JOINS : 두 개 이상의 테이블을 특정 KEY를 기준으로 결합하는 것
FROM 절에서 사용.
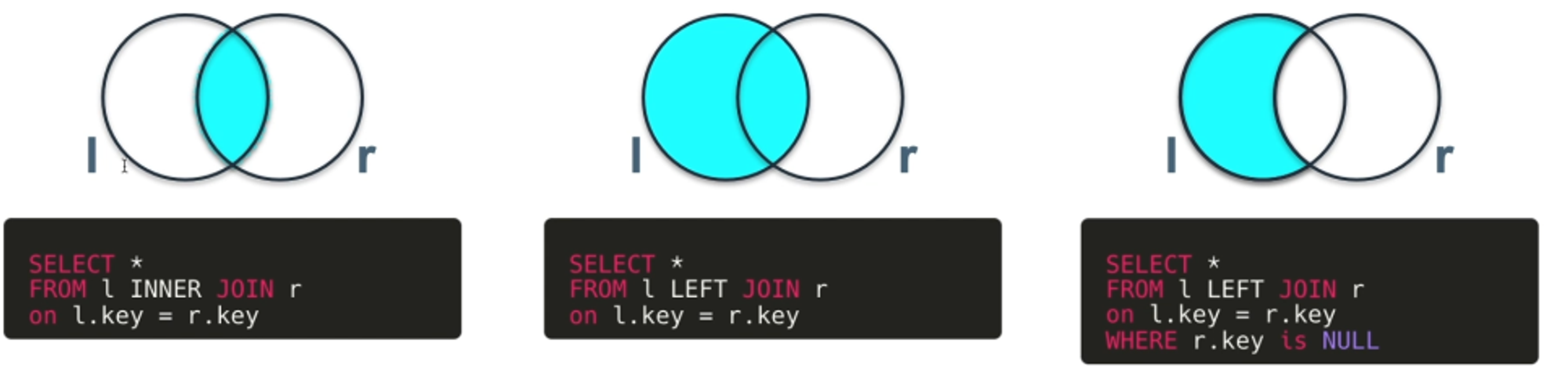
INNER JOIN
두 테이블에서 값이 일치하는 행 만(교집합) 결과에 반환한다.
