
제네릭 타입 파라미터
제네릭스를 사용하면 타입 파라미터를 받는 타입을 정의할 수 있다. 제네릭 타입의 인스턴스를 만들려면 타입 파라미터를 구체적인 타입 인자로 치환해야 한다.
타입 파라미터를 사용하면 "이 변수는 리스트다" 라고 말하는 대신 정확하게 "이 변수는 문자열을 담는 리스트다"라고 말할 수 있다.
코틀린 컴파일러는 보통 타입과 마찬가지로 타입 인자도 추론할 수 있다.
val authors = listOf("Dmitry", "Svetlana")위 코드에서 listOf 에 전달된 두 값이 문자열이기 때문에 컴파일러는 여기서 생기는 리스트가 List<String> 임을 추론한다.
반면 빈 리스트를 만들어야 한다면 타입 인자를 추론할 근거가 없기 때문에 직접 타입 인자를 명시해야 한다.
- 리스트를 만들 때 변수의 타입을 지정하거나
val readers: MutableList<String> = mutableListOf()- 변수를 만드는 함수의 타입 인자를 지정할 수 있다.
val readers = mutalbeListOf<String>()위 두 선언은 동등하다.
1. 제네릭 함수와 프로퍼티
리스트를 다루는 함수를 작성한다면 어떤 특정 타입을 저장하는 리스트뿐 아니라 모든 리스트(즉, 제네릭 리스트)를 다룰 수 있는 함수를 원할 것이다. 이럴때 제네릭 함수를 작성해야 한다.
제네릭 함수를 호출할 때는 반드시 구체적 타입으로 타입 인자를 넘겨야 한다.
 출처: Kotlin in action
출처: Kotlin in action
함수의 타입 파라미터 T가 수신 객체와 반환 타입에 쓰인다. 수신 객체와 반환 타입 모두 List<T> 인 것을 알 수 있는데, 실제로는 대부분 컴파일러가 타입 인자를 추론할 수 있으므로 그럴 필요가 없다.
val authors = listOf("Dmitry", "Svetlana")
val readers = mutableListOf<String>(/* ... */)
fun <T> List<T>.filter(predicate: (T) -> Boolean): List<T>위 코드를 보면 람다 파라미터에 대해 자동으로 만들어진 변수 it 의 타입은 T 라는 제네릭 타입이다.
컴파일러는
filter가List<T>타입의 리스트에 대해 호출될 수 있다는 사실filter의 수신 객체인reader의 타입이List<String>이라는 사실
위 두가지를 통해 T 가 String 이라는 사실을 추론한다.
제네릭 함수를 정의할 때와 마찬가지 방법으로 제네릭 확장 프로퍼티 또한 선언할 수 있다.
val <T> List<T>.penultimate: T // 모든 리스트 타입에 이 제네릭 확장 프로퍼티를 사용할 수 있다.
get() = this[size - 2] // 이 호출에서 타입 파라미터 T는 Int로 추론된다.단, 확장 프로퍼티가 아닌 일반 프로퍼티는 타입 파라미터를 가질 수 없다.
클래스 프로퍼티에 여러 타입의 값을 저장할 수는 없으므로 제네릭한 일반 프로퍼티는 말이 되지 않는다.
2. 제네릭 클래스 선언
자바와 마찬가지로 코틀린에서도 타입 파라미터를 넣은 꺾쇠 기호 < > 를 클래스 또는 인터페이스 뒤에 붙이면 제네릭하게 만들 수 있다.
타입 파라미터를 이름 뒤에 붙이고 나면 클래스 본문 안에서 타입 파라미터를 다른 일반 타입처럼 사용할 수 있다.
interface List<T> { //List 인터페이스에 T라는 타입 파라미터를 정의한다.
operator fun get(index: Int): T .. 인터페이스 안에서 T를 일반 타입처럼 사용할 수 있다.
// ...
}제네릭 클래스를 확장하는 클래스를 정의하려면 기반 타입의 제네릭 파라미터에 대해 타입 인자를 지정해야 한다.
- 구체적인 타입을 넘길 수도 있고
- 타입 파라미터로 받은 타입을 넘길 수도 있다.
또한 아래와 같이 클래스가 자기 자신을 타입 인자로 참조할 수도 있다.
interface Comparable<T> {
fun compareTo(other: T): Int
}
class String : Comparable<String> {
override fun compareTo(other: String): Int = /* ... */3. 타입 파라미터 제약
타입 파라미터 제약은 클래스나 함수에 사용할 수 있는 타입 인자를 제한하는 기능이다.
