이전 글에서는 기존의 데이터프레임의 데이터를 수정하는 것을 알아봤다.
이번 글에서는 원본데이터 대신 별도의 데이터프레임을 생성하는 방법을 알아보자.
포지션이 센터인 사람의 Dataframe
1. 포지션열에서 센터인 사람 확인
# 포지션이 센터에 해당되는 사람만 가진 경우
df[df["포지션"] == "센터"]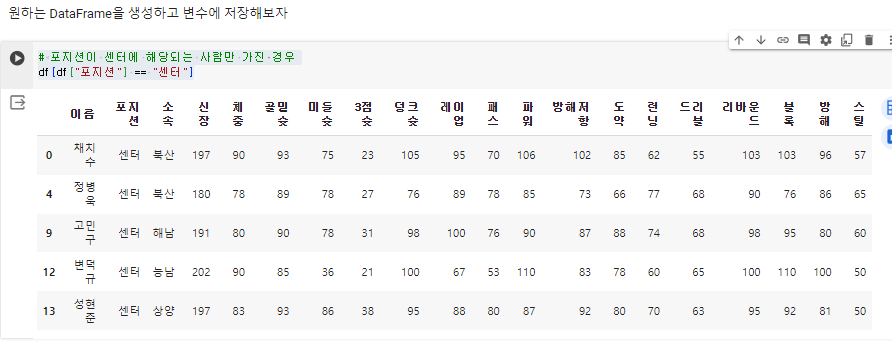
2. 별도의 Dataframe 생성
2-1. 함수를 만들어 저장하는 방법.
df_center 라는 이름의 함수에 넣을 수 있다.
df_center = df[df["포지션"] == "센터"] #얕은복사2-2. 연산 후 새로운 데이터프레임 생성 - .apply()
apply는 연산 후 데이터프레임을 새로 생성해주는 메소드이다.
연산시 lambda 함수를 사용해서 진행해보자.
lambda함수는 따로 정리할 예정
- 먼저 이름, 신장, 체중, 패스만 가진 df_power이라는 함수를 만든다.
df_power = df[["이름","신장","체중","패스"]]- df_power 신장을 늘린 시리즈 만들기
df_power["신장"].apply(lambda x : x+100)- 이제 기존 시리즈에 저장!
df_power["신장"] = df_power["신장"].apply(lambda x : x+100)이때 SettingWithCopyWarning 이라는 경고 메시지가 뜬다.
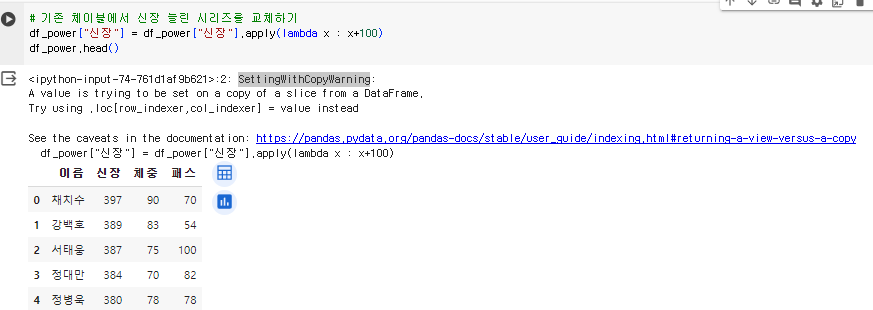
“원본 데이터를 바꾸니 위험한 작업이다~” 라는 뜻으로 이해하고 넘어가면 된다.(얕은 복사)
⭐새로운 컬럼을 만들어서 좀 더 안전하게 작업할 수 있다.
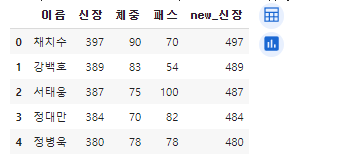
# 기존 체이블에서 신장 늘린 시리즈를 교체하기
df_power["new_신장"] = df_power["신장"].apply(lambda x : x+100)
df_power.head()위 처럼 new_신장 이라는 컬럼을 새로 만들어서 데이터를 넣으면 좀 더 안전하게 작업할 수 있다!
패스 능력치 별 평가
패스 능력치 별 평가를 통해 “우수”,”보통”,”미흡”을 체크해보자.
- 패스 능력치 별 평가 함수를 만들어 줌.
# 패스 능력치 별 평가
def check_skill_pass(x):
if x >= 90:
return '우수'
if x >= 70:
return '보통'
return '미흡'- 이후 apply() 함수를 이용해 능력치 측정
df_power["패스"].apply(check_skill_pass)#aqqly의 인자에는 연산을 넣어줌.