(예시)
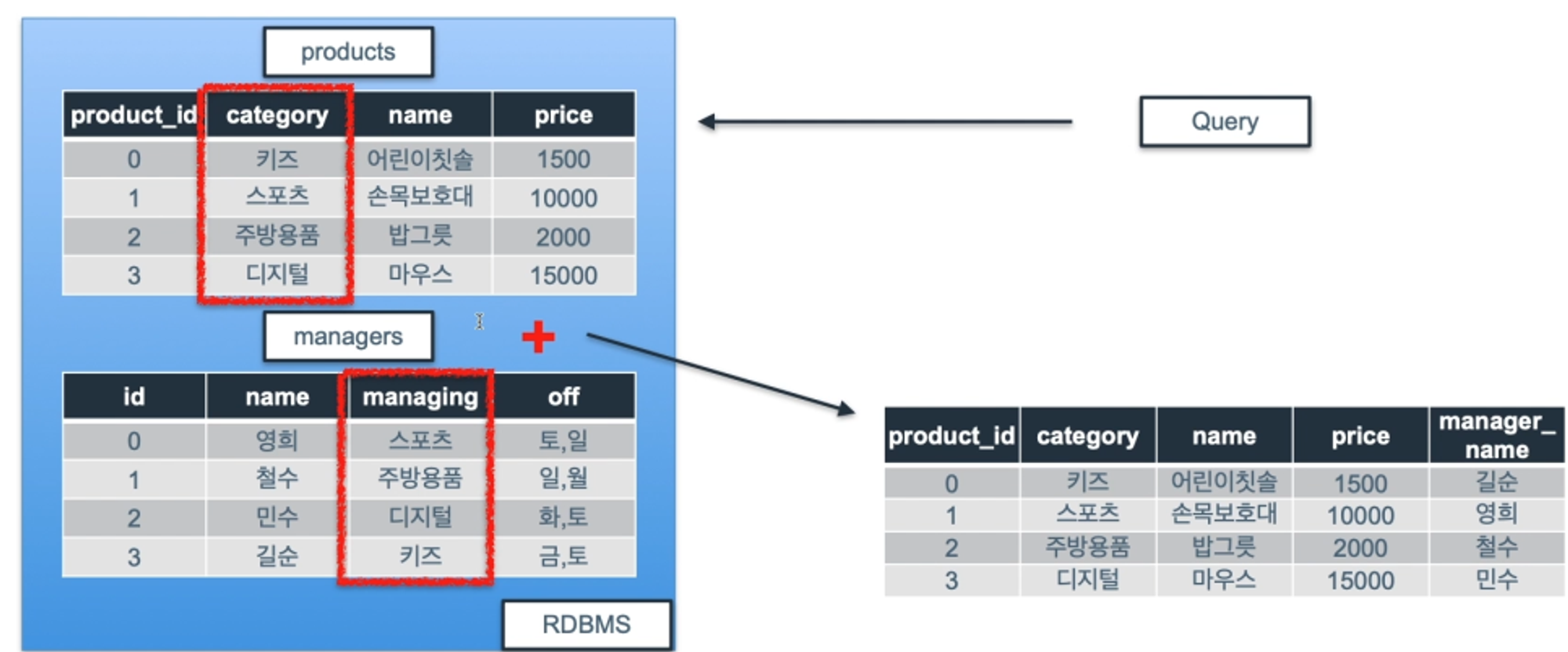
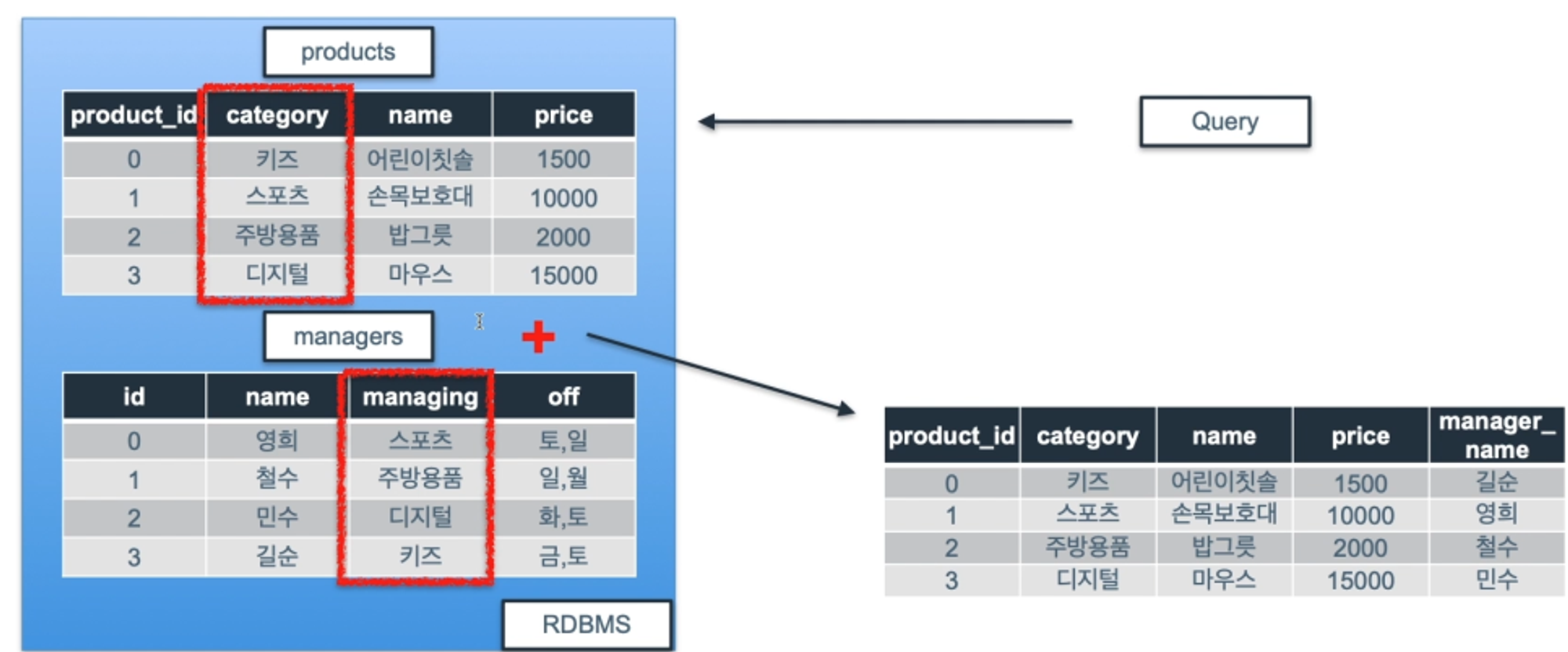
products 테이블과 managers 테이블을 INNER JOIN 해보자.
