데브코스_데이터분석- Python Pandas 활용하기[6주차]
1.[26일차]Pandas 입문 - 모듈 참조, 파일 불러오기, 한글오류 해결
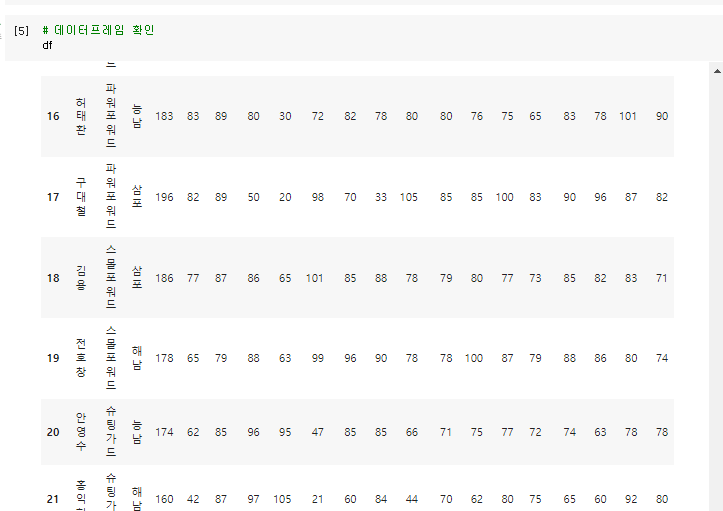
Google Colab 환경에서 진행.슬램덩크 플레이어 파일을 활용하여 강의 진행.https://docs.google.com/spreadsheets/d/1wmAQ8bWCZUMvNDz07IINuqQ-C_GYugTpeyCmB2DFS-o/edit판다스를 사용하기 위
2.[26일차]Pandas 입문 - DataFrame 파악하기
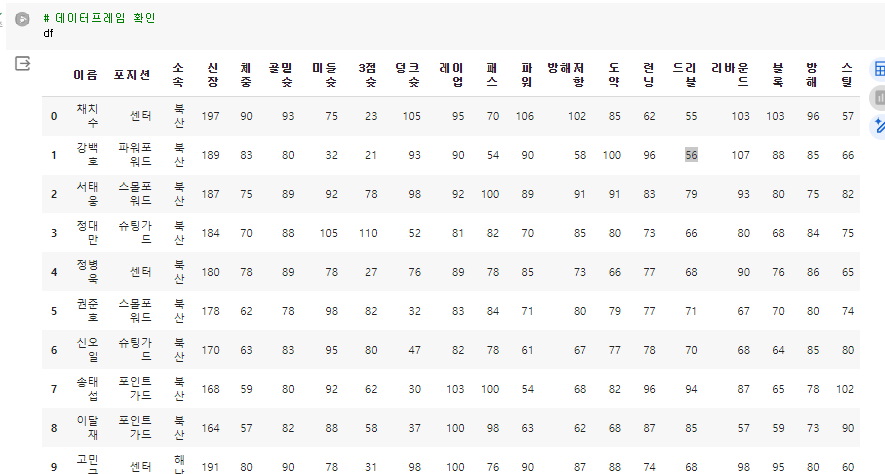
x축과 y축으로 구성된 2차원 테이블 구조로 엑셀과 흡사함. 데이터프레임 예시)해당 데이터를 확인할 때에 전체를 확인하기 보다는 특정 부분만 추출해서 간소화 하는 편이 메모리를 덜 잡아먹는다.아래와 같은 방법으로 진행해보자.info()는 각 데이터의 구성이 어떻게 되어
3.[26일차]Pandas 입문 - 행(row) 조회- index, slice, loc, iloc

series는 데이터를 1차원(한 줄)으로 볼 수 있는 것이다.Series는 Pandas를 사용하면서 계속해서 마주해야 되는 것 이다. 그렇기 때문에 자세히 살펴볼 필요가 있다.컬럼의 갯수Series는 컬럼이 1개, 데이터프레임은 1개 이상이다.series로 인덱스 레
4.[26일차]Pandas 입문 - 행(row) 조회- index, slice, loc, iloc
series는 데이터를 1차원(한 줄)으로 볼 수 있는 것이다.Series는 Pandas를 사용하면서 계속해서 마주해야 되는 것 이다. 그렇기 때문에 자세히 살펴볼 필요가 있다.컬럼의 갯수Series는 컬럼이 1개, 데이터프레임은 1개 이상이다.series로 인덱스 레
5.[26일차]Series가 중요한 이유

Series란 행 한줄 즉, 1차원 데이터를 구성하는 것이다.추출된 예시)1행 데이터 추출.이름 Series 추출.🔎헷갈릴 수 있는 point!행과 데이터를 조회할때는 loc.\[]대괄호를 사용열 데이터를 조회할때는 \[]대괄호만 사용.데이터 조회시 특정 부분을 볼
6.[26일차]기술통계 describe()
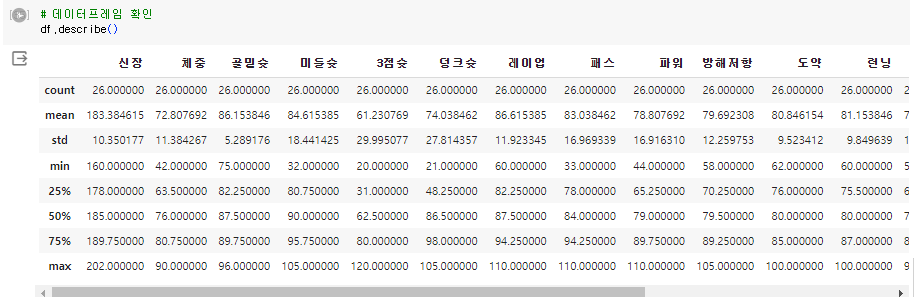
데이터 분석을 하다보면 통계를 만나는 경우가 종종 있다.Pandas에서 통계를 사용할 때는 통계를 지원하는 메소드 describe()를 사용한다.데이터의 분포, count 등의 정보를 파악할 수 있다.count - 갯수mean - 평균값std - 표준편차min - 최소
7.[26일차].str.contains()와 인덱싱을 이용한 문자 탐색
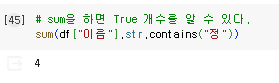
이전 글에서 Series를 잘 다뤄야 우리가 원하는 데이터를 쉽게 쉽게 찾아낼 수 있다고 얘기한적 있다.이번 글에서는 Series를 어떤식으로 다루는지 맛보기 형태로 알아보겠다.문자를 탐색할때 사용하는 contains 메소드에 대해 알아보자.contains 메소드는 문
8.[26일차]수치탐색과 산술연산
Pandas가 왜 데이터분석을 할때 편한지 경험해 보자.나는 180cm 이상인 사람을 추출하고 싶어.먼저 신장열을 추출해보자.기존 파이썬에서는 for문을 활용해 각 데이터 하나하나 180이상인 사람들을 추출해야 되지만 Pandas에서는 비교연산자 하나만으로도 간편하게
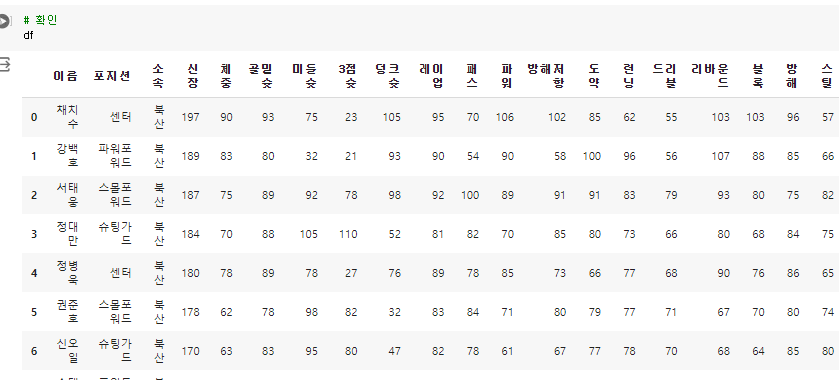
9.[26일차]별도의 DataFrame생성
이전 글에서는 기존의 데이터프레임의 데이터를 수정하는 것을 알아봤다.이번 글에서는 원본데이터 대신 별도의 데이터프레임을 생성하는 방법을 알아보자.2-1. 함수를 만들어 저장하는 방법.df_center 라는 이름의 함수에 넣을 수 있다.2-2. 연산 후 새로운 데이터프레
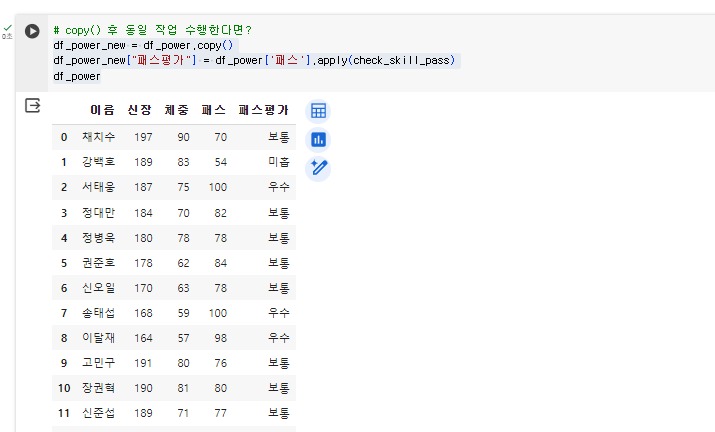
10.[26일차]행과 열 삭제(del, drop)
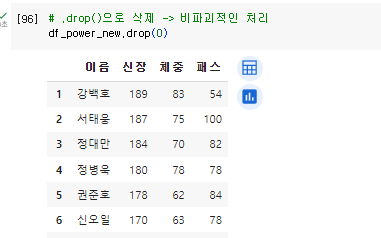
행과 열을 삭제하려면행,열을 타겟 후 삭제를 진행해야 된다.(당연한 소리!)이전에 copy()로 만들었던 df_power_new함수로 실습 진행.df_power_new에서 “패스평가” 열을 삭제해보자.→코드 앞에 del을 붙여주면 삭제 명령이다.del 이후 출력값 "
11.[26일차]열 이름 수정
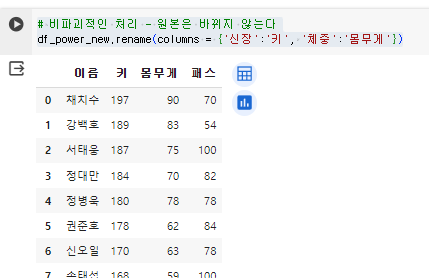
데이터 프레임을 조작하다보면 이름, 신장 등의 열이름을 바꾸고 싶어질때가 있다.이럴때 사용하는 메소드가 rename 이다.열 이름 변경 형태- .rename(columns = {'기존':'변경'}, inplace=True/False)rename의 docstring을 보
12.[26일차]정렬방법 (sort)
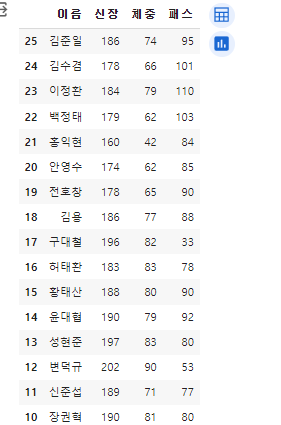
Pandas에서 데이터 정렬시.sort_index(), .sort_values() 두 함수를 주로 사용한다.두 함수 모두 기본적으로 비파괴적 처리를 한다. 물론 inplace = 인자값을 통해 파괴적으로 변경가능!인자에 기입된 열의 값을 기준으로 정렬신장을 기준으로 정
13.[26일차]피봇테이블(pivot table)
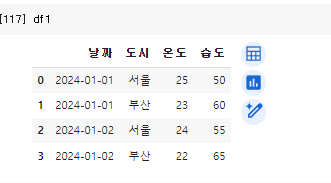
엑셀, 스프레드 시트의 피봇 테이블을 Pandas에서도 만들 수 있다.pandas 라이브러리에서는 pivot_table이라는 함수를 지원해준다.pivot_table(집계 하려는 함수명,values, index, columns, aggfunc)values: 집계하려는 열
