데이터베이스의 용량과 트래픽이 많아지면 단일 데이터베이스로 서비스를 관리하는데 어려움이 생깁니다.
이 경우 다음과 같은 데이터 분산처리를 고려해볼 수 있습니다.
Replication
쓰기 작업보다 읽기 작업이 월등히 높은 데이터베이스의 경우 Replicaiton 을 통해 트래픽 이슈를 해결할 수 있습니다.
Replication 이란 데이터베이스를 복제하여 다른 데이터베이스에 비동기로 저장하는 방법을 의미합니다. 쓰기 작업은 기존의 데이터베이스 (Master)에서만 하도록 하고 읽기 작업은 복제된 데이터베이스(Slave) 에서 하도록 하여 트래픽을 분신시킬 수 있습니다.
만약 마스터 데이터베이스에 문제가 발생하는 경우 복제 데이터베이스가 마스터 데이터베이스로 승격하여 쓰기작업을 수행하게 됩니다.
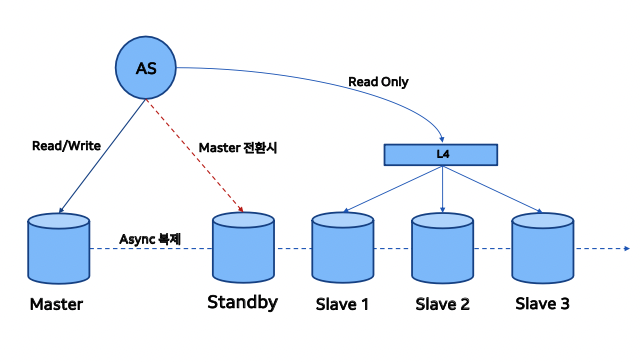
대부분의 데이터베이스가 Replication 기능을 지원합니다.
MySql 의 경우 Master Binary Log 에 기록된 모든 변경사항을 Slave 에 전송하는 방식으로 복제 됩니다.
Replicaiton 을 사용하는 경우 Master, Slave 의 DB 버전을 동일하게 해주는게 좋고 만약 다르다면 Slave DB 의 버전이 더 높아야 합니다. 또 Replicaiton 을 가동할 때는 항상 Master -> Slave 순으로 해야 합니다.
Sharding
데이터 베이스를 여러 개 만들어 분산 저장하는 기술로 읽기/쓰기 트래픽이 모두 많은 경우에 사용할 수 있습니다. Sharding 에서 가장 중요한 것은 어떤 키를 기준으로 나누는가 입니다. 이를 Shard Key 라고 합니다.
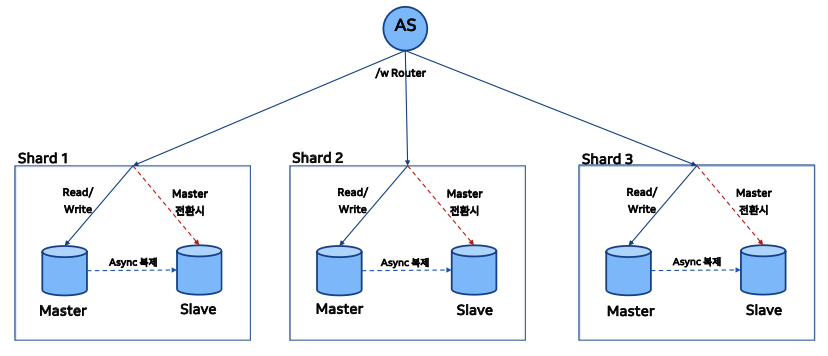
Sharding 을 사용하는 경우 Auto-Increment 로 id 를 부여하는 것은 적절하지 않을 수 있습니다.
데이터베이스마다 중복된 아이디가 생성되기 때문입니다.
이 경우 Twitter Snowflake 알고리즘을 주로 사용합니다. Twitter Snowflake 는 분산 시스템 환경에서 고유한 id 를 생성하기 위한 알고리즘으로 세계적으로 유일한 64비트 정수형 id 를 빠르게 생성할 수 있습니다.