예를 들어 리스트에 속한 모든 원소의 합을 구하는 sum 함수가 있다고 하자.
List<Int> 나 List<Double> 에는 이 함수를 적용할 수 있지만 List<String> 등에는 이 함수를 적용할 수 없다.
이 때 sum 함수가 타입 파라미터로 숫자 타입만을 허용하게 정의하면 이런 조건을 표현할 수 있다.
어떤 타입을 제네릭 타입의 타입 파라미터에 대한 상한(upper bound)로 지정하면 그 제네릭 타입을 인스턴스화할 때 사용하는 타입 인자는 반드시 그 상한 타입이거나 그 상한 타입의 하위 타입이어야 한다.
제약을 가하려면 타입 파라미터 이름 뒤에 콜론 : 을 표시하고 그 뒤에 상한 타입을 적으면 된다.
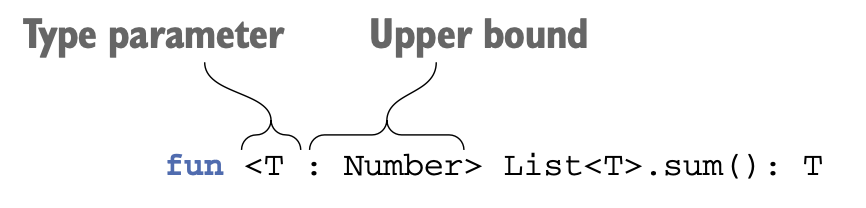 출처: Kotlin in action
출처: Kotlin in action
4. 타입 파라미터를 널이 될 수 없는 타입으로 한정
제네릭 클래스나 함수를 정의하고 그 타입을 인스턴스화할 때는 널이 될 수 있는 타입을 포함하는 어떤 타입으로 타입 인자를 지정해도 타입 파라미터를 치환할 수 있다.
기본적으로는 널이 될 수 있는 타입을 포함
아무런 상한을 정하지 않은 타입 파라미터는 결과적으로 Any? 를 상한으로 정한 파라미터와 같다.
널이 될 수 없는 타입만 받도록
만약 항상 널이 될 수 없는 타입만 타입 인자로 받게 만들려면 타입 파라미터에 제약을 가해야 한다. 널 가능성을 제외한 아무런 제약도 필요 없다면 Any? 대신 Any 를 상한으로 사용하면 된다.
실행 시 제네릭스의 동작: 소거된 타입 파라미터와 실체화된 파라미터
JVM의 제네릭스는 보통 타입 소거를 사용해 구현된다. 이는 실행 시점에 제네릭 클래스의 인스턴스에 타입 인자 정보가 들어있지 않다는 뜻이다.
이번 절에서는 코틀린 타입 소거가 실용적인 면에서 어떤 영향을 끼치는지 살펴보고 함수를 inline 으로 선언함으로써 이런 제약을 어떻게 우회할 수 있는지 살펴본다.
함수를
inline으로 만들면 타입 인자가 지워지지 않게 할 수 이쓴데, 이를 실체화라고 한다.
1. 실행 시점의 제네릭: 타입 검사와 캐스트
코틀린 제네릭 타입 인자 정보는 런타임에 지워진다.
이는 제네릭 클래스 인스턴스가 그 인스턴스를 생성할 때 쓰인 타입 인자에 대한 정보를 유지하지 않는다는 뜻이다.
예를 들어 List<String> 객체를 만들고 그 안에 문자열을 여럿 넣더라도 실행 시점에는 그 객체를 오직 List 로만 볼 수 있고, 그 List 객체가 어떤 타입의 원소를 저장하는지 실행 시점에는 알 수 없다.
 출처: Kotlin in action
출처: Kotlin in action
위 그림을 보면 컴파일러는 두 리스트를 서로 다른 타입으로 인식하지만 실행 시점에 그 둘은 완전히 같은 타입의 객체다.
그럼에도 불구하고 보통은 List<String> 에는 문자열만 들어있고 List<Int> 에는 정수만 들어있다고 가정할 수 있는데, 이는 컴파일러가 타입 인자를 알고 올바른 타입의 값만 각 리스트에 넣도록 보장해주기 때문이다.
다음으로 타입 소거로 인해 생기는 한계를 살펴보자.
타입 인자를 따로 저장하지 않기 때문에 실행 시점에 타입 인자를 검사할 수 없다.
