재샘플링(resample)
더 세밀하게 볼지, 더 간소화해서 볼지 재샘플링하는 방법!
- 시계열 데이터의 주기를 변경하는 작업
- 재샘플링 유형
- 다운 샘플링 : 데이터 빈도(frequency)를 더 낮은 주기로 설정
- 업 샘플링 : 데이터 빈도를 더 높은 주기로 업샘플링
1. 다운샘플링 간단 예제 - 간소화
- 주어진 데이터의 빈도를 낮추는 작업
- 데이터가 일별로 주어졌을 때 주간, 월간 등 더 낮은 주기로 데이터를 집계
- 다운샘플링할 주기를 나타내는 문자열 또는 오프셋 문자열을 인자로 전달
- 다운샘플링 시에는 집계(aggregation) 함수를 사용하여 데이터를 요약
실습
이 데이터 프레임을 주간 평균으로 확인해보자!
# 주간 평균으로 다운샘플링
weekly_df = df.resample('W').mean()
weekly_df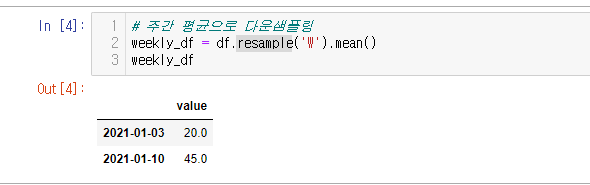
resample() 메소드를 이용해 간소화를 진행!
1주차인 2021-01-01~2021-01-03 의 주는 평균 20
2주차인 2021-01-04~2021-01-05 의 주는 평균 45가 나온다.
다운 샘플링시 없는 데이터 2021-01-10 가 생기는 모습을 볼 수 있다.
2. 업샘플링 간단 예제
-
주어진 데이터의 빈도를 높이는 작업
- 데이터가 월별로 주어졌을 때 일별, 시간별 등 더 높은 주기로 데이터를 채움
-
업샘플링할 주기를 나타내는 문자열 또는 오프셋 문자열을 인자로 전달
-
업샘플링 시에는 보간(interpolation)을 통해 데이터를 채움
-
보간 방식을
method=로 정해줘야함보간(Interpolation)
- 주어진 데이터 사이에 누락값을 추정하는 방법
- 선형 보간, 최근접 이웃 보간, 다항식 보간 등
.asfreq()
- 업샘플링 시에 사용되는 함수
- 주어진 주기에 맞게 데이터를 새로운 인덱스로 재구성
- 누락된 데이터를 NaN 값으로 채움
.interpolate()
- 업샘플링 시에 사용되는 함수로, 보간을 수행하여 누락된 값을 추정
- method 매개변수를 사용하여 다른 보간 방법을 선택
.interpolate() 의 method=
알아야할 기초우선순위를 두어 정리해보았다.순서 보간방식 키워드 보간 설명 1 선형⭐ linear 인덱스를 무시하고 값들을 일정 간격으로 취급하여 보간 2 시간⭐ time 일별 및 더 높은 해상도의 데이터에 대해 지정된 길이의 간격으로 보간 3 인덱스⭐ index, values 인덱스의 실제 숫자 값을 사용하여 보간
설명이 너무 길다..