14.[26일차]얕은 복사(Shallow Copy) vs 깊은 복사(Deep Copy)
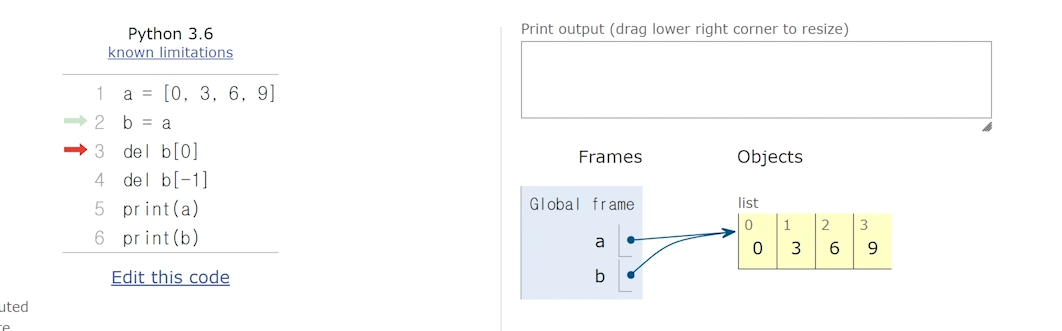
이전 글에서 copy() 함수를 다루는 중 얕은 복사, 깊은 복사를 언급했었다.이 두 단어에 대해 자세하게 알아보자. 복사 대상이 변경되면 원본도 변경된다.변수명만 달라진 개념얕은복사의 예시위의 함수를 통해 값이 어떤식으로 변환되는지 알아보자.1,2 번째 줄을 실행한
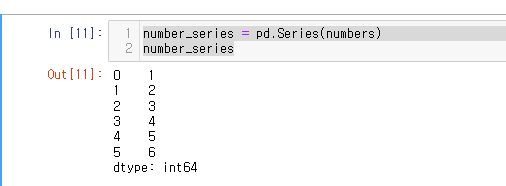
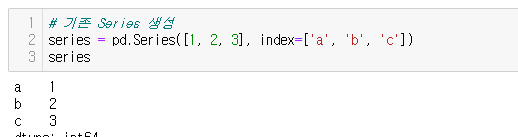
15.[27일차]Series 생성(Create)

27일차에서는 Series를 계속해서 다뤄볼 것이다.Pandas에서는 .Series메소드를 이용하여 Series를 생성할 수 있다. numbers 라는 list를 만든 후 이를 Series화 해보겠다.Series의 index는 인자값에 index = 를 넣어서 변환할
16.[27일차]Series 속성(Attribute)
속성이라 함은데이터 생성 이후 .int, .object 와 같이 어떠한 성질을 의미한다.pandas 라이브러리 참조숫자열과 문자열로 구성된 list 생성Series의 실행결과를 보면 가장 마지막 줄에 dtype을 확인할 수 있다..dtype 이란 시리즈가 반환하고 있는
17.[27일차]Series 메소드(Method)
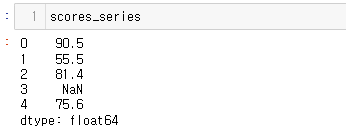
메소드란 객체안에 있는 함수를 말한다..함수() 의 형태로 사용.이번 글에서는 여러 메소드를 활용해볼 것 이다.1.pandas 라이브러리 호출2.scores라는 list를 만든 뒤 Series화 진행scores_series 출력값최대값 추출3번에서 결측치를 True의
18.[27일차] .round() - 반올림(사사오입 방식, 오사오입 방식)
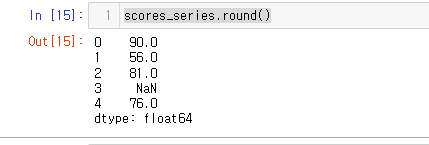
위와 같은 Series가 있다고 할 때 반올림을 해보자.결과🔎혹시 여기서 이상한 점을 발견하셨나요??0 인덱스 90.5 → 90.01 인덱스 55.5 → 56.0으로 변경이 되었습니다.둘다 반올림이 되어야 하는데 한쪽은 내림이 진행되었습니다. 왜 그럴까요?우리는 모두
19.[27일차]csv <> DataFrame 데이터 로드와 세이브
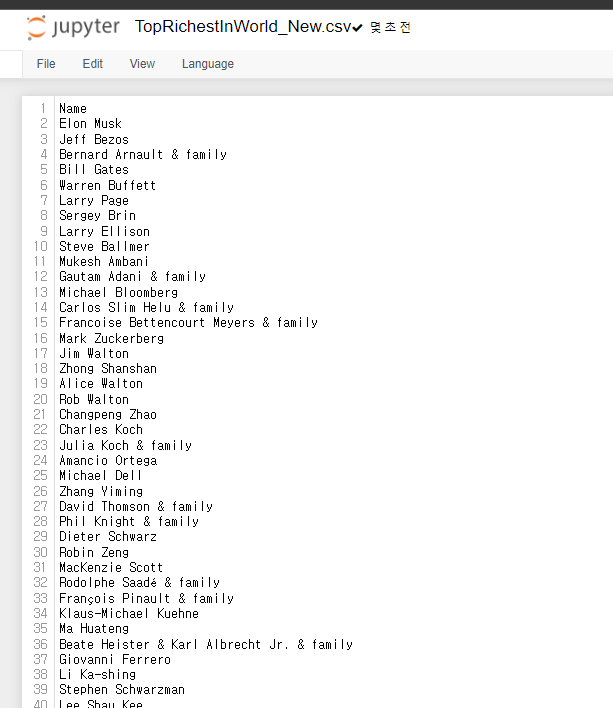
Kaggle 에서 부자들의 데이터를 가져와서 실습해보자링크:100 Richest People In WorldComma-Sperated Value컴마(,)로 값을 구분해놓는 방식 다운받은 csv파일을 주피터노트북에서 보면 컴마(,)들로 구분되어 있는것을 확인할 수 있다
20.[27일차]Series - 값 정렬(sort_values)
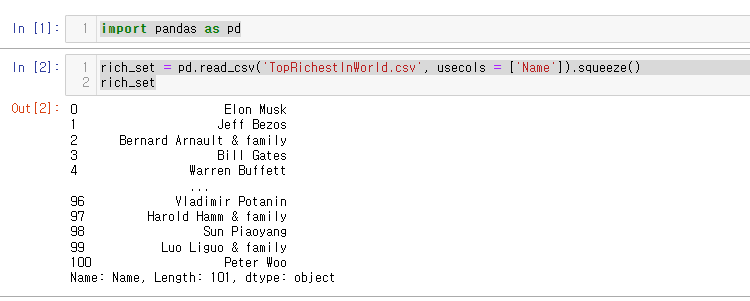
이전 글에서 값 정렬 함수sort_values에 대해 알아보았다.이번글에서 좀 더 심화하여 알아보자.1.판다스 라이브러리 참조이전글에서 다운받은 파일을 불러오는데 이름 컬럼만 Series형태로 가져온다.sort_values 는 기본적으로 오름차순을 보여줌.sort_va
21.[27일차]Series - 값 정렬(inplace=, 비파괴적vs파괴적)
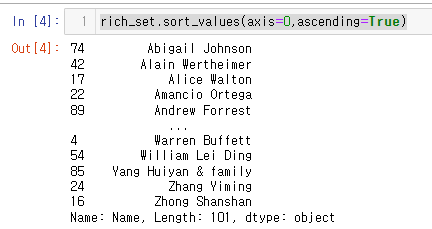
이번 글에서는 sort_values의 인자값 inplace에 대해 상세히 설명해보도록 하겠다.axis= : 축을 넣어준다.(데이터프레임에서 사용)ascending = : 오름차순을 의미 (True = 오름차순, False = 내림차순)Series 형태의 rich_set
22.[27일차]Series - 값 정렬(key=)
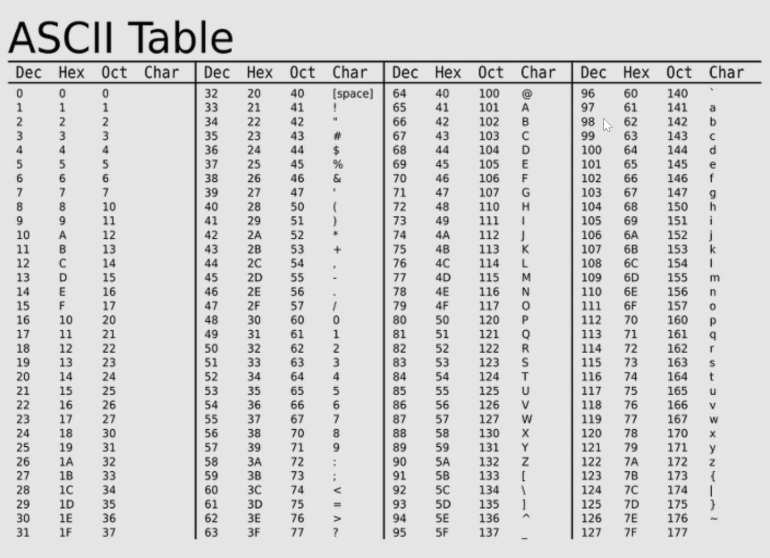
정렬에 필요한 크고 작음의 기준을 정한다.글자라면 A-Z순, 숫자라면 크고 작음key인자에 함수를 지정하면 되며, 잘 사용하려면 lambda에 익숙해야 한다.알파벳 정렬 기준은 보통 A-Z → a-z 순으로 진행된다.아스키 코드를 보면 소문자가 대문자보다 값이 크기 때
23.[27일차]Series - 값 세기(value_counts)
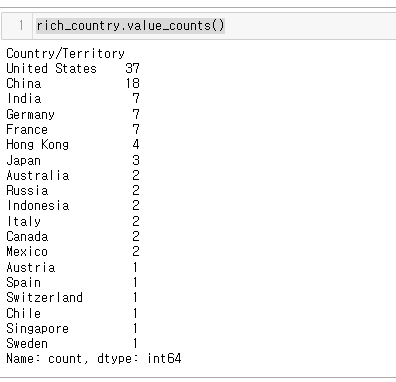
데이터 프레임 생성 : 'Country/Territory','Industry' 컬럼이 있는 rich_df 데이터 프레임과Series 생성 : 'Country/Territory’ 정보가 있는 rich_country Series를 생성해줬다.rich_country의 데이터
24.[27일자]Series - 인덱스 위치 기반 조회(Access, indexing, slicing)
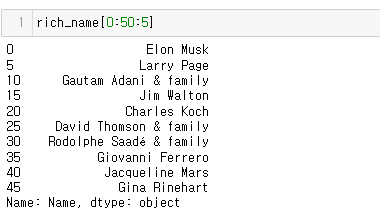
부자들의 이름을 가진 rich_name 함수를 만들어 줬다.인덱스 0 조회업로드중..이때 0~5번째 인덱스 넘버가 아닌인덱스 레이블의 개념으로0과 5인덱스 사이에 있는 인덱스를 가져온다고 이해하자.(0과 5도 포함)0과 50사이의 인덱스를 5의 배수로 추출
25.[27일차]Pandas index 주의사항
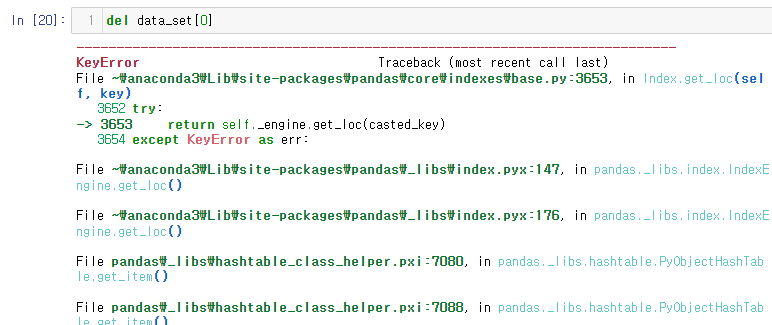
pandas에서 index는 파이썬에서의 index와는 다른 형태를 띄고 있다고 계속해서 설명했다.하지만 예외적으로 파이썬에서 사용되는 index 넘버가 쓰일때가 있는데,바로 index가 문자열일 경우이다.위와 같이 인덱스가 문자열인 Series를 만들었다.이후 인덱스
26.[27일차] Series-미션(과제!!)