예를 들어 어떤 리스트가 문자열로 이뤄진 리스트인지 다른 객체로 이뤄진 리스트인지를 실행 시점에 검사할 수 없다. 일반적으로 말하자면 is 검사에서 타입 인자로 지정한 타입을 검사할 수는 없다.
앞서 말한 것 처럼 코틀린에서는 타입 인자를 명시하지 않고 제네릭 타입을 사용할 수 없다. 그렇다면 어떤 값이 집합이나 맵이 아니라 리스트라는 사실을 어떻게 확인할 수 있을까?
바로 스타프로젝션을 사용하면 된다.
if (value is List<*>){ ... }타입 파라미터가 2개 이상이라면 모든 타입 파라미터에 * 를 포함시켜야 한다.
2. 실체화한 타입 파라미터를 사용한 함수 선언
앞에서 말한 것 처럼 코틀린 제네릭 타입의 타입 인자 정보는 실행 시점에 지워진다. 따라서 제네릭 클래스의 인스턴스가 있어도 그 인스턴스를 만들 때 사용한 타입 인자를 알아낼 수 없다.
제네릭 함수의 타입 인자도 마찬가지다. 제네릭 함수가 호출되어도 그 함수의 본문에서는 호출 시 쓰인 타입 인자를 알 수 없다.
다만, 이런 제약을 피할 수 있는 경우가 하나 있다.
인라인 함수의 타입 파라미터는 실체화되므로 실행 시점에 인라인 함수의 타입 인자를 알 수 있다.
8장에서 보았듯, 어떤 함수에 inline 키워드를 붙이면 컴파일러는 그 함수를 호출한 식을 모두 함수 본문으로 바꾼다. 함수가 람다를 인자로 사용하는 경우 그 함수를 인라인 함수로 만들면 람다 코드도 함께 인라이닝되고, 그에 따라 무명 클래스와 객체가 생성되지 않아서 성능이 더 좋아질 수 있다.
그렇다면 실체화한 타입 인자는 어떻게 작동할까?
컴파일러는 인라인 함수의 본문을 구현한 바이트코드를 그 함수가 호출되는 모든 지점에 삽입한다.
컴파일러는 실체화한 타입 인자를 사용해 인라인 함수를 호출하는 각 부분의 정확한 타입 인자를 알 수 있다. 따라서 컴파일러는 타입 인자로 쓰인 구체적인 클래스를 참조하는 바이트코드를 새성해 삽입할 수 있다.
또한 타입 파라미터가 아니라 구체적인 타입을 사용하므로 만들어진 바이트 코드는 실행 시점에 벌어지는 타입 소거의 영향을 받지 않는다.
성능과 인라인 함수
여기서 함수를 inline 으로 만드는 이유는 8장에서와 달리 성능 향상이 아니라 실체화한 타입 파라미터를 사용하기 위함이다.
성능을 좋게 하고 싶다면 인라인 함수의 크기를 계속 관찰해야 한다. 함수가 커지면 실체화한 타입에 의존하지 않는 부분을 별도의 일반 함수로 뽑아내는 편이 낫다.
3. 실체화한 타입 파라미터로 클래스 참조 대신
표준 자바 API인 ServiceLoader 를 사용해 서비스를 읽어 들이려면 다음 코드처럼 호출해야 한다.
val serviceImpl = ServiceLoader.load(Service::class.java)::class.java 구문은 코틀린 클래스에 대응하는 java.lang.Class 참조를 얻는 방법을 보여준다.
위 코드를 구체화한 타입 파라미터를 사용해 다시 작성하면 아래와 같다.
val serviceImpl = loadService<Service>()훨씬 짧아졌다!
여기서는 읽어 들일 서비스 클래스를 loadService 함수의 타입 인자로 지정한다. 클래스를 타입 인자로 지정하면 ::class.java 라고 쓰는 경우보다 훨씬 더 읽고 이해하기 쉽다.
안드로이드에서 액티비티를 표시하는 과정 역시 예로 들 수 있다.
액티비티의 클래스를java,lang.Class로 전달하는 대신 실체화한 타입 파라미터를 사용할 수 있다.
inline fun <reified T : Activity>
Context.startActivity() {
val intent = Intent(this, T::class.java)
startActivity(intent)
=
}
startActivity<DetailActivity>()4. 실체화한 타입 파라미터의 제약
실체화한 타입 파라미터는 유용한 도구지만 몇 가지 제약이 있다.
