성능 평가 메트릭
성능 평가란?
머신 러닝 모델의 성능을 객관적으로 측정하고 비교하는 과정에서 사용
이를 통해 모델의 강점과 약점을 파악
-
성능 평가에 사용되는 지표를 metric이라고 함
-
Metric에는 다양한 종류가 있으며
-
각각의 지표가 제공하는 정보가 다름
• 목적에 맞는 올바른 metric을 선택해야 함
• 또는 해석이 잘 되는 metric! -
풀고자 하는 문제에 딱 맞는 metric이 존재하지만
-
적지 않은 경우로 적절한 metric이 없을 수 있음
• 예를 들어, 고객이 만족하는 텍스트 prompt 기반 이미지 생성 모델의 성능은???
• 특히 비지도 학습의 경우 문제의 목적에 딱 fit한 metric을 찾기 어려움 -
원초적이지만 시각화도 좋은 방법!
지금까지 살펴본 Metric은
지도 학습
- 분류 문제
• 정확도 (Accuracy)
• 혼동 행렬(Confusion matrix)
• 정밀도 (Precision)
• 재현율 (Recall)
• F1 score
비지도 학습
- 군집화
• SSE (Sum of Squared Error)
• 실루엣 계수 (Silhouette Coefficient) - 이상치 탐지
• 분류 문제의 metric을 대안으로 활용
회귀 문제
- MSE (Mean Squared Error)
분류 문제 성능 추가 Metric
Confusion Matrix
분류 문제에서 모델의 성능을 이해하고 해석하기 위한 중요한 도구
실제 레이블과 예측 레이블을 비교해 모델의 성능을 시각적으로 표현한 행렬
- 다음과 같은 4가지 요소로 구성
• 진짜 양성 (True Positive, TP) /[맞다고한 예측이 맞았다.]
• 거짓 양성 (False Negative, FN) /[맞다고한 예측이 틀렸다.]
• 진짜 음성 (True Negative, TN)[틀렸다고한 예측이 맞았다.]
• 거짓 음성 (False Negative, FN)[틀렸다고한 예측이 틀렸다.]
• 이는 암기의 요소가 아니라 이름을 갖게 된 과정을 이해해야 된다.
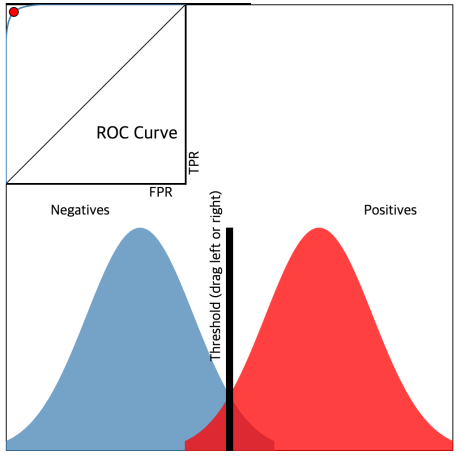
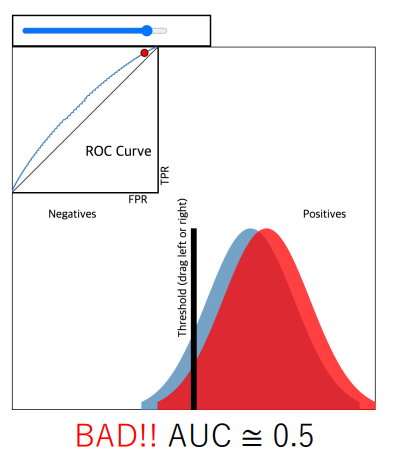
ROC(Receiver Operating Characteristic) curve
이진 분류 문제에서 널리 사용되는 모델 성능 측정 도구
양성(positive)과 음성(negative)를 나누는 임계값의 변화에 따른 성능을 시각화 한 그래프
• 성능은 아래의 두 파라미터를 사용

- 왼쪽 위에 붉은색 포인트가 존재하게 하는 임계치를 선택하는게 좋음!
즉 x축이 0과 가까우면서 y축이 제일 높은 지역을 찾는게 좋다!
