- 데이터를 설명하는 feature x와 알아보고자 하는 label y가 있을 때, 어떠한 feature가 y를 설명하는데에 있어
중요한 feature인지 아는 것 또한 매우 중요하다.
- 지금 까지 배운 데이터 모델링 Logistic regression이나 linear regression, Support vector machine, 그리고 random forest 모두
학습이 된 상태에서 어떠한 feature를 주로 보고있는지를 보여주는 값을들 가지고 있었다. - 이들을 전부 사용 후
마지막으로, 각 feature들과 label 간의 상관관계 분석을 통해 어떤 feature가 중요한지를 안다면
의사결정 과정에서 큰도움이 될 수 있습니다
(e.g. 문제를 일으키는 주된 원인이 무엇인지 파악할 경우)
Feature analysis - Linear regression, Logistic regression
- Regression에서의 Linear regression,
Classification에서의 Logistic regression 모두
학습이 된 상태에서 .coef 와 .intercept 를
조회할 수 있다. - .coef는 각 feature들에 대해서 각각 곱해지는 값,
.intercept 는 절편을 의미 - .coef_의 절대값이 상대적으로 큰 feature가
있다면, label을 설명하는데 중요한 feature일 수
있다.
# Logistic Regression
from sklearn.linear_model import LogisticRegression
lgr = LogisticRegression()
# training
lgr.fit(X_train, y_train)
lgr.coef_
array([[-1.74894748e+00, 2.05970508e+00, 6.90864943e-01,
-1.13234564e+00, 5.70392800e-01, -1.52202120e-03,
3.35484430e-01, 2.87431155e-01, 1.24852192e-01,
6.05941756e-01]])
lgr.intercept_
array([-0.489761])상대적으로 .coef_ 값이 큰 첫 번째, 두 번째
feature에 대해서 label을 color로 주고 scatter
plot을 그려보자
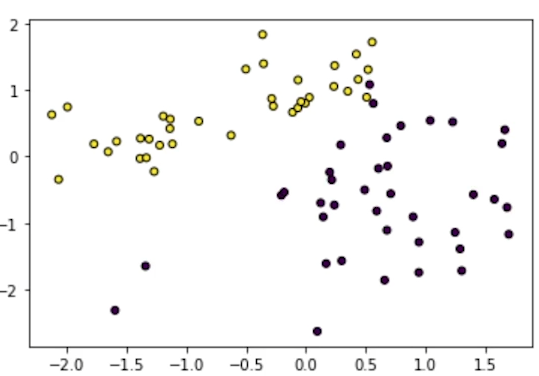
- 두 변수가 label을 설명하는데 중요한 feature일
수도 있다는 것을 알 수 있습니다
SVM
- Support vector machine 역시
학습이 된 상태에서 .coef 와 .intercept 를
조회할 수 있다.
# Logistic Regression
from sklearn.linear_model import LogisticRegression
lgr = LogisticRegression()
# training
lgr.fit(X_train, y_train)
lgr.coef_
array([[-1.74894748e+00, 2.05970508e+00, 6.90864943e-01,
-1.13234564e+00, 5.70392800e-01, -1.52202120e-03,
3.35484430e-01, 2.87431155e-01, 1.24852192e-01,
6.05941756e-01]])
# Support Vector Machines (SVM)
from sklearn.svm import SVC
svc = SVC(kernel='linear')
# training
svc.fit(X, y)
svc.coef_
array([[-1.10086514, 0.96241273, 0.45270636, -0.46822568,
0.21103224,
0.24624928, 0.21930329, -0.13029874, -0.22471887,
0.43350556]])Random forest
- Random forest 모델들에서는
자체적으로 feature importance score를
제공한다. - .featureimportances 를 통해
각 feature의 importance score를 구할 수 있다.
# Logistic Regression
from sklearn.linear_model import LogisticRegression
lgr = LogisticRegression()
# training
lgr.fit(X_train, y_train)
lgr.coef_
array([[-1.74894748e+00, 2.05970508e+00, 6.90864943e-01,
-1.13234564e+00, 5.70392800e-01, -1.52202120e-03,
3.35484430e-01, 2.87431155e-01, 1.24852192e-01,
6.05941756e-01]])
# Random forest classifier
from sklearn.ensemble import RandomForestClassifier
rfc= RandomForestClassifier(n_estimators=100, max_depth=200)
# training
rfc.fit(X, y)
rfc.feature_importances_
array([0.25357745, 0.26571728, 0.09979086, 0.17900508,
0.02387162,
0.02279699, 0.02225427, 0.04759967, 0.02854178, 0.056845
])
LV. 1