데이터 셋
- sample1.csv - 학업성취도
Pandas참조 + students 데이터프레임 생성
import pandas as pd
students = pd.read_csv('sample1.csv')
students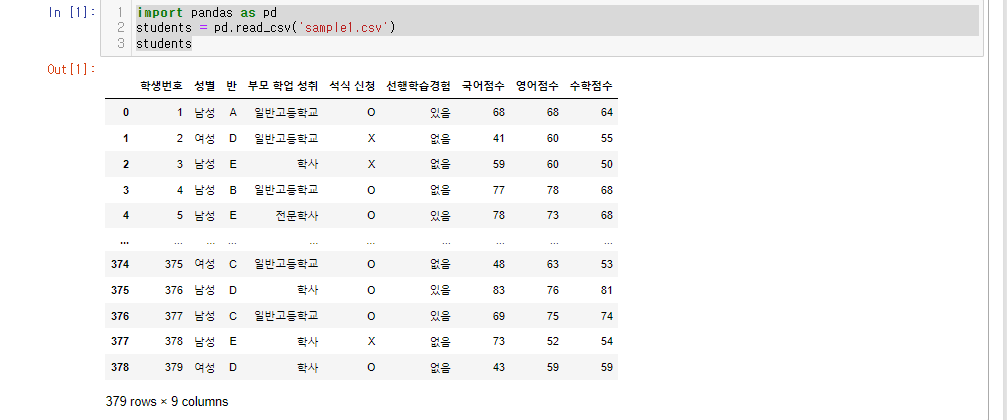
'총점' 열을 데이터프레임에 생성하고 값을 계산(모든과목더하기)
all_jumsu = students[['국어점수','영어점수','수학점수']].agg('sum',axis=1)
students.insert(loc = 9,column='총점', value= all_jumsu)
students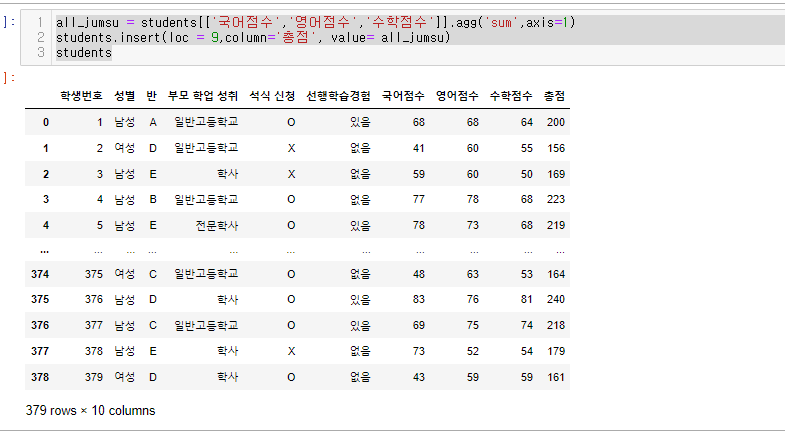
다른 풀이
students['총점'] = students['국어점수']+students['영어점수']+students['수학점수']이렇게 더해도 된다.
변수에 그룹화 데이터된 데이터 저장
- '반'과 '석식 신청'을 기준으로
diner = students.groupby(by =['반','석식 신청'])여기서 값이 잘 들어왔나 확인시 get_group 메소드를 사용
diner.get_group(('A','O'))A반 중 석식O신청자
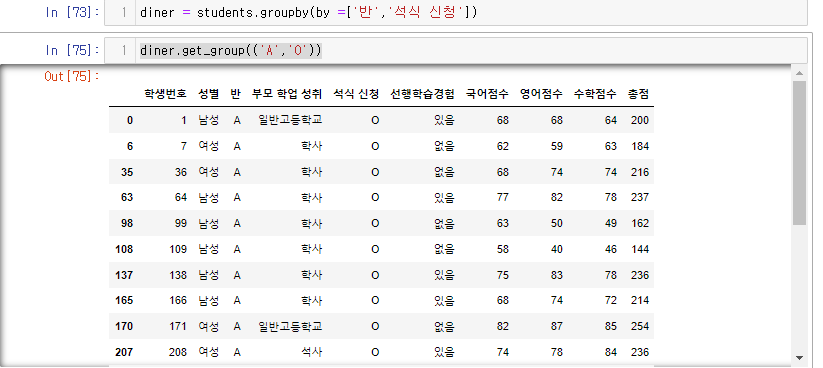
반-석식신청으로 그룹화된 학생 그룹의 '총점' 분석
- agg()를 이용해보자
- count, median, max, min, mean
diner['총점'].agg('sum')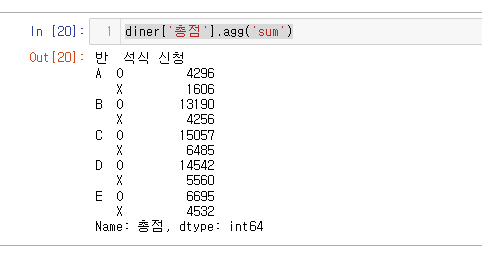
다른풀이
아 나는 총점의 총점을 구했는데 그게 아니였음;;;;
diner['총점'].agg(['count', 'median', 'max', 'min', 'mean', 'std'])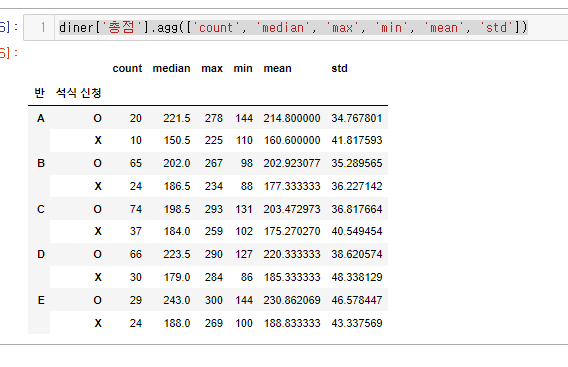
바로 반별 석식 신청별 총점의 집계를 보는 것 이였다..
