데브코스_데이터분석- SQL 기초와 데이터 분석[3주차]
1.[11일차]SQL과 RDB란?

관계형 데이터베이스(RDBMS)를 사용하기 위한 표준언어테이블. 행, 열로 구성관계형 데이터 베이스(Relational DB)표 형태로 데이터를 쌓음.데이터가 열, 행, 테이블과 관계를 맺고 있기 때문에 관계형 데이터 베이스라고 부름.데이터를 입력할때 어떤 테이블에 몇
2.[11일차]SQL FIDDLE 사이트

SQL세팅 없이 테이블 생성 및 쿼리 연습 가능!http://sqlfiddle.com/업로드중..테이블 및 컬럼 생성 쿼리문 작성 후 BUILD Schema 를 클릭해서 스키마 생성.이후 sql문을 돌릴 수 있음.
3.[11일차]SQL 기초 구문 SELECT, FROM, WHERE
쿼리문 기본SELECT - 무엇을 ( 어떤 컬럼을)FROM - 어디에서 (어떤 테이블에서)WHERE 어떤 조건으로예시)🍯실무 꿀팁! - WHERE 구문위와 같이 WHERE 절에서 1=1과 같은 조건을 넣는 이유!여러 추출 조건들을 넣을 때 WHERE 절은 필수로 들어
4.[11일차]SQL 비교 연산자와 논리 연산자
