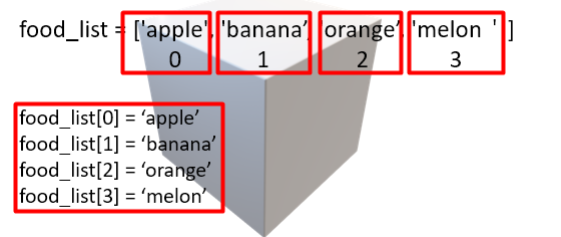
Series란?
series는 데이터를 1차원(한 줄)으로 볼 수 있는 것이다.
Series는 Pandas를 사용하면서 계속해서 마주해야 되는 것 이다. 그렇기 때문에 자세히 살펴볼 필요가 있다.
Series와 데이터 프레임과 차이
- 컬럼의 갯수
- Series는 컬럼이 1개, 데이터프레임은 1개 이상이다.
series로 인덱스 레이블 선택(조회)하기
series로 인덱스 레이블 선택(조회)하기 위해서는 loc 이라는 메소드를 사용한다.
확인해보니 series로 조회하기 위해서 사용하는 함수가 아닌 그저 단일값을 추출할때 사용하는 함수였다.
단, 하나의 컬럼만 조회시 series로 조회,
두개 이상의 컬럼으로 조회시 데이터프레임으로 조회가 된다.
import pandas as pd
df = pd.read_excel('./slamdunk_player_stats.xlsx')
df.loc[1] #대괄호 안에 인덱스 번호를 넣어줌.해당 코드를 실행하면 slamdunk_player_stats.xlsx 파일을 불러오며
인덱스 1번에 있던 강백호의 데이터가 series형태로 추출됨.

출력값을 보고 이런 의문이 들 수 있다.
‘위에서 시리즈는 한줄이라고 했는데 출력값은 두줄로 나오는거 아닌가?’
이에 대한 대답은 value만 보면 1줄이므로 한줄이라고 표현한 것이다.
이름, 포지션 등 속성값은 별개로 본다.
dataframe으로 인덱스 선택(조회)하기
대괄호를 한번더 감싸서 데이터 프레임형식으로도 출력할 수 있다.
df.loc[[1]]
- 범위로 조회하기
인덱스 넘버이기 때문에 범위 조회가 가능하다.
- 만약 3~7번 데이터에서 “이름”~”체중”까지의 데이터만 추출하고자 한다면.
df.loc[3:7,"이름":"체중"]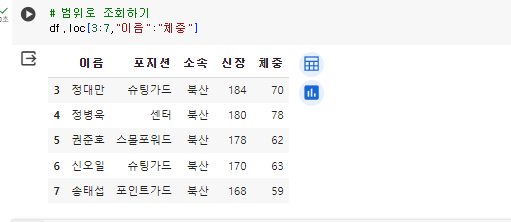
- 3,6,9번의 이름과 체중만 추출시
df.loc[[3,6,9],["이름","체중"]]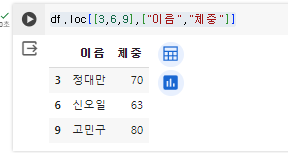
- 전체에서 이름, 포지션, 소속, 리바운드 추출시
df.loc[:,["이름","포지션","소속","리바운드"]]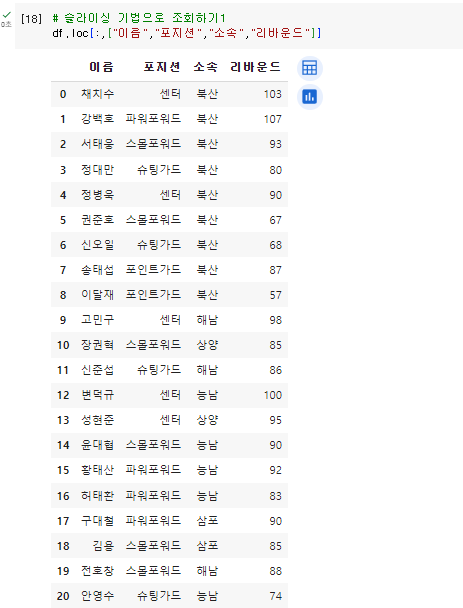
✏️key point!
pandas 인덱스와 파이썬의 인덱스는 같으면서도 다르다.
pandas에서는 인덱스를 넘버로 칭하지 않고 문자로 칭하며, 그 문자가 0이여도 1번째라고 칭함
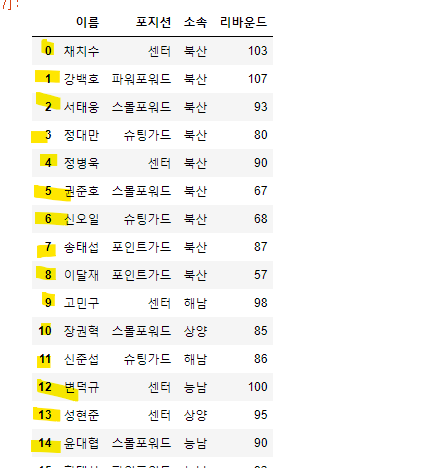
반대로 파이썬은 인덱스를 넘버로 칭하며 1번째를 0번째로 칭한다.
pandas에서 파이썬의 인덱스 넘버링을 사용할 수 있는 코드가 있다.
- iloc
해당 함수로 index location으로 조회 가능!
인덱스 0~3 넘버와 컬럼 0~1을 추출.
df.iloc[0:3[0,1]]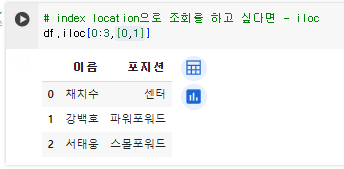

LV. 1