(같은 밀리초에 4096개 이상의 ID 생성이 가능합니다.)
- 1비트 : 예약비트로 항상 0으로 설정
- 41비트 : timestamp
- 10비트 : 머신 아이디 (Data Center + Server)
- 12비트 : 시퀀스 번호 동일 밀리초 내에서 생성된 id 의 순차 증가 번호
만약 두 대의 샤드 DB를 사용하는 경우 샤드키에 따라 특정 샤드 DB에 접근하도록 해야 합니다.
보통 아이디의 비트 수나 해시값을 기반으로 분기하는 방식을 사용합니다.
@Component
public class SnowflakeGenerator {
@Value("${snowflake.dataCenterId}")
private long datacenterId;
@Value("${snowflake.workerId}")
private long workerId;
private final long epoch = 1288834974657L; // 기준 시점 (2010-11-04 01:42:54 UTC)
private final long datacenterIdBits = 5L;
private final long workerIdBits = 5L;
private final long sequenceBits = 12L;
private final long maxDatacenterId = ~(-1L << datacenterIdBits); // 최대 31
private final long maxWorkerId = ~(-1L << workerIdBits); // 최대 31
private final long sequenceMask = ~(-1L << sequenceBits); // 최대 4095
private long sequence = 0L;
private long lastTimestamp = -1L;
public synchronized long nextId() {
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException("Invalid Data Center ID");
}
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("Invalid Worker ID");
}
long currentTimestamp = System.currentTimeMillis();
if (currentTimestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate ID");
}
if (currentTimestamp == lastTimestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
currentTimestamp = waitNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
lastTimestamp = currentTimestamp;
return ((currentTimestamp - epoch) << 22) | (datacenterId << 17) | (workerId << 12)
| sequence;
}
private long waitNextMillis(long lastTimestamp) {
long timestamp = System.currentTimeMillis();
while (timestamp <= lastTimestamp) {
timestamp = System.currentTimeMillis();
}
return timestamp;
}
}@Component
public class ShardKeyUtilImpl implements ShardKeyUtil {
@Override
public boolean isShard1(Long snowflakeId) {
long timestamp = (snowflakeId >> 22) & 0x1FFFFFFFFFFL; // timestamp (41 비트)
long workerId = (snowflakeId >> 12) & 0x1F; // workerId (5 비트)
return (timestamp ^ workerId) % 2 == 0;
}
}
Partition
테이블 기준으로 샤딩 하는것을 의미합니다.
파티셔닝이 된 쿼리를 조회할 땐 파티션 키를 조회 조건에 추가해야 합니다.
그러면 해당 파티션만 조회를 하도록 합니다.
CREATE TABLE USERS (
USER_ID INT NOT NULL,
REG_AT DATETIME NOT NULL,
USER_NAME VARCHAR2 (50)
PRIMARY KEY(USER_ID, REG_AT)
) PARTITION BY RANGE (TO_DAYS(REG_AT)) (
-- PARTITION 파티산명 VALUES LESS THAN 조건
PARTITION P_202206 VALUES LESS THAN (TO_DAYS('2022-07-01')),
PARTITION P_202207 VALUES LESS THAN (TO_DAYS('2022-08-01')),
PARTITION P_202208 VALUES LESS THAN (TO_DAYS('2022-09-01')),
PARTITION P_maxvalue VALUES LESS THAN MAXVALUE
);CREATE TABLE USERS (
USER_ID INT NOT NULL,
REG_AT DATETIME NOT NULL,
USER_NAME VARCHAR2 (50),
TEAM_NAME VARCHAR2 (50)
PRIMARY KEY(USER_ID, TEAM_NAME)
)
PARTITION BY LIST COLUMNS(TEAM_NAME) (
PARTITION p0 VALUES IN ('HR', 'Finance'),
PARTITION p1 VALUES IN ('Engineering', 'Marketing'),
PARTITION p2 VALUES IN ('Sales')
);ALTER TABLE USERS
ADD PARTITION (PARTITION p4 VALUES IN ('newTeam'));
ALTER TABLE USERS
DROP PARTITION p4;