테이블모습
SELECT products.*, managers.name as manager_name
-- "테이블.컬럼명" 형식을 사용.
managers테이블의 name 컬럼에 별칭을 하는 이유는 products테이블에 name이라는 컬럼이 있기 때문에 중복 방지를 위함.
FROM products INNER JOIN managers ON
-- 기준이 되는 테이블을 먼저 작성(products) ON 뒤쪽에는 어떤 컬럼을 기준으로 할지 작성.
products.category = managers.managing
-- 프로덕트 테이블은 카테고리 컬럼 기준, 매니저 테이블은 매니징 컬럼 기준으로 같은 값만 가져옴.
INNER JOIN 특징
테이블 값이 일치하는 값만 가져오므로 데이터 정확성이 높다.교집합을 구하면서 계산 행 수를 줄임으로써 다른 조인보다 속도가 빠르다.
LEFT JOIN
왼쪽 테이블의 모든행을 가져오고, 오른쪽 테이블에서 일치하는 행을 가져옴.
만약 오른쪽 테이블에 일치하지 않는 행은 NULL 표시
(예시)
clicks 테이블과 orders 테이블을 LEFT JOIN 해서 유저별 클릭과 상품구매를 한테이블로 보자.
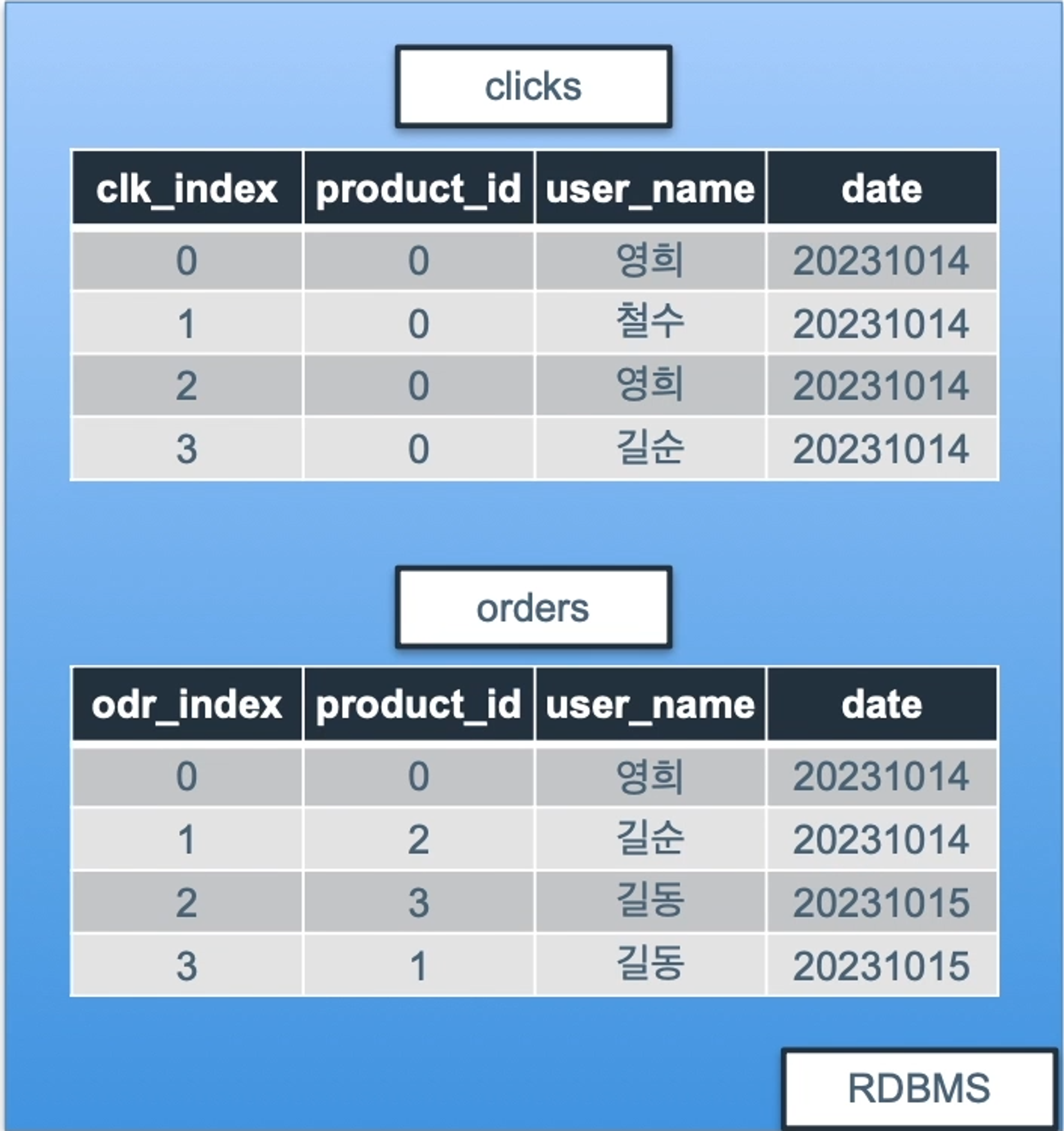
테이블
SELECT clicks.*, orders.odr_index -- clicks의 모든 행, orders의 odr_indx행
FROM clicks LEFT JOIN orders -- clicks를 기준으로 clicks컬럼은 다 가져오고 orders 컬럼은 공통되는 값만.
