[31일차]데이터 분석 과정
데이터 분석 프로세스
- 문제 정의
- 데이터 수집
- 데이터 전처리
- 데이터 분석
- 데이터 분석에서 나온 인사이트 리포팅 / 피드백
1. 문제 정의
풀고자 하는 문제가 명확하지 않으면 데이터 분석은 무용지물이다.
-
문제정의시 생각해야 될 것.
- 궁극적으로 해결하고자 하는 문제(달성하고자 하는 목표)
- 해당 문제를 일으키는 원인이 무엇인가
- 상황을 판단하는 지표나 기준이 무엇인가
-
문제 정의 순서
- 큰 문제를 작은 단위의 문제들로 나눈 후
- 각 작은 문제들에 대해서 여러 가설들을 세운 뒤
- 데이터 분석을 통해 가설을 검증하고 결론을 도출하거나 피드백을 반영한다.
문제 정의 예시
인구 문제를 예로 들어보자
- 인구 감소(문제) ← 저출산 및 인구 유출(원인)
- 노동 인구 부족(문제) ← 인구 감소(원인)
- 내수시장 구매력 부족(문제) ← 인구 감소(원인)
→’인구감소’라는 동일한 상황이 문제가 될 수도 있고, 문제의 원인이 될 수도 있다.
→문제 정의에 따라서 풀어가는 방향이 완전히 바뀔 수 있음.
→메타 인지 관점에서 문제 정의에 대한 충분한 고민이 필요하다.
메타 인지 : 꼬리에 꼬리를 무는 생각
e.g.) 인플레이션← 공급자 비용 증가 ← 노동 시장 비용 증가 ← 노동 인구 부족 ← 인구 감소 ← 저출산 및 인구 유출(원인)
→해당 원인이 정말 문제에 대한 ‘결정적인’ 원인인지 한번 더 생각
e.g.) 인플레이션의 결정적인 원인이 노동시장이 아닌 원자재 시장 비용 증가일 수 도 있다!
이런 경우 문제정의를 처음부터 다시 해줘야 된다.
2. 데이터 수집
검증해보고자 하는 가설을(문제 정의에서 나온) 해결해줄 데이터를 수집
- 가설 검증에 필요한 데이터가 존재하는가?
- 데이터가 가설 검증에 부적절하거나 없을 수도 있다.
- 어떤 종류의 데이터가 필요한가?
- 데이터는 산재되어있고 엄청나게 많다.
즉, 데이터로부터 얻고자 하는 정보가 무엇인지 명확하게 해야 필요한 데이터만 모을 수 있다.
- 데이터는 산재되어있고 엄청나게 많다.
- 얻고자 하는 데이터의 지표가 명확한가?
- 적절해 보이는 데이터라도 지표가 부적절하면 가설 검증 및 결론 도출시 오류를 범할 수 있다.
3. 데이터 전처리
- 데이터 추출, 필터링, 그룹핑, 조인 등 (SQL 및 DB)
- 데이터 분석을 위한 기본적인 테이블을 만드는 단계
- 테이블과 컬럼의 명칭, 처리/집계 기준, 조인시 데이터 증식 방지
- 이상치 제거, 분포 변환, 표준화, 카테고리화, 차원 축소 등(Python/R)
수집한 데이터를 데이터 분석에 용이한 형태로 만드는 과정
4. 데이터 분석
- 탐색적 데이터 분석(EDA)
- 그룹별 평균, 합 등 기술적 통계치 확인
- 분포 확인
- 변수 간 관계 및 영향력 파악
- 데이터 시각화
- 모델링(머신러닝, 딥러닝)
- Classification(categorical lable)
- lable이 정수값을 가지고 있을때 풀이방법
- 여러 속성값을 가지고 있는 사용자들을 정리해두면 lable이라고 말한다.
- Regression(numerical lable)
- lable이 실수값을 가지고 있을때 풀이방법
- 클러스터링(비지도학습)
- lable이 주어지지 않았을 때
- Classification(categorical lable)
5. 리포팅 / 피드백
분석 결과를 전달하는 과정
- 내용의 초점은 데이터 분석가가 아닌 상대방에게 한다고 생각.
- 상대가 이해할 수 있는 언어 사용
- 목적을 수시로 상기하고 재확인 시켜줘야 된다.
- 적절한 시각화 방법 활용
- 항목간 비교시 원 그래프는 지양하고 막대 그래프 위주로!
- 막대 그래프 사용시 x,y축 및 단위를 주위해야 된다.
- 시계열은 라인이나 실선으로 표현
- 분포는 히스토그램이나 박스플롯
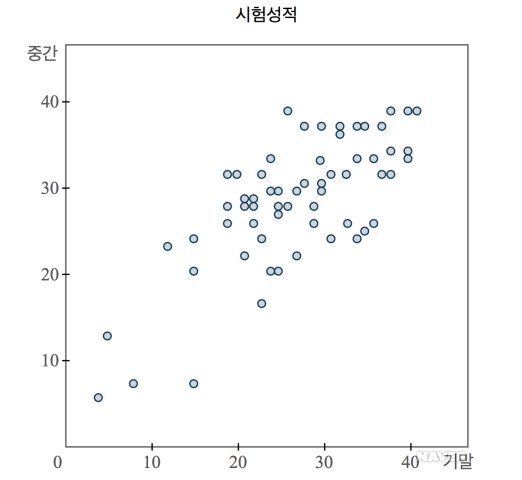
- 변수간 관계는 산점도를 이용하면 좋다.
산점도 예시
- 항목간 비교시 원 그래프는 지양하고 막대 그래프 위주로!

LV. 1