참고 : 연산자는 WHERE 구문에서 사용.비교 연산자=, >, <, >=, <=서로를 비교<>, !=서로 같지 않음을 뜻함.논리 연산자AND모든 조건이 참일경우에 추출OR모든 조건 중 하나만 참일경우에 추출NOT참, 거짓의 반대를 추출.IN컬럼 IN
5.[11일차]SQL 정렬과 집계
정렬을 통해 어떤 순서에 따라 컬럼을 반환할지 결정하고집계를 통해 어떤식으로 데이터를 요약할지 결정한다.정렬 : ORDER BY구문ORDER BY 컬럼명 ASC / DESC오름차순 : 공란 or ASC내림차순 : DESC를 사용.예시)여러 개의 정렬조건을 만들때에는 우
6.[11일차]SQL 기초 함수
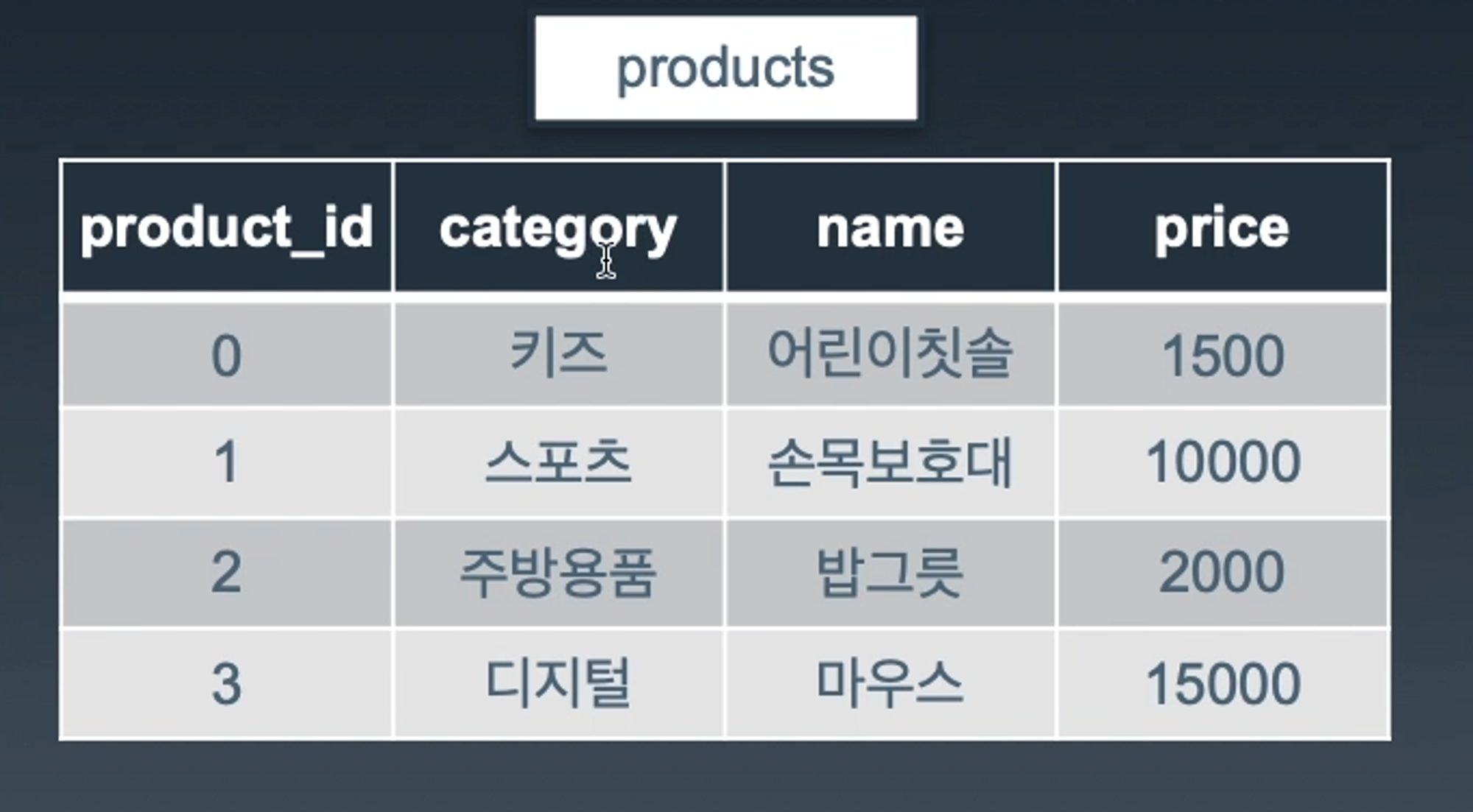
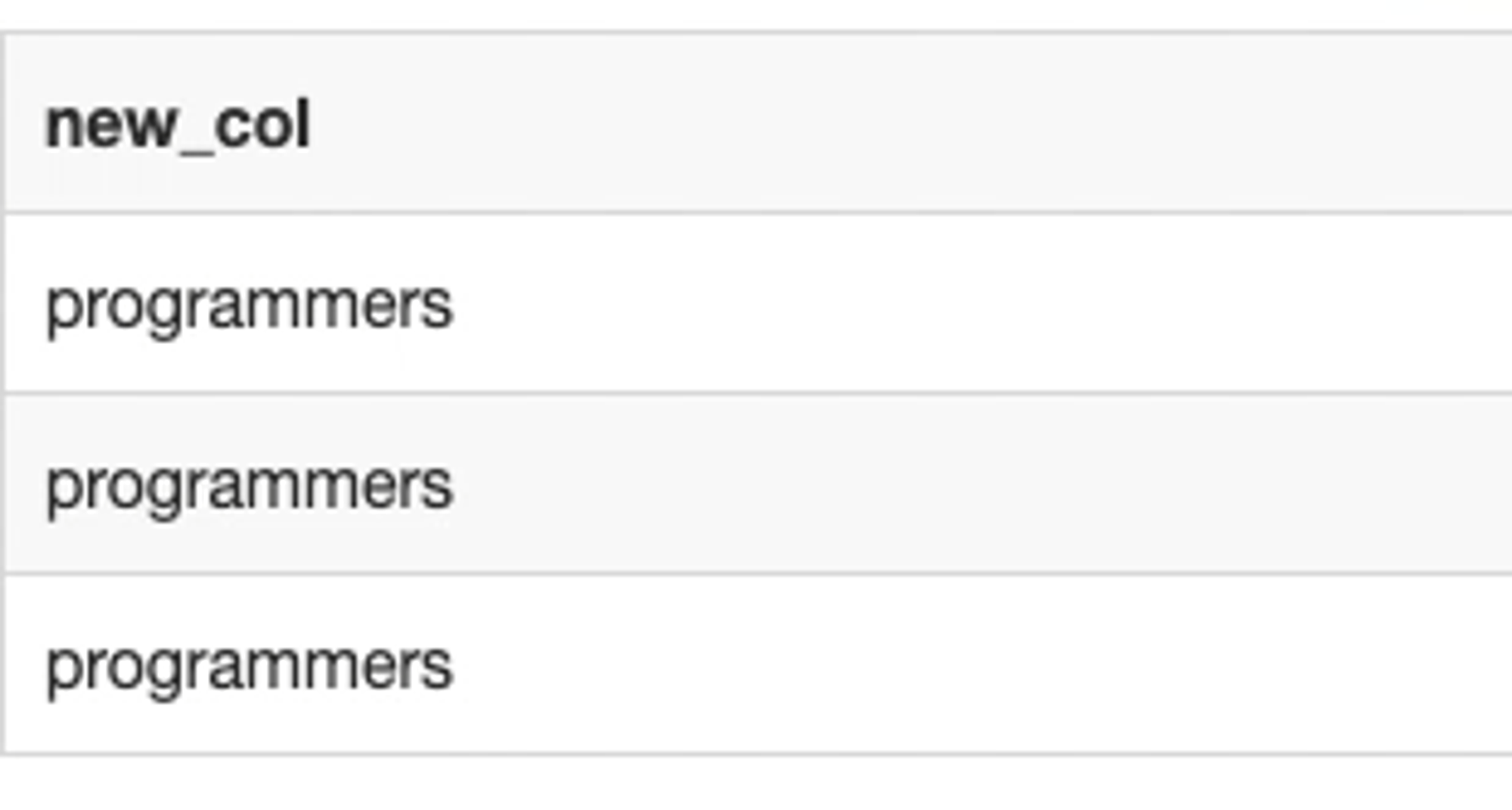
SQL에서 사용되는 기초 함수들로 웬만하면 외우도록 하자..!CONCAT컬럼별 문자열 값들을 하나로 합칠때 사용.괄호안 문자열을 결합.예제products 테이블의 컬럼값.products 테이블category와 name을 합친 열을 반환할 때.SELECT CONCAT(c
7.[11일차]DDL, DML이란?