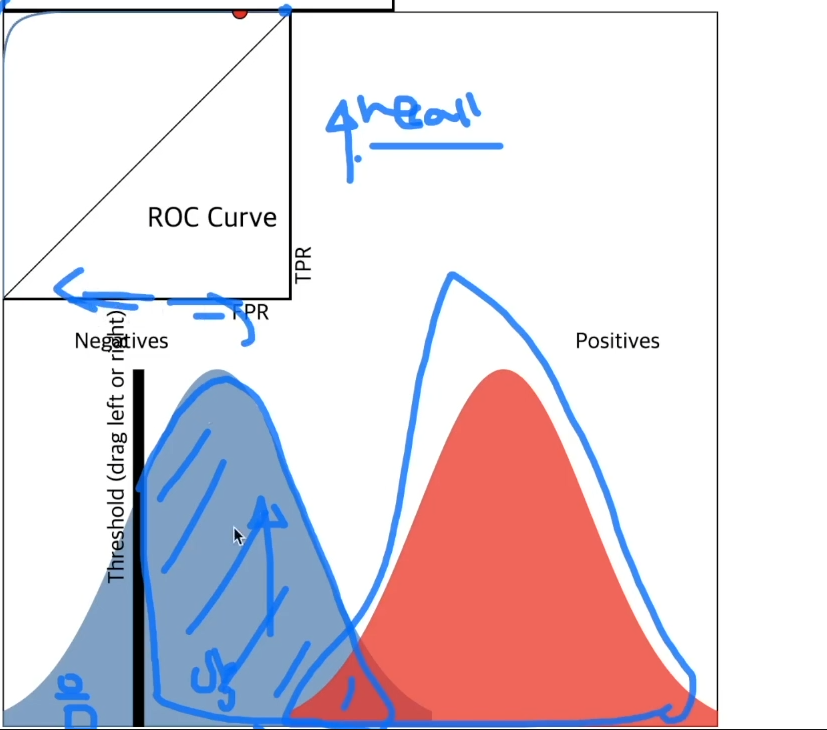
아래 예시는 거짓 양성률이 높아진 모습.
예측에 실패한 데이터가 클 수록 ROC Curve는 0에서 멀어짐.
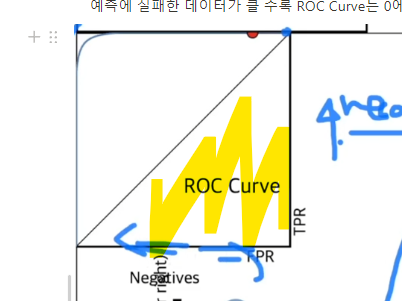
- 즉, ROC 커브란
• 머신러닝 모델이 양성을 최대한 많이, 잘 찾아내면서
• 잡음에 의한 거짓 탐지를 최소화 하는지를 바탕으로
• 적절한 임계치를 찾는 도구
AUC(Area Under the Curve) 점수
ROC커브의 아래쪽 면적을 AUC 라고한다.
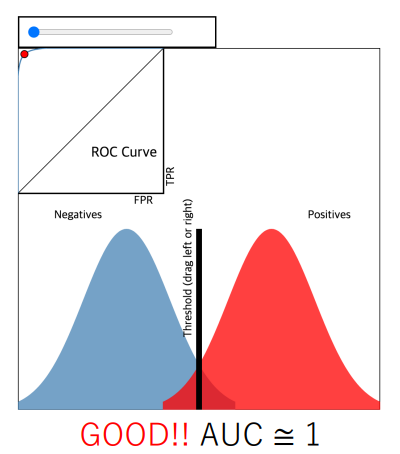
음성과 양성을 잘 구분할수록 좋은 분류기!
- 그것이 ROC 커브 안에서도 확인이 가능
• 음성과 양성을 잘 나눴다면 ROC 커브는 왼쪽 위 방향으로 그래프가 치우침
• 그렇지 않다면 y = x 그래프에 수렴 - 즉, 좋은 분류기인지 아닌지에따라
ROC 커브의 모양이 바뀌고
그것을 수치로 나타내려면 ROC 커브의 아래 면적으로 표시할 수 있음
• 그래서 이름이 Area Under the Curve!
• 최대 : 1 최소 : 0.5
- 정리하면, AUC는 분류기의 전반적인 성능을 알 수 있는 척도로
ROC 커브의 아랫 면적을 의미함
실습!
