속성이라 함은
데이터 생성 이후 .int, .object 와 같이 어떠한 성질을 의미한다.
실습환경 구성
- pandas 라이브러리 참조
import pandas as pd- 숫자열과 문자열로 구성된 list 생성
numbers = list(range(1,7)) #숫자열 리스트
letters = list("spencer") #문자열 리스트- 각각의 리스트 Series화
number_series = pd.Series(numbers)
number_series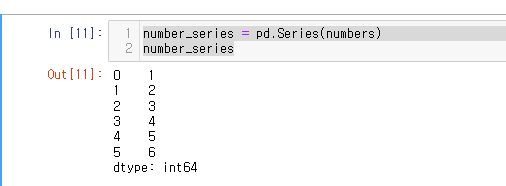
letters_series = pd.Series(letters)
letters_series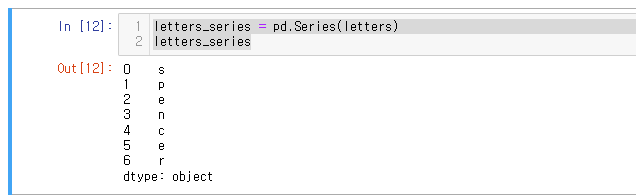
Series의 실행결과를 보면 가장 마지막 줄에 dtype을 확인할 수 있다.
.dtype 이란?
.dtype 이란 시리즈가 반환하고 있는 데이터 타입을 의미한다.
따로 dtype() 메소드를 사용해서 그 타입을 확인할 수 있다.
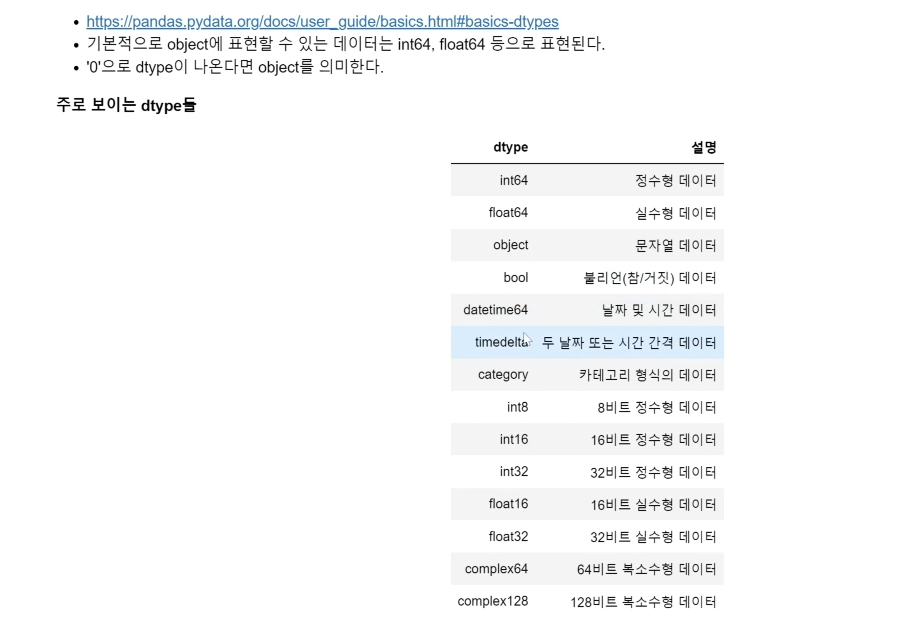
number_series.dtype #반환값 : dtype('int64')이 외에도 주로 보이는 dtype들
.index
.index 메소드를 사용하여 number_series 함수의 인덱스를 확인해 보자.
