
지금까지 클래스와 함수를 사용하는 여러 코틀린 특성을 살펴봤다.
하지만 그 모든 것들은 함수나 클래스 이름을 소스코드에서 정확히 알고 있어야만 사용할 수 있는 기능이었다.
어떤 함수를 호출하려면 그 함수가 정의된 클래스의 이름과 함수이름, 파라미터 이름 등을 알아야만 했다.
애노테이션과리플렉션을 사용하면 그런 제약을 벗어나서 미리 알지 못하는 임의으 클래스를 다룰 수 있다.
애노테이션을 사용하면 라이브러리가 요구하는 의미를 클래스에게 부여할 수 있고, 리플렉션을 사용하면 실행 시점에 컴파일러 내부 구조를 분석할 수 있다.
애노테이션 선언과 적용
메타데이터를 선언에 추가하면 애노테이션을 처리하는 도구가 컴파일 시점이나 실행 시점에 적절한 처리를 해준다.
1. 애노테이션 적용
코틀린에서는 자바와 같은 방법으로 애노테이션을 사용할 수 있다.
애노테이션을 적용하려면 적용하는 대상 앞에 애노테이션을 붙이면 된다.
애노테이션은@과애노테이션 이름으로 이뤄진다.
함수나 클래스 등 여러 다른 코드 구성 요소에 애노테이션을 붙일 수 있다.
예를 들어 JUnit 프레임워크를 사용한다면 테스트 메서드 앞에 @Test 애노테이션을 붙여야 한다.
애노테이션의 인자
애노테이션에 인자를 넘길 때는 일반 함수와 마찬가지로 괄호 안에 인자를 넣는다.
애노테이션의 인자로는 원시 타입의 값, 문자열, enum, 클래스 참조, 다른 애노테이션 클래스, 그리고 지금까지 말한 요소들로 이뤄진 배열이 들어갈 수 있다.
애노테이션의 인자는 컴파일 시점에 알 수 있어야 한다. 따라서 임의의 프로퍼티를 인자로 지정할 수는 없다. 프로퍼티를 애노테이션 인자로 사용하려면 그 앞에 const 변경자를 붙여야 한다. 컴파일러는 const 가 붙은 프로퍼티를 컴파일 시점 상수로 취급한다.
애노테이션의 인자를 지정하는 문법은 아래와 같다.
- 클래스를 애노테이션 인자로 지정할 때는
@MyAnnotation (MyClass:class)처럼::class를 클래스 이름 뒤에 넣어야 한다. - 다른 애노테이션을 인자로 지정할 때는 인자로 들어가는 애노테이션의 이름 앞에
@를 넣지 않아야 한다. - 배열을 인자로 지정하려면
RequestMapping(path = arrayOf("/foo", "/bar"))처럼arrayOf함수를 사용한다.
2. 애노테이션 대상
코틀린 소스코드에서 한 선언을 컴파일한 결과가 여러 자바 선언과 대응하는 경우가 자주 있다. 그리고 이때 코틀린 선언과 대응하는 여러 자바 선언에 각각 애노테이션을 붙여야 할 때가 있다.
예를 들어 코틀린 프로퍼티는 기본적으로 자바 필드와 게터 메서드 선언과 대응한다.
프로퍼티가 변경 가능하면 세터에 대응하는 자바 세터 메서드와 세터 파라미터가 추가된다. 게다가 주 생성자에서 프로퍼티를 선언하면 이런 접근자 메서드와 파라미터 외에 자바 생성자 파라미터와도 대응이 된다.
따라서 애노테이션을 붙일 때 이런 요소 중 어떤 요소에 애노테이션을 붙일지 표시할 필요가 있다.