ON clicks.user_name = orders.user_name
and clicks.product_id = orders.product_id
and clicks.date = orders.date결과 : 철수, 길순은 20231014에 구매한 이력이 없기 때문에 NULL 반영.
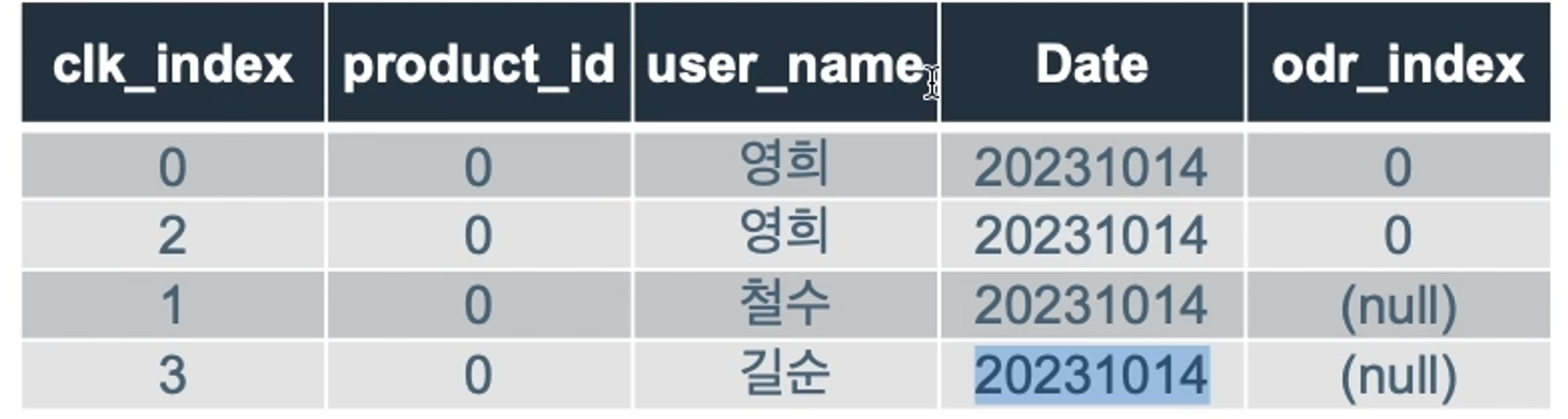
LEFT JOIN 특징
왼쪽테이블의 모든 행을 포함하므로 누락되는 데이터가 없음(오른쪽은 누락되는 데이터 있음)두 테이블의 키값이 일치하지 않으면 NULL값이 표시되므로 어떤 값이 일치하지 않는지 한눈에 볼 수있다.