실체화한 타입 파라미터를 사용할 수 있는 경우
- 타입 검사와 캐스팅
- 10장에서 설명할 코틀린 리플렉션 API
- 코틀린 타입에 대응하는
java,lang.Class를 얻기 - 다른 함수를 호출할 때 타입 인자로 사용
실체화한 타입 파라미터를 사용할 때의 제약
- 타입 파라미터 클래스의 인스턴스 생성하기
- 타입 파라미터 클래스의 동반 객체 메서드 호출하기
- 실체화한 타입 파라미터를 요구하는 함수를 호출하면서 실체화하지 않은 타입 파라미터로 받은 타입을 타입 인자로 넘기기
- 클래스, 프로퍼티, 인라인 함수가 아닌 함수의 타입 파라미터를
reified로 지정, 즉 실체화한 타입 파라미터로 지정하기
여기서 마지막 제약으로 인해 한 가지 흥미로운 파급 효과가 생긴다.
실체화한 타입 파라미터를 인라인 함수에만 사용할 수 있으므로 실체화한 타입 파라미터를 사용하는 함수는 자신에게 전달되는 모든 람다와 함께 인라이닝된다.
람다 내부에서 타입 파라미터를 사용하는 방식에 따라서는 람다를 인라이닝할 수 없는 경우가 생기기도 하고 개발자들이 성능 문제로 람다를 인라이닝하고 싶지 않을 수도 있다.
이런 경우 8장에서 살펴본 noinline 변경자를 함수 타입 파라미터에 붙여서 인라이닝을 금지할 수 있다.
변성: 제네릭과 하위 타입
변성은
List<String>과List<Any>와 같이 기저 타입이 같고 타입 인자가 다른 여러 타입이 서로 어떤 관계가 있는지 설명하는 개념이다.
변성을 잘 활용하면 사용에 불편하지 않으면서 타입 안전성을 보장하는 API를 만들 수 있다.
1. 변성이 있는 이유: 인자를 함수에 넘기기
List<Any> 타입의 파라미터를 받는 함수에 List<String> 을 넘기면 안전할까?
String 클래스는 Any 를 확장하므로 Any 타입 값을 파라미터로 받는 함수에 String 값을 넘겨도 절대로 안전하다.
하지만 Any 와 String 이 List 인터페이스의 타입 인자로 들어가는 경우 그렇게 자신 있게 안전성을 말할 수 없다.
코틀린에서는 리스트의 변경 가능성에 따라 적절한 인터페이스를 선택하면 안전하지 못한 함수 호출을 막을 수 있다.
함수가 읽기 전용 리스트를 받는다면 더 구체적인 타입의 원소를 갖는 리스트를 그 함수에 넘길 수 있다. 하지만 리스트가 변경 가능하다면 그럴 수 없다.
2. 클래스, 타입, 하위 타입
6장에서 변수의 타입이 그 변수에 담을 수 있는 값의 집합을 지정한다고 설명했다. 지금까지 이 책에서는 보통 타입과 클래스라는 용어를 혼용해왔는데, 실제로 그 둘은 같지 않다.
제네릭 클래스가 아닌 클래스에서는 클래스 이름을 바로 타입으로 쓸 수 있다.
제네릭 클래스에서는 상황이 더 복잡하다. 올바른 타입을 얻으려면 제네릭 타입의 타입 파라미터를 구체적인 타입 인자로 바꿔줘야 한다.
이 때 타입 사이의 관계를 논하기 위해 하위 타입이라는 개념을 잘 알아야 한다.
어떤 타입 A의 값이 필요한 모든 장소에 어떤 타입 B의 값을 넣어도 아무 문제가 없다면 타입 B는 타입 A의 하위 타입이다.
예를 들어 Int 는 Number 의 하위 타입이지만 String 의 하위 타입은 아니다.
상위 타입은 하위 타입의 반대로, A 타입이 B 타입의 하위 타입이라면 B는 A의 상위 타입이다.
한 타입이 다른 타입의 하위 타입인지가 왜 중요할까?
컴파일러는 변수 대입이나 함수 인자 전달 시 하위 타입 검사를 매번 수행하여 어떤 값의 타입이 변수 타입의 하위 타입인 경우에만 값을 변수에 대입하게 허용하기 때문이다.
간단한 경우, 하위 타입은 하위 클래스와 근본적으로 같다.
제네릭 타입에 대해 이야기할 때 특히 하위 클래스와 하위 타입의 차이가 중요해진다.
앞에서 살펴본 List<Any> 타입의 파라미터를 받는 함수에 List<String> 을 넘기면 안전할까? 라는 질문을 하위 타입 관계를 써서 다시 쓰면 List<String> 은 List<Any> 의 하위 타입인가?이다.