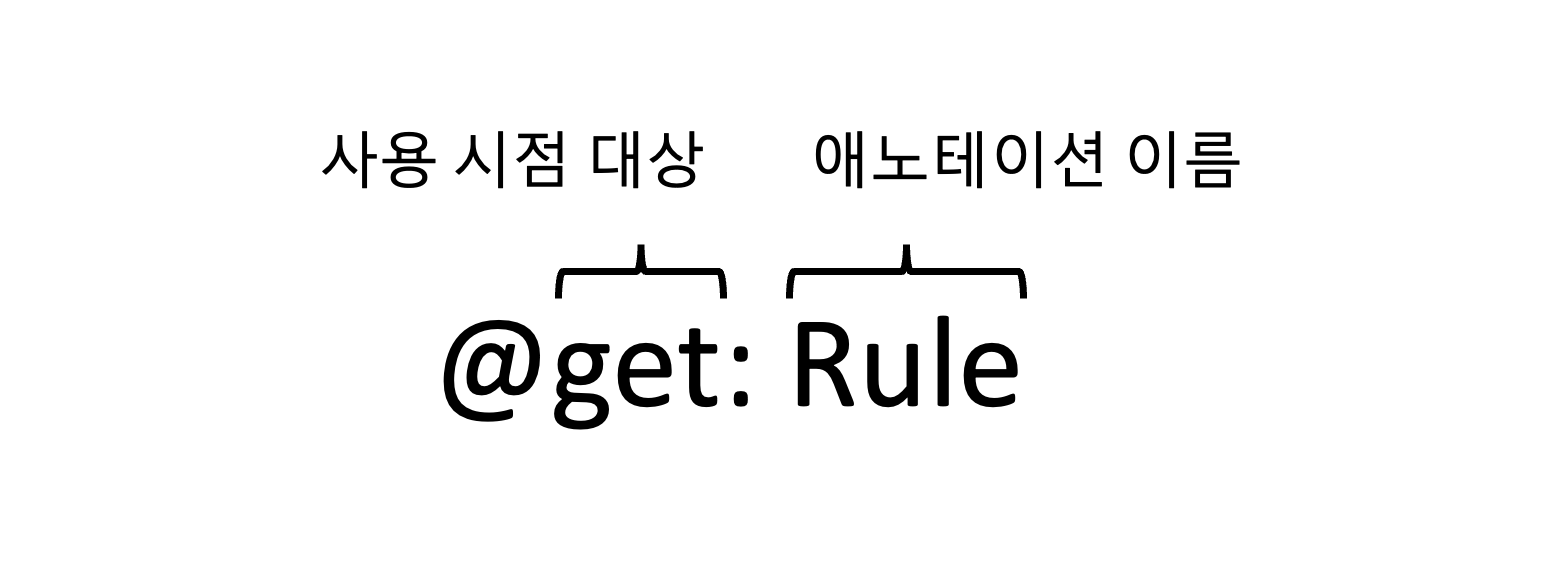
사용 시점 대상 선언으로 애노테이션을 붙일 요소를 정할 수 있다.
사용 시점 대상은@기호와 애노테이션 이름 사이에 붙으며, 애노테이션 이름과는:으로 분리된다.
제이유닛에서는 각 테스트 메서드 앞에 그 메서드를 실행하기 위한 규칙을 지정할 수 있다.
예를 들어 TemporaryFolder 라는 규칙을 사용하면 메서드가 끝아면 삭제될 임시 파일과 폴더를 만들 수 있다.
규칙을 지정하려면 public 필드나 메서드 앞에 @Rule 을 붙여야 한다.
하지만 코틀린 테스트 클래스의 folder 라는 프로퍼티 앞에 @Rule 을 붙이면 The @Rule 'folder' must be public 이라는 제이유닛 예외가 발생한다. @Rule 은 필드에 적용되지만 코틀린의 필드는 기본적으로 비공개이기 때문에 이런 예외가 생긴다.
@Rule 애노테이션을 정확한 대상에 적용하려면 @get: Rule 을 사용해야 한다.
자바에 선언된 애노테이션을 사용해 프로퍼티에 애노테이션을 붙이는 경우 기본적으로 프로퍼티의 필드에 그 애노테이션이 붙는다.하지만 코틀린으로 애노테이션을 선언하면 프로퍼티에 직접 적용할 수 있는 애노테이션을 만들 수 있다.