실습을 진행해 보자
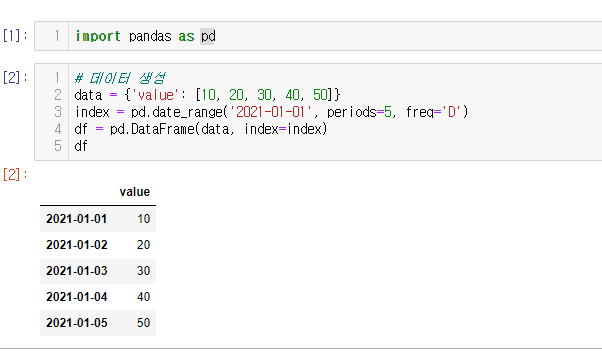
# 원본 데이터 생성
data = {'value': [10, 20]}
index = pd.to_datetime(['2021-01-01', '2021-02-01'])
df = pd.DataFrame(data, index=index)
df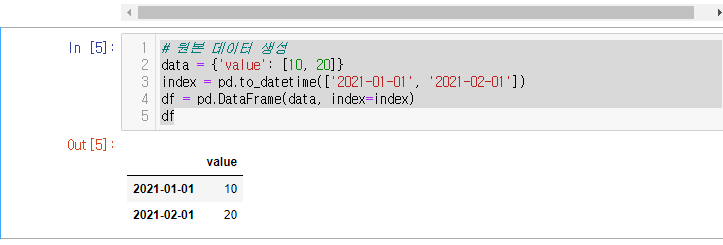
위와 같은 데이터 프레임이 있다.
이때, 일별로 업샘플링하고 선형 보간으로 데이터를 채워보자
# 일별로 업샘플링하고 선형 보간으로 데이터 채우기
daily_df = df.resample('D').asfreq().interpolate(method='linear')
daily_df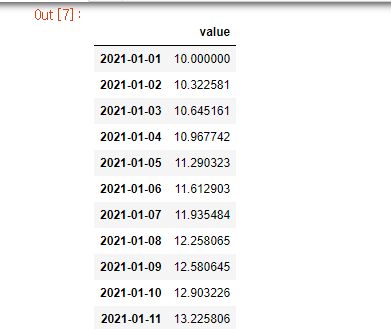
우와! 2021-01-01~2021-02-01 인덱스가 생겨났다.
또한 value는 리니어로 일정 간격으로 높아지면서 생겨남
사용처!
내가 만약 데이터 모델을 만들 때에
월별 데이터 밖에 없다!
근데 일별 데이터가 필요하다! 할 때 사용한다~
**본 데이터 실습 - 다운샘플링**
import pandas as pd
cols = ['date', 'open', 'high', 'low', 'close']
stocks = pd.read_csv('AAPL.csv', usecols=cols, index_col='date', parse_dates=['date'])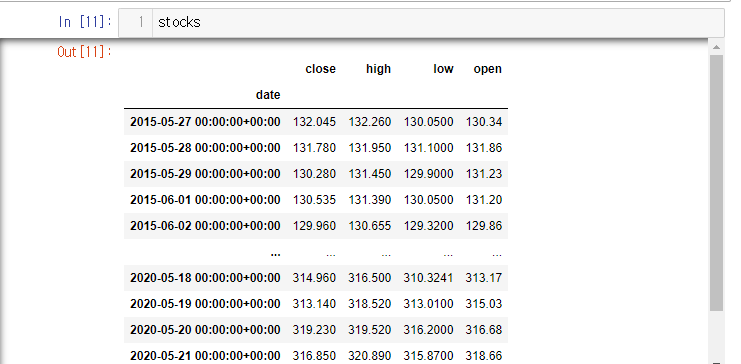
해당 데이터 프레임으로 다운샘플링을 좀 더 실습해보자
**1. 연 단위로 resample (= groupby 데이터 유사)**
먼저 연초 빈도를 인자값에 넣어보자
stocks.resample('AS')‘AS’는 **Offset aliases의 연초 빈도 값이다.**
아래 문서 참고.
• https://pandas.pydata.org/docs/user_guide/timeseries.html#offset-aliases
그럼 출력값은 아래와 같이 나온다.

어디서 많이본 모습…!
그렇다. groupby() 메소드 때와 비슷한 형태이다.
사실 아주 많이 유사하다. 그렇기 때문에 groupby() 메소드처럼 사용이 가능하다.
왜 유사하게 나오는지 로직을 확인해 보자.
stock_years.groups.groups 는 인덱스와 벨류가 어떻게 매칭되어 있는지 알아보는 함수이다!