CREATE : 테이블/뷰/인덱스 생성ALTER : 테이블/뷰/인덱스 구조 변경DROP : 테이블/뷰/인덱스 삭제언어정리!테이블 - 실제로 컬럼이 저장되어있는 곳뷰 - 가상의 테이블을 쿼리하여 보여주는 것.인덱스 - 데이터베이스에서 원하는 데이터를 빠르게 만들기 위한
8.[12일차]다양한 JOINS
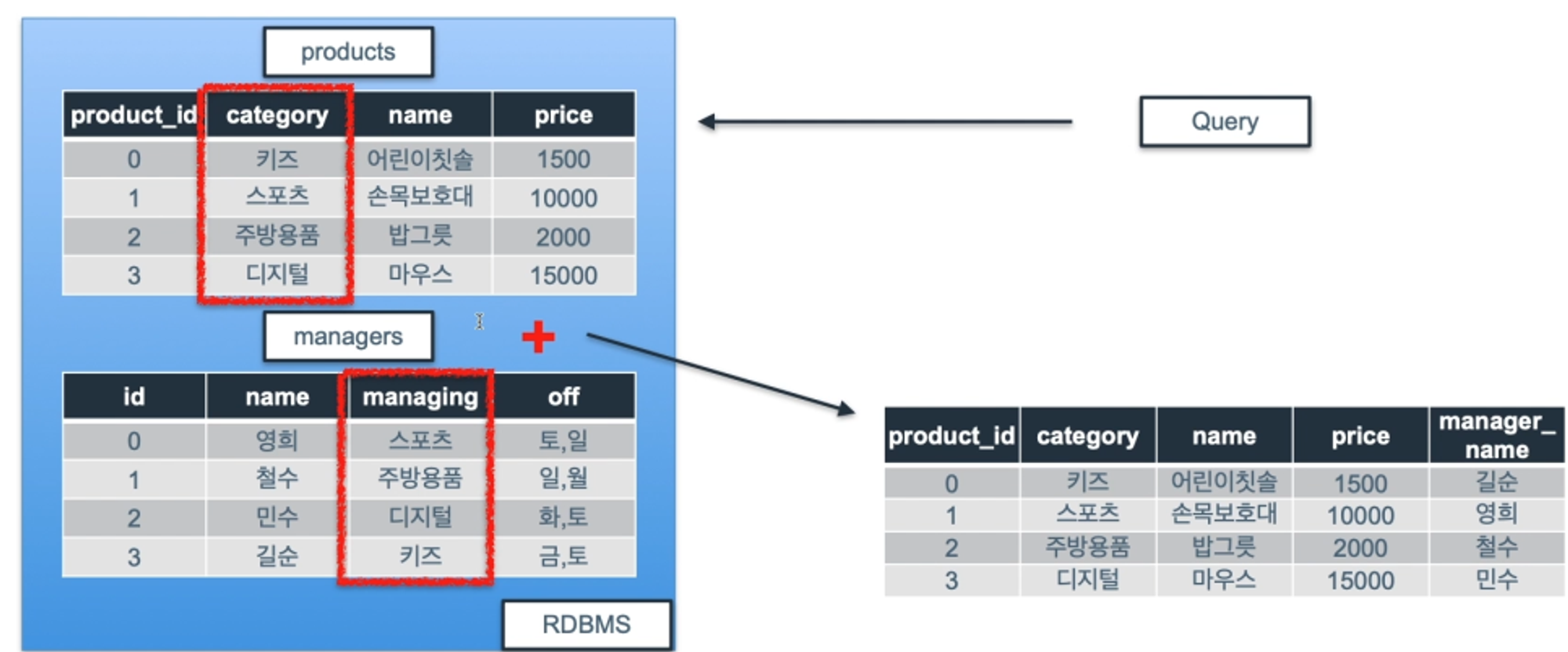
JOINS : 두 개 이상의 테이블을 특정 KEY를 기준으로 결합하는 것FROM 절에서 사용.INNER JOIN두 테이블에서 값이 일치하는 행 만(교집합) 결과에 반환한다.(예시)products 테이블과 managers 테이블을 INNER JOIN 해보자.테이블모습IN
9.[12일차]UNION / UNION ALL
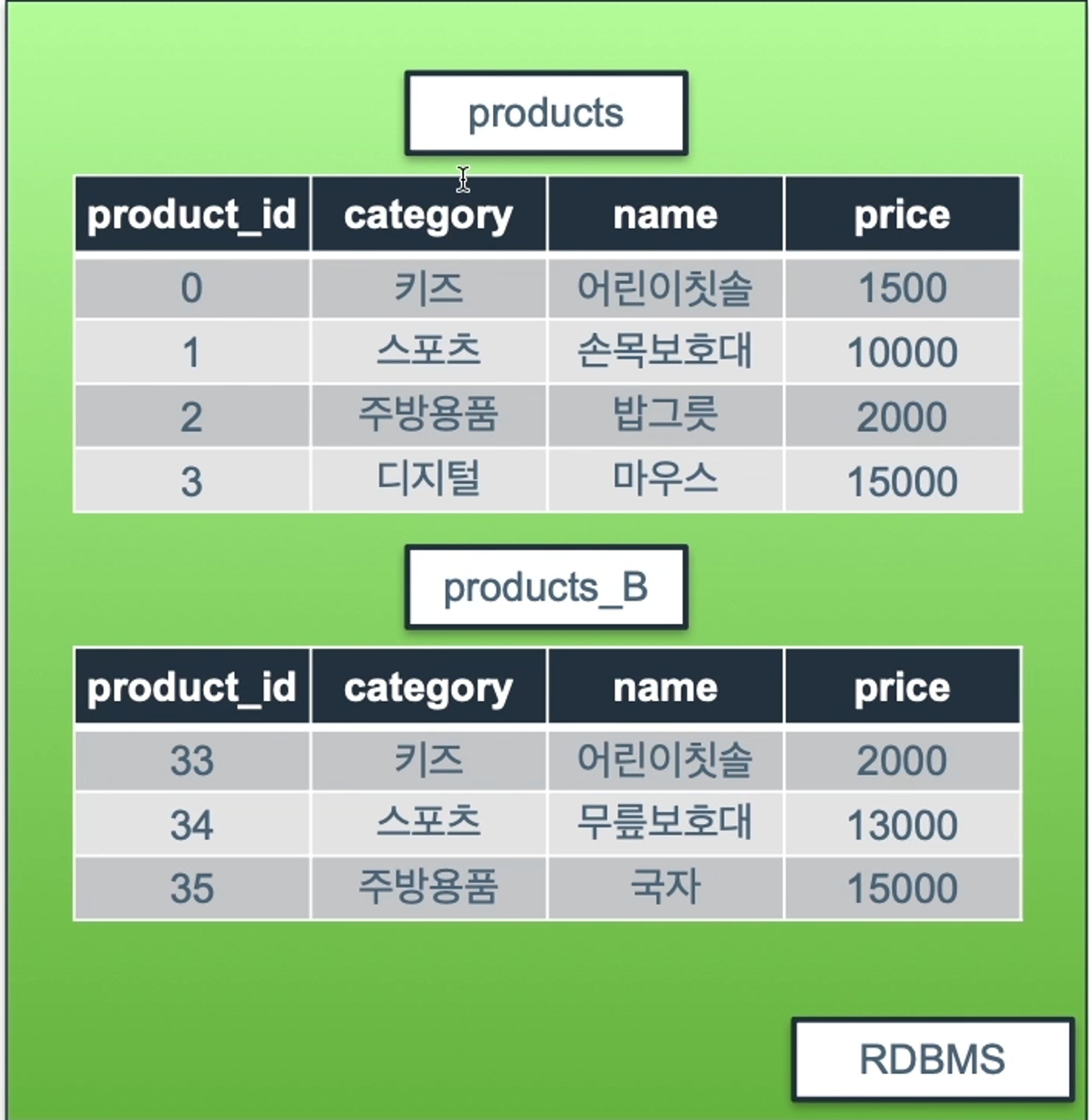
SELECT한 문장들은 결합함.UNION특징중복되는 행 제거UNION 사용을 위해서는 각 SELECT문에 사용되는 열(컬럼)의 수와 데이터 타입이 일치 해야 됨.(예시)컬럼이 각 각 4개인 두 테이블을 결합해 보자.테이블결과값UNION ALL유니온과는 다르게 중복값을
10.[12일차][SQL] WITH 구문
CTE(Common Table Expression) 라고도 부르며, MYSQL 8.0버전 이상에서 지원.임시 결과 집합을 생성하여 복잡한 쿼리를 쉽게 작성할 수 있도록 돕는 기능.복잡한 쿼리에서 하위 쿼리를 사용해 같은 결과를 여러번 계산해야 하는 경우를 줄여 준다.
11.[12일차][SQL]Subquery 서브쿼리