number_series.index # 결과값 : RangeIndex(start=0, stop=6, step=1)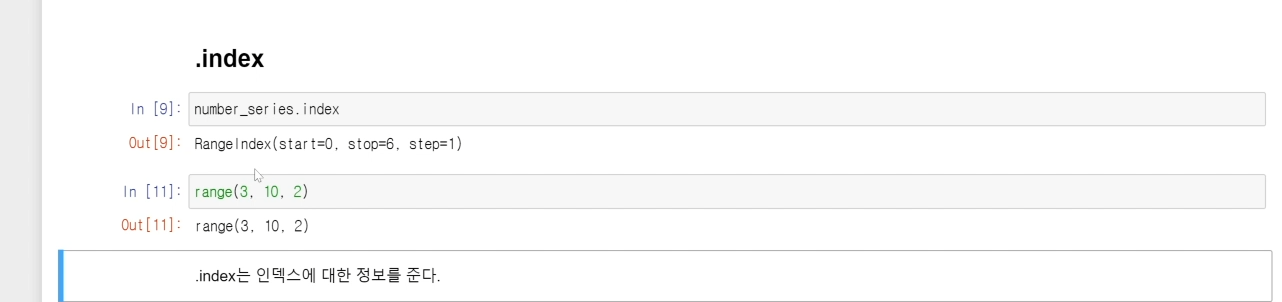
이 형태는 range() 형태와 동일하게 보이는데 그 이유는 무엇일까?
그 이유는 바로!
우리가 직접 index를 부여한 것이 아닌 pandas에서 자동으로 index를 부여할 때
Rangeindex라는 객체를 사용하기 때문!
이와 반대로 인덱스를 직접 부여한 형태로 Series를 만들었을때는
index에는 딕셔너리에 넣어주었던 값이 들어감.
user = {"name":"김준석", "age":20}
user_set = pd.Series(user)
user_set.index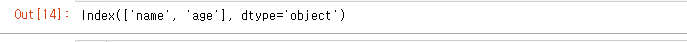
.index 함수 사용시 ‘name’,’age’ 인덱스가 확인된다.
- Rangeindex
- 순차적인 정수로 구성된 인덱스 객체
- 데이터프레임이나 시리즈를 생성할 때, 명시적으로 인덱스를지정하지 않은 경우에 기본적으로 생성되는 인덱스
- Rangeindex는 0부터 시작하는 정수로 구성
- 일반적으로 데이터의 길이 또는 행의 개수에 따라 자동으로 생성
- Rangeindex는 변경할 수 없는(immutable) 객체로, 크기가 고정.
- start= 값과 stop= 값이 고정되어 있다는 뜻.
- Rangeindex는 메모리 사용을 최적화하여 데이터의 검색과 접근 속도를 향상시킴.
정리

.values
- values는 배열의 특징을 가지고 있다.
- 첫번째 값이 숫자열이면 그 열은 모두 숫자열
.values 메소드를 사용해 number_series 함수의 값을 확인해 보자.

array(배열)의 형태로 나오는 것을 확인할 수 있다.
만약 list가 [’김준석’, 1, 2] 이렇게 구성되어 있었다면
Series화 이후1과 2는
‘1’, ‘2’로 문자열화가 진행된다.
.shape
.shape 은 데이터의 구조를 알아낼 때 사용한다.
참고로 Series는 이전에도 말했듯 1차원 구조이다.
.shape 을 활용해 number_series의 구조를 확인해보자.
number_series.shape
결과값을 보면 6개의 요소가 들어간 것이라고 나온다.
1차원이기 때문에 (6,) 6하나의 값만 들어있는 것을 확인할 수 있다.
🔎그런데 왜 6이후에 콤마(,)가 들어가 있을까?
그것은 바로 튜플로 처리하기 위함이다!
(6) 이것은 튜플이 아니지만
(6,) 는 튜플로 처리해주기 때문.
.size
데이터의 크기를 확인하는 메소드이다.
number_series.size# 결과값 : 6
빈번하게 발생하지는 않지만
두 데이터의 크기를 비교할 때 사용한다고 한다.
.hasnans
NaN데이터를 확인해주는 메소드이다.
결측치를 확인할 때 쓰임.
number_series에 NaN데이터가 있는지 확인
number_series.hasnans
NaN 데이터가 없기 때문에 False를 추출한다.
NaN 데이터가 있다면 True를 추출.