사용 지점 대상을 지정할 때 지원하는 대상 목록은 아래와 같다.
property프로퍼티 전체. 자바에서 선언된 애노테이션에는 이 사용 지점 대상을 사용할 수 없다.field프로퍼티에 의해 생성되는 (뒷받침하는) 필드get프로퍼티 게터set프로퍼티 세터receiver확장 함수나 프로퍼티의 수신 객체 파라미터param생성자 파라미터setparam세터 파라미터delegate위임 프로퍼티의 위임 인스턴스를 담아둔 필드file파일 안에 선언된 최상위 함수와 프로퍼티를 담아두는 클래스
file 대상을 사용하는 애노테이션은 package 선언 앞에서 파일의 최상위 수준에만 적용할 수 있다.
자바와 달리 코틀린에서는 애노테이션 인자로 클래스나 함수 선언이나 타입 외에 임의의 식을 허용한다.
가장 흔히 쓰이는 예로는 컴파일러 경고를 무시하기 위한 @Suppress 애노테이션이 있다.
3. 애노테이션을 활용한 JSON 직렬화 제어
애노테이션을 사용하는 고전적인 예제로 객체 직렬화 제어를 들 수 있다.
직렬화(serialization)는 객체를 저장장치에 저장하거나 네트워크를 통해 전송하기 위해 텍스트나 이진 형식으로 변환하는 것이다.
반대과정인 역직렬화(deserialization)는 텍스트나 이진 형식으로 저장된 데이터로부터 원래의 객체를 만들어낸다.
직렬화에 자주 쓰이는 형식에는 JSON이 있다. 자바와 JSON을 변환할 때 자주 쓰이는 라이브러리로는 Jackson과 GSON이 있다. 다른 자바 라이브러리와 마찬가지로 이들도 코틀린과 완전히 호환된다.
지금부터는 제이키드 라이브러리를 통해 JSON의 직렬화에 대해 알아보도록 하겠다.
아래와 같이 Person 의 인스턴스를 serialize 함수에 전달하면 JSON 표현이 담긴 문자열을 돌려받는다.
data class Person(val name: String, val age: Int)
>>> val person = Person("Alice", 29)
>>> println(serialize(person))
{"age": 29, "name": "Alice"}객체 인스턴스의 JSON 표현은 키/값 쌍으로 이뤄진 객체를 표현하며, 각 키/값 쌍은 인스턴스의 프로퍼티 이름과 값을 의미한다.
JSON 표현을 다시 객체로 만들려면 deserialize 함수를 호출한다.
>>> val json = """{"name": "Alice", "age": 29}"""
>>> println(deserialize<Person>(json))
Person(name=Alice, age=29)JSON에는 객체의 타입이 저장되지 않기 때문에 JSON 데이터로부터 인스턴스를 만들려면 타입 인자로 클래스를 명시해야 한다. 여기서는 Person 클래스를 타입 인자로 넘겼다.
애노테이션을 활용해 객체를 직렬화하거나 역직렬화하는 방법을 제어할 수 있다.
객체를 JSON으로 직렬화할 때 제이키드 라이브러리는 기본적으로 모든 프로퍼티를 직렬화하면 프로퍼티 이름을 키로 사용한다. 애노테이션을 사용하면 이런 동작을 변경할 수 있다.
@JsonExclude애노테이션을 사용하면 직렬화나 역직렬화 시 그 프로퍼티를 무시할 수 있다.@JsonName애노테이션을 사용하면 프로퍼티를 표현하는 키/값 쌍의 키로 프로퍼티 이름 대신 애노테이션이 지정한 이름을 쓰게 할 수 있다.
data class Person(
@JsonName("alias") val firstName: String,
@JsonExclude val age: Int? = null
)위 예제를 보면 firstName 프로퍼티를 JSON으로 저장할 때 사용하는 키를 변경하기 위해 @JsonName 애노테이션을 사용하고, age 프로퍼티를 직렬화나 역직렬화에 사용하지 않기 위해 @JsonExclude 애노테이션을 사용한다.
직렬화 대상에서 제외할 age 프로퍼티에는 반드시 디폴트 값을 지정해야 한다. 디폴트 값을 지정하지 않으면 역직렬화 시 Person 의 인스턴스를 새로 만들 수 없다.