까먹었을까봐 다시 설명해준다.

우측의 숫자는(153, 405,…) resample() 이전 데이터의 인덱스의 위치를 뜻한다.
원본 데이터 stocks 의 인덱스를 한번 확인해 보자
아마 resample() 인자에 연초 ‘AS’를 넣었기 때문에 153인덱스는 2015년일 것이다.
stocks.iloc[[152,153]]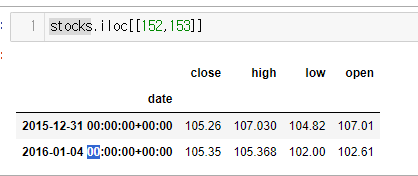
엇 152인덱스가 2015이다.
강의를 들어보니 연도가 바뀌는 지점을 가져간다고 말해준다.
즉 152,153 인덱스 사이의 경계선을 가져가서 ‘AS’(연초)로 보여준것!
다운 샘플링 데이터는 groupby 처럼 다룰 수 있기에
get_group() 도 사용 가능하다.
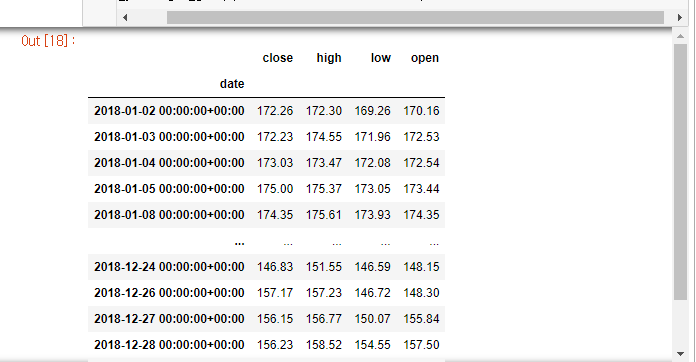
get_group() 을 이용해 2018년 데이터만 가져와 보자
stock_years.get_group('2018-01-01 00:00:00+0000')이때 인자에 시계열 장점인 생략은 안된다. 즉 '2018-01-01'는 안됨
**2. 다운샘플링 이후 집계함수**
- 집계함수 mean으로 년도별 평균 구하기
# 집계함수 mean으로 년도별 평균 구하기
stock_years.mean(2)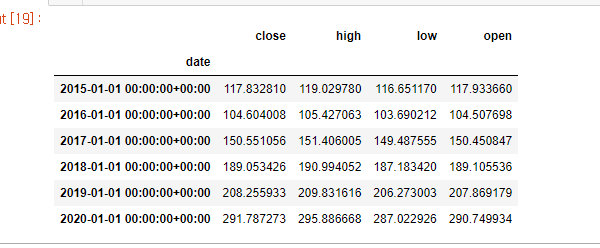
주식이 계속해서 느는것을 볼 수 있다.
- agg()로 집계함수 max, min, mean 년도별 결과 구하기
# agg()로 집계함수 max, min, mean 년도별 결과 구하기
stock_years.agg(['max','min','mean'])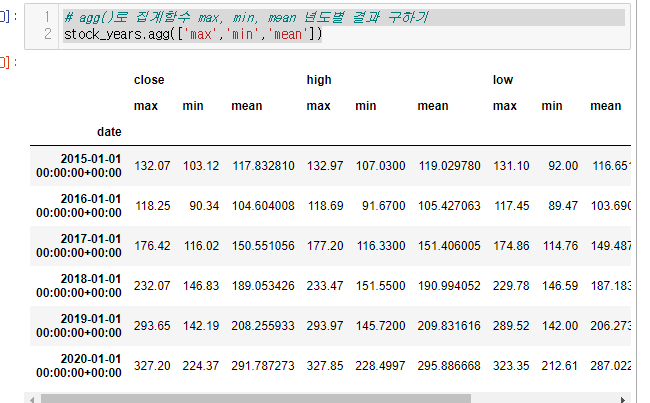
위의 다운 샘플링을 볼 때
날짜 인덱스 부분이 시간때문에 상당히 난잡해 보인다.
resample 의 인자 중 kind= 를 사용해서 해결해 보자
kind= : {‘timestamp’, ‘period’}, optional, default None
- timestamp : 결과 인덱스를 날짜/시간 인덱스로 변환
- period : 기간 인덱스로 변환
먼저 kind= 인자는 월초 ‘MS’, 연초 ‘AS’ 등 초반 데이터는 사용이 안됨. 이점 참고!