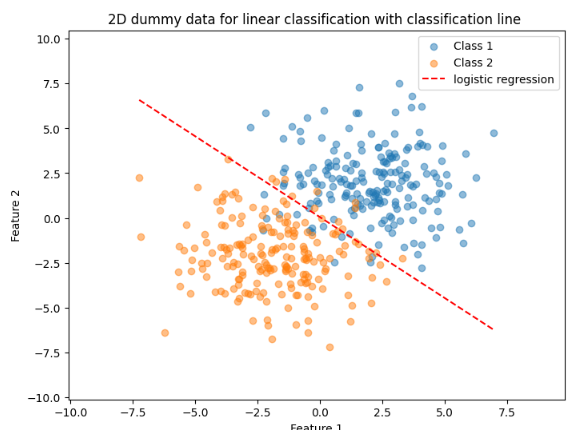
아래와 같은 분류기를 만들었다고 하자
이후 Confusion Matrix를 만들어줌.
from sklearn.metrics import confusion_matrix
y_pred = logistic_reg.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
# 혼동 행렬 시각화
plt.figure(figsize=(6, 6))
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.colorbar()
tick_marks = np.arange(2)
plt.xticks(tick_marks, ['Predicted Negative', 'Predicted Positive'])
plt.yticks(tick_marks, ['Actual Negative', 'Actual Positive'])
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix with Labels')
labels = ['TN', 'FP', 'FN', 'TP']
label_values = [cm[0, 0], cm[0, 1], cm[1, 0], cm[1, 1]]
label_colors = ['white', 'black', 'black', 'white']
indices = [(0, 0), (0, 1), (1, 0), (1, 1)]
for label, value, color, (i, j) in zip(labels, label_values, label_colors, indices):
plt.text(j, i, f'{label}\n{value}', ha='center', va='center', color=color)
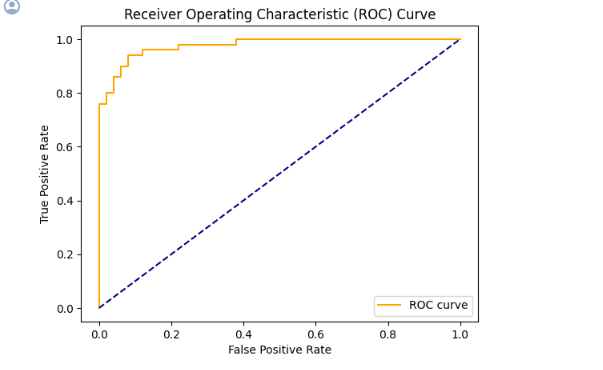
plt.show()- ROC 커브 생성 및 시각화
from sklearn.metrics import roc_curve
# 각 데이터가 양성일 확률, 양성만 취할 예정이므로 1 위치의 값만 가져옴
y_pred_proba = logistic_reg.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)# ROC 커브 시각화
plt.plot(fpr, tpr, color='orange', label=f'ROC curve')
plt.plot([0, 1], [0, 1], color='navy', linestyle='--') # y=x 직선
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show()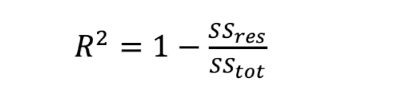
잘만들어진 모습을 볼 수 있다.
이제 여기서 제일 괜찮은 스레쉬 홀드 위치를 찾자면!
# 최적 threshold 위치 찾기
# tpr은 크고 fpr은 작아야하므로 아래와 같은 코드로 위치를 선정
closest_leftupper_conner = np.argmin(np.abs(tpr - 1) + fpr)
optimal_threshold = thresholds[closest_leftupper_conner]
print(f'가장 좌측 상단에 위치한 포인트의 threshold 값 : {optimal_threshold}')출력값:
가장 좌측 상단에 위치한 포인트의 threshold 값 : 0.6006122864959837
AUC또한 구해볼 수 있음.