- df_power에 “패스평가”라는 열을 추가하여 데이터를 삽입.
# 함수 적용하여 새로운 열 추가하기
df_power["패스평가"] = df_power['패스'].apply(check_skill_pass)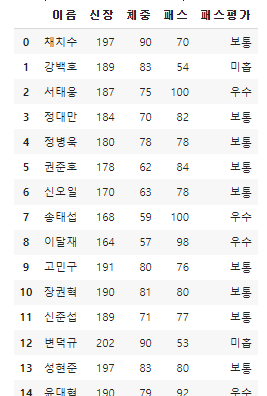
SettingWithCopyWarning:
- 이 경고는 Pandas에서 데이터프레임의 일부를 선택한 후 값을 변경할 때 발생하는 경고 메시지
- 값의 계산과 수정이 동시에 일어날 때의 경고. 얕은 복사일때 나타남.
- 때에 따라 예상과 다른 동작이나 메모리 부족 상태가 발생할 수 있다.
예시1 : 파이썬에서 for과 원본데이터를 조작할 때 의도치 않은 상황
numbers = [0,1,2,3,4,5,6,7]
for n in numbers:
print(n)
numbers.remove(n)위와 같이
리스트를 출력하고 삭제하는
코드가 있다고 하자.
이때 우리가 원하는 출력값은
0
1
2
3
4
5
6
7
일 것이다.
하지만 실제 출력값은
0
2
4
6
으로 나온다.
왜 일까?
그것은 바로 for문은 인덱스 넘버를 기준으로 하기 때문이다.
코드를 보면
첫 for문 : [인덱스 넘버: 0] 0을 출력하고 인덱스 0번째 삭제
두번째 for문 : [인덱스 넘버 : 1] 2를 출력하고 인덱스 1번째 삭제
이런식으로 진행이 된다.
이러한 상황을 방지하기 위해서는 copy()로 해결 가능하다.
예시1의 해결 : copy()
# 파이썬에서 for을 이용한 유사한 상황 - .copy()나 [:]로 해결
numbers = [0,1,2,3,4,5,6,7]
for n in numbers.copy(): #copy
print(n)
numbers.remove(n)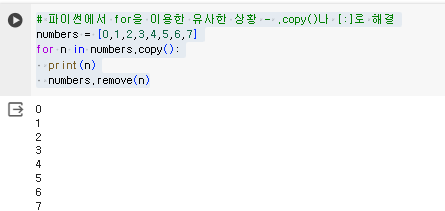
copy() 메소드는 원본 객체와 동일한 값을 가지는 새로운 객체를 반환할때 쓰인다.
즉, 원본 객체와는 별도의 메모리 공간에 저장되며 이를 “깊은 복사” 라고 부른다.
위의 코드에서 copy함수를 통해 기존 리스트 numbers를 삭제(remove)하지 않고 복사본을 삭제함으로써 우리가 원하는 출력값을 추출할 수 있었던 것이다.
이처럼 copy 함수를 이용해 기존에 Series를 수정할때 더 안전하게 진행해보자.
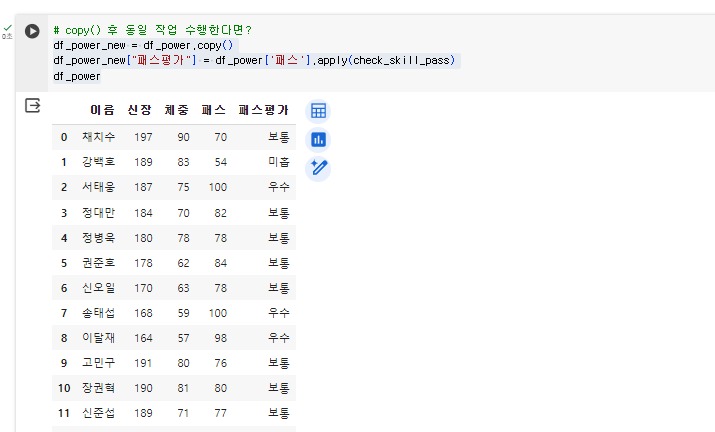
df_power_new = df_power.copy()
df_power_new["패스평가"] = df_power['패스'].apply(check_skill_pass)
df_powerdf_power 함수를 copy후 df_power_new함수에 넣어서 시리즈 수정을 진행하였다.
그 결과 경고문이 뜨지 않음!