해당 인자를 실습하기 위해 처음부터 resample() 메소드를 실행해보자
월 단위 집계 진행
stock_month = stocks.resample('M', kind='period')
stock_month출력값 :<pandas.core.resample.DatetimeIndexResampler object at 0x000001F432D5C9D0>
먼저 집계함수를 사용해주기 위해 groupby처럼 만들어줌
# 월 단위로 .agg() 결과 보기 1
stock_month.agg(['max','min','mean'])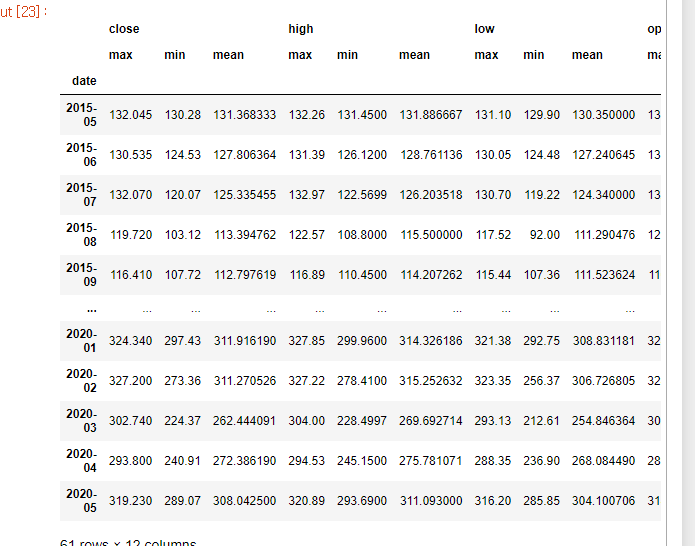
짠! 데이트인덱스가 기간 인덱스로 바뀌었다.
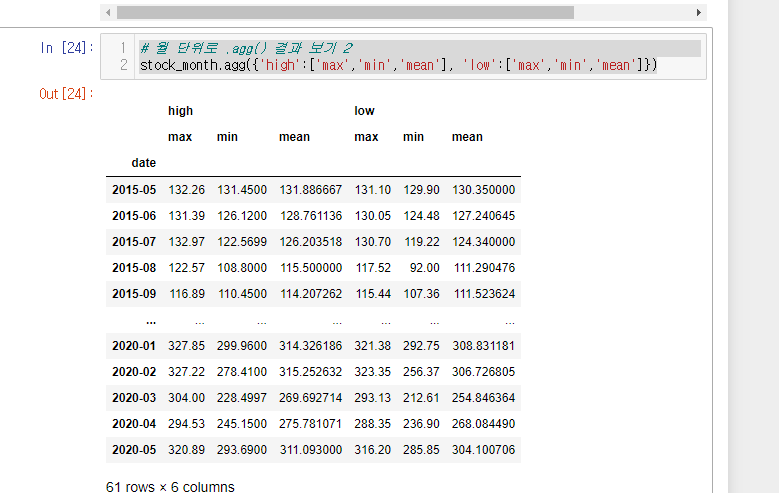
여기서 나는 최고높았던 부분의 high랑 가장 낮았던 부분의 low 만 보려면 아래와 같이 작성하면 된다.
# 월 단위로 .agg() 결과 보기 2
stock_month.agg({'high':['max','min','mean'], 'low':['max','min','mean']})