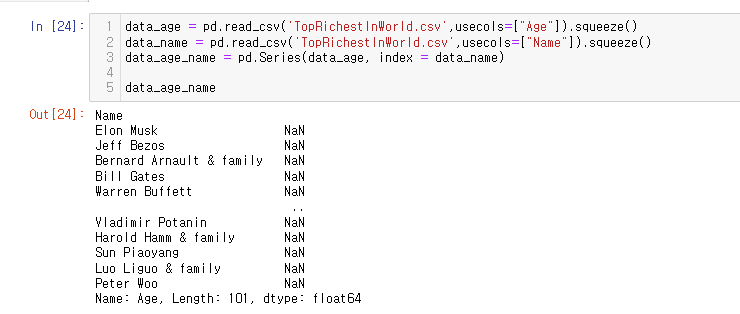
과제를 내주셨다...!각 제목들은 문제이며 내 스스로 풀어보았다.TopRichestInWorld.csv 파일 읽어오기TopRichestInWorld.csv 파일 읽어오기Industry 열만 사용 / usecols=\["Industry"] 사용시리즈화 / .squeeze
27.[28일차]DataFrame기초 - DataFrame생성(Create)
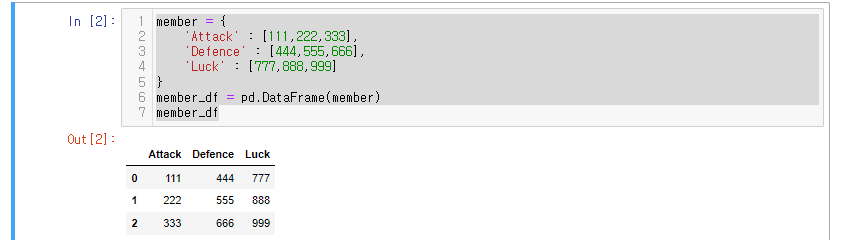
28일차에서는 DataFrame에 대해서 알아볼것이다.Series는 1차원 구조DataFrame은 2차원 구조axis = 0 : index 방향axis = 1 : columns 방향2개 이상의 Series로 구조먼저 실습 환경을 구축해 준다.판다스 라이브러리 참조mem
28.[28일차]DataFrame기초 - DataFrame속성(Attrs)
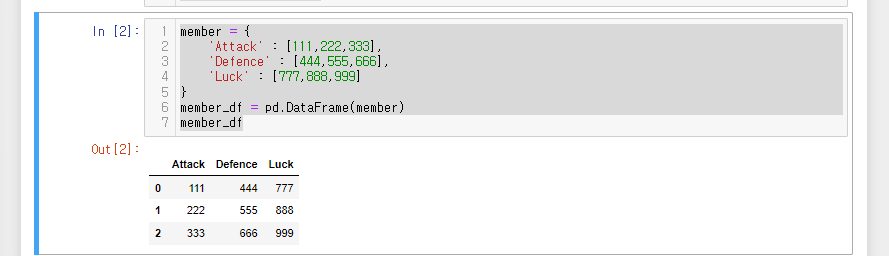
아래의 데이터 프레임을 통해 속성값을 알아보자.크기를 봐주는 함수shape : (n x a)의 형태size : 셀의 갯수를 확인축을 확인해주는 함수즉, 인덱스 정보와 열 정보를 확인할 수 있다.인덱스 정보 : Index(\['Spencer', 'Tommy', 'Urie
29.[28일차]DataFrame기초 - DataFrame메소드(Methods)

DataFrame에서 자주 사용되는 메소드에 대해서 알아보자보통 집계함수를 많이 쓴다!위와 같은 데이터프레임을 만들어 주었다.sum은 각 컬럼별 합계를 집계해준다.출력값이 Serise 형태인데 그럼 여기서 한번더 sum() 메소드 사용이 가능하지 않을까?맞다. 가능하다
30.자주 사용되는 집계함수 목록

min : 최소값max : 최대값sum : 합계mean : 평균median : 중앙값count : 비결측치의 개수value_counts : 각 값의 빈도describe : 요약 통계량mode : 최빈값srd : 표준편차var : 분산prod : 곱셈quantile :
31.[28일차]DataFrame기초 - 정보와 요약(info, describe)
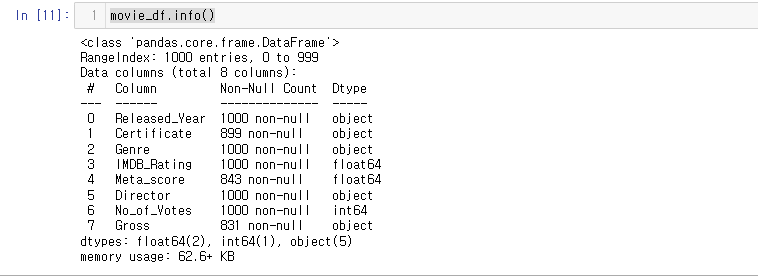
이번 글에서는 실제로 데이터를 다뤄볼 예정이다.IMDB Movies Dataset캐글의 인터넷 영화 데이터베이스 파일을 토대로 진행해 보자!해당 파일의 데이터와 사용 용도 예시는 아래와 같다.파일을 불러왔다.불필요한 열이 있기에 필터링 작업을 해주자.먼저 컬럼으로 사용
32.[28일차]DataFrame기초 - 집계함수와 인자
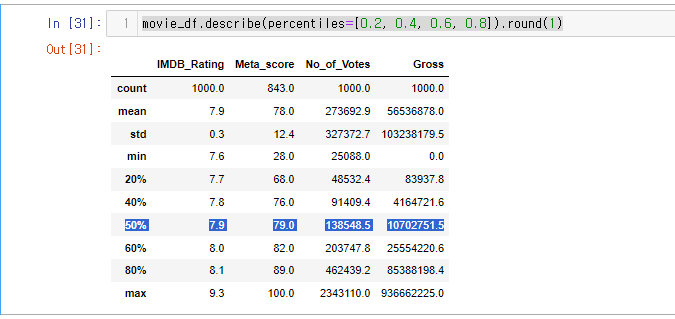
집계함수 관련 인자에는 아래와 같은 값들이 있다.\*\*percentiles=, numeric_only=, include=\*\*백분위수를 확인할 수 있다..describe()사용시 나오는 25%,50%,75%를 커스터 마이징 하는 개념percentiles= 에는 리
33.[28일차]DataFrame기초 - 정렬
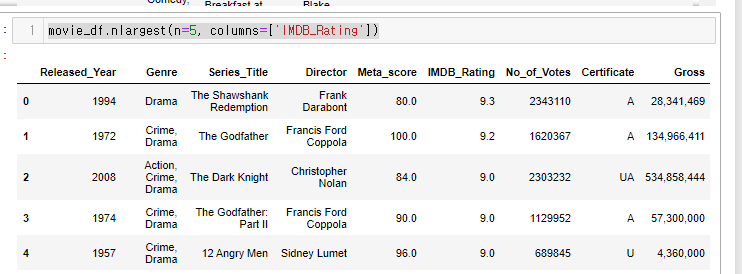
데이터 프레임에서도 이전에 Series에서 배웠던 sort_values를 사용할 수 있다.이번에는 추가적으로 \*\*nlargest, nsmallest 를 배워보도록 하겠다.가지고 오고자 하는 컬럼파일 읽기+컬럼 조정기준 컬럼을 정해서 내림차순 정렬문법 : df.\*
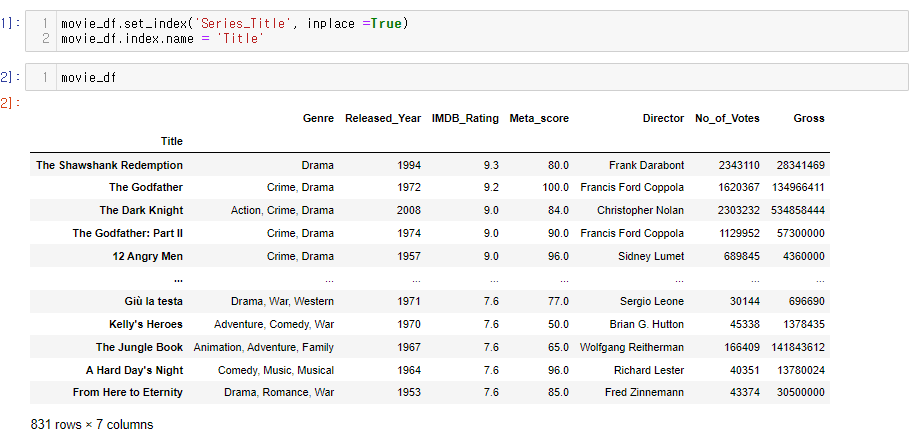
34.[28일차]DataFrame기초 - 인덱스 제어
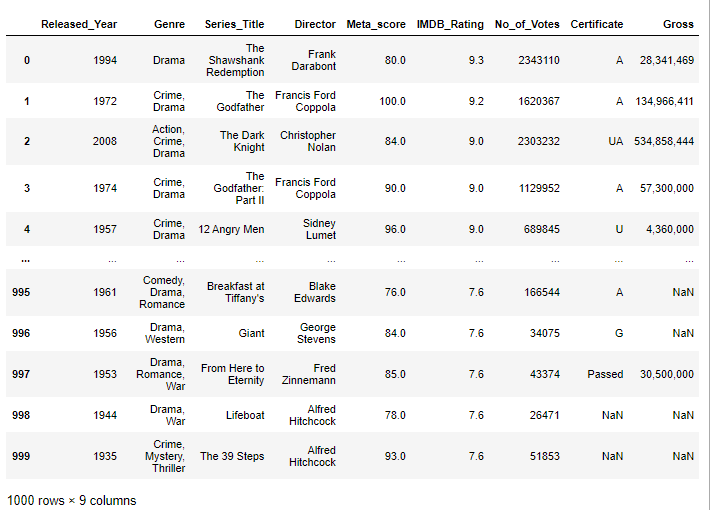
