[33일차]matplotlib plot의 종류 - Scatterplot, Barplot, Histogram
데브코스_데이터분석-데이터 분석 과정 학습 및 시각화 실습(1)[7주차]
실제로 matplotlib.pyplot 에서 사용하는 플롯의 종류를 알아보자
scatter plot - 산점도
산점도는 데이터가 어떤식으로 분포되어있는지 확인할 때 유용하다.
plt.scatter(s=,c=)
- x,y좌표로 이뤄진 데이터들을 점으로 표현하는 플롯
s=점 크기,c=점 색깔을 조절하며
lable이나 class에 따른 데이터 분포를 확인할 때 활용이 가능하다.
실습
x와 y에 각 각 50개의 랜덤한 데이터를 넣어보자
x = np.random.rand(50)
y = np.random.rand(50)
plt.scatter(x,y) 
s= 점 크기, c= 점 색깔을 조절하며 각 데이터를 다르게 표현할 수 있다.
colors = [0]*25 + [1]*25
area = x*y*100
plt.scatter(x,y, c=colors, s=area )코드설명
-
colors = [0]*25 + [1]*250번 클래스(x) 와 1번 클래스(y)를 지정해
각 각 25개씩 색깔을 지정해준다.(전체 데이터가 50개이기 때문) -
area = x*y*100점의 크기는 x축과 y축을 곱해서 더 커질수록 크게 나오도록했다.
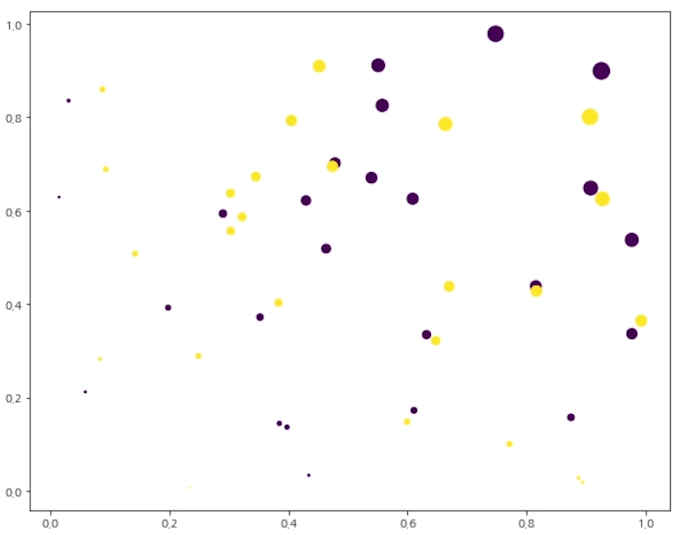
굳!
Barplot, Barhplot - 막대그래프
- plt.bar(), plt.barh()
- 범주가 있는 데이터 값을 막대그래프로 만들어줌!
- width, align 등의 옵션으로 막대의 위치를 조정 할 수 있고,
color와 alpha 옵션 사용이 가능하다.
Barplot : plt.bar(x축,y축) 서있는 막대그래프
각 과목별로 점수를 넣은 그래프를 만들어보자
x = ['Math','Programming','Data Science','Art','English','Physics']
y = [66, 80, 60, 50, 80, 10]
plt.bar(x,y) 
그래프가 좀 더럽게 나온다..!
align= 인자로 막대의 위치를 중앙으로 조정하고
plt.xticks로 x축의 글자 크기를 조정해보자
x = ['Math','Programming','Data Science','Art','English','Physics']
y = [66, 80, 60, 50, 80, 10]
plt.bar(x,y,align = 'center')
plt.xticks(fontsize=8) 
여기서 color=, alpha= 인자도 사용하게 된다면 아래와 같이 표현 가능!
x = ['Math','Programming','Data Science','Art','English','Physics']
y = [66, 80, 60, 50, 80, 10]
plt.bar(x,y,align = 'center',alpha=0.5,color='r')
plt.xticks(fontsize=8)
plt.title('Subject') 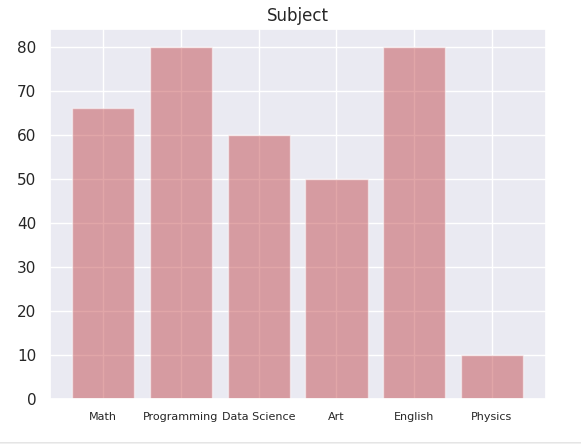
Barhplot : plt.barh(x축,y축) 누워있는 막대그래프
사용법은 plt.bar과 같다.