총점의 '최저점 - 평균'이 낮은 순으로 정렬하기
- 석식 신청을 안한 친구들의 성적 최저점이 낮은 편인가?
diner_mean = diner['총점'].mean()
pd.DataFrame(diner_mean) #데이터프레임화
diner_mean.sort_values() #정렬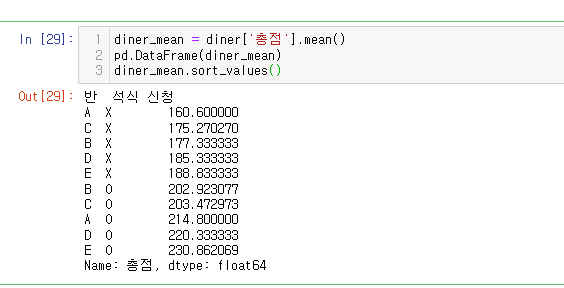
풀이) 엥!!! 총점을 기준으로 집계 낸거에서 최소값, 평균값을 오름차순해줌,,
내가 문제 이해를 잘 못했나벼 ㅋ
analysis = diner['총점'].agg(['count', 'median', 'max', 'min', 'mean', 'std'])
analysis.sort_values(by=['min','mean'])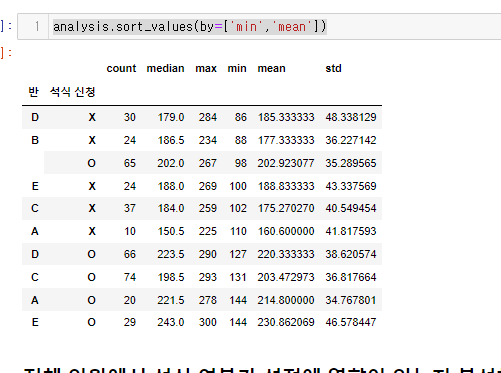
전체 인원에서 석식 여부가 성적에 영향이 있는지 분석해보기
- 석식 신청으로 그룹화하고
- count median max min mean std를 확인해보자
student_diner = students.groupby('석식 신청')
student_diner.agg({'총점':['count', 'median', 'max', 'min', 'mean', 'std']})
#다른방법
#student_diner['총점'].agg(['median', 'max', 'min', 'mean', 'std'])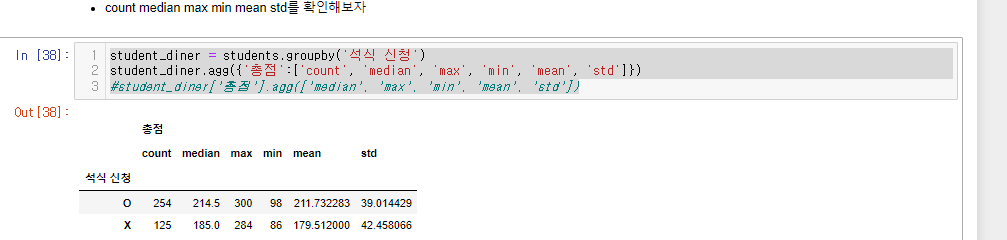
부모 학업 성취 수준에 따라 성적에 영향이 있는지 분석해보기
- 학업 성취 수준으로 그룹화하고
- mean count std median max min 을 확인해보자
- 평균 높은 순으로 정렬
#학업 성취 수준으로 그룹화
students_parants = students.groupby('부모 학업 성취')
#총점을 기준으로 집계
sp_describe = students_parants['총점'].agg(['count', 'median', 'max', 'min', 'mean', 'std'])
#mean 평균을 기준으로 오름차순 정렬
sp_describe.sort_values(by='mean', ascending=False)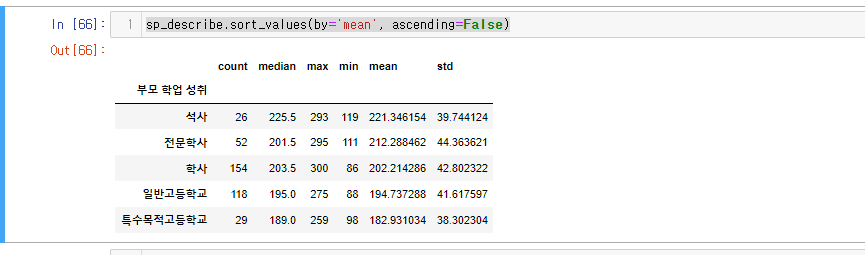
처음에 총점을 기준으로 집계할때
sp_describe = students_parants.agg({'총점':['count', 'median', 'max', 'min', 'mean', 'std']})
sp_describe이런식으로 했더니 컬럼에 멀티 인덱싱이 되어버림 ;;;
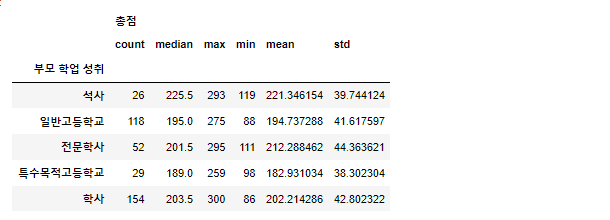
멀티인덱싱 상태에서 정렬 어케하노
.
.
.
방법알아옴!!!
sp_describe.sort_values(('총점','mean'), ascending=False)컬럼 인덱스를 레벨 순으로 튜블 형태로 넣어주면 된다!

LV. 1