인덱스를 제어하는 함수와 인자를 살펴보자\*\*set_index, reset_index, drop=\*\*인덱스를 세팅하는 메소드특정 열을 인덱스로 설정하는 기능을 제공‘Series_Title’ 컬럼을 인덱스로 세팅해보자wow\~~컬럼이 인덱스로 이동하는 개념이기 때문
35.[28일차]DataFrame기초 - 행렬삭제
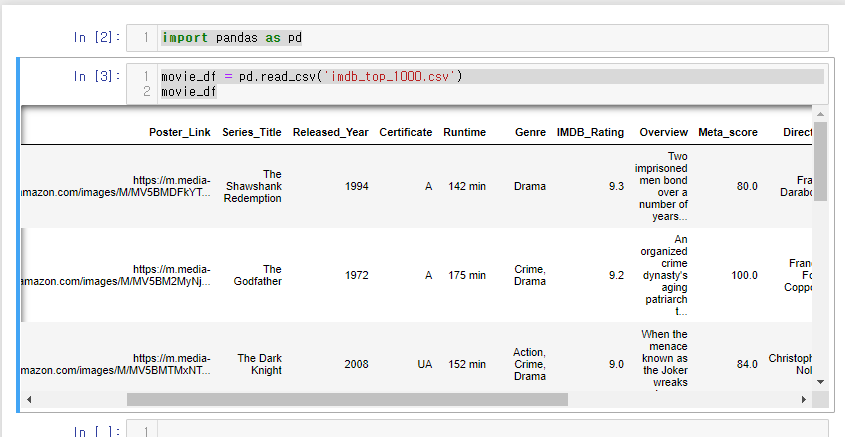
이번 실습은 행렬 삭제이기 때문에 전체 데이터를 가져오겠다.불필요한 컬럼을 삭제해 보자.요렇게 사용하면 'Poster_Link','Overview' 컬럼이 삭제된다.단 .drop은 기본적으로 비파괴적이기 때문에 inplace = True 인자값으로 데이터를 저장할 수
36.[28일차]DataFrame기초 - 열조회와 추가(get, insert)
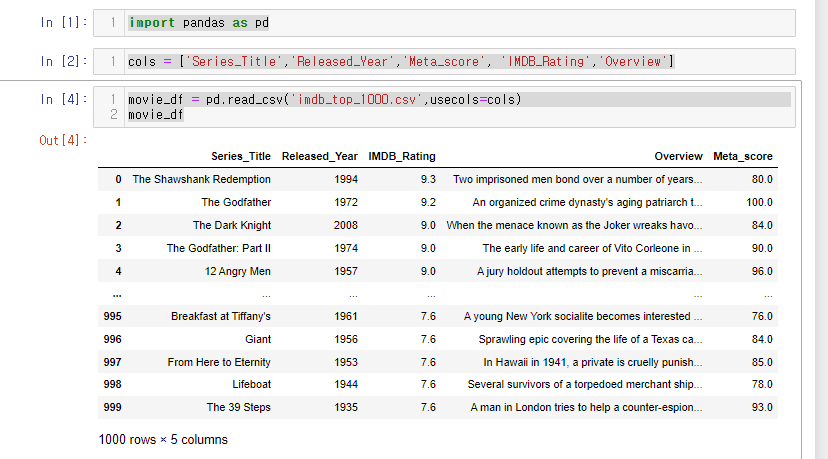
지금까지 컬럼 조회는 아래의 방법들로 구성했다.단일열 (Series)다중열(Df) 없는열을 조회하면 오류가 발생 이때 get() 함수를 사용해서 조회하면 오류가 뜨지 않도록 할 수 있다.사용방법은 조회하고자 하는 컬럼을 인자에 넣어주면 된다.이때 없는 컬럼을 넣어도
37.[28일차]DataFrame기초 - 결측치 제어(dropna)
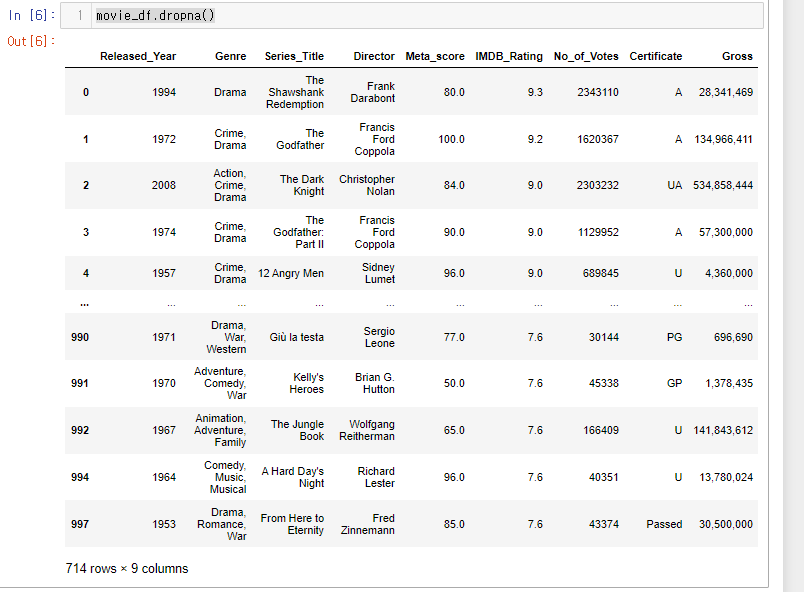
NaN 유형 데이터를 drop(삭제) 시킨다.axis 값이 기본적으로 0(인덱스) 이기 때문에 NaN이 있는 인덱스를 다 지운다.결측치가 있는 인덱스가 지워져 714행밖에 남지 않은 모습.axis = 1 로 처리하면 결측치를 가지고 있는 컬럼들이 삭제된다.how=NA
38.[28일차]DataFrame기초 - 결측치 제어(fillna)
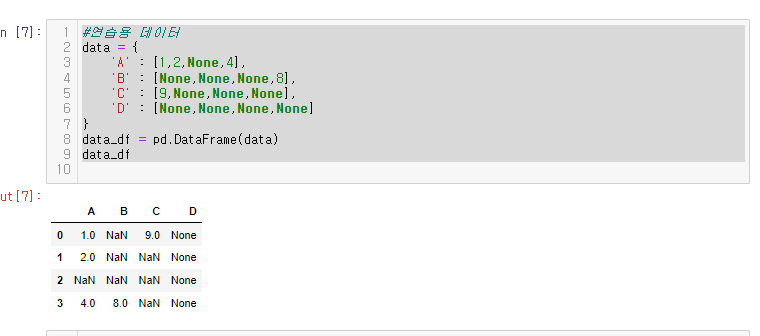
결측값을 다른 값으로 변경해준다.연습용 데이터 data_df 의 결측값을 0으로 바꿔보자. ='ffill' : 결측치를 이전에 있던 인덱스 레이블 값으로 대체 기존 연습용 데이터의 모습과 비교해보면 이전 인덱스 레이블 값을 가져온것을 알 수 있다. 연습용 데이터=’bf
39.[28일차]DataFrame기초 - 과제
Untitled아래 순서로 열이 정렬되어야 된다.UntitledUntitled각 dtype과 null 여부를 확인한다.UntitledUntitledMeta_score는 NA여도 삭제하지 않는다.UntitledUntitled부연설명Untitledmean() 의 인자 중
40.[28일차]DataFrame기초 - 과제 응용!조회(인덱스에서)
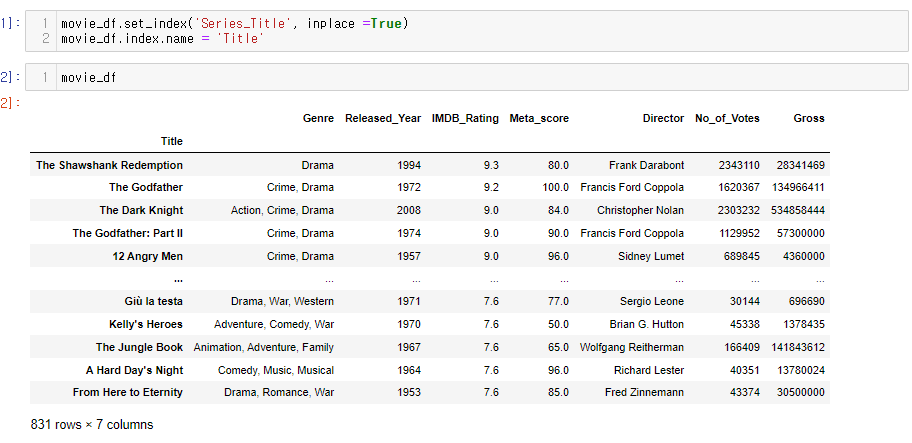
지금까지 컬럼에서 조회를 진행하였다면 이번 글에서는 인덱스를 기준으로 조회를 진행해보자.파일과 필요 컬럼을 가져온다.이후 영화 제목 컬럼을 인덱스로 만들어 준다.이전에 Series 글에서도 사용했던 .col 함수이다.The Godfather 이라는 인덱스(영화제목)를
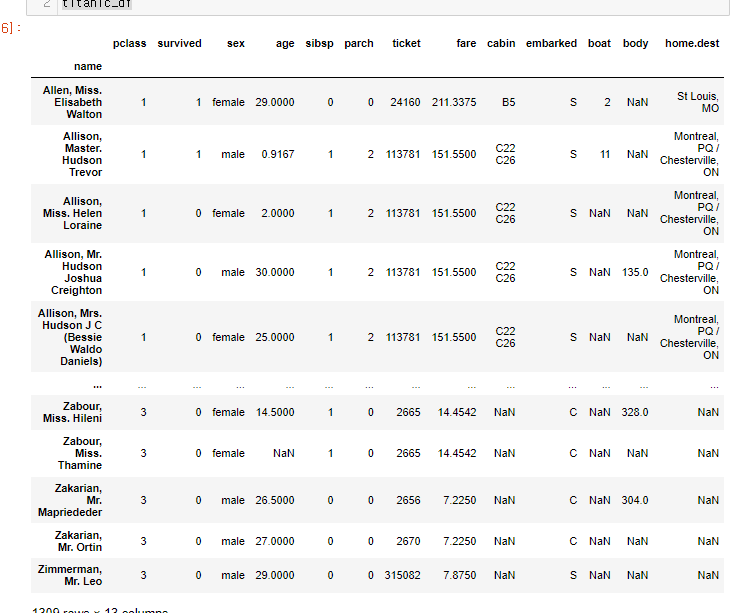
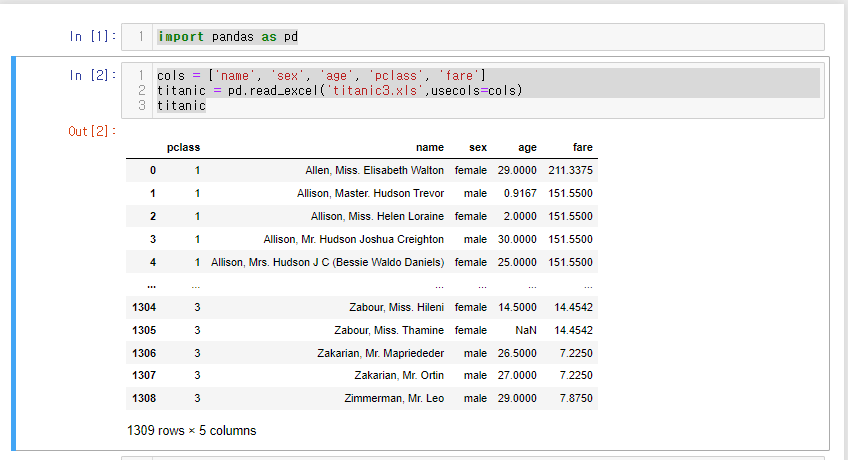
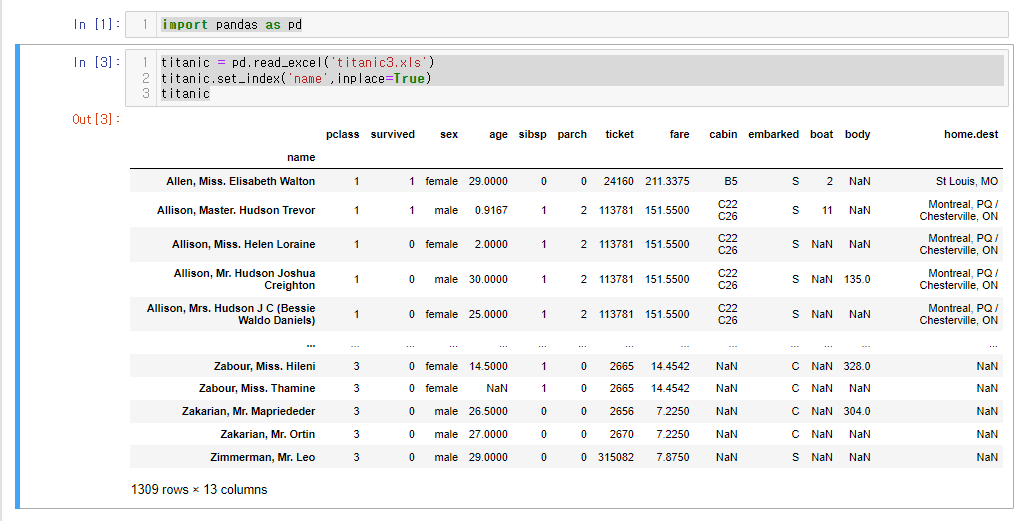
41.[28일차]DataFrame활용 - 1. 데이터셋 확인하기 - 타이타닉
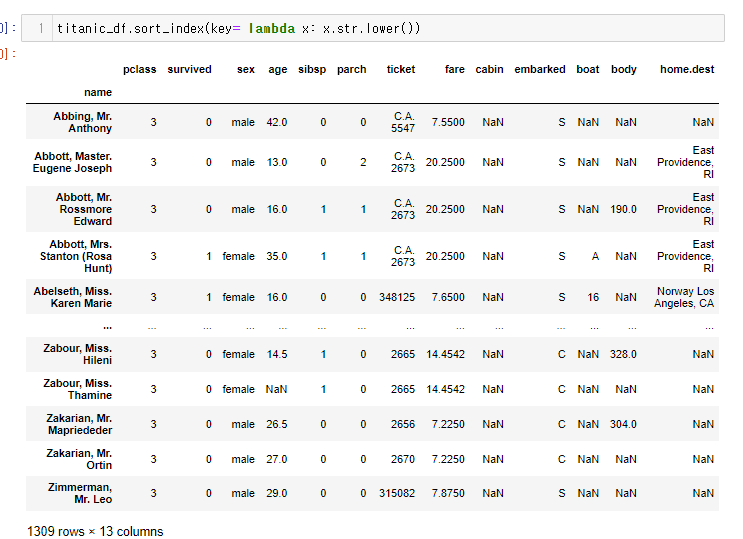
https://www.kaggle.com/datasets/vinicius150987/titanic3캐글에서 타이타닉 데이터를 활용해서 데이터셋 확인 실습을 해보자.헷갈리는 단어여기서 특성 엔지니어링이란?불쾌지수와 같이 수치로 나타내기 애매한 지수를 특성을 기준