4. 애노테이션 선언
@JsonExclude 애노테이션은 아무 파라미터도 없는 가장 단순한 애노테이션이다.
annotation class JsonExclude이 애노테이션 선언 구문은 일반 클래스 선언처럼 보이지만, class 키워드 앞에 annotation 이라는 변경자가 붙어 있는 것을 볼 수 있다.
애노테이션 클래스는 오직 선언이나 식과 관련있는 메타데이터의 구조를 정의하기 때문에 내부에 아무 코드도 들어있을 수 없다.
따라서 컴파일러는 애노테이션 클래스에서 본문을 정의하지 못하게 막는다.
파라미터가 있는 애노테이션을 정의하려면 애노테이션 클래스의 주 생성자에 파라미터를 선언해야 한다.
annotation class JsonName(val name: String)일반 클래스의 주 생성자 구문을 똑같이 사용하나, 애노테이션 클래스에서는 모든 파라미터 앞에 val 을 붙여야 한다.
자바와 달리 코틀린의 애노테이션 적용 문법은 일반적인 생성자 호출과 같다. 따라서 인자의 이름을 명시하기 위해 이름 붙인 인자 구문을 사용할 수도 있고, 이름을 생략할 수도 있다.
5. 메타애노테이션: 애노테이션을 처리하는 방법 제어
애노테이션 클래스에 적용할 수 있는 애노테이션을 메타애노테이션이라고 부른다.
표준 라이브러리에는 몇 가지 메타애노테이션이 있으며, 그런 메타애노테이션들은 컴파일러가 애노테이션을 처리하는 방법을 제어한다.
프레임워크 중에도 메타애노테이션을 제공하는 것이 있는데, 여러 의존관계 주입 라이브러리들이 메타애노테이션을 사용해 주입 가능한 타입이 동일한 여러 객체를 식별한다.
표준 라이브러리에 있는 메타애노테이션 중 가장 흔히 쓰이는 메타애노테이션은 @Target 이다.
@Target(AnnotationTarget.PROPERTY)
annotation class JsonExclude@Target 메타애노테이션은 애노테이션을 적용할 수 있는 요소의 유형을 지정한다.
애노테이션 클래스에 대해 구체적인 @Target 을 지정하지 않으면 모든 선언에 적용할 수 있는 애노테이션이 된다.
애노테이션이 붙을 수 있는 대상이 정의된 enum은 AnnotationTarget 이다. 그 안에는 클래스, 파일, 프로퍼티, 프로퍼티 접근자, 타입, 식 등에 대한 이넘 정의가 들어있다.
메타애노테이션을 직접 만들어야 한다면 ANNOTATION_CLASS 를 대상으로 지정하면 된다.
@Target(AnnotationTarget.ANNOTATION_CLASS)
annotation class BindingAnnotation
@BindingAnnotation
annotation class MyBinding6. 애노테이션 파라미터로 클래스 사용
지금까지는 정적인 데이터를 인자로 유지하는 애노테이션을 정의하는 방법을 살펴봤다. 하지만 어떤 클래스를 선언 메타데이터로 참조할 수 있는 기능이 필요할 때도 있다.
클래스를 참조 파라미터로 하는 애노테이션 클래스를 선언하면 그런 기능을 사용할 수 있다.
제이키드 라이브러리에 있는 @DeserializeInterface 는 인터페이스 타입인 프로퍼티에 대한 역직렬화를 제어할 때 쓰는 애노테이션이다.
이 때 역직렬화를 사용할 클래스를 지정하기 위해 애노테이션의 인자로 CompanyImpl::class 를 넘길 수 있다. 일반적으로 클래스를 가리키려면 클래스 이름 뒤에 ::class 키워드를 붙여야 한다.
이제 @DeserializeInterface(CompanyImpl::class) 처럼 클래스 참조를 인자로 받는 애노테이션을 어떻게 정의하는지 살펴보자.
annotation class DeserializeInterface(val targetClass: KClass<out Any>)코틀린 클래스에 대한 참조를 저장할 때 KClass 을 사용한다. KClass 의 타입 파라미터는 이 KClass 의 인스턴스가 가리키는 코틀린 타입을 지정한다.
