머신러닝 종류
레이블에 대한 이해
메타 데이터(Meta Data)와 레이블(Label)
-
메타 데이터란 주어진 기본 데이터에 추가적으로 제공하는 정보를 의미
- 데이터의 출처, 형식, 위치 등 데이터 간의 관계와 구조를 파악하거나,
데이터의 속성, 특성, 분류 등 데이터의 내용을 설명
- 데이터의 출처, 형식, 위치 등 데이터 간의 관계와 구조를 파악하거나,
-
레이블이란 특정 문제에 해당하는 데이터의 설명 혹은 답변을 의미
- 분류를 하는 문제라면 데이터가 속할 범주(클래스 라고도 부름)
- 목표 값을 찾는 회귀 문제라면 데이터가 표현할 특정 숫자를 의미
- 대부분 사람이 직접 생성해줘야 하는 경우가 많다.
- 혹은 타겟이라고 부르기도 한다.
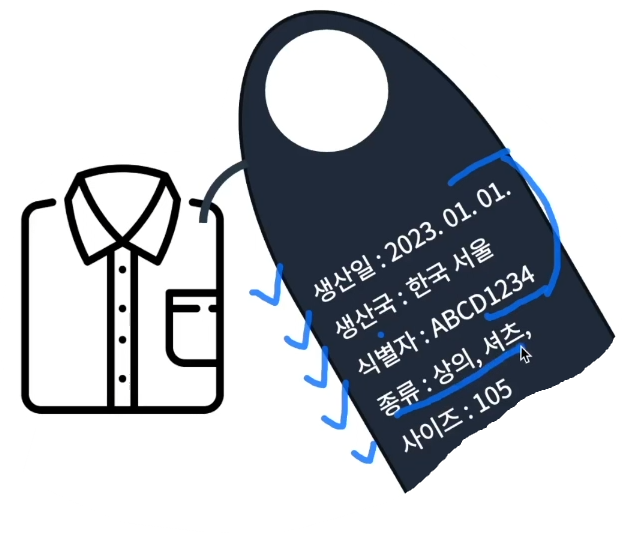
문제에 따라 다르겠지만
메타데이터 = 생산일, 생산국, 식별자
레이블 = 종류, 사이즈
로 볼 수 있다.
지도 학습, Supervised Learning
- 정답 레이블 정보를 활용해 알고리즘을 학습하는 학습 방법론
- 이 방법으로 학습되는 알고리즘은
데이터와 정답인 레이블 사이의 관계를 파악하는 목적을 갖고 있다.
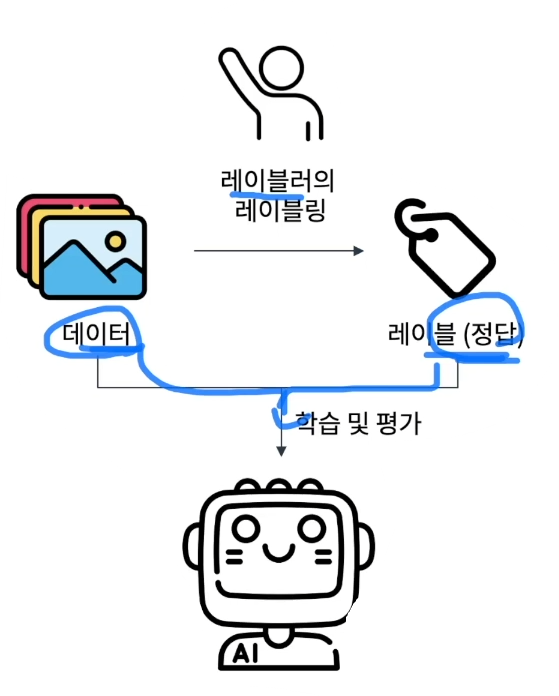
- 특징 및 장점
- 정답이 존재하므로 모델이 풀어야하는 문제가 비교적 쉽고 잘 학습 됨
- 또한, 명확한 평가 수치가 존재하며 학습된 모델의 성능을 쉽게 측정할 수 있음.
- 단점
- 정답이 필요하므로 이를 위해 추가적인 시간, 노동, 비용이 필요
- 정답을 매기는 행위에 필요한 전문 인력과 같은 추가비용이 발생
- 정답이 필요하므로 이를 위해 추가적인 시간, 노동, 비용이 필요
비지도 학습, Un-Supervised Learning
- 정답 레이블 정보가 없이 입력 데이터만을 활용해 알고리즘을 학습하는 학습 방법론
- 이 방법으로 학습되는 알고리즘은
데이터 내부에 존재하는 패턴을 스스로 파악하는 목적을 갖고 있음
특징 및 장점
- 정답(레이블)을 따로 준비할 필요가 없으므로 비용적인 이점이 있다.
