개발환경 : colab
aa_example 테이블의 user_id를 가지고 다음을 수행
- 앞서 설명한 파이썬 함수로 A/B로 나눴을 때 A에 속한 사용자의 수와 B에 속한 사용자의 수
- 앞서 설명한 SQL 함수로 A/B로 나눴을 때 A에 속한 사용자의 수와 B에 속한 사용자의 수
1. Redshift 데이터 불러오기
- 함수 생성
import psycopg2
import pandas as pd
import pandas.io.sql as sqlio
import math
# Redshift connection 함수
def get_Redshift_connection(autocommit):
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
redshift_user = "guest"
redshift_pass = "Guest1234"
port = 5439
dbname = "dev"
conn = psycopg2.connect("dbname={dbname} user={user} host={host} password={password} port={port}".format(
dbname=dbname,
user=redshift_user,
password=redshift_pass,
host=host,
port=port
))
conn.set_session(autocommit=autocommit)
return conn- 함수 사용
conn = get_Redshift_connection(True)이후 SQL을 사용해서 판다스 데이터 프레임 형태로 가져온다.
df = sqlio.read_sql_query("SELECT * FROM raw_data.aa_example LIMIT 10", conn) 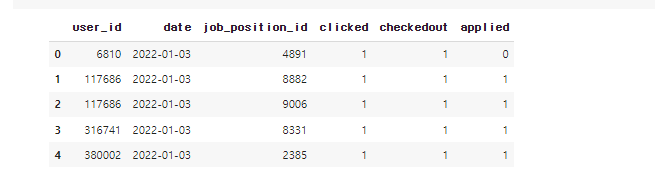
- job_position_id : 포지션 사이트 아이디
- clicked : 유입 여부
- checkedout : 상세 페이지 확인 여부
- applied 지원 여부
2. 사용자 분류
A/A Test 비교 - SQL
A와 B에 속한 사용자 수와 세션 수 카운트하기
- 각 유저를 나누어 준다.
sql = """
SELECT
MOD(STRTOL(LEFT(MD5(user_id),15), 16), 2) variant_id,
COUNT(DISTINCT user_id) user_sum,
COUNT(1) session_sum
FROM (
SELECT DISTINCT user_id, date
FROM raw_data.aa_example
)
GROUP BY 1;
"""
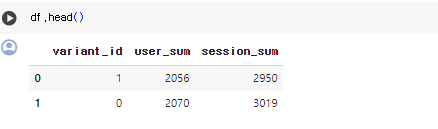
df = sqlio.read_sql_query(sql, conn)- variant_id 1과 0에 각 각 몇명의 사용자와 몇개의 세션이 나누어졌는지 확인
A/A Test 비교 - Python
앞서 만든 split_userid 함수 호출하여 A와 B에 속한 사용자 수와 세션 수 카운트하기
- DISTINCT한 유저 아이디를 가지고 온다.
sql = """SELECT DISTINCT user_id
FROM raw_data.aa_example
"""
df = sqlio.read_sql_query(sql, conn) 
- 유저 아이디별로 랜덤하게 16진수로 변경→10진수로 변경→나머지 0or1로 유저를 나눔
import hashlib
def split_userid(id, num_of_variants=2):
h = hashlib.md5(str(id).encode())
return int(h.hexdigest(), 16) % num_of_variantsa_user_count = 0
b_user_count = 0
for index, row in df.iterrows():
if split_userid(row["user_id"]) == 0:
a_user_count += 1
else:
b_user_count += 1
print(a_user_count, b_user_count)출력값 : 2104 2022
각 유저별로 나눠진 수가 보인다.
3. Z-test를 이용한 비율 확인
위에서 각 유저를 두 그룹으로 나누었다.
- SQL
- A : 2056
B : 2070
- A : 2056
- Python
- A : 2104
- B : 2022
이때 각 그룹이 95%의 확률로 비슷한 크기인지 파악을 해야 된다.
이때 z-score를 구해서 각 그룹이 -1.96~1.96 사이에 있으면 데이터를 사용한다.
Z-test 실제 계산
● A 사용자 수는 2070
● B 사용자 수는 2056
● N = 2070 + 2056 = 4126
● 비교대상 확률 = 0.5
● P(B) = 2056/4126 = 0.498
● z-score = (0.498-0.5) / sqrt(0.498*(1-0.498)/4126)
= -0.217
-1.96~1.96내에 있기 때문에 귀무가설을 채택할 수 있다.
귀무가설 : 두 그룹은 동일하다.
코드를 이용한 Z-test 계산
Scipy 모듈 사용해서 계산해보자
from statsmodels.stats.proportion import proportions_ztest
n_test = 2056
n_ctrl = 2070
stats, pvalue = proportions_ztest(n_test, n_ctrl+n_test, value=0.5, alternative='two-sided')
print(stats, pvalue)proportions_ztest인자 설명- n_test = 비교대상
- n_ctrl+n_test = 전체 수
- value=0.5 = 비교대상확룰
- alternative='two-sided' = 양쪽 비교
출력값 : -0.21795454207115086 0.8274645300878356
손으로 계산 했을때와 동일한 값이 나온다.

LV. 1