42.[28일차]DataFrame활용 - 행조회
.loc 을 사용할 예정.인덱스 레이블로 행 조회메소드가 아닌 속성.loc\[] 는 주로 레이블을 기반으로 행과 열에 접근하는 데 사용되지만, boolean 배열과 함께 사용할 수도 있다..loc 입력방법하나의 레이블5 또는 ‘a’ (5는 인덱스 레이블로 해석되며 파이
43.[28일차]DataFrame활용 - 행의 열 조회(loc)
여기서 데이터 프레임 형태로 만들기 위해서는 데이터 레이블 부분도 리스트처럼 묶어줘야 된다.두 사람을 리스트화 후 .loc에 넣어주었다.이후 가족임을 연관지을 수 있는 컬럼들도 보이도록 했다.연관성 100%!!아마 쌍둥이같다..
44.[28일차]DataFrame활용 - 인덱스 위치 기반 행과 열 조회(iloc)
인덱스 넘버 개념을 사용할 수 있는 iloc 을 이용해서 데이터를 추출해보자.두 차이는 계속해서 말했듯이 인덱스 레이블과, 인덱스 넘버링 차이이다.그 차이를 알기 위해 0번 레이블을 삭제 후 진행해 보자.loc 의 경우 오류가 뜬다.0번 레이블이 없어졌기 때문에..il
45.[28일차]DataFrame활용 - 서로 다른 차원 배열 연산(Matching, Broadcasting)
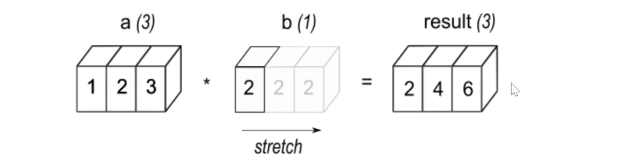
Pandas에서 DataFrame 또는 Series의 모양이 다른 경우에 연산이 가능하도록 모양을 처리하는 방법을 말한다.크기나 모양이 다를 때의 처리 방식을 정하는 것.(차원이 다를때)a(컬럼 3개)와 b(컬럼 1개) 차원이 다른 두 값이 있다.이때 b를 스트레칭 해
46.[28일차]DataFrame활용 - 조건문(Conditional Statement) + 퀴즈
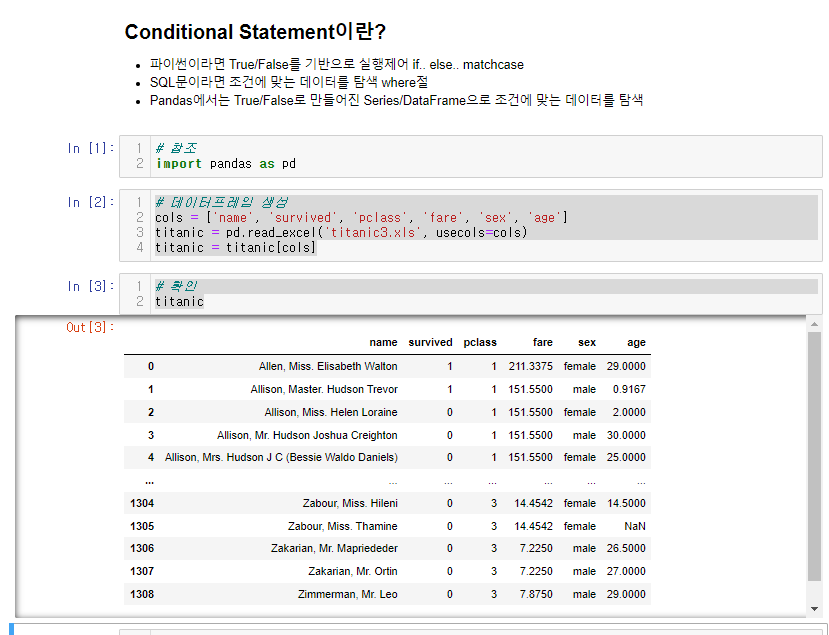
조건문을 영어로 한 것ㅎㅎ파이썬이라면 True/False를 기반으로 실행제어 if…else..matchcaseSQL문이라면 조건에 맞는 데이터를 탐색 where절Pandas에서는 True/False로 만들어진 Series/DataFrame으로 조건에 맞는 데이터를 탐색
47.[28일차]DataFrame활용 - 범위 지정 필터링(between 메소드)
\*\*between()\*\*Series의 메소드주어진 범위 안에 있는 요소를 가진 불리언 시리즈(Boolean Series)를 반환하는 메소드주어진 시리즈(Series)의 각 요소가 left와 right 사이에 있는 경우에 해당하는 위치에 True를 포함하는 불리언
48.[28일차]DataFrame활용 - 결측치 필터와 처리(isin, isnull, isna, notnull)

이번에는 결측치를 이용해서 마스크를 만들어보자.\*\*Series.isin(values)\*\*파이썬의 in과 비슷한 개념• 1 in \[1, 2] 2 in \[1, 2] 모두 True가 나옴.isin 메소드를 사용하여 각 요소가 특정 값들에 속하는지 여부를 확인할 수
49.[28일차]DataFrame활용 - 행렬 인덱스 네이밍 변경(rename)

인덱스 열 이름, 컬럼 이름을 변경해보자titanic 컬럼을 조회해 보자속성을 보면 컬럼명들도 index 로 되어있는 것을 볼 수 있다.그렇기 때문에 컬럼명을 변경할 때이런식으로 변경을 하려고 한다면 에러가 발생한다.인덱스는 지원하지 않는다는 에러가 뜸..rename(
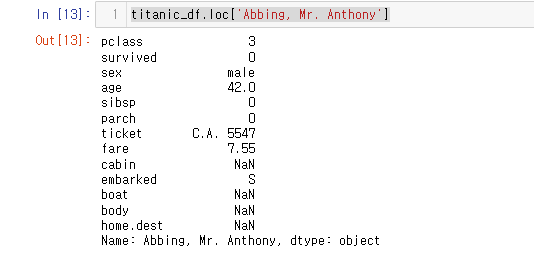
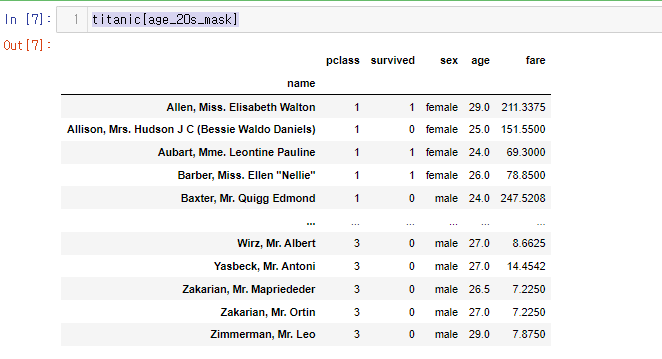
50.[28일차]DataFrame활용 - 과제!