예를 들어 CompanyImpl::class 의 타입은 KClass<CompanyImpl> 이며, 이 타입은 방금 살펴본 DeserializeInterface 의 파라미터 타입인 KClass<out Any> 의 하위 타입이다.
KClass 의 타입 파라미터를 쓸 때 out 변경자 없이 KClass<Any> 라고 쓰면 DeserializeInterface 에게 CompanyImpl::class 를 인자로 넘길 수 없고, 오직 Any::class 만 넘길 수 있다.
반면 out 키워드가 있으면 모든 코틀린 타입 T 에 대해 KClass<T> 가 KClass<out Any> 의 하위 타입이 된다. (공변성)
따라서 DeserializeInterface 의 인자로 Any 뿐 아니라 Any 를 확장하는 모든 클래스에 대한 참조를 전달할 수 있다.
7. 애노테이션 파라미터로 제네릭 클래스 받기
기본적으로 제이키드는 원시 타입이 아닌 프로퍼티를 중첩된 객체로 직렬화한다. 이런 기본 동작을 변경하고 싶으면 값을 직렬화하는 로직을 직접 제공하면 된다.
클래스를 인자로 받아야 하면 애노테이션 파라미터 타입에 KClass<out 허용할 클래스 이름> 을 쓴다.
제네릭 클래스를 인자로 받아야 하면 KClass<out 허용할 클래스 이름<*>> 처럼 허용할 클래스 이름 뒤에 스타 프로젝션을 덧붙인다. 이 애노테이션이 어떤 타입에 대해 쓰일 지 알 수 없기 때문이다.
리플렉션: 실행 시점에 코틀린 객체 내부 관찰
리플랙션은 실행 시점에 동적으로 객체의 프로퍼티와 메서드에 접근할 수 있게 해주는 방법이다.
보통 객체의 메서드나 프로퍼티에 접근할 때는 프로그램 소스코드 안에 구체적인 선언이 있는 메서드나 프로퍼티 이름을 사용하며, 컴파일러는 그런 이름이 실제로 가리키는 선언을 컴파일 시점에 정적으로 찾아내서 해당하는 선언이 실제 존재함을 보장한다.
하지만 타입과 관계없이 객체를 다뤄야 하거나 객체가 제공하는 메서드나 프로퍼티 이름을 오직 실행 시점에만 알 수 있는 경우가 있다.
JSON 직렬화 라이브러리가 바로 그런 경우다.
직렬화 라이브러리는 어떤 객체든 JSON으로 변환할 수 있어야 하고, 실행 시점이 되기 전까지는 라이브러리가 직렬화할 프로퍼티나 클래스에 대한 정보를 알 수 없다. 이런 경우 리플렉션을 사용해야 한다.
코틀린에서 리플렉션을 사용하려면 두 가지 서로 다른 리플렉션 API를 다뤄야 한다.
-
자바가
java.lan.reflect패키지를 통해 제공하는 표준 리플렉션
리플렉션을 사용하는 자바 라이브러리와 코틀린 코드가 완전히 호환된다는 의미다. -
코틀린이
kotlin.reflect패키지를 통해 제공하는 코틀린 리플렉션 API
이 API는 자바에는 없는 프로퍼티나 널이 될 수 있는 타입과 같은 코틀린 고유 개념에 대한 리플렉션을 제공한다. 하지만 현재 코틀린 리플렉션 API는 자바 리플렉션 API를 완전히 대체할 수 있는 복잡한 기능을 제공하지는 않는다.
