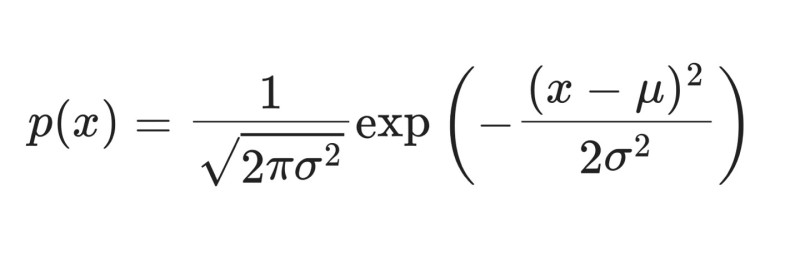Difference between Data and Information
Data
- 어떤 처리가 이루어지지 않은 상태의 character(문자)나 number(수치), image(그림) 등으로 단순히 측정하고 수집된 것 을 의미함.
- 어떤 의미나 목적을 포함하지 않고 수집 측정된 raw data를 의미. 주로 컴퓨터에 입력되는 데이터를 의미.
- 단순한 사실의 나열이라고 생각하면 됨.
Information
- 어떠한 목적이나 의도에 맞게 data를 가공 처리한 것.
- 어떤 목적에 의해 유용하게 사용할 수 있는 것.
Computer에서의 Data
컴퓨터에서 다루는 데이터
- Numerical data
Numberreal number, natural number, integer, ...) - Non-numerical data
Letter (or charactor), Symbol - Data structure (자료구조)
Linear Lists,Trees,Rings,etc - Program (Instruction set)
Data Representatation
- 주로 내부에서 사용되는 표현은 계산을 위한 경우로 이진수를 기반으로 하는 numerical data 중심
- 외부와의 Information exchange(정보 교환)을 위해 사용되는 표현은 code 등을 기반으로 하는 non-numerical data 중심
따라서 Data의 종류 및 용도에 따라 Interal Representation과 External Representation으로 바뀌어 컴퓨터에서 사용된다.
Number(for computing)
컴퓨터에 저장된 대부분의 Number는 계산을 통해 변경된다.
-
계산 효율성을 위해 Interal Representation이 사용됨
-
표현성을 위해 최종 결과를 External Representation으로 변환
Alphabets, Symbols and Some Numbers
정보 처리 과정에서 변경되지 않음
-
처리 및 표시 가능성에 대한 Interal Representation.
-
계산에 사용되지 않기 때문에 Interal Representation이 필요하지 않음.
Operations
컴퓨터가 data를 처리하는 연산, 컴퓨터가 수행하는 작업을 가르키는 instruction과 비슷하게 사용되는데 opertaion은 주로 숫자 도는 논리 연산을 의미하고 instruction은 자료의 로딩, 복사 등의 컴퓨터가 수행하는 작업들이 기본 단위를 의미하는 경우로 많이 사용.
Operation의 구분은 operand(피연산자)에 따른구분
Unary
-
1개의 operand(or input), 1개의 output
-
shift, move, not
Binary
-
2개의 operand(or input), 1개의 output
-
and, or, 사칙연산
operand의 type에 따른 구분(true or false)
Numearical Operator
Logic Operator
Information
학습(어떤 사실을 알게된 경우)의 결과로 인한 놀람의 정도 (degree of surprise)
-
빈번하게 일어날 것 같지 않은 event (발생확률 p가 매우 작음)가 발생하는 경우 (=발생함을 알게 된 경우), 빈번하게 일어나는 event가 일어나는 경우보다 더 많은 information 을 획득.
-
항상 발생하는 event가 발생 할 경우, 우리가 얻는 information의 양은 없음
-
특정 event가 발생할 경우 얻어지는 정보량 h(x)이 해당 event 의 발생확률 p(x)에 의해 결정된다.
정보량 : bit
어떤 Discrete random variable x에서 해당 x의 값을 알게 되는 경우 얻게되는 정보량을 Shannon이 제안한 방식으로 정량화하면 다음과 같은 수식이 된다.
h(x): 확률변수가 값을 가질 때의 정보량
p(x): 확률변수가 값을 가질 확률.
흔히 log의 base(및)은 2를 사용하며 이 경우 정보량의 단위가 bit이다.