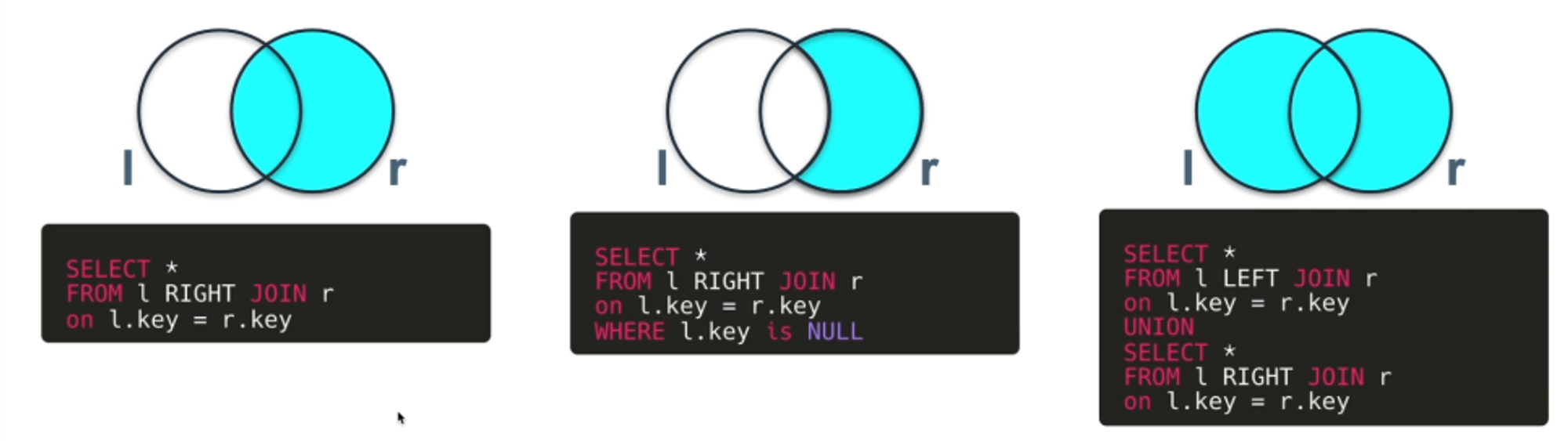
RIGHT JOIN
오른쪽 테이블의 모든행을 가져오고, 왼쪽 테이블에서 일치하는 행을 가져옴.
만약 왼쪽 테이블에 일치하지 않는 행은 NULL 표시
LEFT JOIN의 정 반대.
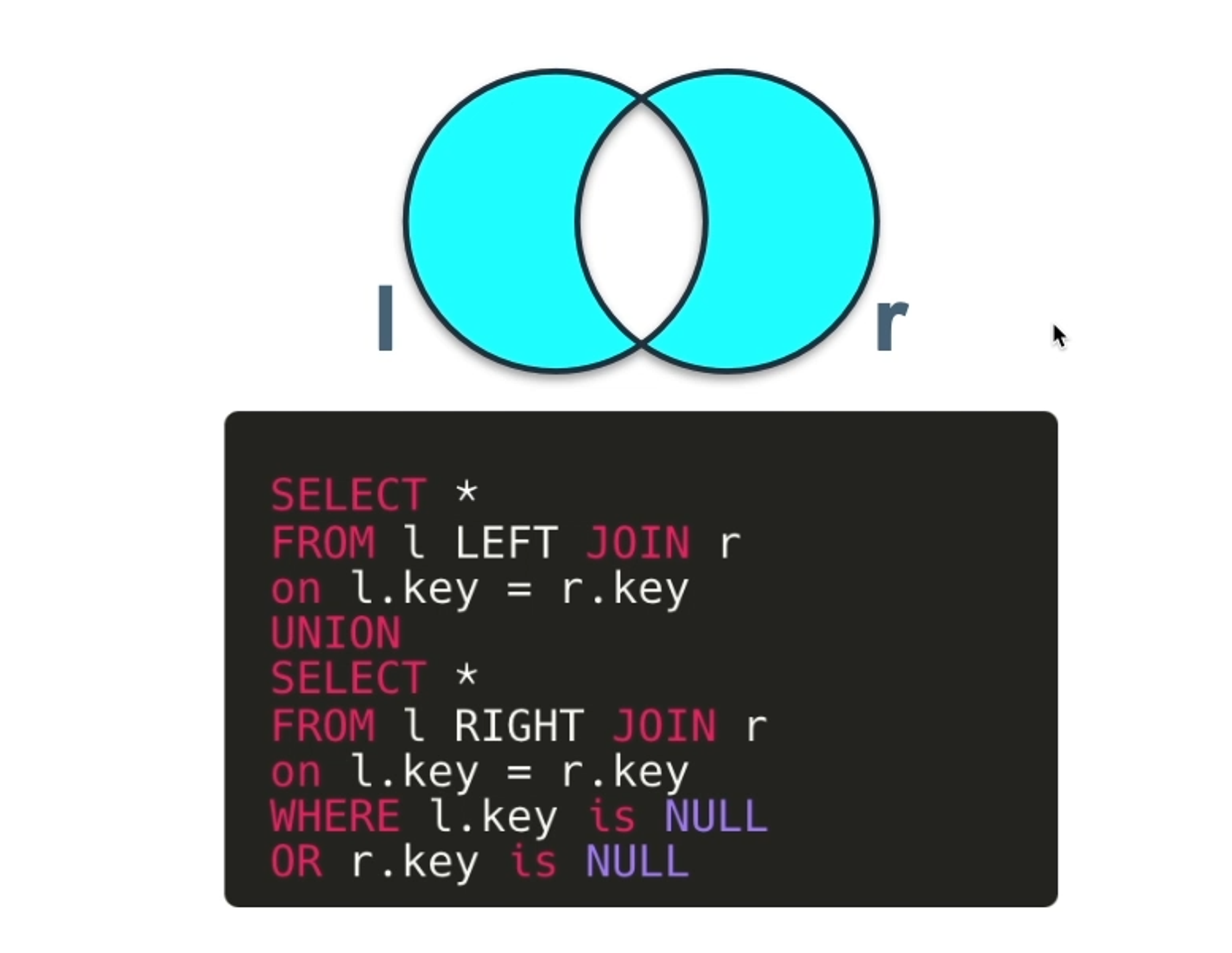
FULL OUTER JOIN
두 테이블 간의 모든 행을 가져오며, 일치하는 행과 일치하지 않는 행을 모두 반환.
일치하지 않는다면 NULL을 표시
FULL OUTER JOIN특징
모든 행을 필터링 없이 가져오기 때문에 과부화 위험이 있다.MYSQL에서는 지원하지 않음. 사용하려면 LEFT JOIN과 RIGHT JOIN을 UNION 해줘야 됨.
CROSS JOIN
두 테이블간 가능한 모든 조합을 생성할때 사용.
보통 모든 조합 생성 후 집계를 구할 때 사용.