Subquery쿼리 내부에 사용되는 서브쿼리잘못 이용시 리소스를 과다하게 사용할 수 있기 때문에 쿼리 최적화에 항상 신경을 써야됨.예제1 비교문) 유저별 평균 구매 가격과 전체 평균 구매 가격을 비교해보자.결과물예제 실무 활용법전체 평균 구매 가격 대비 유저별 평균 구
12.[12일차][SQL]타임스탬프 함수
현재 시간을 구하거나 날짜의 차이 등을 구할 때 사용보통 사용자 로그를 분석할때 사용.데이터 예시)저장된 시간간의 시간을 구한뒤 초단위로 바꾼 뒤클릭 후 구매까지 몇 초가 걸리는지 분석SQL에서 날짜와 시간 다루기데이터 타입STRING : ‘yyyy-mm-dd’, ‘Y
13.[12일차]SQL 조건
조건문 : IF엑셀 if문과 동일.예제) 가격이 1만원 이상이면 고가, 아니면 저가를 추출.테이블결과조건문 : IFNULL값이 NULL일때 지정한 값으로 채워서 반환함.예제)테이블결과갑순 DATE 값에 200231104가 들어감.⭐CASE WHEN⭐3개 이상의 조건을
14.[12일차][SQL]그 외 유용한 함수 - RANK(),LEAD(),LAG()
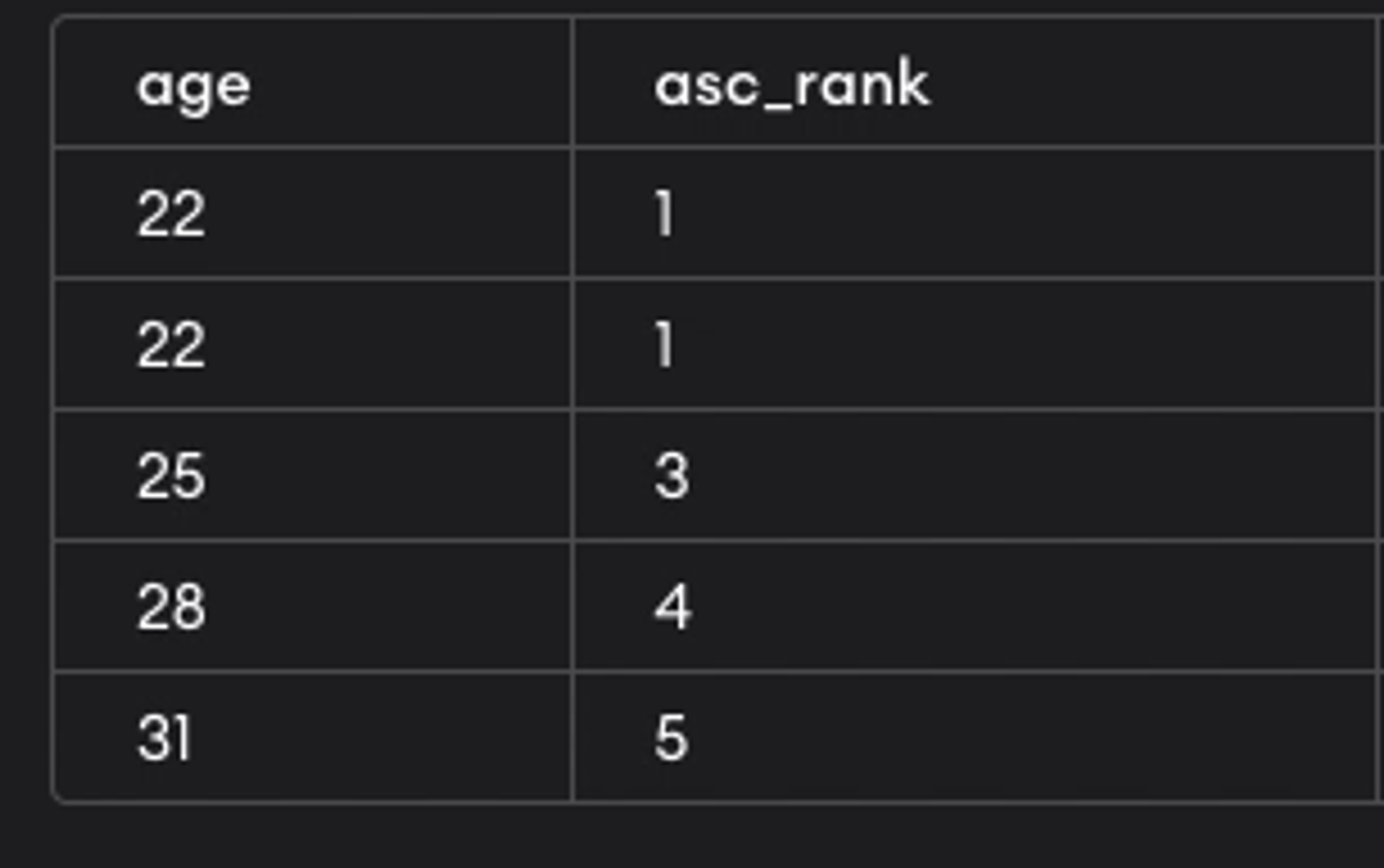
RANKRANK() : 순위를 낼 수 있다. (1위가 동순위라면 그 다음 순위는 3위)dense_rank() : 순위를 낼 수 있다.(1위가 동 순위라면 그 다음 순위는 2위)percent_rank() : %비율로 순위를 매김.(꼴등은 0%, 1등은 100%)구문 :
15.[13일차][SQL]데이터 타입 - 숫자
테이블을 만들거나 쿼리문을 작성할때 사용.BIT(M) 비트!의미 : 0과 1로만 구성 / 2진법BIT 111 = 7BIT(M)에서 M은 몇자리 비트를 쓸 지 정하는 숫자다.1~64까지 값이 올 수 있다.예) BIT(4) = 4자리의 값을 만들 수 있다. “1010”,”
16.[13일차][SQL]데이터 타입 - 문자
