Image
- 컴퓨터가 image를 볼 때 Semantic Gap(의미론적 차이)이 있다. 사람이 이미지를 볼때면 고양이라고 인식하지만, 컴퓨터가 이미지를 볼때 이미지는 단지 0~255로된 큰 그리드의 숫자일 뿐이다.

- 이미지를 인식하는데 있어 몇가지 문제(Challenges)가 존재하는데,
아래처럼 7가지의 문제가 있습니다.- Viewpoint Varation(보는 위치의 차이)
- Intraclass Variation(같은 class라고해도 다른색, 형태가 존재)
- Fine-Grained Categories(세세하게 구분되는 라벨)
- Background Clutter(배경과 구분이 잘 안가는)
- Illumination Changes(조명의 변화)
- Deformation(다양한 모양)
- Occlusion(형체의 일부만 보임)
Datasets
- 여러 종류의 Datasets이 있습니다.
- MNIST
- CIFAR10, CIFAR100
- ImageNet
- MIT Places
- Omniglot
Nearest Neighbor
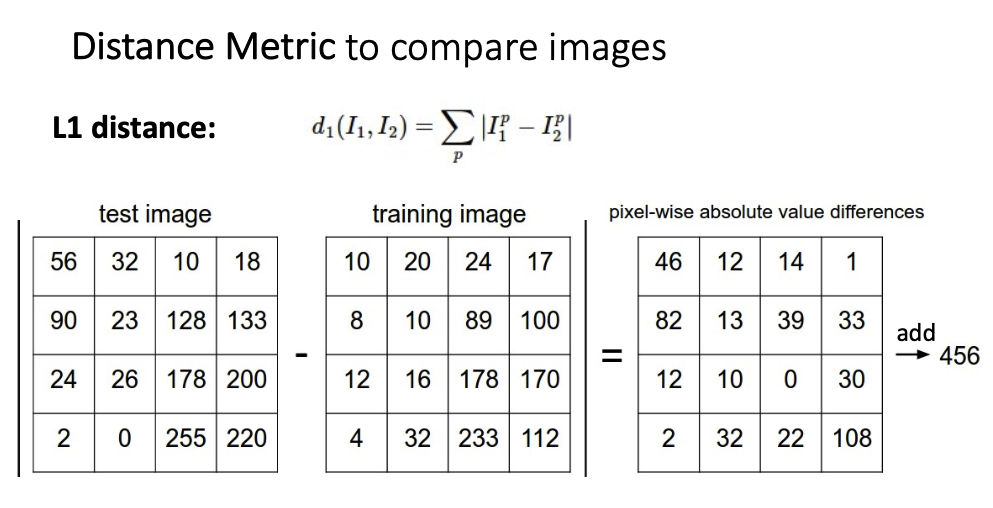
- train(학습)방법: 모든 데이터와 라벨을 기억만 한다. 단순히 저장만 하기 때문에 O(1)의 시간복잡도로 학습합니다.
- predict(예측)방법: train에서 저장한 데이터와 가장 유사한 라벨로 예측합니다. 저장한 모든 데이터를 순회해야하기 때문에 O(n)의 시간복잡도로 예측합니다.
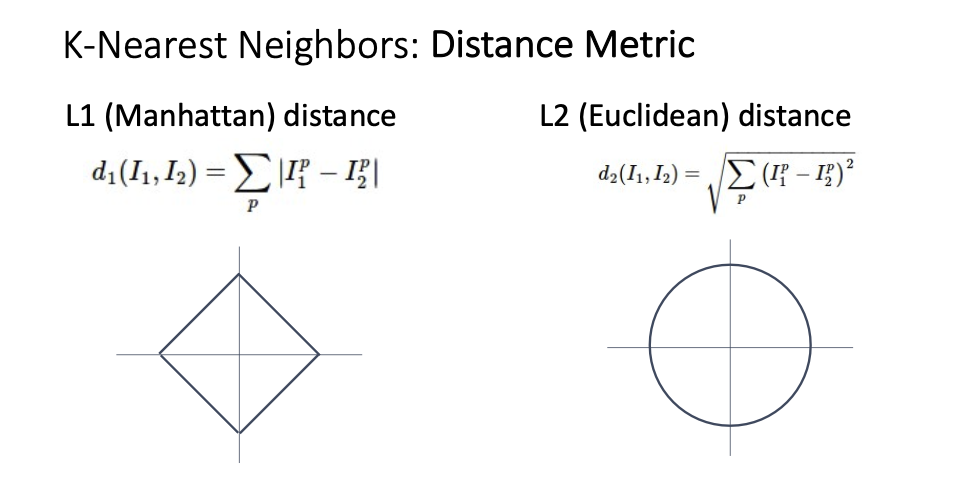
- 그렇다면 가장 유사한 라벨을 어떻게 예측할까? 가장 유사한 라벨을 찾는 방법 중 하나로 L1 distance가 있습니다. (L2 distance도 존재)
K-Nearest Neighbors
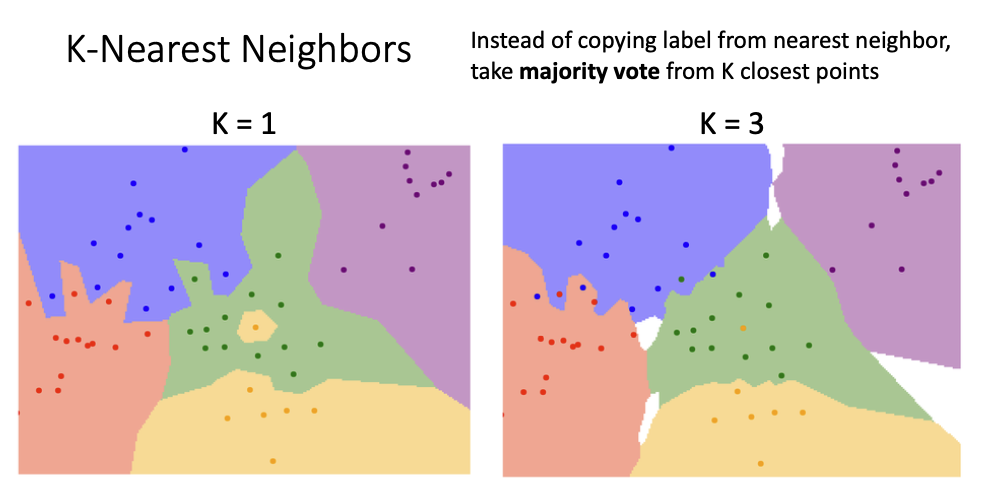
- Nearest Neighbor에서처럼 가장 가까운 이웃의 라벨로 판단하는 것이 아닌, K개의 가장 가까운 지점의 다수투표로 라벨을 결정하는 알고리즘입니다.
- K=1일 때는 단순히 Nearest Neighbor입니다.
Distance Metric
- L1 distance와 L2 distance가 있습니다.
K-Nearest Neighbors 한계

