이번 포스팅으로 정리해볼 내용은 직접 데이터를 모으고 데이터라벨링을 거쳐 학습시킨 후 실시간으로 학습시킨 내용을 확인해보는 내용입니다.
preview
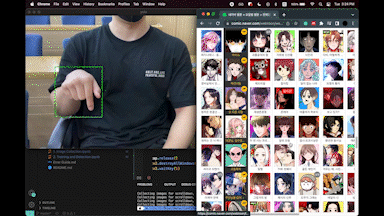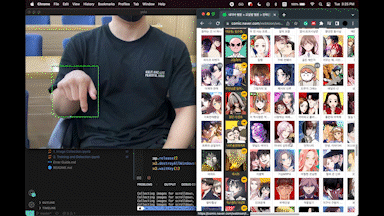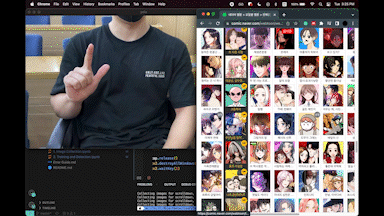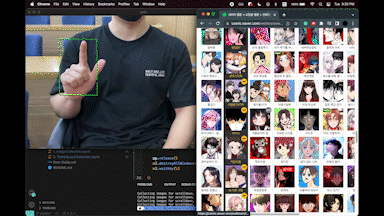
이 포스팅은 이 유튜브에 대한 내용을 활용 및 변형 했습니다.
아직 yolo나 AI에 대한 내용이 미숙해서 구체적으로는 알지 못합니다. 추가적으로 알게되는 내용이 있으면 다시 와서 수정하겠습니다!
개발환경 : Apple Sillicon (Apple M1 pro)
Anaconda를 이용한 가상환경에서 진행
목차는 다음과 같습니다.
- 데이터 수집
- 데이터 라벨링
- yolov5s로 학습 진행
- 실시간 검출 진행
이 시리즈의 내용은 기본적인 openCV에 대해 어느정도 알고있다는 전제 하에 진행됩니다!
이번 포스팅에서는 1번 데이터수집부터 진행해보도록 하겠습니다!
1. 데이터 수집
import cv2
import uuid
import os
import time
IMAGES_PATH = os.path.join('data', 'images') # 현재 위치에 data/images폴더 미리 만들어 주세요
labels = ['scrollup', 'scrolldown'] # 학습시킬 classes
number_imgs = 5 # label 당 몇 장의 사진을 찍을 것인지
cap = cv2.VideoCapture(0) # 웹캠을 받아옴
# labels를 순환
for label in labels:
print('Collecting images for {}'.format(label))
time.sleep(5) # 실제로 사진이 찍히기 전, 잠깐 멈춤
# 설정한 number_imgs만큼 사진 수집
for img_num in range(number_imgs):
print('Collecting images for {}, image number {}'.format(label, img_num))
# frame 읽어오기
ret, frame = cap.read()
# 유니크한 id를 주고 미리 지정한 IMAGES_PATH로
imgname = os.path.join(IMAGES_PATH, label+'.'+str(uuid.uuid1())+'.jpg')
# 읽어들인 frame을 지정한 path에 저장
cv2.imwrite(imgname, frame)
# 어떻게 찍혔는지 보여줌
cv2.imshow('Data Collection', frame)
# 2초 대기
time.sleep(2)
# q 누르면 나감
if cv2.waitKey(10) & 0xFF == ord('q'):
break
# 자원 해제
cap.release()
cv2.destroyAllWindows()우선 코드입니다. openCV를 활용하여 몇 초간의 대기 시간을 주고 프레임을 캡쳐 후 저장합니다.
저장되는 기본 path는 IMAGES_PATH에서 알 수 있듯이 현재 디렉토리에서 data/images 폴더 안에 사진을 저장합니다.
아마 폴더를 만드는 코드는 구현하지 않았으니(?) 현재 디렉토리(위의 파이썬 파일이 있는곳)에 data 폴더를 만든 후 images폴더를 만드시면 됩니다.
1-0 : 필요한 library import
import cv2
import uuid
import os
import timecv2 : 웹캠을 가져오고 frame을 읽어 저장하는 역할을 함
uuid : 각 사진마다 유니크한 값을 줄 수 있음
os : 폴더 path 설정에 활용
time : 사진을 찍은 후 다음 사진까지 딜레이를 주기 위해 사용
1-1 : 기본 변수 설정
IMAGES_PATH = os.path.join('data', 'images') # 현재 위치에 data/images폴더 미리 만들어 주세요
labels = ['scrollup', 'scrolldown'] # 학습시킬 classes
number_imgs = 5 # label 당 몇 장의 사진을 찍을 것인지IMAGES_PATH : 현재 디렉토리(파이썬 파일이 있는 위치에서) data라는 폴더 안의 images폴더에 캡쳐된 프레임이 저장될 것입니다.
labels : 학습시킬 이름을 지정합니다. 이번 프로젝트의 경우 scrollup과 scrolldown을 학습시킬 것이기 때문에, labels에 총 2개의 값을 줬습니다.
numbers_imgs : 위에서 지정한 각 label당 몇 장의 사진을 찍을 것인지 저장합니다. 위와 같은 경우에는 각 label 당 5개씩 데이터를 수집한다는 뜻입니다.
1-2 : labels 순환하며 데이터 수집
cap = cv2.VideoCapture(0) # 웹캠을 받아옴
# labels를 순환
for label in labels: # ㄱ
print('Collecting images for {}'.format(label))
time.sleep(5) # 실제로 사진이 찍히기 전, 잠깐 멈춤
# 설정한 number_imgs만큼 사진 수집
for img_num in range(number_imgs): # ㄴ
print('Collecting images for {}, image number {}'.format(label, img_num))
# frame 읽어오기
ret, frame = cap.read()
# 유니크한 id를 주고 미리 지정한 IMAGES_PATH로
imgname = os.path.join(IMAGES_PATH, label+'.'+str(uuid.uuid1())+'.jpg')
# 읽어들인 frame을 지정한 path에 저장
cv2.imwrite(imgname, frame)
# 어떻게 찍혔는지 보여줌
cv2.imshow('Data Collection', frame)
# 2초 대기
time.sleep(2)
# q 누르면 나감
if cv2.waitKey(10) & 0xFF == ord('q'):
break ㄱ for loop : ㄱ이라고 주석을 단 for loop에서는 labels의 수만큼 loop를 돕니다. 위의 경우 2개의 라벨이 있으므로, 총 2번 돌겠군요.
ㄴ for loop : ㄴ이라고 주석을 단 for loop에서는 우리가 지정한 number_imgs만큼 loop를 돌며 실제로 사진을 캡쳐하고 저장합니다.
나머지 자세한 부분은 주석을 봐주세요.
1-3 : 자원 해제
cap.release()
cv2.destroyAllWindows()사용한 자원해제 부분입니다. 중요하지 않은 부분이므로 자세한 내용은 스킵하겠습니다
이렇게 되면 우선 데이터 수집은 끝입니다!
질문이 있으시다면 댓글 달아주세요. 잘 알지는 못하지만 최대한 답장하겠습니다.
그럼 다음 포스팅에서는 이렇게 수집한 데이터를 직접 라벨링하는 과정에 대해 포스팅 해보겠습니다!