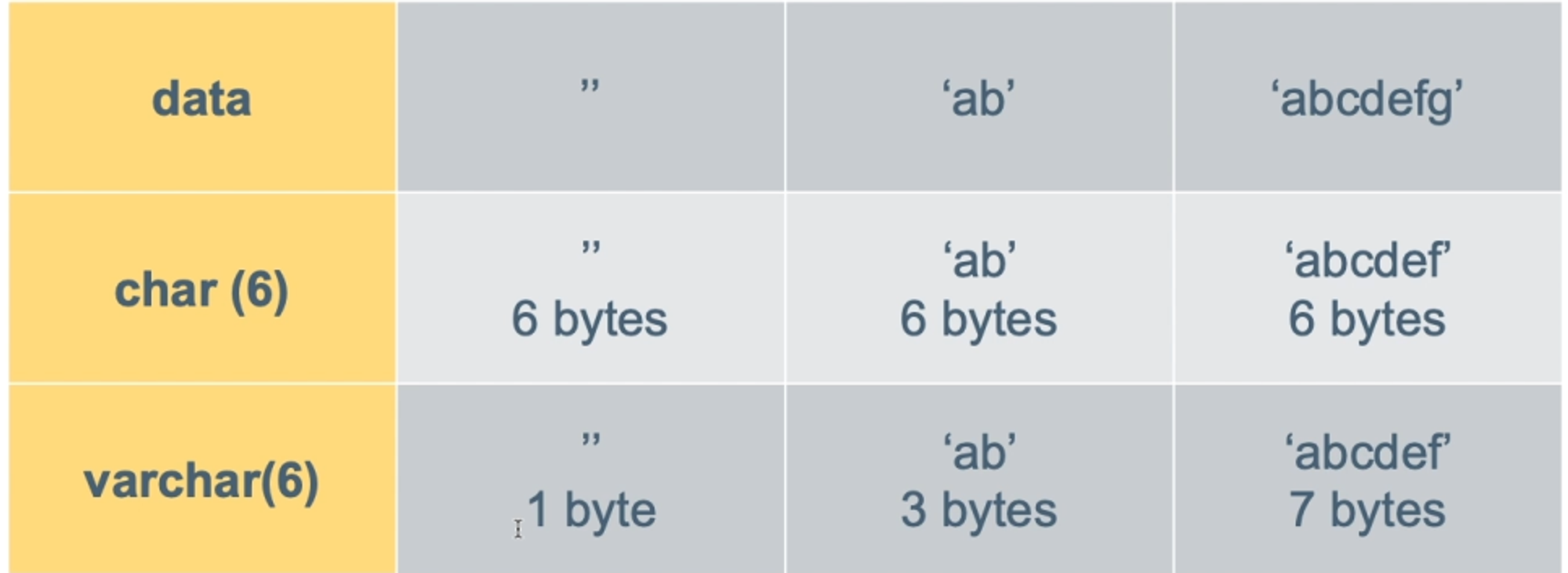
CHAR⭐의미 : 고정된 길이의 문자열길이Byts : 0~255선언된 값보다 짧은 문자열이 들어오면, 빈 문자열로 나머지 길이를 채워줌.1개를 적어도 고정된 저장공간CHAT(4)일 때, 입력값 별로 저장 공간 동일. "파인애플" = 4byts, "사과" =4byts고정
17.[13일차][SQL] 데이터 타입 - 이진
이진 : 두 개의 숫자 또는 상태를 나타내는데 사용되는 용어. 0과 1을 사용!참고! 이진과 문자열은 비슷한 성질을 띔BLOB의미 : Binary Large ObjectBinary파일이란?데이터를 저장, 활용하기 위해 0과1로 인코딩해 둔 파일.길이 최대 65535(길
18.[13일차]데이터 타입 - 배열(Array)
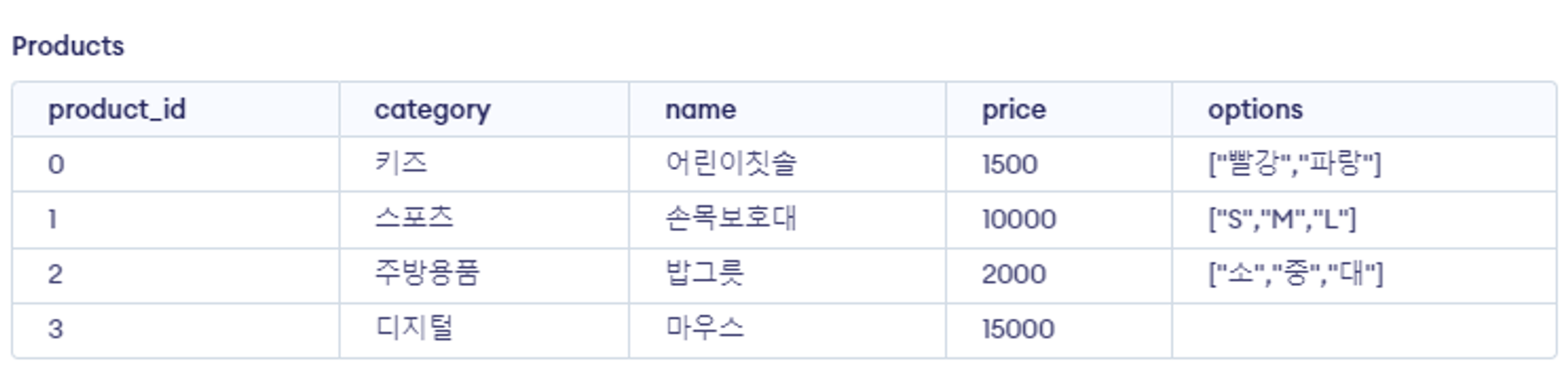
배열 (Array)란?데이터가 저장된 리스트예) ’a’, ‘b’, ‘c’ / 1, 2, 3원소 : a,b,c / 1,2,3Element (원소) : Array에 저장된 각 데이터JSON 타입으로 배열을 저장데이터를 간단하게 한줄로 부를 수 있는 객체JSON Array
19.[13일차][SQL] 데이터 타입 - Key - value 구조체
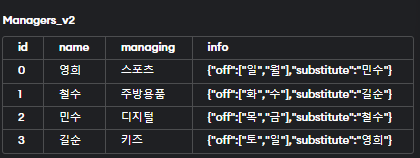
Key - value란?Key - value : Key와 Value로 이루어진 데이터(컬럼) / JSON 타입Key를 통해 Value에 접근할 수 있음예시) {’이름’ : ‘홍길동’, ‘부서’ : ‘개발팀’, ‘직책’ : ‘팀장’, ‘근무지’ : ‘판교’}
20.[14일차]효율적인 SQL 코드 작성하기 - 테이블을 집합으로 생각하기.