- 문제점1: test(predict)를 하는데 굉장히 오랜시간이 걸린다. (학습에 오랜시간이 걸리더라도 예측은 바로 되는 것이 좋은 모델)
- 문제점2: 픽셀에 적용되는 Distance Metrix가 그렇게 유용하지 않다. (위의 사진 처럼 원본과 Boxed, Shifted, Tinted된 사진 모두 같은 L2 distance를 가짐 -> 구분을 하지 못함)
Hyperparameters
- 데이터를 학습하면서 배우는 값이 아닌, 학습과정 초반에 설정해야하는 값들을 말합니다.
- 위의 K-Nearest Neighbors의 예시로, 어떤 K값을 사용할지, 어떤 Distance Metric을 사용할지도 하이퍼파라미터를 정하는 과정이라고 할 수 있습니다.
Data split

- 일반적으로 Train, Validation, Test로 나누는 것이 좋습니다.
- Train: 말 그대로 모델을 학습하는데 쓰는 데이터
- Validation: 학습을 시키진 않지만 오버피팅(overfitting)에 빠지지 않고, 모르는 데이터에 대해서도 좋은 성능을 내주기 위해 사용된다.
- Test: 학습에 관여하지 않고, 최종성능을 평가하는데에만 사용된다.
validation을 이용해서 Hyperparameters를 고른다.
Curse of Dimensionality
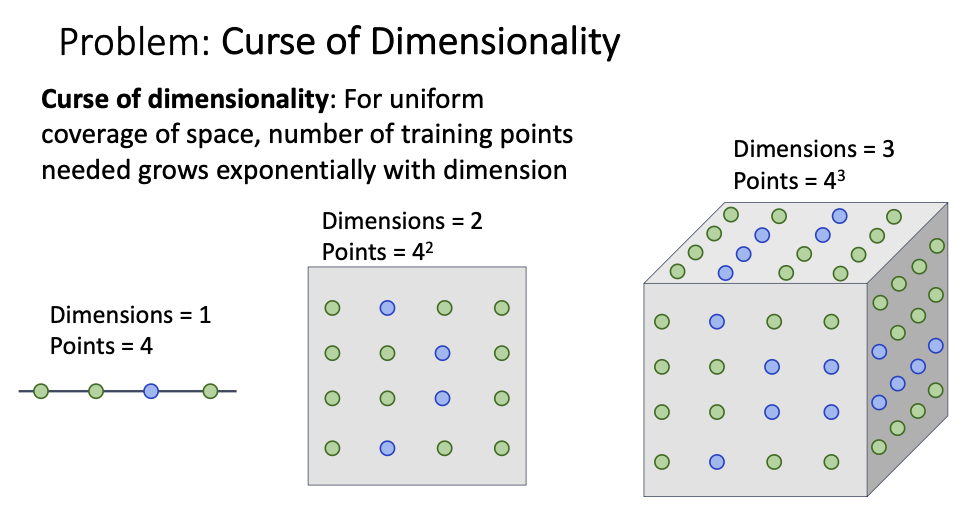
- 차원이 커질수록 학습 포인트가 기하급수적으로 늘어난다는 것 같은데 무슨 의미인지는 좀더 공부 필요
내용오류가 있을 수 있습니다. 감사합니다.

안녕하세요!