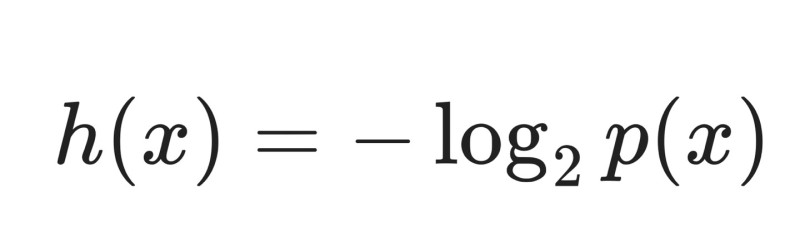
확률변수가 가질 수 있는 값을 다양한 경우의 수를 가지는 경우보다,
0 또는 1 두가지 경우로 한정하는 것이 가장 기본적이라고 볼 수 있다.
ex) 특정 event의 발생 유무).
이는 information을 다루는 컴퓨터가 기본적으로 이진수를 사용하는 것과도 연관된다.
Entropy : 평균 정보량
x가 0,1,...,n의 값을 가지는 random-variable(확률 변수) x에 대한 평균 정보량
discrete random variable(이산 확률 변수)
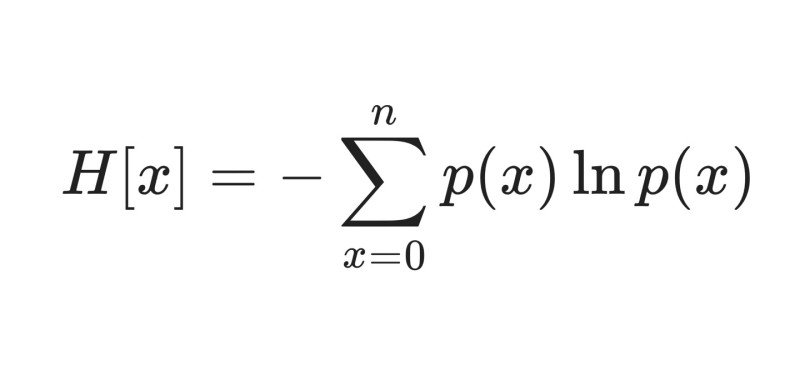
확률변수가 절대 될 수 없는 값이 있을 경우, 해당 값의 발생확률이 p(x)=0이 되므로 이는 entropy에 영향을 미치지 않는다.
확류변수가 특정 상수로 고정될 경우, p(x)=1이기 때문에 = = 0 그래서 entropy가 0이 됨
continuous random variable(연속 확률 변수)
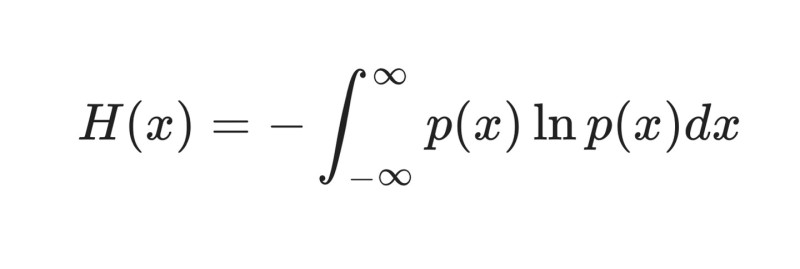
Entropy는 random variable의 상태를 전송하는데 필요한 bit 수의 Lower Bound라고 볼 수 있음.
ex) 엔트로피가 3.4 라면 결국 4bit 이상 필요
Entropy가 극대화 되는 경우
-
Discrete random variable(이산 확률 변수)이 가질 수 있는 값들의 발생확률이 모두 같은 경우, 즉 해당 확률변수가 uniform probability distribution(균일 확률 밀도 분포)인 경우 Entropy가 최대.
-
Gaussian probability distribution(가우시안 확률 분포)을 따르는 Continuous random variable(연속 확률 변수)의 경우, 해당 분포의 Variance(변화량)이 클수록 entropy가 증가함.
가우시안 확률 분포(정규분포)에서 변화량이 무한대일 경우 entropy는 최대.
변화량이 무한대일 경우가 바로 균일 확률 분포인 경우.