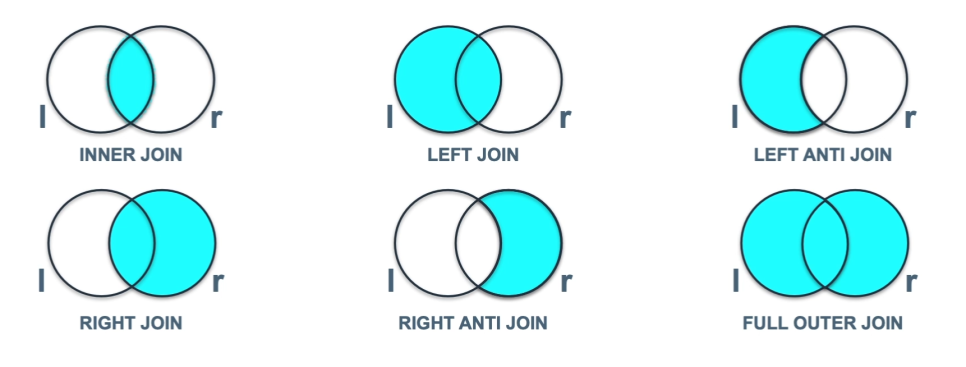
테이블은 RDBMS이기 때문에 일반적으로 집합의 형태를 띈다.아래의 사진은 JOIN을 벤다이어 그램 형태로 반환한 것이다.테이블간의 관계도 사진과 같은 집합으로 생각하면 쿼리문을 짤때 이해하기 쉬울 것 이다.1\. 최대한 작게 만들어 놓고 JOIN 하자.“작게 만들어
21.[14일차]효율적인 SQL 코드 작성하기 - *, % 사용 지양하기
새로운 DB를 관리해야 된다면 가장 먼저 해야 될 일은 DB 내에 데이터를 파악하는 일이 될 것이다.이번 글에서는 데이터를 파악해야 되는 이유와 데이터 추출시 유의할 점을 적어보았다.회사마다 다르겠지만 보통 100명 이상의 직원이 있다면 DB내에 테이블이 아주 많을것이
22.[14일차]효율적인 SQL 코드 작성하기 - 데이터 타입 잘 확인하기

DB마다 다르긴 하지만 SQL에서는 묵시적 형변환을 지원함.비교하고자 하는 두 값이 다른 타입일때 DB가 타입을 자동으로 맞춰서 비교하는 것.이는 굉장히 편리한 기능이지만, 그만큼 리소스를 많이 잡아먹기 때문에 비교하고자 하는 값이 다른 타입일때 형변환을 미리 해주는것
23.[14일차]효율적인 SQL 코드 작성하기 - JOIN시 유의할 점
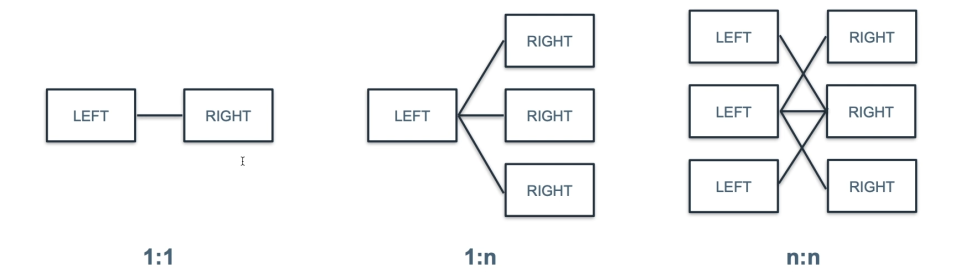
JOIN은 연산량이 크기 때문에 JOIN 대상 테이블을 최대한 줄여서 사용하는 것이 좋다.(WITH, 서브쿼리 등을 사용)JOIN의 관계는 크게 3가지로 볼 수 있다.1:1, 1:N, N:NJOIN 1:1좌측 테이블 행 하나와 우측 테이블 행하나가 1대1로만 대응하는
24.[14일차]효율적인 SQL 코드 작성하기 - 가독성 높이기🍯TIP!