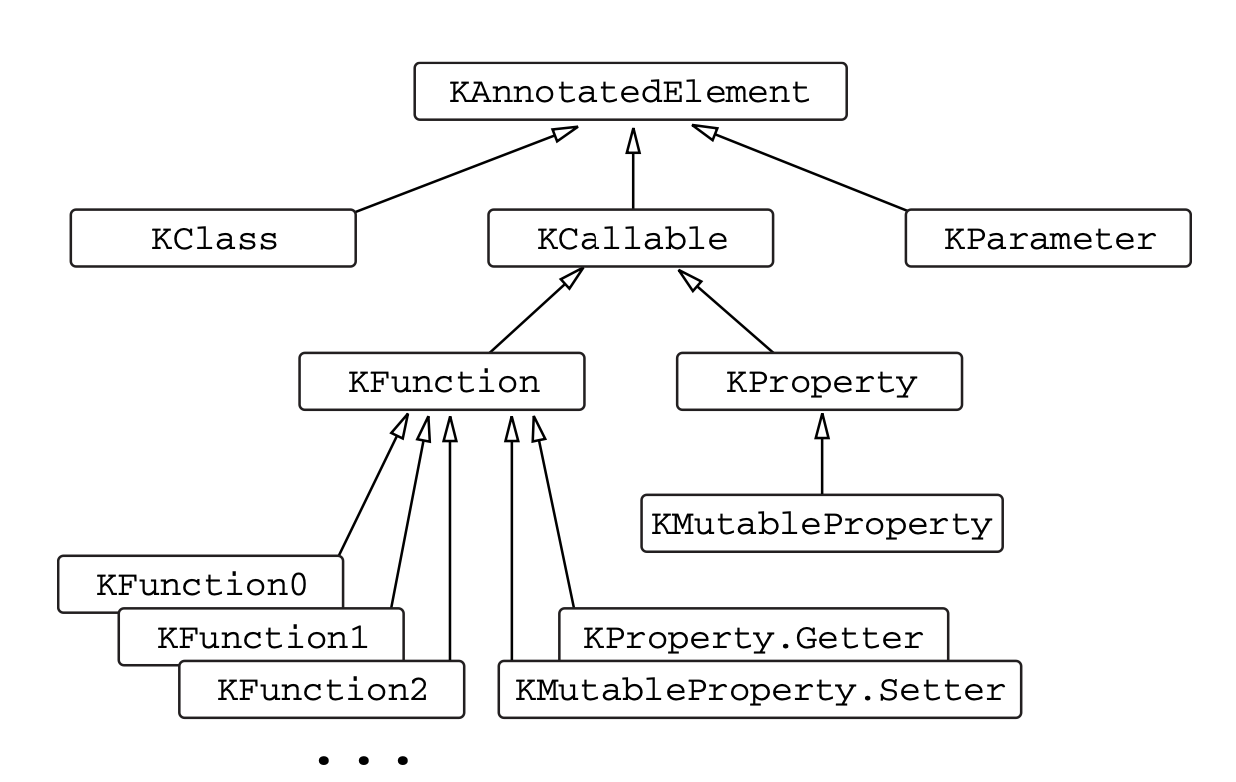
1. 코틀린 리플렉션 API: KClass, KCallable, KFunction, KProperty
java.lang.Class에 해당하는KClass를 사용하면 클래스 안에 있는 모든 선언을 열거하고 각 선언에 접근하거나 클래스의 상위 클래스를 얻는 등의 작업이 가능하다.
MyClass::class라는 식을 쓰면KClass의 인스턴스를 얻을 수 있다.- 실행 시점에 객체의 클래스를 얻으려면 먼저 객체의
javaClass프로퍼티를 사용해 객체의 자바 클래스를 얻어야 한다. javaClass는 자바의java.lang.Object.getClass()와 같다.- 일단 자바 클래스를 얻었으면,
.kotlin확장 프로퍼티를 통해 자바에서 코틀린 리플렉션 API로 옮겨올 수 있다.
KClass 에 대해 사용할 수 있는 다양한 기능은 실제로는 kotlin-reflect 라이브러리를 통해 제공하는 확장 함수다.
이런 확장 함수를 사용하려면 import kotlin.reflect.full.* 로 확장 함수 선언을 임포트해야 한다.
KClass의 모든 멤버 목록은KCallable인스턴스의 컬렉션으로,KCallable은 함수와 프로퍼티를 아우르는 공통 상위 인터페이스다.