- 사용자가 의도한 패턴 이외의 새로운 패턴을 찾을 가능성이 있으며
창작과 같은 다양한 활용 분야에 사용할 수 있음(GPT가 있다.)
단점 ㅠㅠ
- 학습된 모델의 성능을 측정하기 위한 기준(정답)이 없어 결과 해석이 주관적일 수 있다.
- 신뢰할 수 있는 결과를 얻기 위해 다수의 데이터가 필요함
준지도 학습, Semi-Supervised Learning
- 일부의 데이터만 정답이 존재하고, 다수의 데이터에는 레이블이 없는 상황에서 알고리즘을 학습하는 학습 방법론
- 이 방법으로 학습되는 알고리즘은
지도 학습과 비지도 학습의 특징을 일부 차용하여
일부 레이블링 된 데이터로 특성을 파악하고 레이블링 되지 않은 데이터로
전체 데이터의 패턴을 파악하는 방식으로 학습이 진행
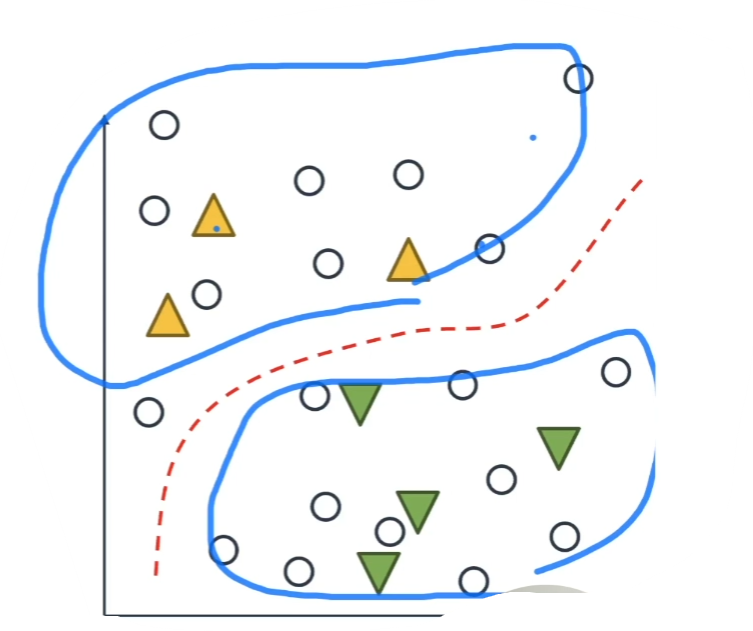
특징 및 장점!
- 레이블이 부족한 데이터셋에서 유용
- 많은 데이터를 활용할 수 있으므로 일반화 성능을 향상시킬 수 있다.
단점
- 품질이 낮은 레이블이나 데이터 존재에 특히 취약할 수 있다.
- 레이블링을 나누는 기준이 애매해 지기 때문.
- 알고리즘의 복잡성이 증가한다. 구현 및 활용에 어려움이 있을 수 있다.
자기 지도 학습, Self-Supervised Learning
- 정답이 하나도 없는 데이터에서, 정답을 강제로 생성 후 학습하는 학습 방법론
- e.g. 강아지 얼굴을 없앤 사진을 넣으면 강아지 얼굴을 복원해줌!

- 이 방법으로 학습되는 알고리즘은
데이터 내부를 강제로 훼손 후 복원하는 방법을 주로 사용
- 이 과정에서 특정 데이터 내부의 성질을 파악하는데 사용됨 - 이렇게 만들어진 알고리즘은 해당 데이터를 이용한 다른 문제에 적용
특징 및 장점
- 레이블 없이 데이터의 특징을 파악할 수 있다.
- 다양한 데이터에 활용할 수 있다.
단점
- 목적하는 문제를 직접적으로 해결하는 것이 아니므로
N회 이상의 추가적인 학습 과정이 필요할 수 있음 - 알고리즘이 잘못된 패턴을 학습할 위험이 있다.
- 훼손 데이터가 자유도가 높은 데이터인 경우 잘못된 패턴을 넣을 수 있다.
강화 학습, Reinforcement Learning
- 어떤 환경에서
상호작용하는 에이전트가
보상을 이용해
특정 행동을 하도록 유도하는 학습 방법론
- e.g. 강아지 훈련할 때 처럼!
- 강아지에게 앉아를 가르칠때(환경 및 특정 행동)
- 강아지(에이전트) : 다양한 행동을 함
- 훈련사 : 강아지가 앉는 행동을 하면 간식(보상)을 줌 - 대표적 알고리즘으로 알파고가 있다.
- 잘못된 수를 놓으면 벌! 잘놓으면 보상을 주면서 가르침.

LV. 1