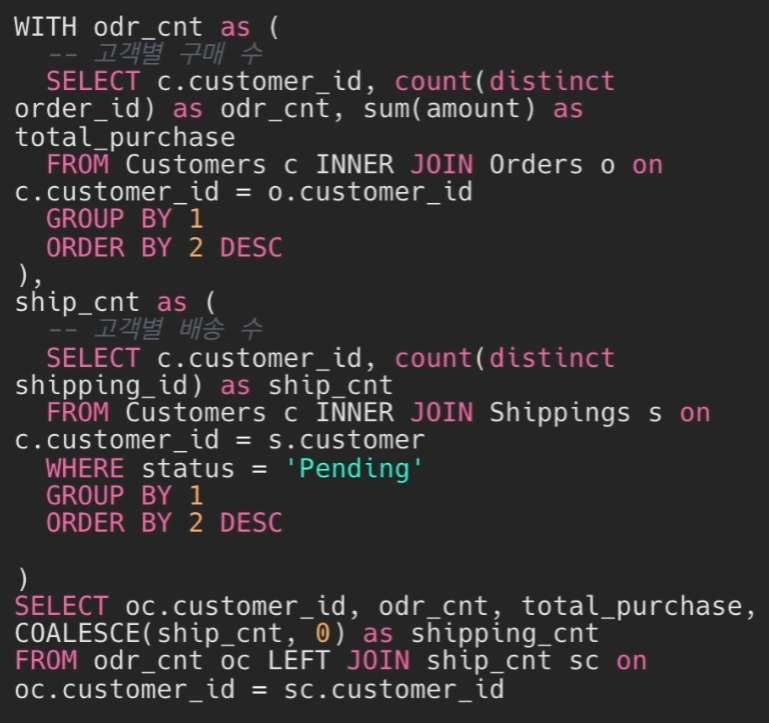
쿼리를 보는 미래의 자기자신과, 다른 사람들을 위해.사람마다 쿼리를 짜는 스타일이 다르기 때문에 다른 사람이 짠 쿼리를 볼 때 이해하기 어려울 수 있음.1\. 서브쿼리 보다는 WITH 구문이 가독성이 좋다.WITH 구문은 블록으로 구분이 되기 때문에각 블록안에 내용만
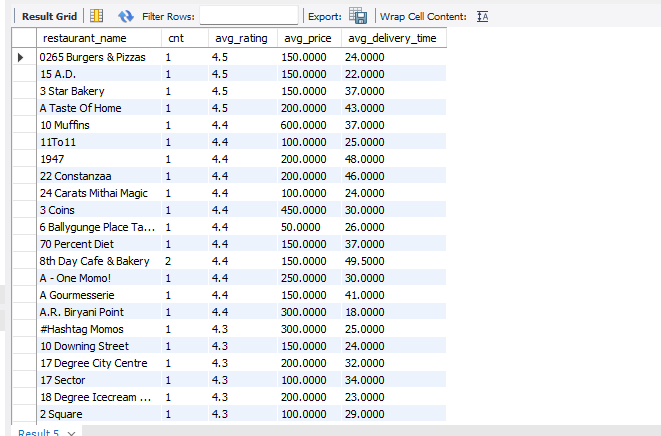
25.[15일차]실전 데이터 분석 사례 1 -인도식당(프렌차이즈 여부에 따른 별점의 분포 확인)
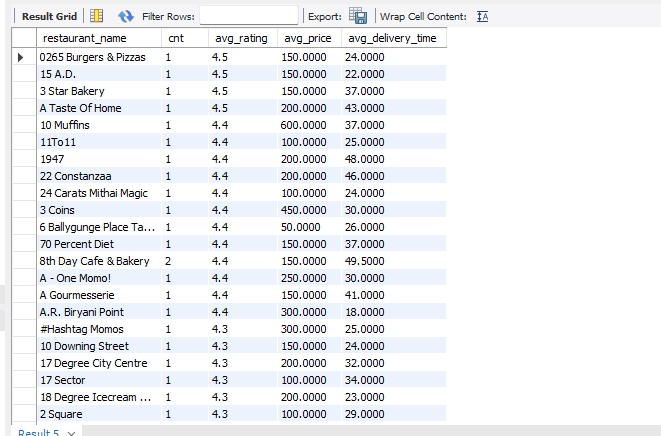
실전 데이터 분석 사례에서는캐글 데이터를 기반으로 분석을 실시해보았다.https://www.kaggle.com/datasets/abhijitdahatonde/27000-indian-restaurant-dataset/data?select=indian_restau
26.[15일차]실전 데이터 분석 사례 1 -인도식당(상관계수를 통한 데이터 분석)
이번 상관계수는 Pearson 상관계수를 활용할 것 이다.Pearson 상관계수 : -1 ~ 1 사이의 값으로 두 변수가 얼마나 상관도가 높은지 측정하는 지표.코드)결과값)이 데이터를 CSV로 반환 후 구글 스프레드시트를 사용해각 데이터들의 별점과의 상관계수를 구해보도
27.[15일차]실전 데이터 분석 사례 1 -인도식당(가격과 평점에 영향을 주는 변수 확인)
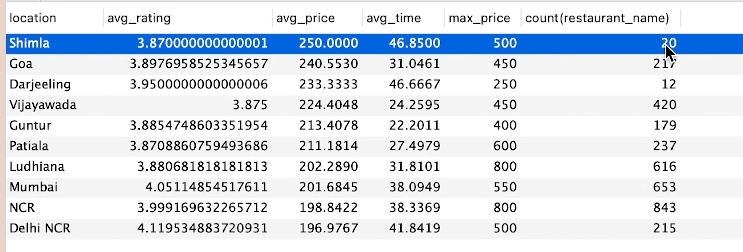
인도식당별 가격과 평점은 어떤 영향을 받았는지 분석을 해보자.지역별로 평균 별점, 평균 가격, 평균 배달시간, 최대가격, 레스토랑 수를 집계해보자.최대가격 - 최대값이 두드러지게 커서 평균 가격의 편차를 높일 수 있기때문에 확인 차 집계.코드)결과값)가장 저렴한 지역과
28.[15일차]실전 데이터 분석 사례 2 - 연봉 데이터 분석(그룹별 평균 비교)