name열이 index로 설정home.destembarkedsibsp원본에 반영parch살아있는 사람은 시신 식별번호가 없는 것은 당연사망자가 809명인데, 식별번호가 없는 명단이 688명이나 된다.notfound_list3등급(하류층)이 많으나, 이건 당연할 수 있다
51.[29일차]DataFrame심화 - 데이터셋 확인하기
데이터를 판다스로 가져온다.데이터의 정보를 확인한다. .info()데이터의 통계를 확인한다. .describe()\*\*DataFrame심화 파트에서는\*\*캐글에서 고객 성격에 대한 데이터 셋을 가져와서 진행하겠다.Customer Personality Analysis
52.[29일차]DataFrame심화 - DataFrame과 Series 각 데이터 함수적용(apply)
데이터 가져오기아래의 사진을 보면 업데이트는 2021년8월23일 기준으로 되었다.즉, 2021에서 탄생년도를 빼면 나이가 나온다.이를 insert 메소드로 새로운 컬럼 추가.구분은 위의 표와 같다.이를 함수를 통해 구분지어보자.(age)에 나이가 들어가면 구분을 해주는
53.[29일차]DataFrame심화 - Series값 매핑(map)과 DataFrame요소 함수적용(applymap)
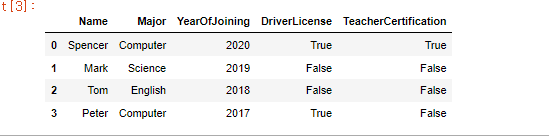
apply() 메소드 외에도 map() 메소드로 함수를 적용할 수 있다.참고로 map() 함수는 파이썬의 map처럼 생각하면 안된다!딕셔너리 형태로 사용되기 때문에 실습을 통해 더 자세히 알아보자.DriverLicense 컬럼을 보면 아래와 같다.이를 map() 메소드
54.[29일차]DataFrame심화 - 타입 변환(astype)
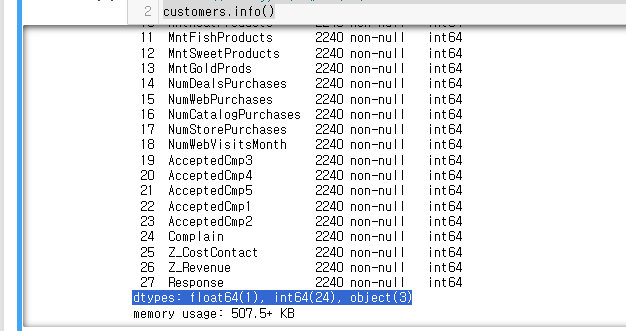
타입 변환시 데이터 프레임의 메모리 크기가 어떻게 달라지는지 보자.또 최적화는 어떻게 진행하는지 알아보자.데이터 하드웨어 저장공간을 줄이기 위해서는 아니다.단지, 연산시 메모리 사용이 기하급수적으로 늘어나기 때문이다.그렇게 되면 상대적으로 적은 캐시 메모리 사용 공간
55.[29일차]DataFrame심화 - 값 교체(replace)
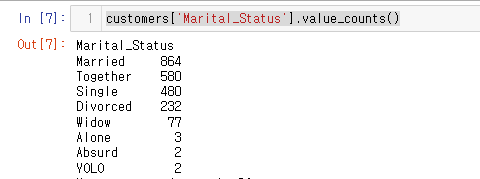
값을 교체하는 replace 메소드를 한번 더 보자~현재 데이터를 확인하면 결혼 상태 컬럼이 다양함을 알 수 있다.총 8가지로 무엇을 뜻하는지 알아보자.이 중 Alone, Absurd, YOLO는 해석에 애매한 부분이 있다.해당 데이터의 토론에도 이슈가 있으며YOLO같
56.[29일차]DataFrame심화 - 조건식(where)
이번에는 조건식을 where() 메소드를 사용해보자.조건에 맞는 데이터가 아니면 결측치를 반환이를 dropna()와 응용해서 결측치인 컬럼을 모두 삭제할 수 있다.other = 메소드는 fillna 메소드와 같이 결측치로 나온값을 다른 값으로 반환하는 인자이다.결측치
57.[29일차]DataFrame심화 - 여러 집계함수 동시 적용(agg)
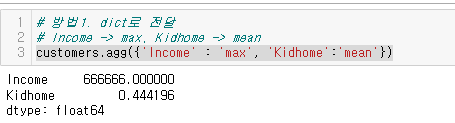
이전에 통계를 확인할 떄에는 describe()메소드를 사용했었다.이번 글에서는 .agg() 메소드를 이용해 데이터를 집계해보자.지정된 축(axis)을 기준으로 하나 이상의 연산을 사용하여 데이터를 집계(aggregate) 하는 기능을 제공func : function,
58.[29일차]DataFrame심화 - 데이터프레임 복제와 일치확인(copy, equals)

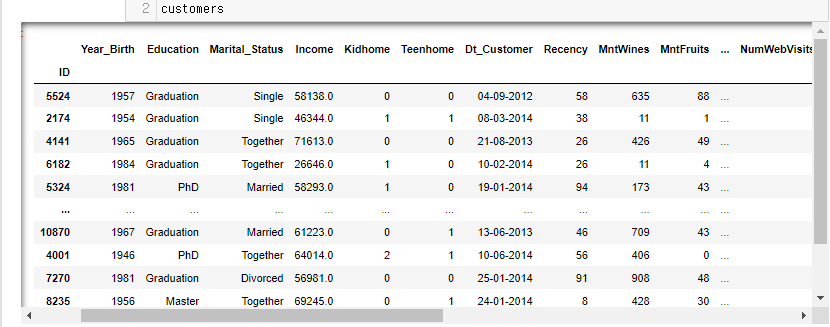
copy()를 좀 더 심화해서 이해해보자.customers 데이터 프레임을 카피한 customers_copy 데이터 프레임을 만들었다.이 두 데이터의 주소와 값을 비교해보자.주소 비교시에는id() 메소드를 사용한다.컴퓨터 메모리 주소를 숫자형으로 반환.주소가 서로 다르
59.[29일]DataFrame심화 - 멀티인덱싱(Multi-indexing)⭐😨⭐
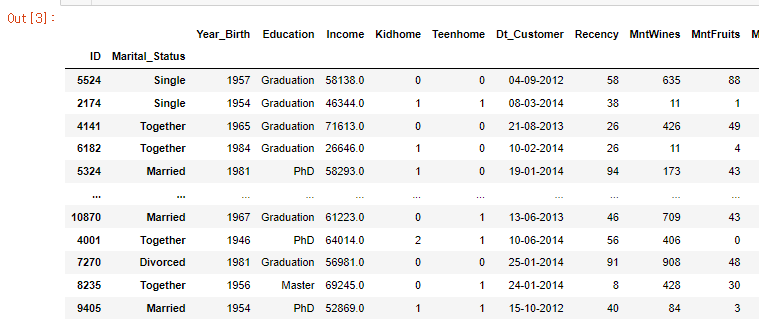
29일차에서 아주 중요한 내용!\*\*멀티인덱싱이란 인덱스가 여러개 라는 의미를 가지고 있다.\*\*https://pandas.pydata.org/docs/reference/api/pandas.MultiIndex.html- 하나 이상의 인덱스 레벨을 가지는 인
60.[29일차]DataFrame심화 - 과제
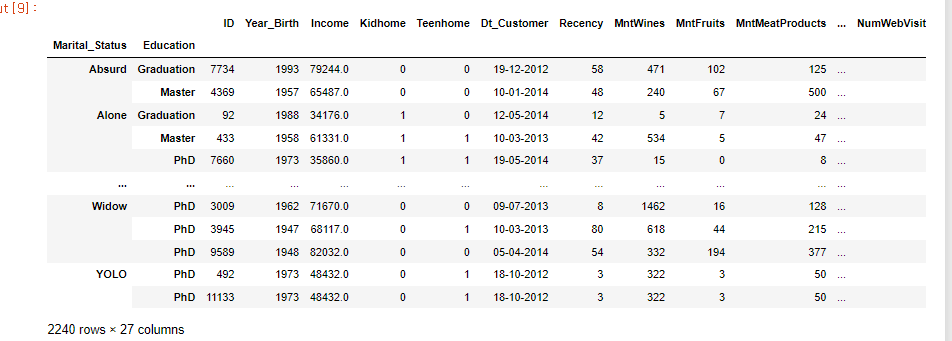
multi_index : 'Marital_Status', 'Education' 순풀이또는코드가 잘못된 건 아닌데, 멀티 인덱싱 정렬이 안되서 경고가 뜬다.데이터프레임의 인덱싱 성능이 저하될 수 있기 때문에 경고가 발생.때문에 정렬이 필요하다.풀이 : 컬럼 열도 해주는
61.[29일차]판다스 쉬어가기~Pandas Cheat Sheet

판다스의 모든것을 두 페이지에 정리된 시트~
62.[29일차]판다스 쉬어가기~Pandas Cheat Sheet
판다스의 모든것을 두 페이지에 정리된 시트~
63.[해커랭크]Contest Leaderboard
https://www.hackerrank.com/challenges/contest-leaderboard/problem?isFullScreen=true문제를 요약하자면점수테이블과 참가자 테이블이 있다.같은 문제를 여러번 풀 수 있고 이는 점수테이블에 저장된다고
64.[30일차]문자열 제어 - .str의 메소드(upper, lower,)
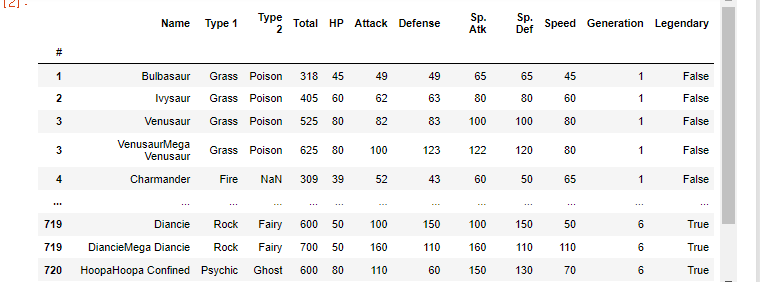
str() 메소드에 대해 알아보자.이번 실습은 포켓몬 특성을 가지고 있는 데이터를 가지고 진행해보자.Pokemon with statshttps://pandas.pydata.org/docs/reference/api/pandas.Series.str.html.str
