
블로그에 게시하는 위 글은 전체적인 내용 정리가 아닌
책을 읽으면서 새로 알게된 내용이나 제가 중요하다고 생각하는 내용을 정리한 글입니다.
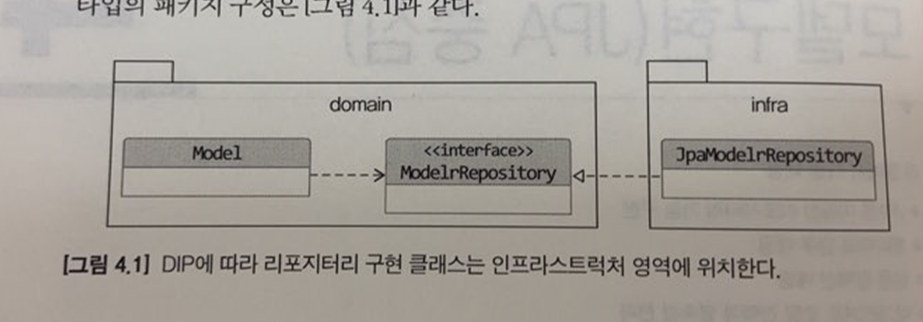
JPA를 이용한 리포지터리 구현
모듈 위치
리포지터리 인터페이스 → 도메인 영역
구현 클래스 → 인프라스트럭처 영역
리포지터리 기본 기능 구현
- 아이디로 애그리거트 조회하기
- 애그리거트 저장하기
인터페이스 → 애그리거트 루트 기준으로 작성한다.
보통 findBy + 프로퍼티 값으로 이름을 지으며, (ex. findById)
트랜잭션 범위에서 변경한 데이터는 자동으로 DB에 반영된다.
매핑 구현
엔티티와 밸류 기본 매핑 구현
애그리거트와 JPA 매핑을 위한 기본 규칙
- 애그리거트 루트는 엔티티이므로 @Entity로 매핑 설정하기
- 한 테이블에 엔티티와 밸류 데이터가 같이 있다면,
- 밸류는 @Enbeddable, 프로퍼티는 @Embedded로매핑 설정하기
- 엔티티와 DB의 이름이 다를 때는 @AttributeOverrides로 칼럼 이름 변경 가능
기본 생성자
@Entity와 @Embeddable을 사용하기 위해서는 기본 생성자가 필요한데,
다른 코드에서 사용하지 못하게 access를 protected로 두는 것을 추천한다.
필드 접근 방식 사용
setter를 사용하게 되면 캡슐화도 깨게 된다.
의도가 더 잘드러나는 메소드(setSate() → cancel()를 도메인 안에서 생성하는 것이 좋다.
- @Id, @EmbeddedId가 필드에 위치 ⇒ 필드 접근 방식 (추천)
- get 메서드에 위치 ⇒ 메서드 접근 방식
@Entity
@Access(AccessType.FIELD) // 필드 방식으로 처리
public class Person {
}AttributeConverter를 이용한 밸류 매핑 처리
Entity 객체에서는 두 개의 프로퍼티를 가지고 있는데, DB에서는 한 개일때가 있다.
(ex. 객체에서는 길이의 값, 단위를 따로 저장 / DB에서는 한 번에 저장)
AttributeConverter를 사용하면 처리 가능 (EmbbedId로 처리 불가능)
convertToDatebaseColumn() : 밸류 타입을 DB 칼럼 값으로
convertToEntityAttribute() : DB 칼럼값을 밸류 타입으로
@Converter(autoApply = true) // 모델에 출현하는 모든 Money 타입의 프로퍼티에 대해 자동으로 적용
public class MoneyConverter implements AttributeConverter<Money, Integer> {
@Override
public Integer convertToDatabaseColumn(Money money) {
if (money == null) {
return null;
}
return money.getValue();
}
@Override
public Money convertToEntityAttribute(Integer value) {
if (value == null) {
return null;
}
return new Money(value);
}
}만약 autoApply가 false라면,
도메인 객체 위에 @Convert(converter = 클래스 이름) 어노테이션을 수동으로 추가해주어야한다.