KCallable안의call메서드를 사용하면 함수나 프로퍼티의 게터를 호출할 수 있다.call을 사용할 때는 함수 인자를vararg리스트로 전달한다.
::foo식의 값 타입은 리플렉션 API에 있는KFunction클래스의 인스턴스다.
- 함수 참조가 가리키는 함수
KFunction을 호출하려면KCallable.call메서드를 호출한다. KFunction의invoke메서드를 호출할 때는 인자 개수나 타입이 맞아 떨어지지 않으면 컴파일이 안 된다.
KProperty의call은 프로퍼티의 게터를 호출한다.
- 최상위 프로퍼티는
KProperty()인터페이스의 인스턴스로 표현되며,KProperty()안에는 인자가 없는get메서드가 있다. - 멤버 프로퍼티는
KProperty1인스턴스로 표현되며, 이는 제네릭 클래스다.
코틀린 리플렉션 API의 인터페이스 계층 구조 (출처: Kotlin in action)
2. 리플렉션을 사용한 객체 직렬화 구현
제이키드의 직렬화 함수 선언을 보면 다음과 같다.
fun serialize(obj: Any) : String이 함수는 객체를 받아서 그 객체에 대한 JSON 표현을 문자열로 돌려준다.
객체의 프로퍼티와 값을 직렬화하면서 StringBuilder 객체 뒤에 직렬화한 문자열을 추가한다.
private fun StringBuilder.serializeObject(x: Any){
append(..)
}이 append 호출을 더 간결하게 수행하기 위해 직렬화 기능을 StringBuilder 의 확장 함수로 구현한다. 이렇게 하면 별도로 StringBuilder 객체를 지정하지 않아도 append 메서드를 편하게 사용할 수 있다.
기본적으로 직렬화 함수는 객체의 모든 프로퍼티를 직렬화한다.
원시 타입이나 문자열, 컬렉션이 아닌 다른 타입인 프로퍼티는 중첩된 JSON 객체로 직렬화된다. 앞 절에서 설명한 것처럼 이런 동작을 애노테이션을 통해 변경할 수 있다.
3. 애노테이션을 활용한 직렬화 제어
앞에서 살펴본 애노테이션을 serializeObject 함수가 어떻게 처리하는지 살펴보자.
@JsonExclude
어떤 프로퍼티를 직렬화에서 제외하고 싶을 때 이 애노테이션을 쓸 수 있다.
KAnnotatedElement 인터페이스에는 annotations 프로퍼티가 있다. annotations 는 소스코드상에서 해당 요소에 적용된 모든 애노테이션 인스턴스의 컬렉션이다.
KProperty 는 KAnnotatedElement 를 확장하므로 property.annotations 를 통해 프로퍼티의 모든 애노테이션을 얻을 수 있다. 하지만 여기서는 모든 애노테이션을 사용하지 않는다. 단지 어떤 한 애노테이션을 찾기만 하면 된다. 이럴 때 findAnnotation 라는 함수가 쓸모 있다.
val properties = kClass.memberProperties
.filter { it.findAnnotation<JsonExclude>() == null }findAnnotation 함수는 인자로 전달받은 타입에 해당하는 애노테이션이 있으면 그 애노테이션을 반환한다. 이를 표준 라이브러리 함수인 filter 와 함께 사용하면 @JsonExclude 로 애노테이션된 프로퍼티를 없앨 수 있다.
@JsonName
이 경우에는 애노테이션의 존재 여부뿐 아니라 애노테이션에 전달한 인자도 알아야 한다.
@JsonName 의 인자는 프로퍼티를 직렬화해서 JSON에 넣을 때 사용할 이름이다. 다행히 findAnnotation 이 이 경우에도 도움이 된다.
val jsonNameAnn = prop.findAnnotation<JsonName>()
val propName = jsonNameAnn?.name ?: prop.name프로퍼티에 @JsonName 애노테이션이 없다면 JsonNameAnn 이 널이다.
이런 경우 여전히 prop.name 을 JSON의 프로퍼티 이름으로 사용할 수 있다. 프로퍼티에 애노테이션이 있다면 애노테이션이 지정하는 이름을 대신 사용한다.