65.[30일차]문자열 제어 - .str의 메소드(slicing)
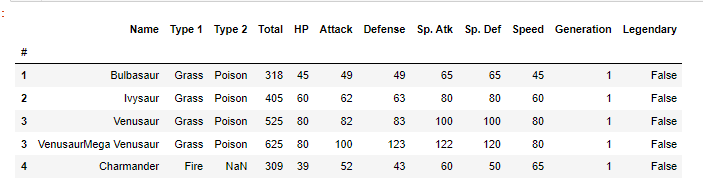
데이터의 글자를 조금만 따오는 방법이 있다.위와 같은 데이터 프레임의 ‘Name’ 컬럼은 너무 길기 때문에 슬라이싱 기법으로 특정 부분만 따와보자.이렇게 .str 앞에 메소드 사용없이 대괄호로 슬라이싱 처리를 해주면 해당 문자 부분만 추출해준다.1번째부터 5번째까지 추
66.[30일차]문자열 제어 - .str의 메소드(contains)
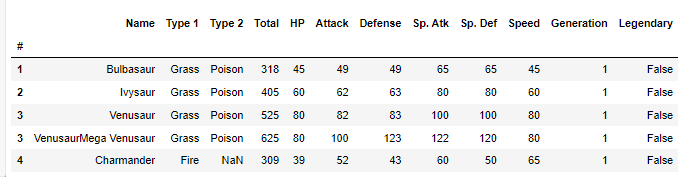
문자열을 조회 해주는 contains 메소드이다.\*\*Series.str.contains(pat, case=True, flags=0, na=None, regex=True)\*\*문자열 Series 또는 Index에서 주어진 패턴 또는 정규식이 포함되어 있는지 확인주어
67.[30일차]문자열 제어 - .str의 메소드(startswith, endswith)

시작되는 문자, 끝나는 마지막 문자를 조회하는 startswith,endswith 메소드를 알아보자.❗물론 이런 과정은 뒤에서 배운 contains 에서도 정규표현식을 이용해 사용할 수 있다.첫글자가 Q를 조회 ^표시 : .str.contains('^Q')마지막 글자
68.[30일차]문자열 제어 - .str의 메소드(replace)
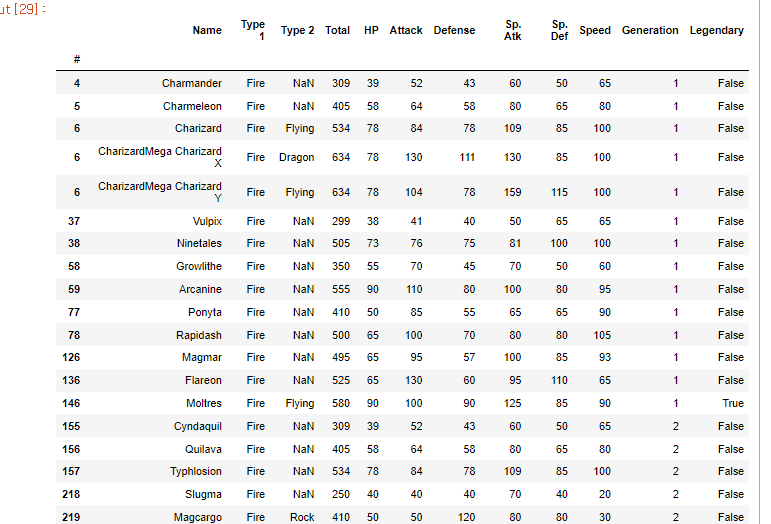
문자열을 변경해주는 replace 메소드 이다.속성값이 Fire인 포켓몬을보면 아래와 같이 확인할 수 있다.원본데이터는 안건들고 실습을 수행해보자카피 데이터프레임을 만든 뒤,replace 함수를 이용해 Fire 를 Flame으로 변경하였다.잘 바뀌었나 확인해보자.아주
69.[30일차]DataFrame재구성 - 행렬 전치(transpose)
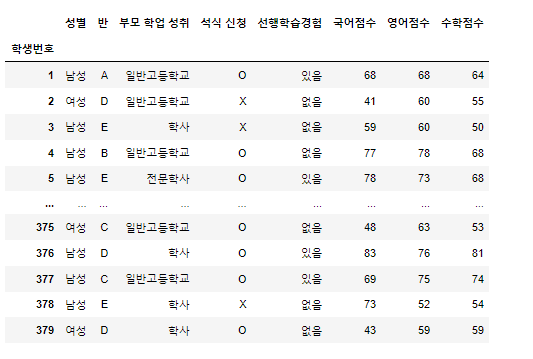
데이터 프레임 구조가 너무 넓게(컬럼이 많다) 되어 있거나 너무 길다(인덱스가 많다.)그럴때 내가 원하는 모습으로 재구성할 수 있다.앞으로의 실습은 아래의 데이터를 가지고 진행할 것이다.가볍게 훑어보자sample1.csv - 학업성취도 총379개의 데이터로 한 학교
70.[30일차]DataFrame재구성 - 인덱스 레벨 제어(stack, unstack, droplevel)
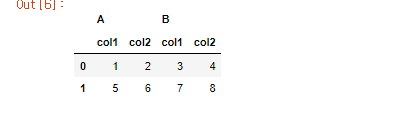
stack : 쌓아간다? 뭘 쌓는다는 걸까?기존 컬럼 또는 로우 값을 다른 곳으로 이동하여 쌓는다~데이터프레임의 구조를 재조정하는 데 유용columns에 다중 인덱스가 있는 데이터프레임에서 사용하면 컬럼 인덱스가 로우 인덱스의 레벨로 이동.컬럼을 로우로 "압축"하는 작
71.[30일차]DataFrame재구성 - 재구조화(melt)
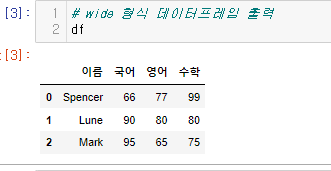
https://pandas.pydata.org/docs/reference/api/pandas.melt.html넓은 형식으로 구성된 데이터프레임을 긴 형식으로 변환하여 데이터를 재구성함수를 사용하면 하나 이상의 열을 식별자 변수(id_vars)로 설정하고, 나머
72.[30일차]DataFrame재구성 - 재구조화(melt)
https://pandas.pydata.org/docs/reference/api/pandas.melt.html넓은 형식으로 구성된 데이터프레임을 긴 형식으로 변환하여 데이터를 재구성함수를 사용하면 하나 이상의 열을 식별자 변수(id_vars)로 설정하고, 나머
73.[30일차]DataFrame재구성 - 피봇과 피봇테이블(pivot, pivot_table)
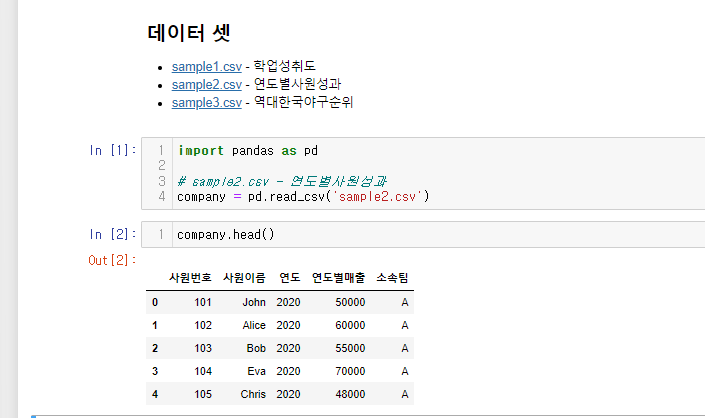
이전 글에서 설명했던 melt()와는 반대되는 피봇에 대해 알아보자실습 데이터는 아래와 같다.long형 데이터를 내가 보고싶은 데이터만 가지고 wide하게 만들어데이터를 보기 더 편하게 만듦 연도를 기준으로 사원들의 연도별매출 피봇사람을 기준으로 연도별 매출 피봇‘이
74.[30일차]DataFrame재구성 - 그룹화(groupby) 생성방법과 단일 열 그룹화
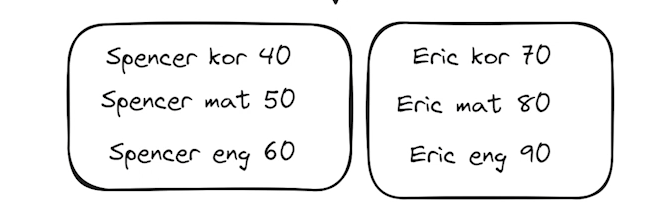
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.groupby.htmlhttps://pandas.pydata.org/docs/reference/api/pandas.Series.groupby
75.[30일차]DataFrame재구성 - 그룹화(groupby) 다중 열 그룹화와 agg()와 연계
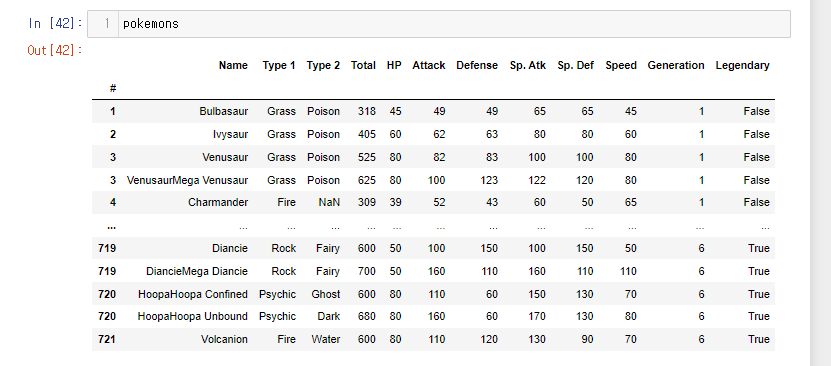
지난 글과 마찬가지로 포켓몬 데이터를 가지고 groupby 실습을 진행해보자Type 1 과 Type 2를 그룹지어보자dropna=False : Type 2가 결측치 인 것도 있기때문에 False로 처리확인해 보면 멀티인덱스가 튜플로 처리되어 있다.타입별로 묶여서 확인이
76.[30일차]DataFrame재구성 - 과제
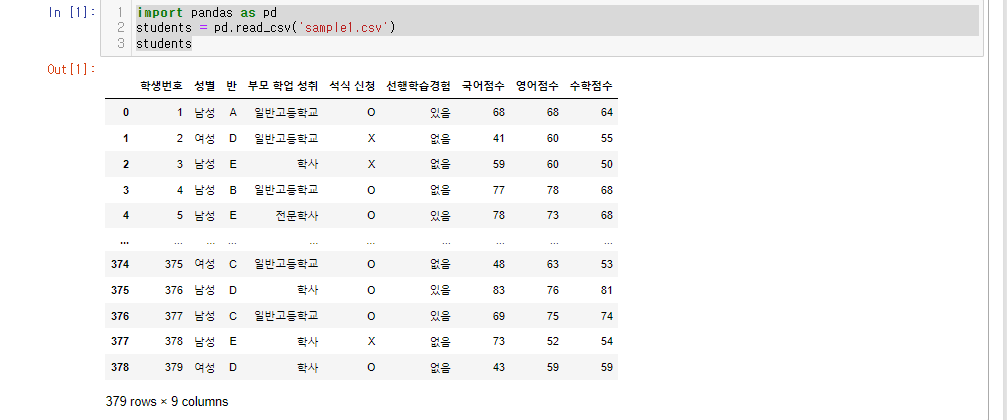
sample1.csv - 학업성취도다른 풀이이렇게 더해도 된다.'반'과 '석식 신청'을 기준으로여기서 값이 잘 들어왔나 확인시 get_group 메소드를 사용A반 중 석식O신청자agg()를 이용해보자count, median, max, min, mean다른풀이아 나는 총
77.[30일차]시계열 제어 - 날짜와 시간(Timestamp)
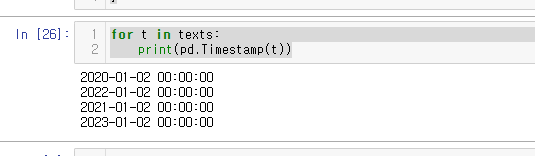
https://pandas.pydata.org/docs/reference/api/pandas.Timestamp.html날짜/시간 표현하는 데이터인자와 인자 입력방법이 많아서 실습하며 인자 활용법을 배워보자시간을 아주 자세하게 표시! 년 월 일 시간 분 초 단위