밸류 컬렉션: 별도 테이블 매핑
밸류 컬렉션을 다른 테이블에 매핑하고 싶을 때,
@ElementCollection, @CollectionTable를 사용하면 매핑이 가능하다.
public class Order {
@ElementCollection
@CollectionTable(name = "order_line", // 밸류를 저장할 테이블을 지정할 때 사용. name으로 테이블 이름 지정
joinColumns = @JoinColumn(name = "order_number")) // 외부키로 사용하는 칼럼 지정
@OrderColumn(name = "line_idx") // 지정한 칼럼에 리스트의 인덱스 값 저장 (밸류에는 인덱스 값이 없음)
private List<OrderLine> orderLines;
}밸류 컬렉션: 한 개 칼럼 매핑
밸류 컬렉션을 한 개 칼럼에 저장해야할 때가 있는데,
(ex. 이메일 주소 목록을 Set으로 보관하는데 DB에는 콤마구분으로 저장할 때)
AttributeConverter를 ****사용하면 된다. (사용법은 AttributeConverter를 이용한 밸류 매핑 처리 참고)
밸류를 이용한 아이디 매핑
식별자를 밸류로 만들고 싶을 때에는,
@Id 대신 @EmbeddedId를 사용하면 된다.
@Entity
public class Order {
@EmbeddedId // 식별자를 밸류로 만들기 위해 EmbeddedId를 사용
private OrderNo id; // 식별자
}@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Embeddable
public class OrderNo implements Serializable {
@Column(name = "order_number")
private String orderNo;
}식별자로 사용되는 밸류타입은 무조건 Serializable 인터페이스를 상속받아야한다.
밸류 타입으로 식별자를 구현하면 식별자에 기능 추가가 가능하다.
별도 테이블에 저장하는 밸류 매핑
애그리거트 - 루트 엔티티 = 대부분 밸류
만약 엔티티가 있다? → '진짜' 엔티티인지 의심해된다.
별도 테이블에 밸류를 저장하고 싶을 때에는,
@SecondaryTable과 @AttributeOverride를 사용하면 된다.
@Entity
@Table(name = "article)
@SecondaryTable(
name = "article_content",
pkJoinColumns = @PrimaryKeyJoinColumn(name = "id")
)
public class Article {
@Id
private Long id;
...
@AttributeOverrides({
@AttributeOverride(name = "content",
column = @Column(table = "article_content")),
@AttributeOverride(name = "contentType",
column = @Column(table = "article_content")),
})
private ArticleContent content;
...
}
@SecondaryTable
- name : 밸류를 저장할 테이블 지정
- pkJoinColumns : 밸류 테이블 - 엔티티 테이블로 조인할 때 사용할 칼럼 지정
@AttributeOverride
- 밸류 데이터가 저장된 테이블 이름 지정
애그리거트 로딩 전략
객체가 완전한 상태 → 즉시로딩을 사용(EAGER)
- 루트를 로딩하는 시점에 애그리거트에 속한 모든 객체를 함께 로딩 가능
- 성능상의 이슈 존재 → 즉시로딩이 꼭 개념적으로 하나라는 것의 해결책 X
애그리거트가 완전해야할 때
- 상태를 변경하는 기능을 실행할 때
- 표현 영역에서 애그리거트 상태 정보를 보여줄 때
지연로딩 (LAZY)
- 경우의 수를 따질 필요가 없음
- 쿼리 실행횟수가 더 많음
상황에 따라 로딩 전략을 잘 선택하는 것이 중요하다.
애그리거트의 영속성 전파
삭제할때도 애그리거트를 하나로 보고 같이 처리해야하다.
CascadeType.PERSIST, CascadeType.REMOVE를 사용하면 된다.
식별자 생성 기능
식별자를 생성하는 종류
- 사용자가 직접 생성
- 도메인 로직으로 생성
- DB를 이용한 일련번호 생성