예를들어
상품을 클릭한 시간과 상품을 구매한 시간 차이의 평균을 구하려고 할 때
크로스 조인 후 모든 클릭, 구매간 조합을 만들어 시간차를 구한 뒤, 평균 집계.
이런 상황이 많지는 않지만 상품간의 유사도를 분석할 때 사용.(연관 상품 추천)
(예시1)
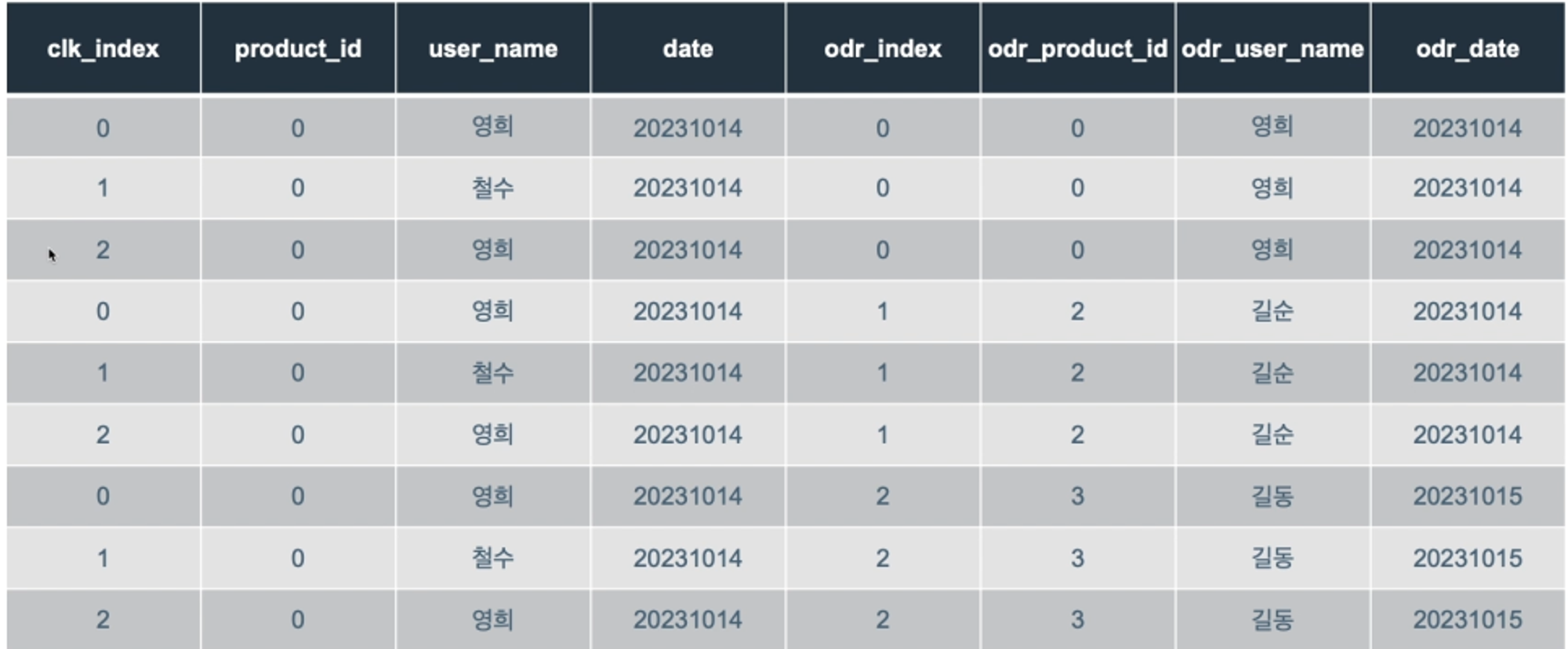
클릭 테이블과 주문 테이블에서id, 사용자 이름, 주문 날짜의 모든 조합을 생성해보자.

테이블
SELECT clicks.*, orders.odr_index,
orders.product_id as odr_product_id -- 중복되는 컬럼명 방지
orders.user_name as odr_user_name,
orders.date as odr_date
FROM clicks CROSS JOIN orders결과
모든 행들의 조합을 보여줌.