78.[30일차]시계열 제어 - 날짜와 시간(DatatimeIndex)
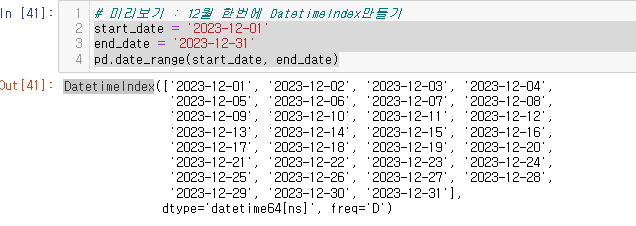
https://pandas.pydata.org/docs/reference/indexing.html- https://pandas.pydata.org/docs/reference/api/pandas.DatetimeIndex.html- 날짜와 시간 데이터를
79.[30일차]시계열 제어 - 날짜와 시간(DatatimeIndex)
https://pandas.pydata.org/docs/reference/indexing.html- https://pandas.pydata.org/docs/reference/api/pandas.DatetimeIndex.html- 날짜와 시간 데이터를
80.[30일차]시계열 제어 - 날짜 범위 생성(date_range)

이전글에서 잠시 만져보았던 date_range() 에 대해 알아보자!https://pandas.pydata.org/docs/reference/api/pandas.date_range.html날짜 범위를 생성하는 함수시작일, 종료일, 날짜 간격시작 날짜를 지정문자
81.[30일차]시계열 제어 - 기간과 기간 인덱스

\*\*특정 시간(Timestamp) vs 기간(Period) vs 기간인덱스(PeriodIndex)\*\*이 세가지 메소드를 비교 해보자 .\*\*Period()\*\* 는 저번 시간에서 본 인자랑은 다른 내용이다.몇시 몇분 몇초를 의미출력값 : Timestamp('
82.[30일차]시계열 제어 - 간격과 간격 인덱스(시간차)

https://pandas.pydata.org/docs/reference/api/pandas.Timedelta.htmlhttps://pandas.pydata.org/docs/user_guide/cookbook.html- 시각 - 시각 = 1월 4일 -
83.[30일차]시계열 제어 - 날짜/시간 속성 접근자(.dt)
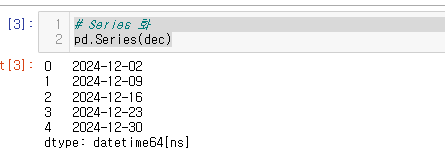
문자열 메소드 접근시 .str 을 사용했듯이 날짜/시간 속성 접근할 때에는 .dt 를 사용한다.https://pandas.pydata.org/pandas-docs/version/1.5/reference/api/pandas.Series.dt.html시리즈에서 날
84.[30일차]시계열 제어 - Timestamp와 DatetimeIndex의 메소드와 속성(+한국 locale 포맷)
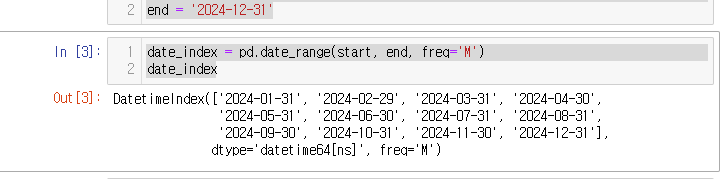
일반적으로 동일의미로 사용. 그러나 일부 상황에서는 다르게 사용할 때가 있음Pandas는 일반적인 상황처럼 동일의미로 쓰고 있음.속성이 Object면 Properties.속성이 값, 수치라면 Attributes.속성이 함수라면 MethodsAttributes : 객체의
85.[30일차]시계열 제어 - 데이터 셋에서 시계열 데이터 처리(to_datetime, parse_dates=)

이번 시간부터는 실습을 통해 진행해 보자데이터 셋은 캐글의 애플 2015~2020 주식 가격 데이터로 진행 하겠다.https://www.kaggle.com/datasets/suyashlakhani/apple-stock-prices-20152020• 날짜가 있는
86.[30일차]시계열 제어 - 날짜 포맷 정리
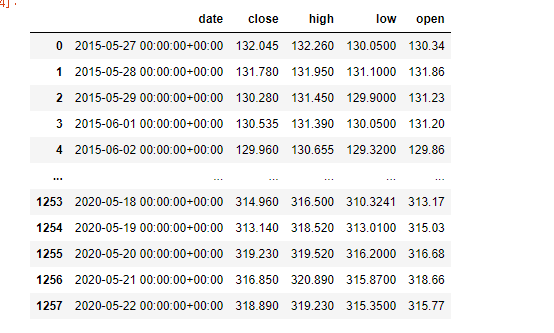
이번에는 아래 데이터를 사용해서새로운 형태의 인덱스를 만들어보자 날짜타입의 컬럼을 조작하려면 .dt 로 불러와야 된다.이후 함수를 사용하면 된다.날짜와 시간을 내가 원하는 형태로 포멧팅 해보자 숫자를 지정하면 그 부분이 그대로 출력됨.이를 인덱스에 저장해보자 dat
87.[30일차]시계열 제어 - 잘못된 날짜 포맷 정리
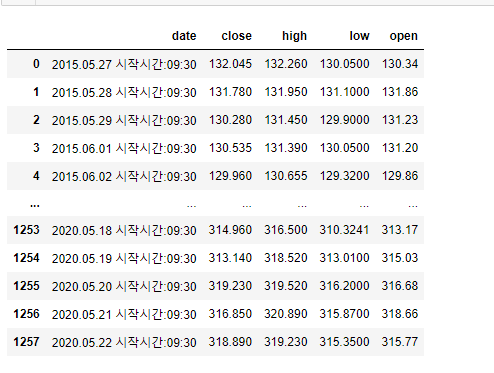
날짜 포맷이 깨지거나 정리가 안되어 있는 경우를 해결해보는 실습을 가져보자이전 시간에 만들었던 아래 데이터 프레임을 가지고 실습할 예정 시작시간 이라는 글씨가 거슬린다. 확인시 데이터 타입은 문자열이다.이는 문자열이 들어가 있기 때문이다.(당연한 말씀!)그렇기 떄문에
88.[30일차]시계열 제어 - 시계열의 조회(.loc)
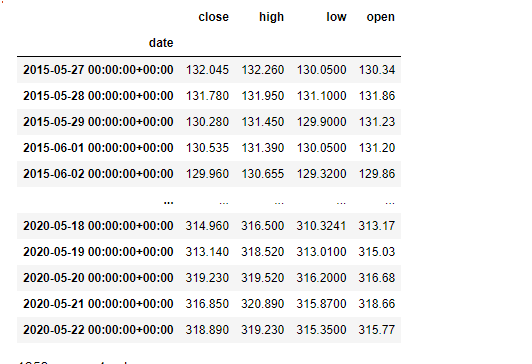
날짜 데이터를 .loc 으로 조회했을 때 어떤식으로 활용할 수 있을지 확인해보자. .iloc인 사용방법은 동일.loc도 사용방법은 동일한데, label을 어떻게 입력해야할까?기간 탐색의 장점을 살려보자.lable을 보면 너\~~무 길다.하지만 날짜 특성을 이용해서 좀
89.[30일차]시계열 제어 - 재색인(reindex)와 결측치 결정
인덱스를 새로운 인덱스로 변경하거나 재정렬하는 작업set_index, reset_index와는 기능적으로 비슷하지만 개념이 다름!인덱스를 갈아끼운다는 개념 보다는 재정렬한다고 생각.데이터를 새로운 인덱스에 맞게 재배열하거나 누락된 값을 처리하는 데 유용시리즈, 데이터프
90.[30일차]시계열 제어 - 재색인(reindex)와 결측치 결정
인덱스를 새로운 인덱스로 변경하거나 재정렬하는 작업set_index, reset_index와는 기능적으로 비슷하지만 개념이 다름!인덱스를 갈아끼운다는 개념 보다는 재정렬한다고 생각.데이터를 새로운 인덱스에 맞게 재배열하거나 누락된 값을 처리하는 데 유용시리즈, 데이터프
91.[30일차]시계열 제어 - 재샘플링(resample)
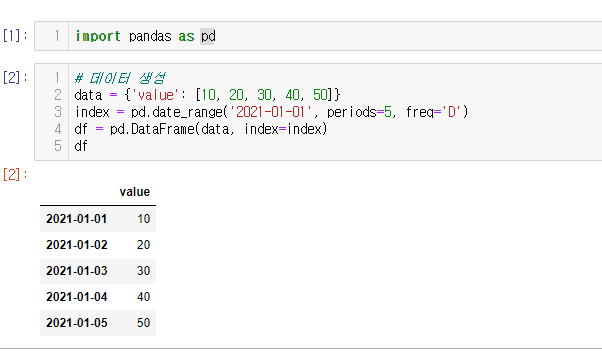
더 세밀하게 볼지, 더 간소화해서 볼지 재샘플링하는 방법!시계열 데이터의 주기를 변경하는 작업재샘플링 유형다운 샘플링 : 데이터 빈도(frequency)를 더 낮은 주기로 설정업 샘플링 : 데이터 빈도를 더 높은 주기로 업샘플링주어진 데이터의 빈도를 낮추는 작업데이터가