from sklearn.metrics import auc
roc_auc = auc(fpr, tpr)
print(f'ROC 커브로부터 구한 AUC : {roc_auc}')출력값:
ROC 커브로부터 구한 AUC : 0.9768
회귀 문제 성능 추가 Metric
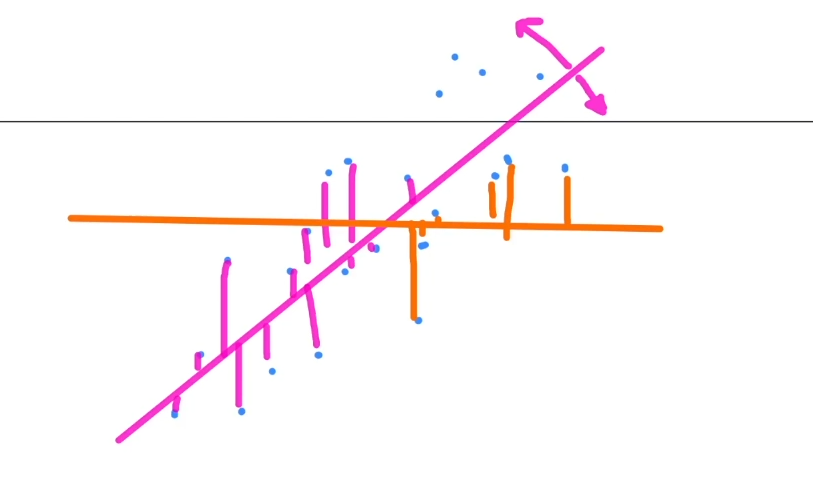
R^2
회귀 모델의 성능을 평가하는 통계적 지표
• 결정 계수(Coefficient of Determination)라고도 함
- 모델이 데이터의 변동성을 얼마나 잘 설명하는지를 나타냄

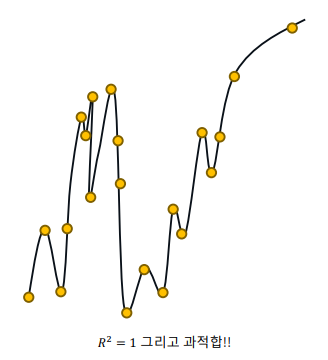
주의 사항! R^2 와 과적합
R^2값은 클 수록 좋음.
하지만! 과적합의 위험성을 주의해야 함
- 더 많은 변수를 추가하면 모델이 비대해지고 R^2값은 자동으로 증가
• 이때 과적합의 상태로 빠지는 것을 주의
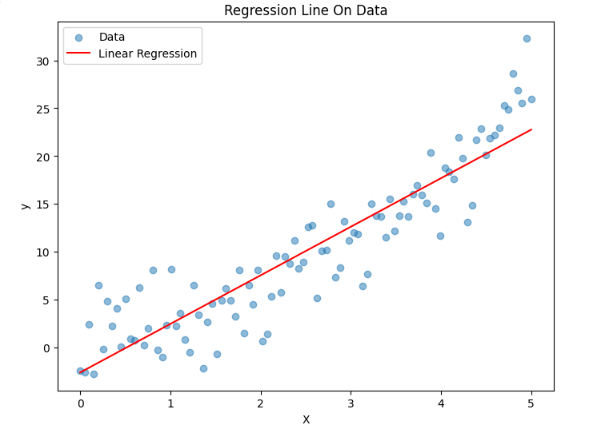
실습
모델에 아래와 같은 회귀선을 그었다.
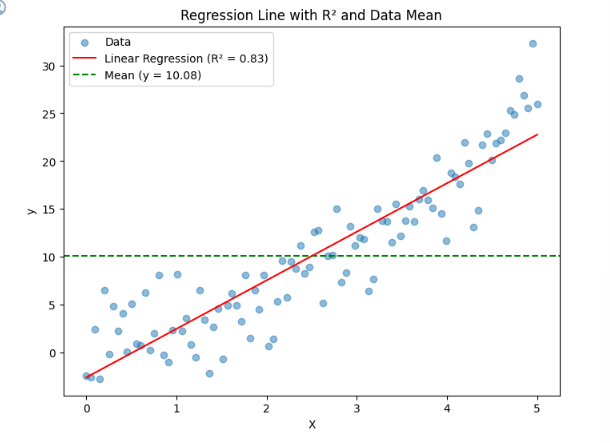
- R^2값 확인
from sklearn.metrics import r2_score
r2 = r2_score(y, y_pred)
print(f'R² 값 : {r2:.4f}')출력값:
R² 값 : 0.8278
즉, 아래의 평균선 대비 설명력이 어느정도 있는지 수치화.