(예시2)
category 테이블의 상품을 본 사람들에게는 B_category 테이블의 상품을 추천하고
B_category 테이블의 상품을 본 사람들에게는 category 테이블의 상품을 추천하고자 할 때.
두 테이블에 있는 상품별 유사도를 구해보자.

코드
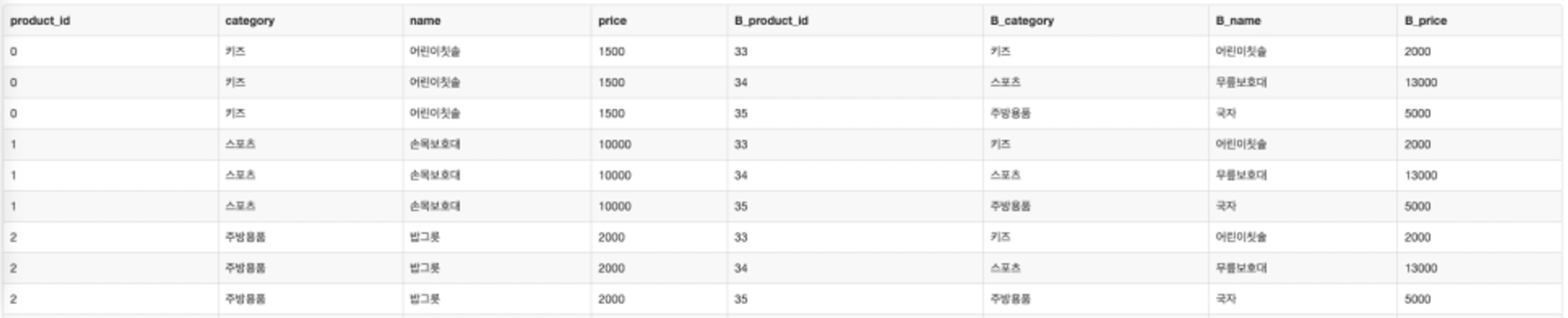
결과값
결과값을 보고 name과 B_name이 같다면 1점,
category와 B_category가 같다면 1점,
가격 차이가 500원 이상 나지 않는다면 1점 등 이런식으로 관련도를 점수를 부여하여 유사도를 측정할 수 있다.
CROSS JOIN 특징
테이블 컬럼들의 모든 조합을 보여줌. 즉 연산량이 어마어마하기 때문에 FULL OUTER JOIN보다 과부화 위험이 있음.상품간의 유사도를 측정할때 사용.
쿼리를 더 가독성 좋게해보자!