이 경우 앞 문장은 참이 아니므로 하위 타입이 아니라고 할 수 있다.
제네릭 타입을 인스턴스화할 때 타입 인자로 서로 다른 타입이 들어가면 인스턴스 타입 사이의 하위 타입 관계가 성립하지 않으면 그 제네릭 타입을 무공변이라고 말한다.
또한 A가 B의 하위 타입이면 List<A> 는 List<B> 의 하위타입이다. 그런 클래스나 인터페이스를 공변적이라고 말한다.
3. 공변성: 하위 타입 관계를 유지
A가 B의 하위 타입일 때
Producer<A>가Producer<B>의 하위타입이면Producer는 공변적이다. 이를 하위 타입 관계가 유지된다고 말한다.
코틀린에서 제네릭 클래스가 타입 파라미터에 대해 공변적임을 표시하려면 타입 파라미터 이름 앞에 out 을 넣어야 한다.
interface Producer<out T> {
fun produce(): T
}클래스의 타입 파라미터를 공변적으로 만들면 함수 정의에 사용한 파라미터 타입과 타입 인자의 타입이 정확히 일치하지 않더라도 그 클래스의 인스턴스를 함수 인자나 반환 값으로 사용할 수 있다.
모든 클래스를 공변적으로 만들 수는 없다. 공변적으로 만들면 안전하지 못한 클래스도 있기 때문이다.
타입 파라미터를 공변적으로 지정하면 클래스 내부에서 그 파라미터를 사용하는 방법을 제한한다.
타입 안전성을 보장하기 위해 공변적 파라미터는 항상 아웃위치에 있어야 한다.
이는 클래스가 T 타입의 값을 생산할 수는 있지만 T 타입의 값을 소비할 수는 없다는 뜻이다.
클래스 멤버를 선언할 때 타입 파라미터를 사용할 수 있는 지점은 모두 인과 아웃 위치로 나뉜다.
T 라는 타입 파라미터를 선언하고 T 를 사용하는 함수가 멤버로 있는 클래스를 생각해보자.
-
T가 함수의 반환 타입에 쓰인다면T는 아웃 위치에 있다.
이 함수는T타입의 값을 생산한다. -
T가 함수의 파라미터 타입에 쓰인다면T는 인 위치에 있다.
이 함수는T타입의 값을 소비한다.
즉, 타입 파라미터 T 에 붙은 out 키워드는 다음 두 가지를 의미한다.
- 공변성: 하위 타입 관계가 유지된다.
- 사용 제한:
T를 아웃 위치에서만 사용할 수 있다.
4. 반공변성: 뒤집힌 하위 타입 관계
반공변 클래스의 하위 타입 관계는 공변 클래스의 경우와 반대다.
타입
B가 타입A의 하위 타입인 경우Consumer<A>가Consumer<B>의 하위 타입인 광계가 성립하면 제네릭 클래스Consumer<T>는 타입 인자T에 대해 반공변이다.
다음 표는 여러 가지 선택할 수 있는 변성에 대해 요약한 것이다.
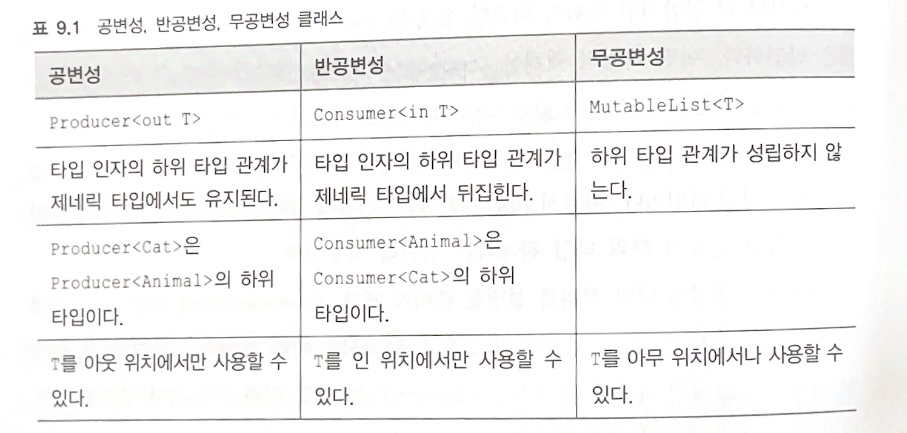 출처: Kotlin in action
출처: Kotlin in action
5. 사용 지점 변성: 타입이 언급되는 지점에서 변성 지정
클래스를 선언하면서 변성을 지정하면 그 클래스를 사용하는 모든 장소에서 변성 지정자가 영향을 끼치므로 편리하다. 이런 방식을 선언 지점 변성이라 부른다.