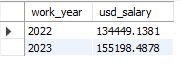
Global AI, ML, Data Science직군의 연봉 데이터를 분석해보자!https://www.kaggle.com/datasets/dparas01/global-ai-ml-data-science-salary2022년과 2023년의 연봉을 비교해 보자.코드
29.[15일차]실전 데이터 분석 사례 2 - 연봉 데이터 분석(2022->2023 연봉 변화에 영향을 주는 변수 확인)
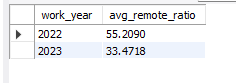
연봉에 영향을 주는 변수가 무엇이 있을까?나는 재택근무 유무, 직무 비율 변화 등을 분석해보았다.1\. 연도별 재택근무 비중의 변화 원인을 알아보자.코드)결과값)2022년 대비 2023년 재택근무의 비중이 낮아졌다.왜 이런 변화가 일어났을까?1\. 숙련도별 평균 재택근
30.[15일차]실전 데이터 분석 사례 3 - NBA Players(시간 흐름에 따른 선수 스펙)
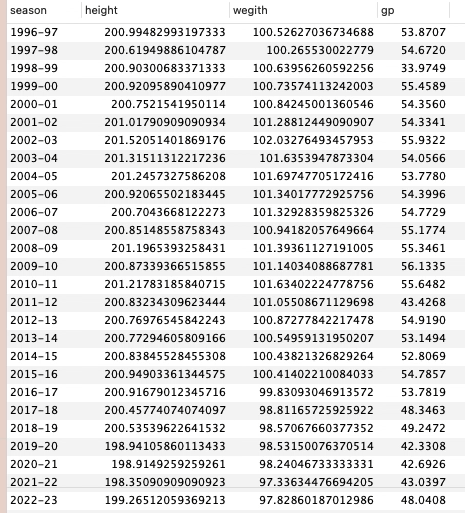
https://www.kaggle.com/datasets/justinas/nba-players-data이번에는 데이터 확인>가설>가설검증 을 순서대로 데이터를 분석해보겠다.코드)시즌별 선수들의 평균 키와 평균 몸무게와 평균 게임수를 가져옴.시간이 지날 수록 키
31.[15일차]실전 데이터 분석 사례 3 - NBA Players(시간 흐름에 따른 상위 선수 지표 확인)
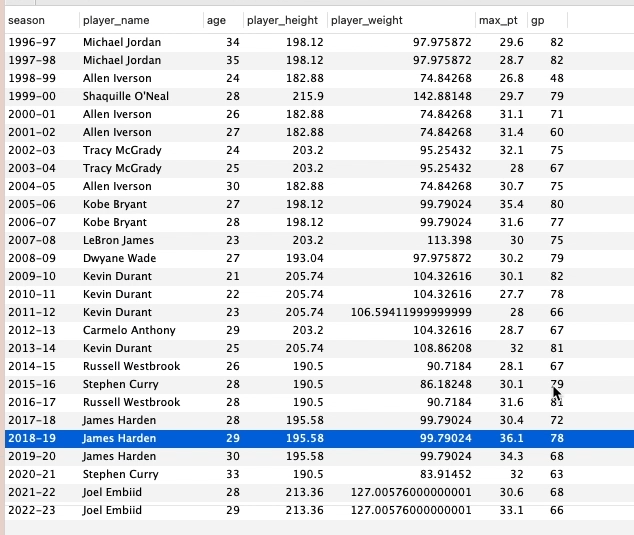
코드)결과값) 눈에 띄는 추세를 파악하기 어려우니 그래프를 그려보자.그래프) 평균 득점수와 게임수는 유지되는 추세이지만 파악하기 어렵다.데이터가 부족해서 그럴 수 있으므로 시즌별 랭킹 1 ~ 10위의 득점 평균을 보자.코드)결과값)여기서 시즌별 랭킹 10위 이내의 선수