막대 그래프 비교시! plt.subplots()
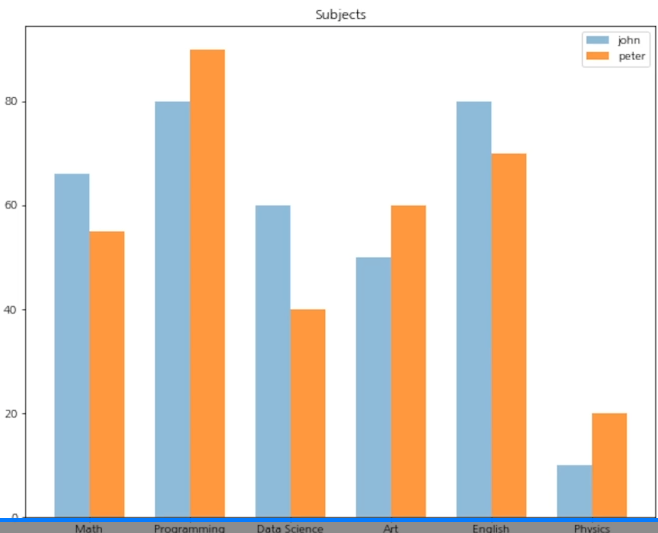
위와 같이 두 값을 비교하는 막대그래프를 만들기 위해서는 plt.subplots() 메소드를 사용해주면 된다.
코드를 보며 설명해보자
#x축 값
x_lable = ['Math','Programming','Data Science','Art','English','Physics']
#y축 값
y_1 = [66, 80, 60, 50, 80, 10]
y_2 = [55,90,40,60,70,20]
#subplots 생성
fig, axes = plt.subplots()
#막대그래프 생성
axes.bar(x_lable,y_1)
axes.bar(x_lable,y_2) 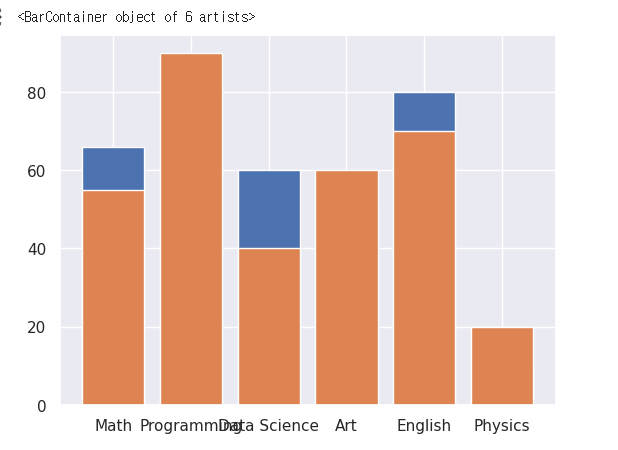
데이터가 이상하게 나온다!!!
plt.subplots().bar() 를 할때에는 x축 데이터의 위치를 지정해 줘야 된다.
x = np.arange(len(x_lable)) #[0 1 2 3 4 5]가 저장됨.
#넓이 지정
width =0.35
#막대그래프 생성
axes.bar(x - width/2,y_1, width)
axes.bar(x + width/2,y_2, width)위의 값을 추가해주면 된다.
보통 넓이는 0.35로 지정한다고 한다.
x - width/2 : 데이터를 지정, 중심선에서부터 데이터 위치를 지정 (x-0.35/2 만큼 옮김)
그래서 해당 width값을 동일하게 + -로 쥐어주면 아래와 같이 이동하는 것을 볼 수 있다.
이건 bar()의 세번째 인자에서 width를 지정해 줬기 때문에 가능!
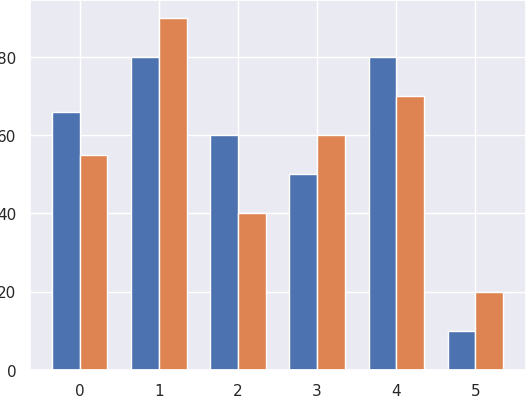
근데 그래프를 확인하면 x레이블이 숫자로 되어있다.