자바에서는 타입 파라미터가 있는 타입을 사용할 때마다 해당 타입 파라미터를 하위 타입이나 상위 타입 중 어떤 타입으로 대치할 수 있는지 명시해야 한다. 이런 방식을 사용 지점 변성이라 부른다.
코틀린도 사용 지점 변성을 지원한다. (이는 자바의 한정 와일드 카드와 똑같다.)
따라서 클래스 안에서 어떤 타입 파라미터가 공변적이거나 반공변적인지 선언할 수 없는 경우에도 특정 타입 파라미터가 나타나는 지점에서 변성을 정할 수 있다.
코틀린에서는 이를 우아하게 표현할 수 있는 방법이 있다.
함수 구현이 아웃 혹은 인 위치에 있는 타입 파라미터를 사용하는 메서드만 호출한다면 그런 정보를 바탕으로 함수 정의 시 타입 파라미터에 변성 변경자를 추가할 수 있다.
fun <T> copyData(source: MutableList<out T>,
destination: MutableList<T>) {
for (item in source) {
destination.add(item)
} }
You can add the “out” keyword to the type usage: no methods with T in the “in” position are used.타입 선언에서 타입 파라미터를 사용하는 위치라면 어디에나 변성 변경자를 붙일 수 있다.
따라서 파라미터 타입, 로컬 변수 타입, 함수 반환 타입 등에 타입 파라미터가 쓰이는 경우 in 이나 out 변경자를 붙일 수 있다.
이때 타입 프로젝션이 일어난다.
즉, source 를 일반적인 MutableList 가 아니라 MutableList 를 프로젝션을 한 타입으로 만든다.
사용 지점 변성을 사용하면 타입 인자로 사용할 수 있는 타입의 범위가 넓어진다.
6. 스타 프로젝션: 타입 인자 대신 * 사용
9장 앞부분에서 타입 검사와 캐스트에 대해 설명할 때 제네릭 타입 인자 정보가 없음을 표현하기 위해 스타 프로젝션 을 사용한다고 말했다.
MutableList<*>는 MutableList<Any?>와 같지 않다.
MutableList<Any?>는 모든 타입의 원소를 담을 수 있다는 사실을 알 수 있는 리스트인 반면, MutableList<*>는 어떤 정해진 구체적인 타입의 원소만을 담는 리스트지만 그 원소의 타입을 정확히 모른다는 사실을 표현한다.
>>> val list: MutableList<Any?> = mutableListOf('a', 1, "qwe")
>>> val chars = mutableListOf('a', 'b', 'c')
>>> val unknownElements: MutableList<*> = // MutableList<*>는 MutableList<Any?>와 같지 않다.
... if (Random().nextBoolean()) list else chars
>>> unknownElements.add(42) // 컴파일러는 이 메소드 호출을 금지한다.
Error: Out-projected type 'MutableList<*>' prohibits
the use of 'fun add(element: E): Boolean'
>>> println(unknownElements.first()) // 원소를 가져와도 안전하다. first()는 Any? 타입의 원소를 반환한다.
a타입 파라미터를 시그니처에서 전혀 언급하지 않거나 데이터를 읽기는 하지만 그 타입에는 관심이 없는 경우와 같이 타입 인자 정보가 중요하지 않을 때도 스타 프로젝션 구문을 사용할 수 있다.
fun printFirst(list: List<*>) { // 모든 리스트를 인자로 받을 수 있다.
if (list.isNotEmpty()) { // isNotEmpty()에서는 제네릭 타입 파라미터를 사용하지 않는다.
println(list.first()) // first()는 이제 Any?를 반환하지만 여기서는 그 타입만으로 충분하다.
}
}
>>> printFirst(listOf("Svetlana", "Dmitry"))
Svetlana스타 프로젝션을 쓰는 쪽에 더 간결하지만 제네릭 타입 파라미터가 어떤 타입인지 굳이 알 필요가 없을 때만 스타 프로젝션을 사용할 수 있다.
스타 프로젝션을 사용할 때는 값을 만들어내는 메서드만 호출할 수 있고 그 값의 타입에 대해서는 신경을 쓰지 말아야 한다.