@CustomSerializer
이 구현은
getSerializer라는 함수에 기초한다.
getSerializer는@CustomSerializer를 통해 등록한ValueSerializer인스턴스를 반환한다.
getSerializer 의 구현은 아래와 같다. getSerializer 가 주로 다루는 객체가 KProperty 인스턴스이기 때문에 KProperty 의 확장 함수로 정의한다.
fun KProperty<*>.getSerializer(): ValueSerializer<Any?>? {
val customSerializerAnn = findAnnotation<CustomSerializer>() ?: return null val serializerClass = customSerializerAnn.serializerClass
val valueSerializer = serializerClass.objectInstance
?: serializerClass.createInstance()
@Suppress("UNCHECKED_CAST")
return valueSerializer as ValueSerializer<Any?>
}getSerializer 는 findAnnotation 함수를 호출해서 @CustomSerializer 애노테이션이 있는지 찾는다. @CustomSerializer 애노테이션이 있다면 그 애노테이션의 serializerClass 가 직렬화기 인스턴스를 얻기 위해 사용해야 할 클래스다.
이 때 클래스와 객체는 모두 KClass 클래스로 표현된다. 다만 객체에는 object 선언에 의해 생성된 싱글턴을 가리키는 objectInstance 라는 프로퍼티가 있다는 것이 클래스와 다른 점이다.
예를 들어 DateSerializer 의 싱글턴 인스턴스가 들어있다. 따라서 그 싱글턴 인스턴스를 사용해 모든 긱체를 직렬화하면 되므로 createInstance 를 호출할 필요가 없다.
하지만 KClass 가 일반 클래스를 표현한다면 createInstance 를 호출해서 새 인스턴스를 만들어야 한다. createInstance 함수는 java.lang.Class.netInstance 와 비슷하다.
4. JSON 파싱과 객체 역직렬화
이제 제이키드 라이브러리의 나머지 절반인 역직렬화 로직에 대해 이야기해보자.
API는 직렬화와 마찬가지로 함수 하나로 이뤄져 있다.
inline fun <reified T: Any> deserialize(json: String) : T이 함수를 사용하는 방법은 아래와 같다.
data class Author(val name: String)
data class Book(val title: String, val author: Author)
>>> val json = """{"title": "Catch-22", "author": {"name": "J. Heller"}}"""
>>> val book = deserialize<Book>(json)
>>> println(book)
Book (title=Catch-22, author-Author(name=J. Heller))역직렬화할 객체의 타입을 실체화한 타입 파라미터로 deserialize 함수에 넘겨서 새로운 객체 인스턴스를 얻는다.
JSON 문자열 입력을 파싱하고, 리플렉션을 사용해 객체의 내부에 접근해서 새로운 객체와 프로퍼티를 생성하기 때문에 JSON을 역직렬화하는 것은 직렬화보다 더 어렵다.
제이키드의 JSON 역직렬화기는 흔히 쓰는 방법을 따라 3단계로 구현돼 있다.
첫 단계는 어휘 분석기로, 렉서라고 부른다.
어휘 분석기는 여러 문자로 이뤄진 입력 문자열을 토큰의 리스트로 변환한다.
토큰에는 2가지 종류가 있다.
- 문자 토큰은 문자를 표현하며 JSON 문법에서 중요한 의미가 있다.
- 값 토큰은 문자열, 수, 불리언 값, null 상수를 말한다.
두 번째 단계는 문법 분석기로, 파서라고 부른다.
파서는 토큰의 리스트를 구조화된 표현으로 변환한다.
제이키드에서 파서는 JSON의 상위 구조를 이해하고 토큰을 JSON에서 지원하는 의미 단위로 변환하는 일을 한다.
JsonObject 인터페이스는 현재 역직렬화하는 중인 객체나 배열을 추적한다. 파서는 현재 객체의 새로운 프로퍼티를 발견할 때마다 그 프로퍼티의 유형에 해당하는 JsonObject 의 함수를 호출한다.
마지막 단계는 파싱한 결과로 객체를 생성하는 역직렬화 컴포턴트다.