이를 set_xticklabels() 메소드를 이용해 지정해줄 수 있다.
#xtick 설정
plt.xticks(x)
axes.set_xticklabels(x_lable)요로코롬!
이제 레이블을 좀 더 다듬으면~~
#x축 값
x_lable = ['Math','Programming','Data Science','Art','English','Physics']
x = np.arange(len(x_lable)) #x축 lable의 수 많큼.
#y축 값
y_1 = [66, 80, 60, 50, 80, 10]
y_2 = [55,90,40,60,70,20]
#넓이 지정
width =0.35
#subplots 생성
fig, axes = plt.subplots()
#막대그래프 생성
axes.bar(x - width/2,y_1, width, align='center')
axes.bar(x + width/2,y_2, width, align='center' )
#xtick 설정
plt.xticks(x)
axes.set_xticklabels(x_lable)
plt.xticks(fontsize=6)
#이름 설정
plt.ylabel('Number of students')
plt.title('Subjects')
plt.legend(['john','peter']) 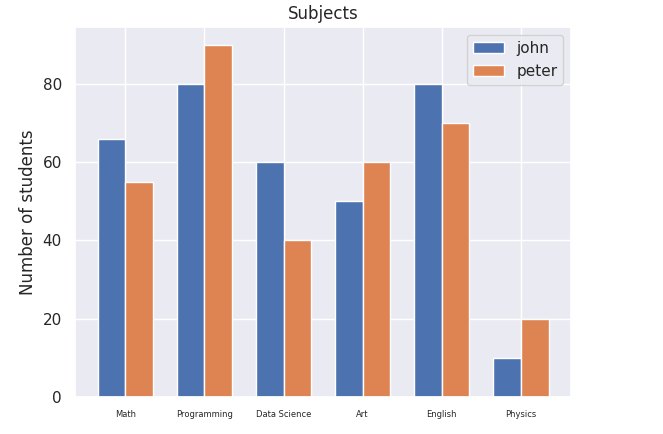
굳!
히스토그램
- 히스토그램
- 도수분포표를 그래프로 나타낸 것
- 가로축은 변수 값, 세로축은 빈도나 비율을 나타냄
plt.hist():히스토그램을 만들어주는 메소드bins=인자를 통해 히스토그램의 막대 개수를 조절할 수 있다.- density=True 인 경우 frequency(빈도) 대신 density(비율)를 y축에 나타낸다.
즉 y축 값이 0~1로 변함
코드를 통해 자세히 알아보자
데이터는 numpy의 표준정규분포를 랜덤하게 불러오는 random.randn() 메소드를 이용했다. (random.rand() 와는 다르다.)
x = np.random.randn(100000)
plt.hist(x, bins=30)10만개의 정규분포를 이루는 숫자를 불러와서 히스토그램 작성!
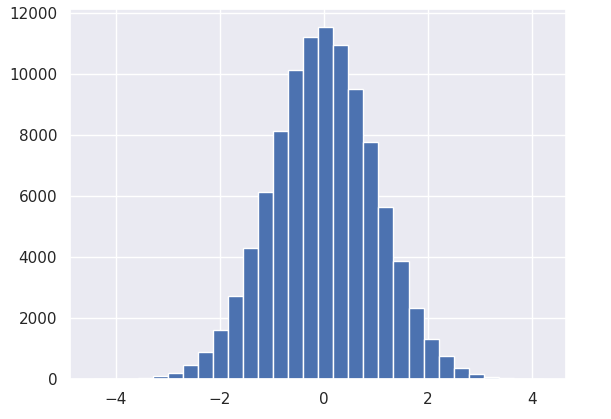
density=True 인 경우
x = np.random.randn(100000)
plt.hist(x, bins=30,density=True) 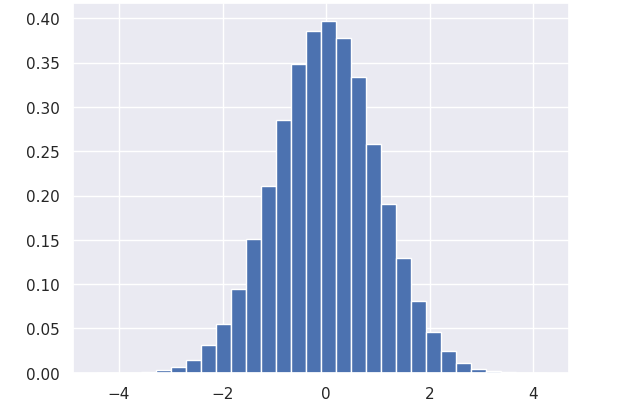
y축 레이블이 비율로 변경되었다.