Alias(별칭)
컬럼을 별칭 할 때 에는
[컬럼명 as 별칭]
테이블을 별칭 할 때 에는
[테이블명 별칭]
SELF JOIN
INNER JOIN을 다른 테이블이 아닌 하나의 테이블에서 사용할 때 사용.
(예시)
substitute 컬럼은 매니저 휴가시 대체자 id를 의미한다.
영희가 휴가라면 대체자 id는 1이므로 철수가 대체자 이다.
이를 더 가독성 좋게 sub_name 컬럼을 만들어 이름도 나올 수 있게 구현해보자.

SELECT m1.*, m2.id as sub_id, m2.name as sub_name -- 같은 테이블의 컬럼이므로 중복 방지를 위해 별칭을 넣음.
FROM managers_v2 m1 INNER JOIN managers_v2 m2 --같은 테이블에서 진행하기 때문에 별칭을 반드시 넣어줌.
ON m1.substitute = m2.id --m1의 대체자 id가 m2의 id와 같을때 결합.JOIN을 필터링 할때에!
JOIN도 테이블을 가져오므로 WHERE 절로 필터링을 할 수 있다.
이때 WHERE 은 JOIN문이 다 끝난뒤 사용.
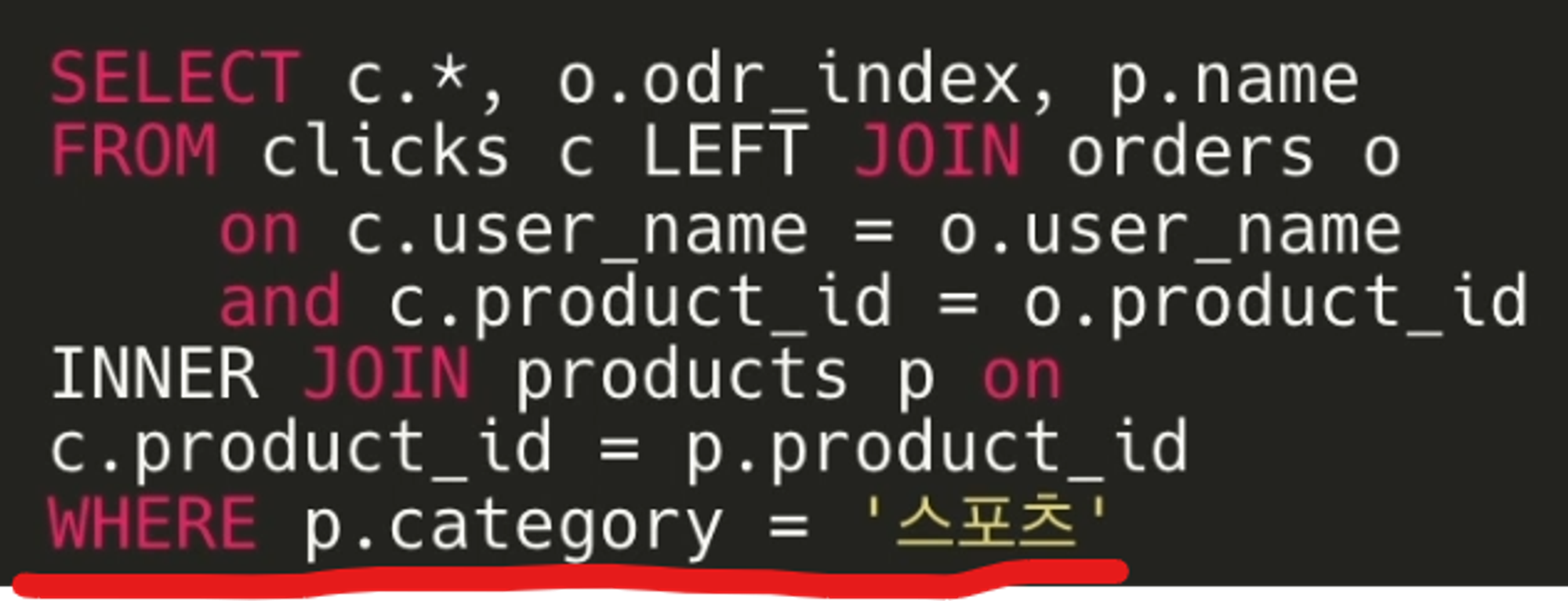
WHERE을 마지막에 넣는다.
하지만 쿼리를 효율적으로 하기 위해서는 필터를 먼저 거는게 더 좋다고 한다…!??(이건 다음 글에서 설명)
벤다이어 그램 최종 정리