**행 조회**
-
.loc을 사용할 예정.- 인덱스 레이블로 행 조회
- 메소드가 아닌 속성
.loc[]는 주로 레이블을 기반으로 행과 열에 접근하는 데 사용되지만, boolean 배열과 함께 사용할 수도 있다.
-
.loc입력방법-
하나의 레이블
-
5또는‘a’(5는 인덱스 레이블로 해석되며 파이썬 처럼 정수 위치로 해석되지는 않음)titanic_df.loc['Abbing, Mr. Anthony']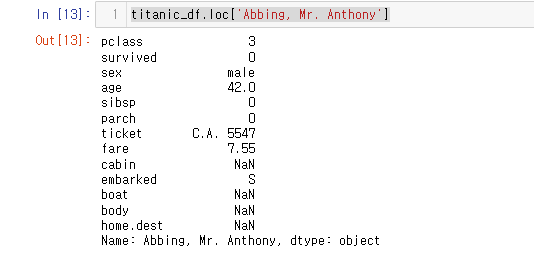
하나의 컬럼이기 때문에 자동으로 Series화 되어 출력 된다.
DataFrame으로 보려면 대괄호를 한번 더 감싸면 된다.
titanic_df.loc[['Abbing, Mr. Anthony']]
-
-
레이블의 리스트 또는 배열
-
['a','b','c']titanic_df.loc[['Abbing, Mr. Anthony','Zimmerman, Mr. Leo']]
-
-
레이블 범위로 된 슬라이스 객체
-
‘a’:’f’titanic_df.loc['Abbott, Master. Eugene Joseph':'Abbott, Mrs. Stanton (Rosa Hunt)']
-
-
축과 길이가 같은 boolean 배열
[True, False, True]
-
에러 대처방법
없는 인덱스를 조회를 하면 에러가 발생할 것이다.
파이썬으로 데이터를 분석하는 과정에서 에러가 뜬다면 ‘없는 데이터구나~’
하고 넘기면 되지만
이 과정이 만약 머신러닝을 만드는 과정이라면 에러는 크게 작용할 것이다.
그렇기 때문에 에러가 발생하지 않도록 안전한 코드를 만드는 것이 중요하다.
인자에 error= 가 있다면 이를 False 값으로 하면 되지만 만약 없다면 if문을 활용하면 된다.
if문 활용법
kimjunseok 이라는 인덱스를 조회하려고 한다.
이게 있다면 조회
없다면 처리하지 않는 코드 작성.
if 'kimjunseok' in titanic_df.index:
result = titanic_df.loc['kimjunseok']
else:
result = Nonetry…except..문 활용법
try:
result = titanic_df.loc['kimjunseok']
except:
result = None.duplicated() - 동명이인 파악
데이터프레임의 인덱스는 인덱스 레이블이기 때문에 동일한 값이 들어갈 수 있다.
이를 어떻게 파악하는지 알아보자.
titanic_df의 인덱스가 중복인지 파악하기위해 뒤에 .duplicated() 메소드를 붙인다.
titanic_df.index.duplicated()
그럼 위와 같이 boolean형 시리즈 형태로 나오기 때문에 쉽게 데이터프레임으로 볼 수 있다.
titanic_df[titanic_df.index.duplicated()]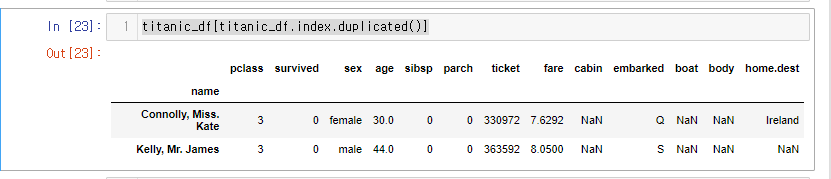
중복값은 4개인데 2개가 나왔다..왜지??
한번 확인해보자
duplicated()는 boolean형태이기 때문에 sum()을 활용하여 True의 갯수를 찾을 수 있다.
titanic_df.index.duplicated().sum()
중복으로 잡은 값은 애초부터 2개였다.
즉, 중복 데이터를 다 추출하는 것이 아닌 중복 중 하나만 추출하는 것이다.
이를 keep = 인자로 설정값을 변경할 수 있다.
keep = : 중복된 값 중 어떤 값을 유지할지를 지정
keep = frist- 첫 번째 등장 값을 제외하고 두번째 등장값을 True 표시
keep = last- 마지막 등장 값을 제외하고 그 이전 등장값을 True 표시
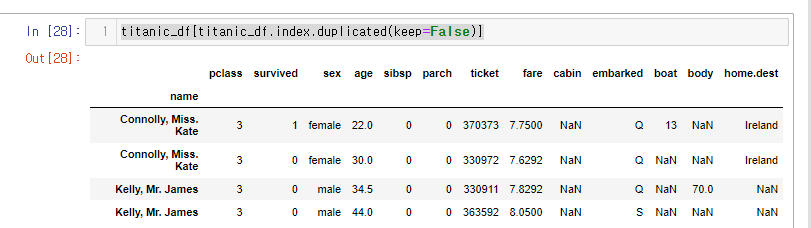
keep = False- 모든 중복된 값을 True로 표시
즉, keep = False 를 이용하여 중복된 이름을 모두 가져올 수 있는 것이다.
titanic_df[titanic_df.index.duplicated(keep=False)]