] http://yann.lecun.com/exdb/mnist/
[2] http://solarisailab.com/archives/1785